 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MOAI: A methodology for evaluating the impact of indoor airflow in the transmission of COVID-19
Mar 31, 2021
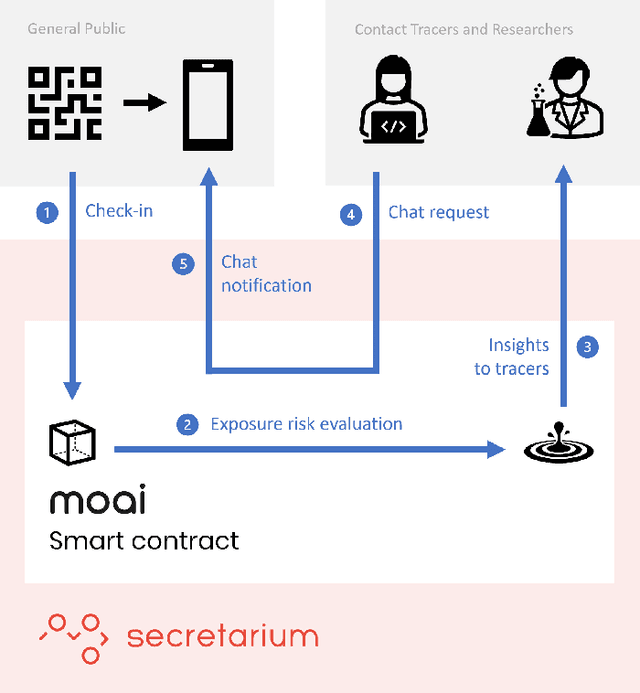
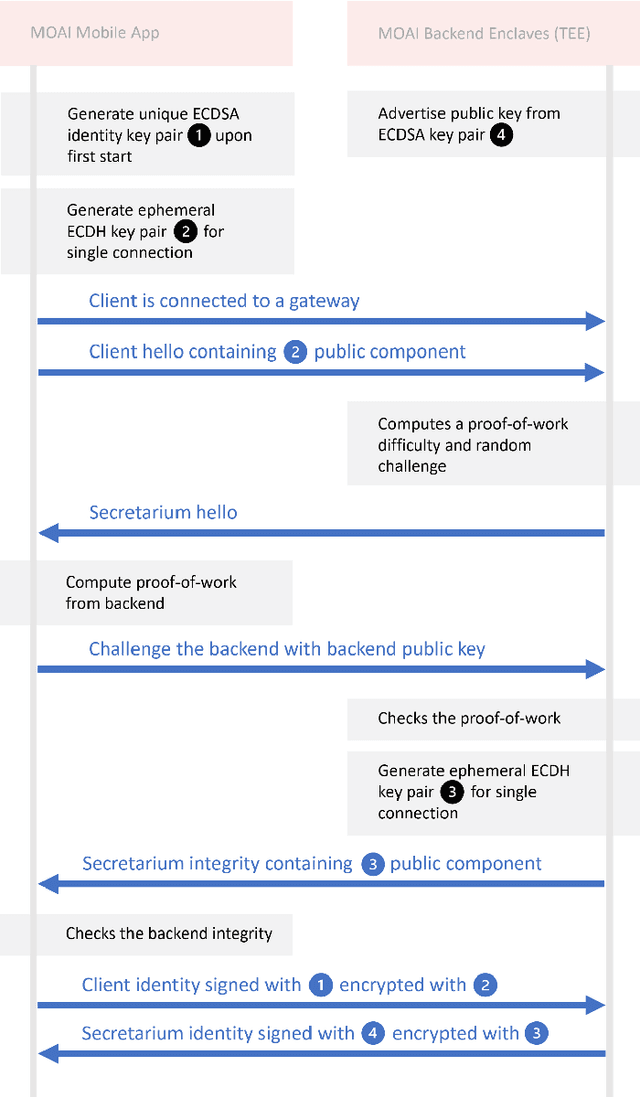
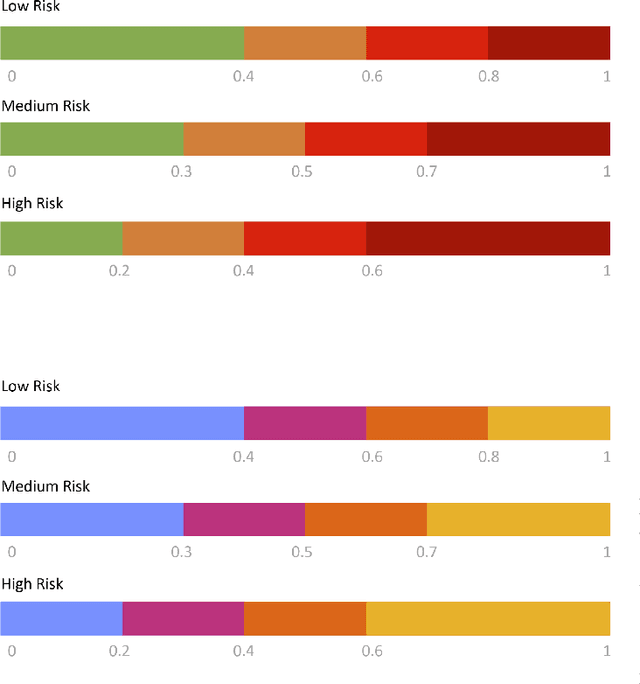
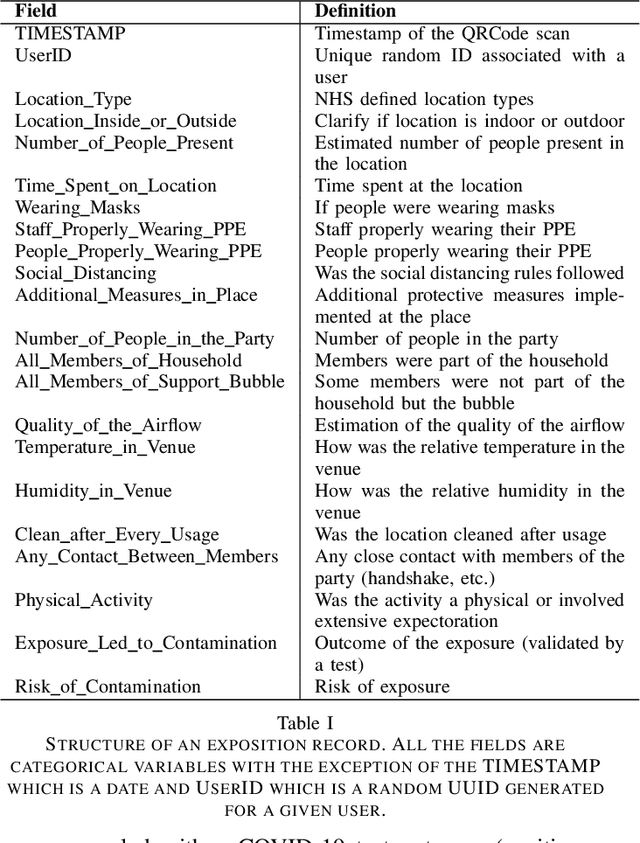
Epidemiology models play a key role in understanding and responding to the COVID-19 pandemic. In order to build those models, scientists need to understand contributing factors and their relative importance. A large strand of literature has identified the importance of airflow to mitigate droplets and far-field aerosol transmission risks. However, the specific factors contributing to higher or lower contamination in various settings have not been clearly defined and quantified. As part of the MOAI project (https://moaiapp.com), we are developing a privacy-preserving test and trace app to enable infection cluster investigators to get in touch with patients without having to know their identity. This approach allows involving users in the fight against the pandemic by contributing additional information in the form of anonymous research questionnaires. We first describe how the questionnaire was designed, and the synthetic data was generated based on a review we carried out on the latest available literature. We then present a model to evaluate the risk exposition of a user for a given setting. We finally propose a temporal addition to the model to evaluate the risk exposure over time for a given user.
A Reinforcement Learning Formulation of the Lyapunov Optimization: Application to Edge Computing Systems with Queue Stability
Dec 14, 2020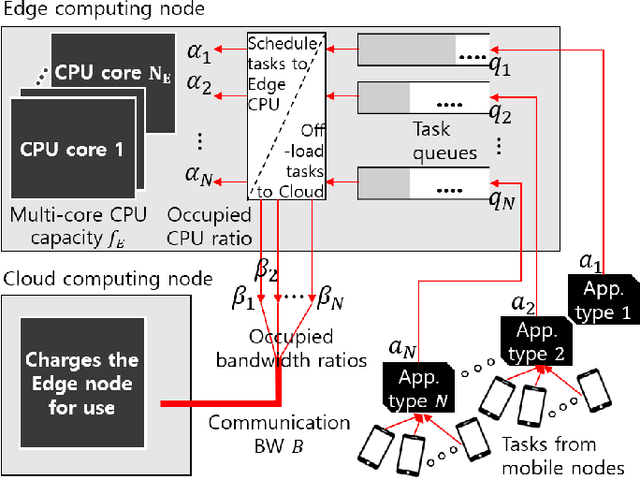
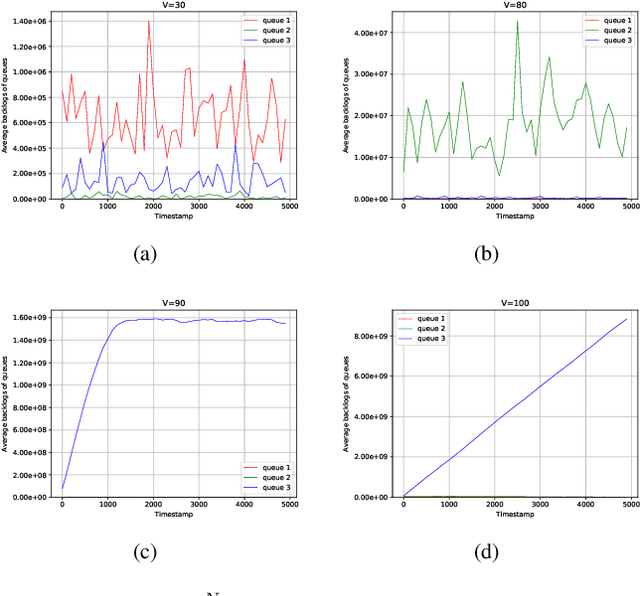
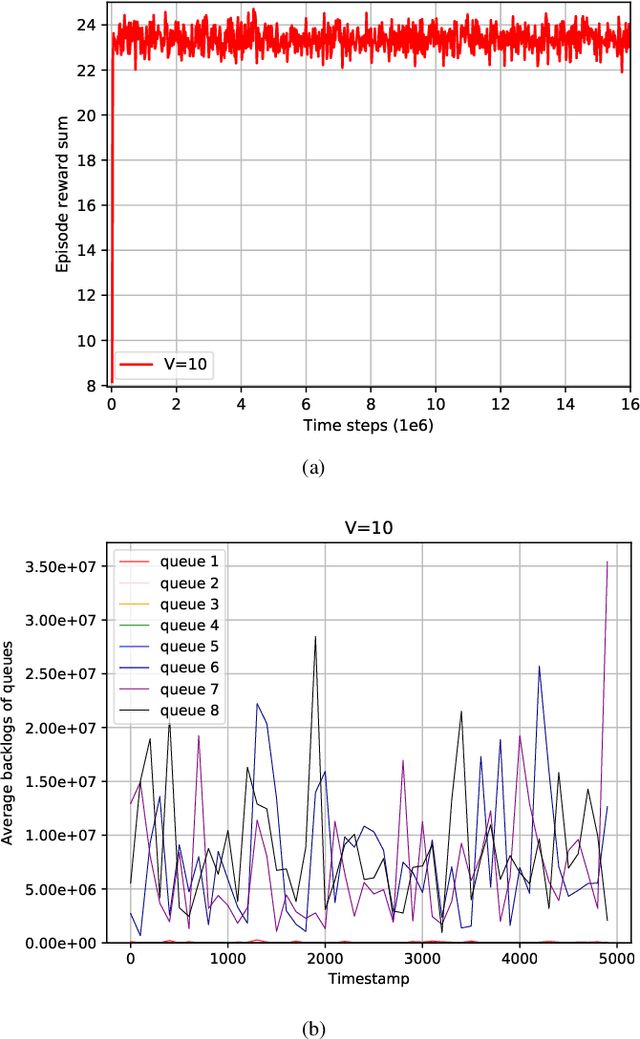
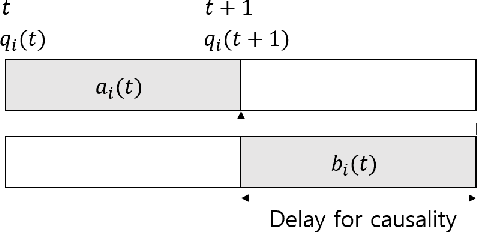
In this papper, a deep reinforcement learning (DRL)-based approach to the Lyapunov optimization is considered to minimize the time-average penalty while maintaining queue stability. A proper construction of state and action spaces is provided to form a proper Markov decision process (MDP) for the Lyapunov optimization. A condition for the reward function of reinforcement learning (RL) for queue stability is derived. Based on the analysis and practical RL with reward discounting, a class of reward functions is proposed for the DRL-based approach to the Lyapunov optimization. The proposed DRL-based approach to the Lyapunov optimization does not required complicated optimization at each time step and operates with general non-convex and discontinuous penalty functions. Hence, it provides an alternative to the conventional drift-plus-penalty (DPP) algorithm for the Lyapunov optimization. The proposed DRL-based approach is applied to resource allocation in edge computing systems with queue stability and numerical results demonstrate its successful operation.
A Knowledge Distillation Ensemble Framework for Predicting Short and Long-term Hospitalisation Outcomes from Electronic Health Records Data
Nov 18, 2020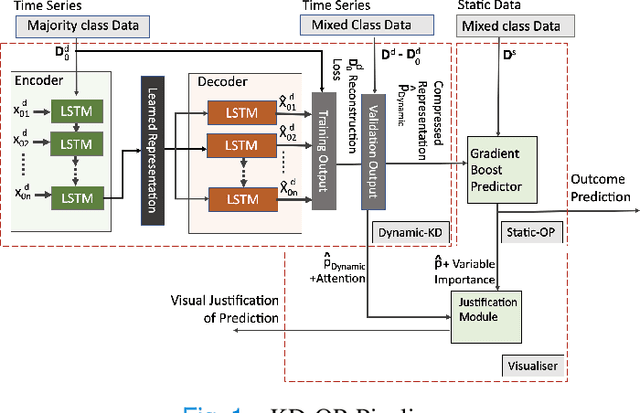
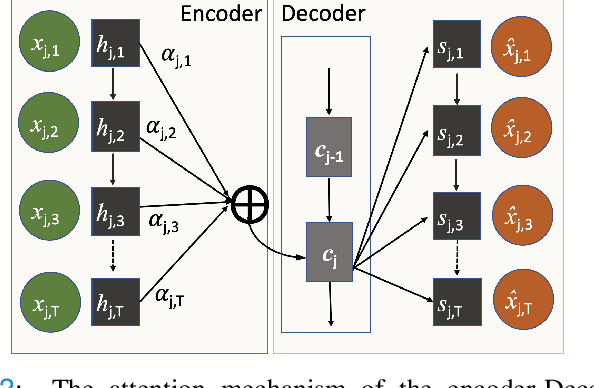
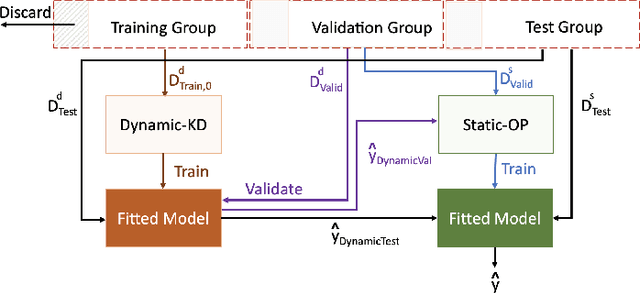
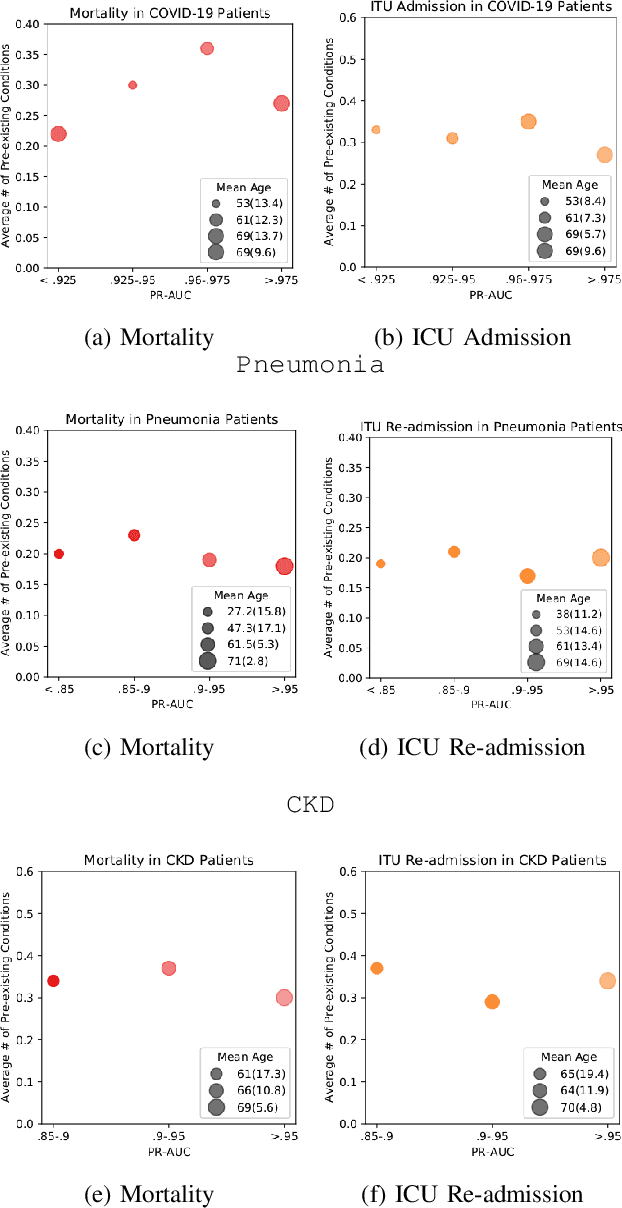
The ability to perform accurate prognosis of patients is crucial for proactive clinical decision making, informed resource management and personalised care. Existing outcome prediction models suffer from a low recall of infrequent positive outcomes. We present a highly-scalable and robust machine learning framework to automatically predict adversity represented by mortality and ICU admission from time-series vital signs and laboratory results obtained within the first 24 hours of hospital admission. The stacked platform comprises two components: a) an unsupervised LSTM Autoencoder that learns an optimal representation of the time-series, using it to differentiate the less frequent patterns which conclude with an adverse event from the majority patterns that do not, and b) a gradient boosting model, which relies on the constructed representation to refine prediction, incorporating static features of demographics, admission details and clinical summaries. The model is used to assess a patient's risk of adversity over time and provides visual justifications of its prediction based on the patient's static features and dynamic signals. Results of three case studies for predicting mortality and ICU admission show that the model outperforms all existing outcome prediction models, achieving PR-AUC of 0.93 (95$%$ CI: 0.878 - 0.969) in predicting mortality in ICU and general ward settings and 0.987 (95$%$ CI: 0.985-0.995) in predicting ICU admission.
STEP: Stochastic Traversability Evaluation and Planning for Safe Off-road Navigation
Mar 04, 2021
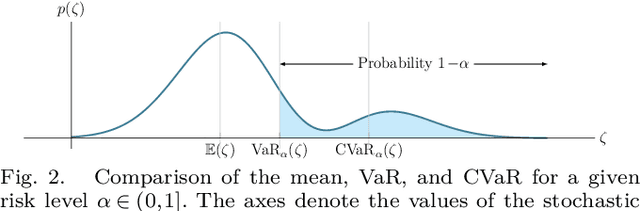
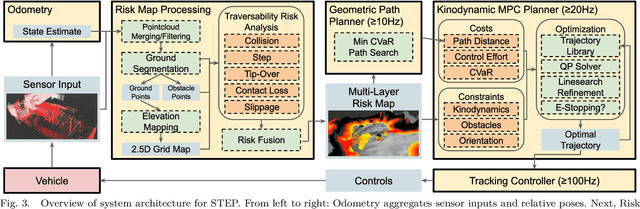
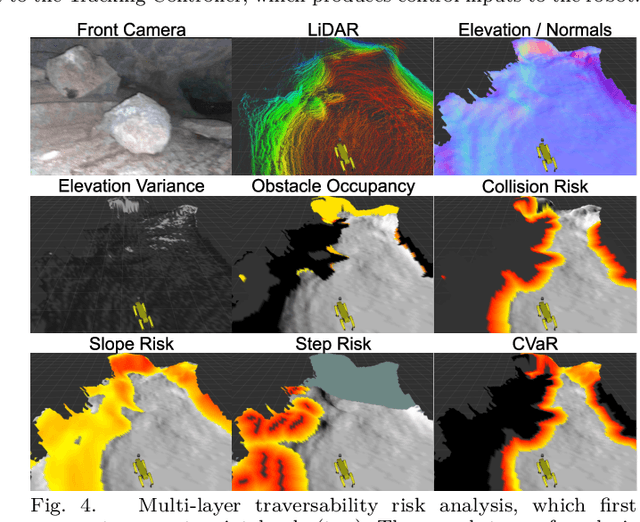
Although ground robotic autonomy has gained widespread usage in structured and controlled environments, autonomy in unknown and off-road terrain remains a difficult problem. Extreme, off-road, and unstructured environments such as undeveloped wilderness, caves, and rubble pose unique and challenging problems for autonomous navigation. To tackle these problems we propose an approach for assessing traversability and planning a safe, feasible, and fast trajectory in real-time. Our approach, which we name STEP (Stochastic Traversability Evaluation and Planning), relies on: 1) rapid uncertainty-aware mapping and traversability evaluation, 2) tail risk assessment using the Conditional Value-at-Risk (CVaR), and 3) efficient risk and constraint-aware kinodynamic motion planning using sequential quadratic programming-based (SQP) model predictive control (MPC). We analyze our method in simulation and validate its efficacy on wheeled and legged robotic platforms exploring extreme terrains including an underground lava tube.
Real-time and robust multiple-view gender classification using gait features in video surveillance
May 03, 2019
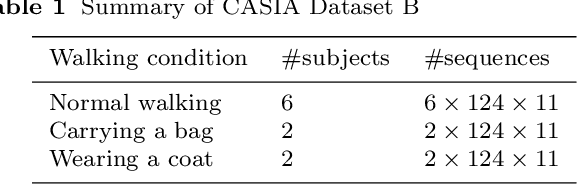
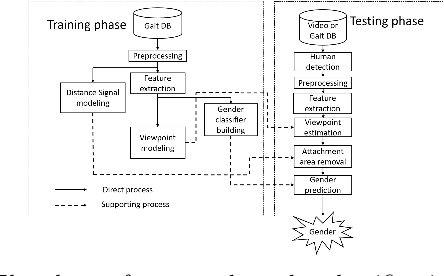
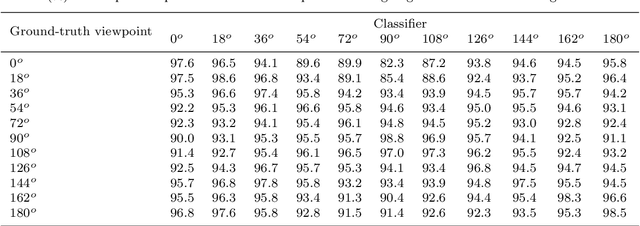
It is common to view people in real applications walking in arbitrary directions, holding items, or wearing heavy coats. These factors are challenges in gait-based application methods because they significantly change a person's appearance. This paper proposes a novel method for classifying human gender in real time using gait information. The use of an average gait image (AGI), rather than a gait energy image (GEI), allows this method to be computationally efficient and robust against view changes. A viewpoint (VP) model is created for automatically determining the viewing angle during the testing phase. A distance signal (DS) model is constructed to remove any areas with an attachment (carried items, worn coats) from a silhouette to reduce the interference in the resulting classification. Finally, the human gender is classified using multiple view-dependent classifiers trained using a support vector machine. Experiment results confirm that the proposed method achieves a high accuracy of 98.8% on the CASIA Dataset B and outperforms the recent state-of-the-art methods.
Izhikevich-Inspired Optoelectronic Neurons with Excitatory and Inhibitory Inputs for Energy-Efficient Photonic Spiking Neural Networks
May 03, 2021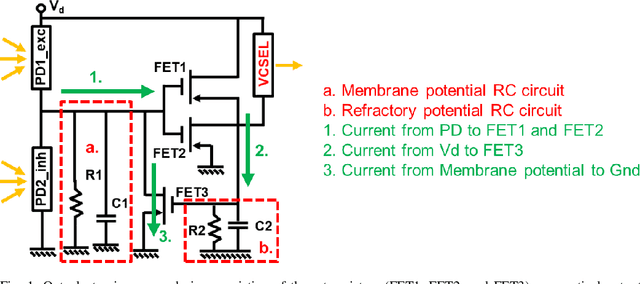
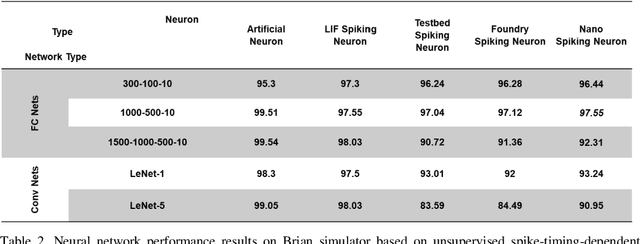
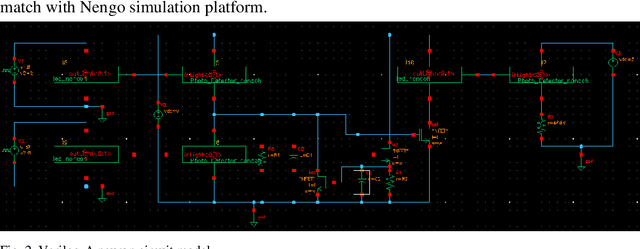

We designed, prototyped, and experimentally demonstrated, for the first time to our knowledge, an optoelectronic spiking neuron inspired by the Izhikevich model incorporating both excitatory and inhibitory optical spiking inputs and producing optical spiking outputs accordingly. The optoelectronic neurons consist of three transistors acting as electrical spiking circuits, a vertical-cavity surface-emitting laser (VCSEL) for optical spiking outputs, and two photodetectors for excitatory and inhibitory optical spiking inputs. Additional inclusion of capacitors and resistors complete the Izhikevich-inspired optoelectronic neurons, which receive excitatory and inhibitory optical spikes as inputs from other optoelectronic neurons. We developed a detailed optoelectronic neuron model in Verilog-A and simulated the circuit-level operation of various cases with excitatory input and inhibitory input signals. The experimental results closely resemble the simulated results and demonstrate how the excitatory inputs trigger the optical spiking outputs while the inhibitory inputs suppress the outputs. Utilizing the simulated neuron model, we conducted simulations using fully connected (FC) and convolutional neural networks (CNN). The simulation results using MNIST handwritten digits recognition show 90% accuracy on unsupervised learning and 97% accuracy on a supervised modified FC neural network. We further designed a nanoscale optoelectronic neuron utilizing quantum impedance conversion where a 200 aJ/spike input can trigger the output from on-chip nanolasers with 10 fJ/spike. The nanoscale neuron can support a fanout of ~80 or overcome 19 dB excess optical loss while running at 10 GSpikes/second in the neural network, which corresponds to 100x throughput and 1000x energy-efficiency improvement compared to state-of-art electrical neuromorphic hardware such as Loihi and NeuroGrid.
Make One-Shot Video Object Segmentation Efficient Again
Dec 03, 2020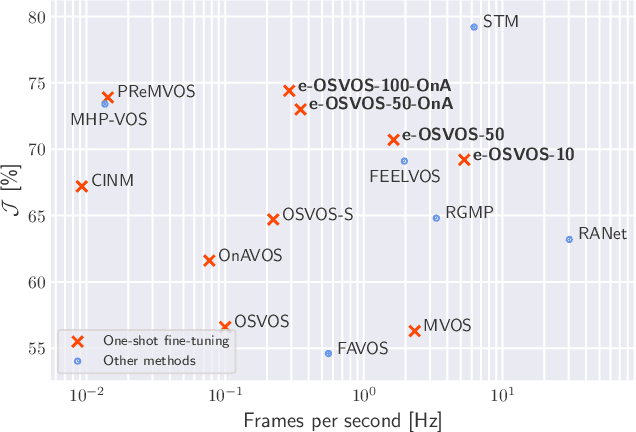
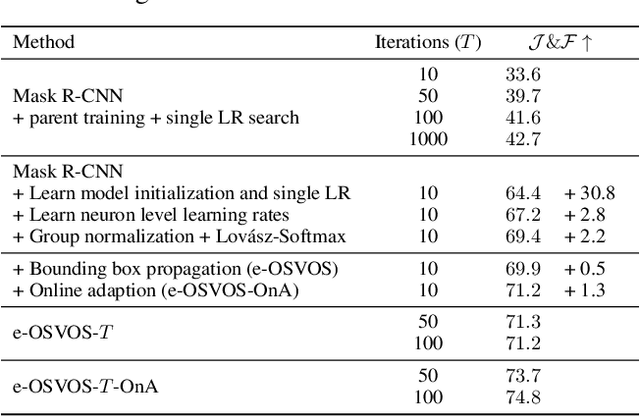

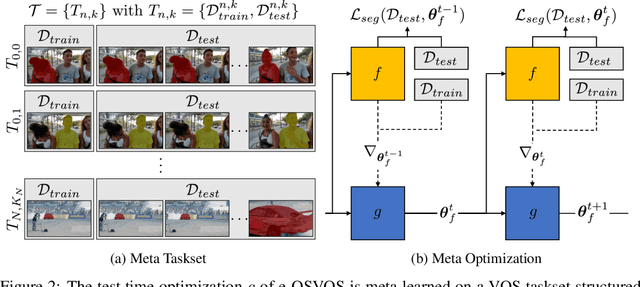
Video object segmentation (VOS) describes the task of segmenting a set of objects in each frame of a video. In the semi-supervised setting, the first mask of each object is provided at test time. Following the one-shot principle, fine-tuning VOS methods train a segmentation model separately on each given object mask. However, recently the VOS community has deemed such a test time optimization and its impact on the test runtime as unfeasible. To mitigate the inefficiencies of previous fine-tuning approaches, we present efficient One-Shot Video Object Segmentation (e-OSVOS). In contrast to most VOS approaches, e-OSVOS decouples the object detection task and predicts only local segmentation masks by applying a modified version of Mask R-CNN. The one-shot test runtime and performance are optimized without a laborious and handcrafted hyperparameter search. To this end, we meta learn the model initialization and learning rates for the test time optimization. To achieve optimal learning behavior, we predict individual learning rates at a neuron level. Furthermore, we apply an online adaptation to address the common performance degradation throughout a sequence by continuously fine-tuning the model on previous mask predictions supported by a frame-to-frame bounding box propagation. e-OSVOS provides state-of-the-art results on DAVIS 2016, DAVIS 2017, and YouTube-VOS for one-shot fine-tuning methods while reducing the test runtime substantially. Code is available at https://github.com/dvl-tum/e-osvos.
Deep Graph Convolutional Networks for Wind Speed Prediction
Jan 25, 2021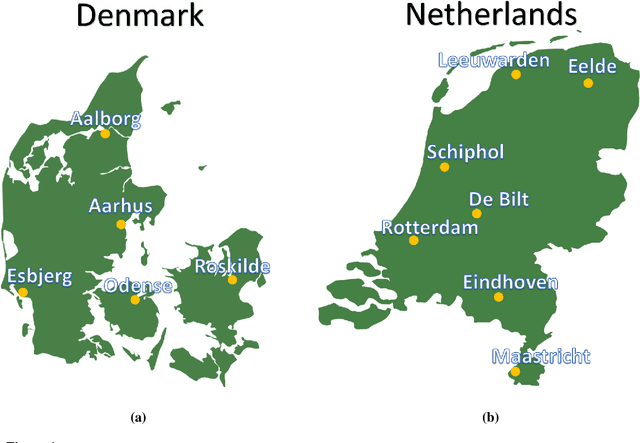
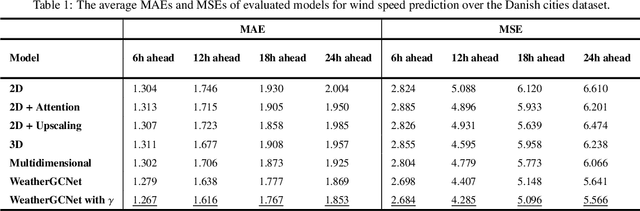
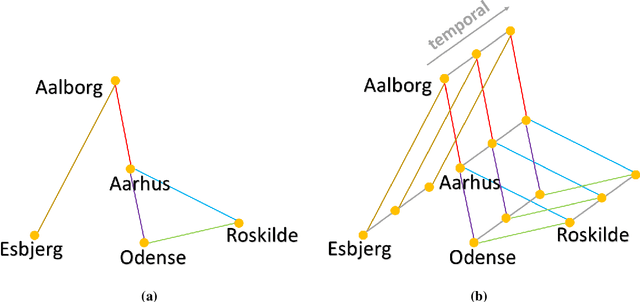
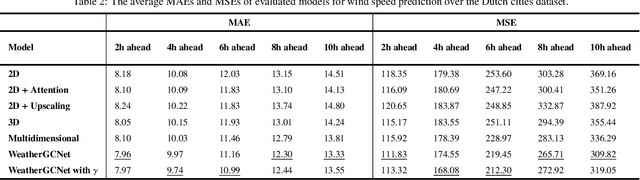
Wind speed prediction and forecasting is important for various business and management sectors. In this paper, we introduce new models for wind speed prediction based on graph convolutional networks (GCNs). Given hourly data of several weather variables acquired from multiple weather stations, wind speed values are predicted for multiple time steps ahead. In particular, the weather stations are treated as nodes of a graph whose associated adjacency matrix is learnable. In this way, the network learns the graph spatial structure and determines the strength of relations between the weather stations based on the historical weather data. We add a self-loop connection to the learnt adjacency matrix and normalize the adjacency matrix. We examine two scenarios with the self-loop connection setting (two separate models). In the first scenario, the self-loop connection is imposed as a constant additive. In the second scenario a learnable parameter is included to enable the network to decide about the self-loop connection strength. Furthermore, we incorporate data from multiple time steps with temporal convolution, which together with spatial graph convolution constitutes spatio-temporal graph convolution. We perform experiments on real datasets collected from weather stations located in cities in Denmark and the Netherlands. The numerical experiments show that our proposed models outperform previously developed baseline models on the referenced datasets. We provide additional insights by visualizing learnt adjacency matrices from each layer of our models.
Unpaired Single-Image Depth Synthesis with cycle-consistent Wasserstein GANs
Mar 31, 2021
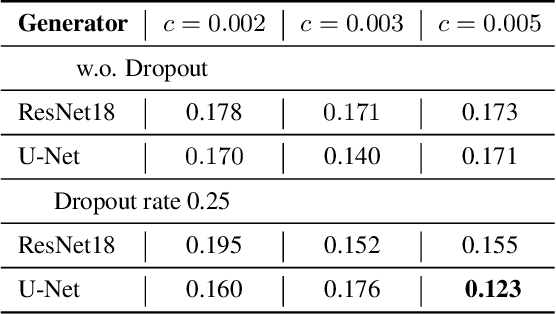
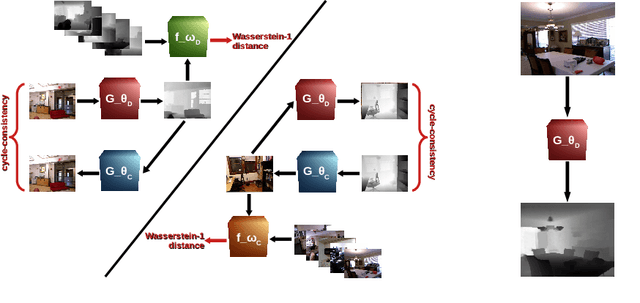
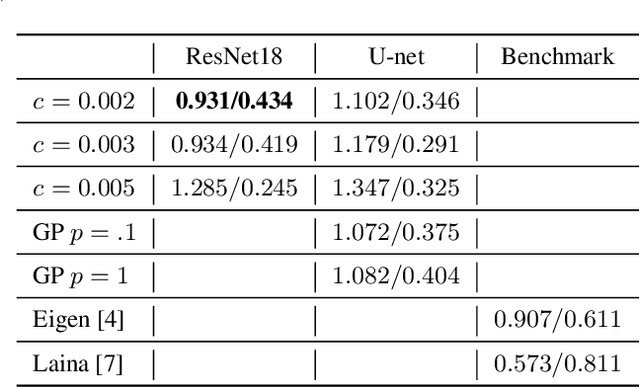
Real-time estimation of actual environment depth is an essential module for various autonomous system tasks such as localization, obstacle detection and pose estimation. During the last decade of machine learning, extensive deployment of deep learning methods to computer vision tasks yielded successful approaches for realistic depth synthesis out of a simple RGB modality. While most of these models rest on paired depth data or availability of video sequences and stereo images, there is a lack of methods facing single-image depth synthesis in an unsupervised manner. Therefore, in this study, latest advancements in the field of generative neural networks are leveraged to fully unsupervised single-image depth synthesis. To be more exact, two cycle-consistent generators for RGB-to-depth and depth-to-RGB transfer are implemented and simultaneously optimized using the Wasserstein-1 distance. To ensure plausibility of the proposed method, we apply the models to a self acquised industrial data set as well as to the renown NYU Depth v2 data set, which allows comparison with existing approaches. The observed success in this study suggests high potential for unpaired single-image depth estimation in real world applications.
Online Stochastic Optimization with Wasserstein Based Non-stationarity
Dec 23, 2020
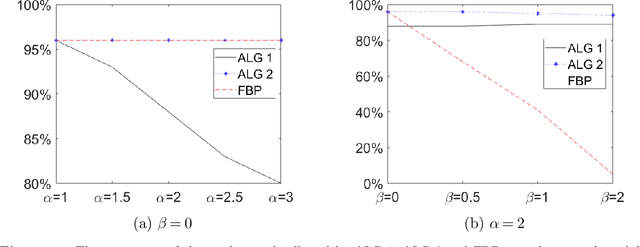
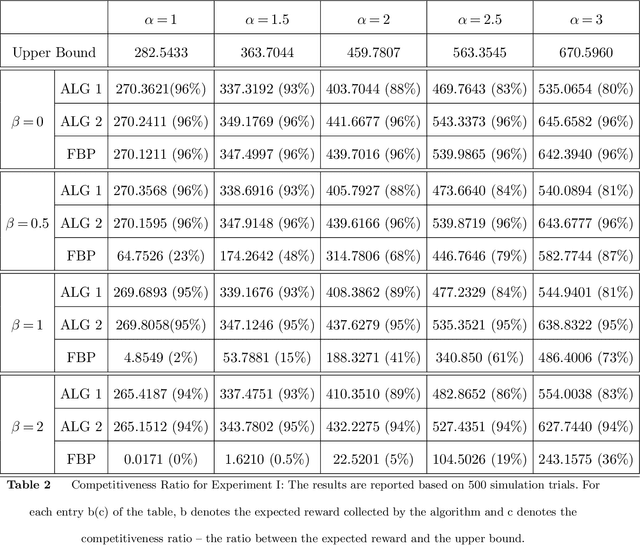
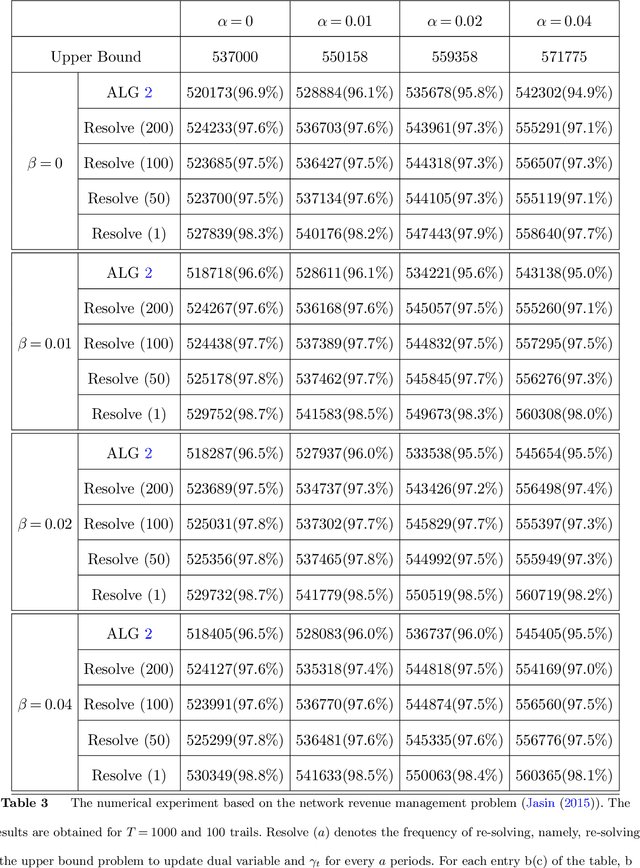
We consider a general online stochastic optimization problem with multiple budget constraints over a horizon of finite time periods. In each time period, a reward function and multiple cost functions are revealed, and the decision maker needs to specify an action from a convex and compact action set to collect the reward and consume the budget. Each cost function corresponds to the consumption of one budget. In each period, the reward and cost functions are drawn from an unknown distribution, which is non-stationary across time. The objective of the decision maker is to maximize the cumulative reward subject to the budget constraints. This formulation captures a wide range of applications including online linear programming and network revenue management, among others. In this paper, we consider two settings: (i) a data-driven setting where the true distribution is unknown but a prior estimate (possibly inaccurate) is available; (ii) an uninformative setting where the true distribution is completely unknown. We propose a unified Wasserstein-distance based measure to quantify the inaccuracy of the prior estimate in setting (i) and the non-stationarity of the system in setting (ii). We show that the proposed measure leads to a necessary and sufficient condition for the attainability of a sublinear regret in both settings. For setting (i), we propose a new algorithm, which takes a primal-dual perspective and integrates the prior information of the underlying distributions into an online gradient descent procedure in the dual space. The algorithm also naturally extends to the uninformative setting (ii). Under both settings, we show the corresponding algorithm achieves a regret of optimal order. In numerical experiments, we demonstrate how the proposed algorithms can be naturally integrated with the re-solving technique to further boost the empirical performance.