 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
COVID-19 and Big Data: Multi-faceted Analysis for Spatio-temporal Understanding of the Pandemic with Social Media Conversations
Apr 22, 2021
COVID-19 has been devastating the world since the end of 2019 and has continued to play a significant role in major national and worldwide events, and consequently, the news. In its wake, it has left no life unaffected. Having earned the world's attention, social media platforms have served as a vehicle for the global conversation about COVID-19. In particular, many people have used these sites in order to express their feelings, experiences, and observations about the pandemic. We provide a multi-faceted analysis of critical properties exhibited by these conversations on social media regarding the novel coronavirus pandemic. We present a framework for analysis, mining, and tracking the critical content and characteristics of social media conversations around the pandemic. Focusing on Twitter and Reddit, we have gathered a large-scale dataset on COVID-19 social media conversations. Our analyses cover tracking potential reports on virus acquisition, symptoms, conversation topics, and language complexity measures through time and by region across the United States. We also present a BERT-based model for recognizing instances of hateful tweets in COVID-19 conversations, which achieves a lower error-rate than the state-of-the-art performance. Our results provide empirical validation for the effectiveness of our proposed framework and further demonstrate that social media data can be efficiently leveraged to provide public health experts with inexpensive but thorough insight over the course of an outbreak.
SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
Apr 08, 2021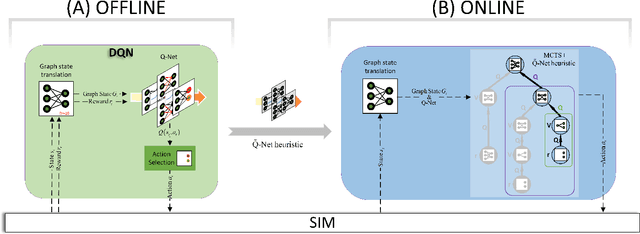
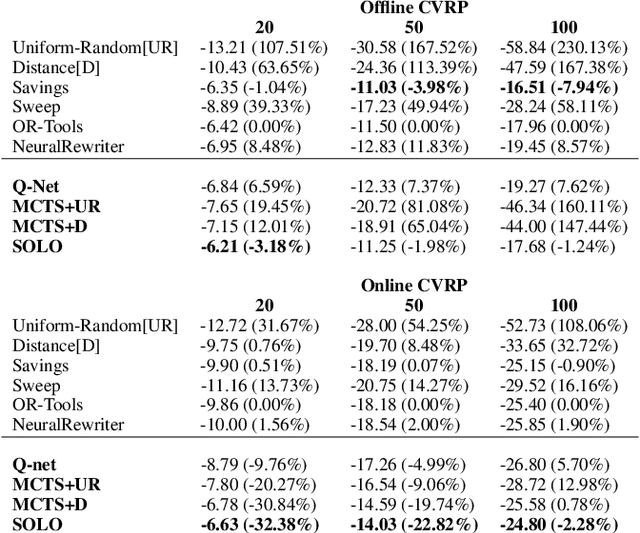

We study combinatorial problems with real world applications such as machine scheduling, routing, and assignment. We propose a method that combines Reinforcement Learning (RL) and planning. This method can equally be applied to both the offline, as well as online, variants of the combinatorial problem, in which the problem components (e.g., jobs in scheduling problems) are not known in advance, but rather arrive during the decision-making process. Our solution is quite generic, scalable, and leverages distributional knowledge of the problem parameters. We frame the solution process as an MDP, and take a Deep Q-Learning approach wherein states are represented as graphs, thereby allowing our trained policies to deal with arbitrary changes in a principled manner. Though learned policies work well in expectation, small deviations can have substantial negative effects in combinatorial settings. We mitigate these drawbacks by employing our graph-convolutional policies as non-optimal heuristics in a compatible search algorithm, Monte Carlo Tree Search, to significantly improve overall performance. We demonstrate our method on two problems: Machine Scheduling and Capacitated Vehicle Routing. We show that our method outperforms custom-tailored mathematical solvers, state of the art learning-based algorithms, and common heuristics, both in computation time and performance.
Fundamental Limits on the Maximum Deviations in Control Systems: How Short Can Distribution Tails be Made by Feedback?
Feb 02, 2021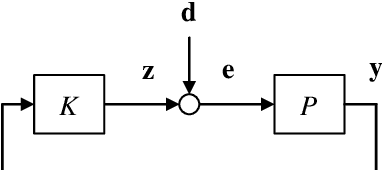
This paper is on the application of information theory to the analysis of fundamental lower bounds on the maximum deviations in feedback control systems, where the plant is linear time-invariant while the controller can generically be any causal functions as long as it stabilizes the plant. It is seen in general that the lower bounds are characterized by the unstable poles (or nonminimum-phase zeros) of the plant as well as the conditional entropy of the disturbance. Such bounds provide fundamental limits on how short the distribution tails in control systems can be made by feedback.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 21, 2021
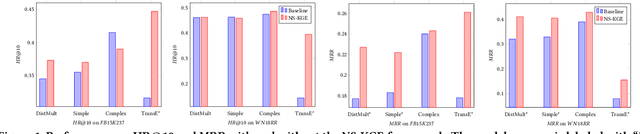
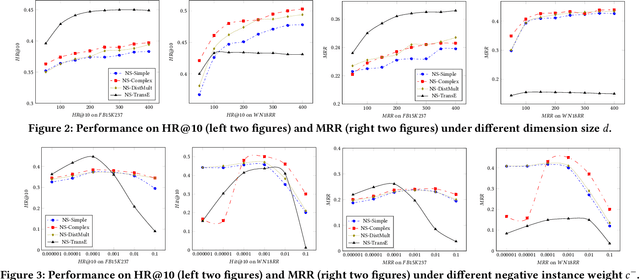
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
Characterizing Trust and Resilience in Distributed Consensus for Cyberphysical Systems
Mar 09, 2021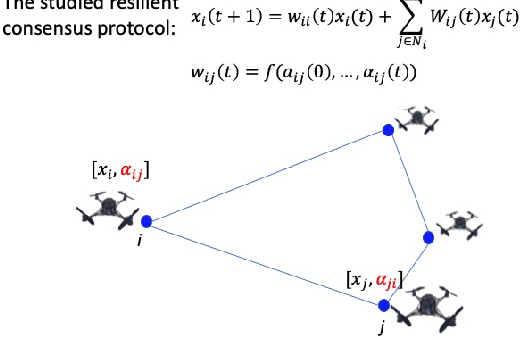
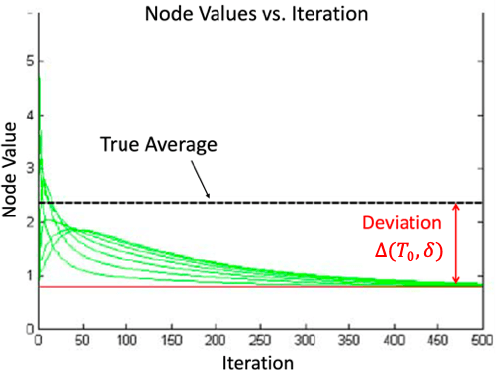
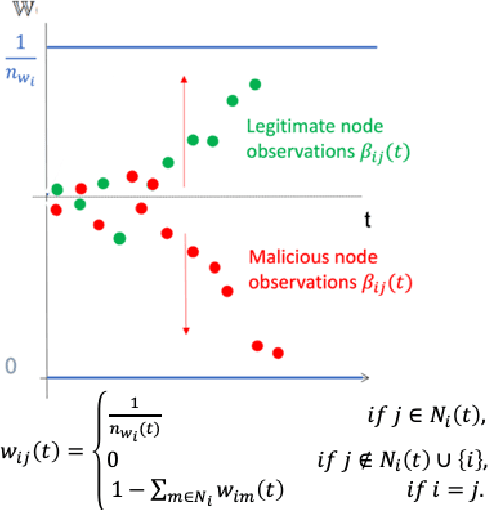
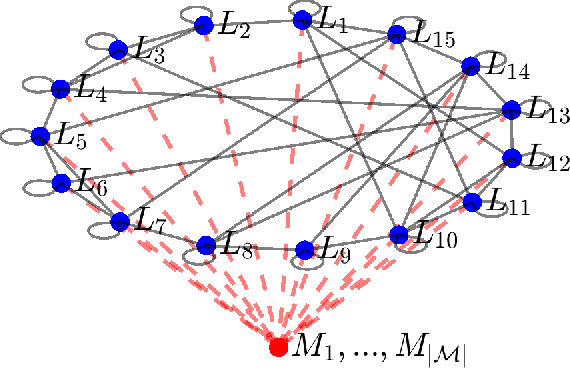
This work considers the problem of resilient consensus where stochastic values of trust between agents are available. Specifically, we derive a unified mathematical framework to characterize convergence, deviation of the consensus from the true consensus value, and expected convergence rate, when there exists additional information of trust between agents. We show that under certain conditions on the stochastic trust values and consensus protocol: 1) almost sure convergence to a common limit value is possible even when malicious agents constitute more than half of the network connectivity, 2) the deviation of the converged limit, from the case where there is no attack, i.e., the true consensus value, can be bounded with probability that approaches 1 exponentially, and 3) correct classification of malicious and legitimate agents can be attained in finite time almost surely. Further, the expected convergence rate decays exponentially with the quality of the trust observations between agents.
Robust Neural Networks Outperform Attitude Estimation Filters
Apr 15, 2021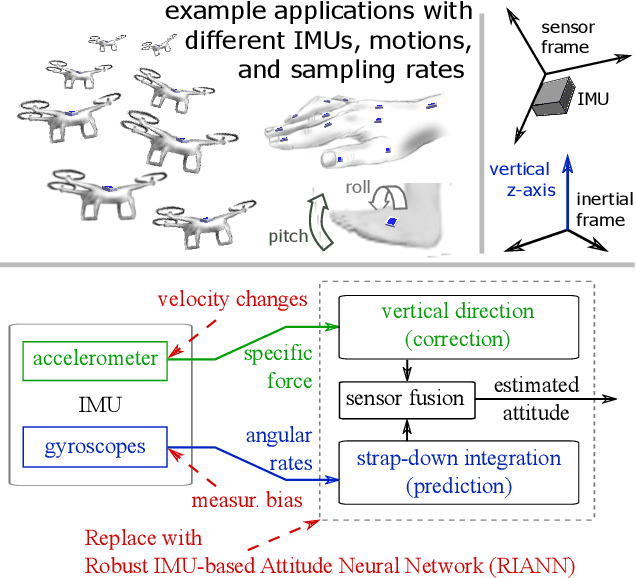
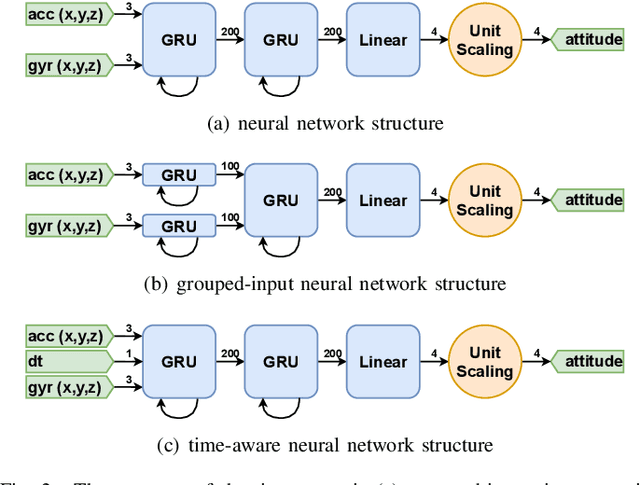
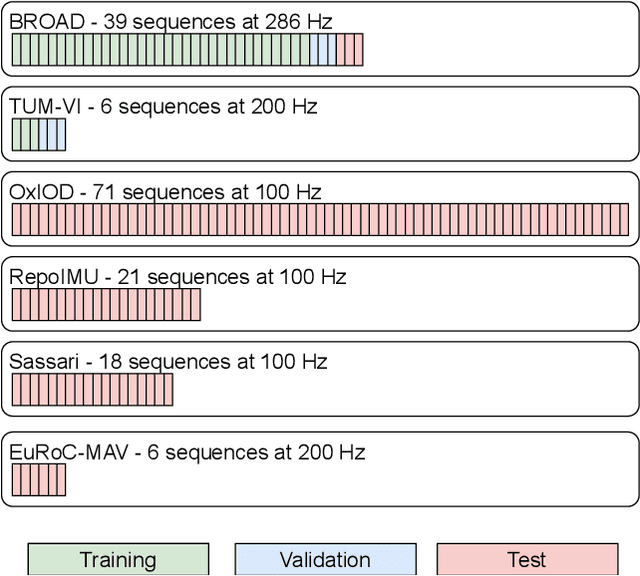
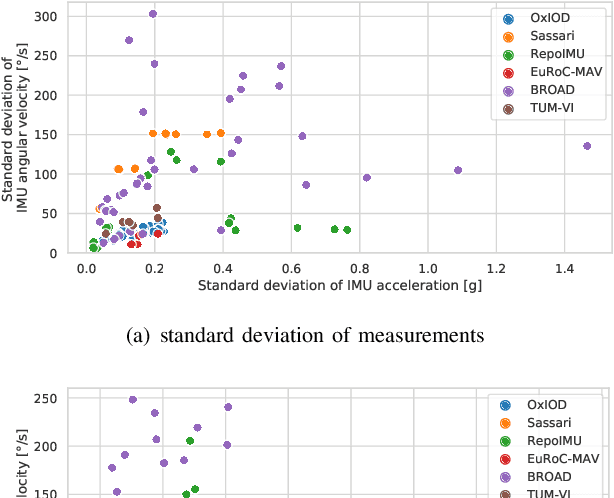
Inertial-sensor-based attitude estimation is a crucial technology in various applications, from human motion tracking to autonomous aerial and ground vehicles. Application scenarios differ in characteristics of the performed motion, presence of disturbances, and environmental conditions. Since state-of-the-art attitude estimators do not generalize well over these characteristics, their parameters must be tuned for the individual motion characteristics and circumstances. We propose RIANN, a real-time-capable neural network for robust IMU-based attitude estimation, which generalizes well across different motion dynamics, environments, and sampling rates, without the need for application-specific adaptations. We exploit two publicly available datasets for the method development and the training, and we add four completely different datasets for evaluation of the trained neural network in three different test scenarios with varying practical relevance. Results show that RIANN performs at least as well as state-of-the-art attitude estimation filters and outperforms them in several cases, even if the filter is tuned on the very same test dataset itself while RIANN has never seen data from that dataset, from the specific application, the same sensor hardware, or the same sampling frequency before. RIANN is expected to enable plug-and-play solutions in numerous applications, especially when accuracy is crucial but no ground-truth data is available for tuning or when motion and disturbance characteristics are uncertain. We made RIANN publicly available.
Highway State Gating for Recurrent Highway Networks: improving information flow through time
May 23, 2018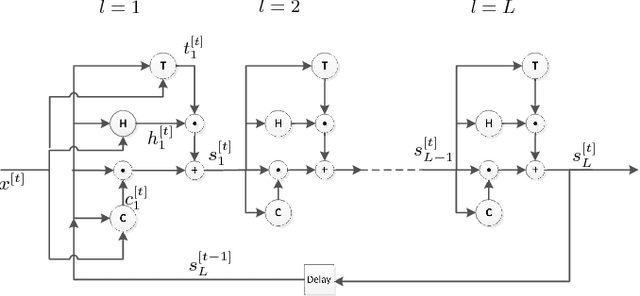
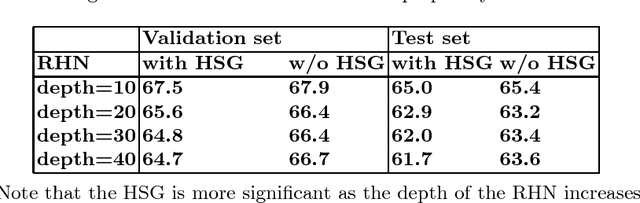
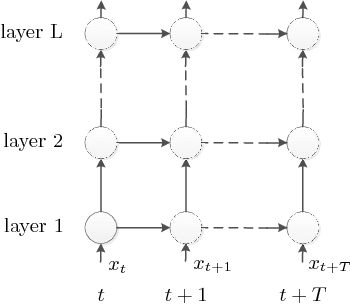
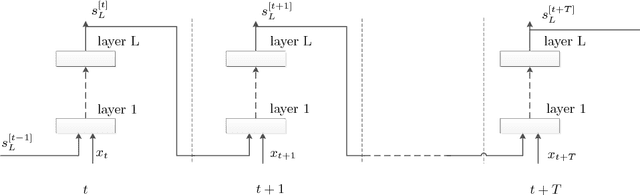
Recurrent Neural Networks (RNNs) play a major role in the field of sequential learning, and have outperformed traditional algorithms on many benchmarks. Training deep RNNs still remains a challenge, and most of the state-of-the-art models are structured with a transition depth of 2-4 layers. Recurrent Highway Networks (RHNs) were introduced in order to tackle this issue. These have achieved state-of-the-art performance on a few benchmarks using a depth of 10 layers. However, the performance of this architecture suffers from a bottleneck, and ceases to improve when an attempt is made to add more layers. In this work, we analyze the causes for this, and postulate that the main source is the way that the information flows through time. We introduce a novel and simple variation for the RHN cell, called Highway State Gating (HSG), which allows adding more layers, while continuing to improve performance. By using a gating mechanism for the state, we allow the net to "choose" whether to pass information directly through time, or to gate it. This mechanism also allows the gradient to back-propagate directly through time and, therefore, results in a slightly faster convergence. We use the Penn Treebank (PTB) dataset as a platform for empirical proof of concept. Empirical results show that the improvement due to Highway State Gating is for all depths, and as the depth increases, the improvement also increases.
Dynamic Graph Neural Networks for Sequential Recommendation
Apr 15, 2021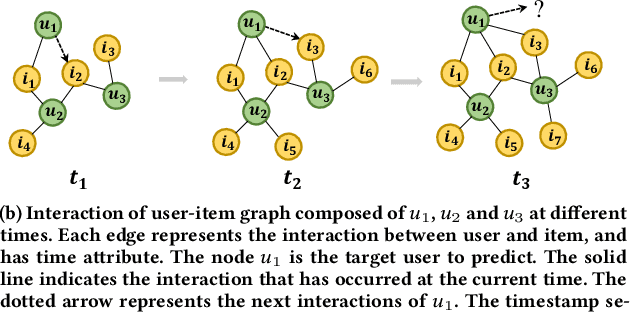
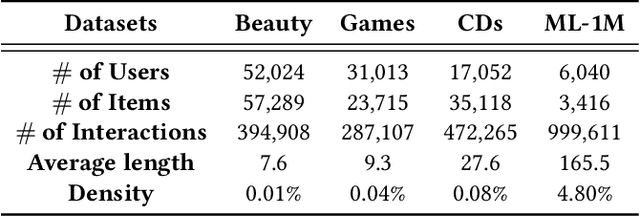
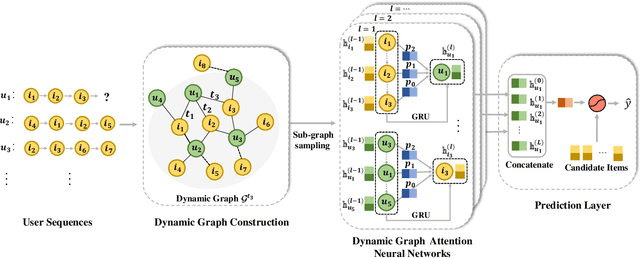
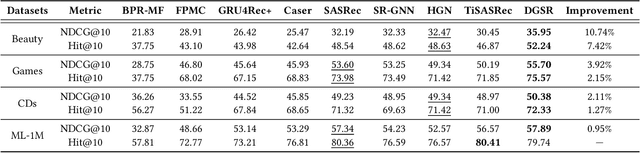
Modeling users' preference from his historical sequences is one of the core problem of sequential recommendation. Existing methods in such fields are widely distributed from conventional methods to deep learning methods. However, most of them only model users' interests within their own sequences and ignore the fine-grained utilization of dynamic collaborative signals among different user sequences, making them insufficient to explore users' preferences. We take inspiration from dynamic graph neural networks to cope with this challenge, unifying the user sequence modeling and dynamic interaction information among users into one framework. We propose a new method named \emph{Dynamic Graph Neural Network for Sequential Recommendation} (DGSR), which connects the sequence of different users through a dynamic graph structure, exploring the interactive behavior of users and items with time and order information. Furthermore, we design a Dynamic Graph Attention Neural Network to achieve the information propagation and aggregation among different users and their sequences in the dynamic graph. Consequently, the next-item prediction task in sequential recommendation is converted into a link prediction task for the user node to the item node in a dynamic graph. Extensive experiments on four public benchmarks show that DGSR outperforms several state-of-the-art methods. Further studies demonstrate the rationality and effectiveness of modeling user sequences through a dynamic graph.
Multi-view data capture for dynamic object reconstruction using handheld augmented reality mobiles
Mar 14, 2021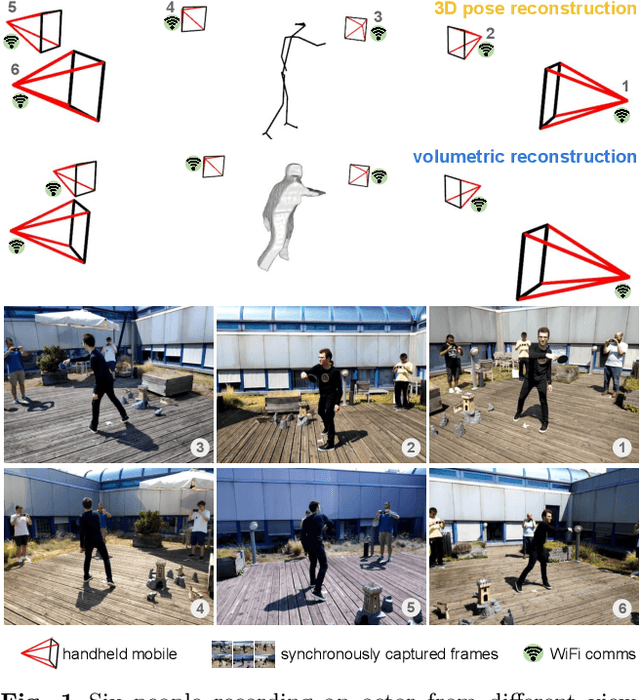

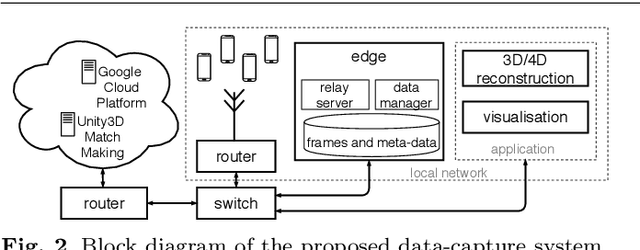

We propose a system to capture nearly-synchronous frame streams from multiple and moving handheld mobiles that is suitable for dynamic object 3D reconstruction. Each mobile executes Simultaneous Localisation and Mapping on-board to estimate its pose, and uses a wireless communication channel to send or receive synchronisation triggers. Our system can harvest frames and mobile poses in real time using a decentralised triggering strategy and a data-relay architecture that can be deployed either at the Edge or in the Cloud. We show the effectiveness of our system by employing it for 3D skeleton and volumetric reconstructions. Our triggering strategy achieves equal performance to that of an NTP-based synchronisation approach, but offers higher flexibility, as it can be adjusted online based on application needs. We created a challenging new dataset, namely 4DM, that involves six handheld augmented reality mobiles recording an actor performing sports actions outdoors. We validate our system on 4DM, analyse its strengths and limitations, and compare its modules with alternative ones.
Depth Completion using Plane-Residual Representation
Apr 15, 2021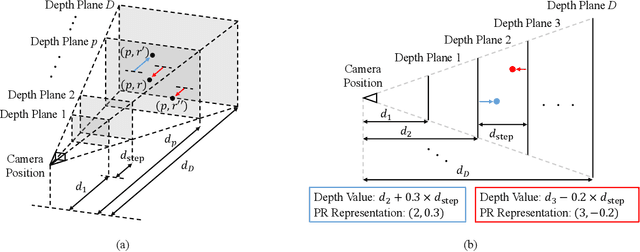
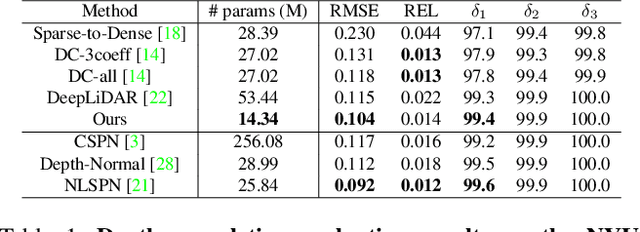
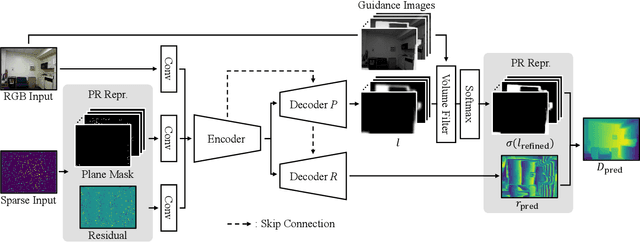
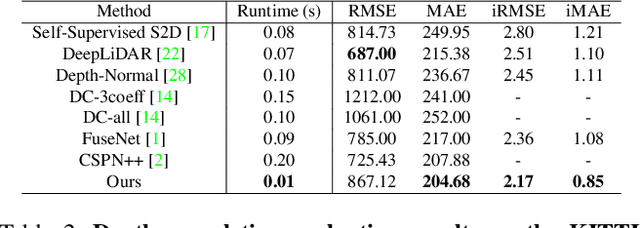
The basic framework of depth completion is to predict a pixel-wise dense depth map using very sparse input data. In this paper, we try to solve this problem in a more effective way, by reformulating the regression-based depth estimation problem into a combination of depth plane classification and residual regression. Our proposed approach is to initially densify sparse depth information by figuring out which plane a pixel should lie among a number of discretized depth planes, and then calculate the final depth value by predicting the distance from the specified plane. This will help the network to lessen the burden of directly regressing the absolute depth information from none, and to effectively obtain more accurate depth prediction result with less computation power and inference time. To do so, we firstly introduce a novel way of interpreting depth information with the closest depth plane label $p$ and a residual value $r$, as we call it, Plane-Residual (PR) representation. We also propose a depth completion network utilizing PR representation consisting of a shared encoder and two decoders, where one classifies the pixel's depth plane label, while the other one regresses the normalized distance from the classified depth plane. By interpreting depth information in PR representation and using our corresponding depth completion network, we were able to acquire improved depth completion performance with faster computation, compared to previous approaches.