 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Divide-and-conquer methods for big data analysis
Feb 22, 2021
In the context of big data analysis, the divide-and-conquer methodology refers to a multiple-step process: first splitting a data set into several smaller ones; then analyzing each set separately; finally combining results from each analysis together. This approach is effective in handling large data sets that are unsuitable to be analyzed entirely by a single computer due to limits either from memory storage or computational time. The combined results will provide a statistical inference which is similar to the one from analyzing the entire data set. This article reviews some recently developments of divide-and-conquer methods in a variety of settings, including combining based on parametric, semiparametric and nonparametric models, online sequential updating methods, among others. Theoretical development on the efficiency of the divide-and-conquer methods is also discussed.
Learning Ultrasound Rendering from Cross-Sectional Model Slices for Simulated Training
Jan 20, 2021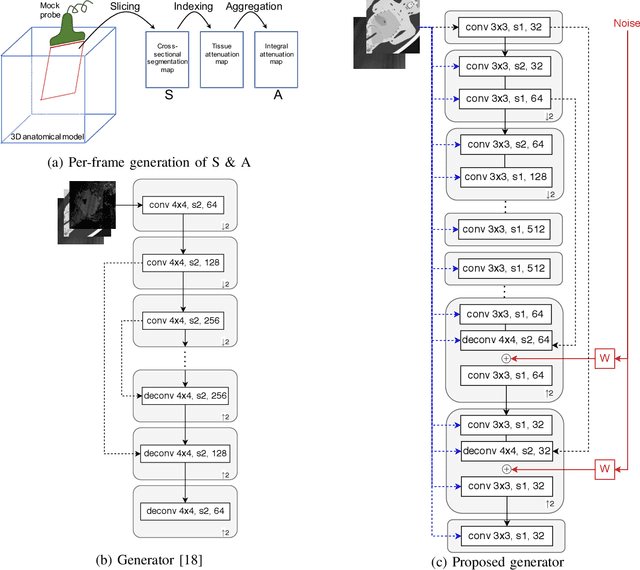

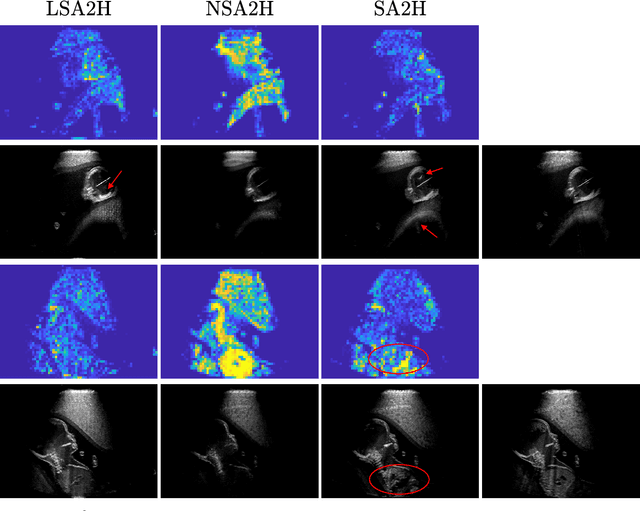
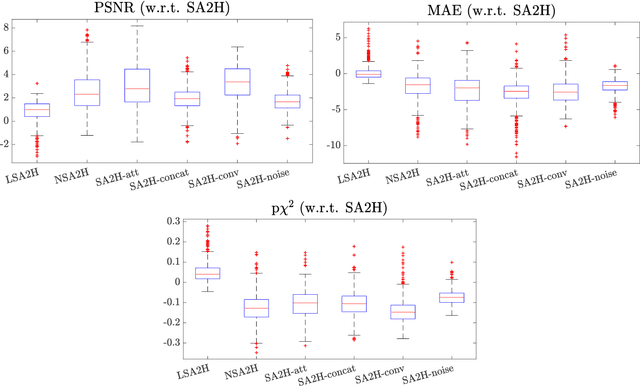
Purpose. Given the high level of expertise required for navigation and interpretation of ultrasound images, computational simulations can facilitate the training of such skills in virtual reality. With ray-tracing based simulations, realistic ultrasound images can be generated. However, due to computational constraints for interactivity, image quality typically needs to be compromised. Methods. We propose herein to bypass any rendering and simulation process at interactive time, by conducting such simulations during a non-time-critical offline stage and then learning image translation from cross-sectional model slices to such simulated frames. We use a generative adversarial framework with a dedicated generator architecture and input feeding scheme, which both substantially improve image quality without increase in network parameters. Integral attenuation maps derived from cross-sectional model slices, texture-friendly strided convolutions, providing stochastic noise and input maps to intermediate layers in order to preserve locality are all shown herein to greatly facilitate such translation task. Results. Given several quality metrics, the proposed method with only tissue maps as input is shown to provide comparable or superior results to a state-of-the-art that uses additional images of low-quality ultrasound renderings. An extensive ablation study shows the need and benefits from the individual contributions utilized in this work, based on qualitative examples and quantitative ultrasound similarity metrics. To that end, a local histogram statistics based error metric is proposed and demonstrated for visualization of local dissimilarities between ultrasound images.
Planning with Pixels in (Almost) Real Time
Jan 10, 2018
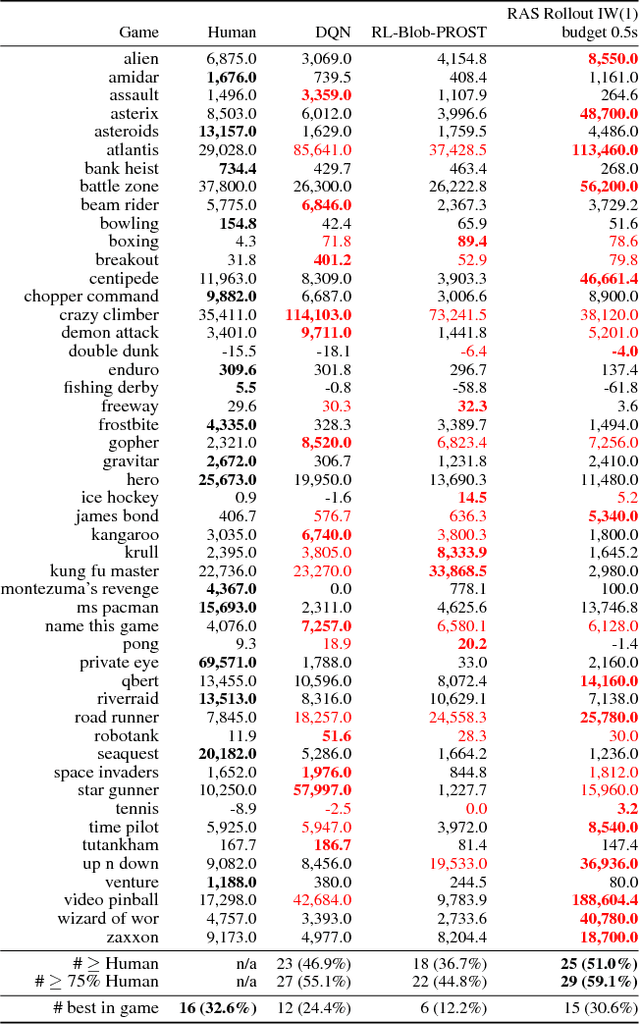
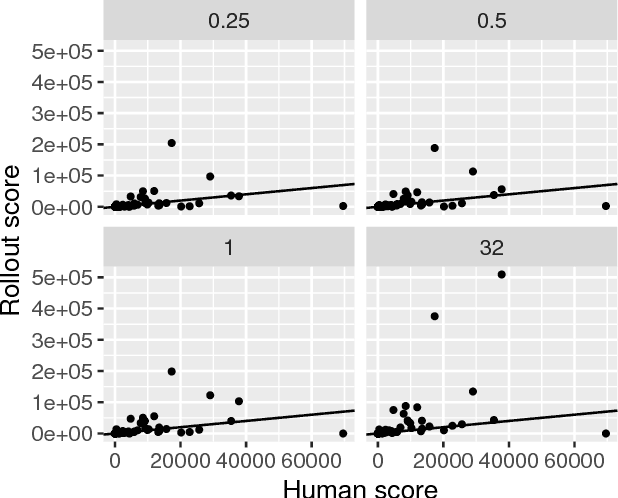
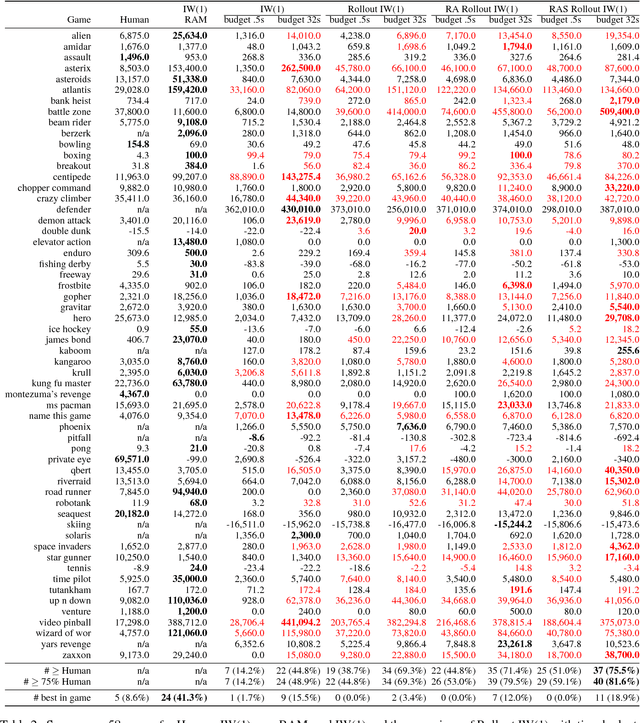
Recently, width-based planning methods have been shown to yield state-of-the-art results in the Atari 2600 video games. For this, the states were associated with the (RAM) memory states of the simulator. In this work, we consider the same planning problem but using the screen instead. By using the same visual inputs, the planning results can be compared with those of humans and learning methods. We show that the planning approach, out of the box and without training, results in scores that compare well with those obtained by humans and learning methods, and moreover, by developing an episodic, rollout version of the IW(k) algorithm, we show that such scores can be obtained in almost real time.
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 09, 2021
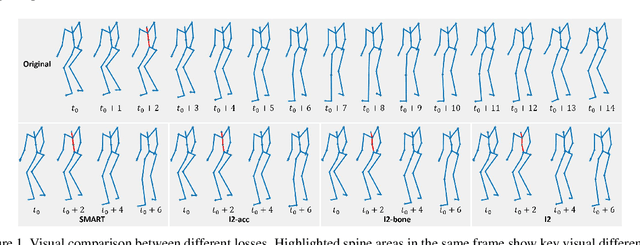
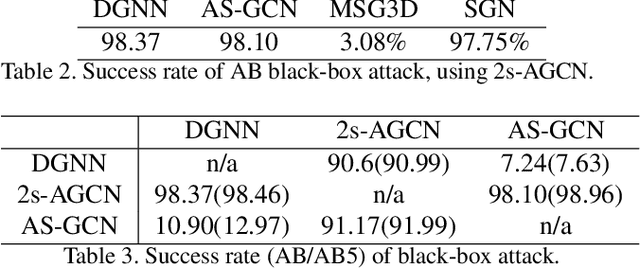

Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
A Mask R-CNN approach to counting bacterial colony forming units in pharmaceutical development
Mar 09, 2021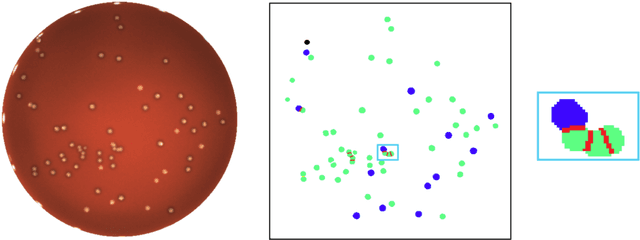
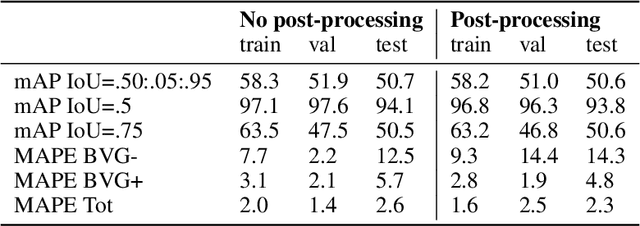
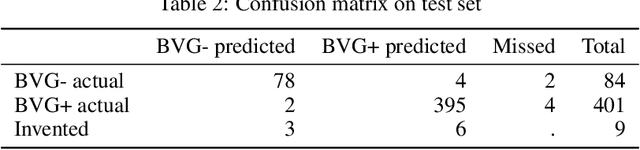
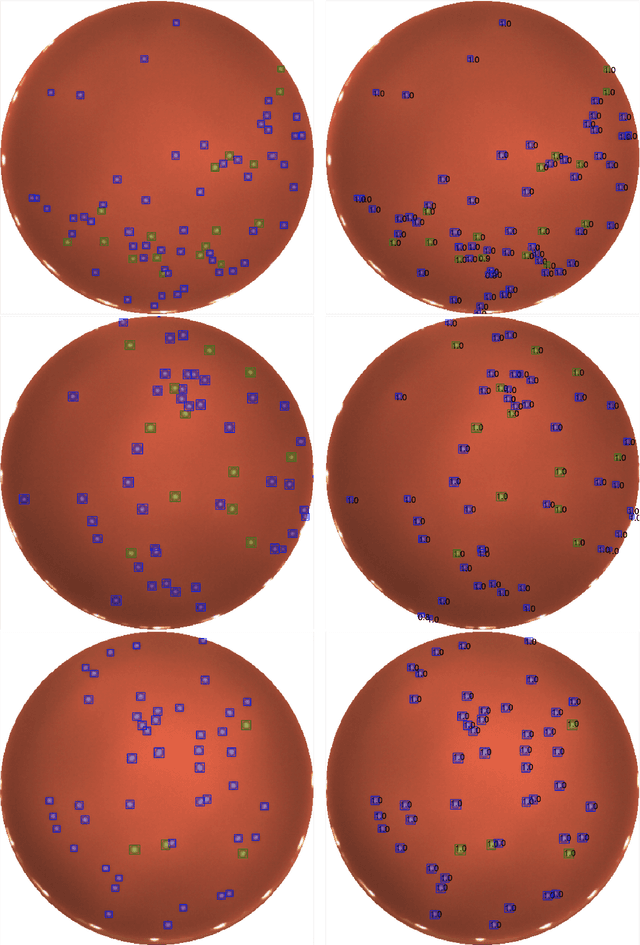
We present an application of the well-known Mask R-CNN approach to the counting of different types of bacterial colony forming units that were cultured in Petri dishes. Our model was made available to lab technicians in a modern SPA (Single-Page Application). Users can upload images of dishes, after which the Mask R-CNN model that was trained and tuned specifically for this task detects the number of BVG- and BVG+ colonies and displays these in an interactive interface for the user to verify. Users can then check the model's predictions, correct them if deemed necessary, and finally validate them. Our adapted Mask R-CNN model achieves a mean average precision (mAP) of 94\% at an intersection-over-union (IoU) threshold of 50\%. With these encouraging results, we see opportunities to bring the benefits of improved accuracy and time saved to related problems, such as generalising to other bacteria types and viral foci counting.
Autoencoding Time Series for Visualisation
May 05, 2015
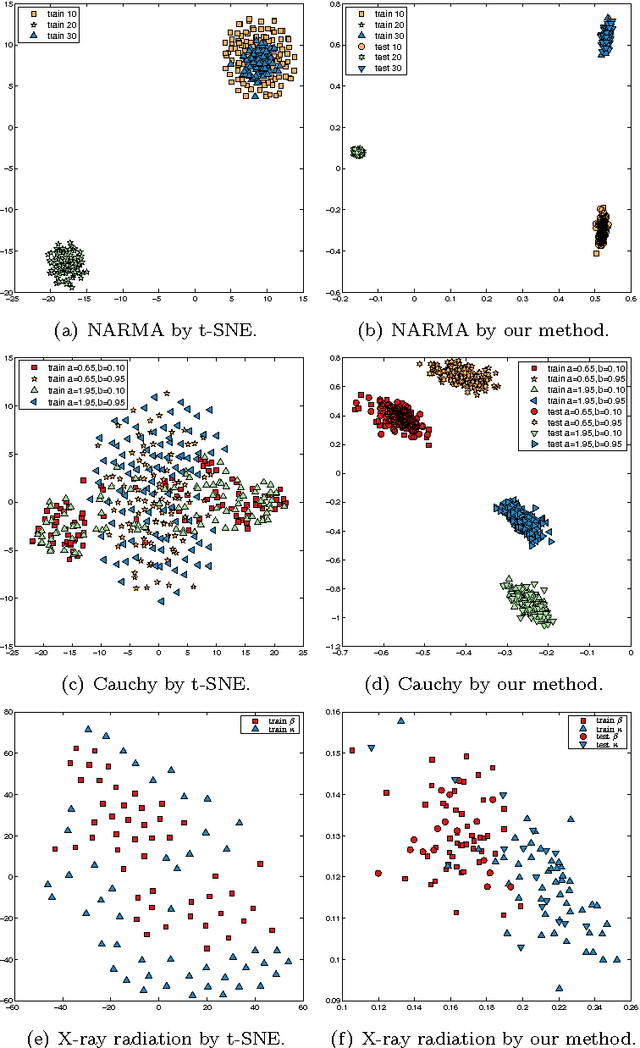
We present an algorithm for the visualisation of time series. To that end we employ echo state networks to convert time series into a suitable vector representation which is capable of capturing the latent dynamics of the time series. Subsequently, the obtained vector representations are put through an autoencoder and the visualisation is constructed using the activations of the bottleneck. The crux of the work lies with defining an objective function that quantifies the reconstruction error of these representations in a principled manner. We demonstrate the method on synthetic and real data.
Landmark-Aware and Part-based Ensemble Transfer Learning Network for Facial Expression Recognition from Static images
Apr 22, 2021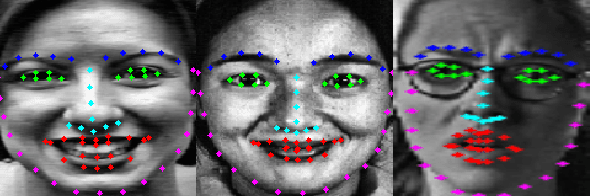
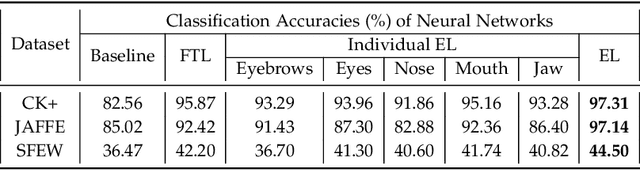

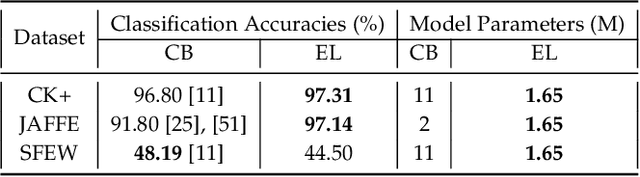
Facial Expression Recognition from static images is a challenging problem in computer vision applications. Convolutional Neural Network (CNN), the state-of-the-art method for various computer vision tasks, has had limited success in predicting expressions from faces having extreme poses, illumination, and occlusion conditions. To mitigate this issue, CNNs are often accompanied by techniques like transfer, multi-task, or ensemble learning that often provide high accuracy at the cost of high computational complexity. In this work, we propose a Part-based Ensemble Transfer Learning network, which models how humans recognize facial expressions by correlating the spatial orientation pattern of the facial features with a specific expression. It consists of 5 sub-networks, in which each sub-network performs transfer learning from one of the five subsets of facial landmarks: eyebrows, eyes, nose, mouth, or jaw to expression classification. We test the proposed network on the CK+, JAFFE, and SFEW datasets, and it outperforms the benchmark for CK+ and JAFFE datasets by 0.51\% and 5.34\%, respectively. Additionally, it consists of a total of 1.65M model parameters and requires only 3.28 $\times$ $10^{6}$ FLOPS, which ensures computational efficiency for real-time deployment. Grad-CAM visualizations of our proposed ensemble highlight the complementary nature of its sub-networks, a key design parameter of an effective ensemble network. Lastly, cross-dataset evaluation results reveal that our proposed ensemble has a high generalization capacity. Our model trained on the SFEW Train dataset achieves an accuracy of 47.53\% on the CK+ dataset, which is higher than what it achieves on the SFEW Valid dataset.
Have convolutions already made recurrence obsolete for unconstrained handwritten text recognition ?
Dec 09, 2020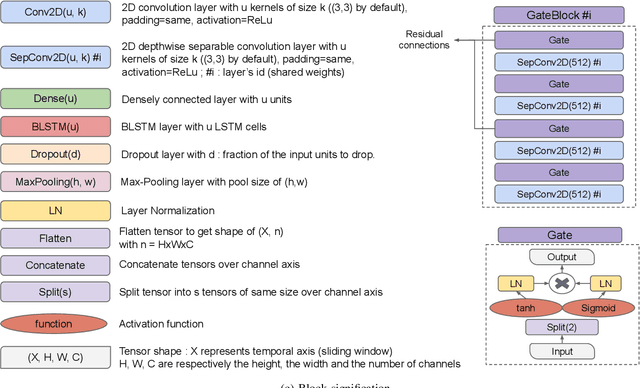

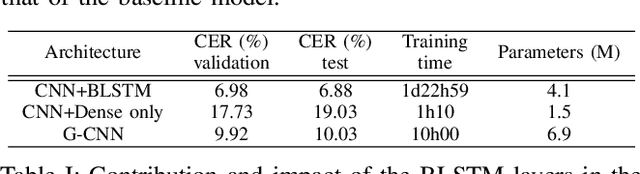
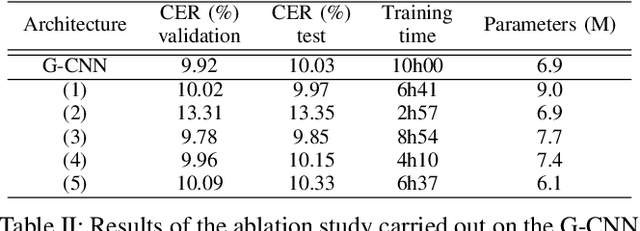
Unconstrained handwritten text recognition remains an important challenge for deep neural networks. These last years, recurrent networks and more specifically Long Short-Term Memory networks have achieved state-of-the-art performance in this field. Nevertheless, they are made of a large number of trainable parameters and training recurrent neural networks does not support parallelism. This has a direct influence on the training time of such architectures, with also a direct consequence on the time required to explore various architectures. Recently, recurrence-free architectures such as Fully Convolutional Networks with gated mechanisms have been proposed as one possible alternative achieving competitive results. In this paper, we explore convolutional architectures and compare them to a CNN+BLSTM baseline. We propose an experimental study regarding different architectures on an offline handwriting recognition task using the RIMES dataset, and a modified version of it that consists of augmenting the images with notebook backgrounds that are printed grids.
Transferring Domain Knowledge with an Adviser in Continuous Tasks
Feb 16, 2021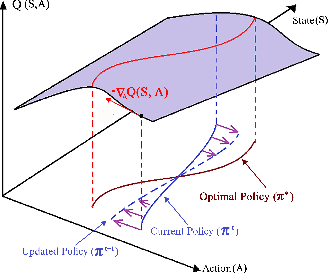
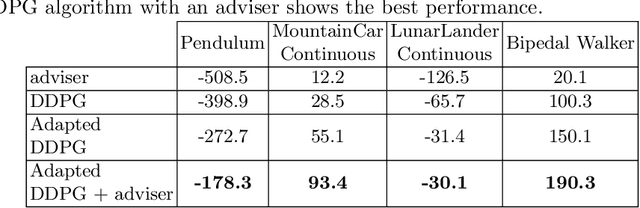
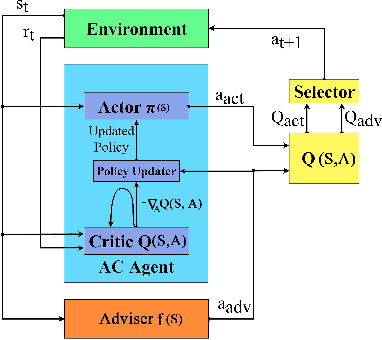
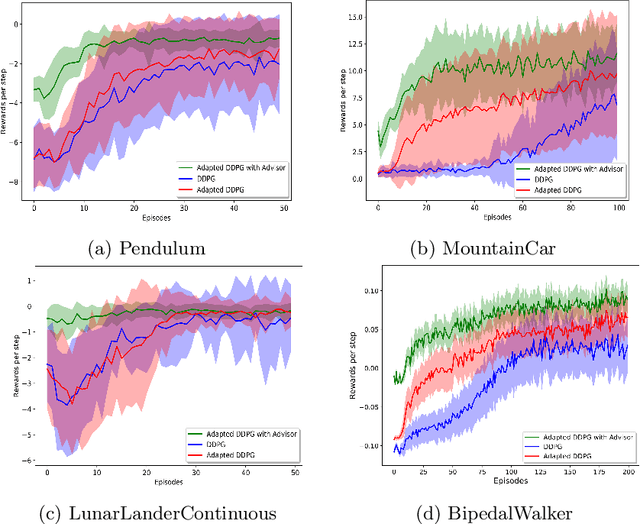
Recent advances in Reinforcement Learning (RL) have surpassed human-level performance in many simulated environments. However, existing reinforcement learning techniques are incapable of explicitly incorporating already known domain-specific knowledge into the learning process. Therefore, the agents have to explore and learn the domain knowledge independently through a trial and error approach, which consumes both time and resources to make valid responses. Hence, we adapt the Deep Deterministic Policy Gradient (DDPG) algorithm to incorporate an adviser, which allows integrating domain knowledge in the form of pre-learned policies or pre-defined relationships to enhance the agent's learning process. Our experiments on OpenAi Gym benchmark tasks show that integrating domain knowledge through advisers expedites the learning and improves the policy towards better optima.
Aerial Scene Understanding in The Wild: Multi-Scene Recognition via Prototype-based Memory Networks
Apr 22, 2021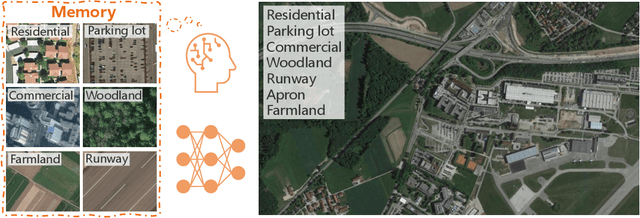
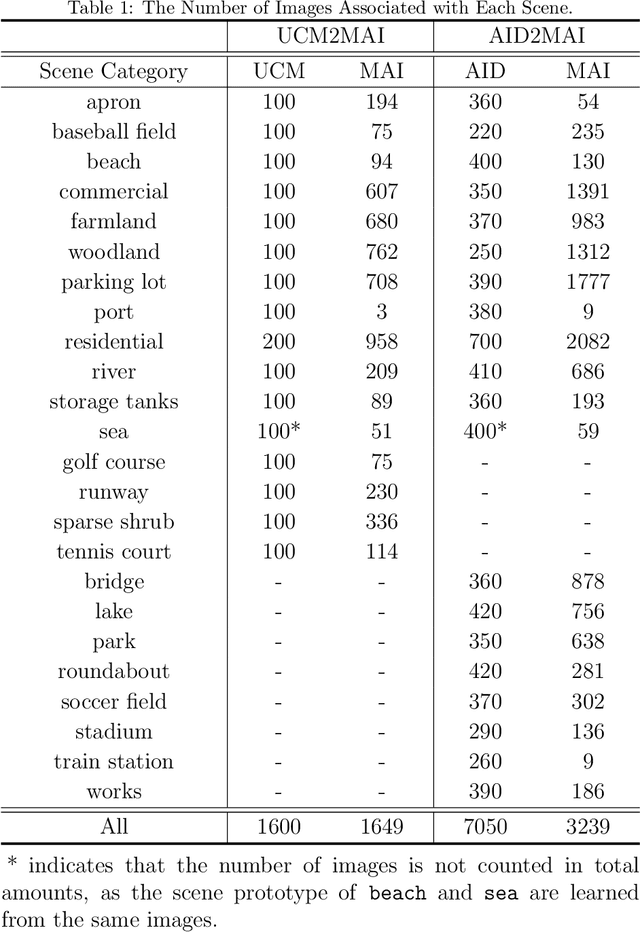

Aerial scene recognition is a fundamental visual task and has attracted an increasing research interest in the last few years. Most of current researches mainly deploy efforts to categorize an aerial image into one scene-level label, while in real-world scenarios, there often exist multiple scenes in a single image. Therefore, in this paper, we propose to take a step forward to a more practical and challenging task, namely multi-scene recognition in single images. Moreover, we note that manually yielding annotations for such a task is extraordinarily time- and labor-consuming. To address this, we propose a prototype-based memory network to recognize multiple scenes in a single image by leveraging massive well-annotated single-scene images. The proposed network consists of three key components: 1) a prototype learning module, 2) a prototype-inhabiting external memory, and 3) a multi-head attention-based memory retrieval module. To be more specific, we first learn the prototype representation of each aerial scene from single-scene aerial image datasets and store it in an external memory. Afterwards, a multi-head attention-based memory retrieval module is devised to retrieve scene prototypes relevant to query multi-scene images for final predictions. Notably, only a limited number of annotated multi-scene images are needed in the training phase. To facilitate the progress of aerial scene recognition, we produce a new multi-scene aerial image (MAI) dataset. Experimental results on variant dataset configurations demonstrate the effectiveness of our network. Our dataset and codes are publicly available.