 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning representations for multivariate time series with missing data using Temporal Kernelized Autoencoders
May 09, 2018
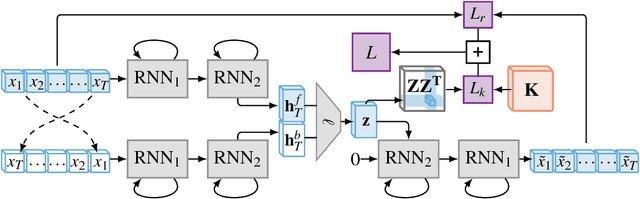
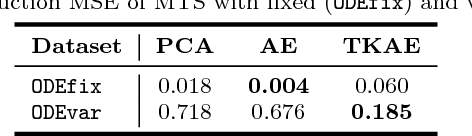
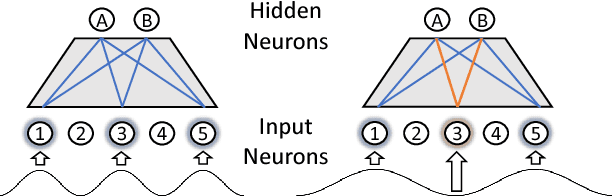
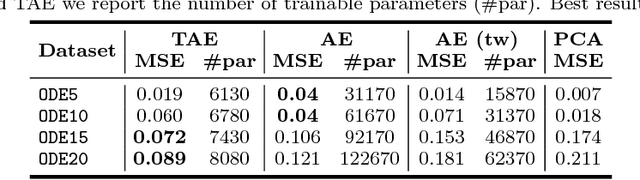
Learning compressed representations of multivariate time series (MTS) facilitate the analysis and process of the data in presence of noise, redundant information, and large amount of variables and time steps. However, classic dimensionality reduction approaches are not designed to process sequential data, especially in the presence of missing values. In this work, we propose a novel autoencoder architecture based on recurrent neural networks to generate compressed representations of MTS, which may contain missing values and have variable lengths. Our autoencoder learns fixed-length vectorial representations, whose pairwise similarities are aligned with a kernel function that operates in input space and handles missing values. This, allows to preserve relationships in the low-dimensional vector space even in presence of missing values. To highlight the main features of the proposed autoencoder, we first investigate its performance in controlled experiments. Successively, we show how the learned representations can be exploited both in several benchmark and real-world classification tasks on medical data. Finally, based on the proposed architecture, we conceive a framework for one-class classification and imputation of missing data in time series extracted from ECG signals.
Privacy-Preserving Federated Depression Detection from Multi-Source Mobile Health Data
Mar 07, 2021
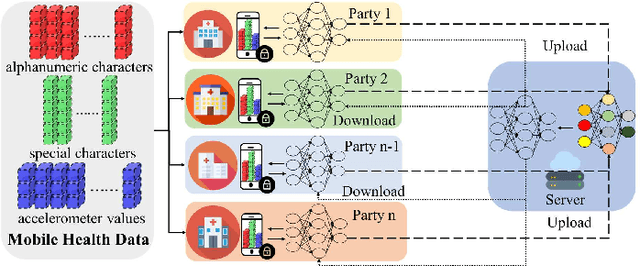
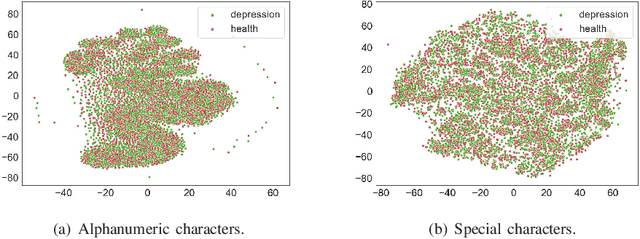
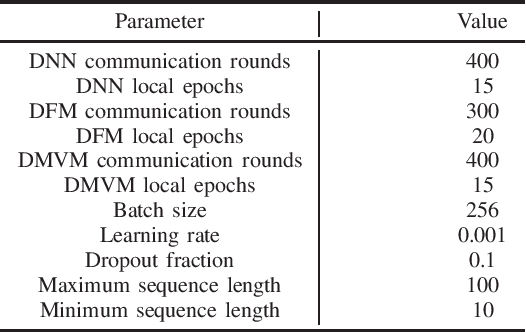
Depression is one of the most common mental illness problems, and the symptoms shown by patients are not consistent, making it difficult to diagnose in the process of clinical practice and pathological research.Although researchers hope that artificial intelligence can contribute to the diagnosis and treatment of depression, the traditional centralized machine learning needs to aggregate patient data, and the data privacy of patients with mental illness needs to be strictly confidential, which hinders machine learning algorithms clinical application.To solve the problem of privacy of the medical history of patients with depression, we implement federated learning to analyze and diagnose depression. First, we propose a general multi-view federated learning framework using multi-source data,which can extend any traditional machine learning model to support federated learning across different institutions or parties.Secondly, we adopt late fusion methods to solve the problem of inconsistent time series of multi-view data.Finally, we compare the federated framework with other cooperative learning frameworks in performance and discuss the related results.
SuperDeConFuse: A Supervised Deep Convolutional Transform based Fusion Framework for Financial Trading Systems
Nov 09, 2020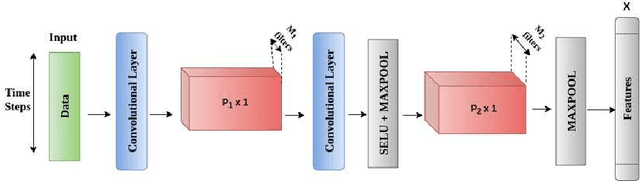
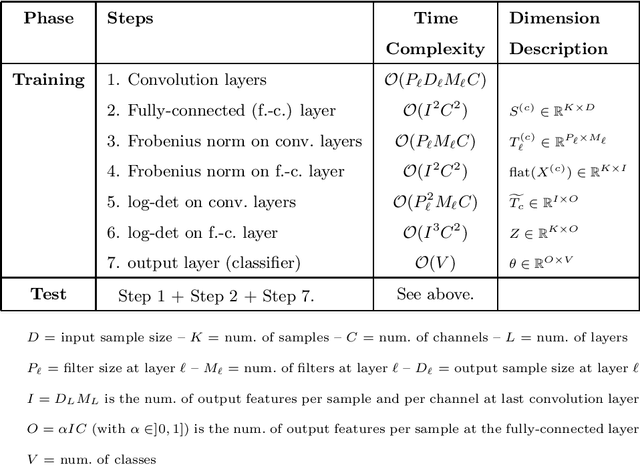
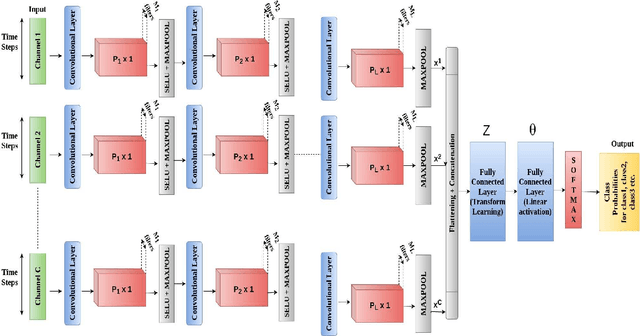
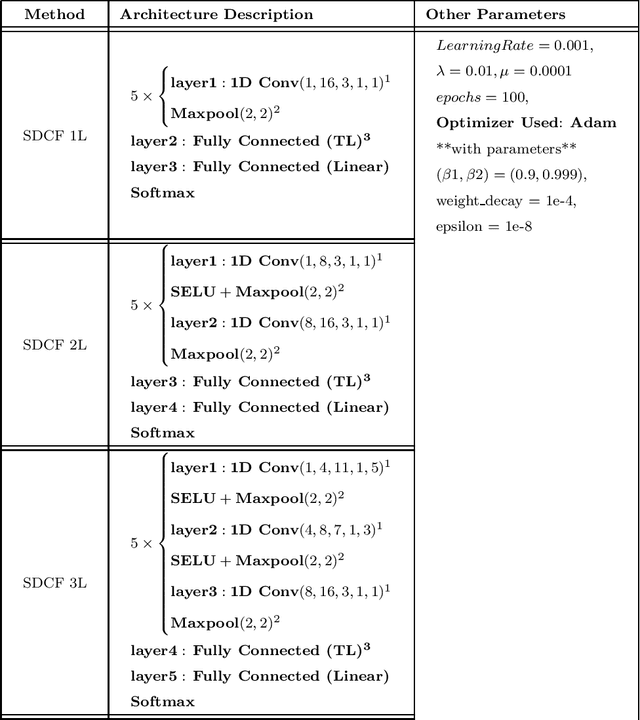
This work proposes a supervised multi-channel time-series learning framework for financial stock trading. Although many deep learning models have recently been proposed in this domain, most of them treat the stock trading time-series data as 2-D image data, whereas its true nature is 1-D time-series data. Since the stock trading systems are multi-channel data, many existing techniques treating them as 1-D time-series data are not suggestive of any technique to effectively fusion the information carried by the multiple channels. To contribute towards both of these shortcomings, we propose an end-to-end supervised learning framework inspired by the previously established (unsupervised) convolution transform learning framework. Our approach consists of processing the data channels through separate 1-D convolution layers, then fusing the outputs with a series of fully-connected layers, and finally applying a softmax classification layer. The peculiarity of our framework - SuperDeConFuse (SDCF), is that we remove the nonlinear activation located between the multi-channel convolution layers and the fully-connected layers, as well as the one located between the latter and the output layer. We compensate for this removal by introducing a suitable regularization on the aforementioned layer outputs and filters during the training phase. Specifically, we apply a logarithm determinant regularization on the layer filters to break symmetry and force diversity in the learnt transforms, whereas we enforce the non-negativity constraint on the layer outputs to mitigate the issue of dead neurons. This results in the effective learning of a richer set of features and filters with respect to a standard convolutional neural network. Numerical experiments confirm that the proposed model yields considerably better results than state-of-the-art deep learning techniques for real-world problem of stock trading.
Voluntary safety commitments provide an escape from over-regulation in AI development
Apr 08, 2021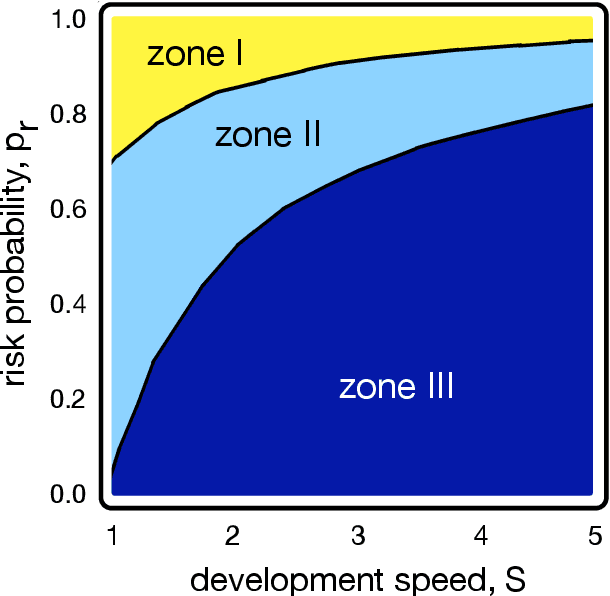
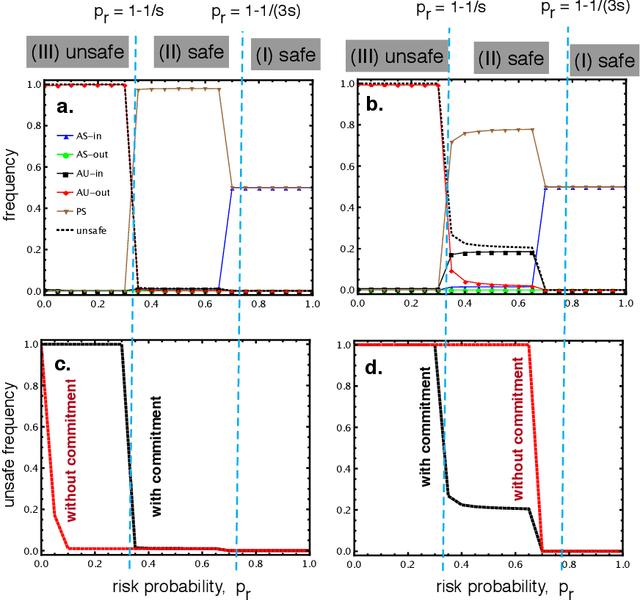
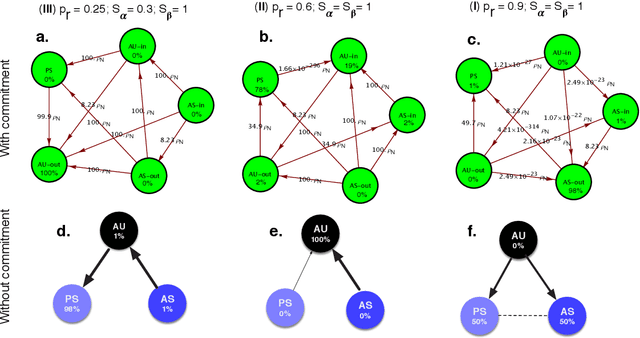
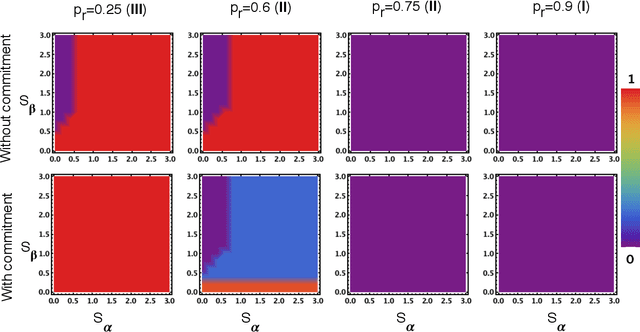
With the introduction of Artificial Intelligence (AI) and related technologies in our daily lives, fear and anxiety about their misuse as well as the hidden biases in their creation have led to a demand for regulation to address such issues. Yet blindly regulating an innovation process that is not well understood, may stifle this process and reduce benefits that society may gain from the generated technology, even under the best intentions. In this paper, starting from a baseline model that captures the fundamental dynamics of a race for domain supremacy using AI technology, we demonstrate how socially unwanted outcomes may be produced when sanctioning is applied unconditionally to risk-taking, i.e. potentially unsafe, behaviours. As an alternative to resolve the detrimental effect of over-regulation, we propose a voluntary commitment approach wherein technologists have the freedom of choice between independently pursuing their course of actions or establishing binding agreements to act safely, with sanctioning of those that do not abide to what they pledged. Overall, this work reveals for the first time how voluntary commitments, with sanctions either by peers or an institution, leads to socially beneficial outcomes in all scenarios envisageable in a short-term race towards domain supremacy through AI technology. These results are directly relevant for the design of governance and regulatory policies that aim to ensure an ethical and responsible AI technology development process.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 14, 2021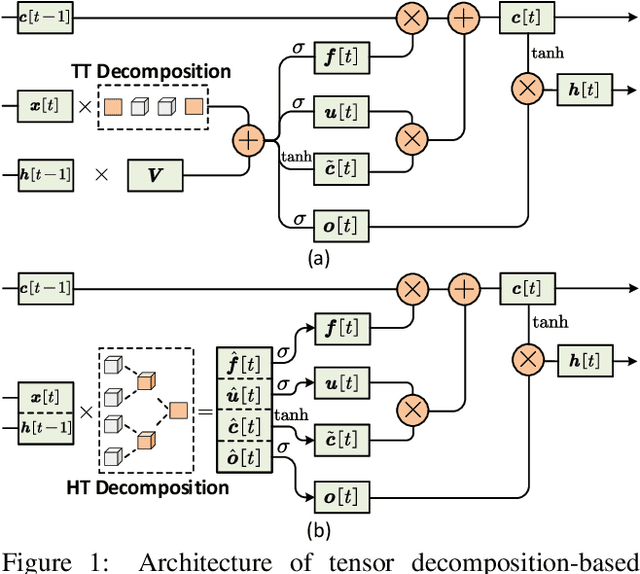
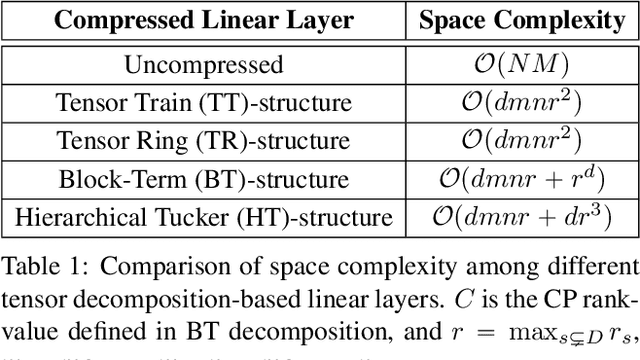
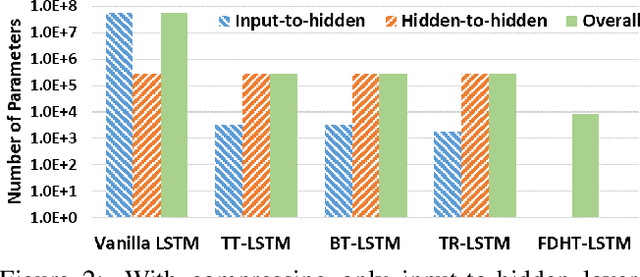
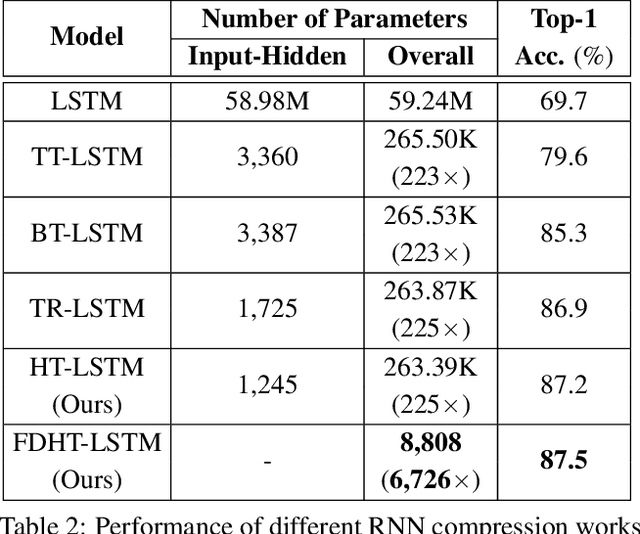
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Target Transformed Regression for Accurate Tracking
Apr 01, 2021
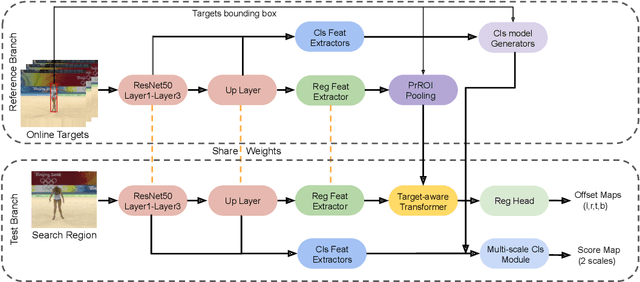
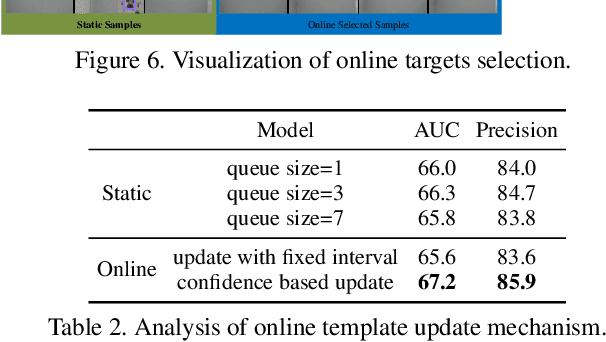
Accurate tracking is still a challenging task due to appearance variations, pose and view changes, and geometric deformations of target in videos. Recent anchor-free trackers provide an efficient regression mechanism but fail to produce precise bounding box estimation. To address these issues, this paper repurposes a Transformer-alike regression branch, termed as Target Transformed Regression (TREG), for accurate anchor-free tracking. The core to our TREG is to model pair-wise relation between elements in target template and search region, and use the resulted target enhanced visual representation for accurate bounding box regression. This target contextualized representation is able to enhance the target relevant information to help precisely locate the box boundaries, and deal with the object deformation to some extent due to its local and dense matching mechanism. In addition, we devise a simple online template update mechanism to select reliable templates, increasing the robustness for appearance variations and geometric deformations of target in time. Experimental results on visual tracking benchmarks including VOT2018, VOT2019, OTB100, GOT10k, NFS, UAV123, LaSOT and TrackingNet demonstrate that TREG obtains the state-of-the-art performance, achieving a success rate of 0.640 on LaSOT, while running at around 30 FPS. The code and models will be made available at https://github.com/MCG-NJU/TREG.
CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
Mar 24, 2021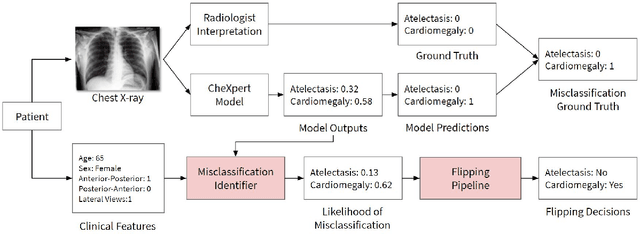
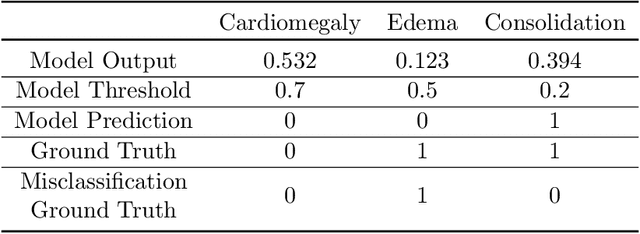
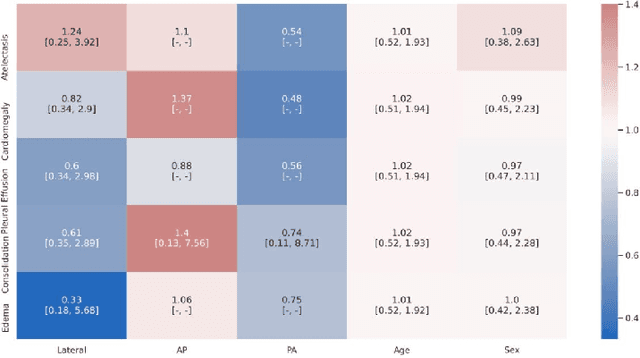
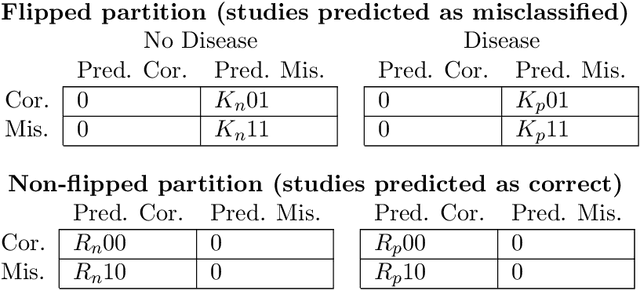
A major obstacle to the integration of deep learning models for chest x-ray interpretation into clinical settings is the lack of understanding of their failure modes. In this work, we first investigate whether there are patient subgroups that chest x-ray models are likely to misclassify. We find that patient age and the radiographic finding of lung lesion, pneumothorax or support devices are statistically relevant features for predicting misclassification for some chest x-ray models. Second, we develop misclassification predictors on chest x-ray models using their outputs and clinical features. We find that our best performing misclassification identifier achieves an AUROC close to 0.9 for most diseases. Third, employing our misclassification identifiers, we develop a corrective algorithm to selectively flip model predictions that have high likelihood of misclassification at inference time. We observe F1 improvement on the prediction of Consolidation (0.008 [95\% CI 0.005, 0.010]) and Edema (0.003, [95\% CI 0.001, 0.006]). By carrying out our investigation on ten distinct and high-performing chest x-ray models, we are able to derive insights across model architectures and offer a generalizable framework applicable to other medical imaging tasks.
Fast IR Drop Estimation with Machine Learning
Nov 26, 2020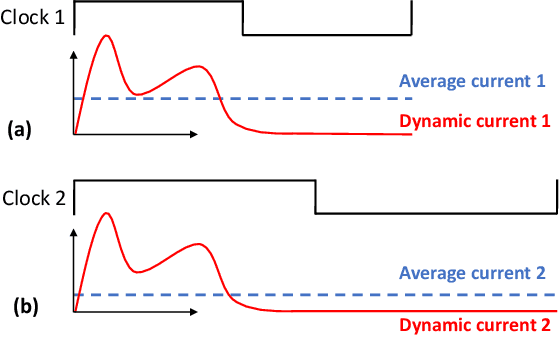
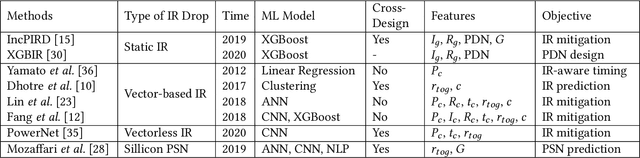
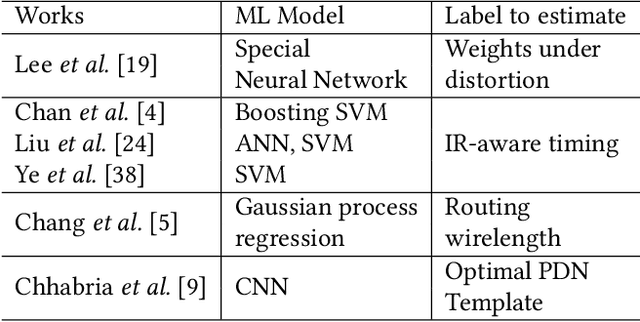

IR drop constraint is a fundamental requirement enforced in almost all chip designs. However, its evaluation takes a long time, and mitigation techniques for fixing violations may require numerous iterations. As such, fast and accurate IR drop prediction becomes critical for reducing design turnaround time. Recently, machine learning (ML) techniques have been actively studied for fast IR drop estimation due to their promise and success in many fields. These studies target at various design stages with different emphasis, and accordingly, different ML algorithms are adopted and customized. This paper provides a review to the latest progress in ML-based IR drop estimation techniques. It also serves as a vehicle for discussing some general challenges faced by ML applications in electronics design automation (EDA), and demonstrating how to integrate ML models with conventional techniques for the better efficiency of EDA tools.
A Framework for 3D Tracking of Frontal Dynamic Objects in Autonomous Cars
Mar 24, 2021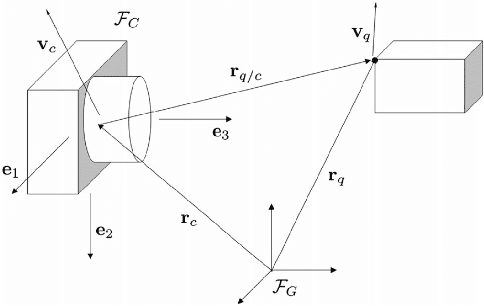

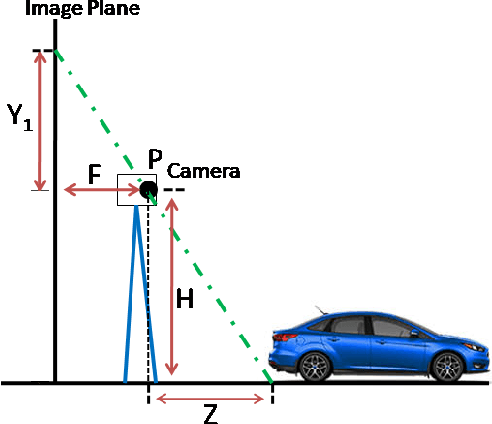
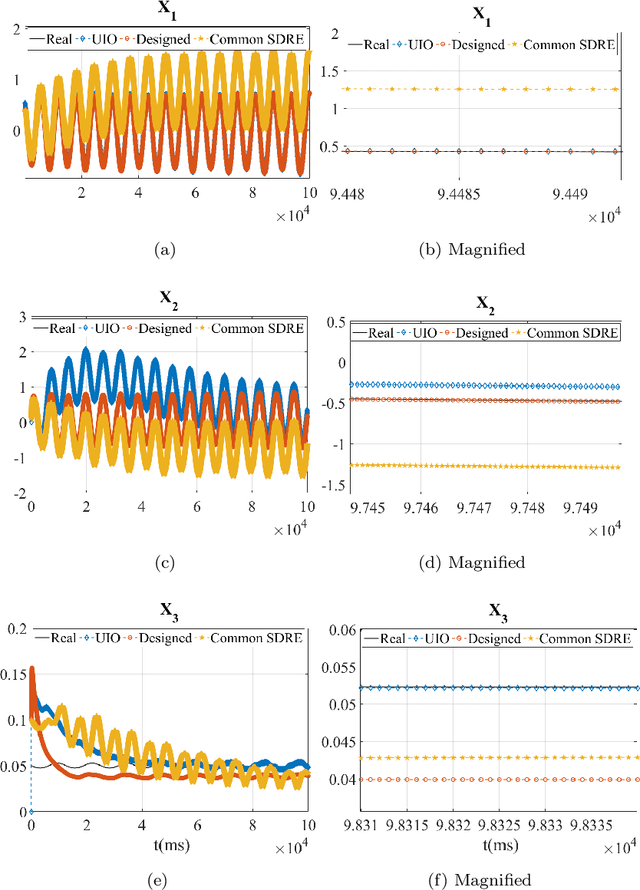
Both recognition and 3D tracking of frontal dynamic objects are crucial problems in an autonomous vehicle, while depth estimation as an essential issue becomes a challenging problem using a monocular camera. Since both camera and objects are moving, the issue can be formed as a structure from motion (SFM) problem. In this paper, to elicit features from an image, the YOLOv3 approach is utilized beside an OpenCV tracker. Subsequently, to obtain the lateral and longitudinal distances, a nonlinear SFM model is considered alongside a state-dependent Riccati equation (SDRE) filter and a newly developed observation model. Additionally, a switching method in the form of switching estimation error covariance is proposed to enhance the robust performance of the SDRE filter. The stability analysis of the presented filter is conducted on a class of discrete nonlinear systems. Furthermore, the ultimate bound of estimation error caused by model uncertainties is analytically obtained to investigate the switching significance. Simulations are reported to validate the performance of the switched SDRE filter. Finally, real-time experiments are performed through a multi-thread framework implemented on a Jetson TX2 board, while radar data is used for the evaluation.
TrajeVAE -- Controllable Human Motion Generation from Trajectories
Apr 01, 2021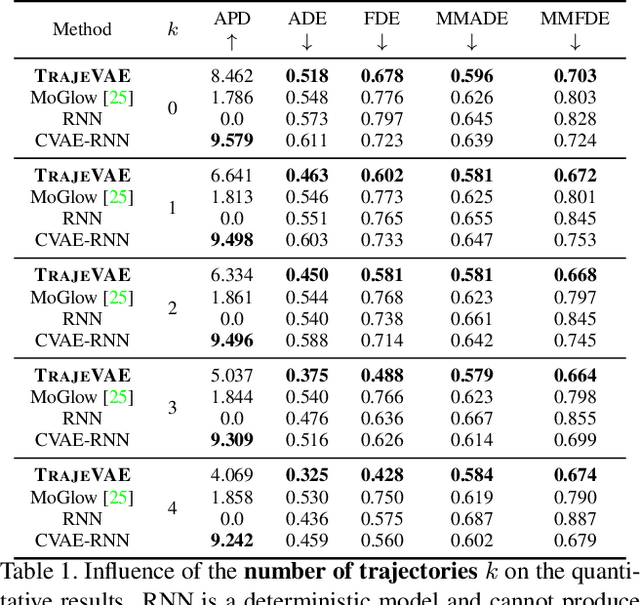
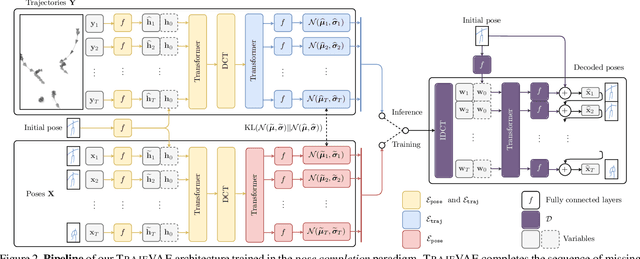
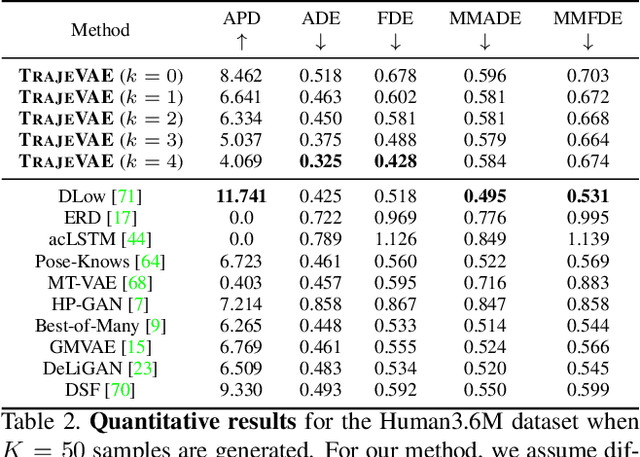
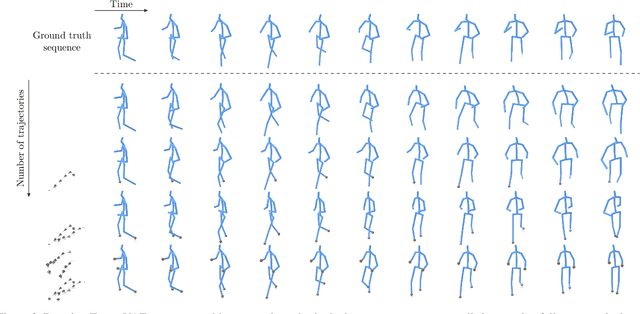
The generation of plausible and controllable 3D human motion animations is a long-standing problem that often requires a manual intervention of skilled artists. Existing machine learning approaches try to semi-automate this process by allowing the user to input partial information about the future movement. However, they are limited in two significant ways: they either base their pose prediction on past prior frames with no additional control over the future poses or allow the user to input only a single trajectory that precludes fine-grained control over the output. To mitigate these two issues, we reformulate the problem of future pose prediction into pose completion in space and time where trajectories are represented as poses with missing joints. We show that such a framework can generalize to other neural networks designed for future pose prediction. Once trained in this framework, a model is capable of predicting sequences from any number of trajectories. To leverage this notion, we propose a novel transformer-like architecture, TrajeVAE, that provides a versatile framework for 3D human animation. We demonstrate that TrajeVAE outperforms trajectory-based reference approaches and methods that base their predictions on past poses in terms of accuracy. We also show that it can predict reasonable future poses even if provided only with an initial pose.