 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NeRD: Neural Reflectance Decomposition from Image Collections
Dec 08, 2020
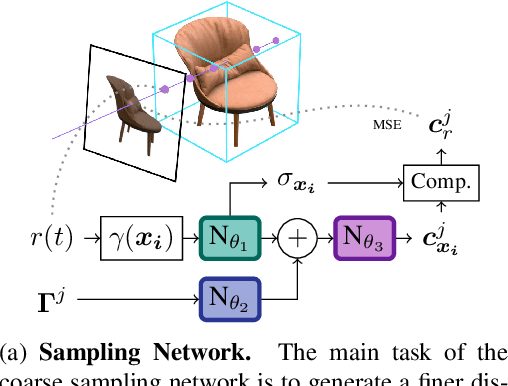

Decomposing a scene into its shape, reflectance, and illumination is a challenging but essential problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. By decomposing a scene into explicit representations, any rendering framework can be leveraged to generate novel views under any illumination in real-time. NeRD is a method that achieves this decomposition by introducing physically-based rendering to neural radiance fields. Even challenging non-Lambertian reflectances, complex geometry, and unknown illumination can be decomposed to high-quality models. The datasets and code is available at the project page: https://markboss.me/publication/2021-nerd/
Cluster-based Input Weight Initialization for Echo State Networks
Mar 08, 2021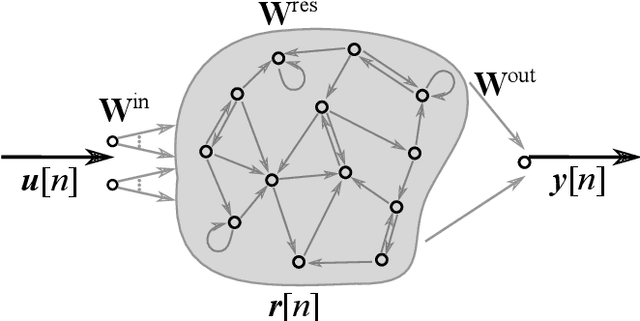
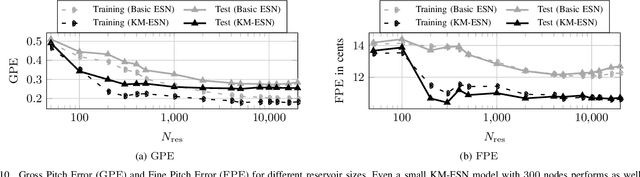
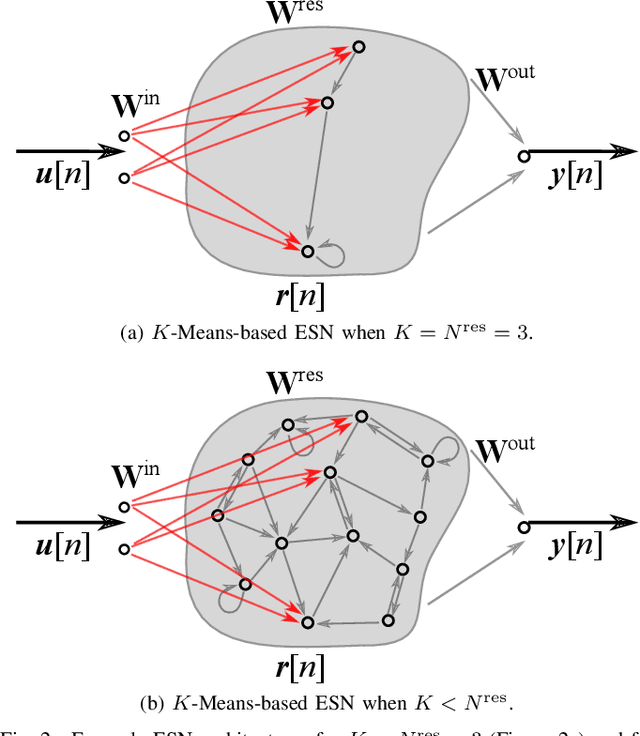
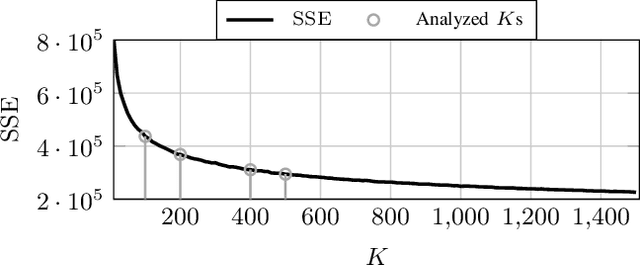
Echo State Networks (ESNs) are a special type of recurrent neural networks (RNNs), in which the input and recurrent connections are traditionally generated randomly, and only the output weights are trained. Despite the recent success of ESNs in various tasks of audio, image and radar recognition, we postulate that a purely random initialization is not the ideal way of initializing ESNs. The aim of this work is to propose an unsupervised initialization of the input connections using the K-Means algorithm on the training data. We show that this initialization performs equivalently or superior than a randomly initialized ESN whilst needing significantly less reservoir neurons (2000 vs. 4000 for spoken digit recognition, and 300 vs. 8000 neurons for f0 extraction) and thus reducing the amount of training time. Furthermore, we discuss that this approach provides the opportunity to estimate the suitable size of the reservoir based on the prior knowledge about the data.
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Mar 17, 2021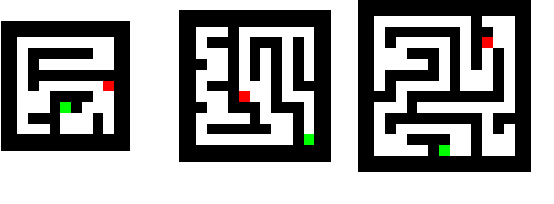
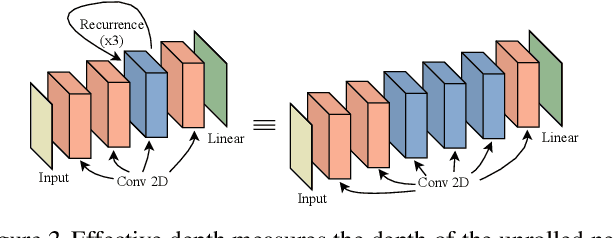

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used at test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.
Merchant Category Identification Using Credit Card Transactions
Nov 05, 2020
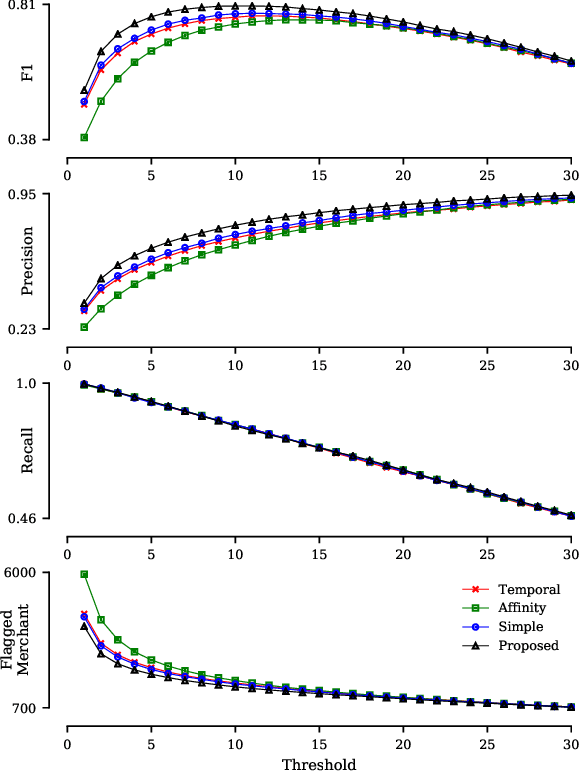
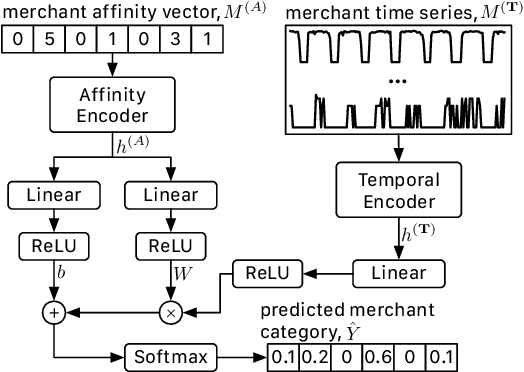
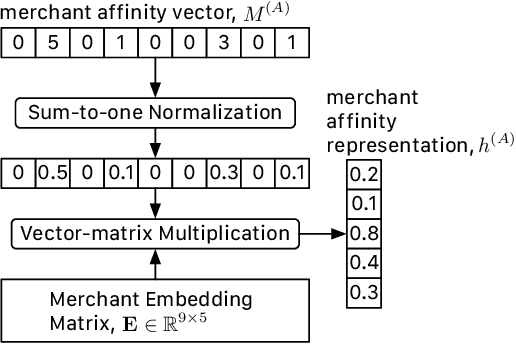
Digital payment volume has proliferated in recent years with the rapid growth of small businesses and online shops. When processing these digital transactions, recognizing each merchant's real identity (i.e., business type) is vital to ensure the integrity of payment processing systems. Conventionally, this problem is formulated as a time series classification problem solely using the merchant transaction history. However, with the large scale of the data, and changing behaviors of merchants and consumers over time, it is extremely challenging to achieve satisfying performance from off-the-shelf classification methods. In this work, we approach this problem from a multi-modal learning perspective, where we use not only the merchant time series data but also the information of merchant-merchant relationship (i.e., affinity) to verify the self-reported business type (i.e., merchant category) of a given merchant. Specifically, we design two individual encoders, where one is responsible for encoding temporal information and the other is responsible for affinity information, and a mechanism to fuse the outputs of the two encoders to accomplish the identification task. Our experiments on real-world credit card transaction data between 71,668 merchants and 433,772,755 customers have demonstrated the effectiveness and efficiency of the proposed model.
Nearly Horizon-Free Offline Reinforcement Learning
Mar 25, 2021
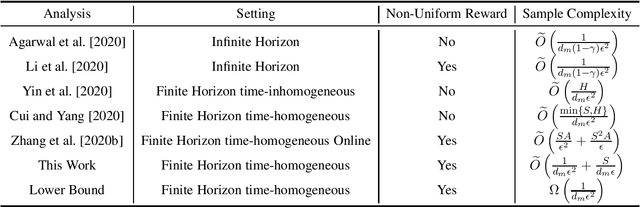
We revisit offline reinforcement learning on episodic time-homogeneous tabular Markov Decision Processes with $S$ states, $A$ actions and planning horizon $H$. Given the collected $N$ episodes data with minimum cumulative reaching probability $d_m$, we obtain the first set of nearly $H$-free sample complexity bounds for evaluation and planning using the empirical MDPs: 1.For the offline evaluation, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} \right)$ error rate, which matches the lower bound and does not have additional dependency on $\poly\left(S,A\right)$ in higher-order term, that is different from previous works~\citep{yin2020near,yin2020asymptotically}. 2.For the offline policy optimization, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} + \frac{S}{Nd_m}\right)$ error rate, improving upon the best known result by \cite{cui2020plug}, which has additional $H$ and $S$ factors in the main term. Furthermore, this bound approaches the $\Omega\left(\sqrt{\frac{1}{Nd_m}}\right)$ lower bound up to logarithmic factors and a high-order term. To the best of our knowledge, these are the first set of nearly horizon-free bounds in offline reinforcement learning.
D-NeRF: Neural Radiance Fields for Dynamic Scenes
Nov 27, 2020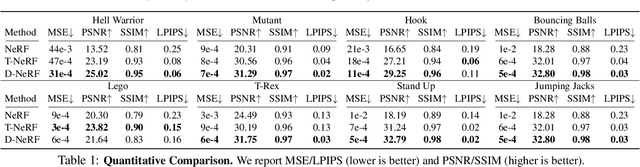
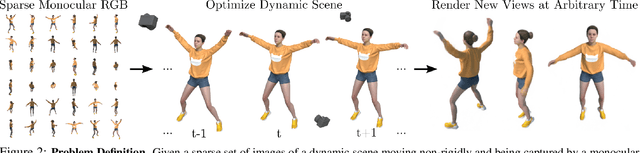
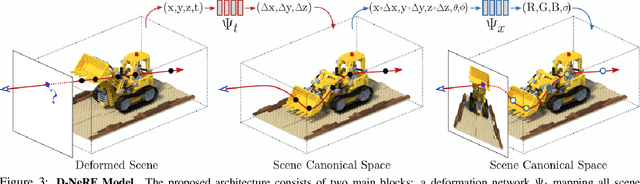

Neural rendering techniques combining machine learning with geometric reasoning have arisen as one of the most promising approaches for synthesizing novel views of a scene from a sparse set of images. Among these, stands out the Neural radiance fields (NeRF), which trains a deep network to map 5D input coordinates (representing spatial location and viewing direction) into a volume density and view-dependent emitted radiance. However, despite achieving an unprecedented level of photorealism on the generated images, NeRF is only applicable to static scenes, where the same spatial location can be queried from different images. In this paper we introduce D-NeRF, a method that extends neural radiance fields to a dynamic domain, allowing to reconstruct and render novel images of objects under rigid and non-rigid motions from a \emph{single} camera moving around the scene. For this purpose we consider time as an additional input to the system, and split the learning process in two main stages: one that encodes the scene into a canonical space and another that maps this canonical representation into the deformed scene at a particular time. Both mappings are simultaneously learned using fully-connected networks. Once the networks are trained, D-NeRF can render novel images, controlling both the camera view and the time variable, and thus, the object movement. We demonstrate the effectiveness of our approach on scenes with objects under rigid, articulated and non-rigid motions. Code, model weights and the dynamic scenes dataset will be released.
Regularized Behavior Value Estimation
Mar 17, 2021
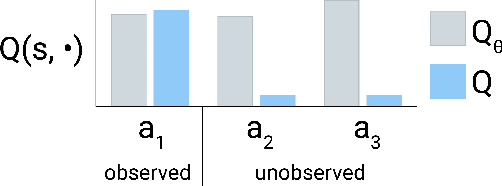
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Online Informative Path Planning for Active Information Gathering of a 3D Surface
Mar 17, 2021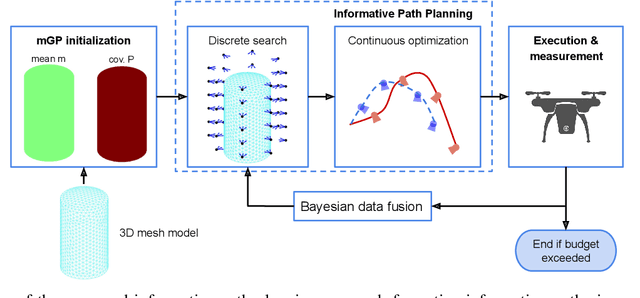
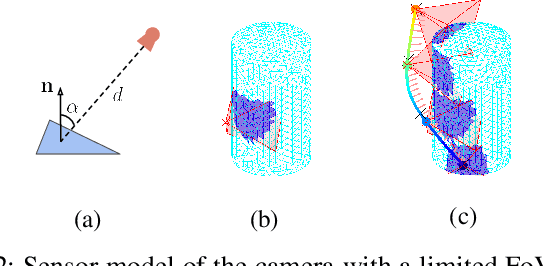
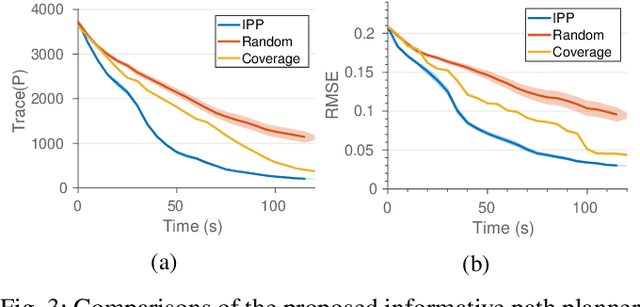
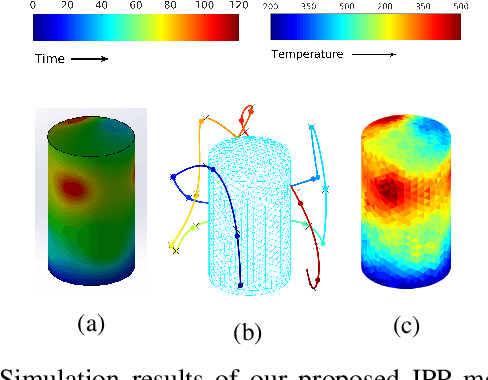
This paper presents an online informative path planning approach for active information gathering on three-dimensional surfaces using aerial robots. Most existing works on surface inspection focus on planning a path offline that can provide full coverage of the surface, which inherently assumes the surface information is uniformly distributed hence ignoring potential spatial correlations of the information field. In this paper, we utilize manifold Gaussian processes (mGPs) with geodesic kernel functions for mapping surface information fields and plan informative paths online in a receding horizon manner. Our approach actively plans information-gathering paths based on recent observations that respect dynamic constraints of the vehicle and a total flight time budget. We provide planning results for simulated temperature modeling for simple and complex 3D surface geometries (a cylinder and an aircraft model). We demonstrate that our informative planning method outperforms traditional approaches such as 3D coverage planning and random exploration, both in reconstruction error and information-theoretic metrics. We also show that by taking spatial correlations of the information field into planning using mGPs, the information gathering efficiency is significantly improved.
Coexistence of Communications and Cognitive MIMO Radar: Waveform Design and Prototype
Mar 08, 2021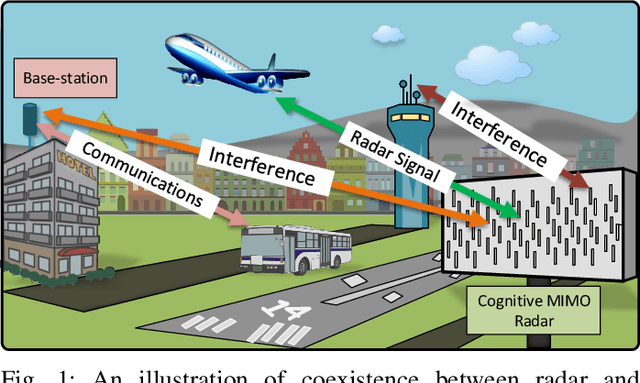
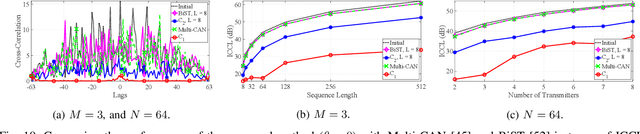
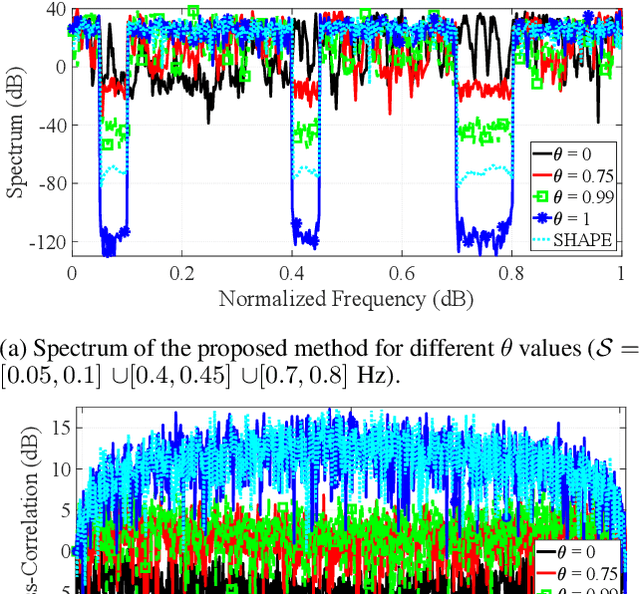
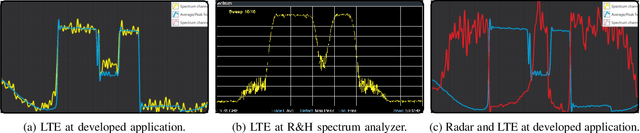
New generation of radar systems will need to coexist with other radio frequency (RF) systems, anticipating their behavior and reacting appropriately to avoid interference. In light of this requirement, this paper designs, implements, and evaluates the performance of phase-only sequences (with constant power) for intelligent spectrum utilization using the custom built cognitive Multiple Input Multiple Output (MIMO) radar prototype. The proposed transmit waveforms avoid the frequency bands occupied by narrowband interferers or communication links, while simultaneously have a small cross-correlation among each other to enable their separability at the MIMO radar receiver. The performance of the optimized set of sequences obtained through solving a non-convex bi-objective optimization problem, is compared with the state-of-the-art counterparts, and its applicability is illustrated by the developed prototype. A realistic Long Term Evolution (LTE) downlink is used for the communications, and the real-time system implementation is validated and evaluated through the throughput calculations for communications and the detection performance measurement for the radar system.
RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content
Jan 26, 2021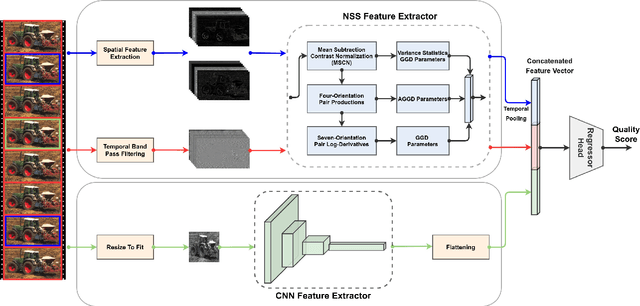
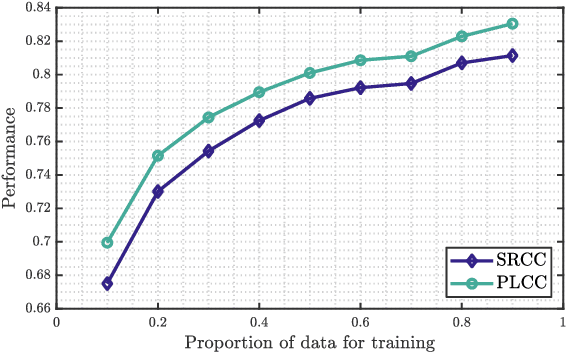
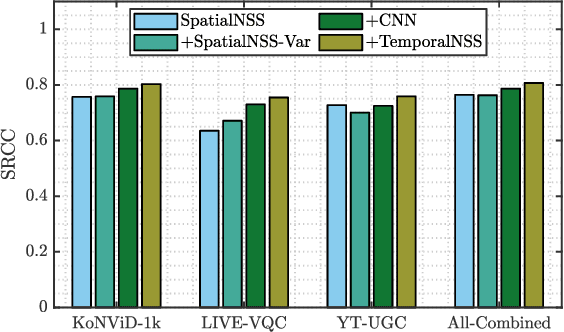
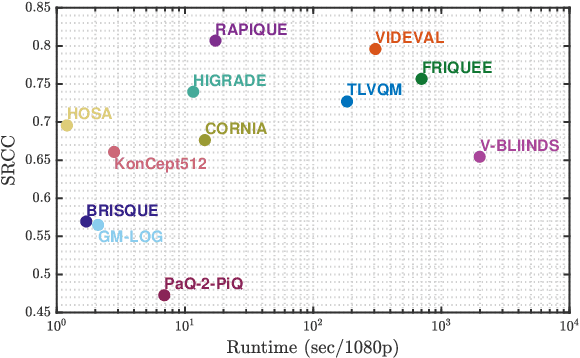
Blind or no-reference video quality assessment of user-generated content (UGC) has become a trending, challenging, unsolved problem. Accurate and efficient video quality predictors suitable for this content are thus in great demand to achieve more intelligent analysis and processing of UGC videos. Previous studies have shown that natural scene statistics and deep learning features are both sufficient to capture spatial distortions, which contribute to a significant aspect of UGC video quality issues. However, these models are either incapable or inefficient for predicting the quality of complex and diverse UGC videos in practical applications. Here we introduce an effective and efficient video quality model for UGC content, which we dub the Rapid and Accurate Video Quality Evaluator (RAPIQUE), which we show performs comparably to state-of-the-art (SOTA) models but with orders-of-magnitude faster runtime. RAPIQUE combines and leverages the advantages of both quality-aware scene statistics features and semantics-aware deep convolutional features, allowing us to design the first general and efficient spatial and temporal (space-time) bandpass statistics model for video quality modeling. Our experimental results on recent large-scale UGC video quality databases show that RAPIQUE delivers top performances on all the datasets at a considerably lower computational expense. We hope this work promotes and inspires further efforts towards practical modeling of video quality problems for potential real-time and low-latency applications. To promote public usage, an implementation of RAPIQUE has been made freely available online: \url{https://github.com/vztu/RAPIQUE}.