 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 12, 2021
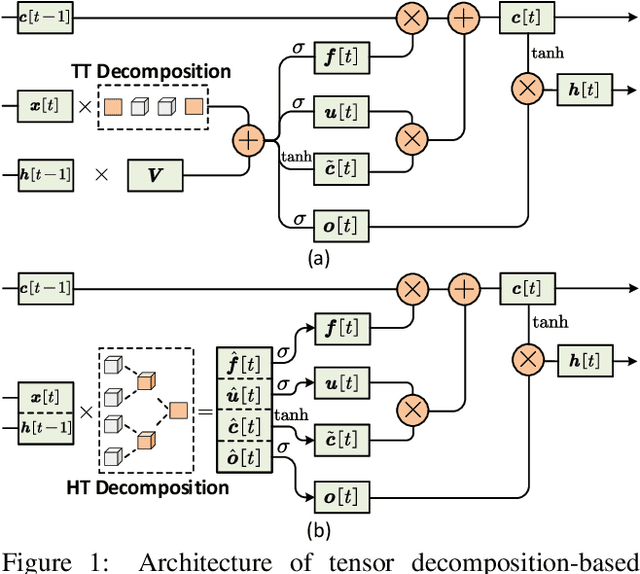
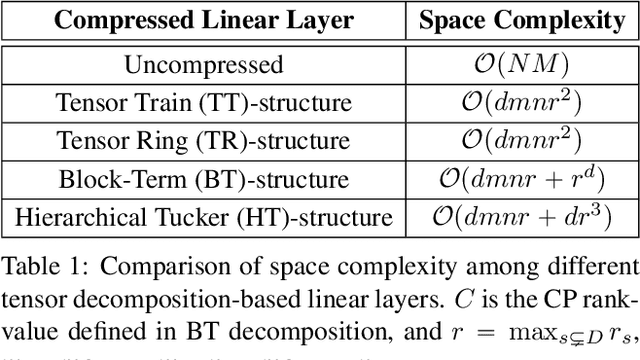
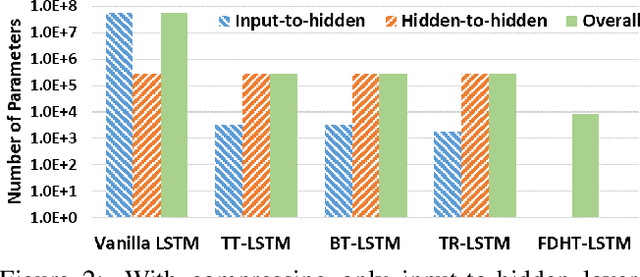
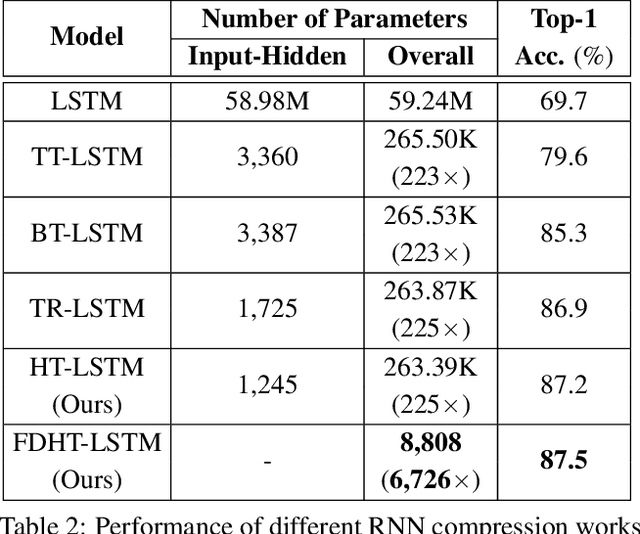
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation
Dec 14, 2020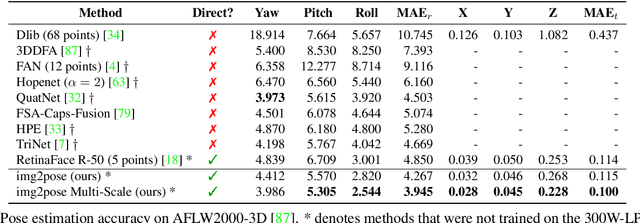

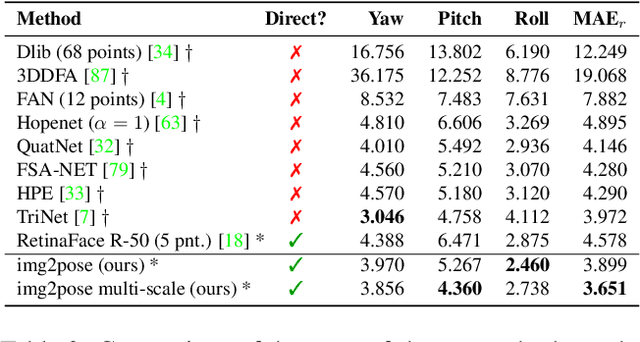
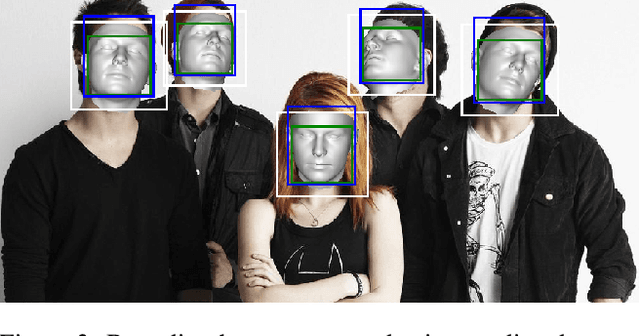
We propose real-time, six degrees of freedom (6DoF), 3D face pose estimation without face detection or landmark localization. We observe that estimating the 6DoF rigid transformation of a face is a simpler problem than facial landmark detection, often used for 3D face alignment. In addition, 6DoF offers more information than face bounding box labels. We leverage these observations to make multiple contributions: (a) We describe an easily trained, efficient, Faster R-CNN--based model which regresses 6DoF pose for all faces in the photo, without preliminary face detection. (b) We explain how pose is converted and kept consistent between the input photo and arbitrary crops created while training and evaluating our model. (c) Finally, we show how face poses can replace detection bounding box training labels. Tests on AFLW2000-3D and BIWI show that our method runs at real-time and outperforms state of the art (SotA) face pose estimators. Remarkably, our method also surpasses SotA models of comparable complexity on the WIDER FACE detection benchmark, despite not been optimized on bounding box labels.
Deep Learning-based Prediction of Key Performance Indicators for Electrical Machine
Jan 23, 2021
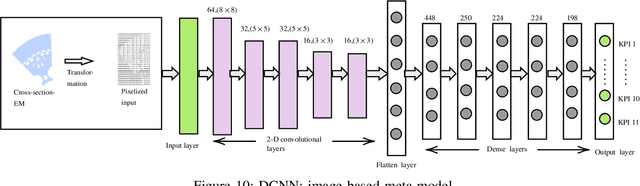
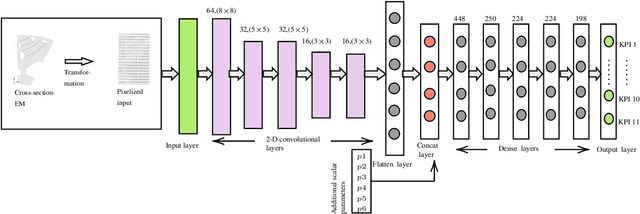
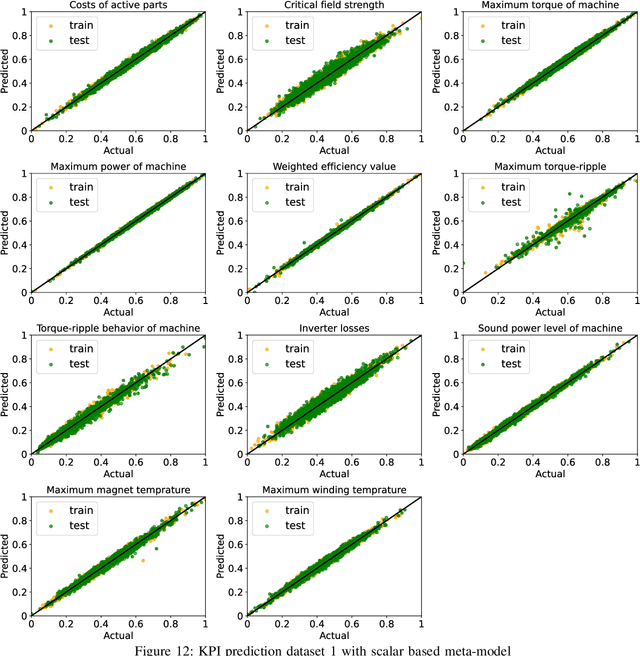
The design of an electrical machine can be quantified and evaluated by Key Performance Indicators (KPIs) such as maximum torque, critical field strength, costs of active parts, sound power, etc. Generally, cross-domain tool-chains are used to optimize all the KPIs from different domains (multi-objective optimization) by varying the given input parameters in the largest possible design space. This optimization process involves magneto-static finite element simulation to obtain these decisive KPIs. It makes the whole process a vehemently time-consuming computational task that counts on the availability of resources with the involvement of high computational cost. In this paper, a data-aided, deep learning-based meta-model is employed to predict the KPIs of an electrical machine quickly and with high accuracy to accelerate the full optimization process and reduce its computational costs. The focus is on analyzing various forms of input data that serve as a geometry representation of the machine. Namely, these are the cross-section image of the electrical machine that allows a very general description of the geometry relating to different topologies and the classical way with scalar parametrization of geometry. The impact of the resolution of the image is studied in detail. The results show a high prediction accuracy and proof that the validity of a deep learning-based meta-model to minimize the optimization time. The results also indicate that the prediction quality of an image-based approach can be made comparable to the classical way based on scalar parameters.
Symbiotic System Design for Safe and Resilient Autonomous Robotics in Offshore Wind Farms
Jan 23, 2021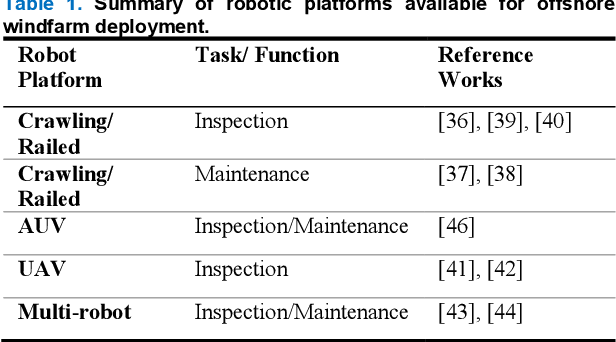
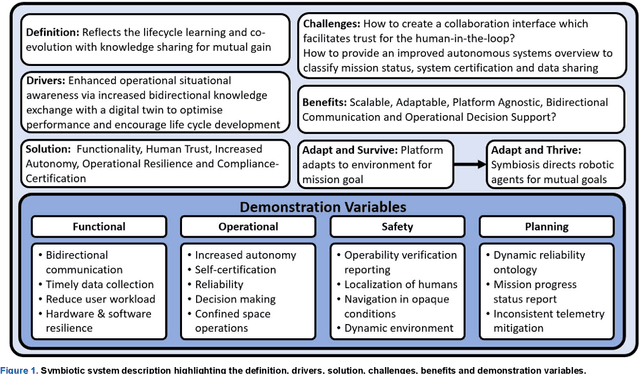
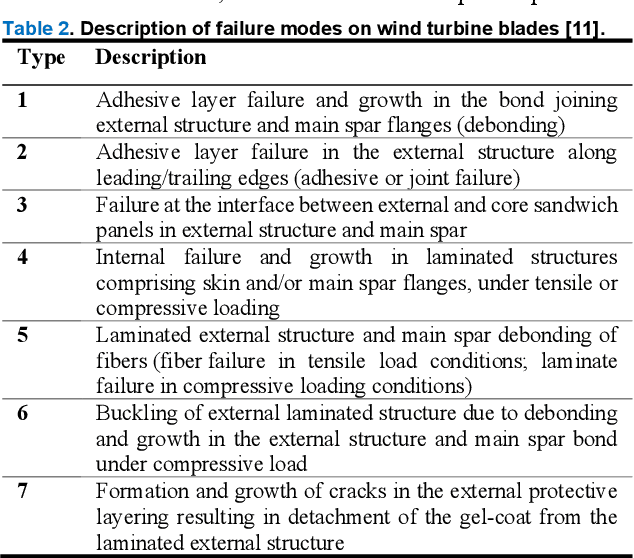
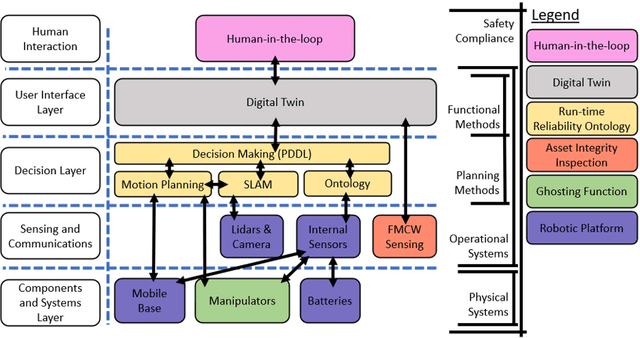
To reduce Operation and Maintenance (O&M) costs on offshore wind farms, wherein 80% of the O&M cost relates to deploying personnel, the offshore wind sector looks to robotics and Artificial Intelligence (AI) for solutions. Barriers to Beyond Visual Line of Sight (BVLOS) robotics include operational safety compliance and resilience, inhibiting the commercialization of autonomous services offshore. To address safety and resilience challenges we propose a symbiotic system; reflecting the lifecycle learning and co-evolution with knowledge sharing for mutual gain of robotic platforms and remote human operators. Our methodology enables the run-time verification of safety, reliability and resilience during autonomous missions. We synchronize digital models of the robot, environment and infrastructure and integrate front-end analytics and bidirectional communication for autonomous adaptive mission planning and situation reporting to a remote operator. A reliability ontology for the deployed robot, based on our holistic hierarchical-relational model, supports computationally efficient platform data analysis. We analyze the mission status and diagnostics of critical sub-systems within the robot to provide automatic updates to our run-time reliability ontology, enabling faults to be translated into failure modes for decision making during the mission. We demonstrate an asset inspection mission within a confined space and employ millimeter-wave sensing to enhance situational awareness to detect the presence of obscured personnel to mitigate risk. Our results demonstrate a symbiotic system provides an enhanced resilience capability to BVLOS missions. A symbiotic system addresses the operational challenges and reprioritization of autonomous mission objectives. This advances the technology required to achieve fully trustworthy autonomous systems.
An efficient Quasi-Newton method for nonlinear inverse problems via learned singular values
Dec 14, 2020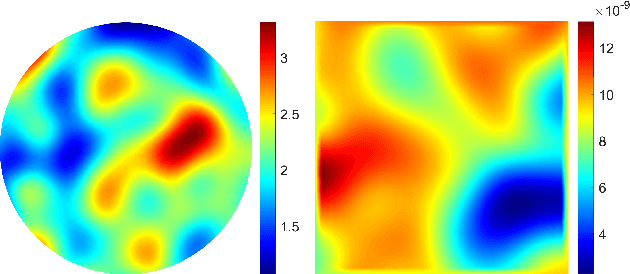
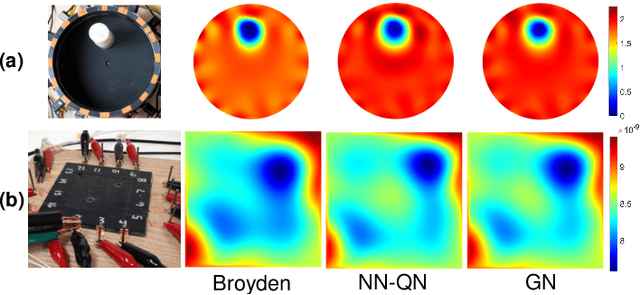

Solving complex optimization problems in engineering and the physical sciences requires repetitive computation of multi-dimensional function derivatives. Commonly, this requires computationally-demanding numerical differentiation such as perturbation techniques, which ultimately limits the use for time-sensitive applications. In particular, in nonlinear inverse problems Gauss-Newton methods are used that require iterative updates to be computed from the Jacobian. Computationally more efficient alternatives are Quasi-Newton methods, where the repeated computation of the Jacobian is replaced by an approximate update. Here we present a highly efficient data-driven Quasi-Newton method applicable to nonlinear inverse problems. We achieve this, by using the singular value decomposition and learning a mapping from model outputs to the singular values to compute the updated Jacobian. This enables a speed-up expected of Quasi-Newton methods without accumulating roundoff errors, enabling time-critical applications and allowing for flexible incorporation of prior knowledge necessary to solve ill-posed problems. We present results for the highly non-linear inverse problem of electrical impedance tomography with experimental data.
Efficient Spatialtemporal Context Modeling for Action Recognition
Apr 06, 2021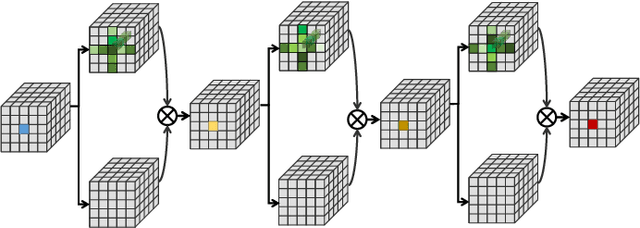
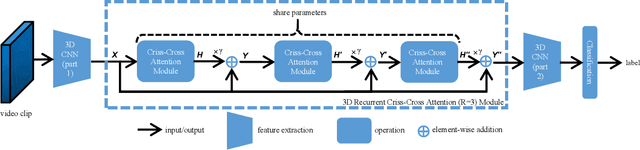
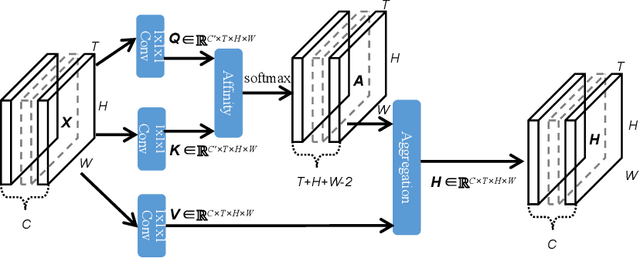
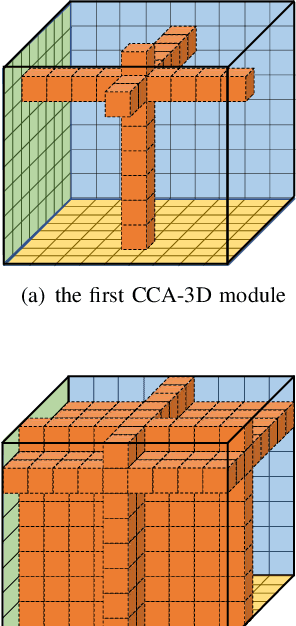
Contextual information plays an important role in action recognition. Local operations have difficulty to model the relation between two elements with a long-distance interval. However, directly modeling the contextual information between any two points brings huge cost in computation and memory, especially for action recognition, where there is an additional temporal dimension. Inspired from 2D criss-cross attention used in segmentation task, we propose a recurrent 3D criss-cross attention (RCCA-3D) module to model the dense long-range spatiotemporal contextual information in video for action recognition. The global context is factorized into sparse relation maps. We model the relationship between points in the same line along the direction of horizon, vertical and depth at each time, which forms a 3D criss-cross structure, and duplicate the same operation with recurrent mechanism to transmit the relation between points in a line to a plane finally to the whole spatiotemporal space. Compared with the non-local method, the proposed RCCA-3D module reduces the number of parameters and FLOPs by 25% and 30% for video context modeling. We evaluate the performance of RCCA-3D with two latest action recognition networks on three datasets and make a thorough analysis of the architecture, obtaining the optimal way to factorize and fuse the relation maps. Comparisons with other state-of-the-art methods demonstrate the effectiveness and efficiency of our model.
Unsupervised Motion Representation Enhanced Network for Action Recognition
Mar 05, 2021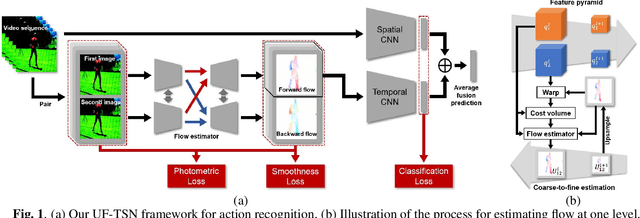


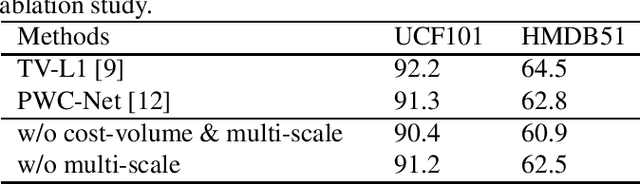
Learning reliable motion representation between consecutive frames, such as optical flow, has proven to have great promotion to video understanding. However, the TV-L1 method, an effective optical flow solver, is time-consuming and expensive in storage for caching the extracted optical flow. To fill the gap, we propose UF-TSN, a novel end-to-end action recognition approach enhanced with an embedded lightweight unsupervised optical flow estimator. UF-TSN estimates motion cues from adjacent frames in a coarse-to-fine manner and focuses on small displacement for each level by extracting pyramid of feature and warping one to the other according to the estimated flow of the last level. Due to the lack of labeled motion for action datasets, we constrain the flow prediction with multi-scale photometric consistency and edge-aware smoothness. Compared with state-of-the-art unsupervised motion representation learning methods, our model achieves better accuracy while maintaining efficiency, which is competitive with some supervised or more complicated approaches.
Towards Ultra-Resolution Neural Style Transfer via Thumbnail Instance Normalization
Mar 22, 2021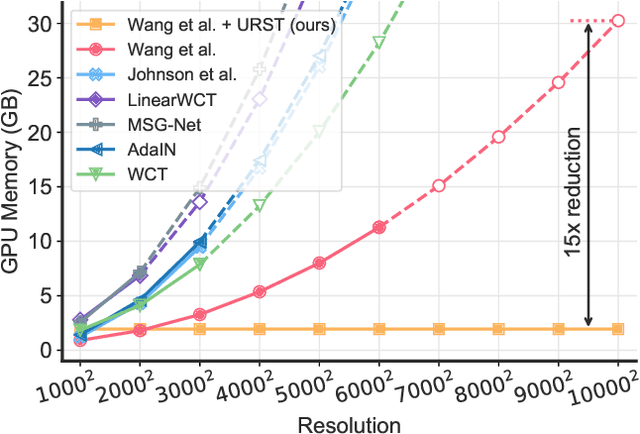
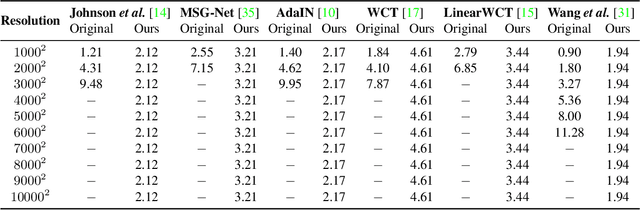

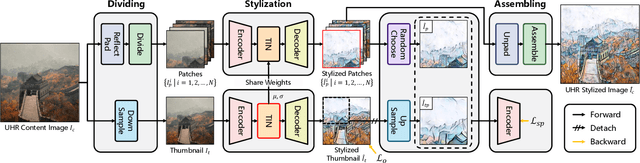
We present an extremely simple Ultra-Resolution Style Transfer framework, termed URST, to flexibly process arbitrary high-resolution images (e.g., 10000x10000 pixels) style transfer for the first time. Most of the existing state-of-the-art methods would fall short due to massive memory cost and small stroke size when processing ultra-high resolution images. URST completely avoids the memory problem caused by ultra-high resolution images by 1) dividing the image into small patches and 2) performing patch-wise style transfer with a novel Thumbnail Instance Normalization (TIN). Specifically, TIN can extract thumbnail's normalization statistics and apply them to small patches, ensuring the style consistency among different patches. Overall, the URST framework has three merits compared to prior arts. 1) We divide input image into small patches and adopt TIN, successfully transferring image style with arbitrary high-resolution. 2) Experiments show that our URST surpasses existing SOTA methods on ultra-high resolution images benefiting from the effectiveness of the proposed stroke perceptual loss in enlarging the stroke size. 3) Our URST can be easily plugged into most existing style transfer methods and directly improve their performance even without training. Code is available at https://github.com/czczup/URST.
StackRec: Efficient Training of Very Deep Sequential Recommender Models by Layer Stacking
Dec 14, 2020
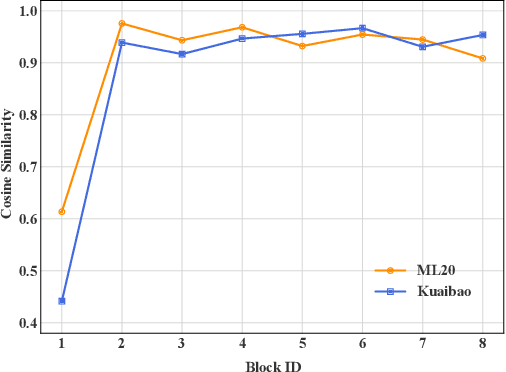
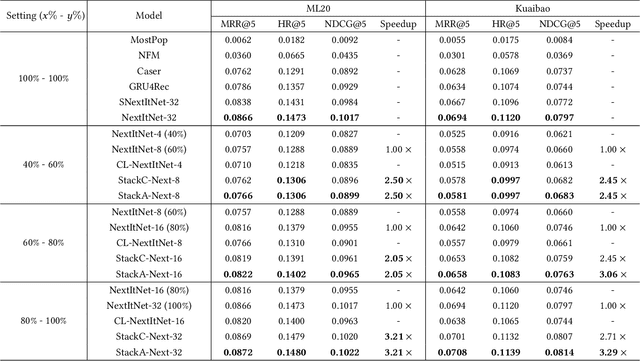
Deep learning has brought great progress for the sequential recommendation (SR) tasks. With the structure of advanced residual networks, sequential recommender models can be stacked with many hidden layers, e.g., up to 100 layers on real-world SR datasets. Training such a deep network requires expensive computation and longer training time, especially in situations when there are tens of billions of user-item interactions. To deal with such a challenge, we present StackRec, a simple but very efficient training framework for deep SR models by layer stacking. Specifically, we first offer an important insight that residual layers/blocks in a well-trained deep SR model have similar distribution. Enlightened by this, we propose progressively stacking such pre-trained residual layers/blocks so as to yield a deeper but easier-to-train SR model. We validate the proposed StackRec by instantiating with two state-of-the-art SR models in three practical scenarios and real-world datasets. Extensive experiments show that StackRec achieves not only comparable performance, but also significant acceleration in training time, compared to SR models that are trained from scratch.
Handling Missing Observations with an RNN-based Prediction-Update Cycle
Mar 22, 2021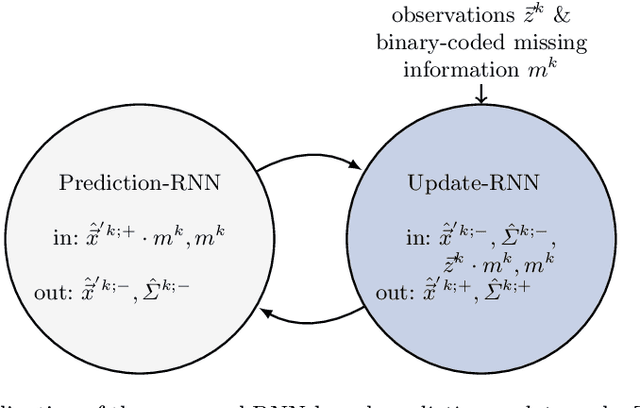
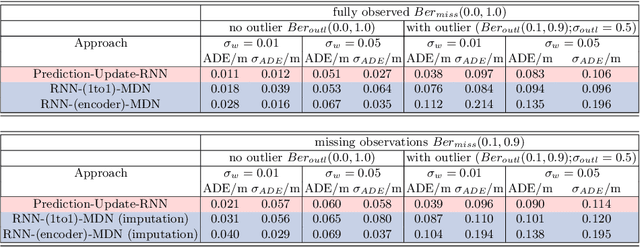
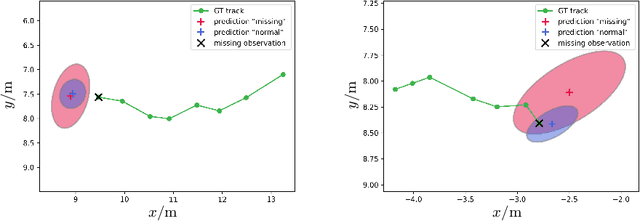
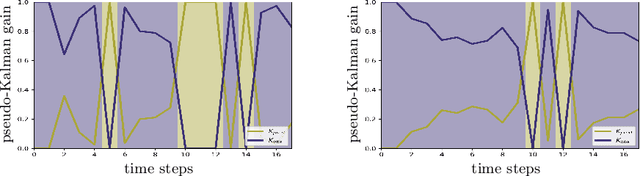
In tasks such as tracking, time-series data inevitably carry missing observations. While traditional tracking approaches can handle missing observations, recurrent neural networks (RNNs) are designed to receive input data in every step. Furthermore, current solutions for RNNs, like omitting the missing data or data imputation, are not sufficient to account for the resulting increased uncertainty. Towards this end, this paper introduces an RNN-based approach that provides a full temporal filtering cycle for motion state estimation. The Kalman filter inspired approach, enables to deal with missing observations and outliers. For providing a full temporal filtering cycle, a basic RNN is extended to take observations and the associated belief about its accuracy into account for updating the current state. An RNN prediction model, which generates a parametrized distribution to capture the predicted states, is combined with an RNN update model, which relies on the prediction model output and the current observation. By providing the model with masking information, binary-encoded missing events, the model can overcome limitations of standard techniques for dealing with missing input values. The model abilities are demonstrated on synthetic data reflecting prototypical pedestrian tracking scenarios.