 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Visual Attention and Invariance for Reinforcement Learning
Apr 07, 2021
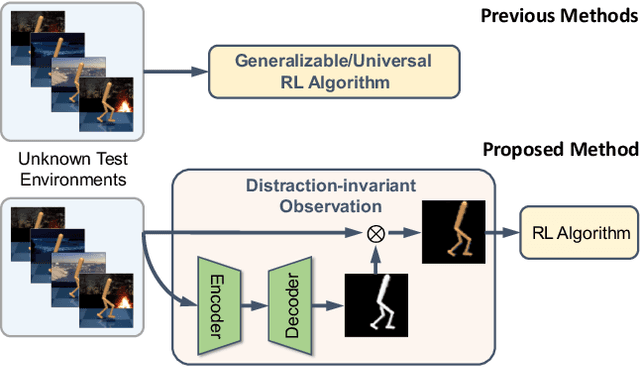
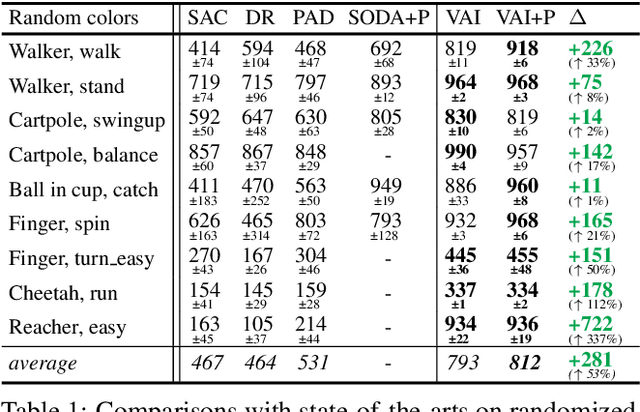
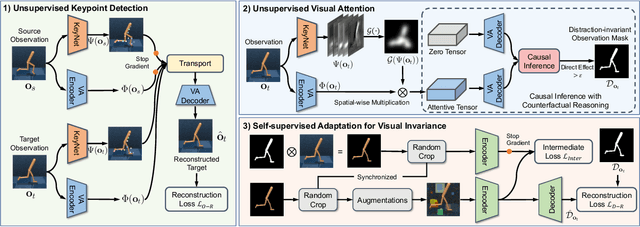
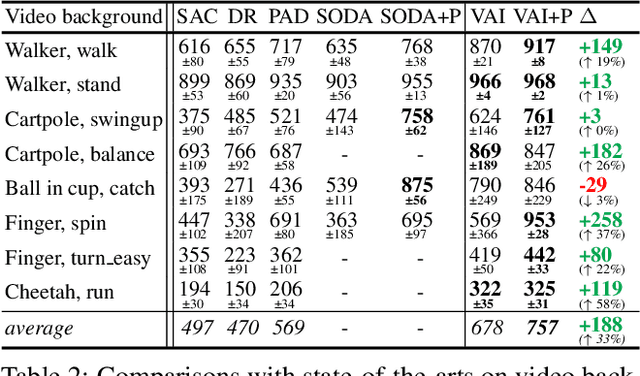
The vision-based reinforcement learning (RL) has achieved tremendous success. However, generalizing vision-based RL policy to unknown test environments still remains as a challenging problem. Unlike previous works that focus on training a universal RL policy that is invariant to discrepancies between test and training environment, we focus on developing an independent module to disperse interference factors irrelevant to the task, thereby providing "clean" observations for the RL policy. The proposed unsupervised visual attention and invariance method (VAI) contains three key components: 1) an unsupervised keypoint detection model which captures semantically meaningful keypoints in observations; 2) an unsupervised visual attention module which automatically generates the distraction-invariant attention mask for each observation; 3) a self-supervised adapter for visual distraction invariance which reconstructs distraction-invariant attention mask from observations with artificial disturbances generated by a series of foreground and background augmentations. All components are optimized in an unsupervised way, without manual annotation or access to environment internals, and only the adapter is used during inference time to provide distraction-free observations to RL policy. VAI empirically shows powerful generalization capabilities and significantly outperforms current state-of-the-art (SOTA) method by 15% to 49% in DeepMind Control suite benchmark and 61% to 229% in our proposed robot manipulation benchmark, in term of cumulative rewards per episode.
Learning Camera Localization via Dense Scene Matching
Mar 31, 2021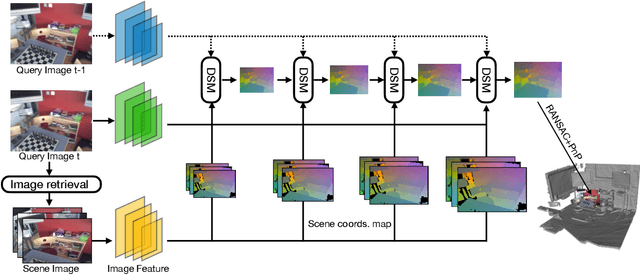
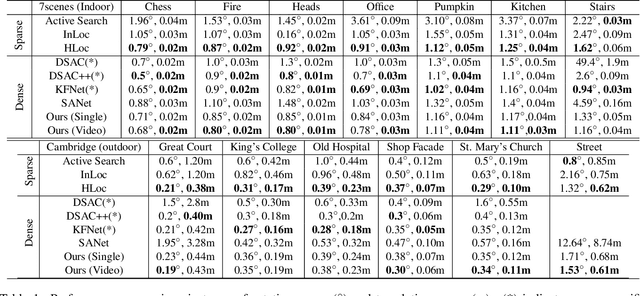
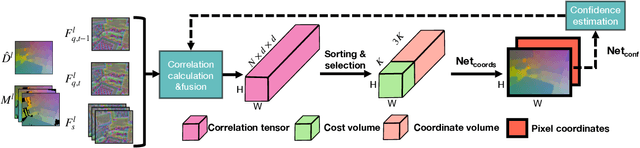
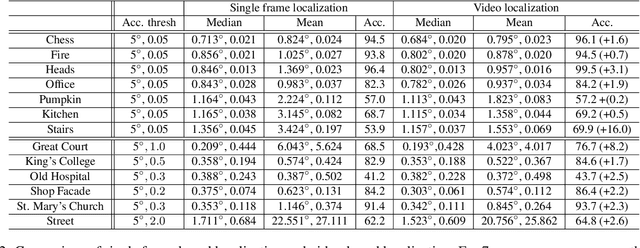
Camera localization aims to estimate 6 DoF camera poses from RGB images. Traditional methods detect and match interest points between a query image and a pre-built 3D model. Recent learning-based approaches encode scene structures into a specific convolutional neural network (CNN) and thus are able to predict dense coordinates from RGB images. However, most of them require re-training or re-adaption for a new scene and have difficulties in handling large-scale scenes due to limited network capacity. We present a new method for scene agnostic camera localization using dense scene matching (DSM), where a cost volume is constructed between a query image and a scene. The cost volume and the corresponding coordinates are processed by a CNN to predict dense coordinates. Camera poses can then be solved by PnP algorithms. In addition, our method can be extended to temporal domain, which leads to extra performance boost during testing time. Our scene-agnostic approach achieves comparable accuracy as the existing scene-specific approaches, such as KFNet, on the 7scenes and Cambridge benchmark. This approach also remarkably outperforms state-of-the-art scene-agnostic dense coordinate regression network SANet. The Code is available at https://github.com/Tangshitao/Dense-Scene-Matching.
Data-Driven Reinforcement Learning for Virtual Character Animation Control
Apr 13, 2021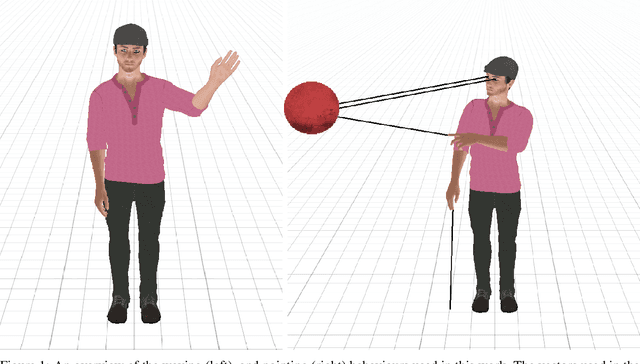
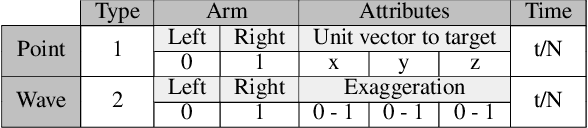
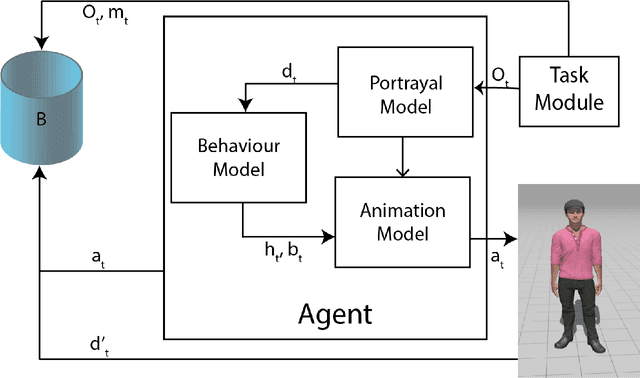
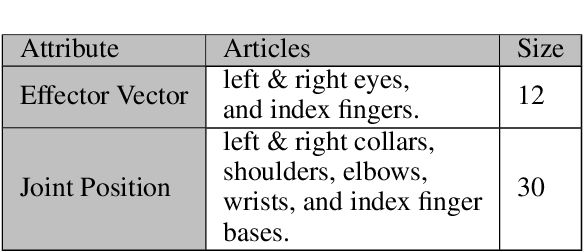
Virtual character animation control is a problem for which Reinforcement Learning (RL) is a viable approach. While current work have applied RL effectively to portray physics-based skills, social behaviours are challenging to design reward functions for, due to their lack of physical interaction with the world. On the other hand, data-driven implementations for these skills have been limited to supervised learning methods which require extensive training data and carry constraints on generalisability. In this paper, we propose RLAnimate, a novel data-driven deep RL approach to address this challenge, where we combine the strengths of RL together with an ability to learn from a motion dataset when creating agents. We formalise a mathematical structure for training agents by refining the conceptual roles of elements such as agents, environments, states and actions, in a way that leverages attributes of the character animation domain and model-based RL. An agent trained using our approach learns versatile animation dynamics to portray multiple behaviours, using an iterative RL training process, which becomes aware of valid behaviours via representations learnt from motion capture clips. We demonstrate, by training agents that portray realistic pointing and waving behaviours, that our approach requires a significantly lower training time, and substantially fewer sample episodes to be generated during training relative to state-of-the-art physics-based RL methods. Also, compared to existing supervised learning-based animation agents, RLAnimate needs a limited dataset of motion clips to generate representations of valid behaviours during training.
Interpreting intermediate convolutional layers of CNNs trained on raw speech
Apr 19, 2021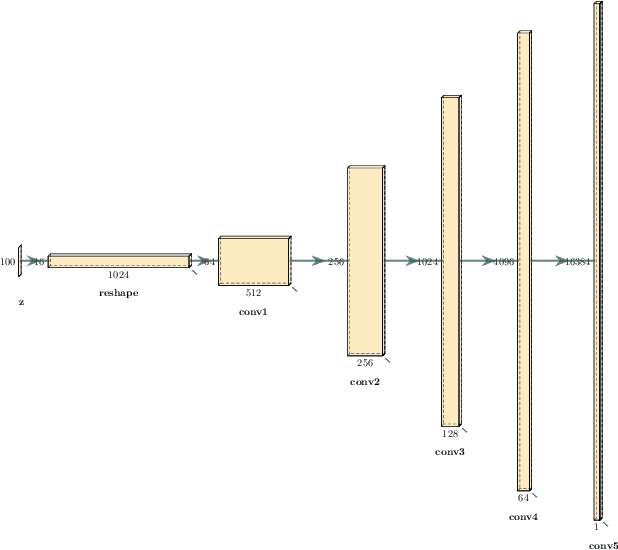
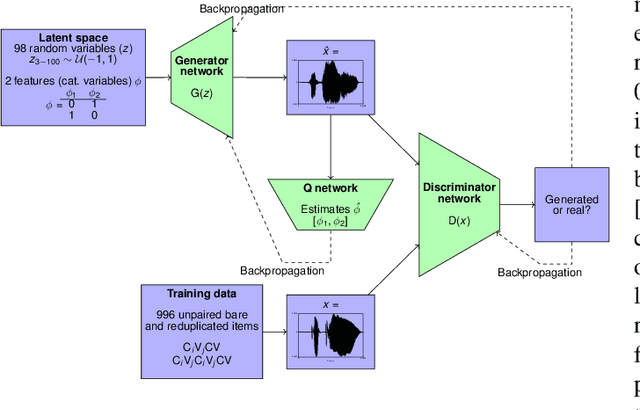
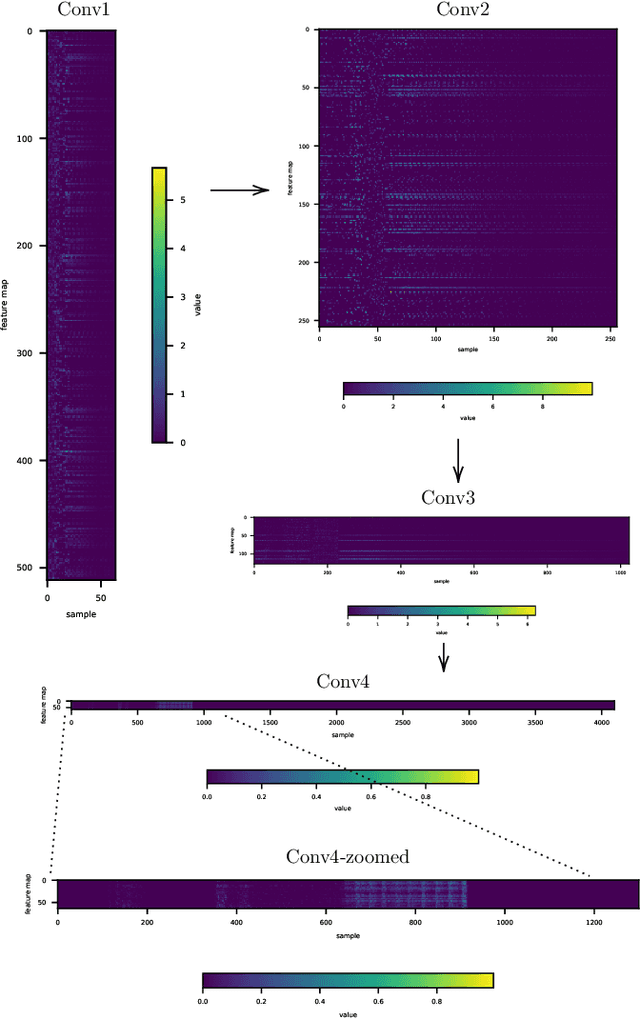
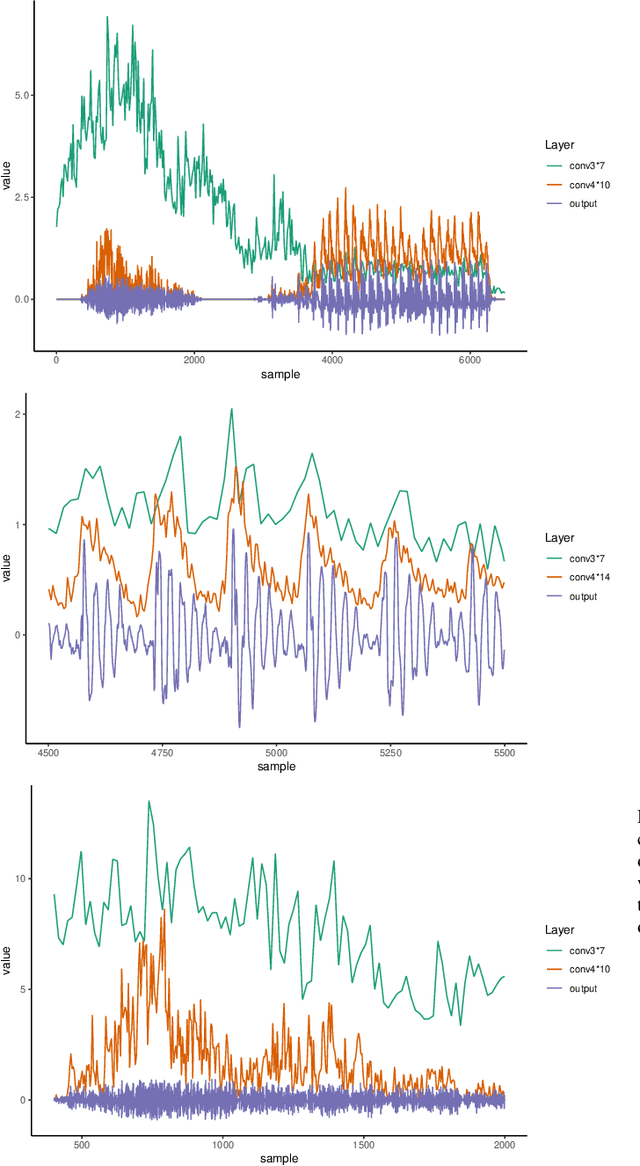
This paper presents a technique to interpret and visualize intermediate layers in CNNs trained on raw speech data in an unsupervised manner. We show that averaging over feature maps after ReLU activation in each convolutional layer yields interpretable time-series data. The proposed technique enables acoustic analysis of intermediate convolutional layers. To uncover how meaningful representation in speech gets encoded in intermediate layers of CNNs, we manipulate individual latent variables to marginal levels outside of the training range. We train and probe internal representations on two models -- a bare GAN architecture and a ciwGAN extension which forces the Generator to output informative data and results in emergence of linguistically meaningful representations. Interpretation and visualization is performed for three basic acoustic properties of speech: periodic vibration (corresponding to vowels), aperiodic noise vibration (corresponding to fricatives), and silence (corresponding to stops). We also argue that the proposed technique allows acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information. The models are trained on two speech processes with different degrees of complexity: a simple presence of [s] and a computationally complex presence of reduplication (copied material). Observing the causal effect between interpolation and the resulting changes in intermediate layers can reveal how individual variables get transformed into spikes in activation in intermediate layers. Using the proposed technique, we can analyze how linguistically meaningful units in speech get encoded in different convolutional layers.
Real-time 3D Reconstruction on Construction Site using Visual SLAM and UAV
Dec 19, 2017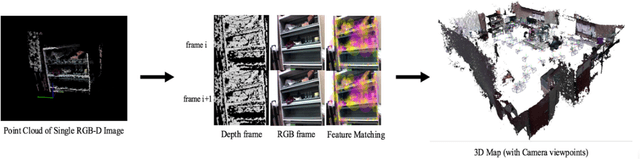
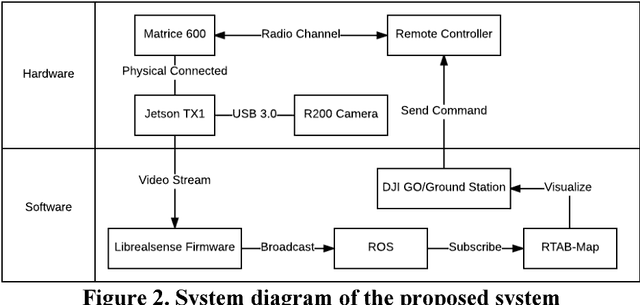


3D reconstruction can be used as a platform to monitor the performance of activities on construction site, such as construction progress monitoring, structure inspection and post-disaster rescue. Comparing to other sensors, RGB image has the advantages of low-cost, texture rich and easy to implement that has been used as the primary method for 3D reconstruction in construction industry. However, the image-based 3D reconstruction always requires extended time to acquire and/or to process the image data, which limits its application on time critical projects. Recent progress in Visual Simultaneous Localization and Mapping (SLAM) make it possible to reconstruct a 3D map of construction site in real-time. Integrated with Unmanned Aerial Vehicle (UAV), the obstacles areas that are inaccessible for the ground equipment can also be sensed. Despite these advantages of visual SLAM and UAV, until now, such technique has not been fully investigated on construction site. Therefore, the objective of this research is to present a pilot study of using visual SLAM and UAV for real-time construction site reconstruction. The system architecture and the experimental setup are introduced, and the preliminary results and the potential applications using Visual SLAM and UAV on construction site are discussed.
Multimodal Punctuation Prediction with Contextual Dropout
Feb 12, 2021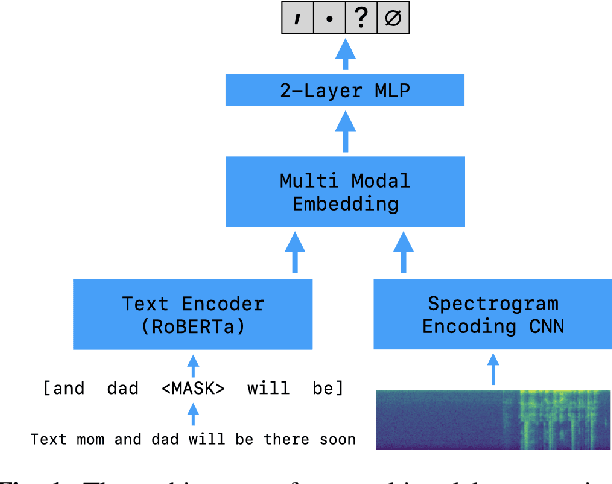

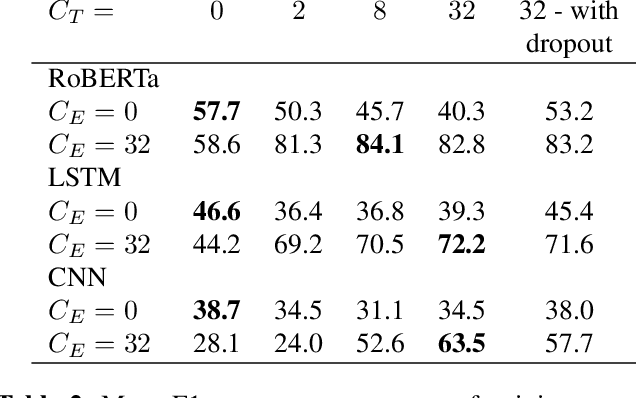
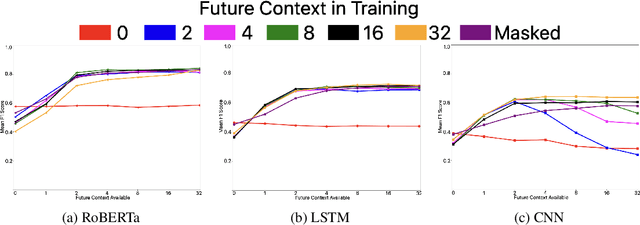
Automatic speech recognition (ASR) is widely used in consumer electronics. ASR greatly improves the utility and accessibility of technology, but usually the output is only word sequences without punctuation. This can result in ambiguity in inferring user-intent. We first present a transformer-based approach for punctuation prediction that achieves 8% improvement on the IWSLT 2012 TED Task, beating the previous state of the art [1]. We next describe our multimodal model that learns from both text and audio, which achieves 8% improvement over the text-only algorithm on an internal dataset for which we have both the audio and transcriptions. Finally, we present an approach to learning a model using contextual dropout that allows us to handle variable amounts of future context at test time.
Deep learning with self-supervision and uncertainty regularization to count fish in underwater images
Apr 30, 2021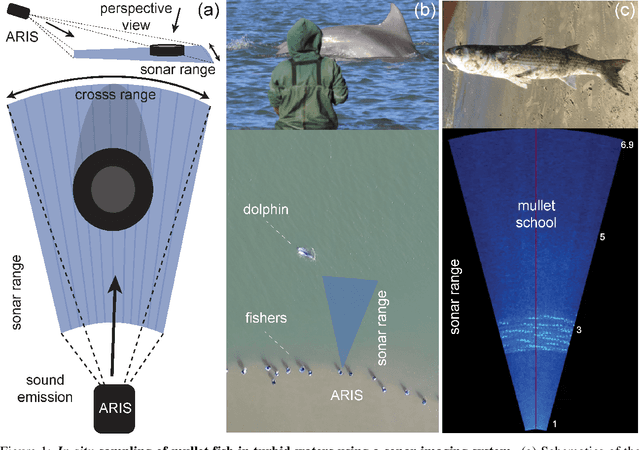
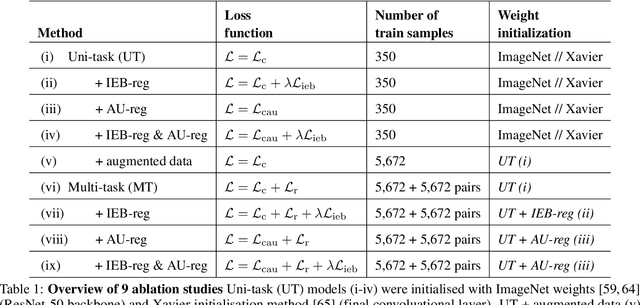
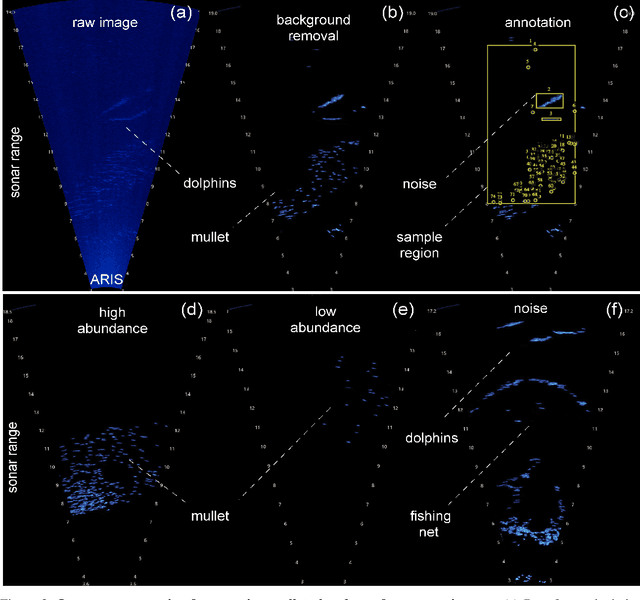
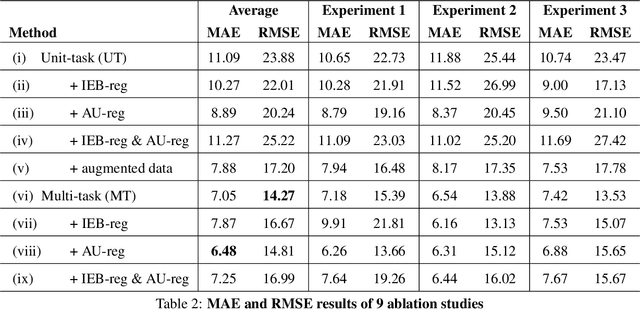
Effective conservation actions require effective population monitoring. However, accurately counting animals in the wild to inform conservation decision-making is difficult. Monitoring populations through image sampling has made data collection cheaper, wide-reaching and less intrusive but created a need to process and analyse this data efficiently. Counting animals from such data is challenging, particularly when densely packed in noisy images. Attempting this manually is slow and expensive, while traditional computer vision methods are limited in their generalisability. Deep learning is the state-of-the-art method for many computer vision tasks, but it has yet to be properly explored to count animals. To this end, we employ deep learning, with a density-based regression approach, to count fish in low-resolution sonar images. We introduce a large dataset of sonar videos, deployed to record wild mullet schools (Mugil liza), with a subset of 500 labelled images. We utilise abundant unlabelled data in a self-supervised task to improve the supervised counting task. For the first time in this context, by introducing uncertainty quantification, we improve model training and provide an accompanying measure of prediction uncertainty for more informed biological decision-making. Finally, we demonstrate the generalisability of our proposed counting framework through testing it on a recent benchmark dataset of high-resolution annotated underwater images from varying habitats (DeepFish). From experiments on both contrasting datasets, we demonstrate our network outperforms the few other deep learning models implemented for solving this task. By providing an open-source framework along with training data, our study puts forth an efficient deep learning template for crowd counting aquatic animals thereby contributing effective methods to assess natural populations from the ever-increasing visual data.
Multi-Discriminator Sobolev Defense-GAN Against Adversarial Attacks for End-to-End Speech Systems
Mar 15, 2021

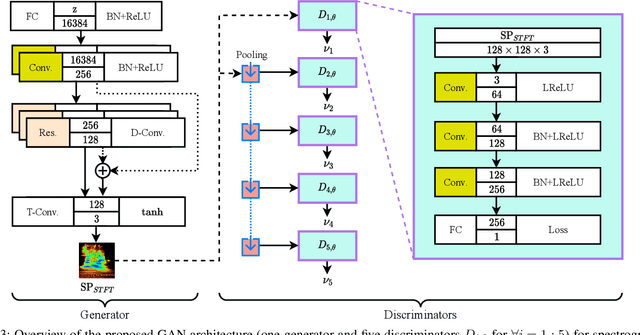
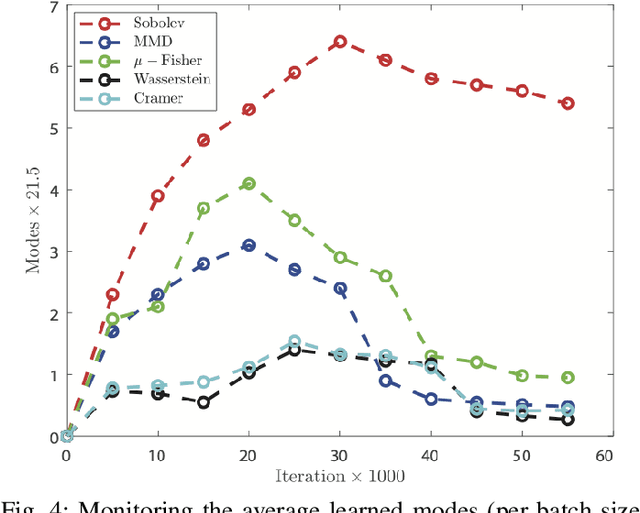
This paper introduces a defense approach against end-to-end adversarial attacks developed for cutting-edge speech-to-text systems. The proposed defense algorithm has four major steps. First, we represent speech signals with 2D spectrograms using the short-time Fourier transform. Second, we iteratively find a safe vector using a spectrogram subspace projection operation. This operation minimizes the chordal distance adjustment between spectrograms with an additional regularization term. Third, we synthesize a spectrogram with such a safe vector using a novel GAN architecture trained with Sobolev integral probability metric. To improve the model's performance in terms of stability and the total number of learned modes, we impose an additional constraint on the generator network. Finally, we reconstruct the signal from the synthesized spectrogram and the Griffin-Lim phase approximation technique. We evaluate the proposed defense approach against six strong white and black-box adversarial attacks benchmarked on DeepSpeech, Kaldi, and Lingvo models. Our experimental results show that our algorithm outperforms other state-of-the-art defense algorithms both in terms of accuracy and signal quality.
The Impact of Activation Sparsity on Overfitting in Convolutional Neural Networks
Apr 13, 2021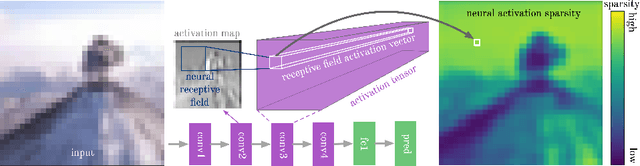
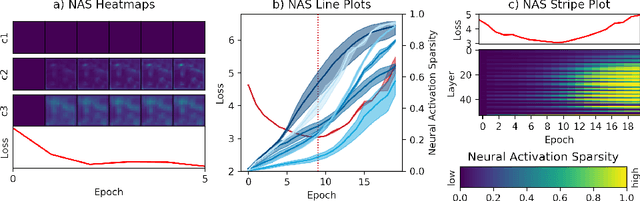
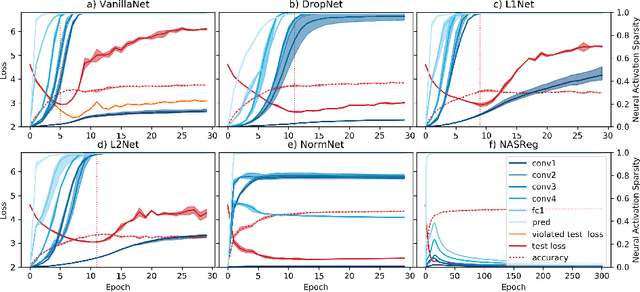
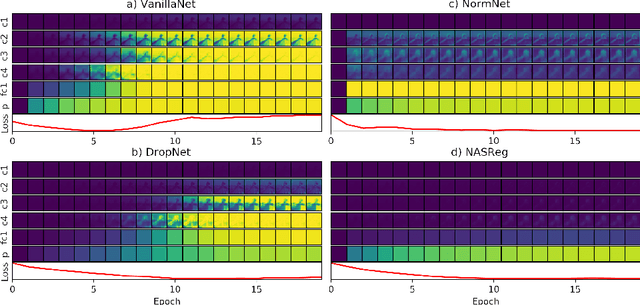
Overfitting is one of the fundamental challenges when training convolutional neural networks and is usually identified by a diverging training and test loss. The underlying dynamics of how the flow of activations induce overfitting is however poorly understood. In this study we introduce a perplexity-based sparsity definition to derive and visualise layer-wise activation measures. These novel explainable AI strategies reveal a surprising relationship between activation sparsity and overfitting, namely an increase in sparsity in the feature extraction layers shortly before the test loss starts rising. This tendency is preserved across network architectures and reguralisation strategies so that our measures can be used as a reliable indicator for overfitting while decoupling the network's generalisation capabilities from its loss-based definition. Moreover, our differentiable sparsity formulation can be used to explicitly penalise the emergence of sparsity during training so that the impact of reduced sparsity on overfitting can be studied in real-time. Applying this penalty and analysing activation sparsity for well known regularisers and in common network architectures supports the hypothesis that reduced activation sparsity can effectively improve the generalisation and classification performance. In line with other recent work on this topic, our methods reveal novel insights into the contradicting concepts of activation sparsity and network capacity by demonstrating that dense activations can enable discriminative feature learning while efficiently exploiting the capacity of deep models without suffering from overfitting, even when trained excessively.
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
Feb 18, 2021
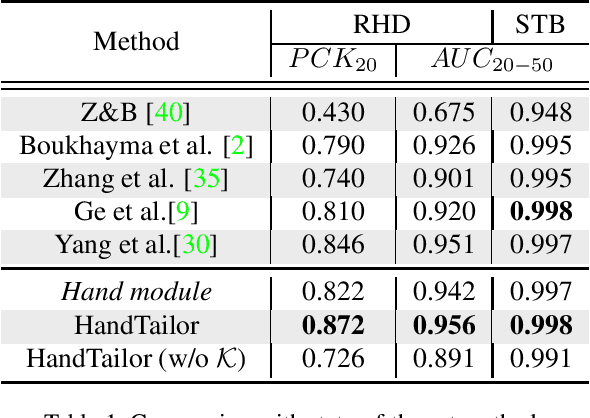
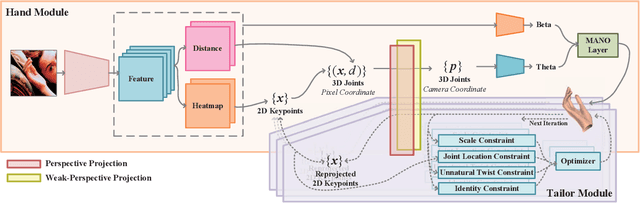
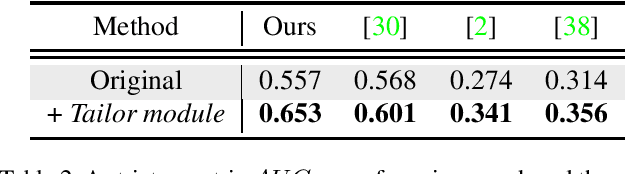
3D hand pose estimation and shape recovery are challenging tasks in computer vision. We introduce a novel framework HandTailor, which combines a learning-based hand module and an optimization-based tailor module to achieve high-precision hand mesh recovery from a monocular RGB image. The proposed hand module unifies perspective projection and weak perspective projection in a single network towards accuracy-oriented and in-the-wild scenarios. The proposed tailor module then utilizes the coarsely reconstructed mesh model provided by the hand module as initialization, and iteratively optimizes an energy function to obtain better results. The tailor module is time-efficient, costs only 8ms per frame on a modern CPU. We demonstrate that HandTailor can get state-of-the-art performance on several public benchmarks, with impressive qualitative results on in-the-wild experiments.