 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamical prediction of two meteorological factors using the deep neural network and the long short-term memory $(2)$
Apr 28, 2021
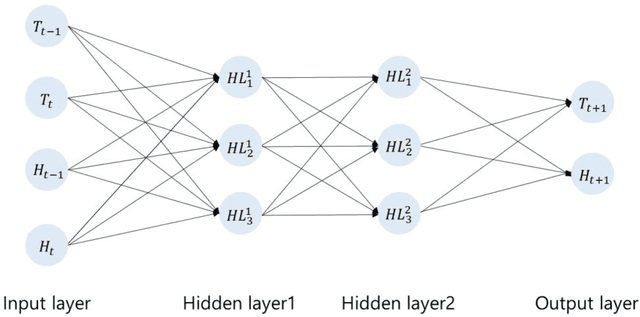
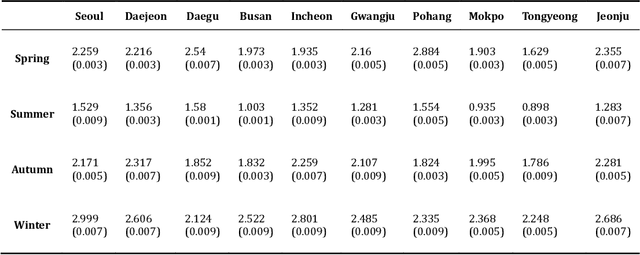
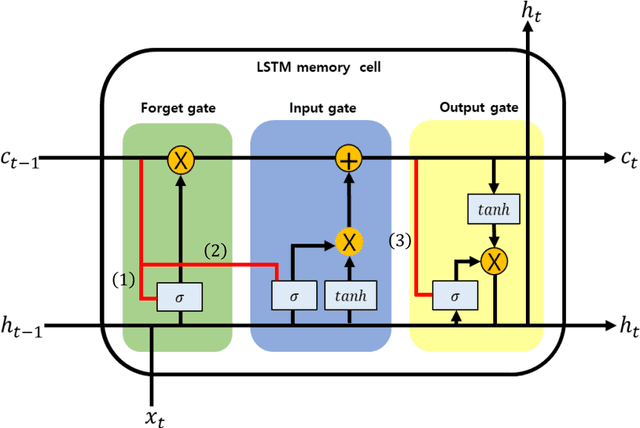
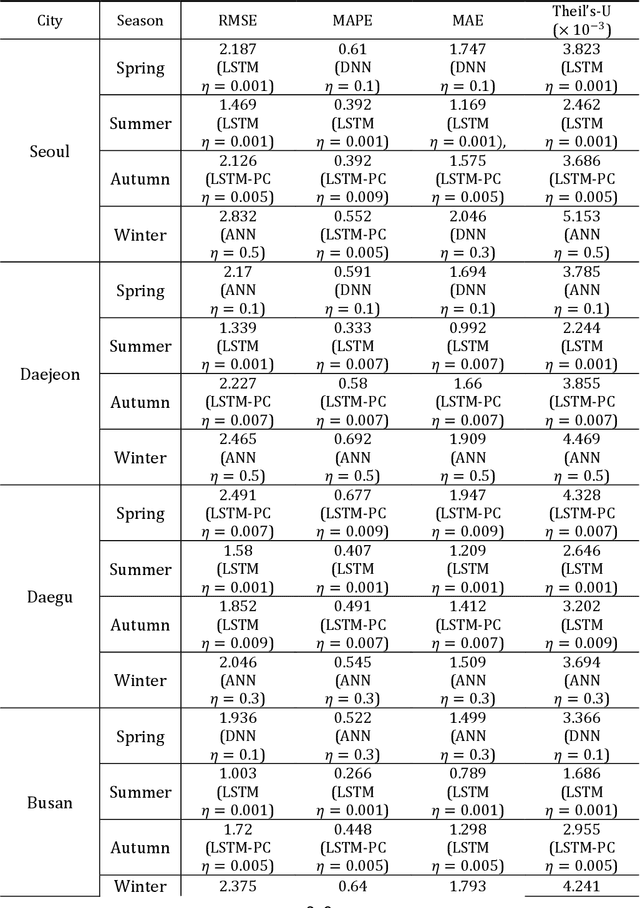
This paper presents the predictive accuracy using two-variate meteorological factors, average temperature and average humidity, in neural network algorithms. We analyze result in five learning architectures such as the traditional artificial neural network, deep neural network, and extreme learning machine, long short-term memory, and long-short-term memory with peephole connections, after manipulating the computer-simulation. Our neural network modes are trained on the daily time-series dataset during seven years (from 2014 to 2020). From the trained results for 2500, 5000, and 7500 epochs, we obtain the predicted accuracies of the meteorological factors produced from outputs in ten metropolitan cities (Seoul, Daejeon, Daegu, Busan, Incheon, Gwangju, Pohang, Mokpo, Tongyeong, and Jeonju). The error statistics is found from the result of outputs, and we compare these values to each other after the manipulation of five neural networks. As using the long-short-term memory model in testing 1 (the average temperature predicted from the input layer with six input nodes), Tonyeong has the lowest root mean squared error (RMSE) value of 0.866 $(%)$ in summer from the computer-simulation in order to predict the temperature. To predict the humidity, the RMSE is shown the lowest value of 5.732 $(%)$, when using the long short-term memory model in summer in Mokpo in testing 2 (the average humidity predicted from the input layer with six input nodes). Particularly, the long short-term memory model is is found to be more accurate in forecasting daily levels than other neural network models in temperature and humidity forecastings. Our result may provide a computer-simuation basis for the necessity of exploring and develping a novel neural network evaluation method in the future.
Hybrid Intelligence
May 03, 2021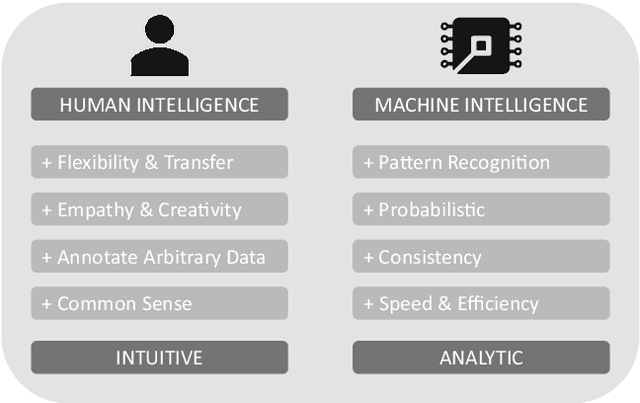
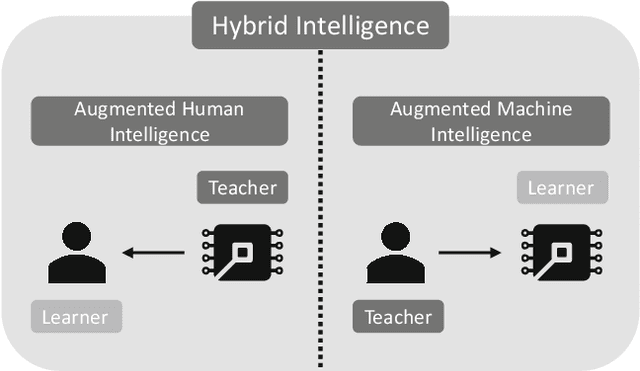
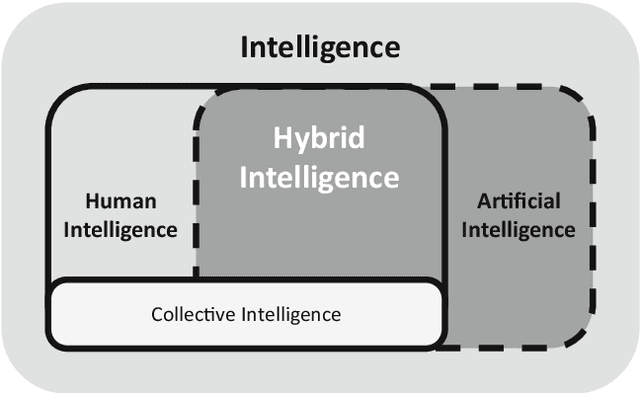
Research has a long history of discussing what is superior in predicting certain outcomes: statistical methods or the human brain. This debate has repeatedly been sparked off by the remarkable technological advances in the field of artificial intelligence (AI), such as solving tasks like object and speech recognition, achieving significant improvements in accuracy through deep-learning algorithms (Goodfellow et al. 2016), or combining various methods of computational intelligence, such as fuzzy logic, genetic algorithms, and case-based reasoning (Medsker 2012). One of the implicit promises that underlie these advancements is that machines will 1 day be capable of performing complex tasks or may even supersede humans in performing these tasks. This triggers new heated debates of when machines will ultimately replace humans (McAfee and Brynjolfsson 2017). While previous research has proved that AI performs well in some clearly defined tasks such as playing chess, playing Go or identifying objects on images, it is doubted that the development of an artificial general intelligence (AGI) which is able to solve multiple tasks at the same time can be achieved in the near future (e.g., Russell and Norvig 2016). Moreover, the use of AI to solve complex business problems in organizational contexts occurs scarcely, and applications for AI that solve complex problems remain mainly in laboratory settings instead of being implemented in practice. Since the road to AGI is still a long one, we argue that the most likely paradigm for the division of labor between humans and machines in the next decades is Hybrid Intelligence. This concept aims at using the complementary strengths of human intelligence and AI, so that they can perform better than each of the two could separately (e.g., Kamar 2016).
A Comparison of Discrete Latent Variable Models for Speech Representation Learning
Oct 24, 2020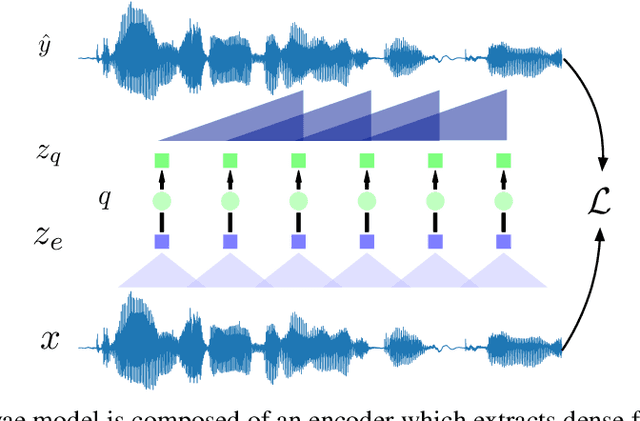
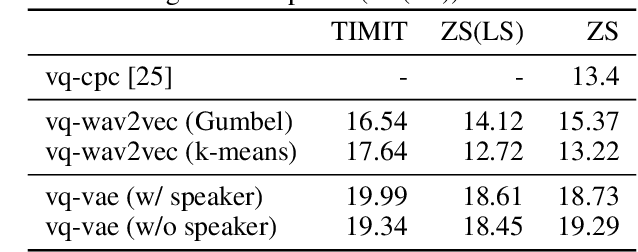
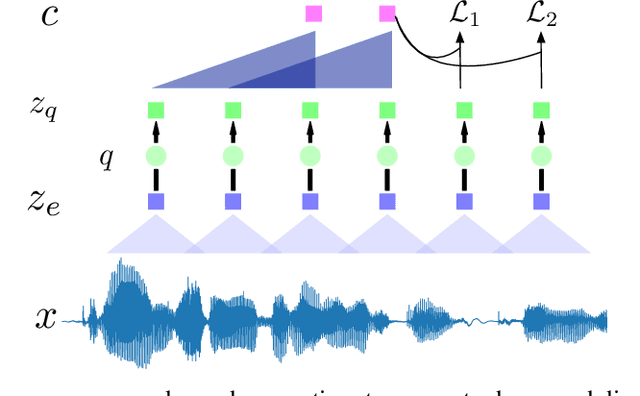
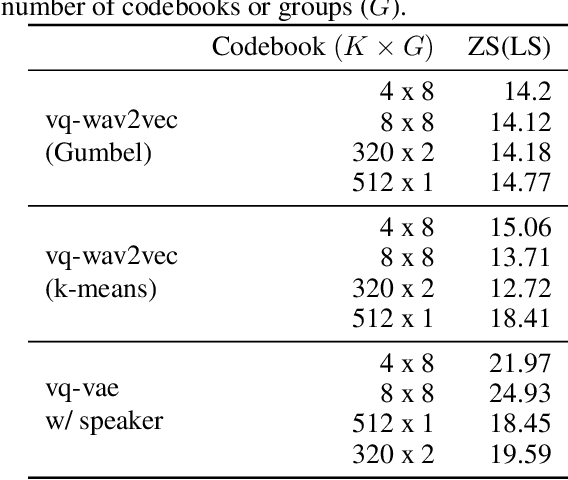
Neural latent variable models enable the discovery of interesting structure in speech audio data. This paper presents a comparison of two different approaches which are broadly based on predicting future time-steps or auto-encoding the input signal. Our study compares the representations learned by vq-vae and vq-wav2vec in terms of sub-word unit discovery and phoneme recognition performance. Results show that future time-step prediction with vq-wav2vec achieves better performance. The best system achieves an error rate of 13.22 on the ZeroSpeech 2019 ABX phoneme discrimination challenge
Learning Hidden Markov Models from Aggregate Observations
Nov 23, 2020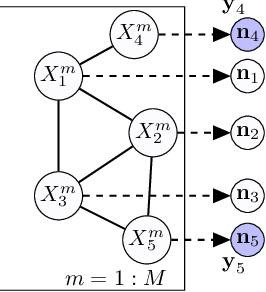
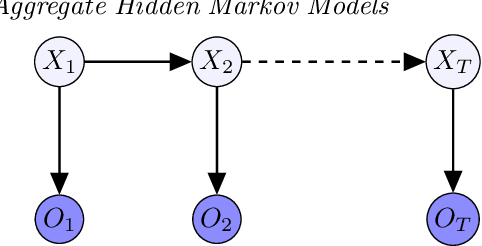
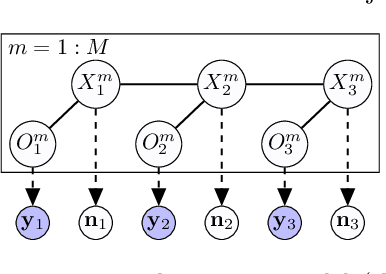
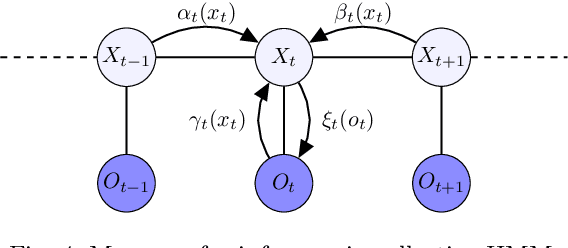
In this paper, we propose an algorithm for estimating the parameters of a time-homogeneous hidden Markov model from aggregate observations. This problem arises when only the population level counts of the number of individuals at each time step are available, from which one seeks to learn the individual hidden Markov model. Our algorithm is built upon expectation-maximization and the recently proposed aggregate inference algorithm, the Sinkhorn belief propagation. As compared with existing methods such as expectation-maximization with non-linear belief propagation, our algorithm exhibits convergence guarantees. Moreover, our learning framework naturally reduces to the standard Baum-Welch learning algorithm when observations corresponding to a single individual are recorded. We further extend our learning algorithm to handle HMMs with continuous observations. The efficacy of our algorithm is demonstrated on a variety of datasets.
Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021
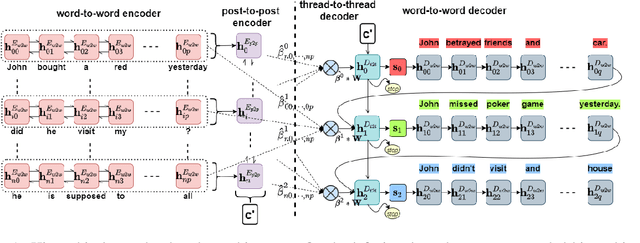

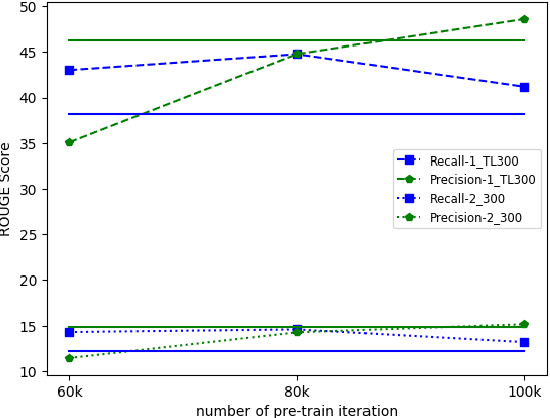
Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.
A Survey on Embedding Dynamic Graphs
Jan 04, 2021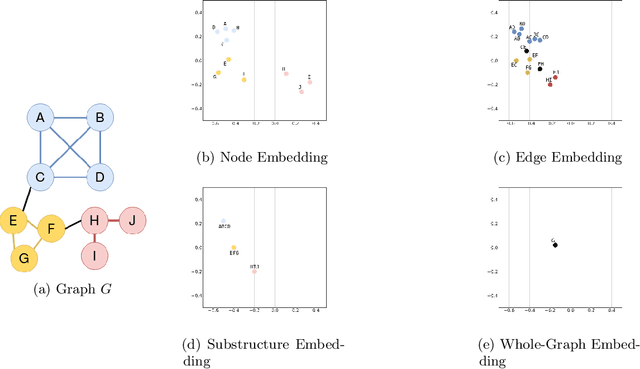


Embedding static graphs in low-dimensional vector spaces plays a key role in network analytics and inference, supporting applications like node classification, link prediction, and graph visualization. However, many real-world networks present dynamic behavior, including topological evolution, feature evolution, and diffusion. Therefore, several methods for embedding dynamic graphs have been proposed to learn network representations over time, facing novel challenges, such as time-domain modeling, temporal features to be captured, and the temporal granularity to be embedded. In this survey, we overview dynamic graph embedding, discussing its fundamentals and the recent advances developed so far. We introduce the formal definition of dynamic graph embedding, focusing on the problem setting and introducing a novel taxonomy for dynamic graph embedding input and output. We further explore different dynamic behaviors that may be encompassed by embeddings, classifying by topological evolution, feature evolution, and processes on networks. Afterward, we describe existing techniques and propose a taxonomy for dynamic graph embedding techniques based on algorithmic approaches, from matrix and tensor factorization to deep learning, random walks, and temporal point processes. We also elucidate main applications, including dynamic link prediction, anomaly detection, and diffusion prediction, and we further state some promising research directions in the area.
Federated Unlearning
Dec 27, 2020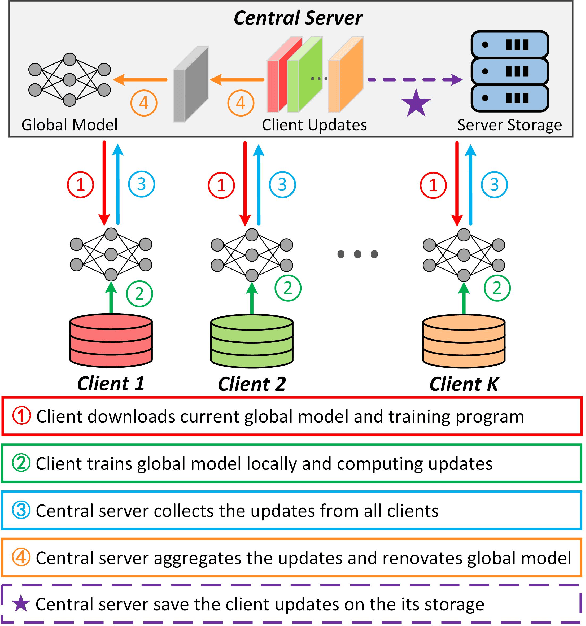
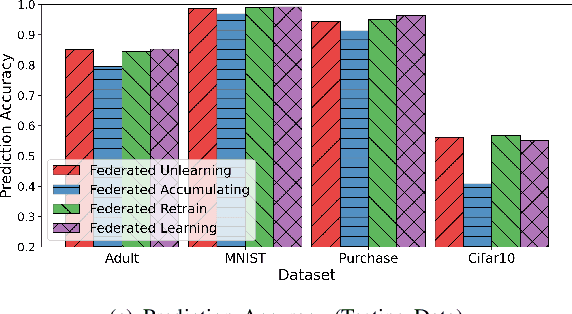
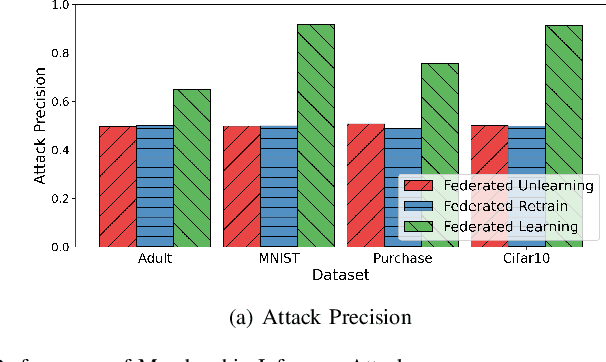
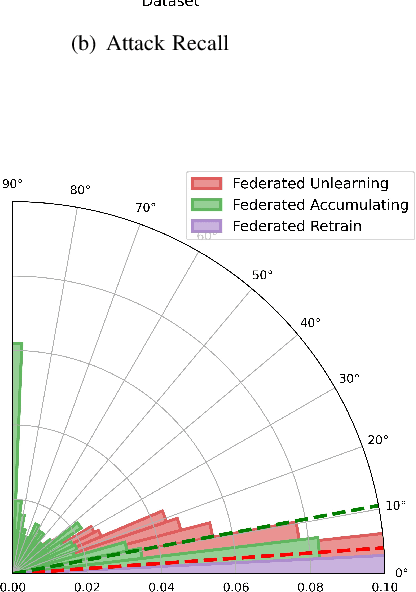
Data removal from machine learning models has been paid more attentions due to the demands of the "right to be forgotten" and countering data poisoning attacks. In this paper, we frame the problem of federated unlearning, a post-process operation of the federated learning models to remove the influence of the specified training sample(s). We present FedEraser, the first federated unlearning methodology that can eliminate the influences of a federated client's data on the global model while significantly reducing the time consumption used for constructing the unlearned model. The core idea of FedEraser is to trade the central server's storage for unlearned model's construction time. In particular, FedEraser reconstructs the unlearned model by leveraging the historical parameter updates of federated clients that have been retained at the central server during the training process of FL. A novel calibration method is further developed to calibrate the retained client updates, which can provide a significant speed-up to the reconstruction of the unlearned model. Experiments on four realistic datasets demonstrate the effectiveness of FedEraser, with an expected speed-up of $4\times$ compared with retraining from the scratch.
On the Power of Localized Perceptron for Label-Optimal Learning of Halfspaces with Adversarial Noise
Jan 20, 2021
We study {\em online} active learning of homogeneous halfspaces in $\mathbb{R}^d$ with adversarial noise where the overall probability of a noisy label is constrained to be at most $\nu$. Our main contribution is a Perceptron-like online active learning algorithm that runs in polynomial time, and under the conditions that the marginal distribution is isotropic log-concave and $\nu = \Omega(\epsilon)$, where $\epsilon \in (0, 1)$ is the target error rate, our algorithm PAC learns the underlying halfspace with near-optimal label complexity of $\tilde{O}\big(d \cdot polylog(\frac{1}{\epsilon})\big)$ and sample complexity of $\tilde{O}\big(\frac{d}{\epsilon} \big)$. Prior to this work, existing online algorithms designed for tolerating the adversarial noise are subject to either label complexity polynomial in $\frac{1}{\epsilon}$, or suboptimal noise tolerance, or restrictive marginal distributions. With the additional prior knowledge that the underlying halfspace is $s$-sparse, we obtain attribute-efficient label complexity of $\tilde{O}\big( s \cdot polylog(d, \frac{1}{\epsilon}) \big)$ and sample complexity of $\tilde{O}\big(\frac{s}{\epsilon} \cdot polylog(d) \big)$. As an immediate corollary, we show that under the agnostic model where no assumption is made on the noise rate $\nu$, our active learner achieves an error rate of $O(OPT) + \epsilon$ with the same running time and label and sample complexity, where $OPT$ is the best possible error rate achievable by any homogeneous halfspace.
Rethinking Automatic Evaluation in Sentence Simplification
Apr 16, 2021
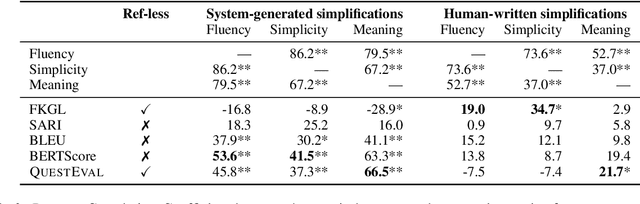
Automatic evaluation remains an open research question in Natural Language Generation. In the context of Sentence Simplification, this is particularly challenging: the task requires by nature to replace complex words with simpler ones that shares the same meaning. This limits the effectiveness of n-gram based metrics like BLEU. Going hand in hand with the recent advances in NLG, new metrics have been proposed, such as BERTScore for Machine Translation. In summarization, the QuestEval metric proposes to automatically compare two texts by questioning them. In this paper, we first propose a simple modification of QuestEval allowing it to tackle Sentence Simplification. We then extensively evaluate the correlations w.r.t. human judgement for several metrics including the recent BERTScore and QuestEval, and show that the latter obtain state-of-the-art correlations, outperforming standard metrics like BLEU and SARI. More importantly, we also show that a large part of the correlations are actually spurious for all the metrics. To investigate this phenomenon further, we release a new corpus of evaluated simplifications, this time not generated by systems but instead, written by humans. This allows us to remove the spurious correlations and draw very different conclusions from the original ones, resulting in a better understanding of these metrics. In particular, we raise concerns about very low correlations for most of traditional metrics. Our results show that the only significant measure of the Meaning Preservation is our adaptation of QuestEval.
Environment and Person Independent Activity Recognition with a Commodity IEEE 802.11ac Access Point
Mar 17, 2021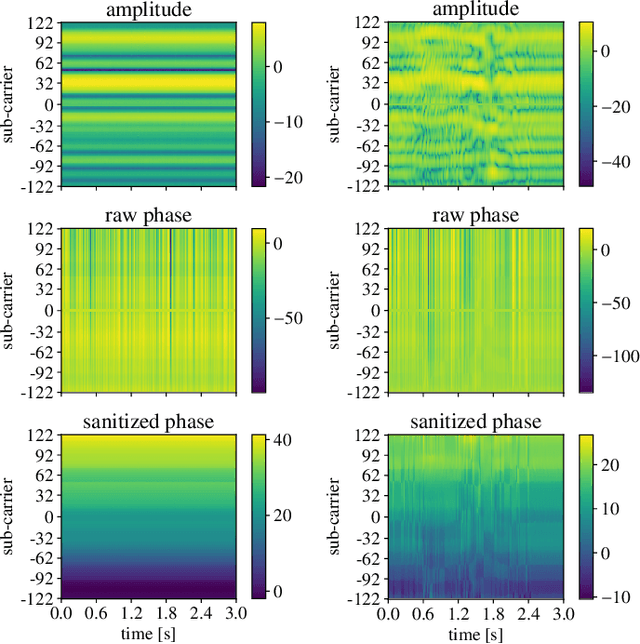
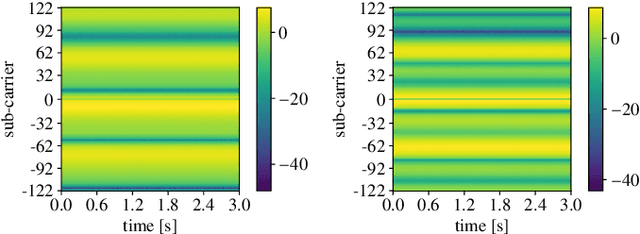
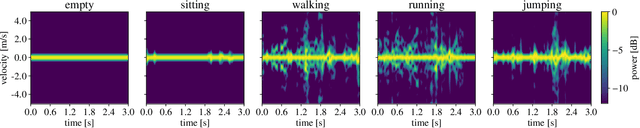
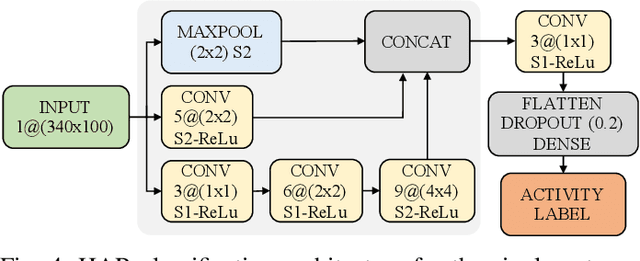
Here, we propose an original approach for human activity recognition (HAR) with commercial IEEE 802.11ac (WiFi) devices, which generalizes across different persons, days and environments. To achieve this, we devise a technique to extract, clean and process the received phases from the channel frequency response (CFR) of the WiFi channel, obtaining an estimate of the Doppler shift at the receiver of the communication link. The Doppler shift reveals the presence of moving scatterers in the environment, while not being affected by (environment specific) static objects. The proposed HAR framework is trained on data collected as a person performs four different activities and is tested on unseen setups, to assess its performance as the person, the day and/or the environment change with respect to those considered at training time. In the worst case scenario, the proposed HAR technique reaches an average accuracy higher than 95%, validating the effectiveness of the extracted Doppler information, used in conjunction with a learning algorithm based on a neural network, in recognizing human activities in a subject and environment independent fashion.