 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
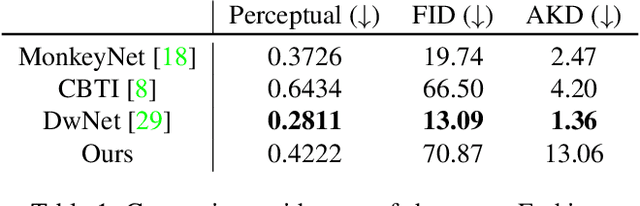
From Shadow Generation to Shadow Removal
Mar 24, 2021
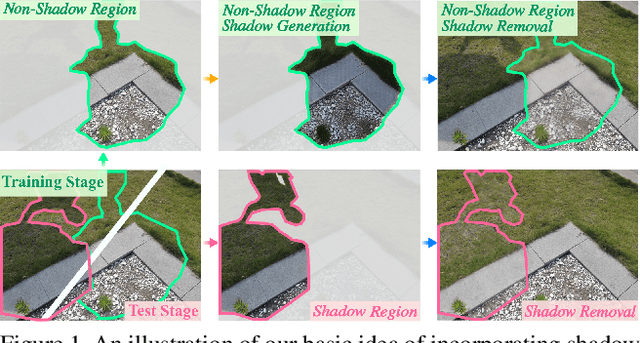
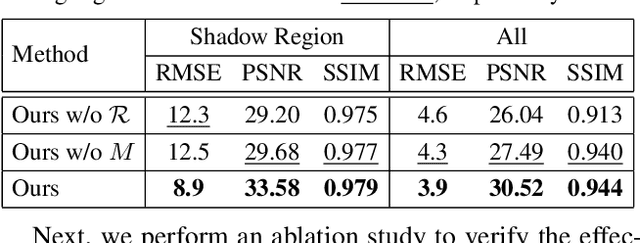
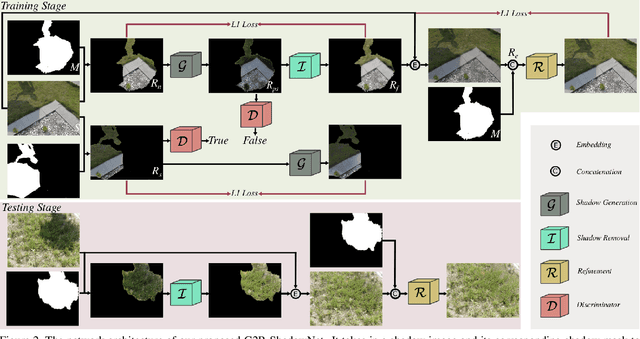
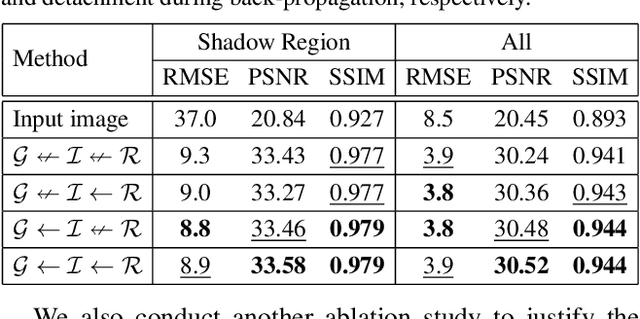
Shadow removal is a computer-vision task that aims to restore the image content in shadow regions. While almost all recent shadow-removal methods require shadow-free images for training, in ECCV 2020 Le and Samaras introduces an innovative approach without this requirement by cropping patches with and without shadows from shadow images as training samples. However, it is still laborious and time-consuming to construct a large amount of such unpaired patches. In this paper, we propose a new G2R-ShadowNet which leverages shadow generation for weakly-supervised shadow removal by only using a set of shadow images and their corresponding shadow masks for training. The proposed G2R-ShadowNet consists of three sub-networks for shadow generation, shadow removal and refinement, respectively and they are jointly trained in an end-to-end fashion. In particular, the shadow generation sub-net stylises non-shadow regions to be shadow ones, leading to paired data for training the shadow-removal sub-net. Extensive experiments on the ISTD dataset and the Video Shadow Removal dataset show that the proposed G2R-ShadowNet achieves competitive performances against the current state of the arts and outperforms Le and Samaras' patch-based shadow-removal method.
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
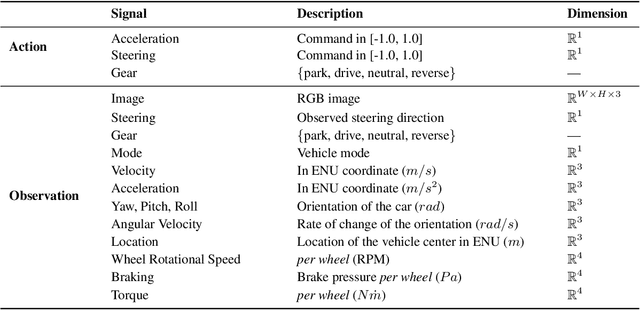
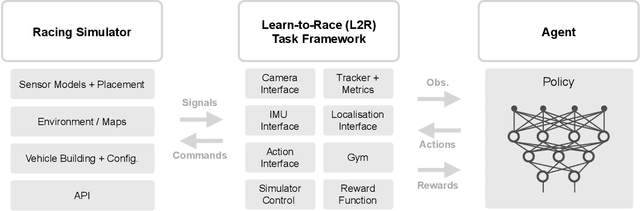

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
Learning representations for multivariate time series with missing data using Temporal Kernelized Autoencoders
May 09, 2018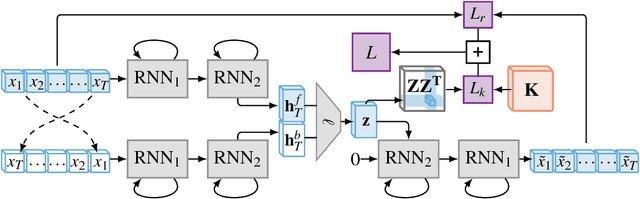
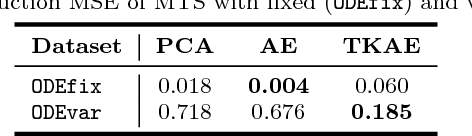
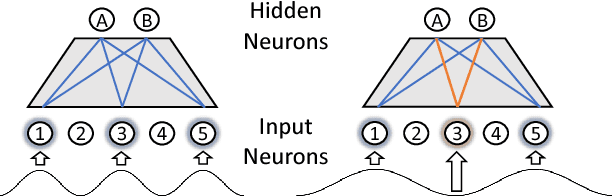
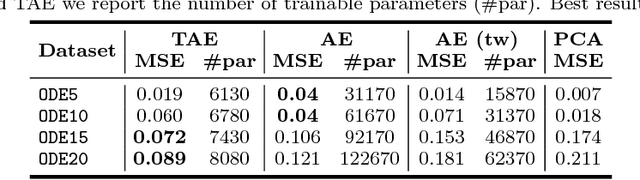
Learning compressed representations of multivariate time series (MTS) facilitate the analysis and process of the data in presence of noise, redundant information, and large amount of variables and time steps. However, classic dimensionality reduction approaches are not designed to process sequential data, especially in the presence of missing values. In this work, we propose a novel autoencoder architecture based on recurrent neural networks to generate compressed representations of MTS, which may contain missing values and have variable lengths. Our autoencoder learns fixed-length vectorial representations, whose pairwise similarities are aligned with a kernel function that operates in input space and handles missing values. This, allows to preserve relationships in the low-dimensional vector space even in presence of missing values. To highlight the main features of the proposed autoencoder, we first investigate its performance in controlled experiments. Successively, we show how the learned representations can be exploited both in several benchmark and real-world classification tasks on medical data. Finally, based on the proposed architecture, we conceive a framework for one-class classification and imputation of missing data in time series extracted from ECG signals.
Multiclass Burn Wound Image Classification Using Deep Convolutional Neural Networks
Mar 01, 2021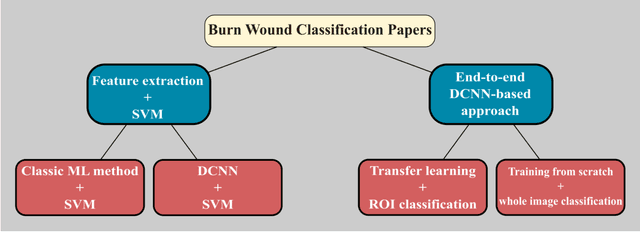
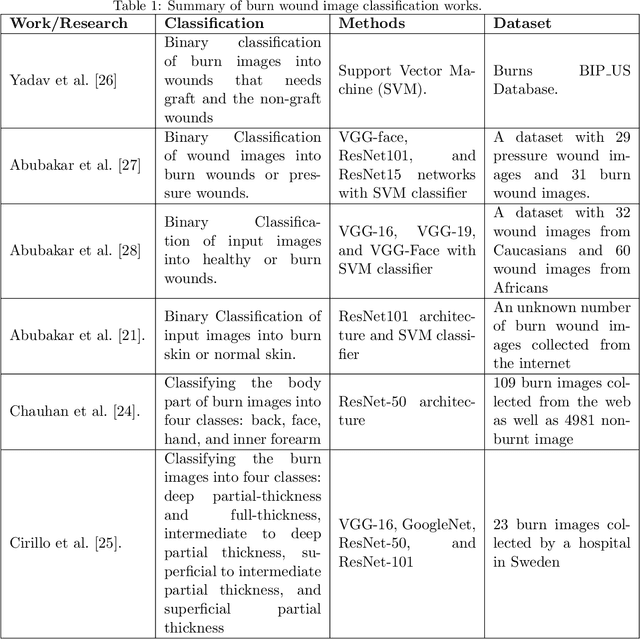
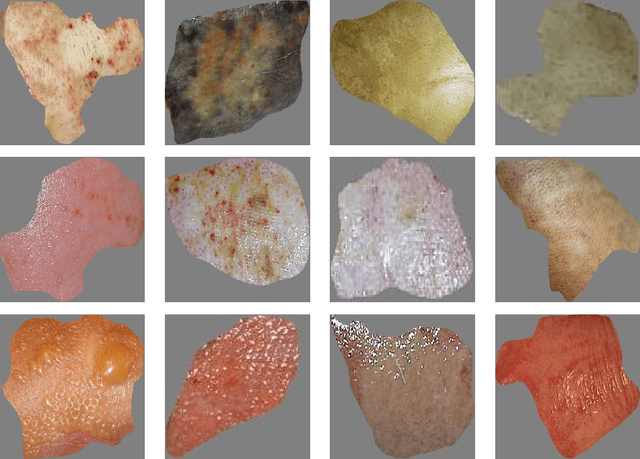
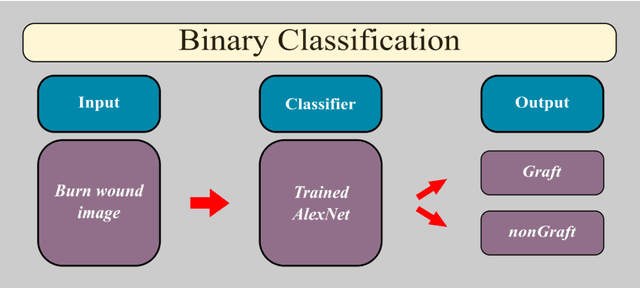
Millions of people are affected by acute and chronic wounds yearly across the world. Continuous wound monitoring is important for wound specialists to allow more accurate diagnosis and optimization of management protocols. Machine Learning-based classification approaches provide optimal care strategies resulting in more reliable outcomes, cost savings, healing time reduction, and improved patient satisfaction. In this study, we use a deep learning-based method to classify burn wound images into two or three different categories based on the wound conditions. A pre-trained deep convolutional neural network, AlexNet, is fine-tuned using a burn wound image dataset and utilized as the classifier. The classifier's performance is evaluated using classification metrics such as accuracy, precision, and recall as well as confusion matrix. A comparison with previous works that used the same dataset showed that our designed classifier improved the classification accuracy by more than 8%.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021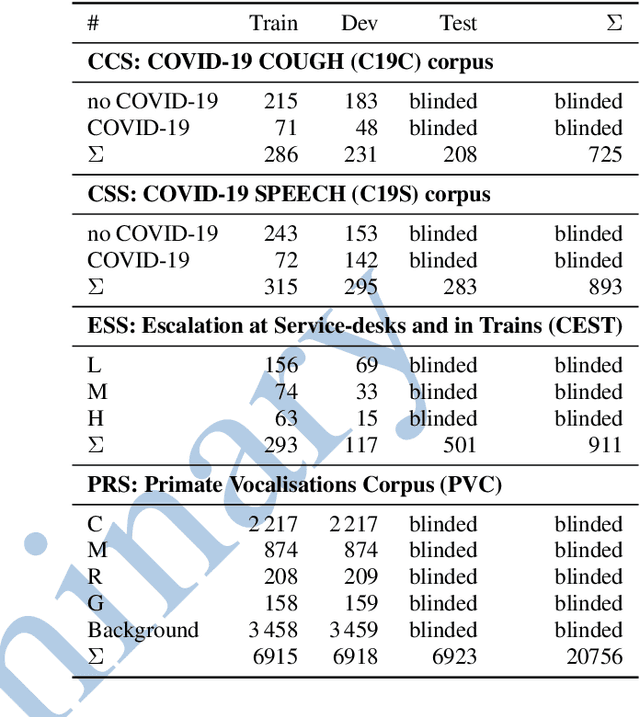
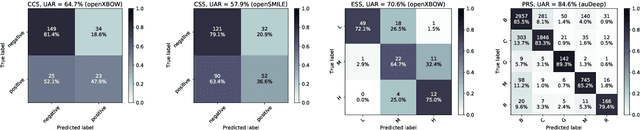
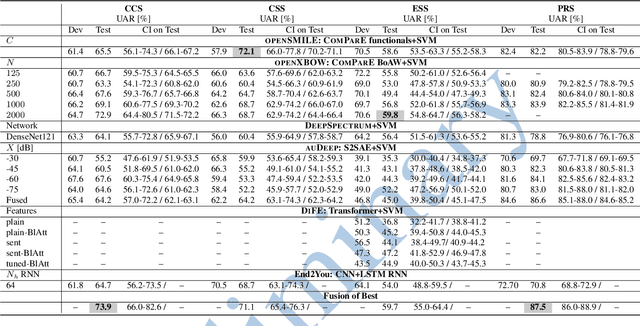
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
Local Change Point Detection and Signal Cleaning using EEMD with applications to Acoustic Shockwaves and Cardiac Signals
Mar 01, 2021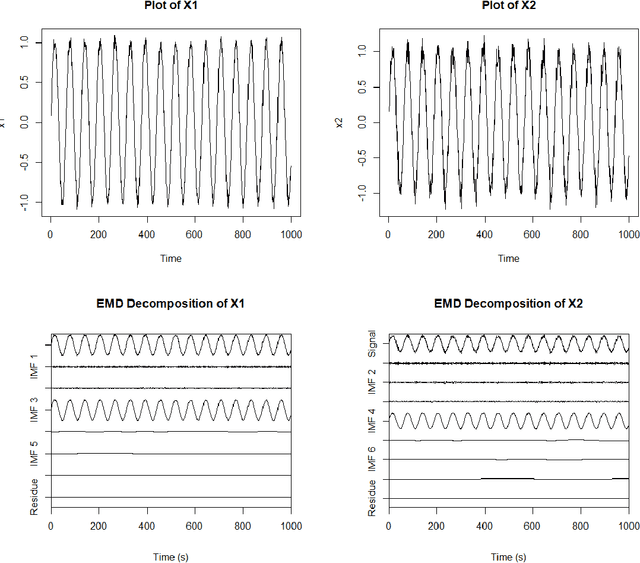
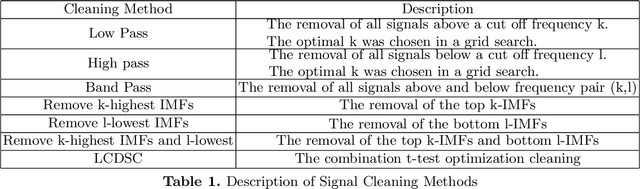
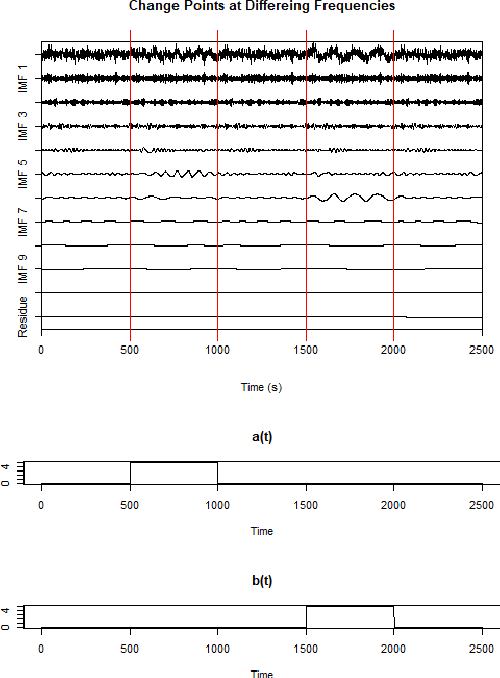
With the ability to create time varying basis functions, the Ensemble Empirical Mode Decomposition (EEMD) has quickly become the preferred way to decompose nonlinear and nonstationary signals. However, we find current EEMD signal cleaning techniques lacking, unable to deal with the nonlinearities that are common for the complex signals that the EEMD is used for. By combining change point detection and a new sparse basis function optimization problem, we are able to show that it is possible to create unique filters for each change point which emphasize the basis functions that are observing a change. This not only allows one to understand which frequency bands are observing a change, but cleaning the signal to emphasize changes can lead to improved signal classification accuracy. We show that this technique has implications for a variety of applications including acoustics and medicine. The technique is implemented in R via the \textbf{LCDSC} package.
CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
Mar 31, 2021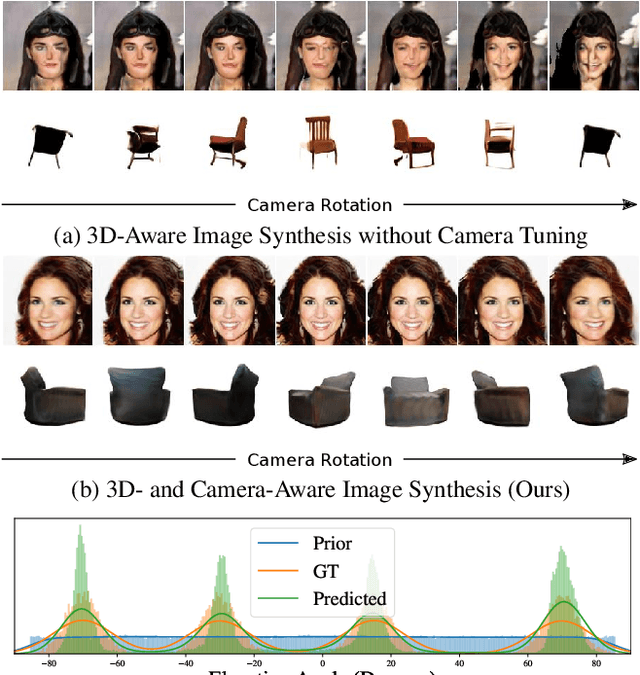
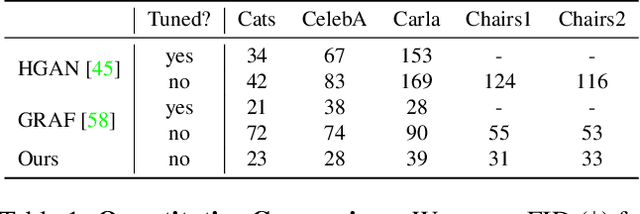
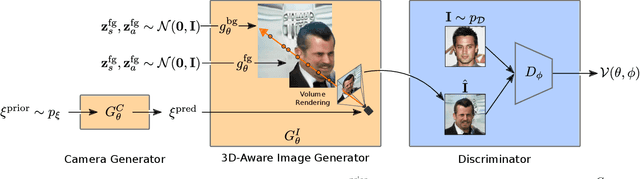

Tremendous progress in deep generative models has led to photorealistic image synthesis. While achieving compelling results, most approaches operate in the two-dimensional image domain, ignoring the three-dimensional nature of our world. Several recent works therefore propose generative models which are 3D-aware, i.e., scenes are modeled in 3D and then rendered differentiably to the image plane. This leads to impressive 3D consistency, but incorporating such a bias comes at a price: the camera needs to be modeled as well. Current approaches assume fixed intrinsics and a predefined prior over camera pose ranges. As a result, parameter tuning is typically required for real-world data, and results degrade if the data distribution is not matched. Our key hypothesis is that learning a camera generator jointly with the image generator leads to a more principled approach to 3D-aware image synthesis. Further, we propose to decompose the scene into a background and foreground model, leading to more efficient and disentangled scene representations. While training from raw, unposed image collections, we learn a 3D- and camera-aware generative model which faithfully recovers not only the image but also the camera data distribution. At test time, our model generates images with explicit control over the camera as well as the shape and appearance of the scene.
Efficient Regional Memory Network for Video Object Segmentation
Mar 24, 2021
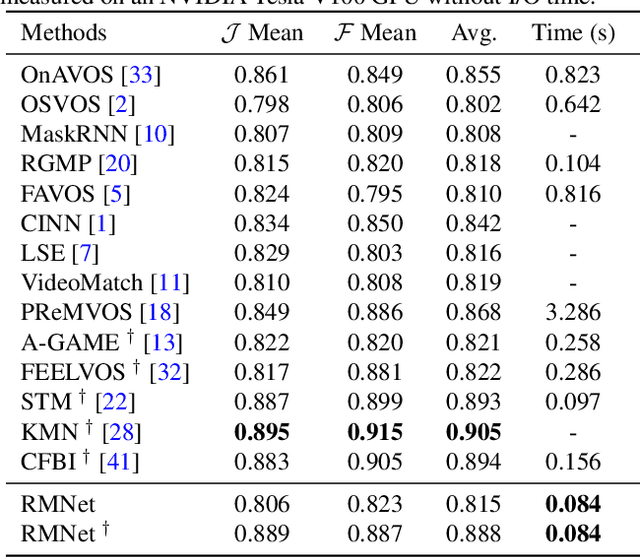
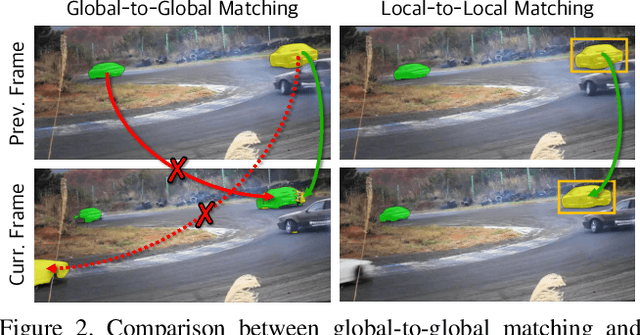
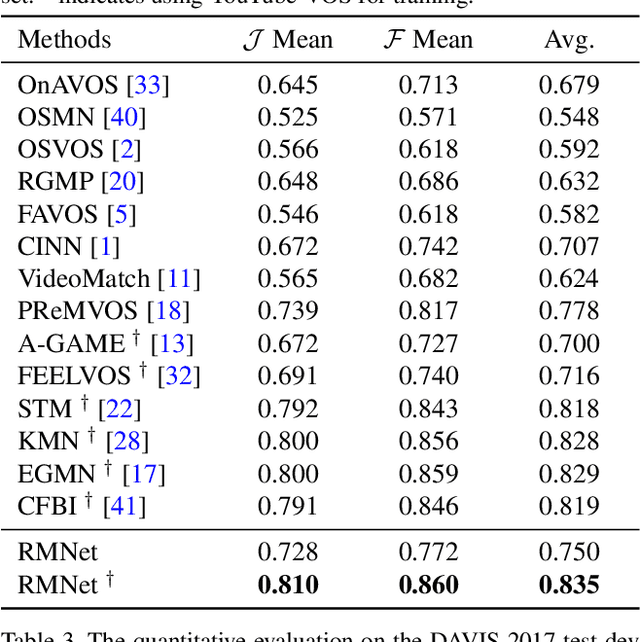
Recently, several Space-Time Memory based networks have shown that the object cues (e.g. video frames as well as the segmented object masks) from the past frames are useful for segmenting objects in the current frame. However, these methods exploit the information from the memory by global-to-global matching between the current and past frames, which lead to mismatching to similar objects and high computational complexity. To address these problems, we propose a novel local-to-local matching solution for semi-supervised VOS, namely Regional Memory Network (RMNet). In RMNet, the precise regional memory is constructed by memorizing local regions where the target objects appear in the past frames. For the current query frame, the query regions are tracked and predicted based on the optical flow estimated from the previous frame. The proposed local-to-local matching effectively alleviates the ambiguity of similar objects in both memory and query frames, which allows the information to be passed from the regional memory to the query region efficiently and effectively. Experimental results indicate that the proposed RMNet performs favorably against state-of-the-art methods on the DAVIS and YouTube-VOS datasets.
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021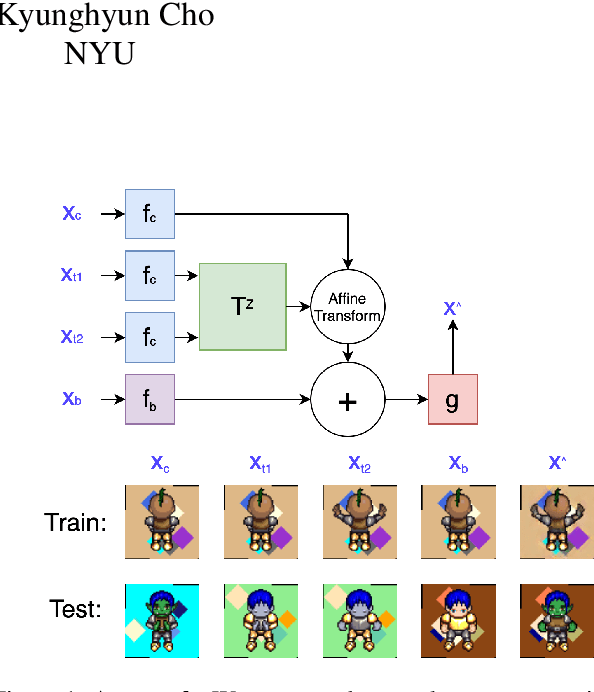
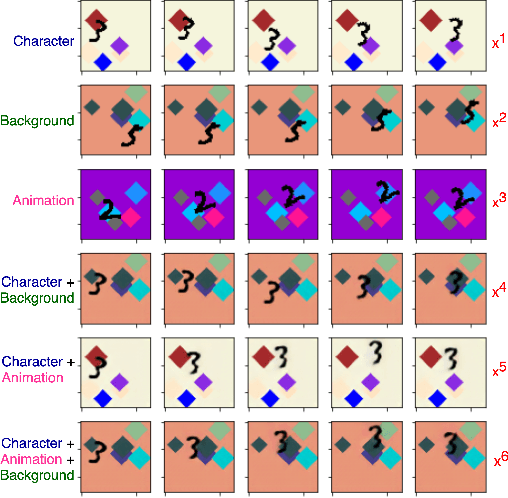
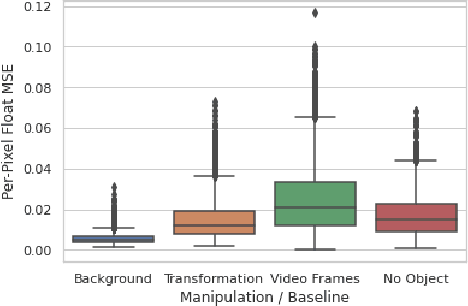
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
ThetA -- fast and robust clustering via a distance parameter
Mar 01, 2021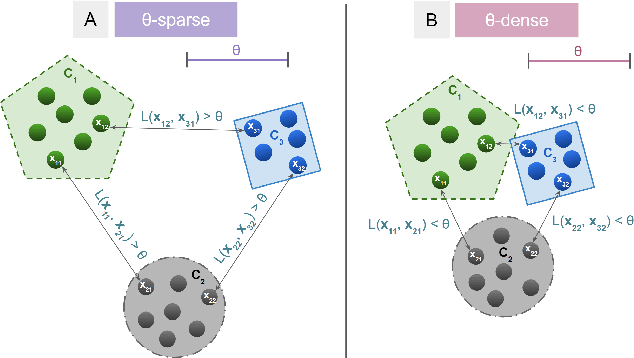
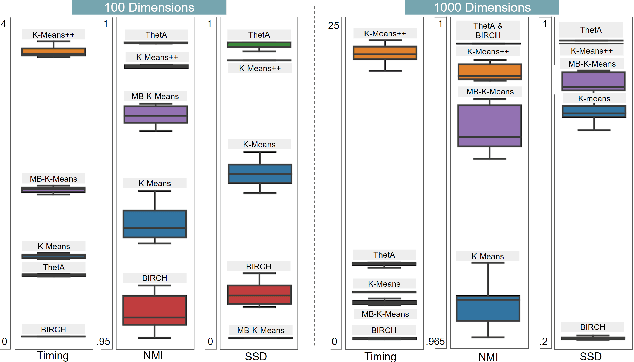
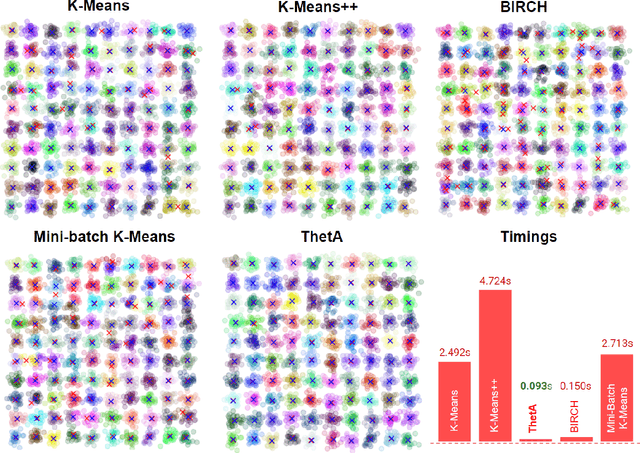
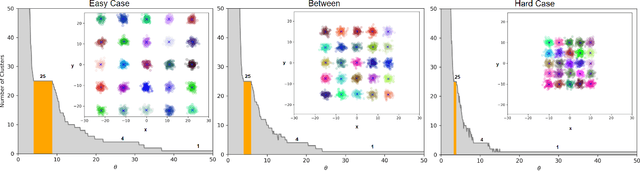
Clustering is a fundamental problem in machine learning where distance-based approaches have dominated the field for many decades. This set of problems is often tackled by partitioning the data into K clusters where the number of clusters is chosen apriori. While significant progress has been made on these lines over the years, it is well established that as the number of clusters or dimensions increase, current approaches dwell in local minima resulting in suboptimal solutions. In this work, we propose a new set of distance threshold methods called Theta-based Algorithms (ThetA). Via experimental comparisons and complexity analyses we show that our proposed approach outperforms existing approaches in: a) clustering accuracy and b) time complexity. Additionally, we show that for a large class of problems, learning the optimal threshold is straightforward in comparison to learning K. Moreover, we show how ThetA can infer the sparsity of datasets in higher dimensions.