 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HyperDynamics: Meta-Learning Object and Agent Dynamics with Hypernetworks
Mar 17, 2021
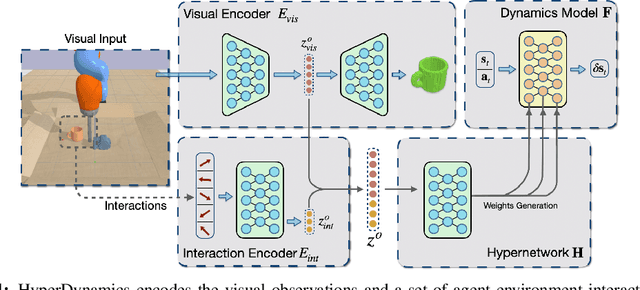
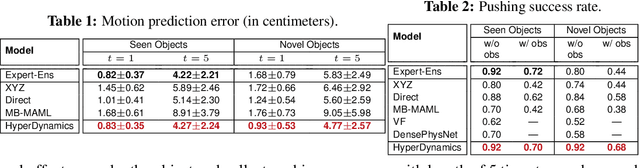

We propose HyperDynamics, a dynamics meta-learning framework that conditions on an agent's interactions with the environment and optionally its visual observations, and generates the parameters of neural dynamics models based on inferred properties of the dynamical system. Physical and visual properties of the environment that are not part of the low-dimensional state yet affect its temporal dynamics are inferred from the interaction history and visual observations, and are implicitly captured in the generated parameters. We test HyperDynamics on a set of object pushing and locomotion tasks. It outperforms existing dynamics models in the literature that adapt to environment variations by learning dynamics over high dimensional visual observations, capturing the interactions of the agent in recurrent state representations, or using gradient-based meta-optimization. We also show our method matches the performance of an ensemble of separately trained experts, while also being able to generalize well to unseen environment variations at test time. We attribute its good performance to the multiplicative interactions between the inferred system properties -- captured in the generated parameters -- and the low-dimensional state representation of the dynamical system.
Gradient Descent Can Take Exponential Time to Escape Saddle Points
Nov 05, 2017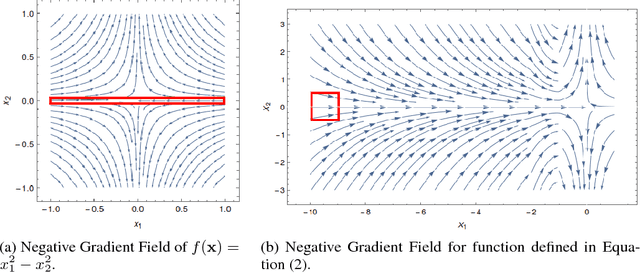
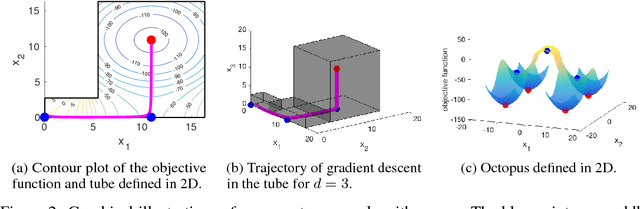
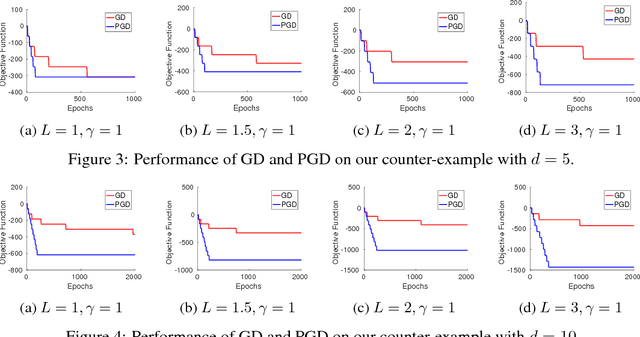
Although gradient descent (GD) almost always escapes saddle points asymptotically [Lee et al., 2016], this paper shows that even with fairly natural random initialization schemes and non-pathological functions, GD can be significantly slowed down by saddle points, taking exponential time to escape. On the other hand, gradient descent with perturbations [Ge et al., 2015, Jin et al., 2017] is not slowed down by saddle points - it can find an approximate local minimizer in polynomial time. This result implies that GD is inherently slower than perturbed GD, and justifies the importance of adding perturbations for efficient non-convex optimization. While our focus is theoretical, we also present experiments that illustrate our theoretical findings.
Perspective, Survey and Trends: Public Driving Datasets and Toolsets for Autonomous Driving Virtual Test
Apr 02, 2021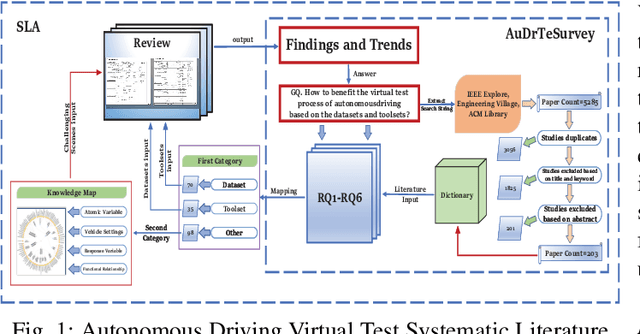
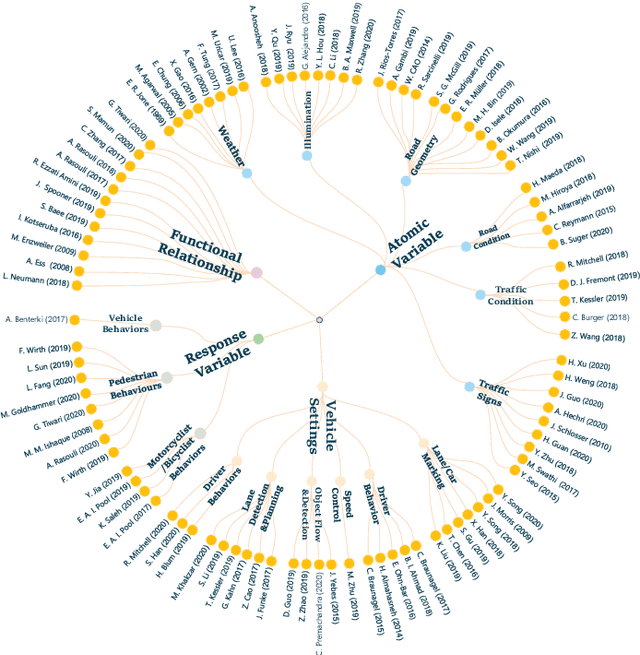
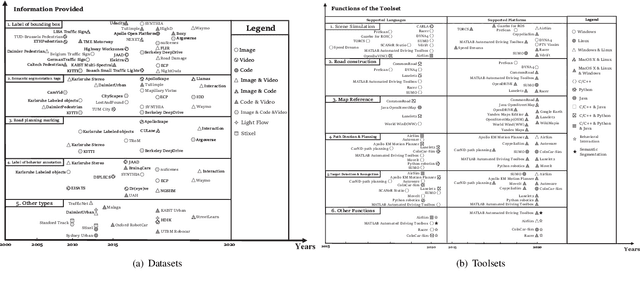
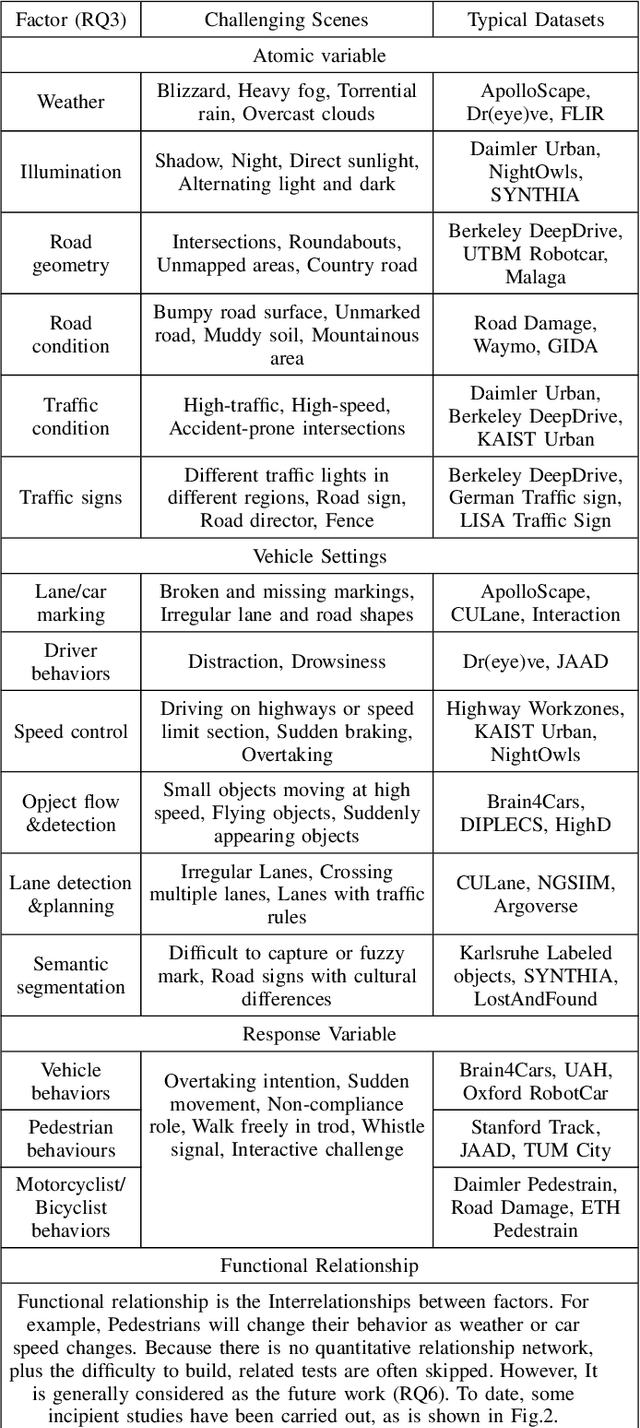
Owing to the merits of early safety and reliability guarantee, autonomous driving virtual testing has recently gains increasing attention compared with closed-loop testing in real scenarios. Although the availability and quality of autonomous driving datasets and toolsets are the premise to diagnose the autonomous driving system bottlenecks and improve the system performance, due to the diversity and privacy of the datasets and toolsets, collecting and featuring the perspective and quality of them become not only time-consuming but also increasingly challenging. This paper first proposes a Systematic Literature Review (SLR) approach for autonomous driving tests, then presents an overview of existing publicly available datasets and toolsets from 2000 to 2020. Quantitative findings with the scenarios concerned, perspectives and trend inferences and suggestions with 35 automated driving test tool sets and 70 test data sets are also presented. To the best of our knowledge, we are the first to perform such recent empirical survey on both the datasets and toolsets using a SLA based survey approach. Our multifaceted analyses and new findings not only reveal insights that we believe are useful for system designers, practitioners and users, but also can promote more researches on a systematic survey analysis in autonomous driving surveys on dataset and toolsets.
Interpreting intermediate convolutional layers of CNNs trained on raw speech
Apr 21, 2021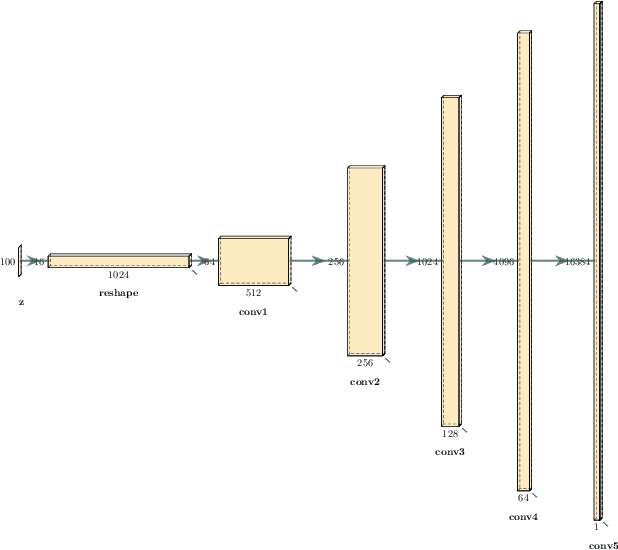
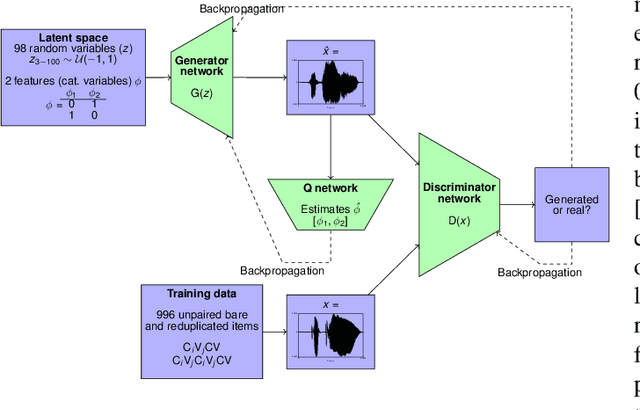
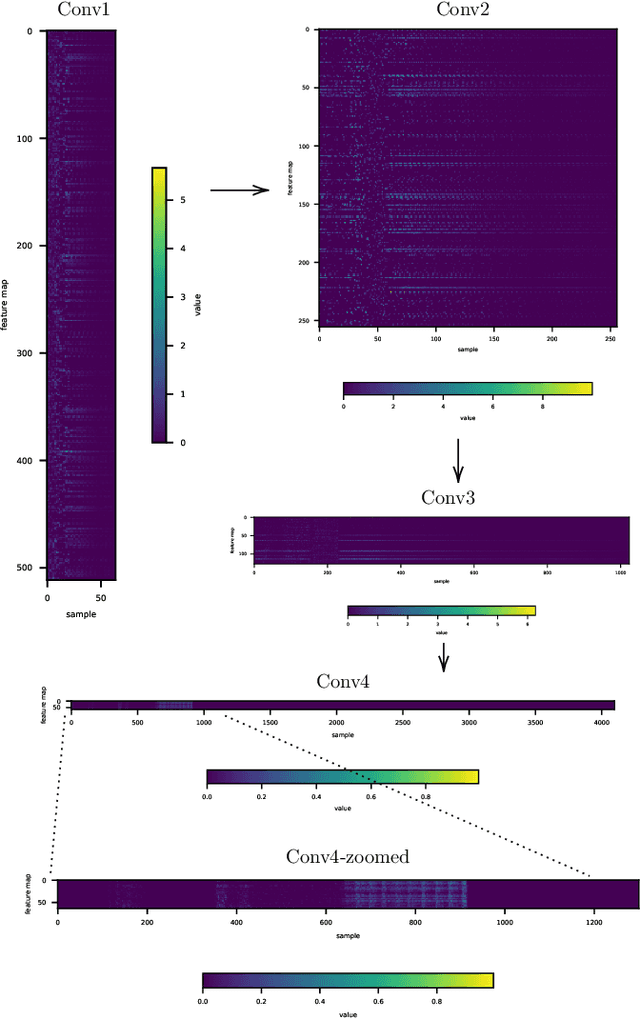
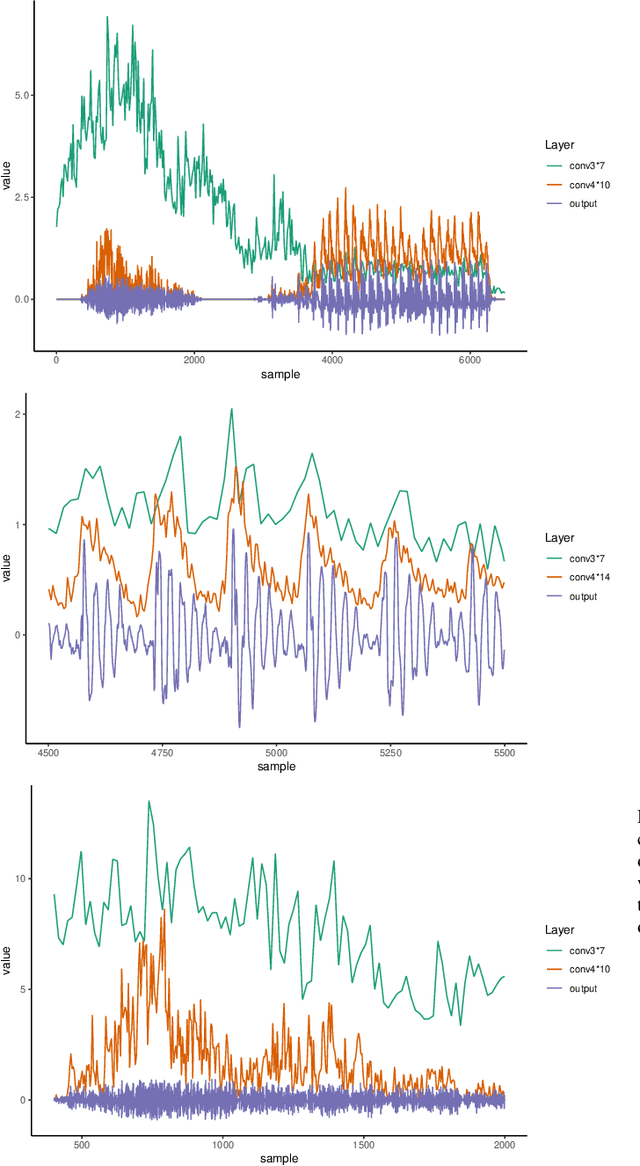
This paper presents a technique to interpret and visualize intermediate layers in CNNs trained on raw speech data in an unsupervised manner. We show that averaging over feature maps after ReLU activation in each convolutional layer yields interpretable time-series data. The proposed technique enables acoustic analysis of intermediate convolutional layers. To uncover how meaningful representation in speech gets encoded in intermediate layers of CNNs, we manipulate individual latent variables to marginal levels outside of the training range. We train and probe internal representations on two models -- a bare WaveGAN architecture and a ciwGAN extension which forces the Generator to output informative data and results in emergence of linguistically meaningful representations. Interpretation and visualization is performed for three basic acoustic properties of speech: periodic vibration (corresponding to vowels), aperiodic noise vibration (corresponding to fricatives), and silence (corresponding to stops). We also argue that the proposed technique allows acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information. The models are trained on two speech processes with different degrees of complexity: a simple presence of [s] and a computationally complex presence of reduplication (copied material). Observing the causal effect between interpolation and the resulting changes in intermediate layers can reveal how individual variables get transformed into spikes in activation in intermediate layers. Using the proposed technique, we can analyze how linguistically meaningful units in speech get encoded in different convolutional layers.
Fast IR Drop Estimation with Machine Learning
Nov 26, 2020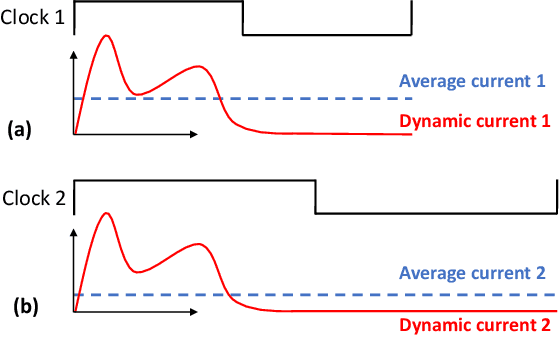
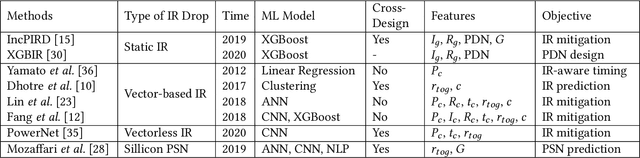
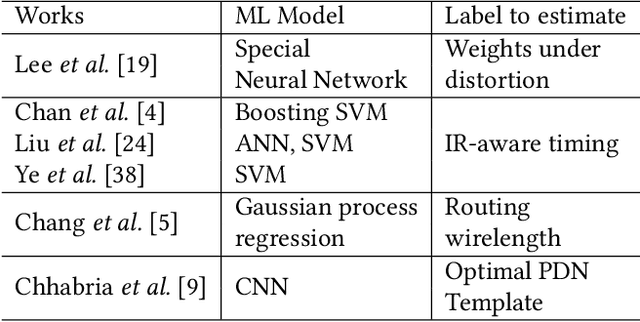

IR drop constraint is a fundamental requirement enforced in almost all chip designs. However, its evaluation takes a long time, and mitigation techniques for fixing violations may require numerous iterations. As such, fast and accurate IR drop prediction becomes critical for reducing design turnaround time. Recently, machine learning (ML) techniques have been actively studied for fast IR drop estimation due to their promise and success in many fields. These studies target at various design stages with different emphasis, and accordingly, different ML algorithms are adopted and customized. This paper provides a review to the latest progress in ML-based IR drop estimation techniques. It also serves as a vehicle for discussing some general challenges faced by ML applications in electronics design automation (EDA), and demonstrating how to integrate ML models with conventional techniques for the better efficiency of EDA tools.
Rethinking Automatic Evaluation in Sentence Simplification
Apr 15, 2021
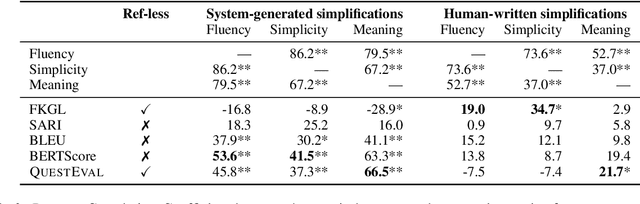
Automatic evaluation remains an open research question in Natural Language Generation. In the context of Sentence Simplification, this is particularly challenging: the task requires by nature to replace complex words with simpler ones that shares the same meaning. This limits the effectiveness of n-gram based metrics like BLEU. Going hand in hand with the recent advances in NLG, new metrics have been proposed, such as BERTScore for Machine Translation. In summarization, the QuestEval metric proposes to automatically compare two texts by questioning them. In this paper, we first propose a simple modification of QuestEval allowing it to tackle Sentence Simplification. We then extensively evaluate the correlations w.r.t. human judgement for several metrics including the recent BERTScore and QuestEval, and show that the latter obtain state-of-the-art correlations, outperforming standard metrics like BLEU and SARI. More importantly, we also show that a large part of the correlations are actually spurious for all the metrics. To investigate this phenomenon further, we release a new corpus of evaluated simplifications, this time not generated by systems but instead, written by humans. This allows us to remove the spurious correlations and draw very different conclusions from the original ones, resulting in a better understanding of these metrics. In particular, we raise concerns about very low correlations for most of traditional metrics. Our results show that the only significant measure of the Meaning Preservation is our adaptation of QuestEval.
Deep Dynamic Neural Network to trade-off between Accuracy and Diversity in a News Recommender System
Mar 17, 2021
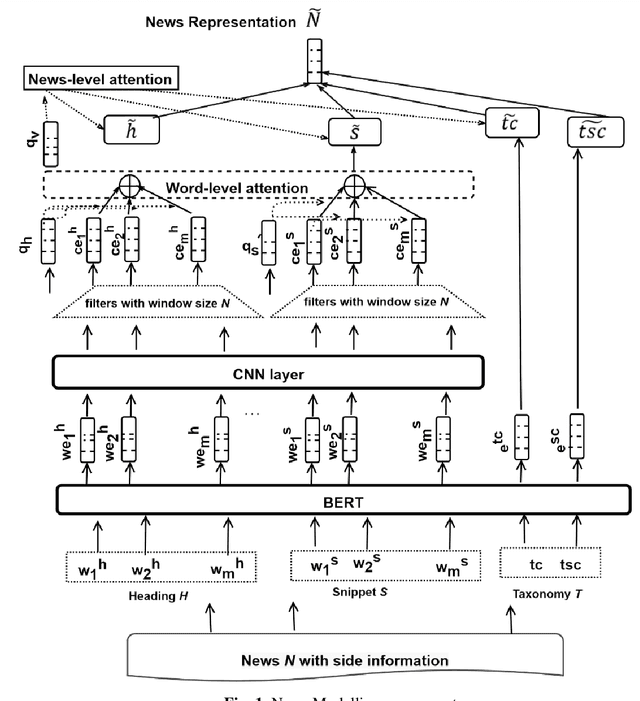
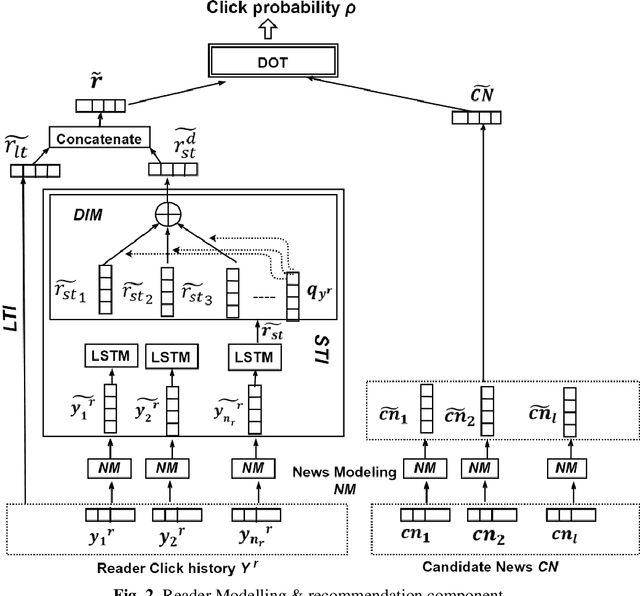
The news recommender systems are marked by a few unique challenges specific to the news domain. These challenges emerge from rapidly evolving readers' interests over dynamically generated news items that continuously change over time. News reading is also driven by a blend of a reader's long-term and short-term interests. In addition, diversity is required in a news recommender system, not only to keep the reader engaged in the reading process but to get them exposed to different views and opinions. In this paper, we propose a deep neural network that jointly learns informative news and readers' interests into a unified framework. We learn the news representation (features) from the headlines, snippets (body) and taxonomy (category, subcategory) of news. We learn a reader's long-term interests from the reader's click history, short-term interests from the recent clicks via LSTMSs and the diversified reader's interests through the attention mechanism. We also apply different levels of attention to our model. We conduct extensive experiments on two news datasets to demonstrate the effectiveness of our approach.
Actuator Fault-Tolerant Vehicle Motion Control: A Survey
Mar 25, 2021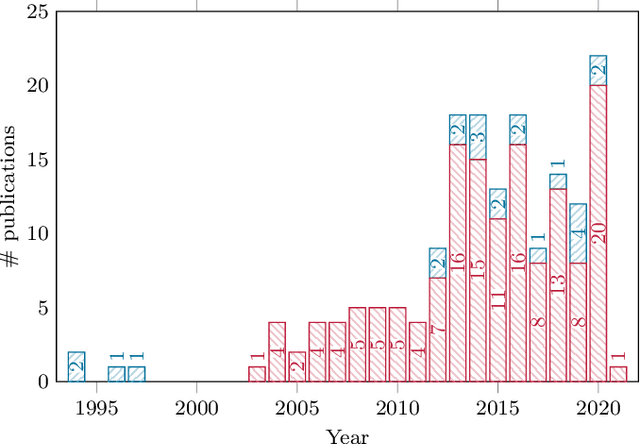
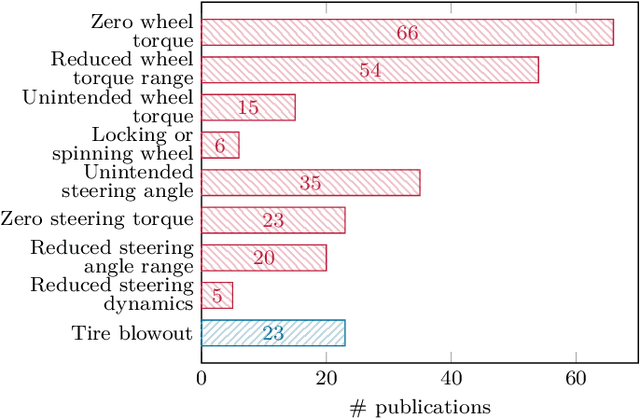
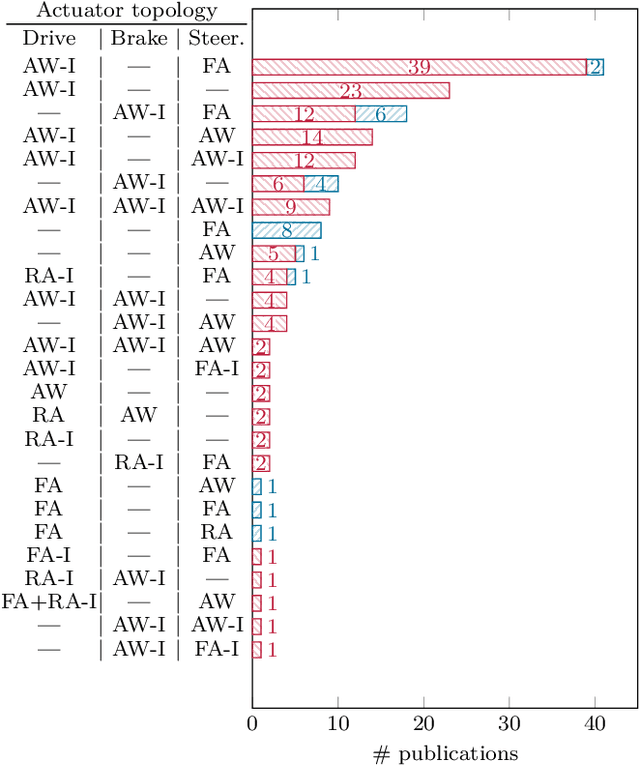
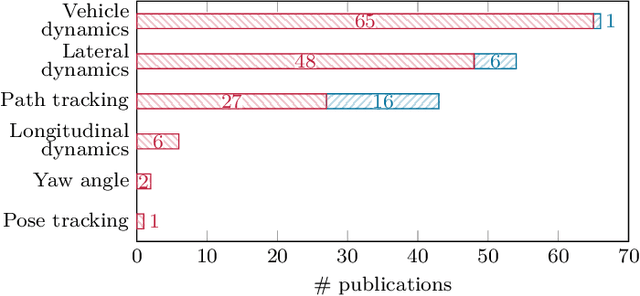
The advent of automated vehicles operating at SAE levels 4 and 5 poses high fault tolerance demands for all functions contributing to the driving task. At the actuator level, fault-tolerant vehicle motion control, which exploits functional redundancies among the actuators, is one means to achieve the required degree of fault tolerance. Therefore, we give a comprehensive overview of the state of the art in actuator fault-tolerant vehicle motion control with a focus on drive, brake, and steering degradations, as well as tire blowouts. This review shows that actuator fault-tolerant vehicle motion is a widely studied field; yet, the presented approaches differ with respect to many aspects. To provide a starting point for future research, we survey the employed actuator topologies, the tolerated degradations, the presented control approaches, as well as the experiments conducted for validation. Overall, and despite the large number of different approaches, the covered literature reveals the potential of increasing fault tolerance by fault-tolerant vehicle motion control. Thus, besides developing novel approaches or demonstrating real-time applicability, future research should aim at investigating limitations and enabling comparison of fault-tolerant motion control approaches in order to allow for a thorough safety argumentation.
Estimation with Low-Rank Time-Frequency Synthesis Models
Jun 29, 2018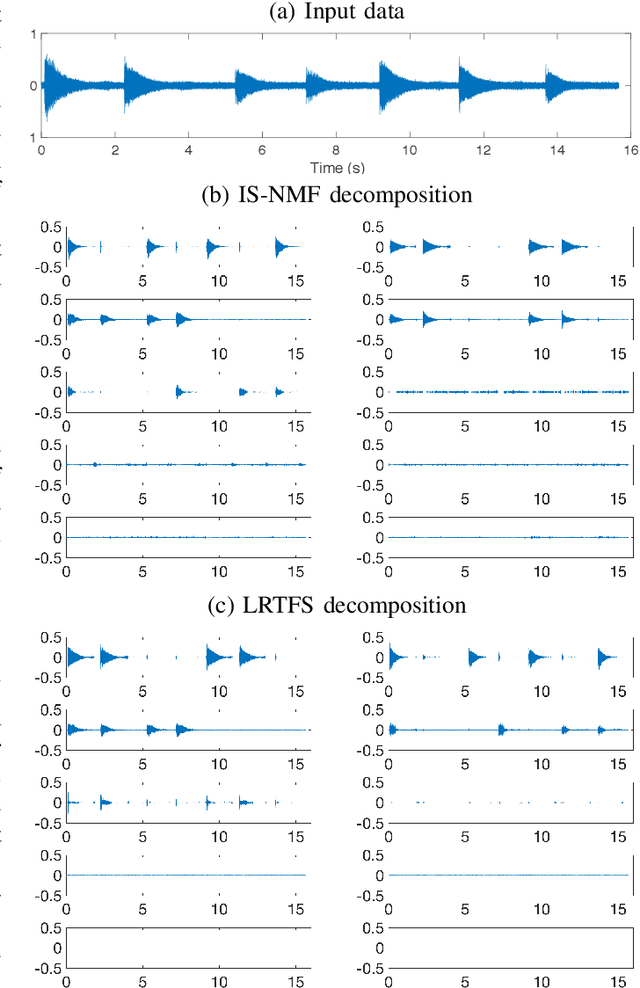
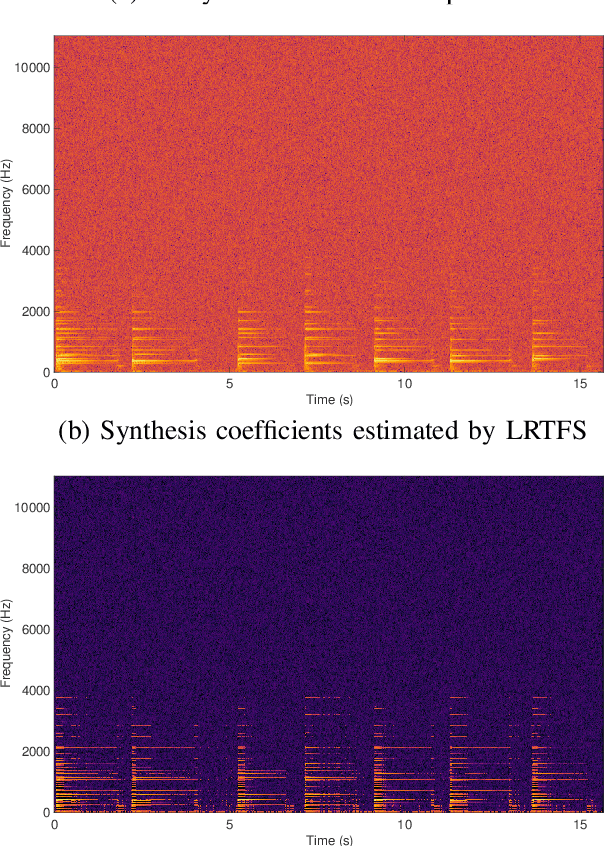
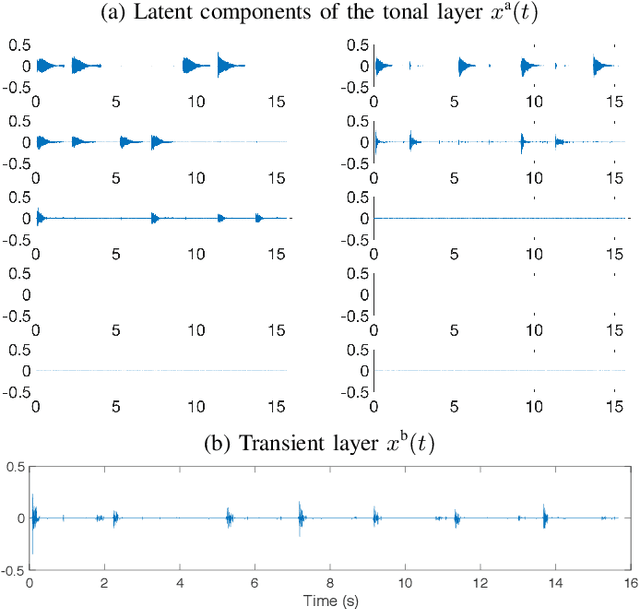
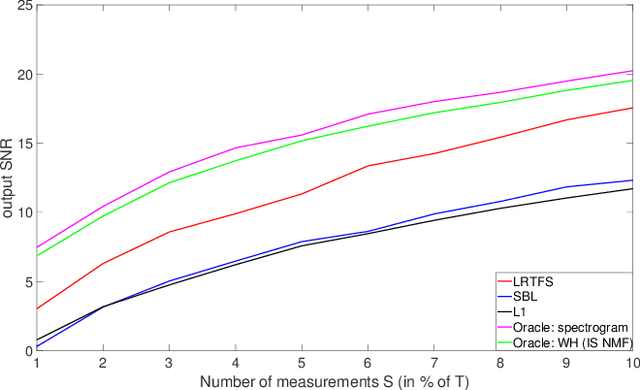
Many state-of-the-art signal decomposition techniques rely on a low-rank factorization of a time-frequency (t-f) transform. In particular, nonnegative matrix factorization (NMF) of the spectrogram has been considered in many audio applications. This is an analysis approach in the sense that the factorization is applied to the squared magnitude of the analysis coefficients returned by the t-f transform. In this paper we instead propose a synthesis approach, where low-rankness is imposed to the synthesis coefficients of the data signal over a given t-f dictionary (such as a Gabor frame). As such we offer a novel modeling paradigm that bridges t-f synthesis modeling and traditional analysis-based NMF approaches. The proposed generative model allows in turn to design more sophisticated multi-layer representations that can efficiently capture diverse forms of structure. Additionally, the generative modeling allows to exploit t-f low-rankness for compressive sensing. We present efficient iterative shrinkage algorithms to perform estimation in the proposed models and illustrate the capabilities of the new modeling paradigm over audio signal processing examples.
Photothermal-SR-Net: A Customized Deep Unfolding Neural Network for Photothermal Super Resolution Imaging
Apr 21, 2021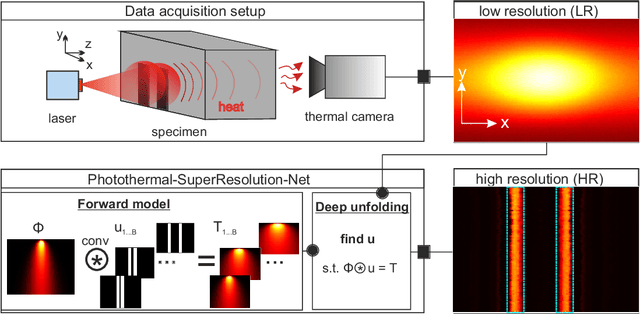

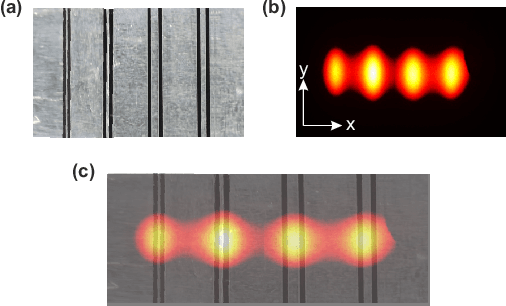
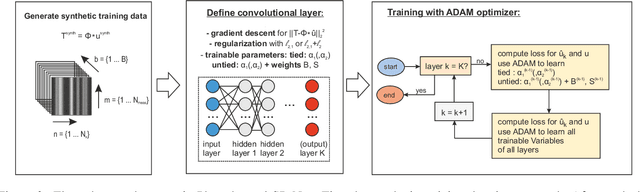
This paper presents deep unfolding neural networks to handle inverse problems in photothermal radiometry enabling super resolution (SR) imaging. Photothermal imaging is a well-known technique in active thermography for nondestructive inspection of defects in materials such as metals or composites. A grand challenge of active thermography is to overcome the spatial resolution limitation imposed by heat diffusion in order to accurately resolve each defect. The photothermal SR approach enables to extract high-frequency spatial components based on the deconvolution with the thermal point spread function. However, stable deconvolution can only be achieved by using the sparse structure of defect patterns, which often requires tedious, hand-crafted tuning of hyperparameters and results in computationally intensive algorithms. On this account, Photothermal-SR-Net is proposed in this paper, which performs deconvolution by deep unfolding considering the underlying physics. This enables to super resolve 2D thermal images for nondestructive testing with a substantially improved convergence rate. Since defects appear sparsely in materials, Photothermal-SR-Net applies trained block-sparsity thresholding to the acquired thermal images in each convolutional layer. The performance of the proposed approach is evaluated and discussed using various deep unfolding and thresholding approaches applied to 2D thermal images. Subsequently, studies are conducted on how to increase the reconstruction quality and the computational performance of Photothermal-SR-Net is evaluated. Thereby, it was found that the computing time for creating high-resolution images could be significantly reduced without decreasing the reconstruction quality by using pixel binning as a preprocessing step.