 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
May 08, 2018

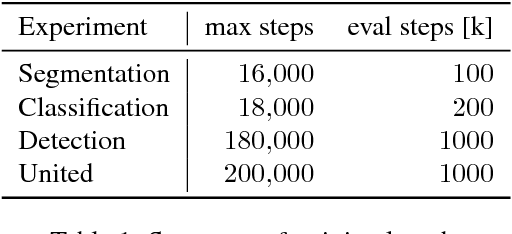
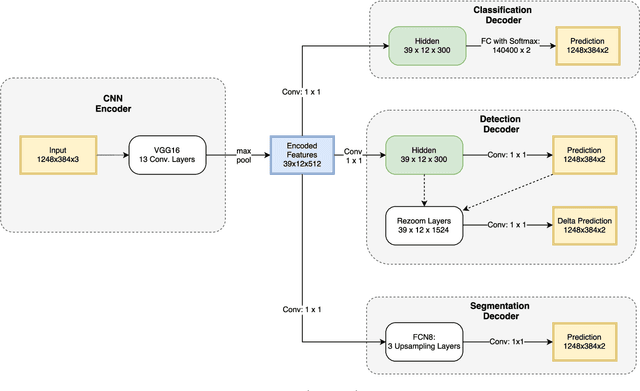
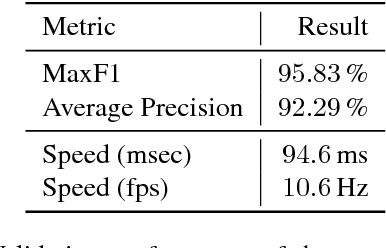
While most approaches to semantic reasoning have focused on improving performance, in this paper we argue that computational times are very important in order to enable real time applications such as autonomous driving. Towards this goal, we present an approach to joint classification, detection and semantic segmentation via a unified architecture where the encoder is shared amongst the three tasks. Our approach is very simple, can be trained end-to-end and performs extremely well in the challenging KITTI dataset, outperforming the state-of-the-art in the road segmentation task. Our approach is also very efficient, taking less than 100 ms to perform all tasks.
Online Adaptation for Consistent Mesh Reconstruction in the Wild
Dec 06, 2020

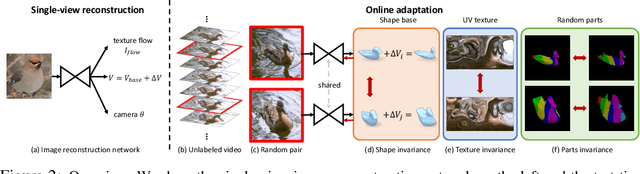
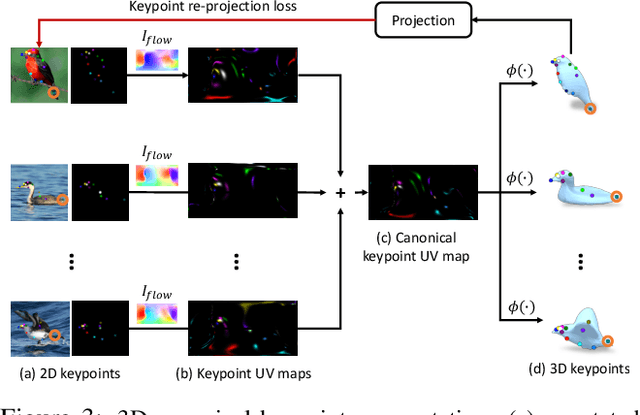
This paper presents an algorithm to reconstruct temporally consistent 3D meshes of deformable object instances from videos in the wild. Without requiring annotations of 3D mesh, 2D keypoints, or camera pose for each video frame, we pose video-based reconstruction as a self-supervised online adaptation problem applied to any incoming test video. We first learn a category-specific 3D reconstruction model from a collection of single-view images of the same category that jointly predicts the shape, texture, and camera pose of an image. Then, at inference time, we adapt the model to a test video over time using self-supervised regularization terms that exploit temporal consistency of an object instance to enforce that all reconstructed meshes share a common texture map, a base shape, as well as parts. We demonstrate that our algorithm recovers temporally consistent and reliable 3D structures from videos of non-rigid objects including those of animals captured in the wild -- an extremely challenging task rarely addressed before.
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
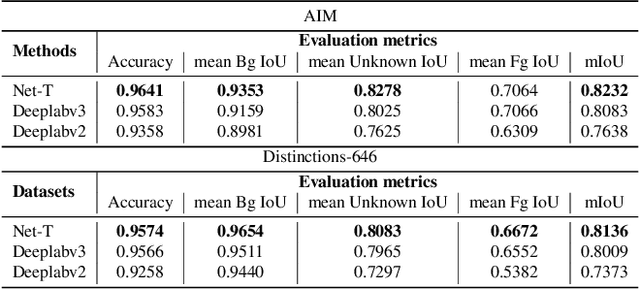
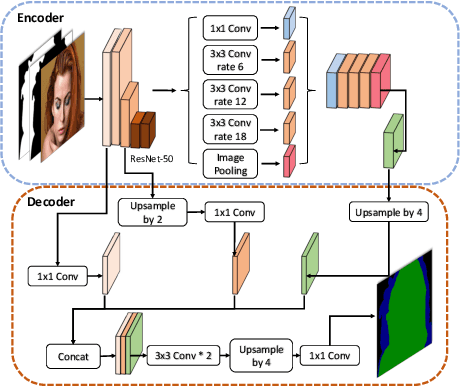

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
Self-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Mar 01, 2021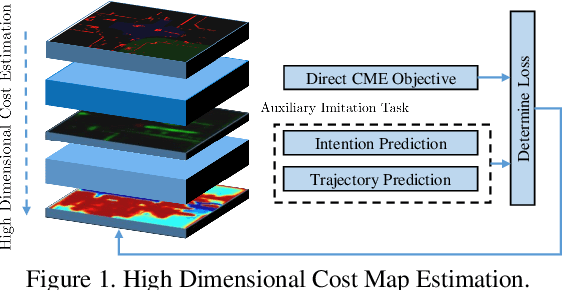
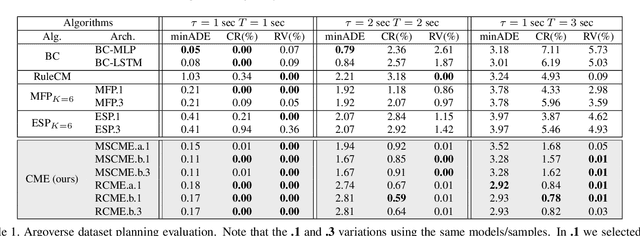
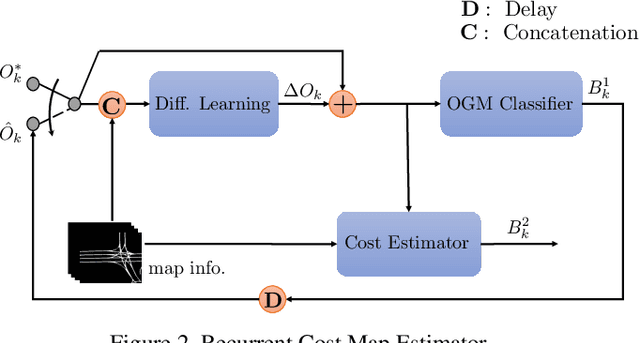
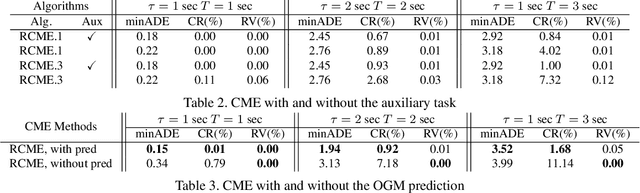
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.
Optimization of the Waiting Time for H-R Coordination
Sep 22, 2017
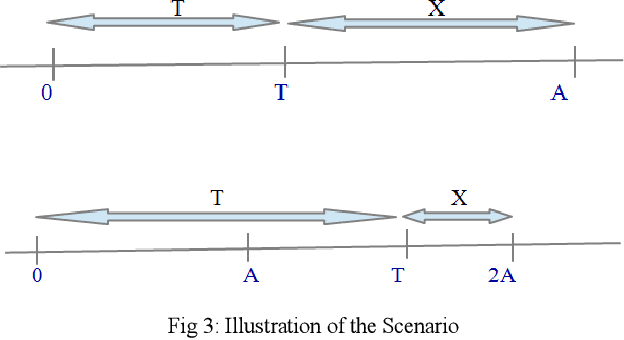
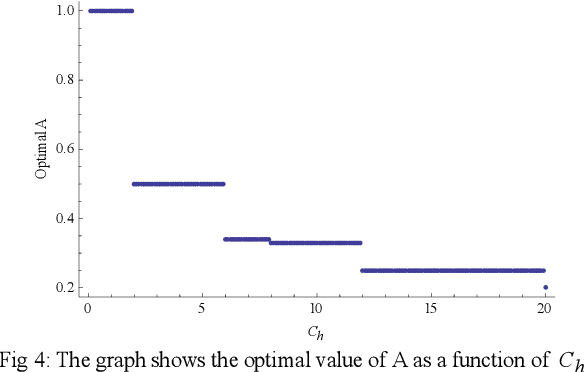
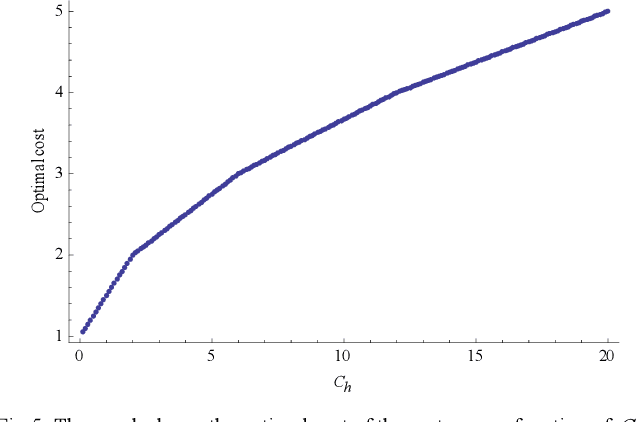
An analytical model of Human-Robot (H-R) coordination is presented for a Human-Robot system executing a collaborative task in which a high level of synchronization among the agents is desired. The influencing parameters and decision variables that affect the waiting time of the collaborating agents were analyzed. The performance of the model was evaluated based on the costs of the waiting times of each of the agents at the pre-defined spatial point of handover. The model was tested for two cases of dynamic H-R coordination scenarios. Results indicate that this analytical model can be used as a tool for designing an H-R system that optimizes the agent waiting time thereby increasing the joint-efficiency of the system and making coordination fluent and natural.
Variable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling
Mar 23, 2021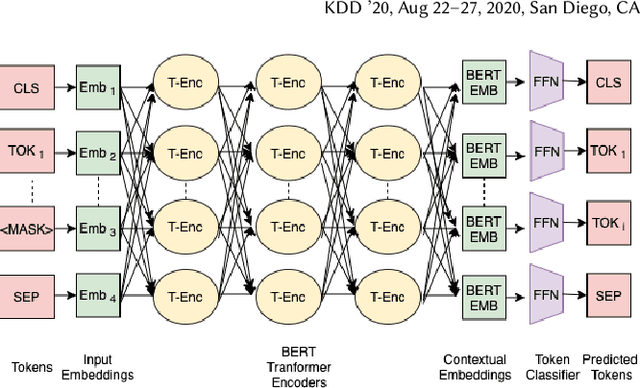
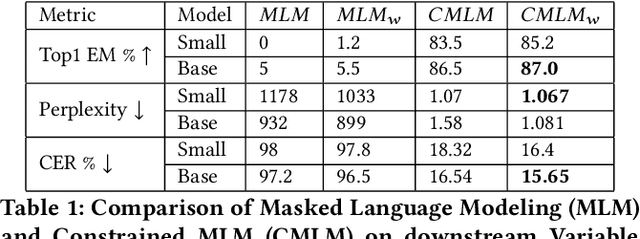
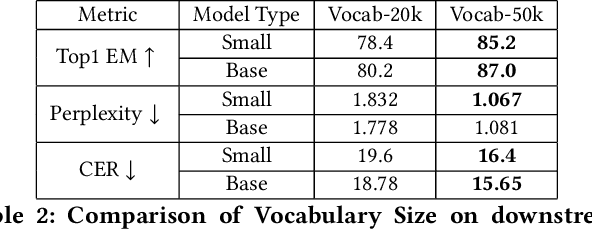
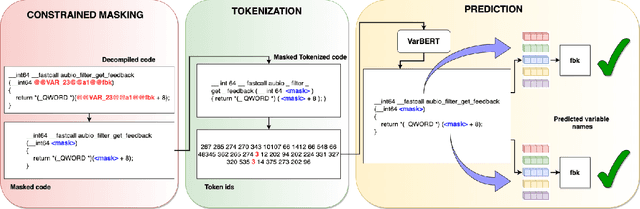
Decompilation is the procedure of transforming binary programs into a high-level representation, such as source code, for human analysts to examine. While modern decompilers can reconstruct and recover much information that is discarded during compilation, inferring variable names is still extremely difficult. Inspired by recent advances in natural language processing, we propose a novel solution to infer variable names in decompiled code based on Masked Language Modeling, Byte-Pair Encoding, and neural architectures such as Transformers and BERT. Our solution takes \textit{raw} decompiler output, the less semantically meaningful code, as input, and enriches it using our proposed \textit{finetuning} technique, Constrained Masked Language Modeling. Using Constrained Masked Language Modeling introduces the challenge of predicting the number of masked tokens for the original variable name. We address this \textit{count of token prediction} challenge with our post-processing algorithm. Compared to the state-of-the-art approaches, our trained VarBERT model is simpler and of much better performance. We evaluated our model on an existing large-scale data set with 164,632 binaries and showed that it can predict variable names identical to the ones present in the original source code up to 84.15\% of the time.
Trust Your IMU: Consequences of Ignoring the IMU Drift
Mar 15, 2021
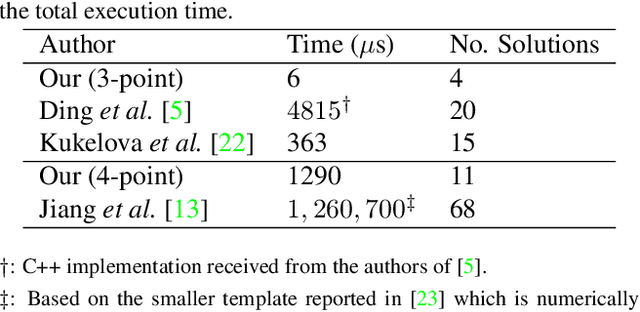
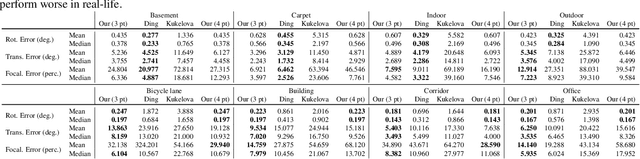
In this paper, we argue that modern pre-integration methods for inertial measurement units (IMUs) are accurate enough to ignore the drift for short time intervals. This allows us to consider a simplified camera model, which in turn admits further intrinsic calibration. We develop the first-ever solver to jointly solve the relative pose problem with unknown and equal focal length and radial distortion profile while utilizing the IMU data. Furthermore, we show significant speed-up compared to state-of-the-art algorithms, with small or negligible loss in accuracy for partially calibrated setups. The proposed algorithms are tested on both synthetic and real data, where the latter is focused on navigation using unmanned aerial vehicles (UAVs). We evaluate the proposed solvers on different commercially available low-cost UAVs, and demonstrate that the novel assumption on IMU drift is feasible in real-life applications. The extended intrinsic auto-calibration enables us to use distorted input images, making tedious calibration processes obsolete, compared to current state-of-the-art methods.
Seeing through a Black Box: Toward High-Quality Terahertz TomographicImaging via Multi-Scale Spatio-Spectral Image Fusion
Mar 31, 2021
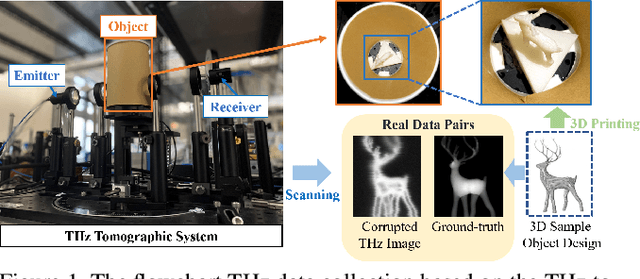
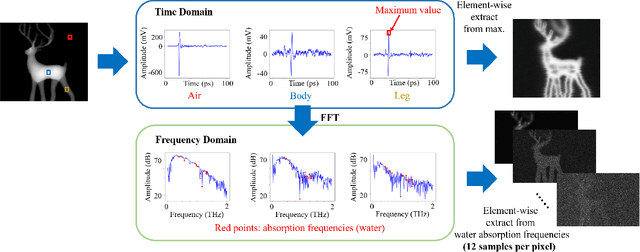
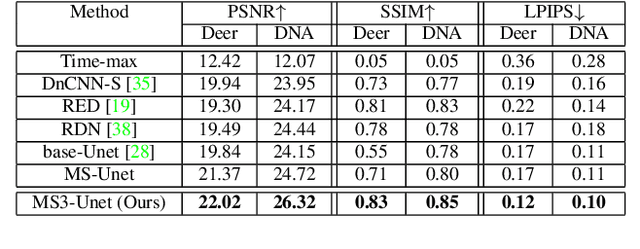
Terahertz tomographic imaging has recently arisen significant attention due to its non-invasive, non-destructive, non-ionizing, material-classification, and ultrafast-frame-rate nature for object exploration and inspection. However, its strong water absorption nature and low noise tolerance lead to undesired blurring and distortion of reconstructed terahertz images. Research groups aim to deal with this issue through the use of synthetic data in the training phase, but still, their performances are highly constrained by the diffraction-limited terahertz signals. In this paper, we propose a novel multi-scale spatio-spectral fusion Unet (MS3-Unet) that extracts multi-scale features from the different spectral of terahertz image data for restoration. MS3-Unet utilizes multi-scale branches to extract spatio-spectral features which are then processed by element-wise adaptive filters, and then fused to achieve high-quality terahertz image restoration. Here, we experimentally construct ultra-high-speed terahertz time-domain spectroscopy system covering a broad frequency range from 0.1 THz to 4 THz for building up temporal/spectral/spatial/phase/material terahertz database of hidden 3-D objects. Complementary to a quantitative evaluation, we demonstrate the effectiveness of the proposed MS3-Unet image restoration approach on 3-D terahertz tomographic reconstruction applications.
Learning Compositional Representation for 4D Captures with Neural ODE
Mar 15, 2021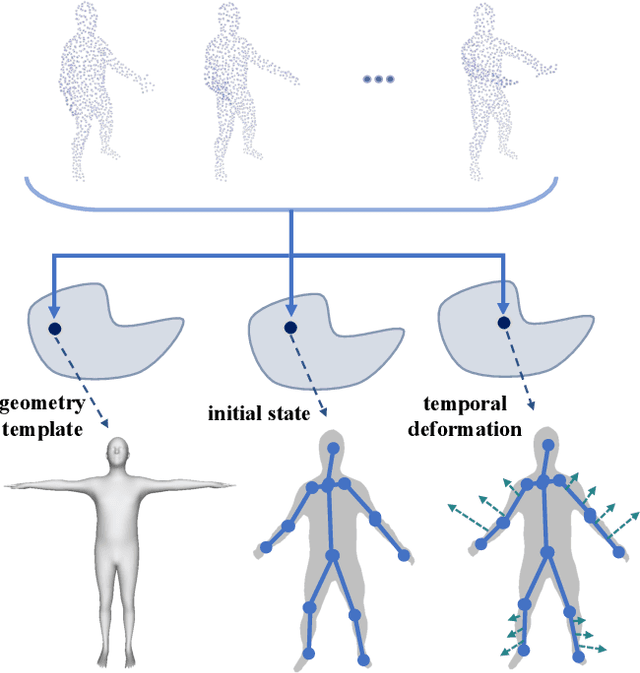
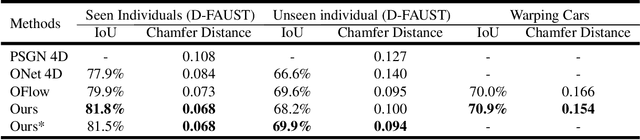
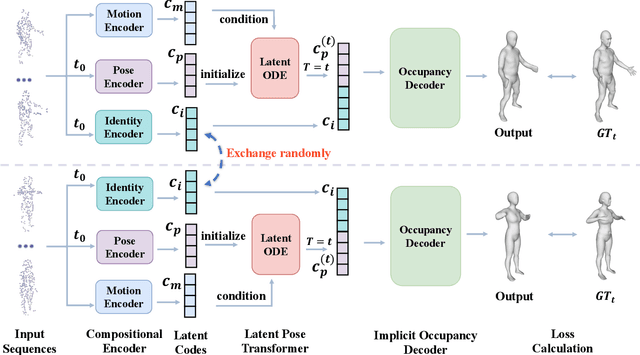

Learning based representation has become the key to the success of many computer vision systems. While many 3D representations have been proposed, it is still an unaddressed problem for how to represent a dynamically changing 3D object. In this paper, we introduce a compositional representation for 4D captures, i.e. a deforming 3D object over a temporal span, that disentangles shape, initial state, and motion respectively. Each component is represented by a latent code via a trained encoder. To model the motion, a neural Ordinary Differential Equation (ODE) is trained to update the initial state conditioned on the learned motion code, and a decoder takes the shape code and the updated pose code to reconstruct 4D captures at each time stamp. To this end, we propose an Identity Exchange Training (IET) strategy to encourage the network to learn effectively decoupling each component. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art deep learning based methods on 4D reconstruction, and significantly improves on various tasks, including motion transfer and completion.
Convolutional Normalization
Feb 19, 2021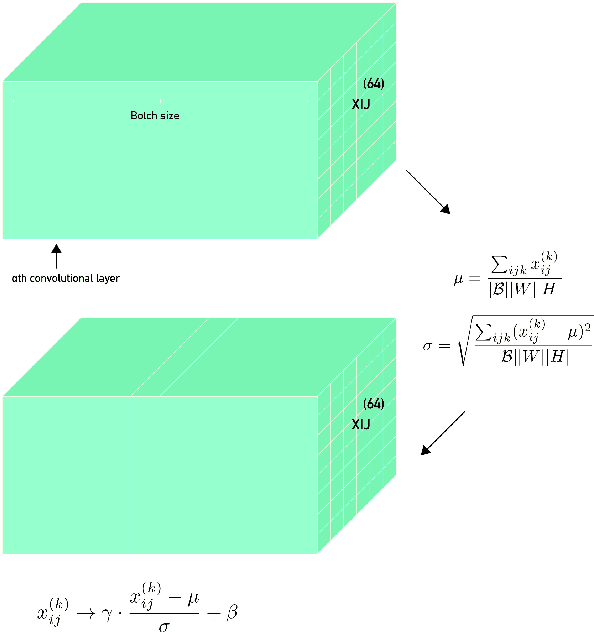
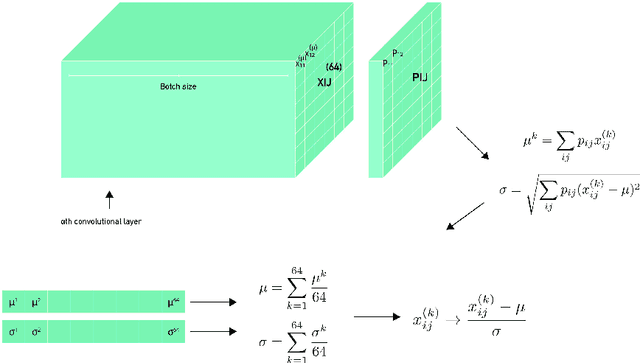
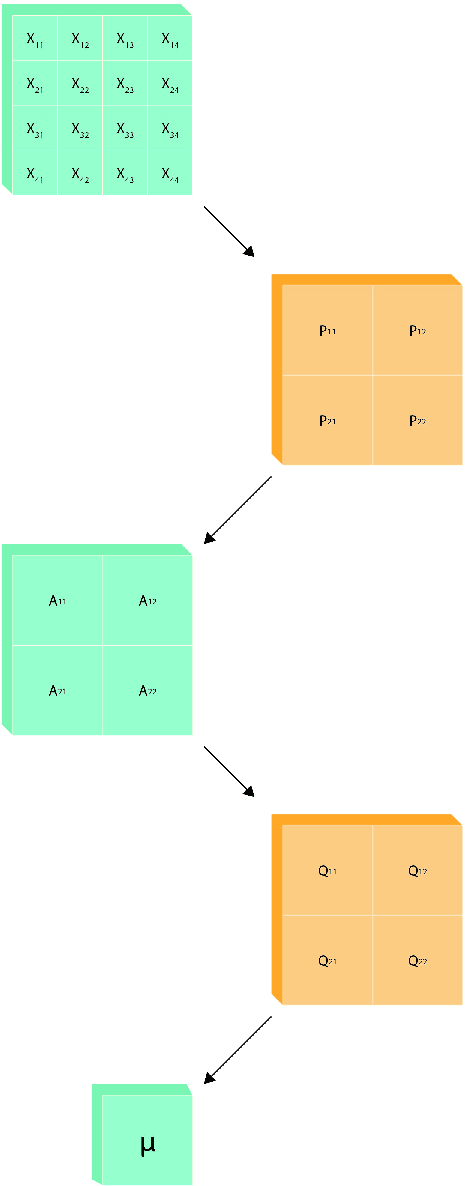
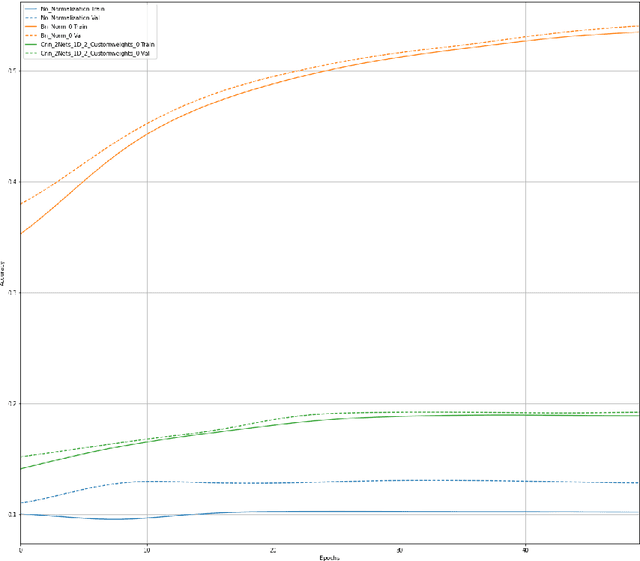
As the deep neural networks are being applied to complex tasks, the size of the networks and architecture increases and their topology becomes more complicated too. At the same time, training becomes slow and at some instances inefficient. This motivated the introduction of various normalization techniques such as Batch Normalization and Layer Normalization. The aforementioned normalization methods use arithmetic operations to compute an approximation statistics (mainly the first and second moments) of the layer's data and use it to normalize it. The aforementioned methods use plain Monte Carlo method to approximate the statistics and such method fails when approximating the statistics whose distribution is complex. Here, we propose an approach that uses weighted sum, implemented using depth-wise convolutional neural networks, to not only approximate the statistics, but to learn the coefficients of the sum.