 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 12, 2021

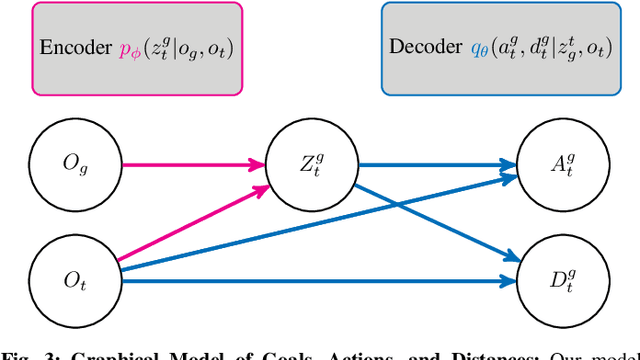
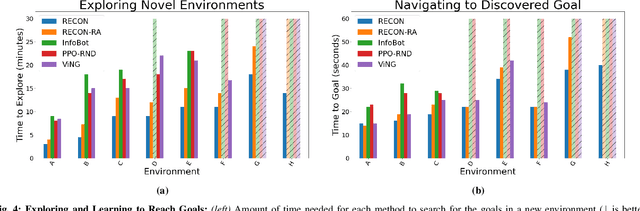
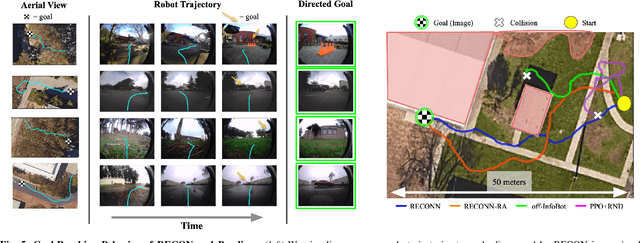
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Hybrid Backpropagation Parallel Reservoir Networks
Oct 27, 2020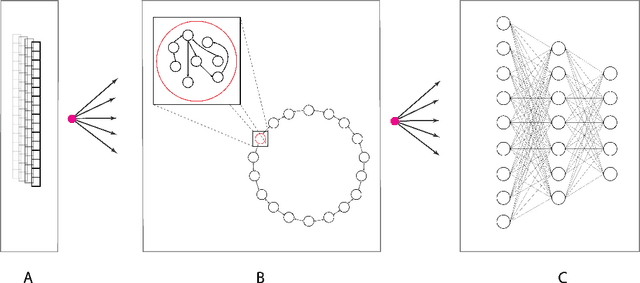
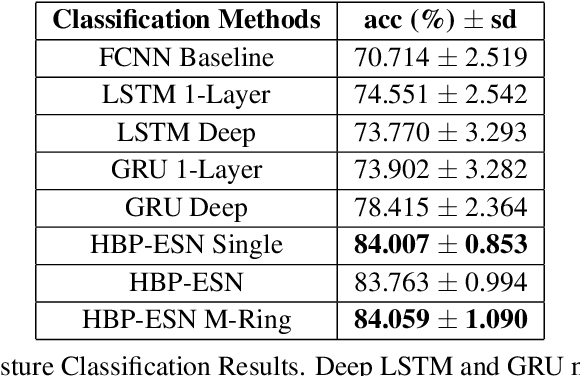

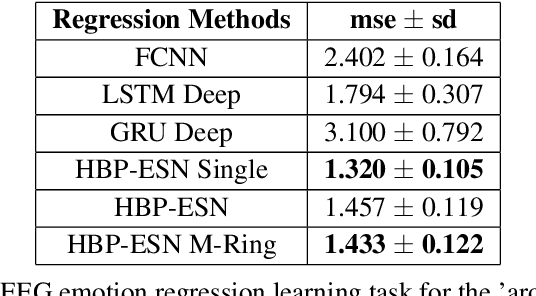
In many real-world applications, fully-differentiable RNNs such as LSTMs and GRUs have been widely deployed to solve time series learning tasks. These networks train via Backpropagation Through Time, which can work well in practice but involves a biologically unrealistic unrolling of the network in time for gradient updates, are computationally expensive, and can be hard to tune. A second paradigm, Reservoir Computing, keeps the recurrent weight matrix fixed and random. Here, we propose a novel hybrid network, which we call Hybrid Backpropagation Parallel Echo State Network (HBP-ESN) which combines the effectiveness of learning random temporal features of reservoirs with the readout power of a deep neural network with batch normalization. We demonstrate that our new network outperforms LSTMs and GRUs, including multi-layer "deep" versions of these networks, on two complex real-world multi-dimensional time series datasets: gesture recognition using skeleton keypoints from ChaLearn, and the DEAP dataset for emotion recognition from EEG measurements. We show also that the inclusion of a novel meta-ring structure, which we call HBP-ESN M-Ring, achieves similar performance to one large reservoir while decreasing the memory required by an order of magnitude. We thus offer this new hybrid reservoir deep learning paradigm as a new alternative direction for RNN learning of temporal or sequential data.
PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
May 02, 2021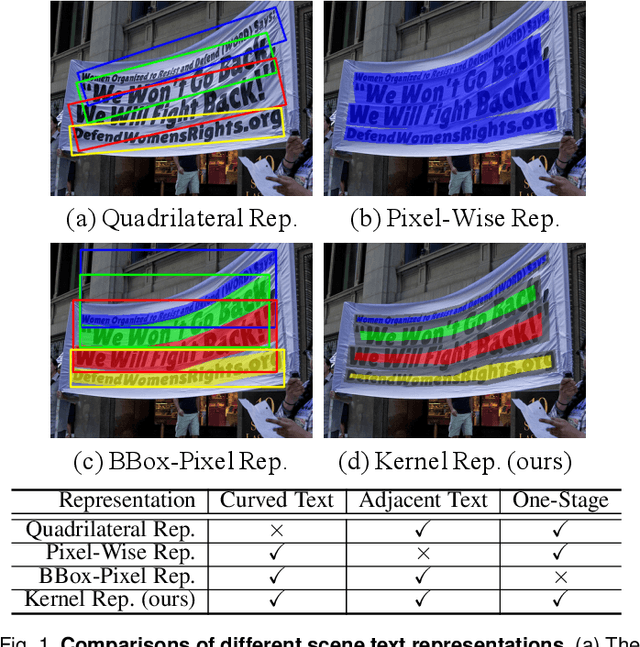
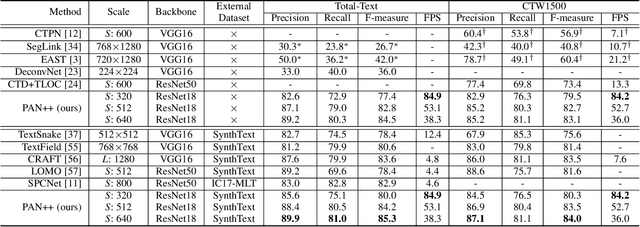
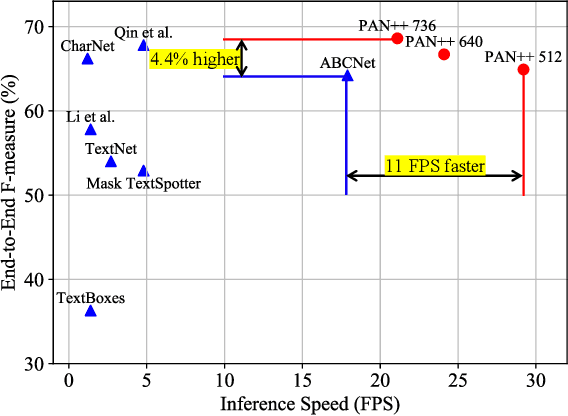
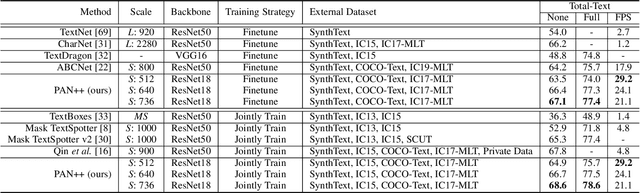
Scene text detection and recognition have been well explored in the past few years. Despite the progress, efficient and accurate end-to-end spotting of arbitrarily-shaped text remains challenging. In this work, we propose an end-to-end text spotting framework, termed PAN++, which can efficiently detect and recognize text of arbitrary shapes in natural scenes. PAN++ is based on the kernel representation that reformulates a text line as a text kernel (central region) surrounded by peripheral pixels. By systematically comparing with existing scene text representations, we show that our kernel representation can not only describe arbitrarily-shaped text but also well distinguish adjacent text. Moreover, as a pixel-based representation, the kernel representation can be predicted by a single fully convolutional network, which is very friendly to real-time applications. Taking the advantages of the kernel representation, we design a series of components as follows: 1) a computationally efficient feature enhancement network composed of stacked Feature Pyramid Enhancement Modules (FPEMs); 2) a lightweight detection head cooperating with Pixel Aggregation (PA); and 3) an efficient attention-based recognition head with Masked RoI. Benefiting from the kernel representation and the tailored components, our method achieves high inference speed while maintaining competitive accuracy. Extensive experiments show the superiority of our method. For example, the proposed PAN++ achieves an end-to-end text spotting F-measure of 64.9 at 29.2 FPS on the Total-Text dataset, which significantly outperforms the previous best method. Code will be available at: https://git.io/PAN.
Pruning and Quantization for Deep Neural Network Acceleration: A Survey
Jan 24, 2021
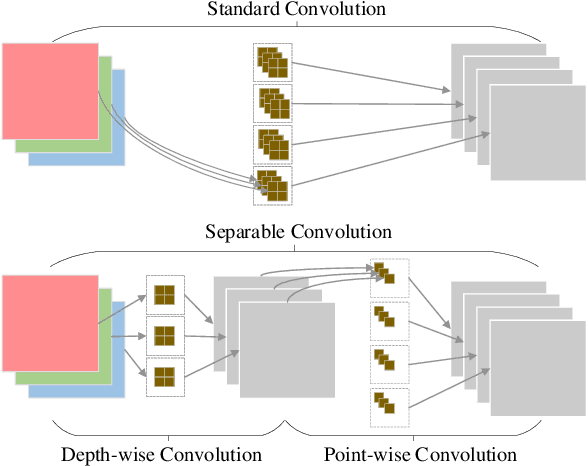
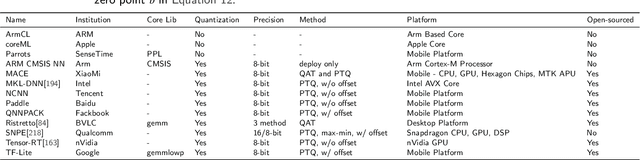
Deep neural networks have been applied in many applications exhibiting extraordinary abilities in the field of computer vision. However, complex network architectures challenge efficient real-time deployment and require significant computation resources and energy costs. These challenges can be overcome through optimizations such as network compression. This paper provides a survey on two types of network compression: pruning and quantization. We compare current techniques, analyze their strengths and weaknesses, provide guidance for compressing networks, and discuss possible future compression techniques.
Contextual Biasing of Language Models for Speech Recognition in Goal-Oriented Conversational Agents
Mar 19, 2021
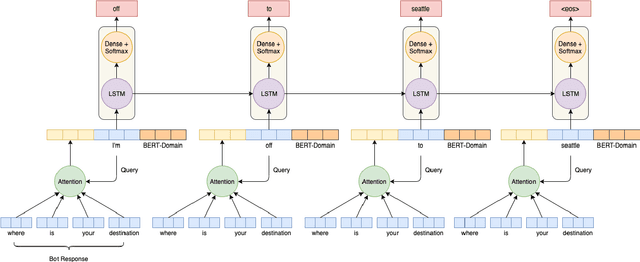
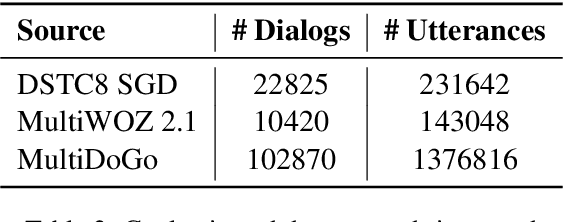
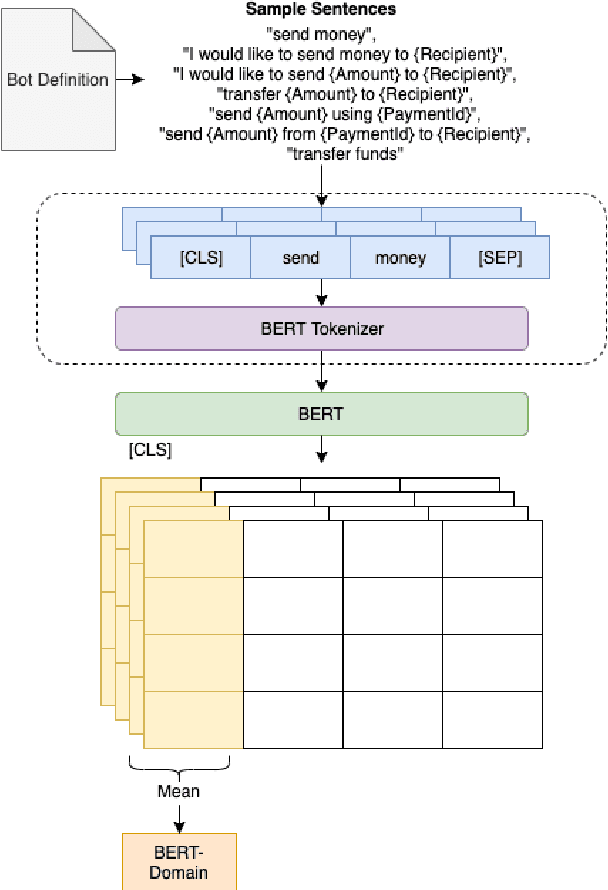
Goal-oriented conversational interfaces are designed to accomplish specific tasks and typically have interactions that tend to span multiple turns adhering to a pre-defined structure and a goal. However, conventional neural language models (NLM) in Automatic Speech Recognition (ASR) systems are mostly trained sentence-wise with limited context. In this paper, we explore different ways to incorporate context into a LSTM based NLM in order to model long range dependencies and improve speech recognition. Specifically, we use context carry over across multiple turns and use lexical contextual cues such as system dialog act from Natural Language Understanding (NLU) models and the user provided structure of the chatbot. We also propose a new architecture that utilizes context embeddings derived from BERT on sample utterances provided during inference time. Our experiments show a word error rate (WER) relative reduction of 7% over non-contextual utterance-level NLM rescorers on goal-oriented audio datasets.
Towards a Next Generation Computing Paradigm: Approximate Computing in Robotics Systems and Environment-Experimentation, Case Study and Practical Implications
Apr 12, 2021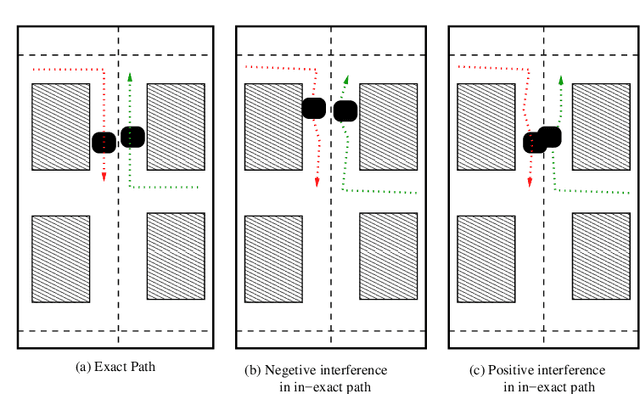
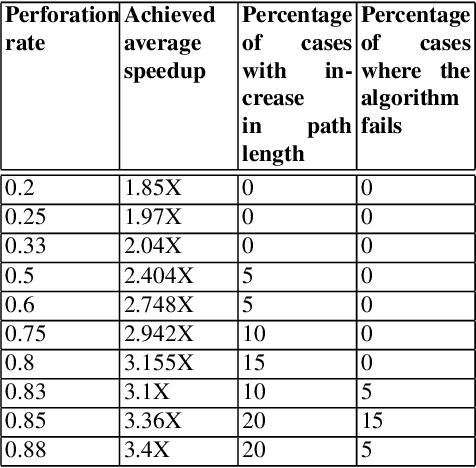
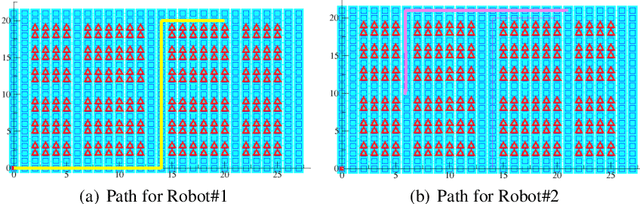
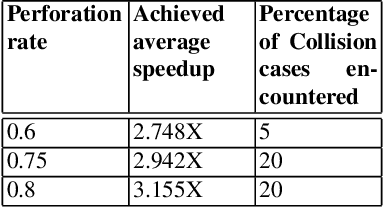
Approximate computing is a computation domain which can be used to trade time and energy with quality and therefore is useful in embedded systems. Energy is the prime resource in battery-driven embedded systems, like robots. Approximate computing can be used as a technique to generate approximate version of the control functionalities of a robot, enabling it to ration energy for computation at the cost of degraded quality. Usually, the programmer of the function specifies the extent of degradation that is safe for the overall safety of the system. However, in a collaborative environment, where several sub-systems co-exist and some of the functionality of each of them have been approximated, the safety of the overall system may be compromised. In this paper, we consider multiple identical robots operate in a warehouse, and the path planning function of the robot is approximated. Although the planned paths are safe for individual robots (i.e. they do not collide with the racks), we show that this leads to a collision among the robots. So, a controlled approximation needs to be carried out in such situations to harness the full power of this new paradigm if it needs to be a mainstream paradigm in future.
Orientation to Pose: Continuum Robots Shape Sensing Based on Piecewise Polynomial Curvature Model
Mar 09, 2021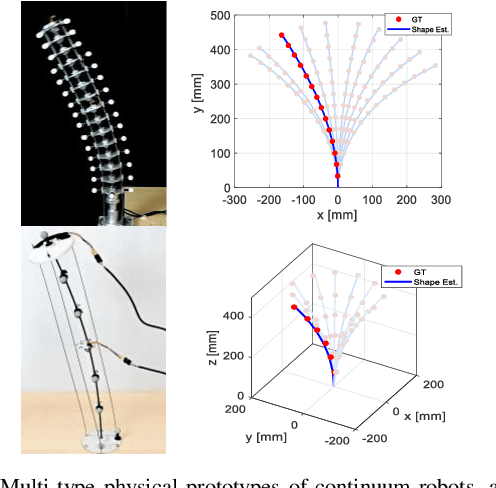
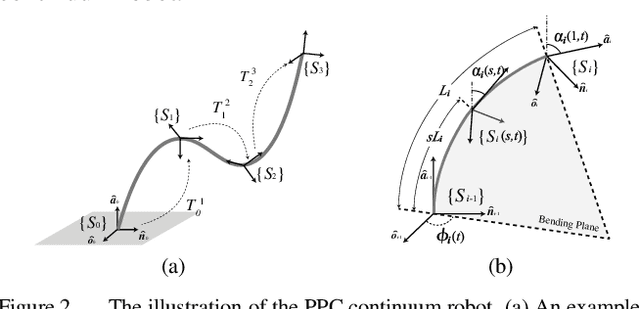
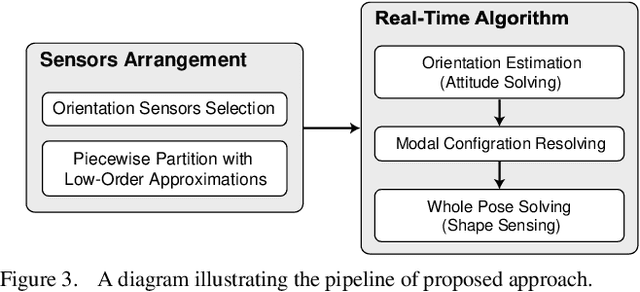
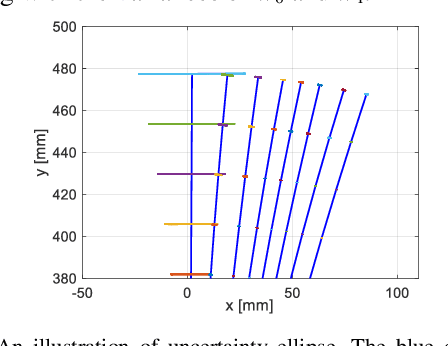
Continuum robots are typically slender and flexible with infinite freedoms in theory, which poses a challenge for their control and application. The shape sensing of continuum robots is vital to realise accuracy control. This letter proposed a novel general real-time shape sensing framework of continuum robots based on the piecewise polynomial curvature (PPC) kinematics model. We illustrate the coupling between orientation and position at any given location of the continuum robots. Further, the coupling relation could be bridged by the PPC kinematics. Therefore, we propose to estimate the shape of continuum robots through orientation estimation, using the off-the-shelf orientation sensors, e.g., IMUs, mounted on certain locations. The approach gives a valuable framework to the shape sensing of continuum robots, universality, accuracy and convenience. The accuracy of the general approach is verified in the experiments of multi-type physical prototypes.
Augmented World Models Facilitate Zero-Shot Dynamics Generalization From a Single Offline Environment
Apr 12, 2021
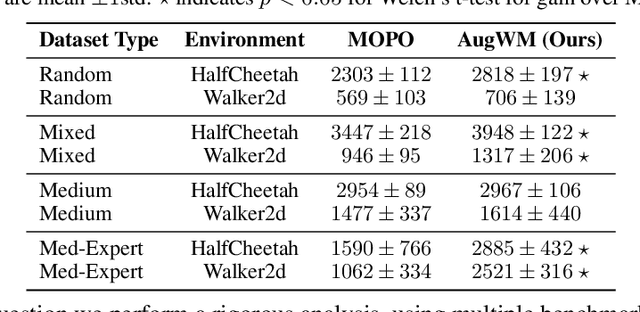

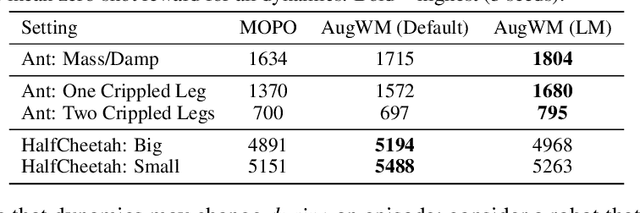
Reinforcement learning from large-scale offline datasets provides us with the ability to learn policies without potentially unsafe or impractical exploration. Significant progress has been made in the past few years in dealing with the challenge of correcting for differing behavior between the data collection and learned policies. However, little attention has been paid to potentially changing dynamics when transferring a policy to the online setting, where performance can be up to 90% reduced for existing methods. In this paper we address this problem with Augmented World Models (AugWM). We augment a learned dynamics model with simple transformations that seek to capture potential changes in physical properties of the robot, leading to more robust policies. We not only train our policy in this new setting, but also provide it with the sampled augmentation as a context, allowing it to adapt to changes in the environment. At test time we learn the context in a self-supervised fashion by approximating the augmentation which corresponds to the new environment. We rigorously evaluate our approach on over 100 different changed dynamics settings, and show that this simple approach can significantly improve the zero-shot generalization of a recent state-of-the-art baseline, often achieving successful policies where the baseline fails.
Self-Adjusting Population Sizes for Non-Elitist Evolutionary Algorithms: Why Success Rates Matter
Apr 12, 2021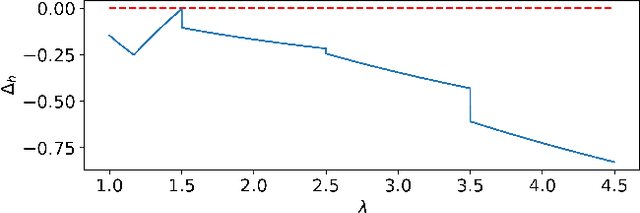
Recent theoretical studies have shown that self-adjusting mechanisms can provably outperform the best static parameters in evolutionary algorithms on discrete problems. However, the majority of these studies concerned elitist algorithms and we do not have a clear answer on whether the same mechanisms can be applied for non-elitist algorithms. We study one of the best-known parameter control mechanisms, the one-fifth success rule, to control the offspring population size $\lambda$ in the non-elitist ${(1 , \lambda)}$ EA. It is known that the ${(1 , \lambda)}$ EA has a sharp threshold with respect to the choice of $\lambda$ where the runtime on OneMax changes from polynomial to exponential time. Hence, it is not clear whether parameter control mechanisms are able to find and maintain suitable values of $\lambda$. We show that the answer crucially depends on the success rate $s$ (i.,e. a one-$(s+1)$-th success rule). We prove that, if the success rate is appropriately small, the self-adjusting ${(1 , \lambda)}$ EA optimises OneMax in $O(n)$ expected generations and $O(n \log n)$ expected evaluations. A small success rate is crucial: we also show that if the success rate is too large, the algorithm has an exponential runtime on OneMax.
WHOSe Heritage: Classification of UNESCO World Heritage "Outstanding Universal Value" Documents with Smoothed Labels
Apr 12, 2021
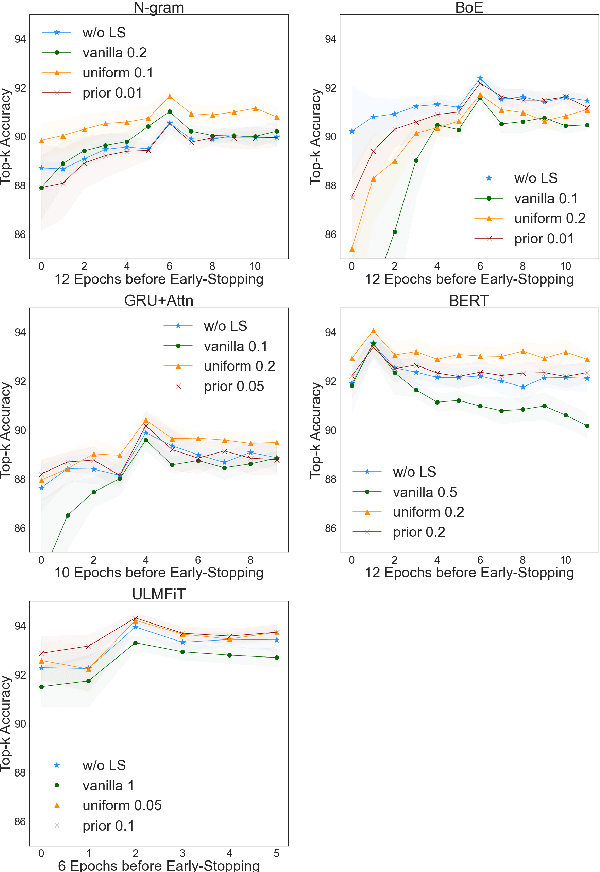
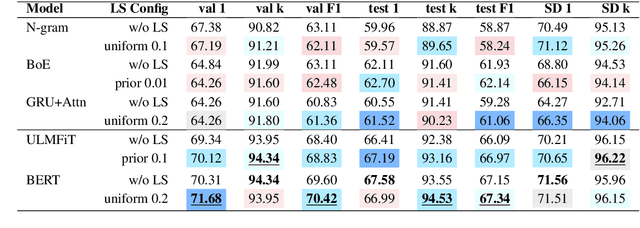

The UNESCO World Heritage List (WHL) is to identify the exceptionally valuable cultural and natural heritage to be preserved for mankind as a whole. Evaluating and justifying the Outstanding Universal Value (OUV) of each nomination in WHL is essentially important for a property to be inscribed, and yet a complex task even for experts since the criteria are not mutually exclusive. Furthermore, manual annotation of heritage values, which is currently dominant in the field, is knowledge-demanding and time-consuming, impeding systematic analysis of such authoritative documents in terms of their implications on heritage management. This study applies state-of-the-art NLP models to build a classifier on a new real-world dataset containing official OUV justification statements, seeking an explainable, scalable, and less biased automation tool to facilitate the nomination, evaluation, and monitoring processes of World Heritage properties. Label smoothing is innovatively adapted to transform the task smoothly between multi-class and multi-label classification by adding prior inter-class relationship knowledge into the labels, improving the performance of most baselines. The study shows that the best models fine-tuned from BERT and ULMFiT can reach 94.3% top-3 accuracy, which is promising to be further developed and applied in heritage research and practice.