 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021
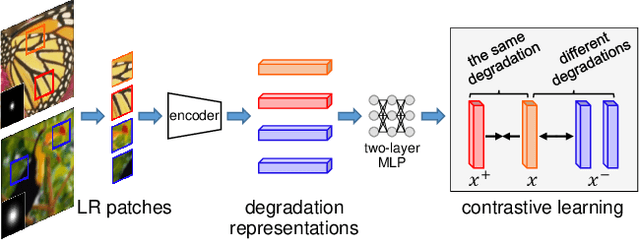

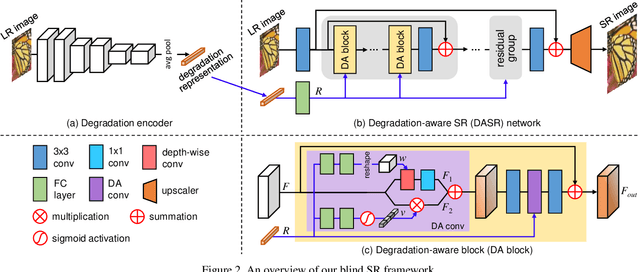
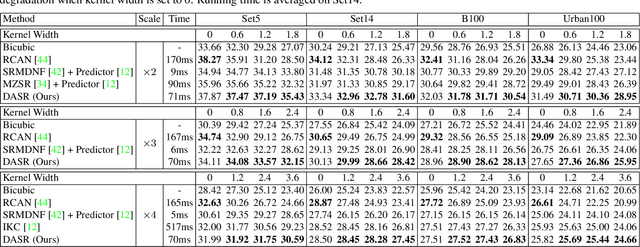
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.
MBAPose: Mask and Bounding-Box Aware Pose Estimation of Surgical Instruments with Photorealistic Domain Randomization
Mar 15, 2021
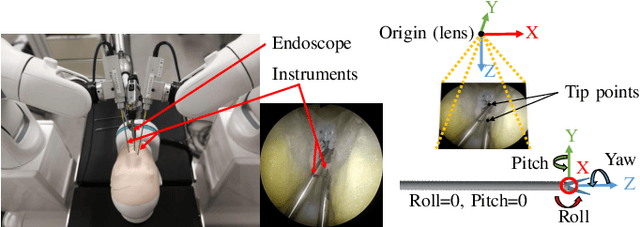
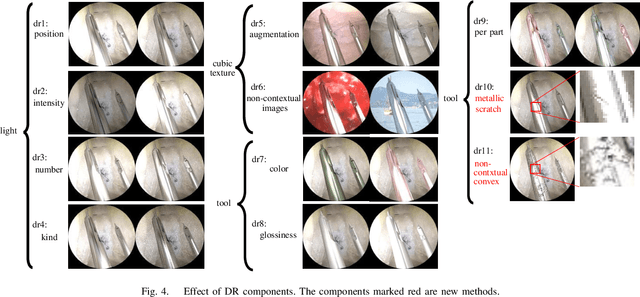
Surgical robots are controlled using a priori models based on robots' geometric parameters, which are calibrated before the surgical procedure. One of the challenges in using robots in real surgical settings is that parameters change over time, consequently deteriorating control accuracy. In this context, our group has been investigating online calibration strategies without added sensors. In one step toward that goal, we have developed an algorithm to estimate the pose of the instruments' shafts in endoscopic images. In this study, we build upon that earlier work and propose a new framework to more precisely estimate the pose of a rigid surgical instrument. Our strategy is based on a novel pose estimation model called MBAPose and the use of synthetic training data. Our experiments demonstrated an improvement of 21 % for translation error and 26 % for orientation error on synthetic test data with respect to our previous work. Results with real test data provide a baseline for further research.
Model-Driven Deep Learning Based Channel Estimation and Feedback for Millimeter-Wave Massive Hybrid MIMO Systems
Apr 22, 2021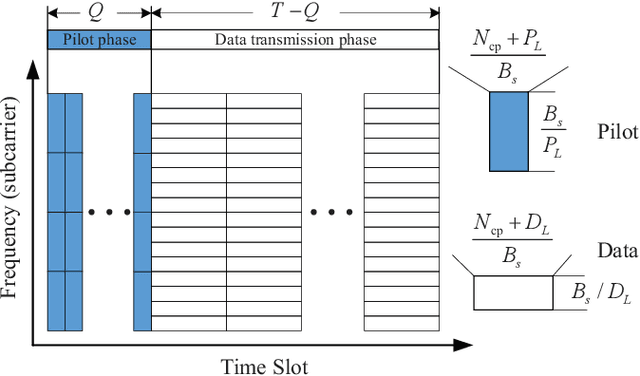
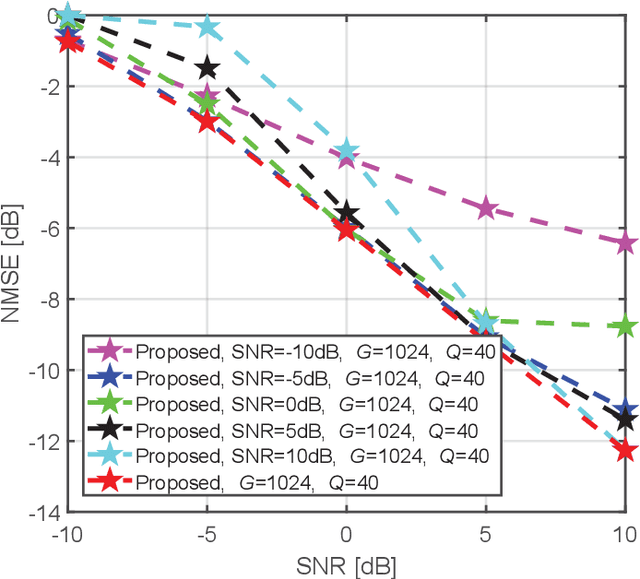
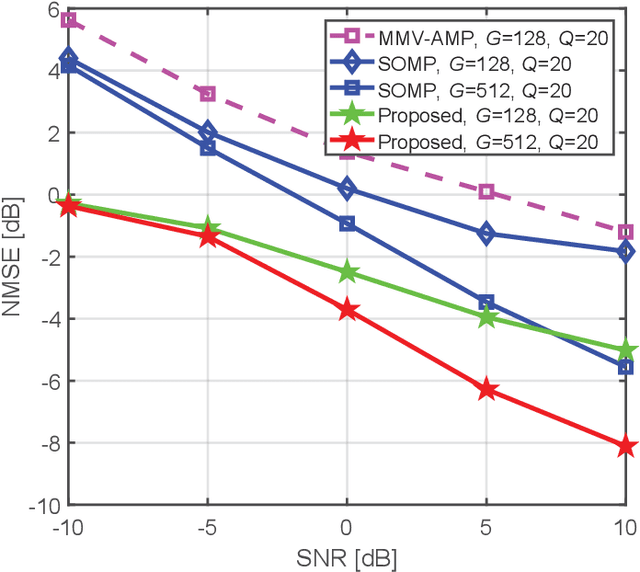
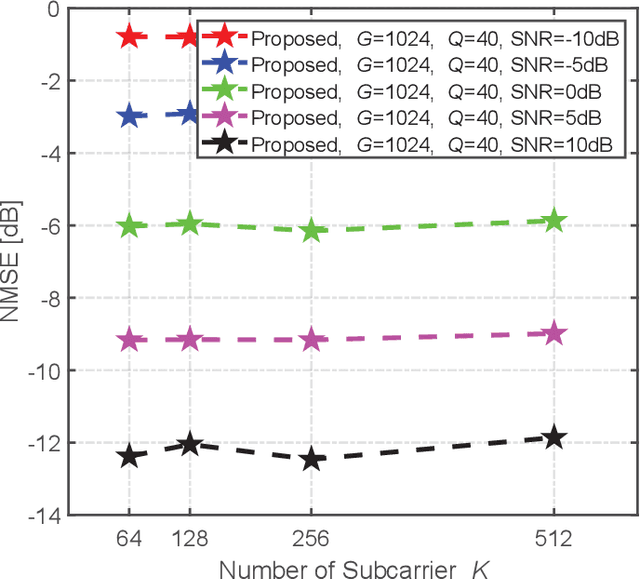
This paper proposes a model-driven deep learning (MDDL)-based channel estimation and feedback scheme for wideband millimeter-wave (mmWave) massive hybrid multiple-input multiple-output (MIMO) systems, where the angle-delay domain channels' sparsity is exploited for reducing the overhead. Firstly, we consider the uplink channel estimation for time-division duplexing systems. To reduce the uplink pilot overhead for estimating the high-dimensional channels from a limited number of radio frequency (RF) chains at the base station (BS), we propose to jointly train the phase shift network and the channel estimator as an auto-encoder. Particularly, by exploiting the channels' structured sparsity from an a priori model and learning the integrated trainable parameters from the data samples, the proposed multiple-measurement-vectors learned approximate message passing (MMV-LAMP) network with the devised redundant dictionary can jointly recover multiple subcarriers' channels with significantly enhanced performance. Moreover, we consider the downlink channel estimation and feedback for frequency-division duplexing systems. Similarly, the pilots at the BS and channel estimator at the users can be jointly trained as an encoder and a decoder, respectively. Besides, to further reduce the channel feedback overhead, only the received pilots on part of the subcarriers are fed back to the BS, which can exploit the MMV-LAMP network to reconstruct the spatial-frequency channel matrix. Numerical results show that the proposed MDDL-based channel estimation and feedback scheme outperforms the state-of-the-art approaches.
Resolution Limits of 20 Questions Search Strategies for Moving Targets
Mar 15, 2021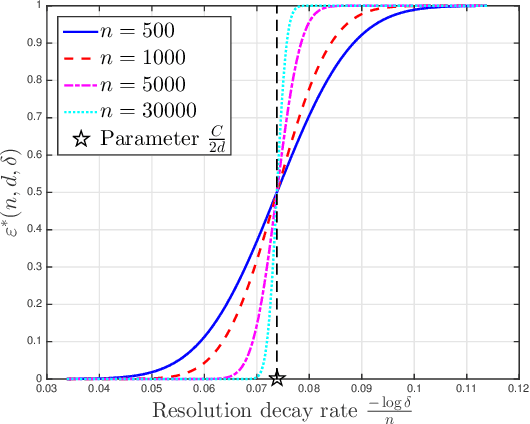
We establish fundamental limits of tracking a moving target over the unit cube under the framework of 20 questions with measurement-dependent noise. In this problem, there is an oracle who knows the instantaneous location of a target. Our task is to query the oracle as few times as possible to accurately estimate the trajectory of the moving target, whose initial location and velocity is \emph{unknown}. We study the case where the oracle's answer to each query is corrupted by random noise with query-dependent discrete distribution. In our formulation, the performance criterion is the resolution, which is defined as the maximal absolute value between the true location and estimated location at each discrete time during the searching process. We are interested in the minimal resolution of any non-adaptive searching procedure with a finite number of queries and derive approximations to this optimal resolution via the second-order asymptotic analysis.
Low-complexity Distributed Detection with One-bit Memory Under Neyman-Pearson Criterion
Apr 22, 2021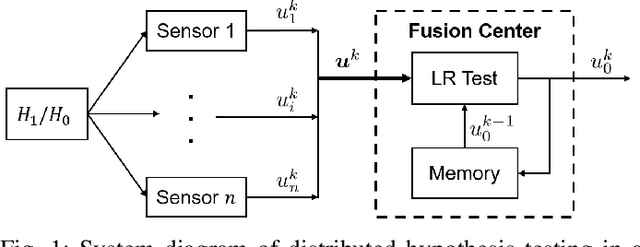
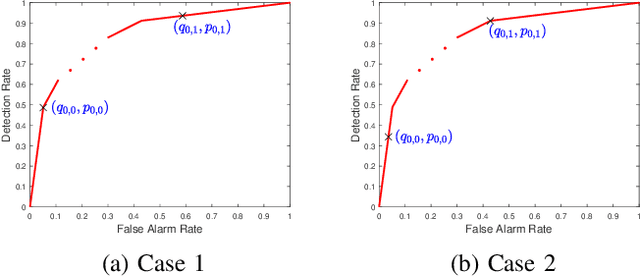
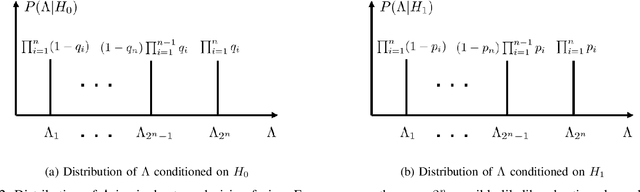
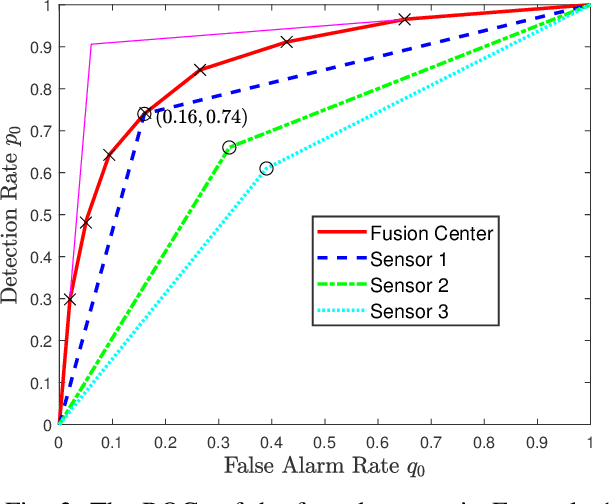
We consider a multi-stage distributed detection scenario, where $n$ sensors and a fusion center (FC) are deployed to accomplish a binary hypothesis test. At each time stage, local sensors generate binary messages, assumed to be spatially and temporally independent given the hypothesis, and then upload them to the FC for global detection decision making. We suppose a one-bit memory is available at the FC to store its decision history and focus on developing iterative fusion schemes. We first visit the detection problem of performing the Neyman-Pearson (N-P) test at each stage and give an optimal algorithm, called the oracle algorithm, to solve it. Structural properties and limitation of the fusion performance in the asymptotic regime are explored for the oracle algorithm. We notice the computational inefficiency of the oracle fusion and propose a low-complexity alternative, for which the likelihood ratio (LR) test threshold is tuned in connection to the fusion decision history compressed in the one-bit memory. The low-complexity algorithm greatly brings down the computational complexity at each stage from $O(4^n)$ to $O(n)$. We show that the proposed algorithm is capable of converging exponentially to the same detection probability as that of the oracle one. Moreover, the rate of convergence is shown to be asymptotically identical to that of the oracle algorithm. Finally, numerical simulations and real-world experiments demonstrate the effectiveness and efficiency of our distributed algorithm.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021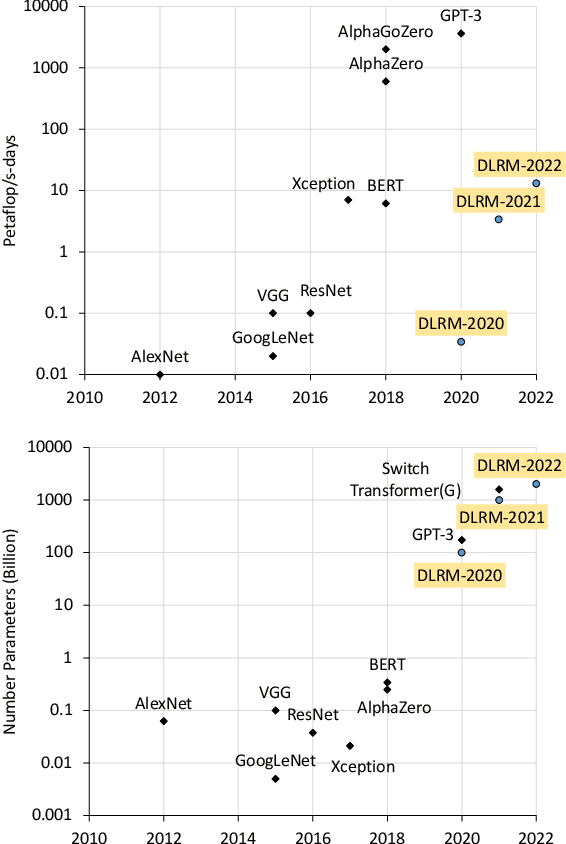

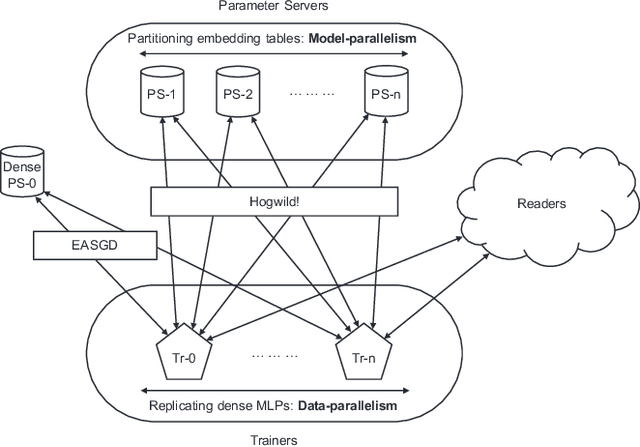
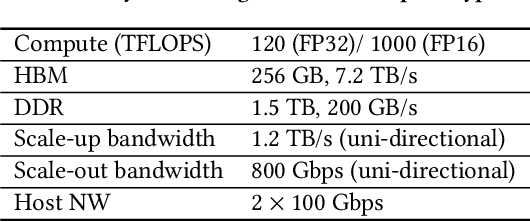
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
A data-set of piercing needle through deformable objects for Deep Learning from Demonstrations
Dec 04, 2020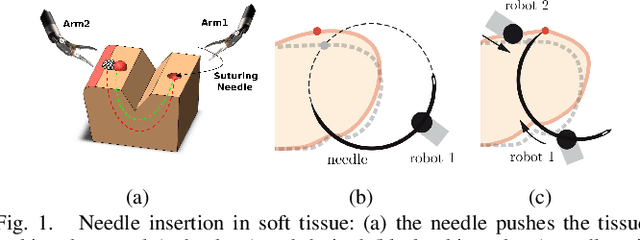
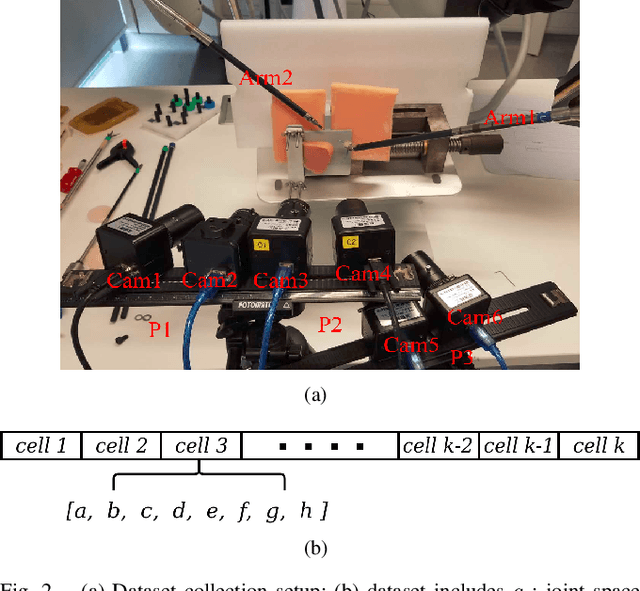

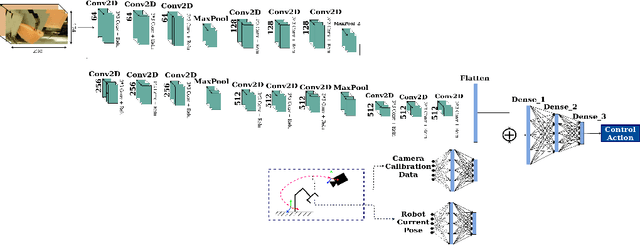
Many robotic tasks are still teleoperated since automating them is very time consuming and expensive. Robot Learning from Demonstrations (RLfD) can reduce programming time and cost. However, conventional RLfD approaches are not directly applicable to many robotic tasks, e.g. robotic suturing with minimally invasive robots, as they require a time-consuming process of designing features from visual information. Deep Neural Networks (DNN) have emerged as useful tools for creating complex models capturing the relationship between high-dimensional observation space and low-level action/state space. Nonetheless, such approaches require a dataset suitable for training appropriate DNN models. This paper presents a dataset of inserting/piercing a needle with two arms of da Vinci Research Kit in/through soft tissues. The dataset consists of (1) 60 successful needle insertion trials with randomised desired exit points recorded by 6 high-resolution calibrated cameras, (2) the corresponding robot data, calibration parameters and (3) the commanded robot control input where all the collected data are synchronised. The dataset is designed for Deep-RLfD approaches. We also implemented several deep RLfD architectures, including simple feed-forward CNNs and different Recurrent Convolutional Networks (RCNs). Our study indicates RCNs improve the prediction accuracy of the model despite that the baseline feed-forward CNNs successfully learns the relationship between the visual information and the next step control actions of the robot. The dataset, as well as our baseline implementations of RLfD, are publicly available for bench-marking at https://github.com/imanlab/d-lfd.
Learning from Noisy Labels via Dynamic Loss Thresholding
Apr 01, 2021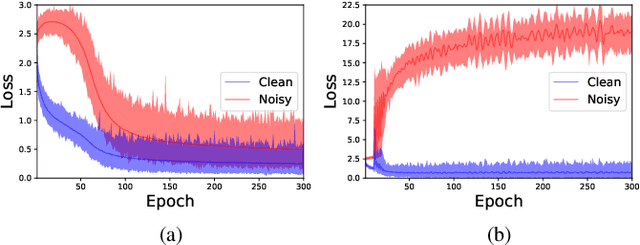
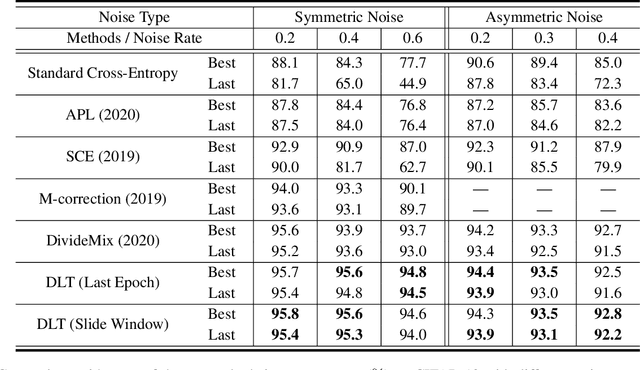
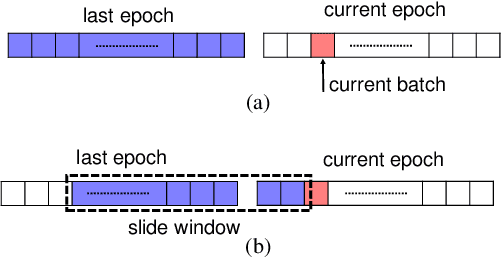
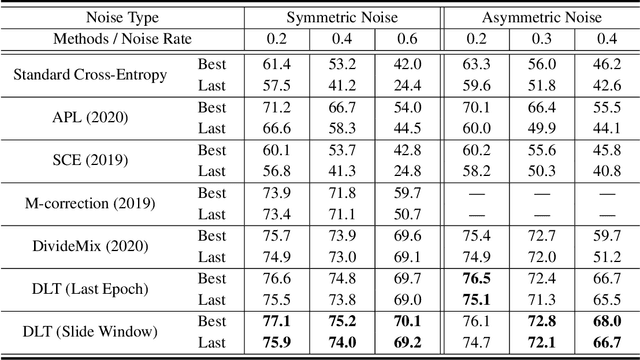
Numerous researches have proved that deep neural networks (DNNs) can fit everything in the end even given data with noisy labels, and result in poor generalization performance. However, recent studies suggest that DNNs tend to gradually memorize the data, moving from correct data to mislabeled data. Inspired by this finding, we propose a novel method named Dynamic Loss Thresholding (DLT). During the training process, DLT records the loss value of each sample and calculates dynamic loss thresholds. Specifically, DLT compares the loss value of each sample with the current loss threshold. Samples with smaller losses can be considered as clean samples with higher probability and vice versa. Then, DLT discards the potentially corrupted labels and further leverages supervised learning techniques. Experiments on CIFAR-10/100 and Clothing1M demonstrate substantial improvements over recent state-of-the-art methods. In addition, we investigate two real-world problems for the first time. Firstly, we propose a novel approach to estimate the noise rates of datasets based on the loss difference between the early and late training stages of DNNs. Secondly, we explore the effect of hard samples (which are difficult to be distinguished) on the process of learning from noisy labels.
Compressive lensless endoscopy with partial speckle scanning
Apr 22, 2021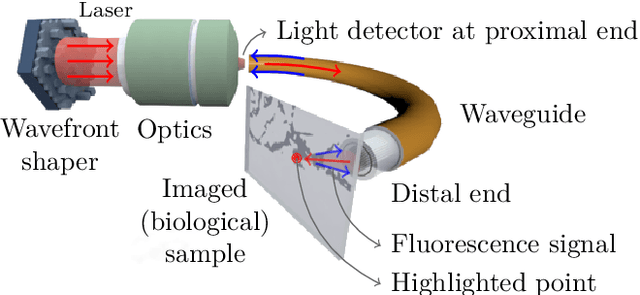
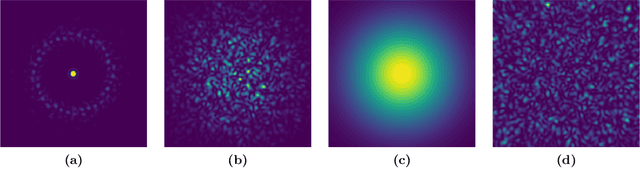
The lensless endoscope (LE) is a promising device to acquire in vivo images at a cellular scale. The tiny size of the probe enables a deep exploration of the tissues. Lensless endoscopy with a multicore fiber (MCF) commonly uses a spatial light modulator (SLM) to coherently combine, at the output of the MCF, few hundreds of beamlets into a focus spot. This spot is subsequently scanned across the sample to generate a fluorescent image. We propose here a novel scanning scheme, partial speckle scanning (PSS), inspired by compressive sensing theory, that avoids the use of an SLM to perform fluorescent imaging in LE with reduced acquisition time. Such a strategy avoids photo-bleaching while keeping high reconstruction quality. We develop our approach on two key properties of the LE: (i) the ability to easily generate speckles, and (ii) the memory effect in MCF that allows to use fast scan mirrors to shift light patterns. First, we show that speckles are sub-exponential random fields. Despite their granular structure, an appropriate choice of the reconstruction parameters makes them good candidates to build efficient sensing matrices. Then, we numerically validate our approach and apply it on experimental data. The proposed sensing technique outperforms conventional raster scanning: higher reconstruction quality is achieved with far fewer observations. For a fixed reconstruction quality, our speckle scanning approach is faster than compressive sensing schemes which require to change the speckle pattern for each observation.
On the Unreasonable Effectiveness of Centroids in Image Retrieval
Apr 28, 2021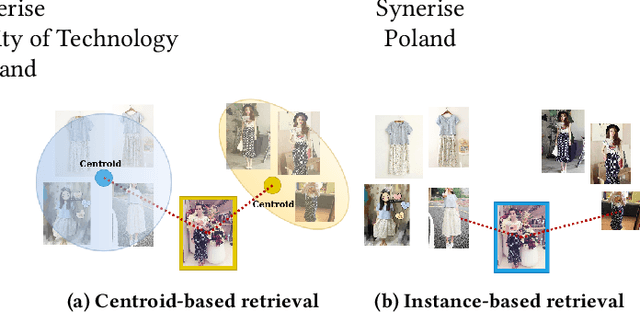
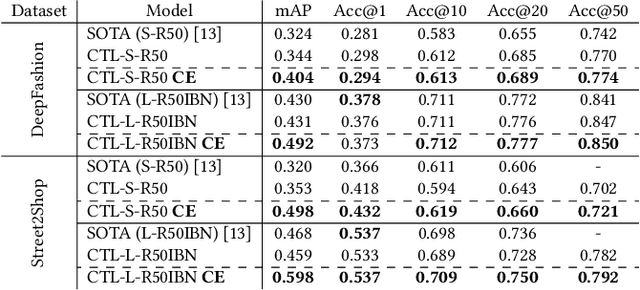
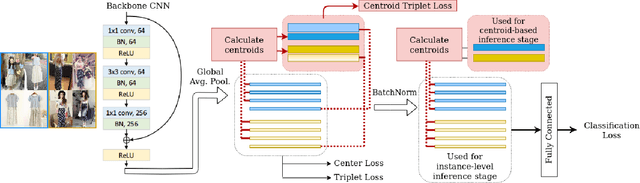
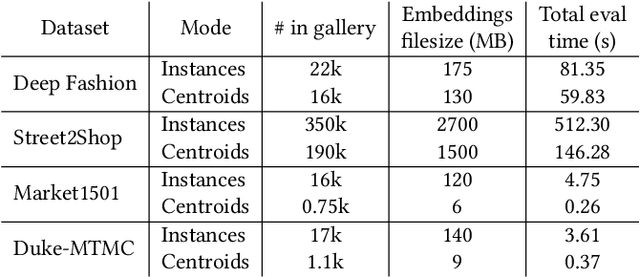
Image retrieval task consists of finding similar images to a query image from a set of gallery (database) images. Such systems are used in various applications e.g. person re-identification (ReID) or visual product search. Despite active development of retrieval models it still remains a challenging task mainly due to large intra-class variance caused by changes in view angle, lighting, background clutter or occlusion, while inter-class variance may be relatively low. A large portion of current research focuses on creating more robust features and modifying objective functions, usually based on Triplet Loss. Some works experiment with using centroid/proxy representation of a class to alleviate problems with computing speed and hard samples mining used with Triplet Loss. However, these approaches are used for training alone and discarded during the retrieval stage. In this paper we propose to use the mean centroid representation both during training and retrieval. Such an aggregated representation is more robust to outliers and assures more stable features. As each class is represented by a single embedding - the class centroid - both retrieval time and storage requirements are reduced significantly. Aggregating multiple embeddings results in a significant reduction of the search space due to lowering the number of candidate target vectors, which makes the method especially suitable for production deployments. Comprehensive experiments conducted on two ReID and Fashion Retrieval datasets demonstrate effectiveness of our method, which outperforms the current state-of-the-art. We propose centroid training and retrieval as a viable method for both Fashion Retrieval and ReID applications.