 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Active$^2$ Learning: Actively reducing redundancies in Active Learning methods for Sequence Tagging and Machine Translation
Apr 03, 2021
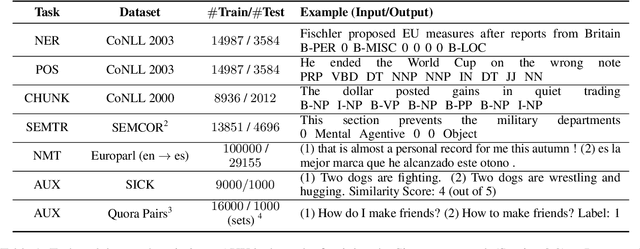
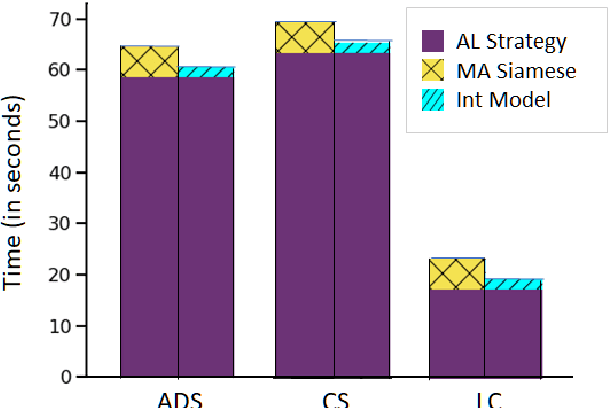
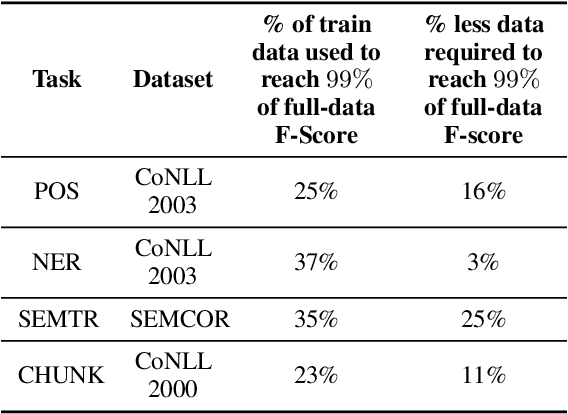
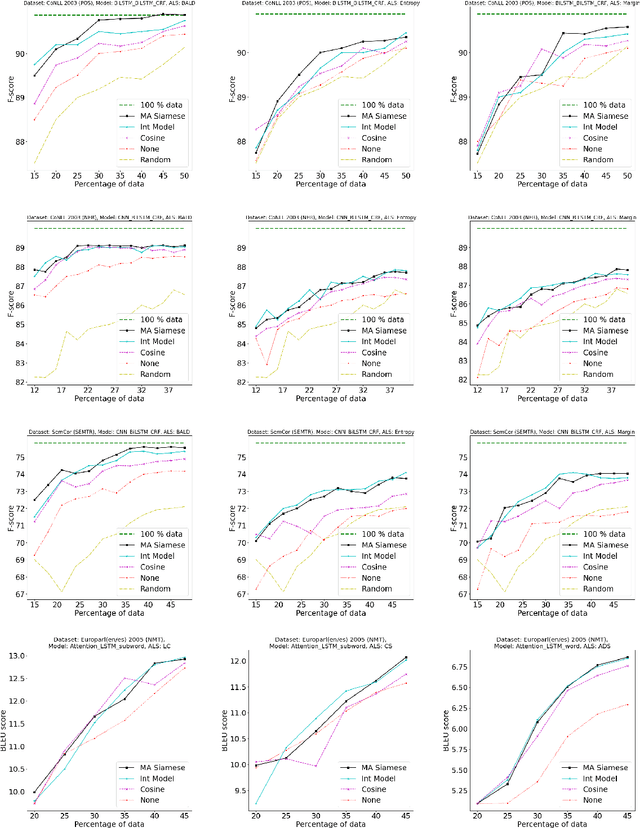
While deep learning is a powerful tool for natural language processing (NLP) problems, successful solutions to these problems rely heavily on large amounts of annotated samples. However, manually annotating data is expensive and time-consuming. Active Learning (AL) strategies reduce the need for huge volumes of labeled data by iteratively selecting a small number of examples for manual annotation based on their estimated utility in training the given model. In this paper, we argue that since AL strategies choose examples independently, they may potentially select similar examples, all of which may not contribute significantly to the learning process. Our proposed approach, Active$\mathbf{^2}$ Learning (A$\mathbf{^2}$L), actively adapts to the deep learning model being trained to eliminate further such redundant examples chosen by an AL strategy. We show that A$\mathbf{^2}$L is widely applicable by using it in conjunction with several different AL strategies and NLP tasks. We empirically demonstrate that the proposed approach is further able to reduce the data requirements of state-of-the-art AL strategies by an absolute percentage reduction of $\approx\mathbf{3-25\%}$ on multiple NLP tasks while achieving the same performance with no additional computation overhead.
Predicting seasonal influenza using supermarket retail records
Dec 17, 2020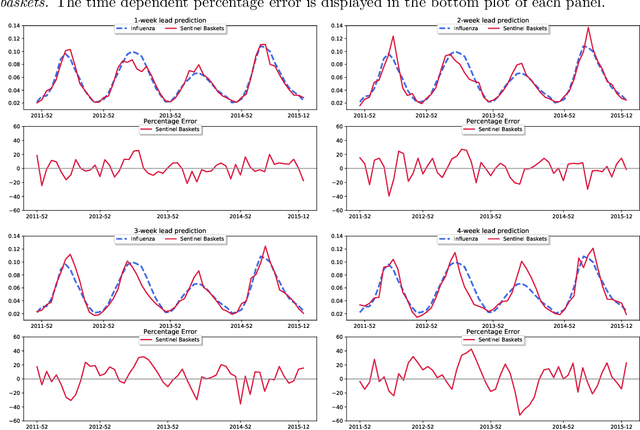


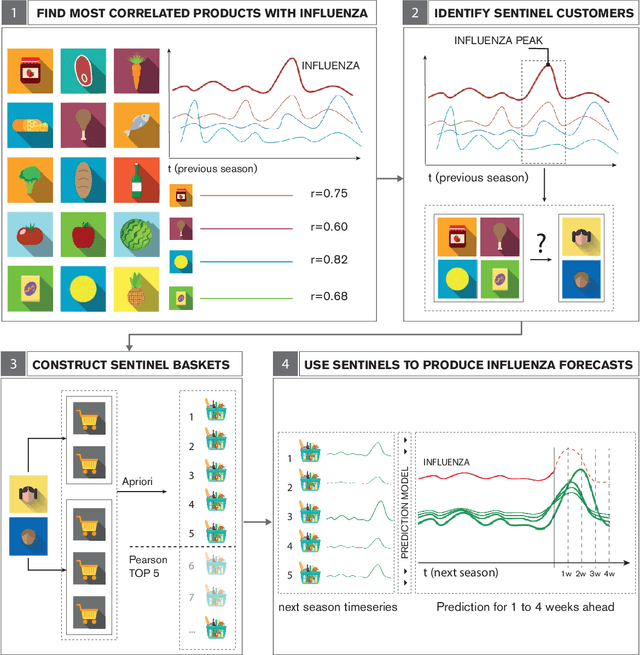
Increased availability of epidemiological data, novel digital data streams, and the rise of powerful machine learning approaches have generated a surge of research activity on real-time epidemic forecast systems. In this paper, we propose the use of a novel data source, namely retail market data to improve seasonal influenza forecasting. Specifically, we consider supermarket retail data as a proxy signal for influenza, through the identification of sentinel baskets, i.e., products bought together by a population of selected customers. We develop a nowcasting and forecasting framework that provides estimates for influenza incidence in Italy up to 4 weeks ahead. We make use of the Support Vector Regression (SVR) model to produce the predictions of seasonal flu incidence. Our predictions outperform both a baseline autoregressive model and a second baseline based on product purchases. The results show quantitatively the value of incorporating retail market data in forecasting models, acting as a proxy that can be used for the real-time analysis of epidemics.
Emotion Dynamics in Movie Dialogues
Mar 01, 2021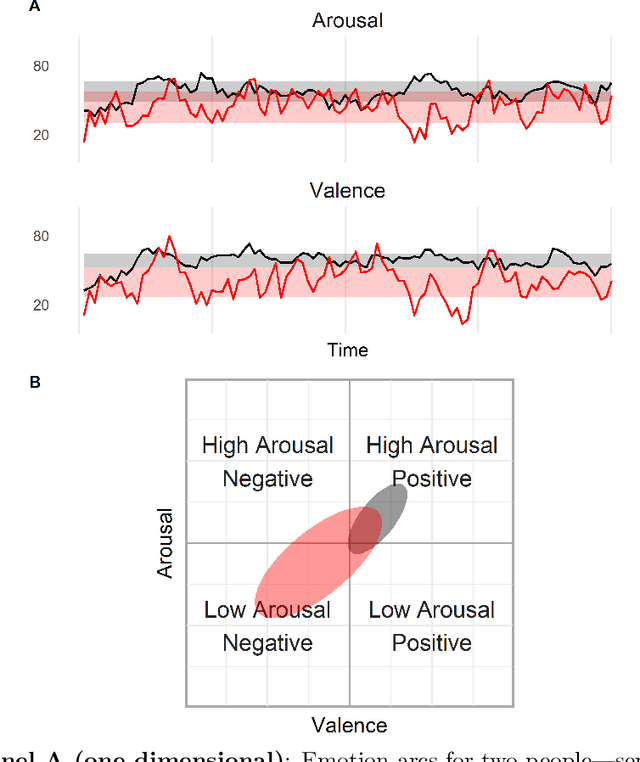
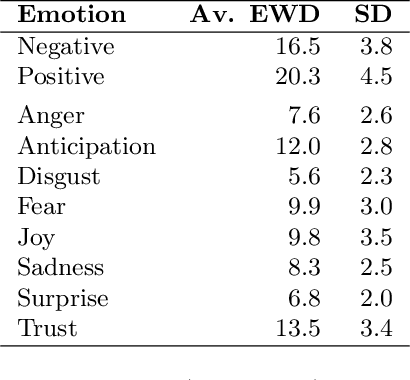
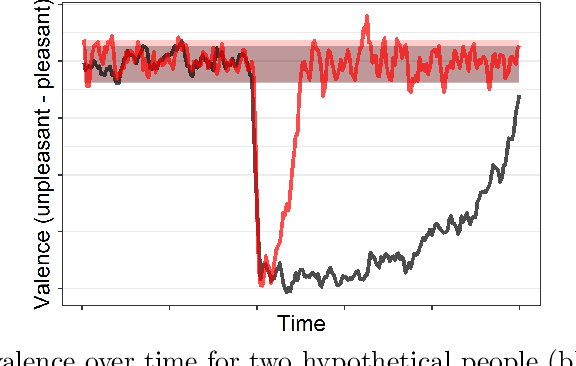
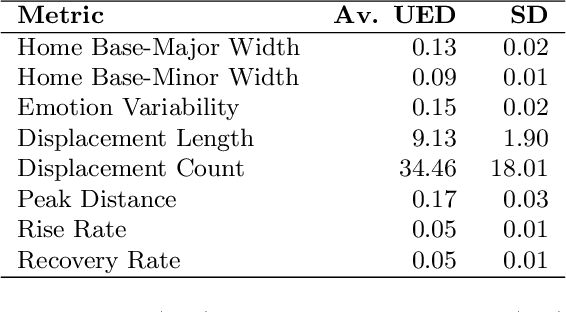
Emotion dynamics is a framework for measuring how an individual's emotions change over time. It is a powerful tool for understanding how we behave and interact with the world. In this paper, we introduce a framework to track emotion dynamics through one's utterances. Specifically we introduce a number of utterance emotion dynamics (UED) metrics inspired by work in Psychology. We use this approach to trace emotional arcs of movie characters. We analyze thousands of such character arcs to test hypotheses that inform our broader understanding of stories. Notably, we show that there is a tendency for characters to use increasingly more negative words and become increasingly emotionally discordant with each other until about 90 percent of the narrative length. UED also has applications in behavior studies, social sciences, and public health.
White-box Audio VST Effect Programming
Feb 05, 2021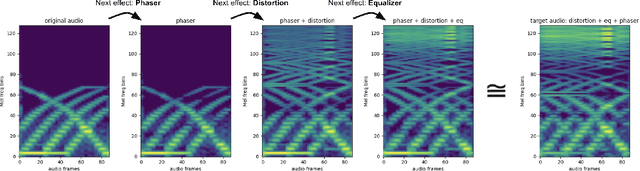
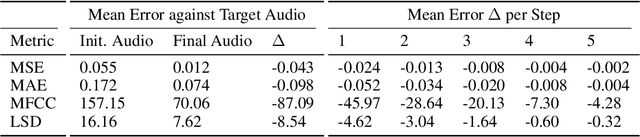
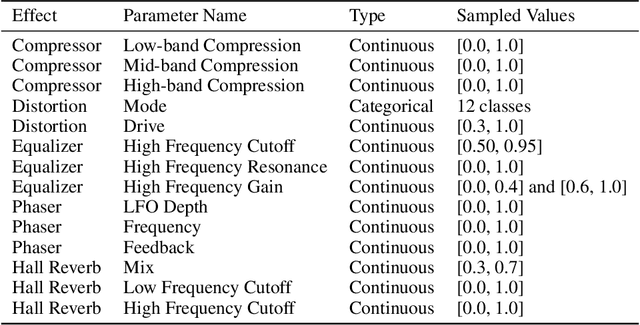
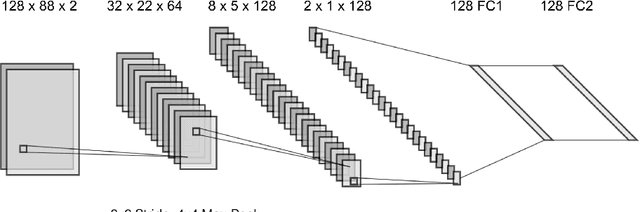
Learning to program an audio production VST plugin is a time consuming process, usually obtained through inefficient trial and error and only mastered after extensive user experience. We propose a white-box, iterative system that provides step-by-step instructions for applying audio effects to change a user's audio signal towards a desired sound. We apply our system to Xfer Records Serum: currently one of the most popular and complex VST synthesizers used by the audio production community. Our results indicate that our system is consistently able to provide useful feedback for a variety of different audio effects and synthesizer presets.
* The latest version of the system is to appear at EvoMUSART 2021 as a full paper. Audio samples of the latest system can be listened to at https://bit.ly/serum_rnn
StructFormer: Joint Unsupervised Induction of Dependency and Constituency Structure from Masked Language Modeling
Dec 01, 2020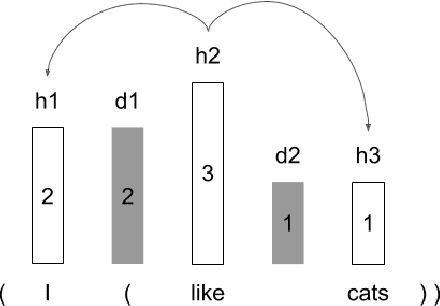

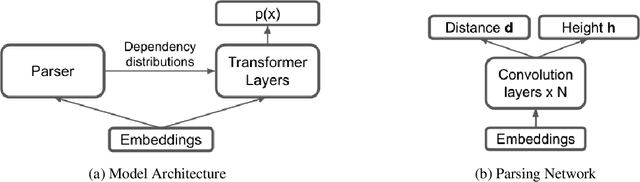
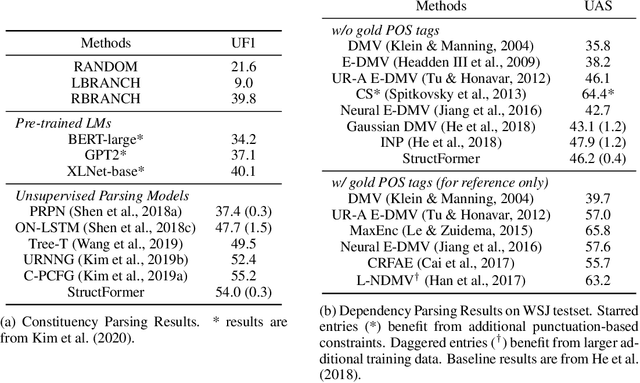
There are two major classes of natural language grammars -- the dependency grammar that models one-to-one correspondences between words and the constituency grammar that models the assembly of one or several corresponded words. While previous unsupervised parsing methods mostly focus on only inducing one class of grammars, we introduce a novel model, StructFormer, that can induce dependency and constituency structure at the same time. To achieve this, we propose a new parsing framework that can jointly generate a constituency tree and dependency graph. Then we integrate the induced dependency relations into the transformer, in a differentiable manner, through a novel dependency-constrained self-attention mechanism. Experimental results show that our model can achieve strong results on unsupervised constituency parsing, unsupervised dependency parsing, and masked language modeling at the same time.
Robust Pandemic Control Synthesis with Formal Specifications: A Case Study on COVID-19 Pandemic
Mar 26, 2021
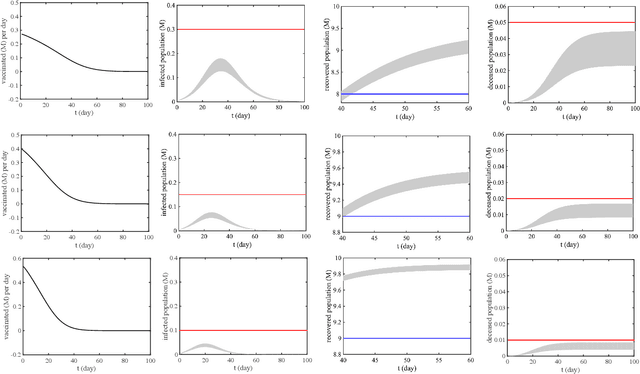
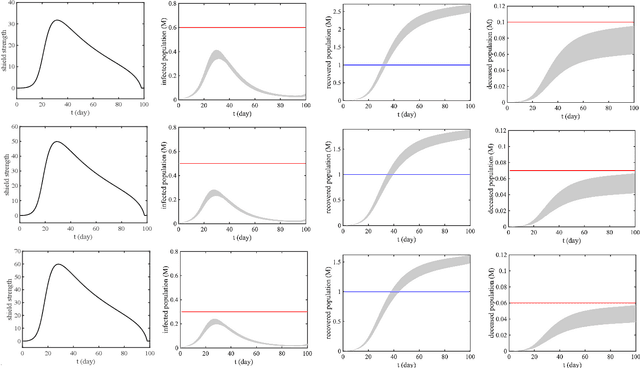
Pandemics can bring a range of devastating consequences to public health and the world economy. Identifying the most effective control strategies has been the imperative task all around the world. Various public health control strategies have been proposed and tested against pandemic diseases (e.g., COVID-19). We study two specific pandemic control models: the susceptible, exposed, infectious, recovered (SEIR) model with vaccination control; and the SEIR model with shield immunity control. We express the pandemic control requirement in metric temporal logic (MTL) formulas. We then develop an iterative approach for synthesizing the optimal control strategies with MTL specifications. We provide simulation results in two different scenarios for robust control of the COVID-19 pandemic: one for vaccination control, and another for shield immunity control, with the model parameters estimated from data in Lombardy, Italy. The results show that the proposed synthesis approach can generate control inputs such that the time-varying numbers of individuals in each category (e.g., infectious, immune) satisfy the MTL specifications with robustness against initial state and parameter uncertainties.
A Persistent and Context-aware Behavior Tree Framework for Multi Sensor Localization in Autonomous Driving
Mar 26, 2021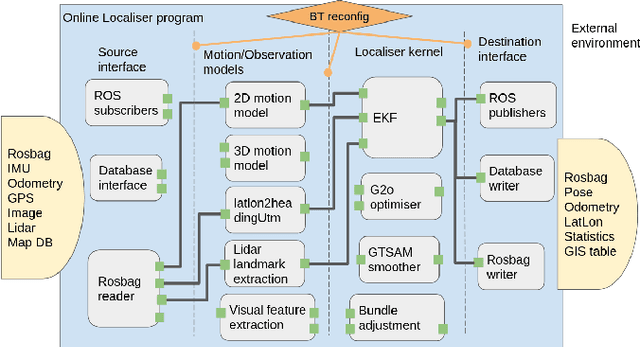
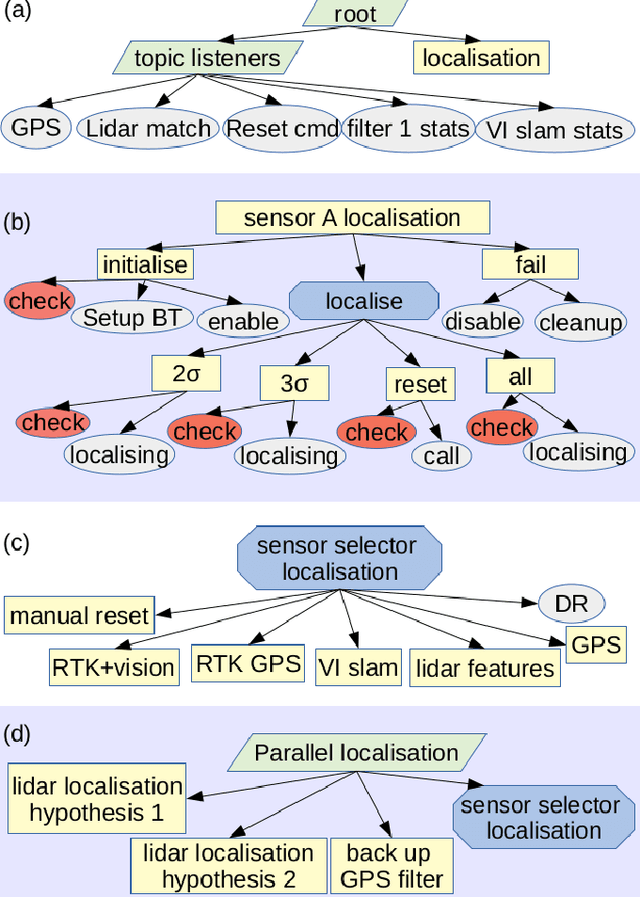
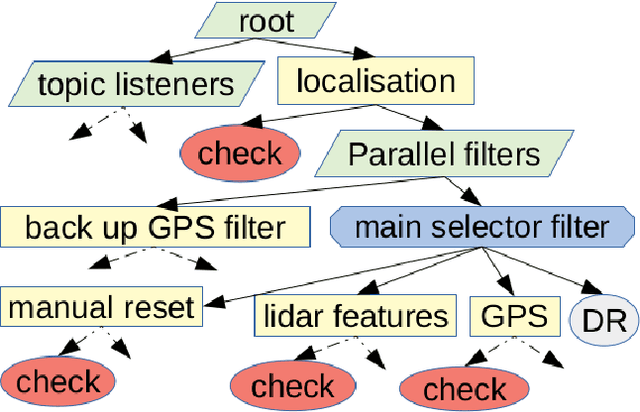
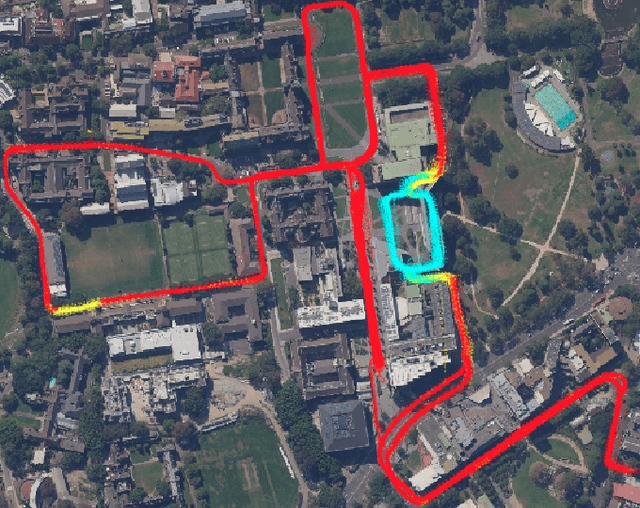
Robust and persistent localisation is essential for ensuring the safe operation of autonomous vehicles. When operating in large and diverse urban driving environments, autonomous vehicles are frequently exposed to situations that violate the assumptions of algorithms, suffer from the failure of one or more sensors, or other events that lead to a loss of localisation. This paper proposes the use of a behavior tree framework that can monitor the performance of localisation health metrics and triggers intelligent responses such as sensor switching and loss recovery. The algorithm presented selects the best available sensor data at given time and location, and can perform a series of actions to react to adverse situations. The behavior tree encapsulates the system-level logic to give commands that make up the intelligent behaviors, so that the localisation "actuators" (data association, optimisation, filters, etc) can perform decoupled actions without needing context. Experimental results to validate the algorithms are presented using the University of Sydney Campus dataset which was taken weekly over an 18 month period. A video showing the online localisation process can be found here: https://youtu.be/353uKqXLV5g
YOLOStereo3D: A Step Back to 2D for Efficient Stereo 3D Detection
Mar 17, 2021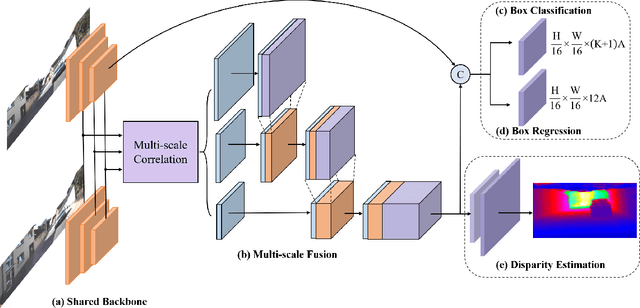
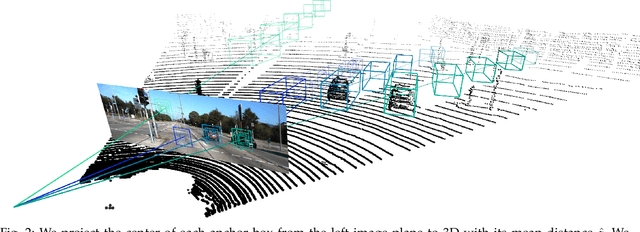
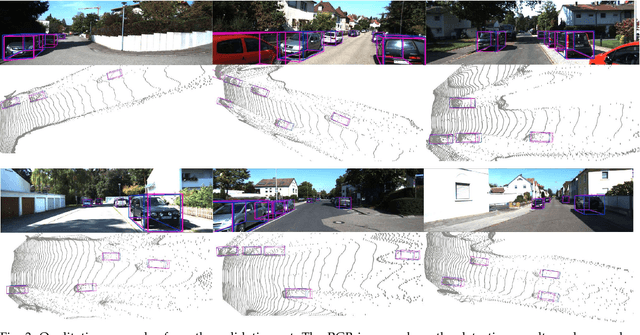
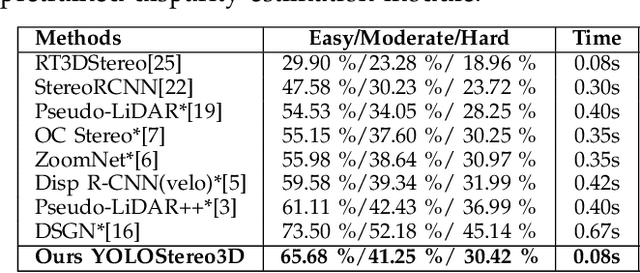
Object detection in 3D with stereo cameras is an important problem in computer vision, and is particularly crucial in low-cost autonomous mobile robots without LiDARs. Nowadays, most of the best-performing frameworks for stereo 3D object detection are based on dense depth reconstruction from disparity estimation, making them extremely computationally expensive. To enable real-world deployments of vision detection with binocular images, we take a step back to gain insights from 2D image-based detection frameworks and enhance them with stereo features. We incorporate knowledge and the inference structure from real-time one-stage 2D/3D object detector and introduce a light-weight stereo matching module. Our proposed framework, YOLOStereo3D, is trained on one single GPU and runs at more than ten fps. It demonstrates performance comparable to state-of-the-art stereo 3D detection frameworks without usage of LiDAR data. The code will be published in https://github.com/Owen-Liuyuxuan/visualDet3D.
Learning Reactive and Predictive Differentiable Controllers for Switching Linear Dynamical Models
Mar 26, 2021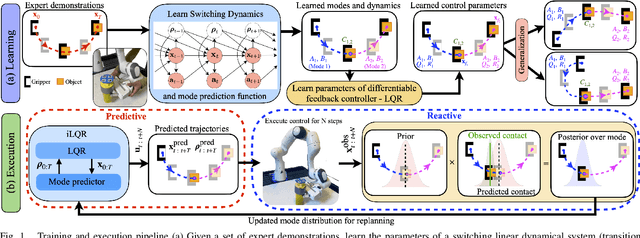
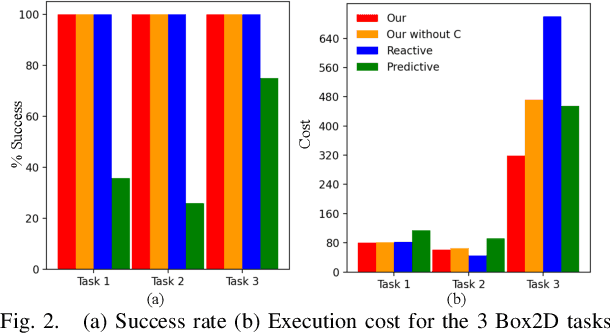
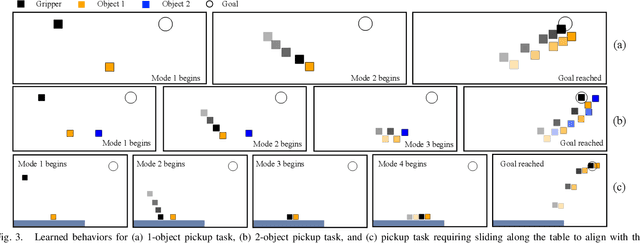

Humans leverage the dynamics of the environment and their own bodies to accomplish challenging tasks such as grasping an object while walking past it or pushing off a wall to turn a corner. Such tasks often involve switching dynamics as the robot makes and breaks contact. Learning these dynamics is a challenging problem and prone to model inaccuracies, especially near contact regions. In this work, we present a framework for learning composite dynamical behaviors from expert demonstrations. We learn a switching linear dynamical model with contacts encoded in switching conditions as a close approximation of our system dynamics. We then use discrete-time LQR as the differentiable policy class for data-efficient learning of control to develop a control strategy that operates over multiple dynamical modes and takes into account discontinuities due to contact. In addition to predicting interactions with the environment, our policy effectively reacts to inaccurate predictions such as unanticipated contacts. Through simulation and real world experiments, we demonstrate generalization of learned behaviors to different scenarios and robustness to model inaccuracies during execution.
Drifting Features: Detection and evaluation in the context of automatic RRLs identification in VVV
May 06, 2021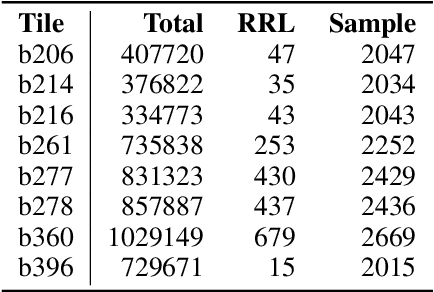
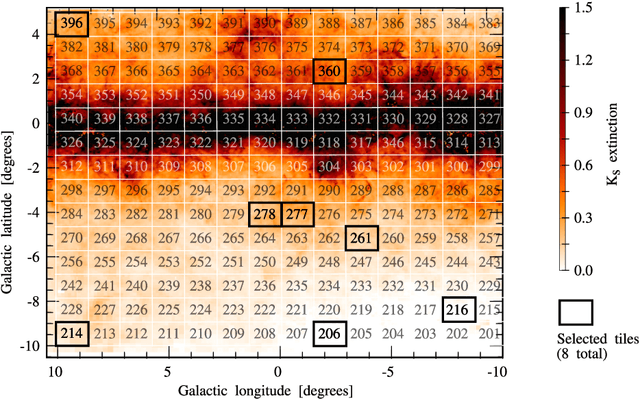
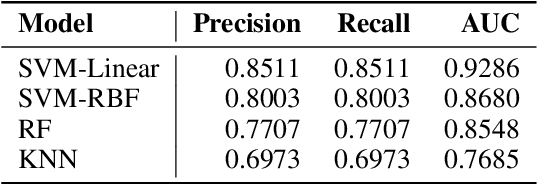
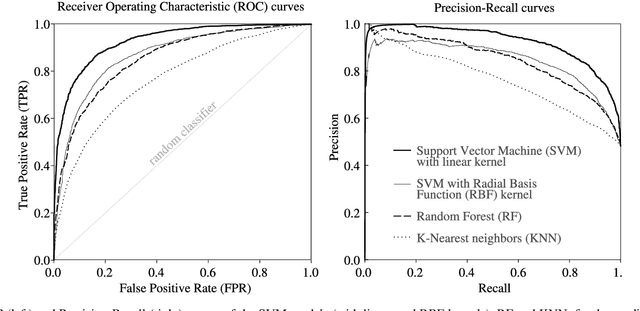
As most of the modern astronomical sky surveys produce data faster than humans can analyze it, Machine Learning (ML) has become a central tool in Astronomy. Modern ML methods can be characterized as highly resistant to some experimental errors. However, small changes on the data over long distances or long periods of time, which cannot be easily detected by statistical methods, can be harmful to these methods. We develop a new strategy to cope with this problem, also using ML methods in an innovative way, to identify these potentially harmful features. We introduce and discuss the notion of Drifting Features, related with small changes in the properties as measured in the data features. We use the identification of RRLs in VVV based on an earlier work and introduce a method for detecting Drifting Features. Our method forces a classifier to learn the tile of origin of diverse sources (mostly stellar 'point sources'), and select the features more relevant to the task of finding candidates to Drifting Features. We show that this method can efficiently identify a reduced set of features that contains useful information about the tile of origin of the sources. For our particular example of detecting RRLs in VVV, we find that Drifting Features are mostly related to color indices. On the other hand, we show that, even if we have a clear set of Drifting Features in our problem, they are mostly insensitive to the identification of RRLs. Drifting Features can be efficiently identified using ML methods. However, in our example, removing Drifting Features does not improve the identification of RRLs.