 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deluca -- A Differentiable Control Library: Environments, Methods, and Benchmarking
Feb 19, 2021
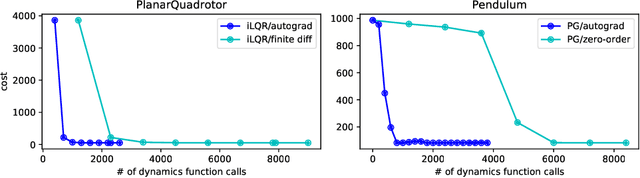
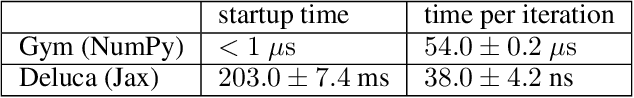
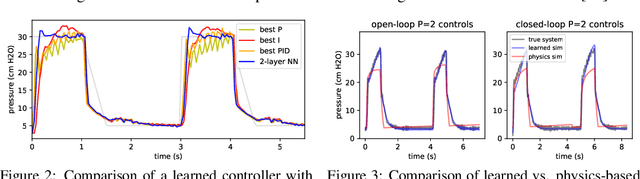
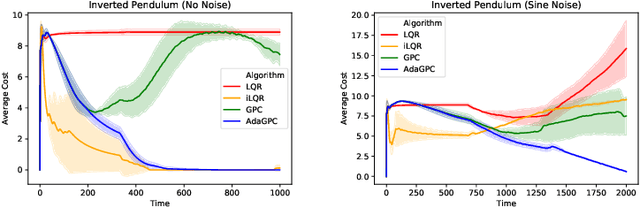
We present an open-source library of natively differentiable physics and robotics environments, accompanied by gradient-based control methods and a benchmark-ing suite. The introduced environments allow auto-differentiation through the simulation dynamics, and thereby permit fast training of controllers. The library features several popular environments, including classical control settings from OpenAI Gym. We also provide a novel differentiable environment, based on deep neural networks, that simulates medical ventilation. We give several use-cases of new scientific results obtained using the library. This includes a medical ventilator simulator and controller, an adaptive control method for time-varying linear dynamical systems, and new gradient-based methods for control of linear dynamical systems with adversarial perturbations.
Dynamic Traffic Modeling From Overhead Imagery
Dec 18, 2020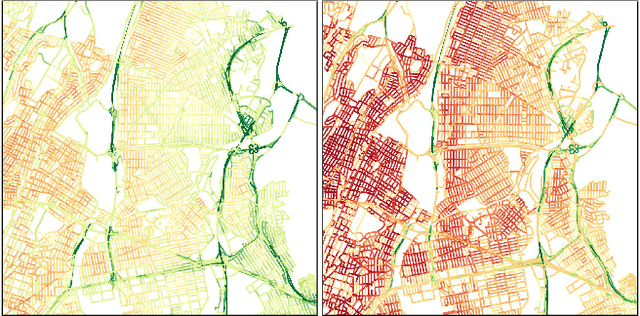
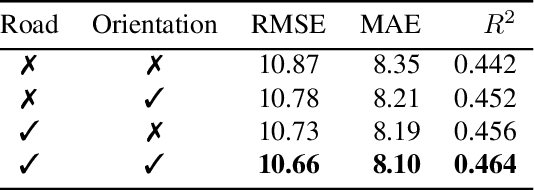
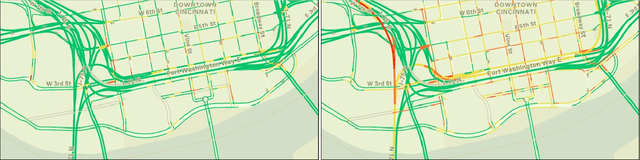
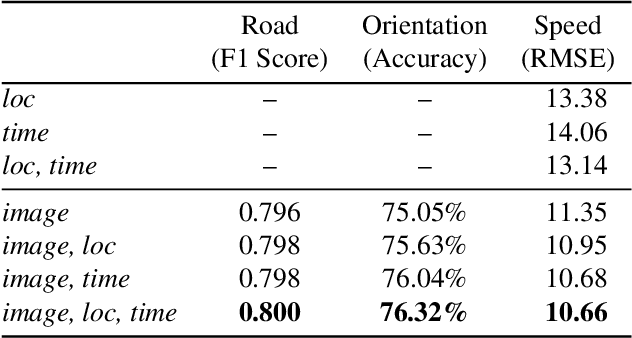
Our goal is to use overhead imagery to understand patterns in traffic flow, for instance answering questions such as how fast could you traverse Times Square at 3am on a Sunday. A traditional approach for solving this problem would be to model the speed of each road segment as a function of time. However, this strategy is limited in that a significant amount of data must first be collected before a model can be used and it fails to generalize to new areas. Instead, we propose an automatic approach for generating dynamic maps of traffic speeds using convolutional neural networks. Our method operates on overhead imagery, is conditioned on location and time, and outputs a local motion model that captures likely directions of travel and corresponding travel speeds. To train our model, we take advantage of historical traffic data collected from New York City. Experimental results demonstrate that our method can be applied to generate accurate city-scale traffic models.
Vision-Aided 6G Wireless Communications: Blockage Prediction and Proactive Handoff
Feb 18, 2021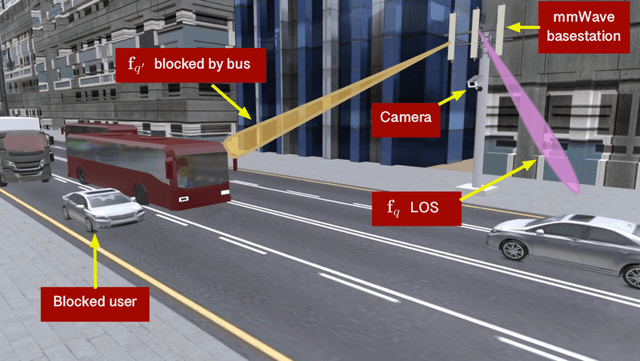
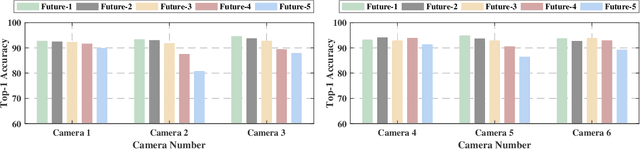
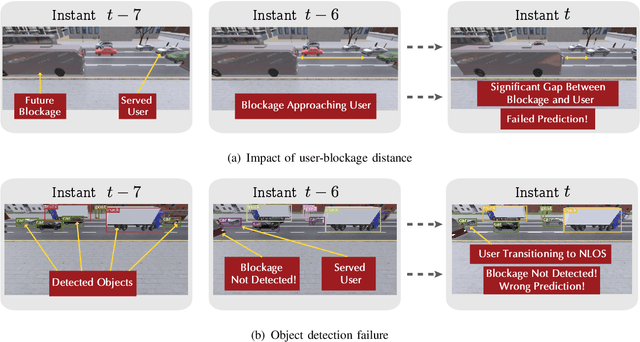
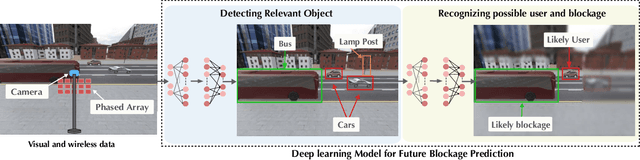
The sensitivity to blockages is a key challenge for the high-frequency (5G millimeter wave and 6G sub-terahertz) wireless networks. Since these networks mainly rely on line-of-sight (LOS) links, sudden link blockages highly threatens the reliability of the networks. Further, when the LOS link is blocked, the network typically needs to hand off the user to another LOS basestation, which may incur critical time latency, especially if a search over a large codebook of narrow beams is needed. A promising way to tackle the reliability and latency challenges lies in enabling proaction in wireless networks. Proaction basically allows the network to anticipate blockages, especially dynamic blockages, and initiate user hand-off beforehand. This paper presents a complete machine learning framework for enabling proaction in wireless networks relying on visual data captured, for example, by RGB cameras deployed at the base stations. In particular, the paper proposes a vision-aided wireless communication solution that utilizes bimodal machine learning to perform proactive blockage prediction and user hand-off. The bedrock of this solution is a deep learning algorithm that learns from visual and wireless data how to predict incoming blockages. The predictions of this algorithm are used by the wireless network to proactively initiate hand-off decisions and avoid any unnecessary latency. The algorithm is developed on a vision-wireless dataset generated using the ViWi data-generation framework. Experimental results on two basestations with different cameras indicate that the algorithm is capable of accurately detecting incoming blockages more than $\sim 90\%$ of the time. Such blockage prediction ability is directly reflected in the accuracy of proactive hand-off, which also approaches $87\%$. This highlights a promising direction for enabling high reliability and low latency in future wireless networks.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
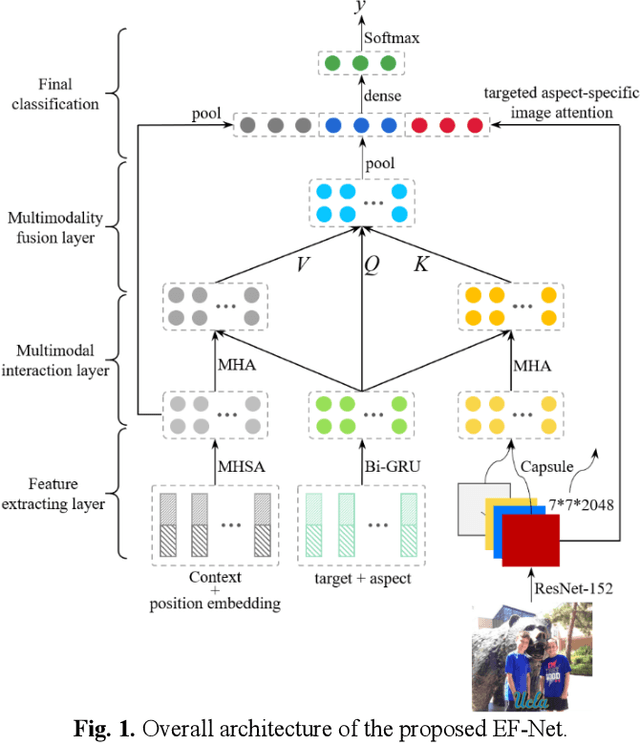
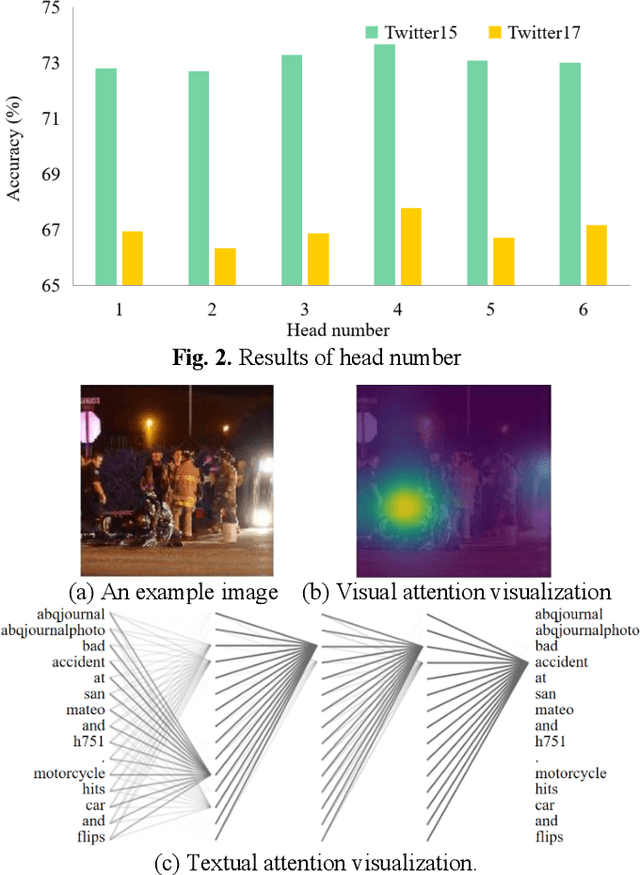
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 02, 2021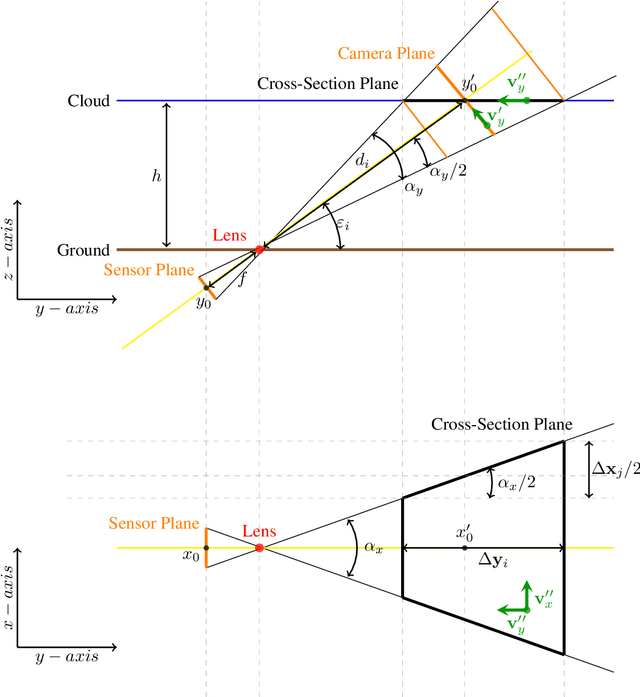
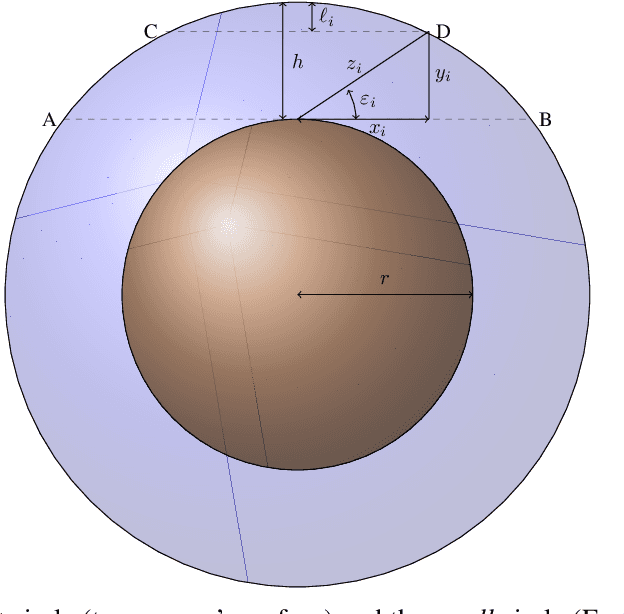
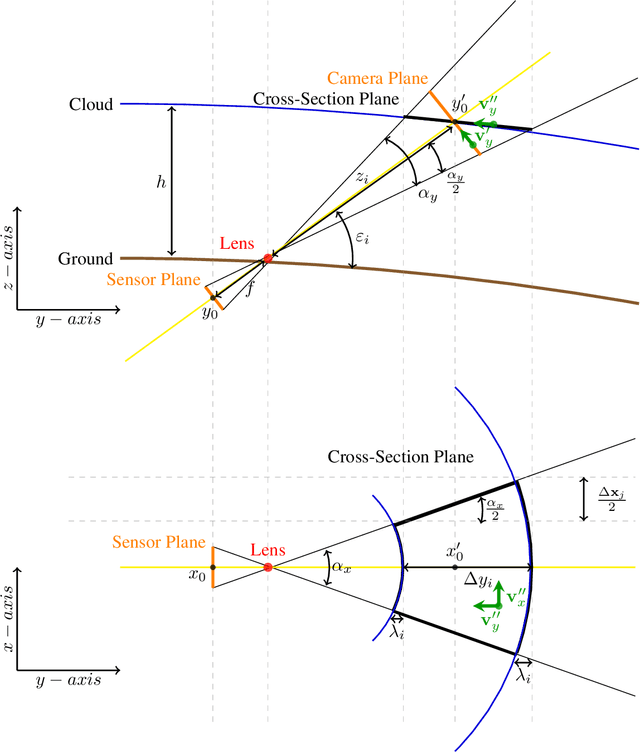

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the imager have an elevation angle with respect to the normal of the device. This produces that the pixels in an image contain information from different areas of the sky within imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imaging system are mounted on a solar tracker the angle of incidence of the light beams varies along time. This investigation introduces a transformation that projects the original euclidean frame of the plane of the imager to the geospatial frame of the sky imaging system field of view.
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Mar 27, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
Reliably fast adversarial training via latent adversarial perturbation
Apr 04, 2021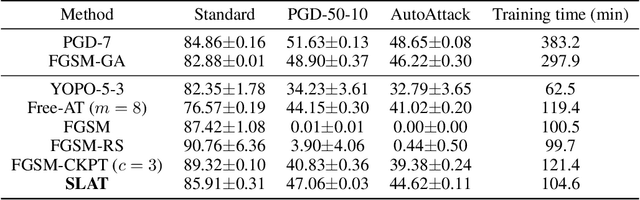
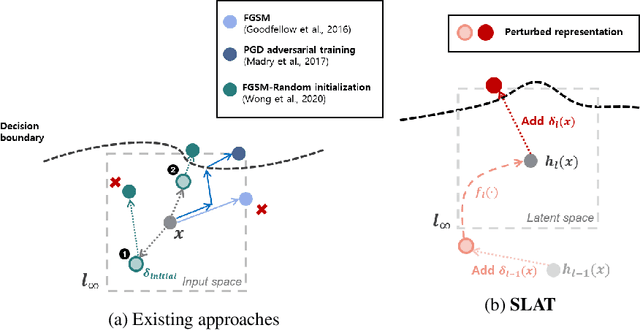
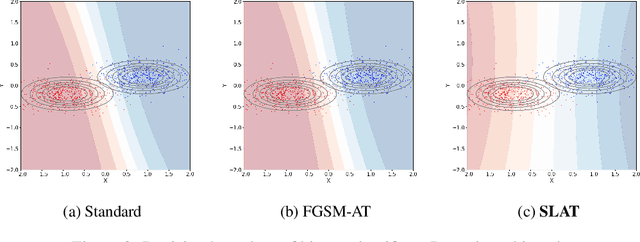

While multi-step adversarial training is widely popular as an effective defense method against strong adversarial attacks, its computational cost is notoriously expensive, compared to standard training. Several single-step adversarial training methods have been proposed to mitigate the above-mentioned overhead cost; however, their performance is not sufficiently reliable depending on the optimization setting. To overcome such limitations, we deviate from the existing input-space-based adversarial training regime and propose a single-step latent adversarial training method (SLAT), which leverages the gradients of latent representation as the latent adversarial perturbation. We demonstrate that the L1 norm of feature gradients is implicitly regularized through the adopted latent perturbation, thereby recovering local linearity and ensuring reliable performance, compared to the existing single-step adversarial training methods. Because latent perturbation is based on the gradients of the latent representations which can be obtained for free in the process of input gradients computation, the proposed method costs roughly the same time as the fast gradient sign method. Experiment results demonstrate that the proposed method, despite its structural simplicity, outperforms state-of-the-art accelerated adversarial training methods.
Graph Computing for Financial Crime and Fraud Detection: Trends, Challenges and Outlook
Mar 02, 2021The rise of digital payments has caused consequential changes in the financial crime landscape. As a result, traditional fraud detection approaches such as rule-based systems have largely become ineffective. AI and machine learning solutions using graph computing principles have gained significant interest in recent years. Graph-based techniques provide unique solution opportunities for financial crime detection. However, implementing such solutions at industrial-scale in real-time financial transaction processing systems has brought numerous application challenges to light. In this paper, we discuss the implementation difficulties current and next-generation graph solutions face. Furthermore, financial crime and digital payments trends indicate emerging challenges in the continued effectiveness of the detection techniques. We analyze the threat landscape and argue that it provides key insights for developing graph-based solutions.
Deep Spectrum Cartography: Completing Radio Map Tensors Using Learned Neural Models
May 01, 2021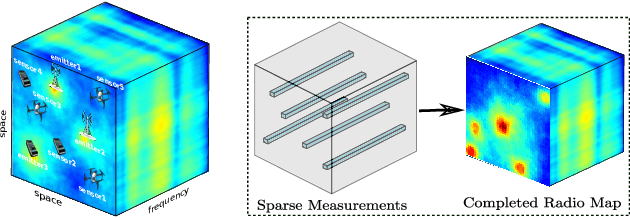
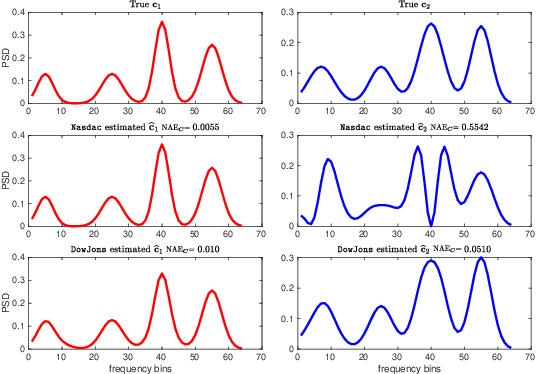
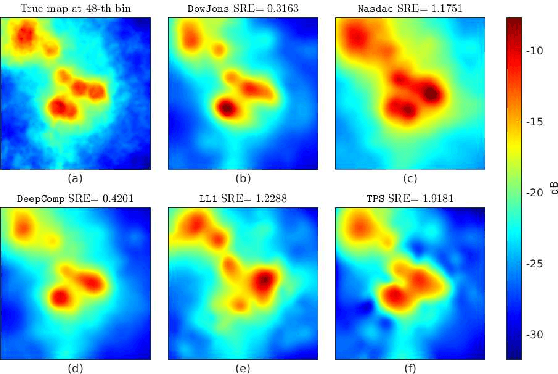
The spectrum cartography (SC) technique constructs multi-domain (e.g., frequency, space, and time) radio frequency (RF) maps from limited measurements, which can be viewed as an ill-posed tensor completion problem. Model-based cartography techniques often rely on handcrafted priors (e.g., sparsity, smoothness and low-rank structures) for the completion task. Such priors may be inadequate to capture the essence of complex wireless environments -- especially when severe shadowing happens. To circumvent such challenges, offline-trained deep neural models of radio maps were considered for SC, as deep neural networks (DNNs) are able to "learn" intricate underlying structures from data. However, such deep learning (DL)-based SC approaches encounter serious challenges in both off-line model learning (training) and completion (generalization), possibly because the latent state space for generating the radio maps is prohibitively large. In this work, an emitter radio map disaggregation-based approach is proposed, under which only individual emitters' radio maps are modeled by DNNs. This way, the learning and generalization challenges can both be substantially alleviated. Using the learned DNNs, a fast nonnegative matrix factorization-based two-stage SC method and a performance-enhanced iterative optimization algorithm are proposed. Theoretical aspects -- such as recoverability of the radio tensor, sample complexity, and noise robustness -- under the proposed framework are characterized, and such theoretical properties have been elusive in the context of DL-based radio tensor completion. Experiments using synthetic and real-data from indoor and heavily shadowed environments are employed to showcase the effectiveness of the proposed methods.
Learning Frame Similarity using Siamese networks for Audio-to-Score Alignment
Nov 15, 2020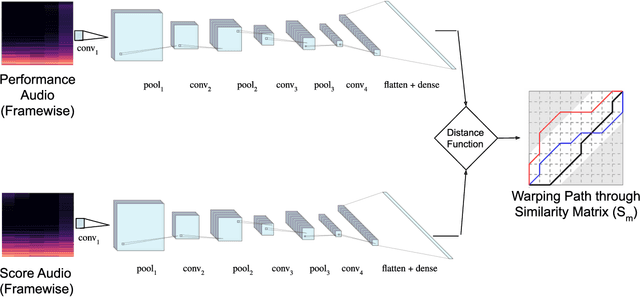
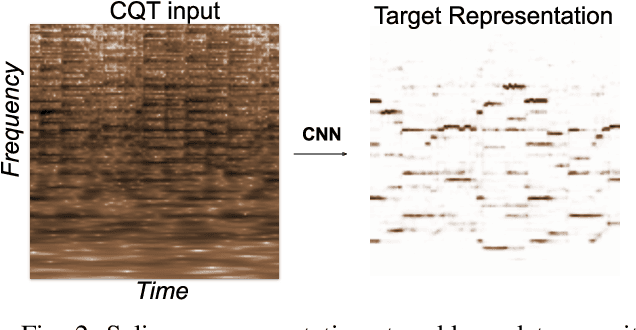
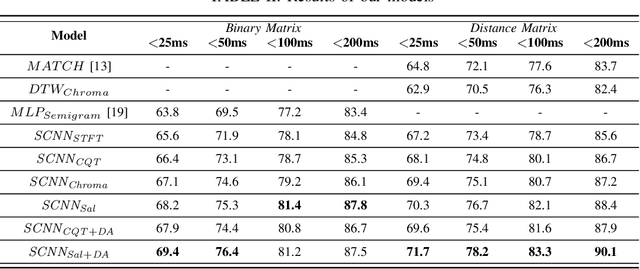
Audio-to-score alignment aims at generating an accurate mapping between a performance audio and the score of a given piece. Standard alignment methods are based on Dynamic Time Warping (DTW) and employ handcrafted features, which cannot be adapted to different acoustic conditions. We propose a method to overcome this limitation using learned frame similarity for audio-to-score alignment. We focus on offline audio-to-score alignment of piano music. Experiments on music data from different acoustic conditions demonstrate that our method achieves higher alignment accuracy than a standard DTW-based method that uses handcrafted features, and generates robust alignments whilst being adaptable to different domains at the same time.