 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Computer methods for 3D motion tracking in real-time
Jul 05, 2017
This thesis is devoted to marker-less 3D human motion tracking in calibrated and synchronized multicamera systems. Pose estimation is based on a 3D model, which is transformed into the image plane and then rendered. Owing to elaborated techniques the tracking of the full body has been achieved in real-time via dynamic optimization or dynamic Bayesian filtering. The objective function of a particle swarm optimization algorithm and the observation model of a particle filter are based on matching between the rendered 3D models in the required poses and image features representing the extracted person. In such an approach the main part of the computational overload is associated with the rendering of 3D models in hypothetical poses as well as determination of value of objective function. Effective methods for rendering of 3D models in real-time with support of OpenGL as well as parallel methods for determining the objective function on the GPU were developed. The elaborated solutions permit 3D tracking of full body motion in real-time.
StressNet: Deep Learning to Predict Stress With Fracture Propagation in Brittle Materials
Nov 20, 2020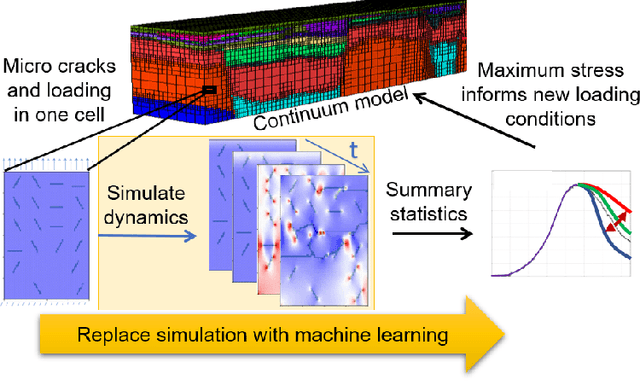

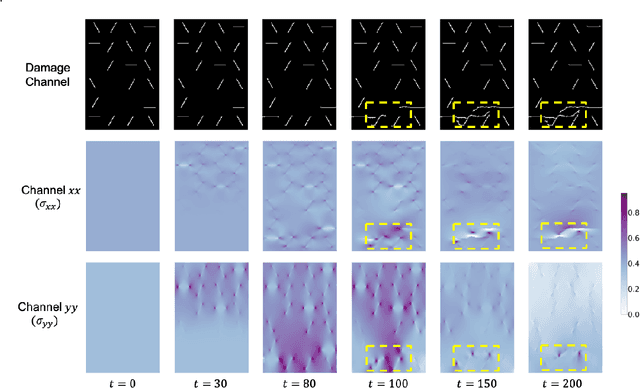

Catastrophic failure in brittle materials is often due to the rapid growth and coalescence of cracks aided by high internal stresses. Hence, accurate prediction of maximum internal stress is critical to predicting time to failure and improving the fracture resistance and reliability of materials. Existing high-fidelity methods, such as the Finite-Discrete Element Model (FDEM), are limited by their high computational cost. Therefore, to reduce computational cost while preserving accuracy, a novel deep learning model, "StressNet," is proposed to predict the entire sequence of maximum internal stress based on fracture propagation and the initial stress data. More specifically, the Temporal Independent Convolutional Neural Network (TI-CNN) is designed to capture the spatial features of fractures like fracture path and spall regions, and the Bidirectional Long Short-term Memory (Bi-LSTM) Network is adapted to capture the temporal features. By fusing these features, the evolution in time of the maximum internal stress can be accurately predicted. Moreover, an adaptive loss function is designed by dynamically integrating the Mean Squared Error (MSE) and the Mean Absolute Percentage Error (MAPE), to reflect the fluctuations in maximum internal stress. After training, the proposed model is able to compute accurate multi-step predictions of maximum internal stress in approximately 20 seconds, as compared to the FDEM run time of 4 hours, with an average MAPE of 2% relative to test data.
Actuator Fault-Tolerant Vehicle Motion Control: A Survey
Mar 25, 2021
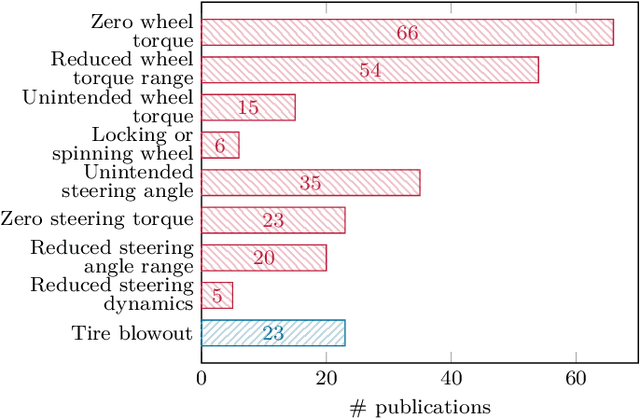
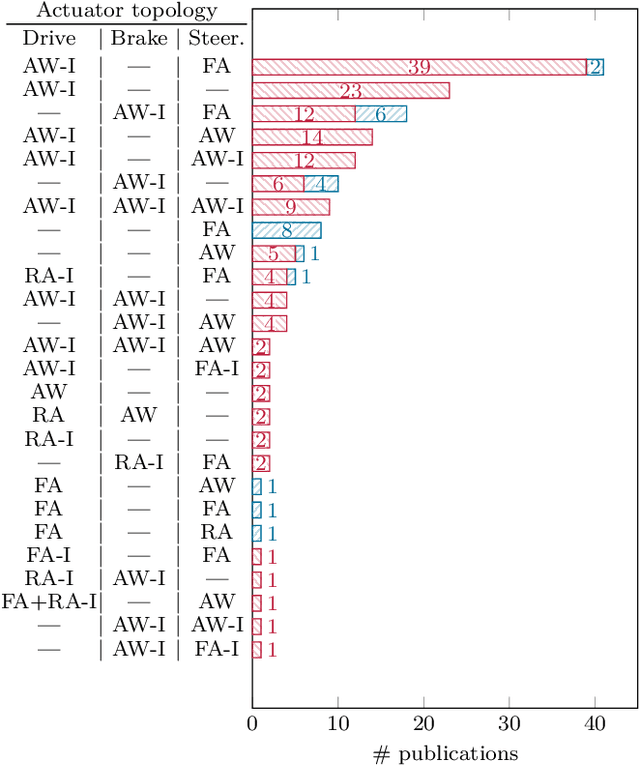
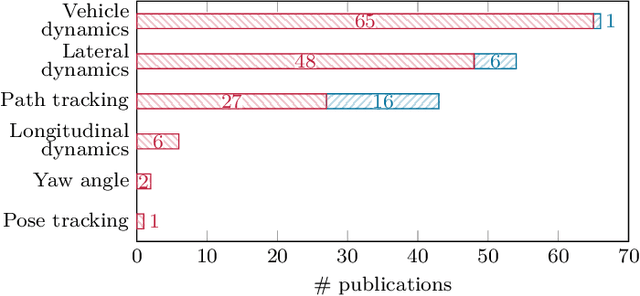
The advent of automated vehicles operating at SAE levels 4 and 5 poses high fault tolerance demands for all functions contributing to the driving task. At the actuator level, fault-tolerant vehicle motion control, which exploits functional redundancies among the actuators, is one means to achieve the required degree of fault tolerance. Therefore, we give a comprehensive overview of the state of the art in actuator fault-tolerant vehicle motion control with a focus on drive, brake, and steering degradations, as well as tire blowouts. This review shows that actuator fault-tolerant vehicle motion is a widely studied field; yet, the presented approaches differ with respect to many aspects. To provide a starting point for future research, we survey the employed actuator topologies, the tolerated degradations, the presented control approaches, as well as the experiments conducted for validation. Overall, and despite the large number of different approaches, the covered literature reveals the potential of increasing fault tolerance by fault-tolerant vehicle motion control. Thus, besides developing novel approaches or demonstrating real-time applicability, future research should aim at investigating limitations and enabling comparison of fault-tolerant motion control approaches in order to allow for a thorough safety argumentation.
Variance-Reduced Off-Policy TDC Learning: Non-Asymptotic Convergence Analysis
Oct 27, 2020


Variance reduction techniques have been successfully applied to temporal-difference (TD) learning and help to improve the sample complexity in policy evaluation. However, the existing work applied variance reduction to either the less popular one time-scale TD algorithm or the two time-scale GTD algorithm but with a finite number of i.i.d.\ samples, and both algorithms apply to only the on-policy setting. In this work, we develop a variance reduction scheme for the two time-scale TDC algorithm in the off-policy setting and analyze its non-asymptotic convergence rate over both i.i.d.\ and Markovian samples. In the i.i.d.\ setting, our algorithm achieves a sample complexity $O(\epsilon^{-\frac{3}{5}} \log{\epsilon}^{-1})$ that is lower than the state-of-the-art result $O(\epsilon^{-1} \log {\epsilon}^{-1})$. In the Markovian setting, our algorithm achieves the state-of-the-art sample complexity $O(\epsilon^{-1} \log {\epsilon}^{-1})$ that is near-optimal. Experiments demonstrate that the proposed variance-reduced TDC achieves a smaller asymptotic convergence error than both the conventional TDC and the variance-reduced TD.
Deep Dynamic Neural Network to trade-off between Accuracy and Diversity in a News Recommender System
Mar 17, 2021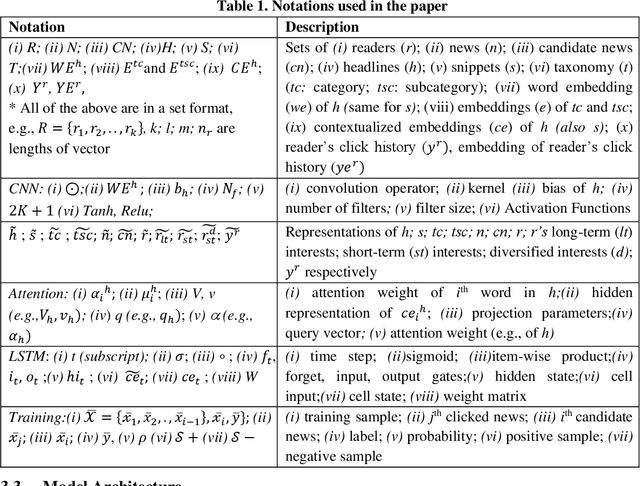
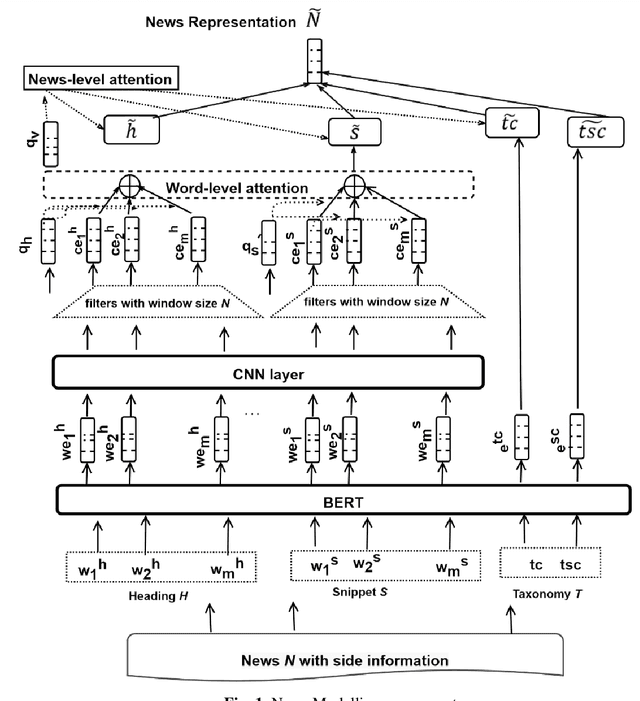
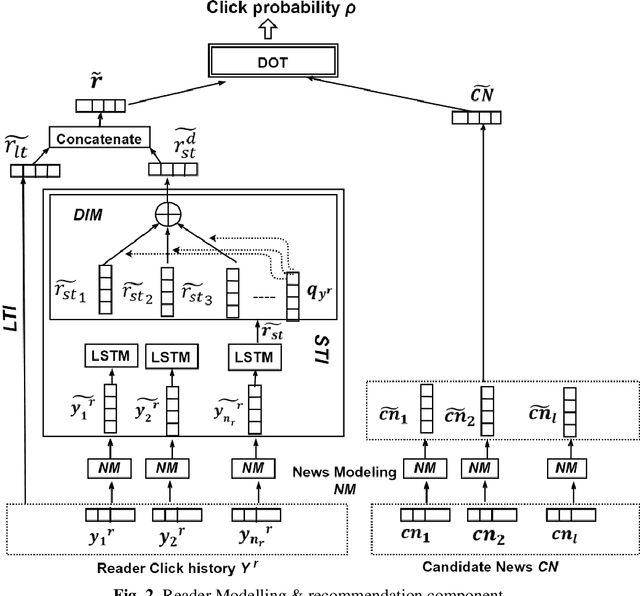
The news recommender systems are marked by a few unique challenges specific to the news domain. These challenges emerge from rapidly evolving readers' interests over dynamically generated news items that continuously change over time. News reading is also driven by a blend of a reader's long-term and short-term interests. In addition, diversity is required in a news recommender system, not only to keep the reader engaged in the reading process but to get them exposed to different views and opinions. In this paper, we propose a deep neural network that jointly learns informative news and readers' interests into a unified framework. We learn the news representation (features) from the headlines, snippets (body) and taxonomy (category, subcategory) of news. We learn a reader's long-term interests from the reader's click history, short-term interests from the recent clicks via LSTMSs and the diversified reader's interests through the attention mechanism. We also apply different levels of attention to our model. We conduct extensive experiments on two news datasets to demonstrate the effectiveness of our approach.
Prediction of Solar Radiation Using Artificial Neural Network
Apr 01, 2021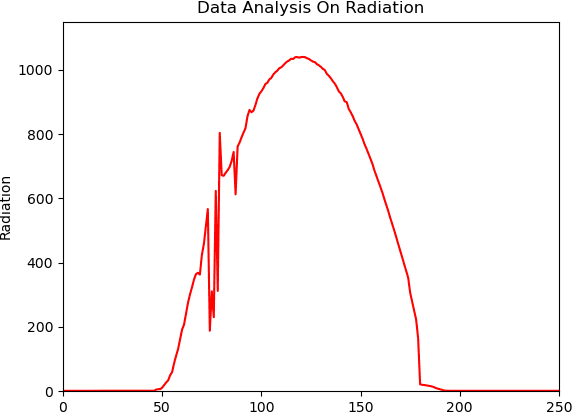
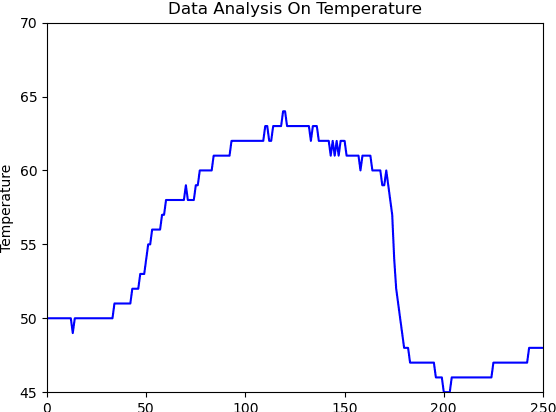
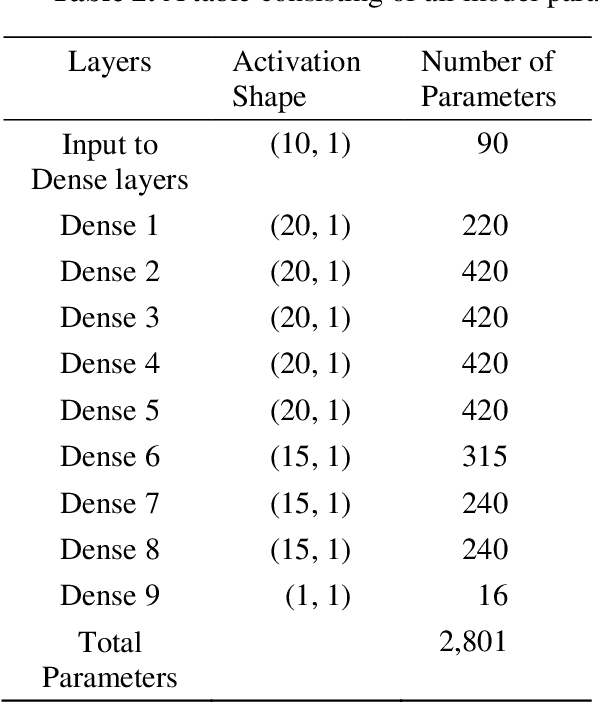
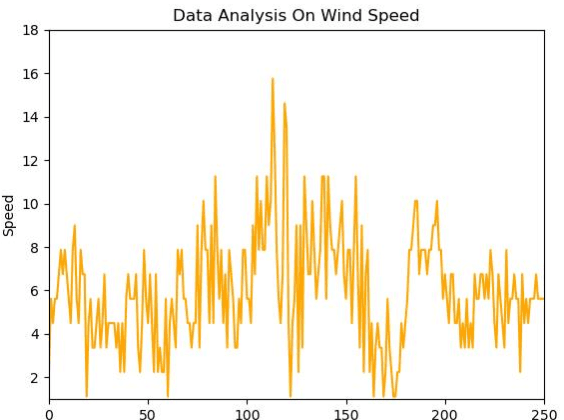
Most solar applications and systems can be reliably used to generate electricity and power in many homes and offices. Recently, there is an increase in many solar required systems that can be found not only in electricity generation but other applications such as solar distillation, water heating, heating of buildings, meteorology and producing solar conversion energy. Prediction of solar radiation is very significant in order to accomplish the previously mentioned objectives. In this paper, the main target is to present an algorithm that can be used to predict an hourly activity of solar radiation. Using a dataset that consists of temperature of air, time, humidity, wind speed, atmospheric pressure, direction of wind and solar radiation data, an Artificial Neural Network (ANN) model is constructed to effectively forecast solar radiation using the available weather forecast data. Two models are created to efficiently create a system capable of interpreting patterns through supervised learning data and predict the correct amount of radiation present in the atmosphere. The results of the two statistical indicators: Mean Absolute Error (MAE) and Mean Squared Error (MSE) are performed and compared with observed and predicted data. These two models were able to generate efficient predictions with sufficient performance accuracy.
* Published as open access, 12 pages, 13 images and 2 tables
C2CL: Contact to Contactless Fingerprint Matching
Apr 08, 2021
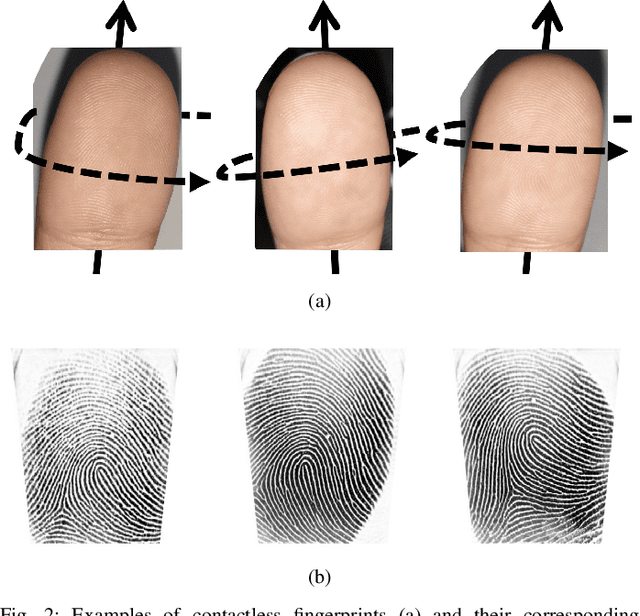
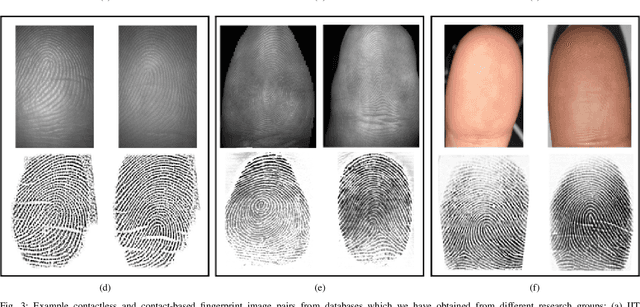
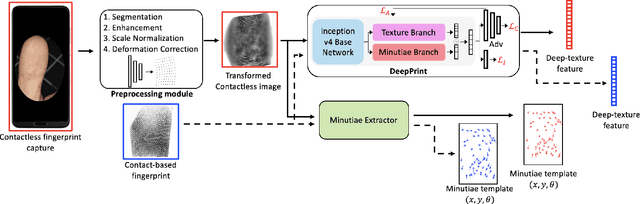
Matching contactless fingerprints or finger photos to contact-based fingerprint impressions has received increased attention in the wake of COVID-19 due to the superior hygiene of the contactless acquisition and the widespread availability of low cost mobile phones capable of capturing photos of fingerprints with sufficient resolution for verification purposes. This paper presents an end-to-end automated system, called C2CL, comprised of a mobile finger photo capture app, preprocessing, and matching algorithms to handle the challenges inhibiting previous cross-matching methods; namely i) low ridge-valley contrast of contactless fingerprints, ii) varying roll, pitch, yaw, and distance of the finger to the camera, iii) non-linear distortion of contact-based fingerprints, and vi) different image qualities of smartphone cameras. Our preprocessing algorithm segments, enhances, scales, and unwarps contactless fingerprints, while our matching algorithm extracts both minutiae and texture representations. A sequestered dataset of 9,888 contactless 2D fingerprints and corresponding contact-based fingerprints from 206 subjects (2 thumbs and 2 index fingers for each subject) acquired using our mobile capture app is used to evaluate the cross-database performance of our proposed algorithm. Furthermore, additional experimental results on 3 publicly available datasets demonstrate, for the first time, contact to contactless fingerprint matching accuracy that is comparable to existing contact to contact fingerprint matching systems (TAR in the range of 96.67% to 98.15% at FAR=0.01%).
CEL-Net: Continuous Exposure for Extreme Low-Light Imaging
Dec 07, 2020



Deep learning methods for enhancing dark images learn a mapping from input images to output images with pre-determined discrete exposure levels. Often, at inference time the input and optimal output exposure levels of the given image are different from the seen ones during training. As a result the enhanced image might suffer from visual distortions, such as low contrast or dark areas. We address this issue by introducing a deep learning model that can continuously generalize at inference time to unseen exposure levels without the need to retrain the model. To this end, we introduce a dataset of 1500 raw images captured in both outdoor and indoor scenes, with five different exposure levels and various camera parameters. Using the dataset, we develop a model for extreme low-light imaging that can continuously tune the input or output exposure level of the image to an unseen one. We investigate the properties of our model and validate its performance, showing promising results.
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
Mar 07, 2021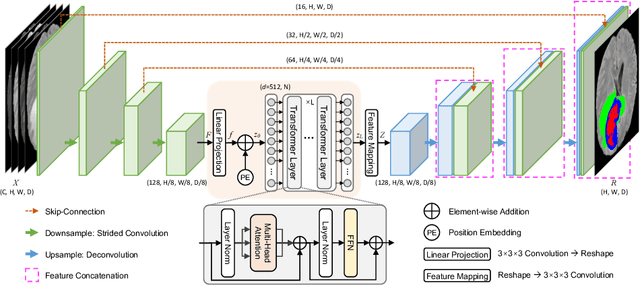
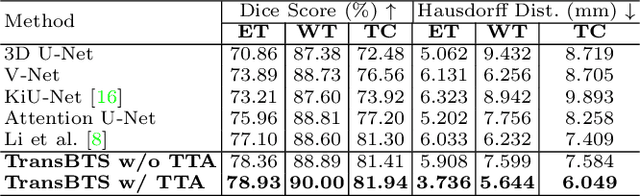
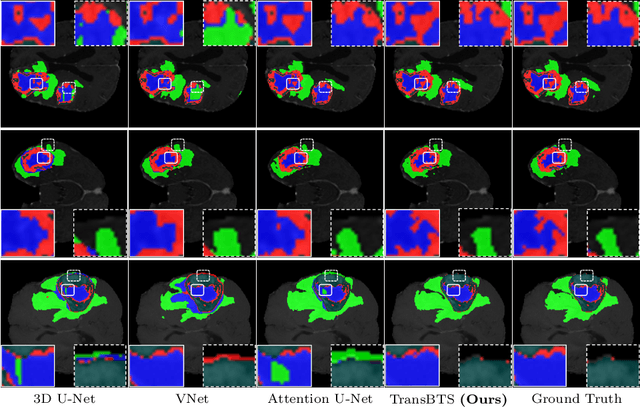
Transformer, which can benefit from global (long-range) information modeling using self-attention mechanisms, has been successful in natural language processing and 2D image classification recently. However, both local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation. In this paper, we for the first time exploit Transformer in 3D CNN for MRI Brain Tumor Segmentation and propose a novel network named TransBTS based on the encoder-decoder structure. To capture the local 3D context information, the encoder first utilizes 3D CNN to extract the volumetric spatial feature maps. Meanwhile, the feature maps are reformed elaborately for tokens that are fed into Transformer for global feature modeling. The decoder leverages the features embedded by Transformer and performs progressive upsampling to predict the detailed segmentation map. Experimental results on the BraTS 2019 dataset show that TransBTS outperforms state-of-the-art methods for brain tumor segmentation on 3D MRI scans. Code is available at https://github.com/Wenxuan-1119/TransBTS
Deep Indexed Active Learning for Matching Heterogeneous Entity Representations
Apr 08, 2021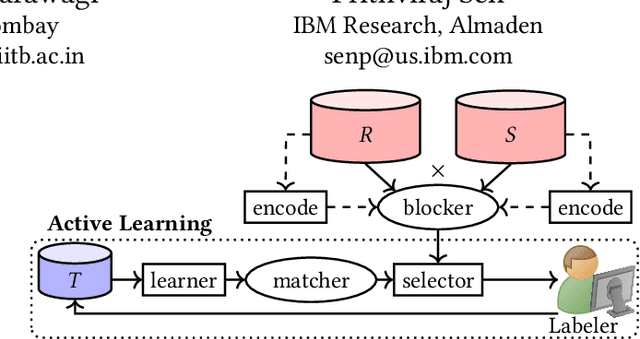
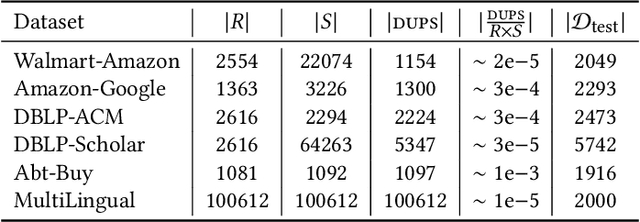
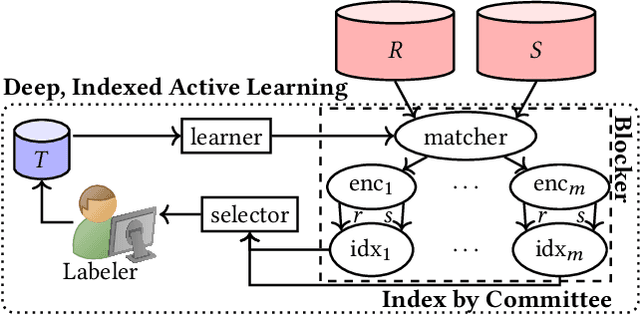
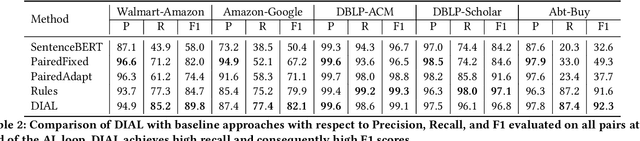
Given two large lists of records, the task in entity resolution (ER) is to find the pairs from the Cartesian product of the lists that correspond to the same real world entity. Typically, passive learning methods on tasks like ER require large amounts of labeled data to yield useful models. Active Learning is a promising approach for ER in low resource settings. However, the search space, to find informative samples for the user to label, grows quadratically for instance-pair tasks making active learning hard to scale. Previous works, in this setting, rely on hand-crafted predicates, pre-trained language model embeddings, or rule learning to prune away unlikely pairs from the Cartesian product. This blocking step can miss out on important regions in the product space leading to low recall. We propose DIAL, a scalable active learning approach that jointly learns embeddings to maximize recall for blocking and accuracy for matching blocked pairs. DIAL uses an Index-By-Committee framework, where each committee member learns representations based on powerful transformer models. We highlight surprising differences between the matcher and the blocker in the creation of the training data and the objective used to train their parameters. Experiments on five benchmark datasets and a multilingual record matching dataset show the effectiveness of our approach in terms of precision, recall and running time. Code is available at https://github.com/ArjitJ/DIAL