 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Ultrasound Rendering from Cross-Sectional Model Slices for Simulated Training
Jan 20, 2021
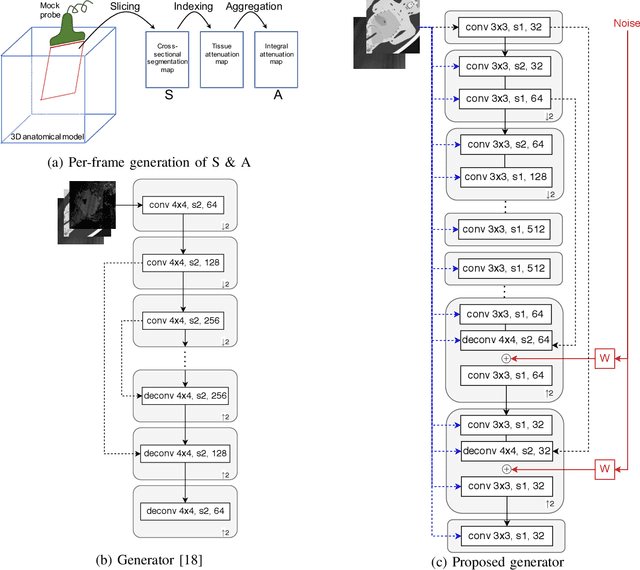

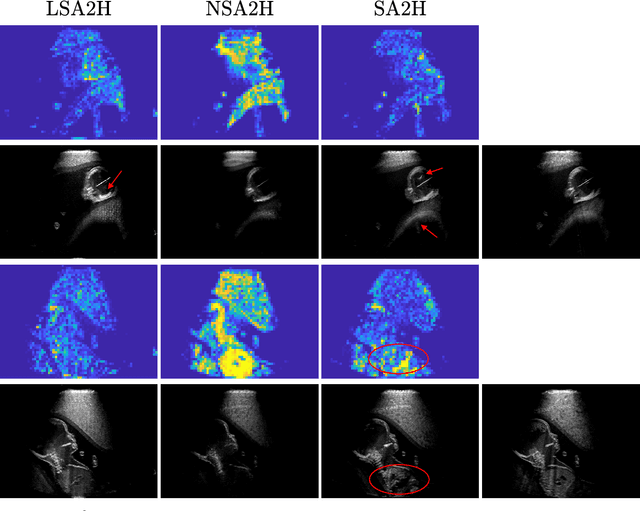
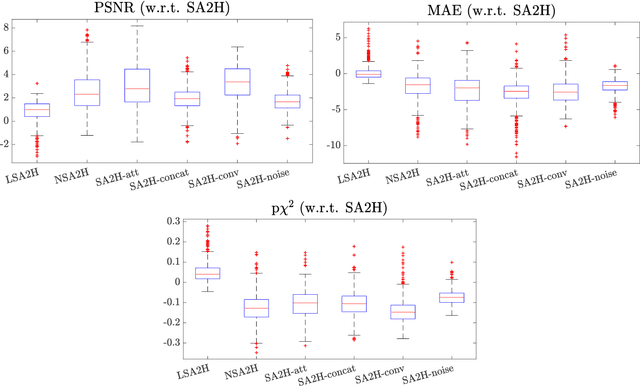
Purpose. Given the high level of expertise required for navigation and interpretation of ultrasound images, computational simulations can facilitate the training of such skills in virtual reality. With ray-tracing based simulations, realistic ultrasound images can be generated. However, due to computational constraints for interactivity, image quality typically needs to be compromised. Methods. We propose herein to bypass any rendering and simulation process at interactive time, by conducting such simulations during a non-time-critical offline stage and then learning image translation from cross-sectional model slices to such simulated frames. We use a generative adversarial framework with a dedicated generator architecture and input feeding scheme, which both substantially improve image quality without increase in network parameters. Integral attenuation maps derived from cross-sectional model slices, texture-friendly strided convolutions, providing stochastic noise and input maps to intermediate layers in order to preserve locality are all shown herein to greatly facilitate such translation task. Results. Given several quality metrics, the proposed method with only tissue maps as input is shown to provide comparable or superior results to a state-of-the-art that uses additional images of low-quality ultrasound renderings. An extensive ablation study shows the need and benefits from the individual contributions utilized in this work, based on qualitative examples and quantitative ultrasound similarity metrics. To that end, a local histogram statistics based error metric is proposed and demonstrated for visualization of local dissimilarities between ultrasound images.
Dory: Overcoming Barriers to Computing Persistent Homology
Mar 09, 2021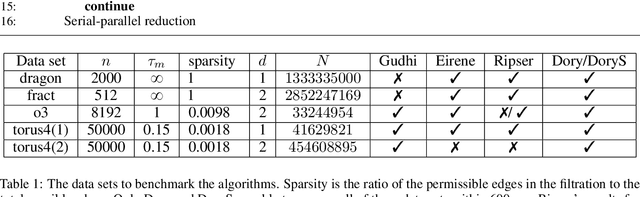
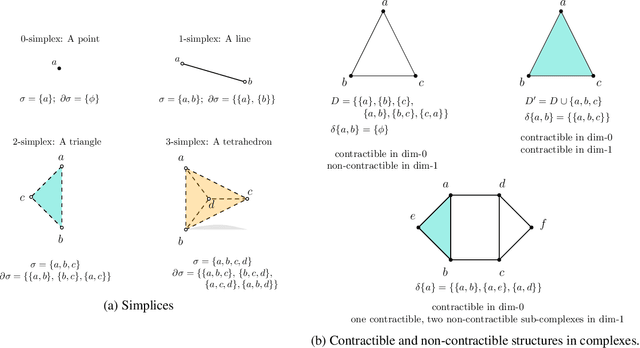
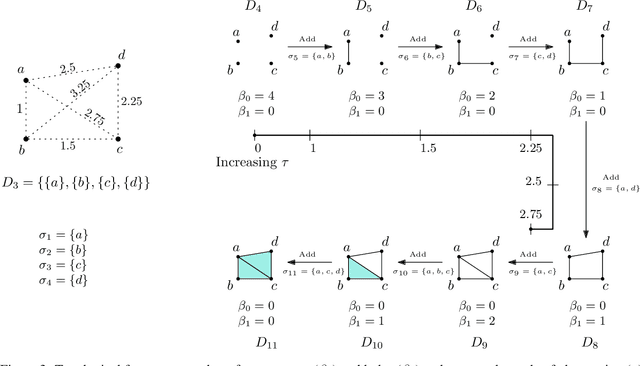
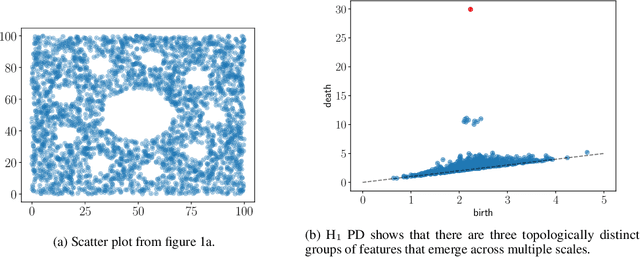
Persistent homology (PH) is an approach to topological data analysis (TDA) that computes multi-scale topologically invariant properties of high-dimensional data that are robust to noise. While PH has revealed useful patterns across various applications, computational requirements have limited applications to small data sets of a few thousand points. We present Dory, an efficient and scalable algorithm that can compute the persistent homology of large data sets. Dory uses significantly less memory than published algorithms and also provides significant reductions in the computation time compared to most algorithms. It scales to process data sets with millions of points. As an application, we compute the PH of the human genome at high resolution as revealed by a genome-wide Hi-C data set. Results show that the topology of the human genome changes significantly upon treatment with auxin, a molecule that degrades cohesin, corroborating the hypothesis that cohesin plays a crucial role in loop formation in DNA.
A Comparison of Discrete Latent Variable Models for Speech Representation Learning
Oct 24, 2020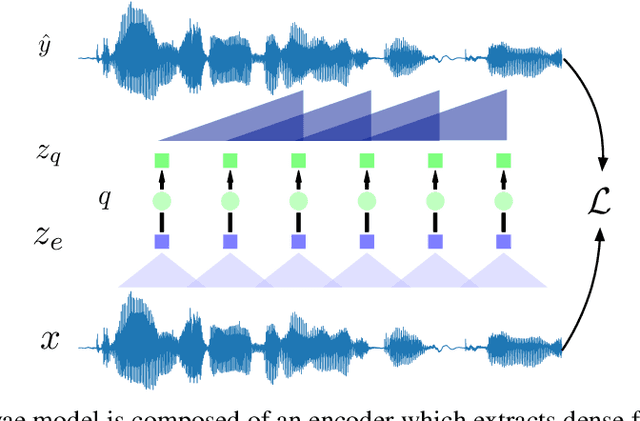
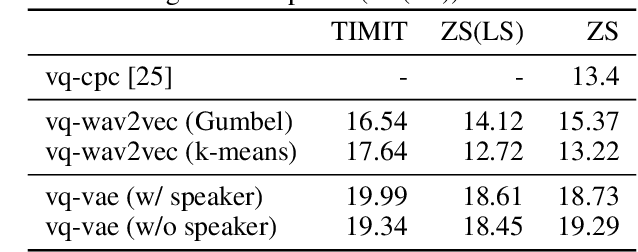
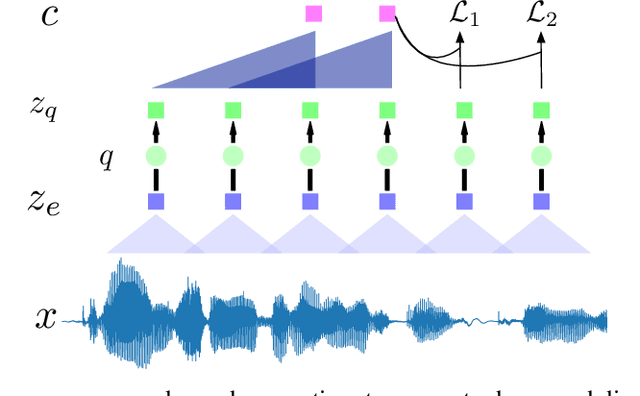
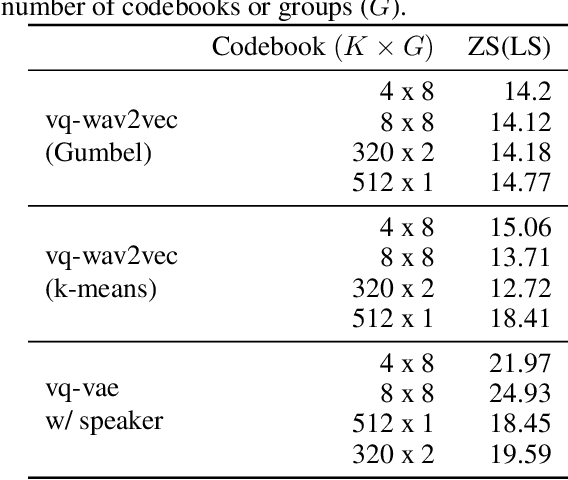
Neural latent variable models enable the discovery of interesting structure in speech audio data. This paper presents a comparison of two different approaches which are broadly based on predicting future time-steps or auto-encoding the input signal. Our study compares the representations learned by vq-vae and vq-wav2vec in terms of sub-word unit discovery and phoneme recognition performance. Results show that future time-step prediction with vq-wav2vec achieves better performance. The best system achieves an error rate of 13.22 on the ZeroSpeech 2019 ABX phoneme discrimination challenge
Hybrid Model for Anomaly Detection on Call Detail Records by Time Series Forecasting
Jun 07, 2020
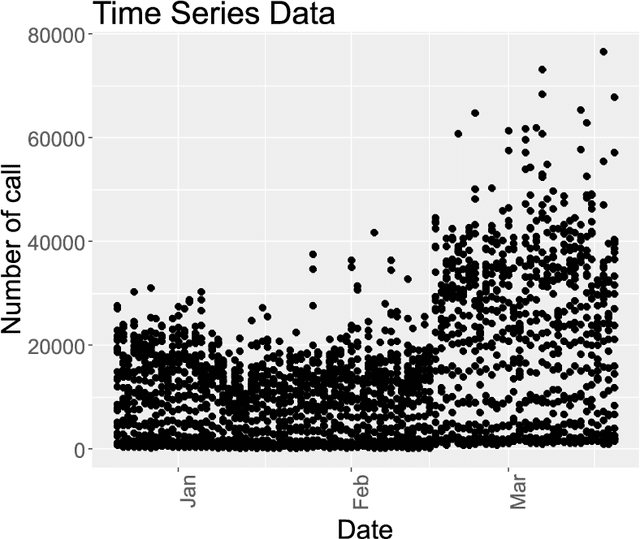
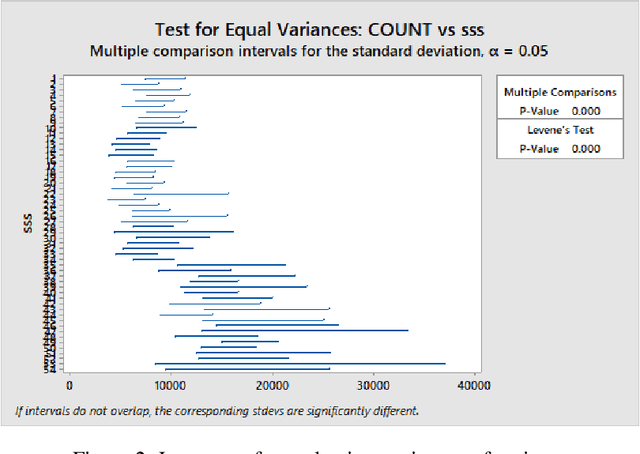
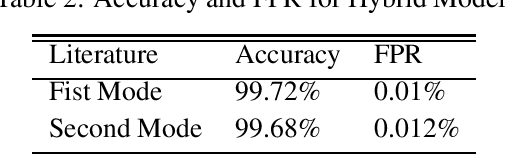
Mobile network operators store an enormous amount of information like log files that describe various events and users' activities. Analysis of these logs might be used in many critical applications such as detecting cyber-attacks, finding behavioral patterns of users, security incident response, network forensics, etc. In a cellular network Call Detail Records (CDR) is one type of such logs containing metadata of calls and usually includes valuable information about contact such as the phone numbers of originating and receiving subscribers, call duration, the area of activity, type of call (SMS or voice call) and a timestamp. With anomaly detection, it is possible to determine abnormal reduction or increment of network traffic in an area or for a particular person. This paper's primary goal is to study subscribers' behavior in a cellular network, mainly predicting the number of calls in a region and detecting anomalies in the network traffic. In this paper, a new hybrid method is proposed based on various anomaly detection methods such as GARCH, K-means, and Neural Network to determine the anomalous data. Moreover, we have discussed the possible causes of such anomalies.
Variational models for signal processing with Graph Neural Networks
Apr 03, 2021
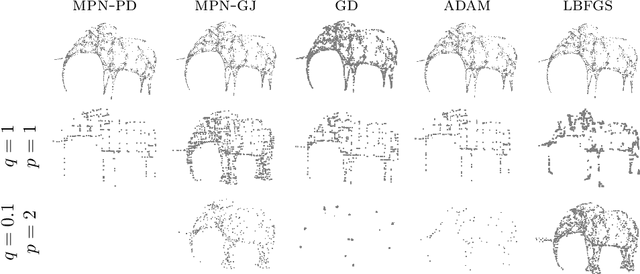

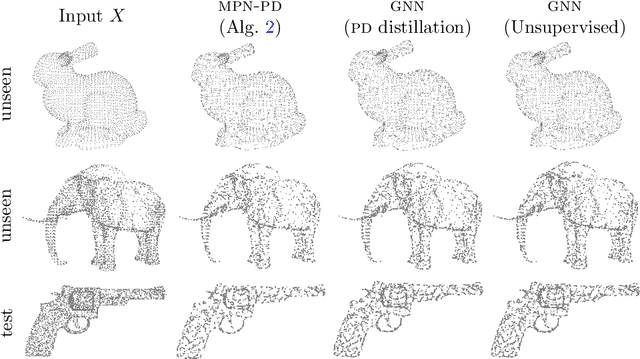
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning. Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning
Divide-and-conquer methods for big data analysis
Feb 22, 2021In the context of big data analysis, the divide-and-conquer methodology refers to a multiple-step process: first splitting a data set into several smaller ones; then analyzing each set separately; finally combining results from each analysis together. This approach is effective in handling large data sets that are unsuitable to be analyzed entirely by a single computer due to limits either from memory storage or computational time. The combined results will provide a statistical inference which is similar to the one from analyzing the entire data set. This article reviews some recently developments of divide-and-conquer methods in a variety of settings, including combining based on parametric, semiparametric and nonparametric models, online sequential updating methods, among others. Theoretical development on the efficiency of the divide-and-conquer methods is also discussed.
Hierarchical Graph-RNNs for Action Detection of Multiple Activities
Jan 21, 2021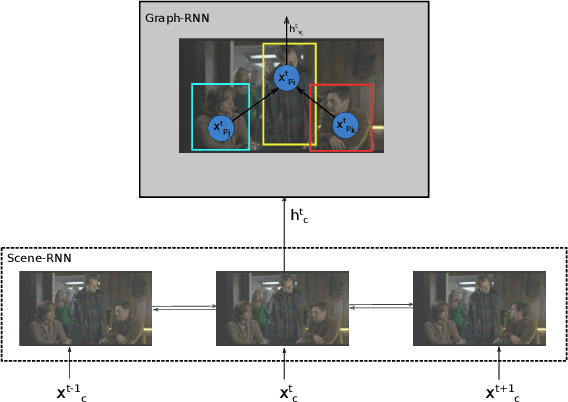



In this paper, we propose an approach that spatially localizes the activities in a video frame where each person can perform multiple activities at the same time. Our approach takes the temporal scene context as well as the relations of the actions of detected persons into account. While the temporal context is modeled by a temporal recurrent neural network (RNN), the relations of the actions are modeled by a graph RNN. Both networks are trained together and the proposed approach achieves state of the art results on the AVA dataset.
Learning Hidden Markov Models from Aggregate Observations
Nov 23, 2020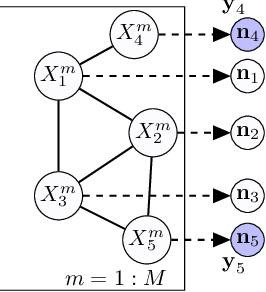
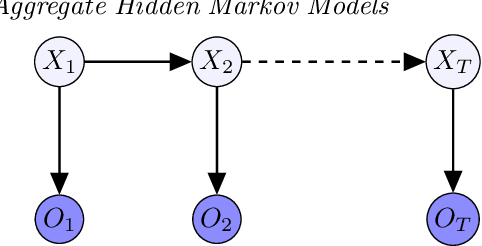
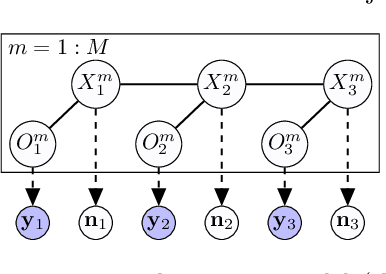
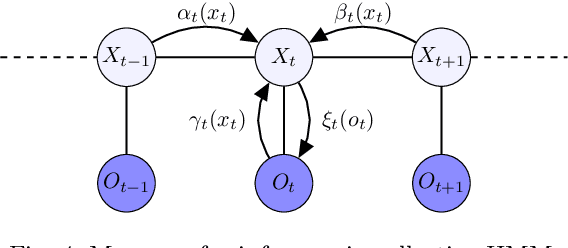
In this paper, we propose an algorithm for estimating the parameters of a time-homogeneous hidden Markov model from aggregate observations. This problem arises when only the population level counts of the number of individuals at each time step are available, from which one seeks to learn the individual hidden Markov model. Our algorithm is built upon expectation-maximization and the recently proposed aggregate inference algorithm, the Sinkhorn belief propagation. As compared with existing methods such as expectation-maximization with non-linear belief propagation, our algorithm exhibits convergence guarantees. Moreover, our learning framework naturally reduces to the standard Baum-Welch learning algorithm when observations corresponding to a single individual are recorded. We further extend our learning algorithm to handle HMMs with continuous observations. The efficacy of our algorithm is demonstrated on a variety of datasets.
Learning discrete Bayesian networks in polynomial time and sample complexity
Oct 05, 2018
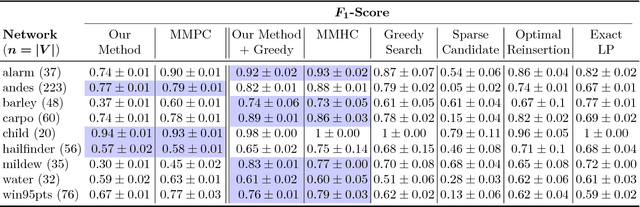
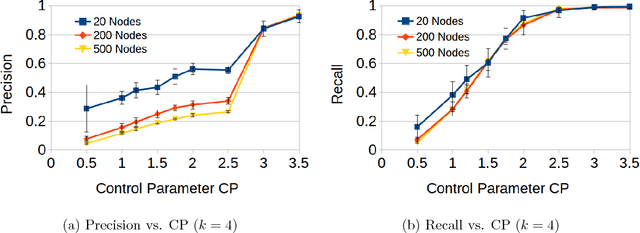
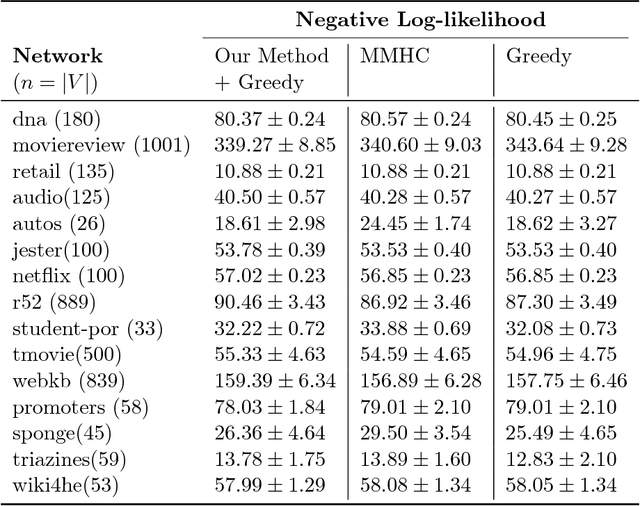
In this paper, we study the problem of structure learning for Bayesian networks in which nodes take discrete values. The problem is NP-hard in general but we show that under certain conditions we can recover the true structure of a Bayesian network with sufficient number of samples. We develop a mathematical model which does not assume any specific conditional probability distributions for the nodes. We use a primal-dual witness construction to prove that, under some technical conditions on the interaction between node pairs, we can do exact recovery of the parents and children of a node by performing group l_12-regularized multivariate regression. Thus, we recover the true Bayesian network structure. If degree of a node is bounded then the sample complexity of our proposed approach grows logarithmically with respect to the number of nodes in the Bayesian network. Furthermore, our method runs in polynomial time.
PSpan:Mining Frequent Subnets of Petri Nets
Jan 28, 2021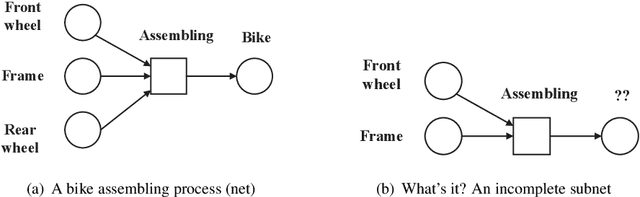

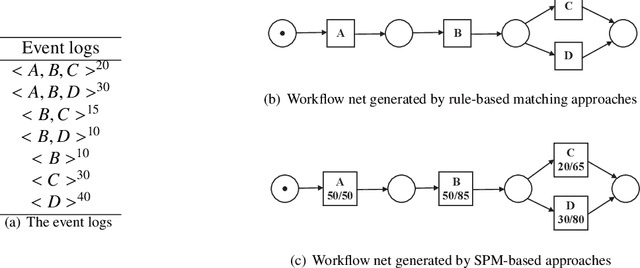
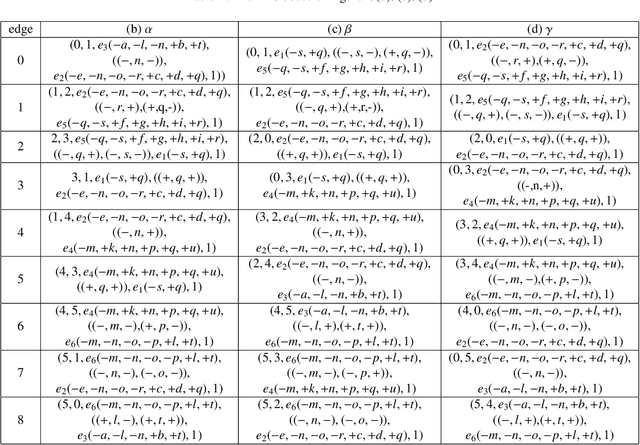
This paper proposes for the first time an algorithm PSpan for mining frequent complete subnets from a set of Petri nets. We introduced the concept of complete subnets and the net graph representation. PSpan transforms Petri nets in net graphs and performs sub-net graph mining on them, then transforms the results back to frequent subnets. PSpan follows the pattern growth approach and has similar complexity like gSpan in graph mining. Experiments have been done to confirm PSpan's reliability and complexity. Besides C/E nets, it applies also to a set of other Petri net subclasses.