 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient Flow of Energy: A General and Efficient Approach for Entity Alignment Decoding
Jan 23, 2024
Entity alignment (EA), a pivotal process in integrating multi-source Knowledge Graphs (KGs), seeks to identify equivalent entity pairs across these graphs. Most existing approaches regard EA as a graph representation learning task, concentrating on enhancing graph encoders. However, the decoding process in EA - essential for effective operation and alignment accuracy - has received limited attention and remains tailored to specific datasets and model architectures, necessitating both entity and additional explicit relation embeddings. This specificity limits its applicability, particularly in GNN-based models. To address this gap, we introduce a novel, generalized, and efficient decoding approach for EA, relying solely on entity embeddings. Our method optimizes the decoding process by minimizing Dirichlet energy, leading to the gradient flow within the graph, to promote graph homophily. The discretization of the gradient flow produces a fast and scalable approach, termed Triple Feature Propagation (TFP). TFP innovatively channels gradient flow through three views: entity-to-entity, entity-to-relation, and relation-to-entity. This generalized gradient flow enables TFP to harness the multi-view structural information of KGs. Rigorous experimentation on diverse real-world datasets demonstrates that our approach significantly enhances various EA methods. Notably, the approach achieves these advancements with less than 6 seconds of additional computational time, establishing a new benchmark in efficiency and adaptability for future EA methods.
Embedded feature selection in LSTM networks with multi-objective evolutionary ensemble learning for time series forecasting
Dec 29, 2023Time series forecasting plays a crucial role in diverse fields, necessitating the development of robust models that can effectively handle complex temporal patterns. In this article, we present a novel feature selection method embedded in Long Short-Term Memory networks, leveraging a multi-objective evolutionary algorithm. Our approach optimizes the weights and biases of the LSTM in a partitioned manner, with each objective function of the evolutionary algorithm targeting the root mean square error in a specific data partition. The set of non-dominated forecast models identified by the algorithm is then utilized to construct a meta-model through stacking-based ensemble learning. Furthermore, our proposed method provides an avenue for attribute importance determination, as the frequency of selection for each attribute in the set of non-dominated forecasting models reflects their significance. This attribute importance insight adds an interpretable dimension to the forecasting process. Experimental evaluations on air quality time series data from Italy and southeast Spain demonstrate that our method substantially improves the generalization ability of conventional LSTMs, effectively reducing overfitting. Comparative analyses against state-of-the-art CancelOut and EAR-FS methods highlight the superior performance of our approach.
Real Time Human Detection by Unmanned Aerial Vehicles
Jan 06, 2024One of the most important problems in computer vision and remote sensing is object detection, which identifies particular categories of diverse things in pictures. Two crucial data sources for public security are the thermal infrared (TIR) remote sensing multi-scenario photos and videos produced by unmanned aerial vehicles (UAVs). Due to the small scale of the target, complex scene information, low resolution relative to the viewable videos, and dearth of publicly available labeled datasets and training models, their object detection procedure is still difficult. A UAV TIR object detection framework for pictures and videos is suggested in this study. The Forward-looking Infrared (FLIR) cameras used to gather ground-based TIR photos and videos are used to create the ``You Only Look Once'' (YOLO) model, which is based on CNN architecture. Results indicated that in the validating task, detecting human object had an average precision at IOU (Intersection over Union) = 0.5, which was 72.5\%, using YOLOv7 (YOLO version 7) state of the art model \cite{1}, while the detection speed around 161 frames per second (FPS/second). The usefulness of the YOLO architecture is demonstrated in the application, which evaluates the cross-detection performance of people in UAV TIR videos under a YOLOv7 model in terms of the various UAVs' observation angles. The qualitative and quantitative evaluation of object detection from TIR pictures and videos using deep-learning models is supported favorably by this work.
A Systematic Approach to Robustness Modelling for Deep Convolutional Neural Networks
Jan 24, 2024Convolutional neural networks have shown to be widely applicable to a large number of fields when large amounts of labelled data are available. The recent trend has been to use models with increasingly larger sets of tunable parameters to increase model accuracy, reduce model loss, or create more adversarially robust models -- goals that are often at odds with one another. In particular, recent theoretical work raises questions about the ability for even larger models to generalize to data outside of the controlled train and test sets. As such, we examine the role of the number of hidden layers in the ResNet model, demonstrated on the MNIST, CIFAR10, CIFAR100 datasets. We test a variety of parameters including the size of the model, the floating point precision, and the noise level of both the training data and the model output. To encapsulate the model's predictive power and computational cost, we provide a method that uses induced failures to model the probability of failure as a function of time and relate that to a novel metric that allows us to quickly determine whether or not the cost of training a model outweighs the cost of attacking it. Using this approach, we are able to approximate the expected failure rate using a small number of specially crafted samples rather than increasingly larger benchmark datasets. We demonstrate the efficacy of this technique on both the MNIST and CIFAR10 datasets using 8-, 16-, 32-, and 64-bit floating-point numbers, various data pre-processing techniques, and several attacks on five configurations of the ResNet model. Then, using empirical measurements, we examine the various trade-offs between cost, robustness, latency, and reliability to find that larger models do not significantly aid in adversarial robustness despite costing significantly more to train.
Real-Time Object Detection in Occluded Environment with Background Cluttering Effects Using Deep Learning
Jan 02, 2024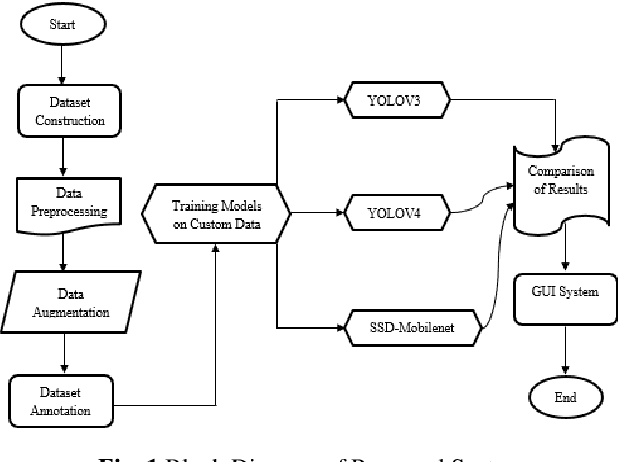

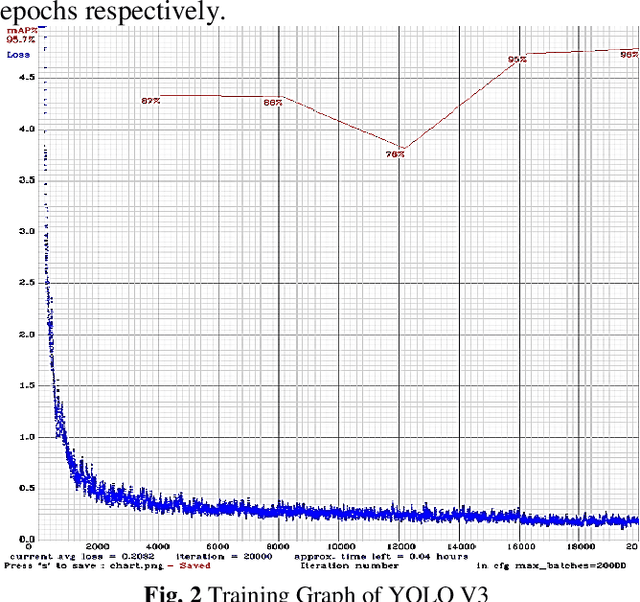

Detection of small, undetermined moving objects or objects in an occluded environment with a cluttered background is the main problem of computer vision. This greatly affects the detection accuracy of deep learning models. To overcome these problems, we concentrate on deep learning models for real-time detection of cars and tanks in an occluded environment with a cluttered background employing SSD and YOLO algorithms and improved precision of detection and reduce problems faced by these models. The developed method makes the custom dataset and employs a preprocessing technique to clean the noisy dataset. For training the developed model we apply the data augmentation technique to balance and diversify the data. We fine-tuned, trained, and evaluated these models on the established dataset by applying these techniques and highlighting the results we got more accurately than without applying these techniques. The accuracy and frame per second of the SSD-Mobilenet v2 model are higher than YOLO V3 and YOLO V4. Furthermore, by employing various techniques like data enhancement, noise reduction, parameter optimization, and model fusion we improve the effectiveness of detection and recognition. We further added a counting algorithm, and target attributes experimental comparison, and made a graphical user interface system for the developed model with features of object counting, alerts, status, resolution, and frame per second. Subsequently, to justify the importance of the developed method analysis of YOLO V3, V4, and SSD were incorporated. Which resulted in the overall completion of the proposed method.
Understanding the Generalization Benefits of Late Learning Rate Decay
Jan 21, 2024Why do neural networks trained with large learning rates for a longer time often lead to better generalization? In this paper, we delve into this question by examining the relation between training and testing loss in neural networks. Through visualization of these losses, we note that the training trajectory with a large learning rate navigates through the minima manifold of the training loss, finally nearing the neighborhood of the testing loss minimum. Motivated by these findings, we introduce a nonlinear model whose loss landscapes mirror those observed for real neural networks. Upon investigating the training process using SGD on our model, we demonstrate that an extended phase with a large learning rate steers our model towards the minimum norm solution of the training loss, which may achieve near-optimal generalization, thereby affirming the empirically observed benefits of late learning rate decay.
Edit One for All: Interactive Batch Image Editing
Jan 18, 2024In recent years, image editing has advanced remarkably. With increased human control, it is now possible to edit an image in a plethora of ways; from specifying in text what we want to change, to straight up dragging the contents of the image in an interactive point-based manner. However, most of the focus has remained on editing single images at a time. Whether and how we can simultaneously edit large batches of images has remained understudied. With the goal of minimizing human supervision in the editing process, this paper presents a novel method for interactive batch image editing using StyleGAN as the medium. Given an edit specified by users in an example image (e.g., make the face frontal), our method can automatically transfer that edit to other test images, so that regardless of their initial state (pose), they all arrive at the same final state (e.g., all facing front). Extensive experiments demonstrate that edits performed using our method have similar visual quality to existing single-image-editing methods, while having more visual consistency and saving significant time and human effort.
Learning shallow quantum circuits
Jan 18, 2024Despite fundamental interests in learning quantum circuits, the existence of a computationally efficient algorithm for learning shallow quantum circuits remains an open question. Because shallow quantum circuits can generate distributions that are classically hard to sample from, existing learning algorithms do not apply. In this work, we present a polynomial-time classical algorithm for learning the description of any unknown $n$-qubit shallow quantum circuit $U$ (with arbitrary unknown architecture) within a small diamond distance using single-qubit measurement data on the output states of $U$. We also provide a polynomial-time classical algorithm for learning the description of any unknown $n$-qubit state $\lvert \psi \rangle = U \lvert 0^n \rangle$ prepared by a shallow quantum circuit $U$ (on a 2D lattice) within a small trace distance using single-qubit measurements on copies of $\lvert \psi \rangle$. Our approach uses a quantum circuit representation based on local inversions and a technique to combine these inversions. This circuit representation yields an optimization landscape that can be efficiently navigated and enables efficient learning of quantum circuits that are classically hard to simulate.
Learning Non-myopic Power Allocation in Constrained Scenarios
Jan 18, 2024We propose a learning-based framework for efficient power allocation in ad hoc interference networks under episodic constraints. The problem of optimal power allocation -- for maximizing a given network utility metric -- under instantaneous constraints has recently gained significant popularity. Several learnable algorithms have been proposed to obtain fast, effective, and near-optimal performance. However, a more realistic scenario arises when the utility metric has to be optimized for an entire episode under time-coupled constraints. In this case, the instantaneous power needs to be regulated so that the given utility can be optimized over an entire sequence of wireless network realizations while satisfying the constraint at all times. Solving each instance independently will be myopic as the long-term constraint cannot modulate such a solution. Instead, we frame this as a constrained and sequential decision-making problem, and employ an actor-critic algorithm to obtain the constraint-aware power allocation at each step. We present experimental analyses to illustrate the effectiveness of our method in terms of superior episodic network-utility performance and its efficiency in terms of time and computational complexity.
Incremental Extractive Opinion Summarization Using Cover Trees
Jan 16, 2024Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accrue over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank. CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 25x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.