 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Symbolic Multibody Methods for Real-Time Simulation of Railway Vehicles
Jun 06, 2017
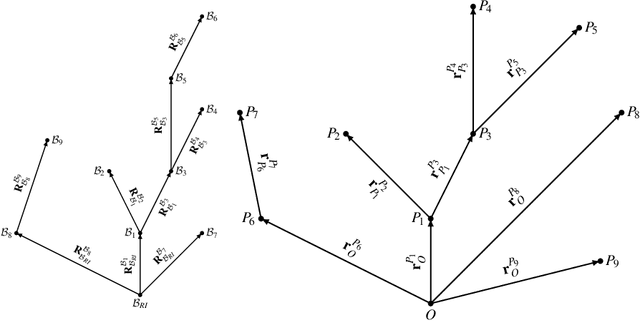


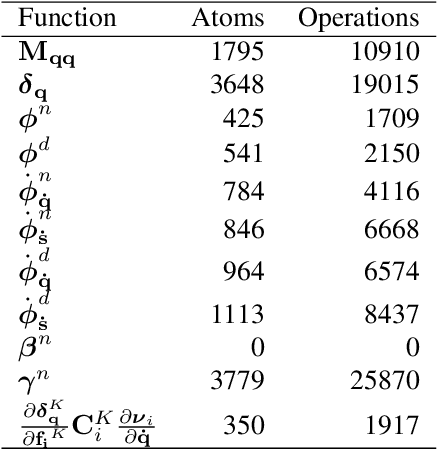
In this work, recently developed state-of-the-art symbolic multibody methods are tested to accurately model a complex railway vehicle. The model is generated using a symbolic implementation of the principle of the virtual power. Creep forces are modeled using a direct symbolic implementation of the standard linear Kalker model. No simplifications, as base parameter reduction, partial-linearization or look-up tables for contact kinematics, are used. An Implicit-Explicit integration scheme is proposed to efficiently deal with the stiff creep dynamics. Hard real-time performance is achieved: the CPU time required for a very stable 1 ms integration time step is 256 {\mu}s.
PSIMiner: A Tool for Mining Rich Abstract Syntax Trees from Code
Mar 23, 2021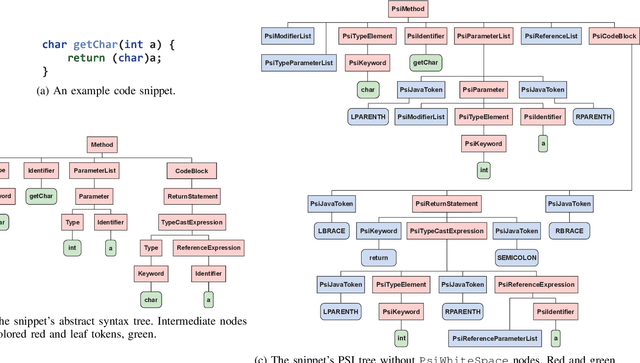

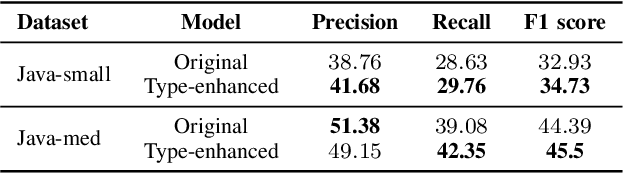
The application of machine learning algorithms to source code has grown in the past years. Since these algorithms are quite sensitive to input data, it is not surprising that researchers experiment with input representations. Nowadays, a popular starting point to represent code is abstract syntax trees (ASTs). Abstract syntax trees have been used for a long time in various software engineering domains, and in particular in IDEs. The API of modern IDEs allows to manipulate and traverse ASTs, resolve references between code elements, etc. Such algorithms can enrich ASTs with new data and therefore may be useful in ML-based code analysis. In this work, we present PSIMiner - a tool for processing PSI trees from the IntelliJ Platform. PSI trees contain code syntax trees as well as functions to work with them, and therefore can be used to enrich code representation using static analysis algorithms of modern IDEs. To showcase this idea, we use our tool to infer types of identifiers in Java ASTs and extend the code2seq model for the method name prediction problem.
Reframing demand forecasting: a two-fold approach for lumpy and intermittent demand
Mar 23, 2021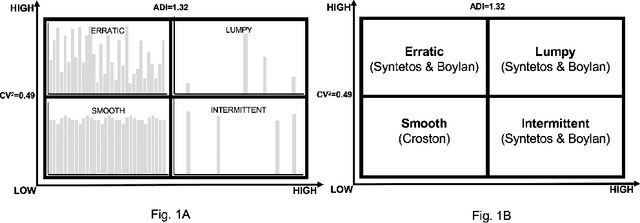

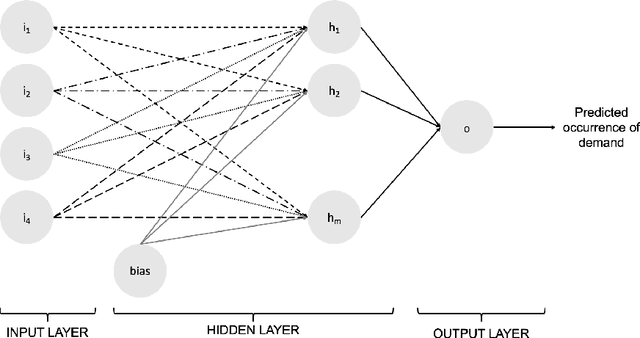
Demand forecasting is a crucial component of demand management. While shortening the forecasting horizon allows for more recent data and less uncertainty, this frequently means lower data aggregation levels and a more significant data sparsity. Sparse demand data usually results in lumpy or intermittent demand patterns, which have sparse and irregular demand intervals. Usual statistical and machine learning models fail to provide good forecasts in such scenarios. Our research shows that competitive demand forecasts can be obtained through two models: predicting the demand occurrence and estimating the demand size. We analyze the usage of local and global machine learning models for both cases and compare results against baseline methods. Finally, we propose a novel evaluation criterion of lumpy and intermittent demand forecasting models' performance. Our research shows that global classification models are the best choice when predicting demand event occurrence. When predicting demand sizes, we achieved the best results using Simple Exponential Smoothing forecast. We tested our approach on real-world data consisting of 516 three-year-long time series corresponding to European automotive original equipment manufacturers' daily demand.
Multi-scale Deep Learning Architecture for Nucleus Detection in Renal Cell Carcinoma Microscopy Image
Apr 28, 2021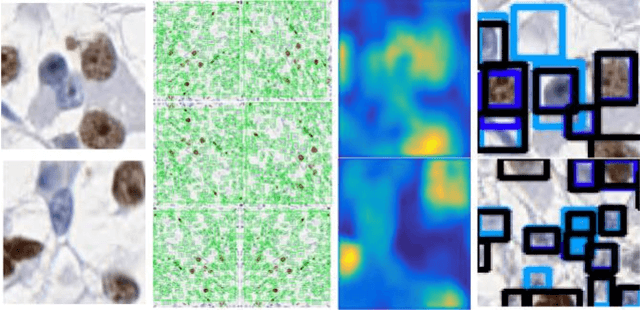
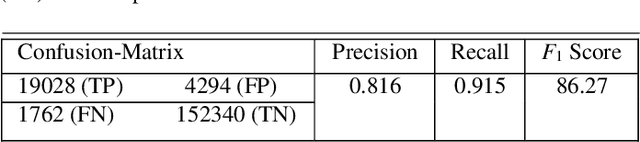
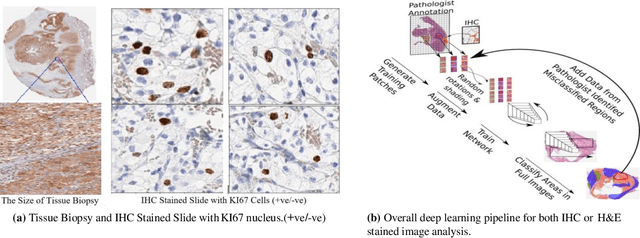
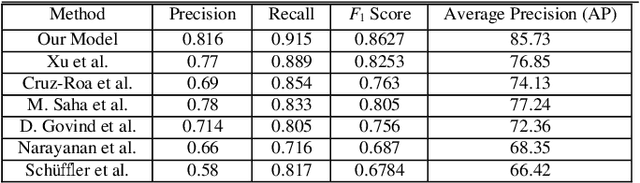
Clear cell renal cell carcinoma (ccRCC) is one of the most common forms of intratumoral heterogeneity in the study of renal cancer. ccRCC originates from the epithelial lining of proximal convoluted renal tubules. These cells undergo abnormal mutations in the presence of Ki67 protein and create a lump-like structure through cell proliferation. Manual counting of tumor cells in the tissue-affected sections is one of the strongest prognostic markers for renal cancer. However, this procedure is time-consuming and also prone to subjectivity. These assessments are based on the physical cell appearance and suffer wide intra-observer variations. Therefore, better cell nucleus detection and counting techniques can be an important biomarker for the assessment of tumor cell proliferation in routine pathological investigations. In this paper, we introduce a deep learning-based detection model for cell classification on IHC stained histology images. These images are classified into binary classes to find the presence of Ki67 protein in cancer-affected nucleus regions. Our model maps the multi-scale pyramid features and saliency information from local bounded regions and predicts the bounding box coordinates through regression. Our method validates the impact of Ki67 expression across a cohort of four hundred histology images treated with localized ccRCC and compares our results with the existing state-of-the-art nucleus detection methods. The precision and recall scores of the proposed method are computed and compared on the clinical data sets. The experimental results demonstrate that our model improves the F1 score up to 86.3% and an average area under the Precision-Recall curve as 85.73%.
Automatic Differentiation to Simultaneously Identify Nonlinear Dynamics and Extract Noise Probability Distributions from Data
Sep 29, 2020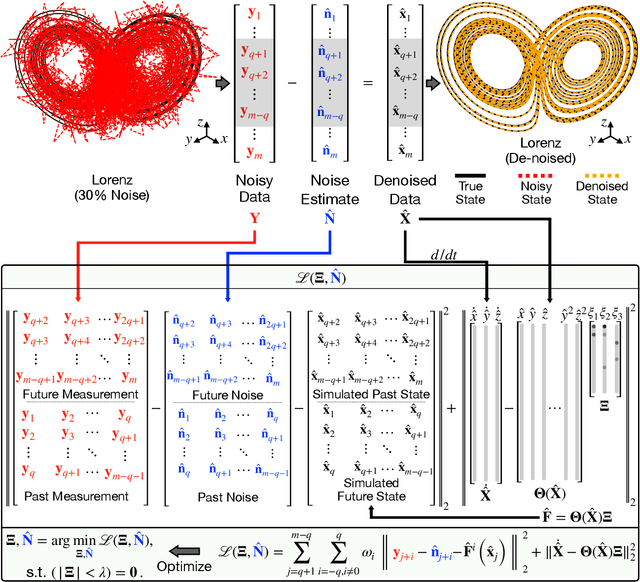
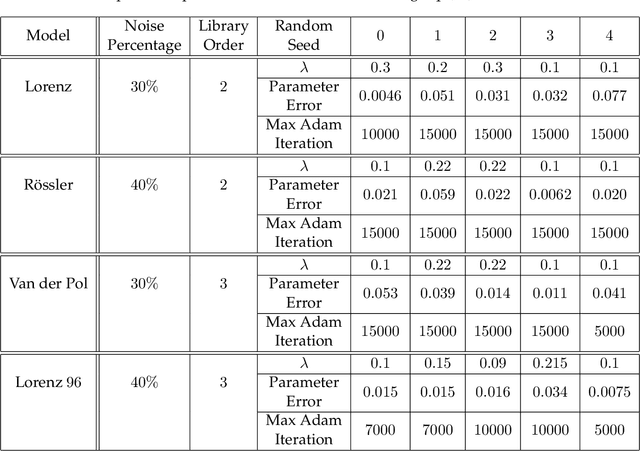
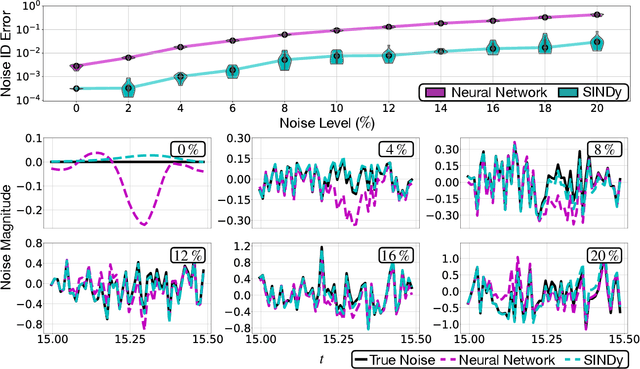
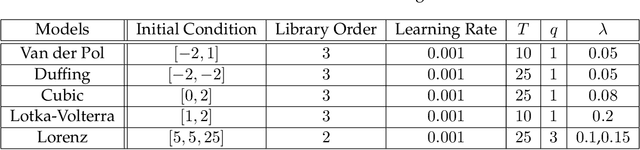
The sparse identification of nonlinear dynamics (SINDy) is a regression framework for the discovery of parsimonious dynamic models and governing equations from time-series data. As with all system identification methods, noisy measurements compromise the accuracy and robustness of the model discovery procedure. In this work, we develop a variant of the SINDy algorithm that integrates automatic differentiation and recent time-stepping constrained motivated by Rudy et al. for simultaneously (i) denoising the data, (ii) learning and parametrizing the noise probability distribution, and (iii) identifying the underlying parsimonious dynamical system responsible for generating the time-series data. Thus within an integrated optimization framework, noise can be separated from signal, resulting in an architecture that is approximately twice as robust to noise as state-of-the-art methods, handling as much as 40% noise on a given time-series signal and explicitly parametrizing the noise probability distribution. We demonstrate this approach on several numerical examples, from Lotka-Volterra models to the spatio-temporal Lorenz 96 model. Further, we show the method can identify a diversity of probability distributions including Gaussian, uniform, Gamma, and Rayleigh.
Universal Neural Vocoding with Parallel WaveNet
Feb 15, 2021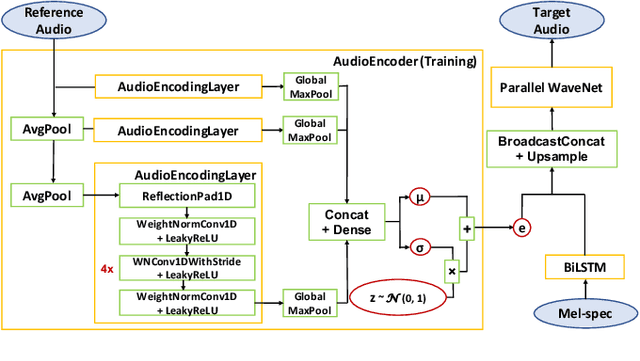

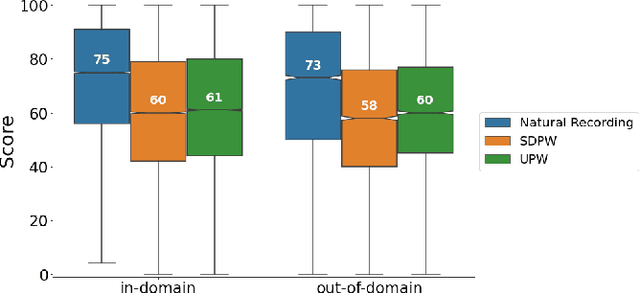
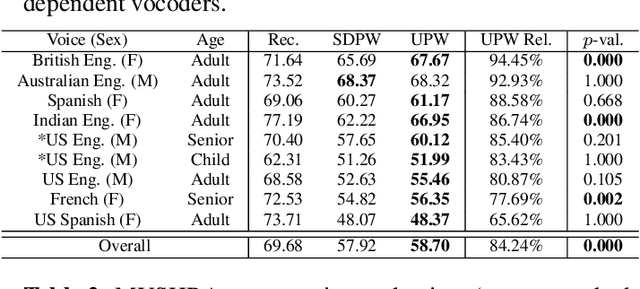
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
TPCN: Temporal Point Cloud Networks for Motion Forecasting
Mar 04, 2021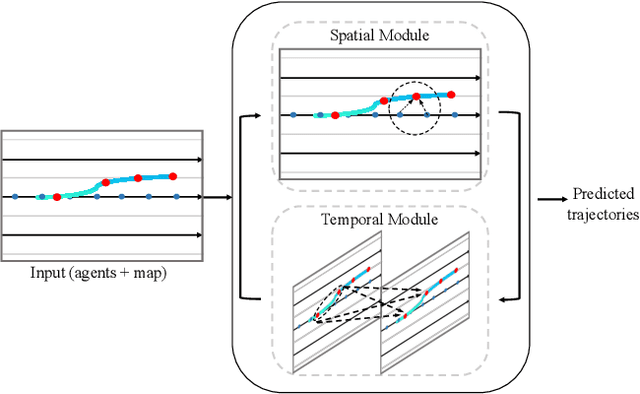
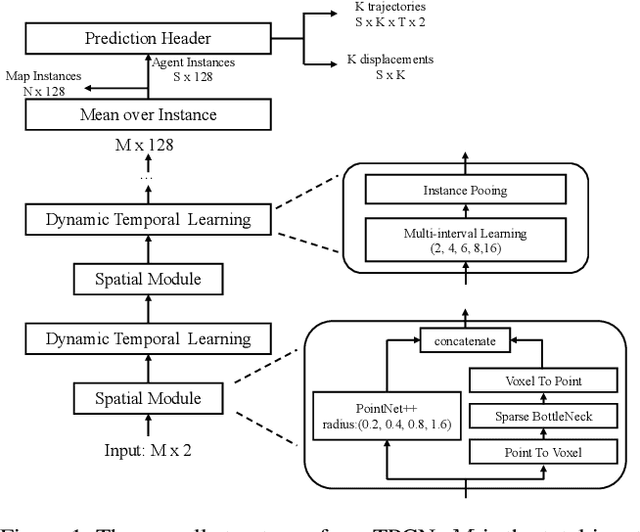
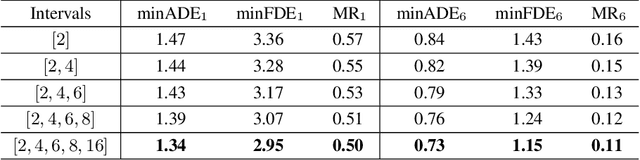
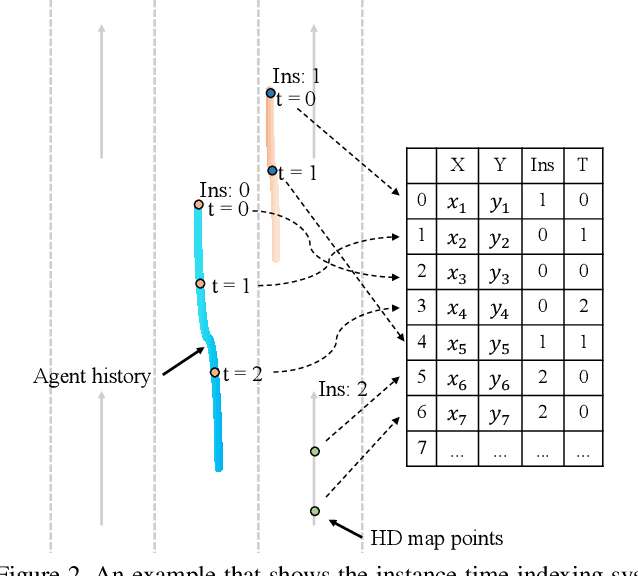
We propose the Temporal Point Cloud Networks (TPCN), a novel and flexible framework with joint spatial and temporal learning for trajectory prediction. Unlike existing approaches that rasterize agents and map information as 2D images or operate in a graph representation, our approach extends ideas from point cloud learning with dynamic temporal learning to capture both spatial and temporal information by splitting trajectory prediction into both spatial and temporal dimensions. In the spatial dimension, agents can be viewed as an unordered point set, and thus it is straightforward to apply point cloud learning techniques to model agents' locations. While the spatial dimension does not take kinematic and motion information into account, we further propose dynamic temporal learning to model agents' motion over time. Experiments on the Argoverse motion forecasting benchmark show that our approach achieves the state-of-the-art results.
GraphKKE: Graph Kernel Koopman Embedding for Human Microbiome Analysis
Sep 07, 2020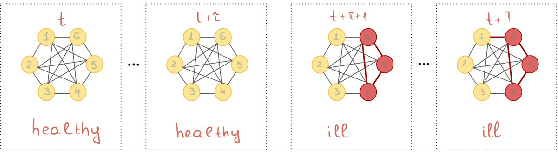
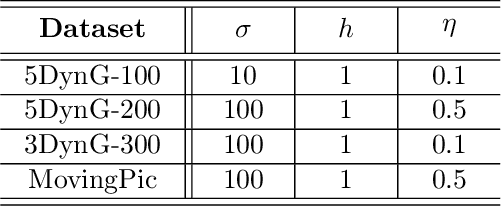
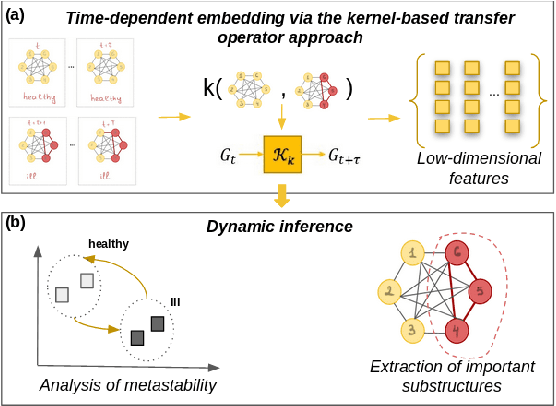

More and more diseases have been found to be strongly correlated with disturbances in the microbiome constitution, e.g., obesity, diabetes, or some cancer types. Thanks to modern high-throughput omics technologies, it becomes possible to directly analyze human microbiome and its influence on the health status. Microbial communities are monitored over long periods of time and the associations between their members are explored. These relationships can be described by a time-evolving graph. In order to understand responses of the microbial community members to a distinct range of perturbations such as antibiotics exposure or diseases and general dynamical properties, the time-evolving graph of the human microbial communities has to be analyzed. This becomes especially challenging due to dozens of complex interactions among microbes and metastable dynamics. The key to solving this problem is the representation of the time-evolving graphs as fixed-length feature vectors preserving the original dynamics. We propose a method for learning the embedding of the time-evolving graph that is based on the spectral analysis of transfer operators and graph kernels. We demonstrate that our method can capture temporary changes in the time-evolving graph on both created synthetic data and real-world data. Our experiments demonstrate the efficacy of the method. Furthermore, we show that our method can be applied to human microbiome data to study dynamic processes.
Robust Self-Ensembling Network for Hyperspectral Image Classification
Apr 08, 2021
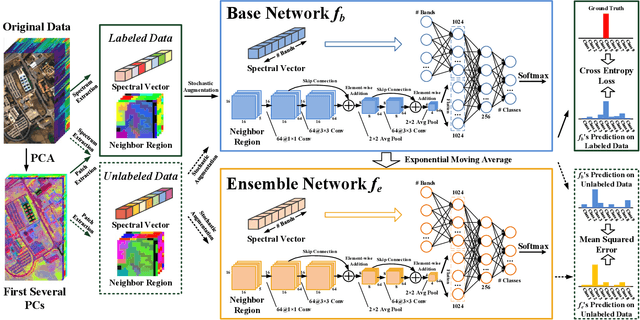
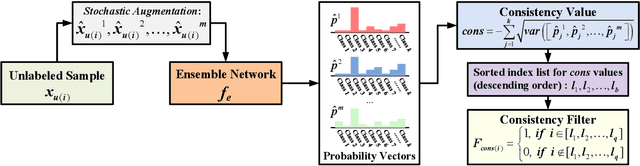
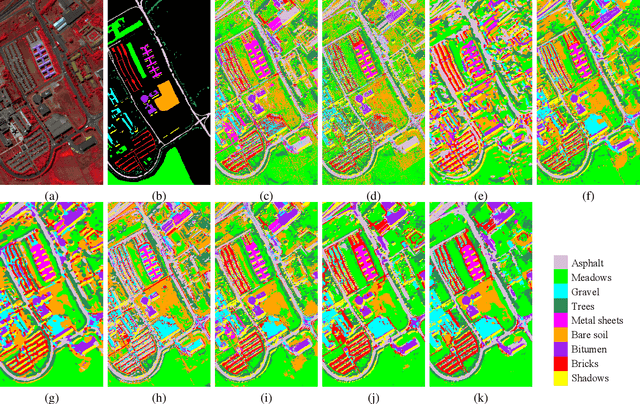
Recent research has shown the great potential of deep learning algorithms in the hyperspectral image (HSI) classification task. Nevertheless, training these models usually requires a large amount of labeled data. Since the collection of pixel-level annotations for HSI is laborious and time-consuming, developing algorithms that can yield good performance in the small sample size situation is of great significance. In this study, we propose a robust self-ensembling network (RSEN) to address this problem. The proposed RSEN consists of two subnetworks including a base network and an ensemble network. With the constraint of both the supervised loss from the labeled data and the unsupervised loss from the unlabeled data, the base network and the ensemble network can learn from each other, achieving the self-ensembling mechanism. To the best of our knowledge, the proposed method is the first attempt to introduce the self-ensembling technique into the HSI classification task, which provides a different view on how to utilize the unlabeled data in HSI to assist the network training. We further propose a novel consistency filter to increase the robustness of self-ensembling learning. Extensive experiments on three benchmark HSI datasets demonstrate that the proposed algorithm can yield competitive performance compared with the state-of-the-art methods.
Sensor-Aided Beamwidth and Power Control for Next Generation Vehicular Communications
Apr 08, 2021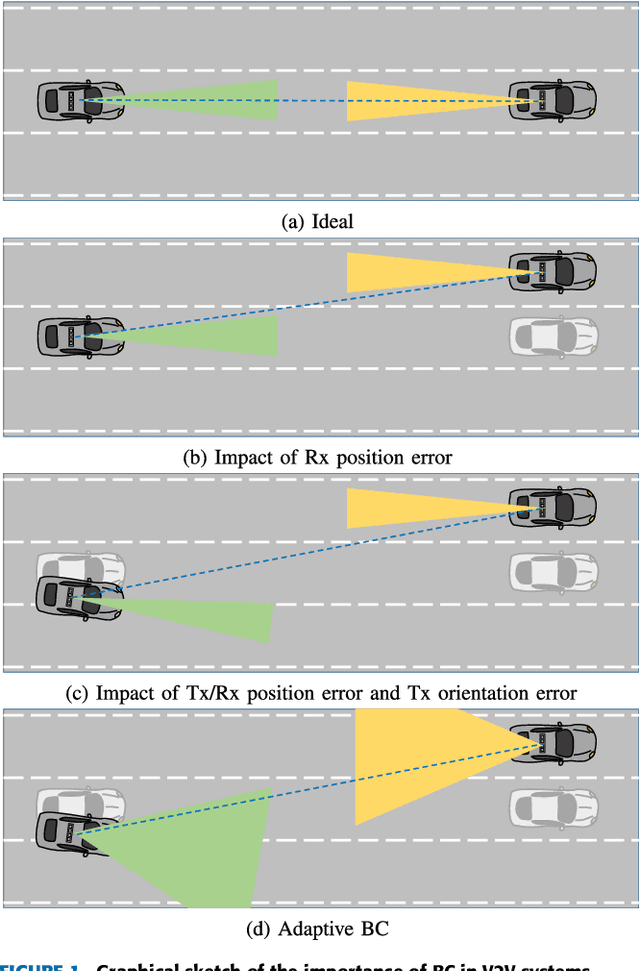

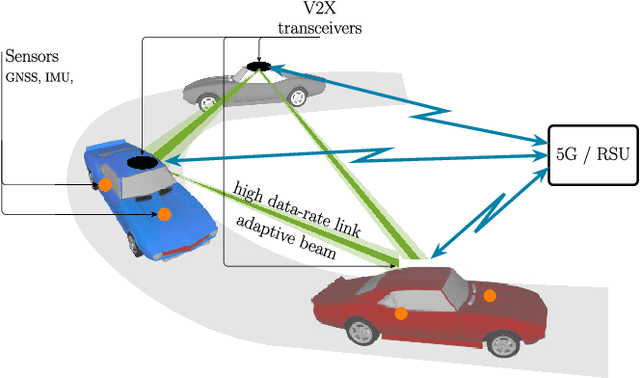
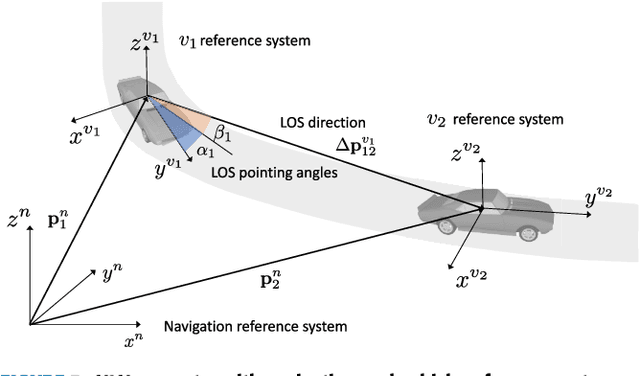
Ultra-reliable low-latency Vehicle-to-Everything (V2X) communications are needed to meet the extreme requirements of enhanced driving applications. Millimeter-Wave (24.25-52.6 GHz) or sub-THz (>100 GHz) V2X communications are a viable solution, provided that the highly collimated beams are kept aligned during vehicles' maneuverings. In this work, we propose a sensor-assisted dynamic Beamwidth and Power Control (BPC) system to counteract the detrimental effect of vehicle dynamics, exploiting data collected by on-board inertial and positioning sensors, mutually exchanged among vehicles over a parallel low-rate link, e.g., 5G New Radio (NR) Frequency Range 1 (FR1). The proposed BPC solution works on top of a sensor-aided Beam Alignment and Tracking (BAT) system, overcoming the limitations of fixed-beamwidth systems and optimizing the performance in challenging Vehicle-to-Vehicle (V2V) scenarios, even if extensions to Vehicle-to-Infrastructure (V2I) use-cases are feasible. We validate the sensor-assisted dynamic BPC on real trajectories and sensors' data collected by a dedicated experimental campaign. The goal is to show the advantages of the proposed BPC strategy in a high data-rate Line-Of-Sight (LOS) V2V context, and to outline the requirements in terms of sensors' sampling time and accuracy, along with the end-to-end latency on the control channel.