 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 18, 2021

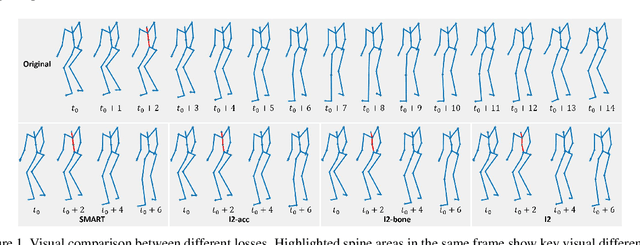
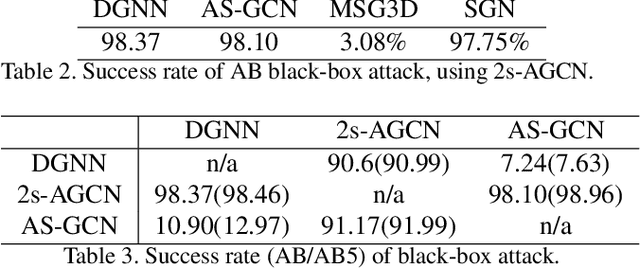

Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
Discovering Playing Patterns: Time Series Clustering of Free-To-Play Game Data
Oct 06, 2017
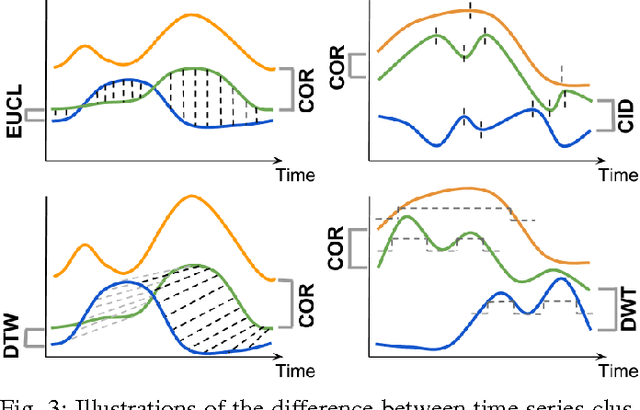
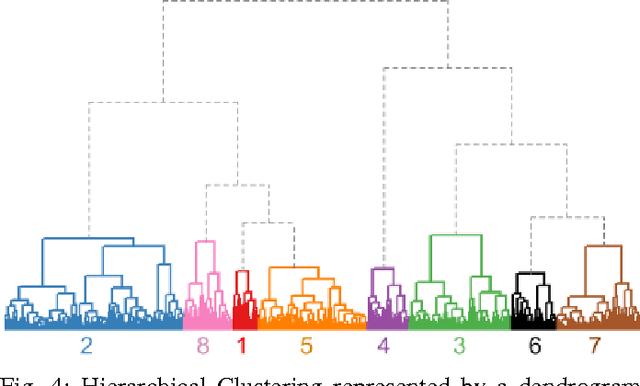
The classification of time series data is a challenge common to all data-driven fields. However, there is no agreement about which are the most efficient techniques to group unlabeled time-ordered data. This is because a successful classification of time series patterns depends on the goal and the domain of interest, i.e. it is application-dependent. In this article, we study free-to-play game data. In this domain, clustering similar time series information is increasingly important due to the large amount of data collected by current mobile and web applications. We evaluate which methods cluster accurately time series of mobile games, focusing on player behavior data. We identify and validate several aspects of the clustering: the similarity measures and the representation techniques to reduce the high dimensionality of time series. As a robustness test, we compare various temporal datasets of player activity from two free-to-play video-games. With these techniques we extract temporal patterns of player behavior relevant for the evaluation of game events and game-business diagnosis. Our experiments provide intuitive visualizations to validate the results of the clustering and to determine the optimal number of clusters. Additionally, we assess the common characteristics of the players belonging to the same group. This study allows us to improve the understanding of player dynamics and churn behavior.
Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention
Apr 12, 2021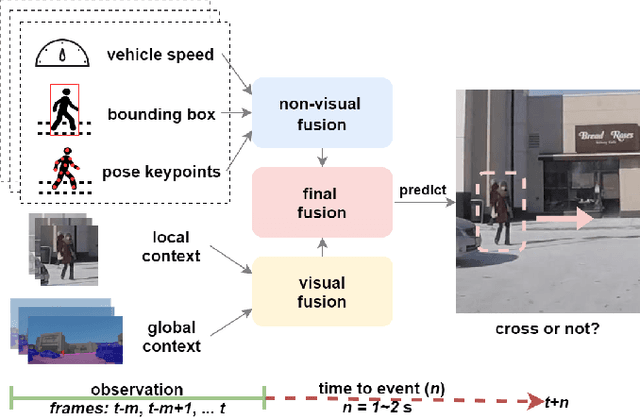
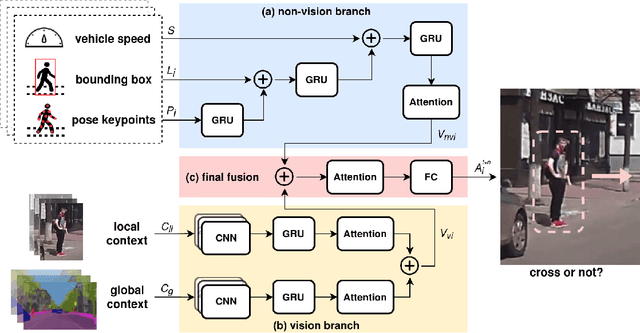
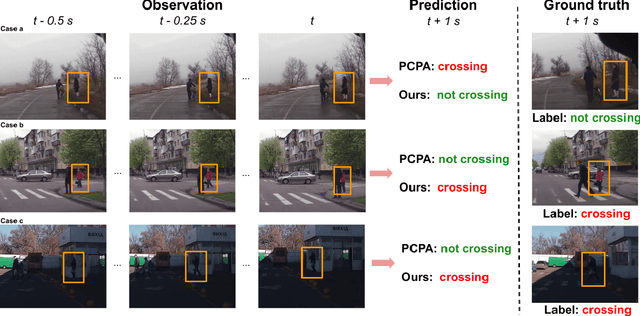
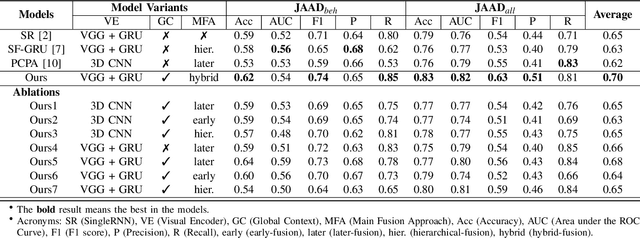
Predicting vulnerable road user behavior is an essential prerequisite for deploying Automated Driving Systems (ADS) in the real-world. Pedestrian crossing intention should be recognized in real-time, especially for urban driving. Recent works have shown the potential of using vision-based deep neural network models for this task. However, these models are not robust and certain issues still need to be resolved. First, the global spatio-temproal context that accounts for the interaction between the target pedestrian and the scene has not been properly utilized. Second, the optimum strategy for fusing different sensor data has not been thoroughly investigated. This work addresses the above limitations by introducing a novel neural network architecture to fuse inherently different spatio-temporal features for pedestrian crossing intention prediction. We fuse different phenomena such as sequences of RGB imagery, semantic segmentation masks, and ego-vehicle speed in an optimum way using attention mechanisms and a stack of recurrent neural networks. The optimum architecture was obtained through exhaustive ablation and comparison studies. Extensive comparative experiments on the JAAD pedestrian action prediction benchmark demonstrate the effectiveness of the proposed method, where state-of-the-art performance was achieved. Our code is open-source and publicly available.
Panoptic-PolarNet: Proposal-free LiDAR Point Cloud Panoptic Segmentation
Mar 27, 2021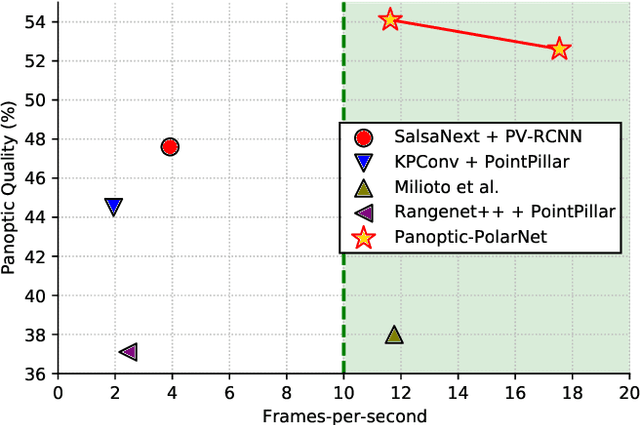
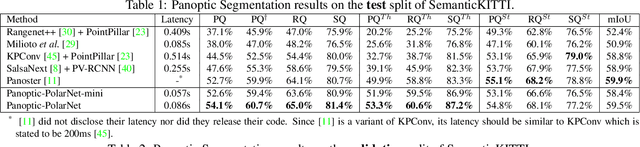
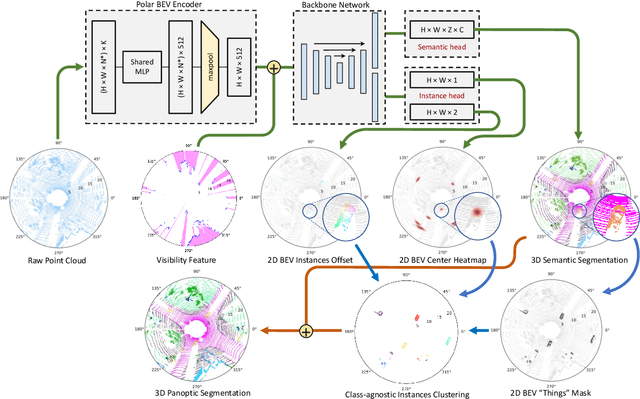
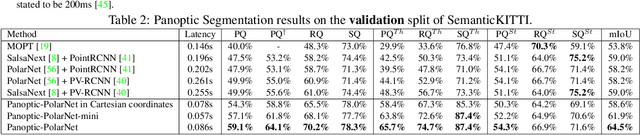
Panoptic segmentation presents a new challenge in exploiting the merits of both detection and segmentation, with the aim of unifying instance segmentation and semantic segmentation in a single framework. However, an efficient solution for panoptic segmentation in the emerging domain of LiDAR point cloud is still an open research problem and is very much under-explored. In this paper, we present a fast and robust LiDAR point cloud panoptic segmentation framework, referred to as Panoptic-PolarNet. We learn both semantic segmentation and class-agnostic instance clustering in a single inference network using a polar Bird's Eye View (BEV) representation, enabling us to circumvent the issue of occlusion among instances in urban street scenes. To improve our network's learnability, we also propose an adapted instance augmentation technique and a novel adversarial point cloud pruning method. Our experiments show that Panoptic-PolarNet outperforms the baseline methods on SemanticKITTI and nuScenes datasets with an almost real-time inference speed. Panoptic-PolarNet achieved 54.1% PQ in the public SemanticKITTI panoptic segmentation leaderboard and leading performance for the validation set of nuScenes.
Neural Networks for Semantic Gaze Analysis in XR Settings
Mar 18, 2021
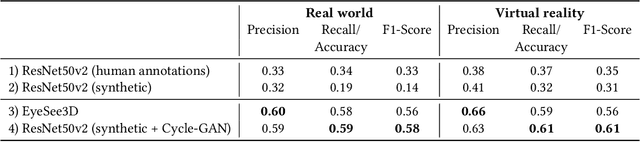
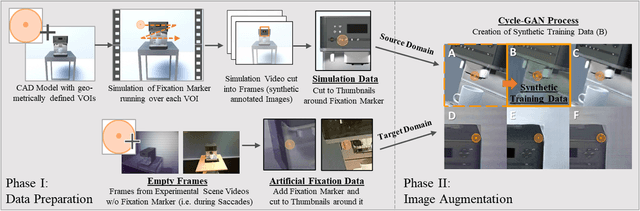
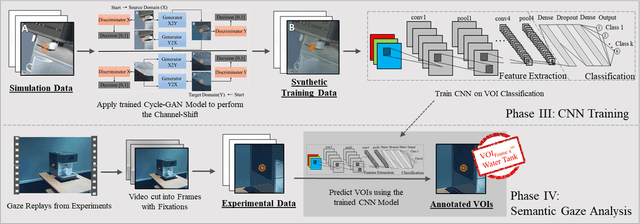
Virtual-reality (VR) and augmented-reality (AR) technology is increasingly combined with eye-tracking. This combination broadens both fields and opens up new areas of application, in which visual perception and related cognitive processes can be studied in interactive but still well controlled settings. However, performing a semantic gaze analysis of eye-tracking data from interactive three-dimensional scenes is a resource-intense task, which so far has been an obstacle to economic use. In this paper we present a novel approach which minimizes time and information necessary to annotate volumes of interest (VOIs) by using techniques from object recognition. To do so, we train convolutional neural networks (CNNs) on synthetic data sets derived from virtual models using image augmentation techniques. We evaluate our method in real and virtual environments, showing that the method can compete with state-of-the-art approaches, while not relying on additional markers or preexisting databases but instead offering cross-platform use.
Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning
Mar 18, 2021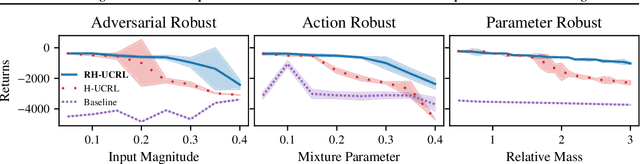
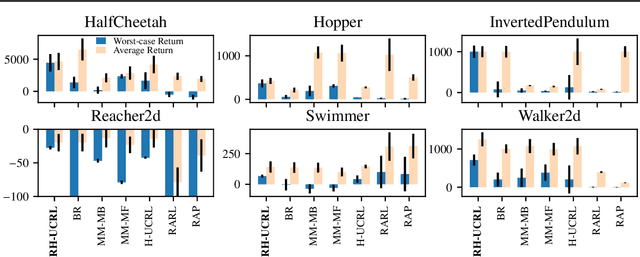
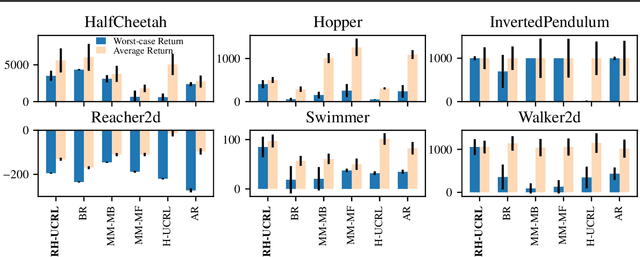
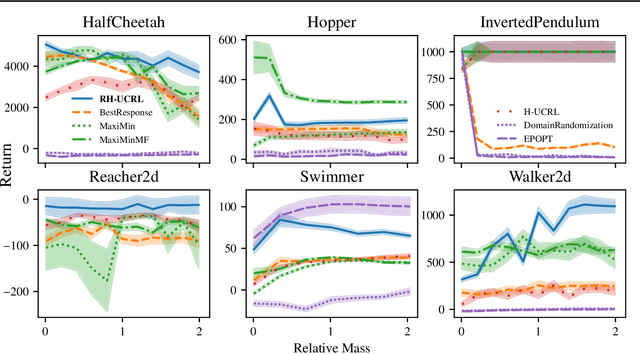
In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness against worst-case situations. The robust RL framework addresses this challenge via a worst-case optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally, we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.
Discriminating Traces with Time
Feb 23, 2017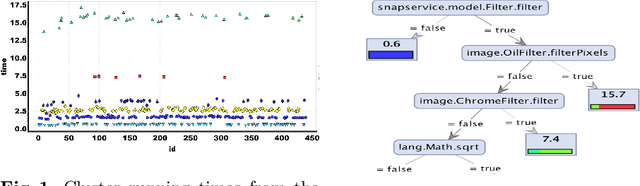
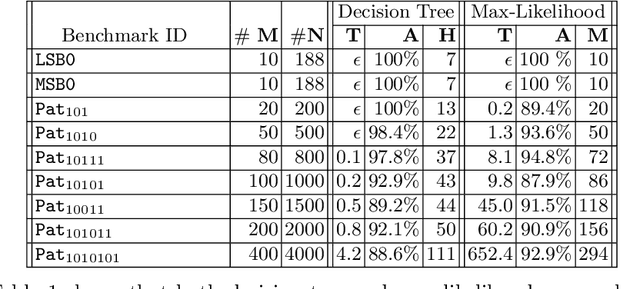
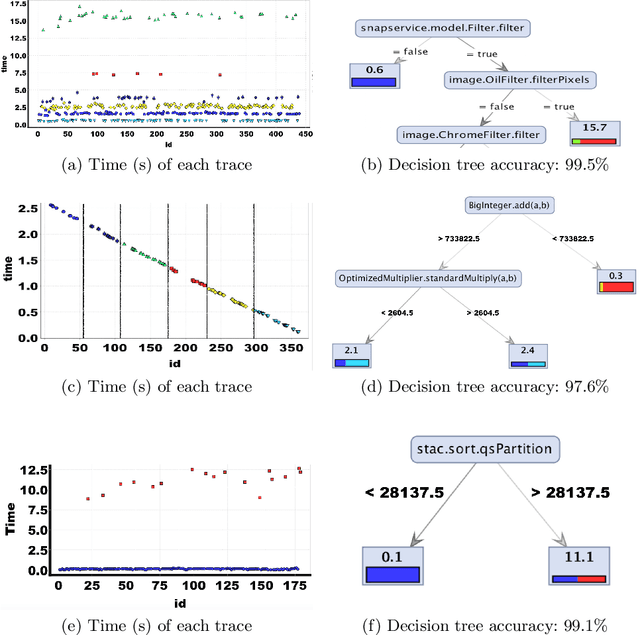
What properties about the internals of a program explain the possible differences in its overall running time for different inputs? In this paper, we propose a formal framework for considering this question we dub trace-set discrimination. We show that even though the algorithmic problem of computing maximum likelihood discriminants is NP-hard, approaches based on integer linear programming (ILP) and decision tree learning can be useful in zeroing-in on the program internals. On a set of Java benchmarks, we find that compactly-represented decision trees scalably discriminate with high accuracy---more scalably than maximum likelihood discriminants and with comparable accuracy. We demonstrate on three larger case studies how decision-tree discriminants produced by our tool are useful for debugging timing side-channel vulnerabilities (i.e., where a malicious observer infers secrets simply from passively watching execution times) and availability vulnerabilities.
Contextual Biasing of Language Models for Speech Recognition in Goal-Oriented Conversational Agents
Mar 18, 2021
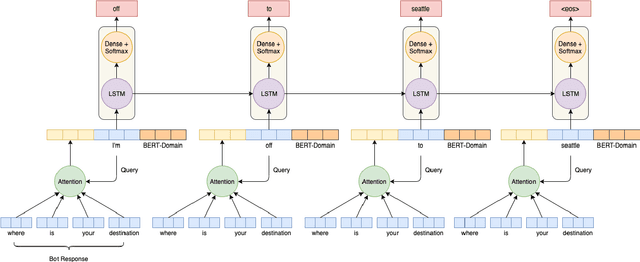
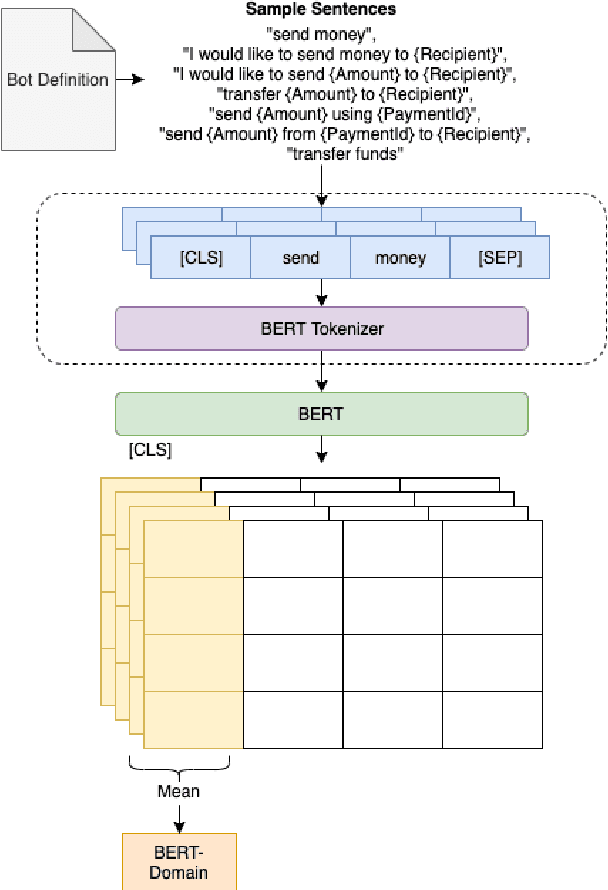
Goal-oriented conversational interfaces are designed to accomplish specific tasks and typically have interactions that tend to span multiple turns adhering to a pre-defined structure and a goal. However, conventional neural language models (NLM) in Automatic Speech Recognition (ASR) systems are mostly trained sentence-wise with limited context. In this paper, we explore different ways to incorporate context into a LSTM based NLM in order to model long range dependencies and improve speech recognition. Specifically, we use context carry over across multiple turns and use lexical contextual cues such as system dialog act from Natural Language Understanding (NLU) models and the user provided structure of the chatbot. We also propose a new architecture that utilizes context embeddings derived from BERT on sample utterances provided during inference time. Our experiments show a word error rate (WER) relative reduction of 7% over non-contextual utterance-level NLM rescorers on goal-oriented audio datasets.
Attend and Diagnose: Clinical Time Series Analysis using Attention Models
Nov 19, 2017
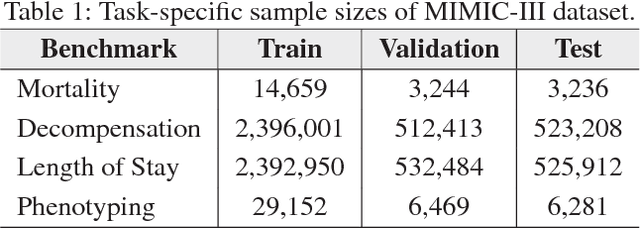
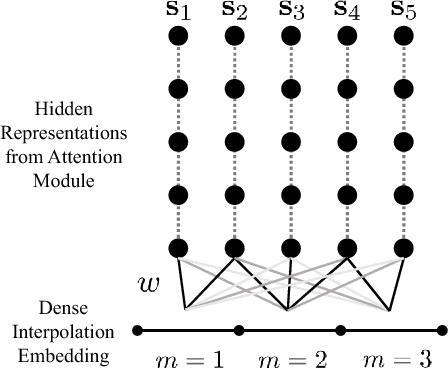
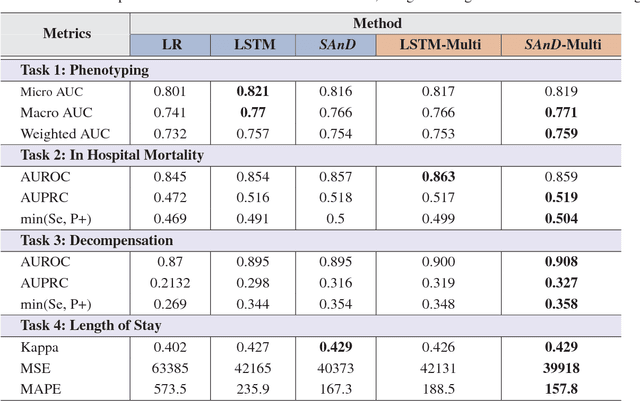
With widespread adoption of electronic health records, there is an increased emphasis for predictive models that can effectively deal with clinical time-series data. Powered by Recurrent Neural Network (RNN) architectures with Long Short-Term Memory (LSTM) units, deep neural networks have achieved state-of-the-art results in several clinical prediction tasks. Despite the success of RNNs, its sequential nature prohibits parallelized computing, thus making it inefficient particularly when processing long sequences. Recently, architectures which are based solely on attention mechanisms have shown remarkable success in transduction tasks in NLP, while being computationally superior. In this paper, for the first time, we utilize attention models for clinical time-series modeling, thereby dispensing recurrence entirely. We develop the \textit{SAnD} (Simply Attend and Diagnose) architecture, which employs a masked, self-attention mechanism, and uses positional encoding and dense interpolation strategies for incorporating temporal order. Furthermore, we develop a multi-task variant of \textit{SAnD} to jointly infer models with multiple diagnosis tasks. Using the recent MIMIC-III benchmark datasets, we demonstrate that the proposed approach achieves state-of-the-art performance in all tasks, outperforming LSTM models and classical baselines with hand-engineered features.
Combining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021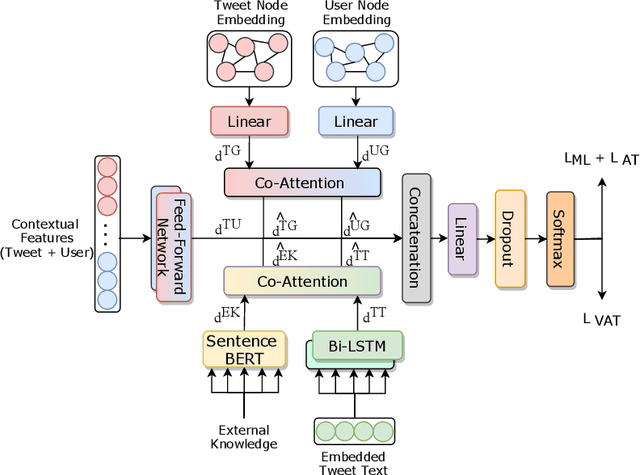
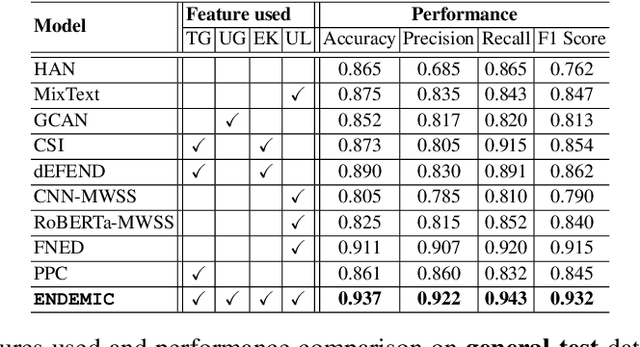
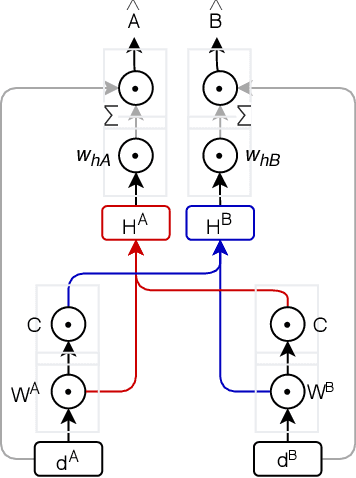
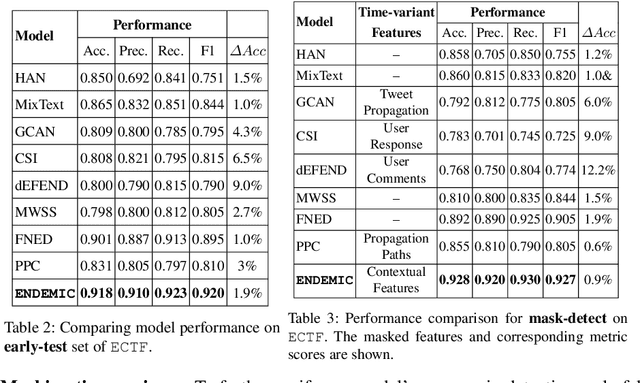
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.