 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021

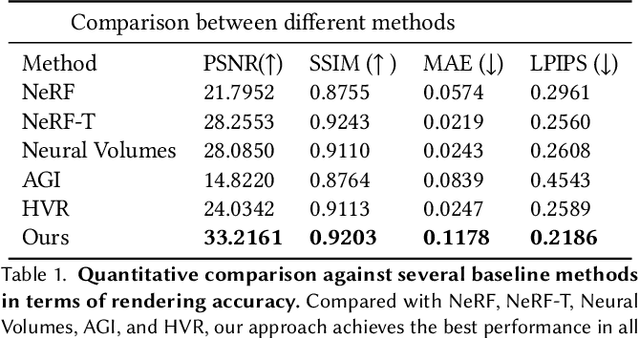
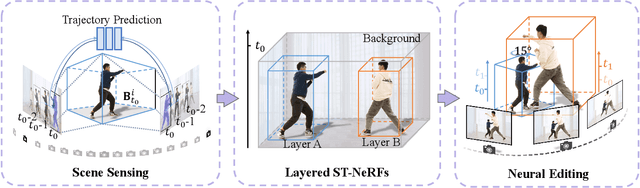
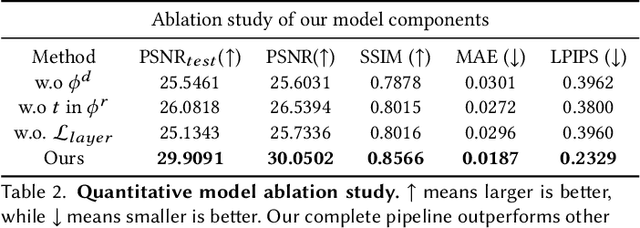
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.
Transient Information Adaptation of Artificial Intelligence: Towards Sustainable Data Processes in Complex Projects
Apr 18, 2021Large scale projects increasingly operate in complicated settings whilst drawing on an array of complex data-points, which require precise analysis for accurate control and interventions to mitigate possible project failure. Coupled with a growing tendency to rely on new information systems and processes in change projects, 90% of megaprojects globally fail to achieve their planned objectives. Renewed interest in the concept of Artificial Intelligence (AI) against a backdrop of disruptive technological innovations, seeks to enhance project managers cognitive capacity through the project lifecycle and enhance project excellence. However, despite growing interest there remains limited empirical insights on project managers ability to leverage AI for cognitive load enhancement in complex settings. As such this research adopts an exploratory sequential linear mixed methods approach to address unresolved empirical issues on transient adaptations of AI in complex projects, and the impact on cognitive load enhancement. Initial thematic findings from semi-structured interviews with domain experts, suggest that in order to leverage AI technologies and processes for sustainable cognitive load enhancement with complex data over time, project managers require improved knowledge and access to relevant technologies that mediate data processes in complex projects, but equally reflect application across different project phases. These initial findings support further hypothesis testing through a larger quantitative study incorporating structural equation modelling to examine the relationship between artificial intelligence and project managers cognitive load with project data in complex contexts.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Feb 18, 2021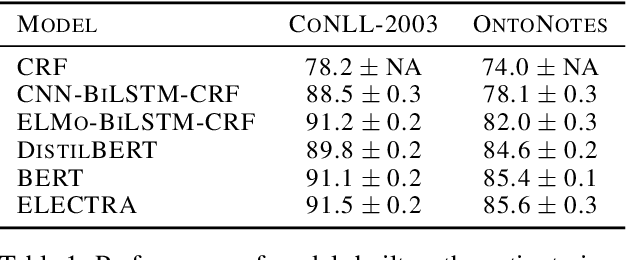
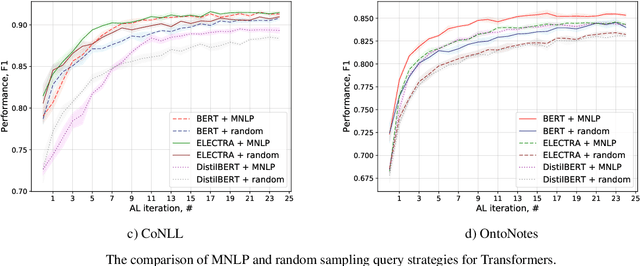
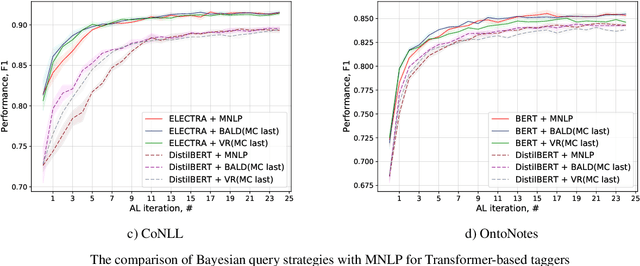
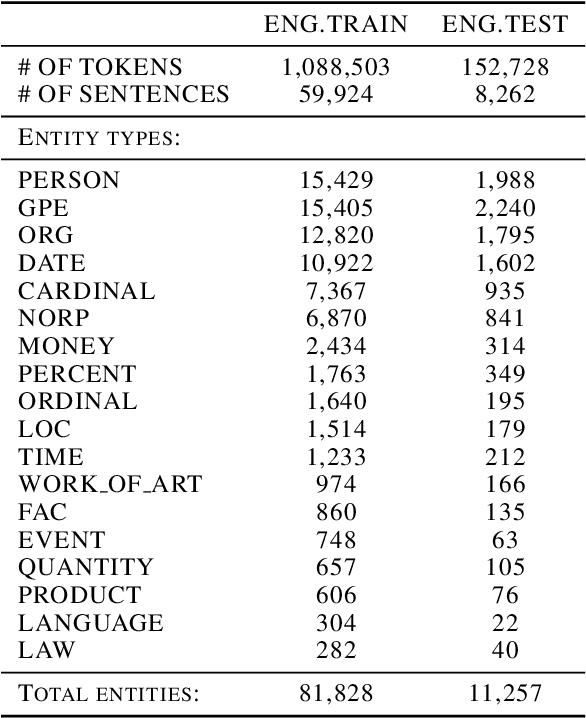
Annotating training data for sequence tagging of texts is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination for the sequence tagging task. We conduct an extensive empirical study of various Bayesian uncertainty estimation methods and Monte Carlo dropout options for deep pre-trained models in the active learning framework and find the best combinations for different types of models. Besides, we also demonstrate that to acquire instances during active learning, a full-size Transformer can be substituted with a distilled version, which yields better computational performance and reduces obstacles for applying deep active learning in practice.
DynamicHS: Streamlining Reiter's Hitting-Set Tree for Sequential Diagnosis
Dec 21, 2020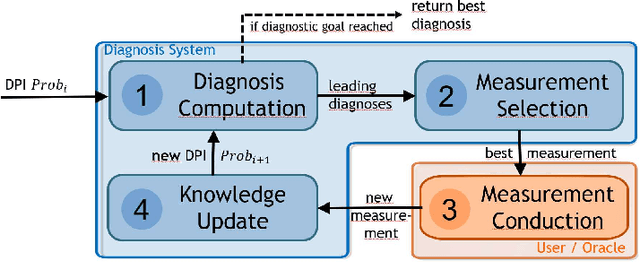
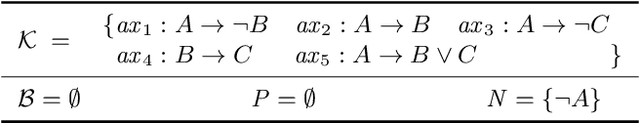


Given a system that does not work as expected, Sequential Diagnosis (SD) aims at suggesting a series of system measurements to isolate the true explanation for the system's misbehavior from a potentially exponential set of possible explanations. To reason about the best next measurement, SD methods usually require a sample of possible fault explanations at each step of the iterative diagnostic process. The computation of this sample can be accomplished by various diagnostic search algorithms. Among those, Reiter's HS-Tree is one of the most popular due its desirable properties and general applicability. Usually, HS-Tree is used in a stateless fashion throughout the SD process to (re)compute a sample of possible fault explanations in each iteration, each time given the latest (updated) system knowledge including all so-far collected measurements. At this, the built search tree is discarded between two iterations, although often large parts of the tree have to be rebuilt in the next iteration, involving redundant operations and calls to costly reasoning services. As a remedy to this, we propose DynamicHS, a variant of HS-Tree that maintains state throughout the diagnostic session and additionally embraces special strategies to minimize the number of expensive reasoner invocations. In this vein, DynamicHS provides an answer to a longstanding question posed by Raymond Reiter in his seminal paper from 1987. Extensive evaluations on real-world diagnosis problems prove the reasonability of the DynamicHS and testify its clear superiority to HS-Tree wrt. computation time. More specifically, DynamicHS outperformed HS-Tree in 96% of the executed sequential diagnosis sessions and, per run, the latter required up to 800% the time of the former. Remarkably, DynamicHS achieves these performance improvements while preserving all desirable properties as well as the general applicability of HS-Tree.
Black-box Adversarial Attacks in Autonomous Vehicle Technology
Jan 15, 2021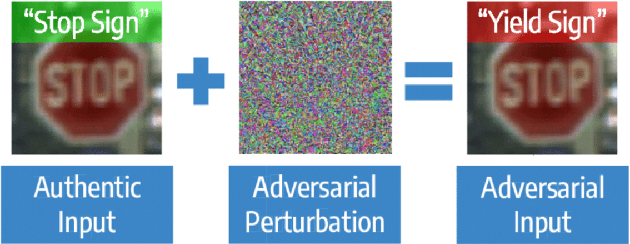
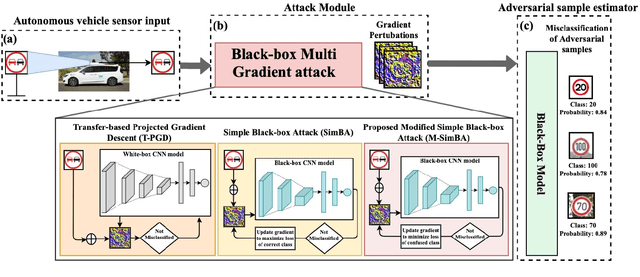
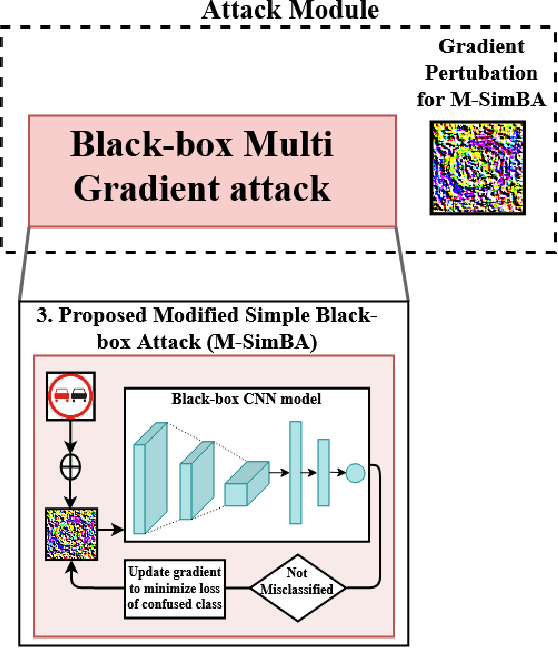
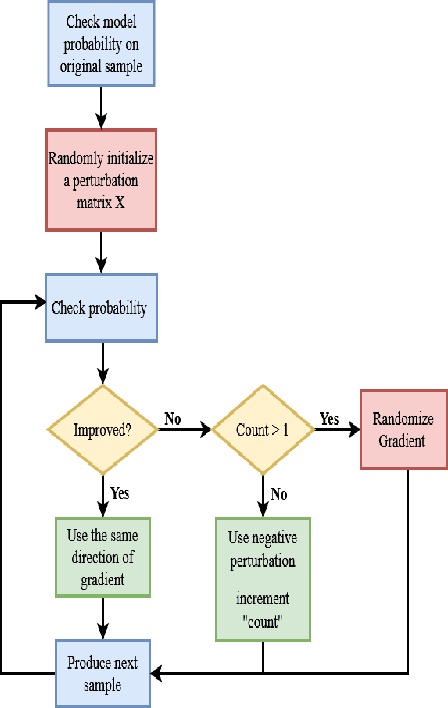
Despite the high quality performance of the deep neural network in real-world applications, they are susceptible to minor perturbations of adversarial attacks. This is mostly undetectable to human vision. The impact of such attacks has become extremely detrimental in autonomous vehicles with real-time "safety" concerns. The black-box adversarial attacks cause drastic misclassification in critical scene elements such as road signs and traffic lights leading the autonomous vehicle to crash into other vehicles or pedestrians. In this paper, we propose a novel query-based attack method called Modified Simple black-box attack (M-SimBA) to overcome the use of a white-box source in transfer based attack method. Also, the issue of late convergence in a Simple black-box attack (SimBA) is addressed by minimizing the loss of the most confused class which is the incorrect class predicted by the model with the highest probability, instead of trying to maximize the loss of the correct class. We evaluate the performance of the proposed approach to the German Traffic Sign Recognition Benchmark (GTSRB) dataset. We show that the proposed model outperforms the existing models like Transfer-based projected gradient descent (T-PGD), SimBA in terms of convergence time, flattening the distribution of confused class probability, and producing adversarial samples with least confidence on the true class.
Symmetry-Aware Reservoir Computing
Jan 30, 2021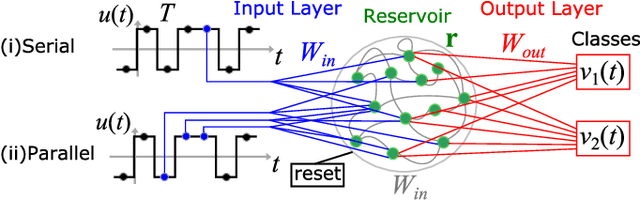
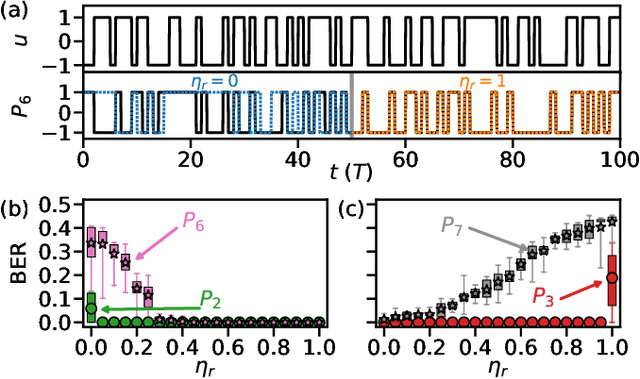
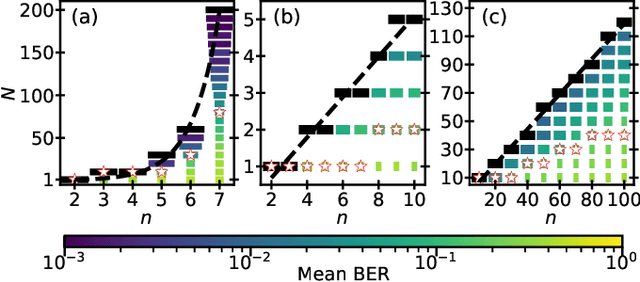
We demonstrate that matching the symmetry properties of a reservoir computer (RC) to the data being processed can dramatically increase its processing power. We apply our method to the parity task, a challenging benchmark problem, which highlights the benefits of symmetry matching. Our method outperforms all other approaches on this task, even artificial neural networks (ANN) hand crafted for this problem. The symmetry-aware RC can obtain zero error using an exponentially reduced number of artificial neurons and training data, greatly speeding up the time-to-result. We anticipate that generalizations of our procedure will have widespread applicability in information processing with ANNs.
Using contrastive learning to improve the performance of steganalysis schemes
Mar 01, 2021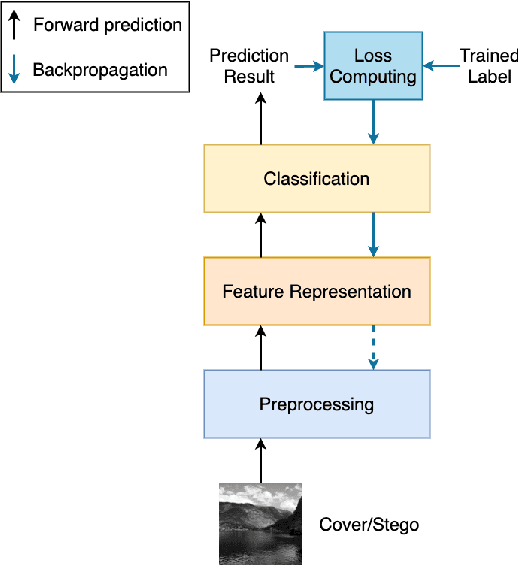
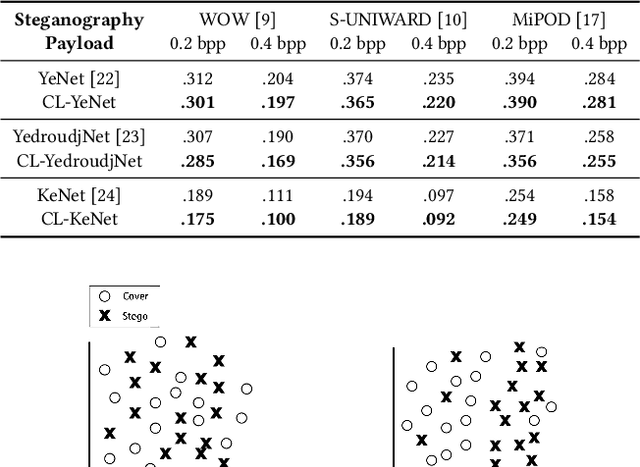
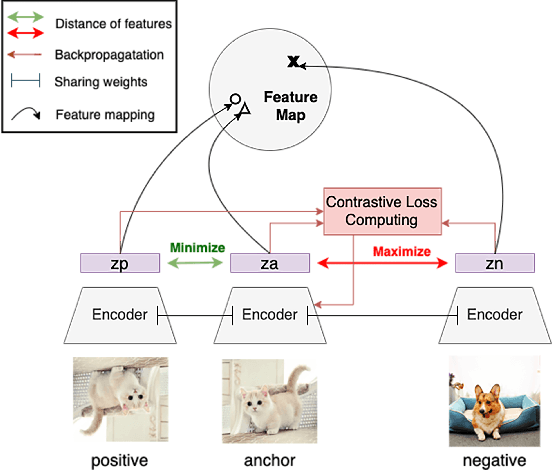
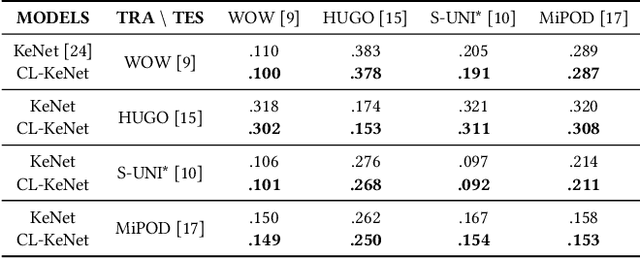
To improve the detection accuracy and generalization of steganalysis, this paper proposes the Steganalysis Contrastive Framework (SCF) based on contrastive learning. The SCF improves the feature representation of steganalysis by maximizing the distance between features of samples of different categories and minimizing the distance between features of samples of the same category. To decrease the computing complexity of the contrastive loss in supervised learning, we design a novel Steganalysis Contrastive Loss (StegCL) based on the equivalence and transitivity of similarity. The StegCL eliminates the redundant computing in the existing contrastive loss. The experimental results show that the SCF improves the generalization and detection accuracy of existing steganalysis DNNs, and the maximum promotion is 2% and 3% respectively. Without decreasing the detection accuracy, the training time of using the StegCL is 10% of that of using the contrastive loss in supervised learning.
Sill-Net: Feature Augmentation with Separated Illumination Representation
Feb 06, 2021

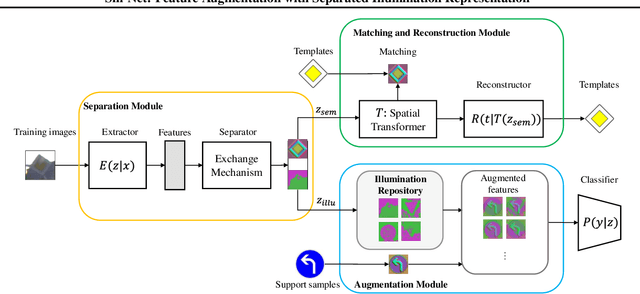

For visual object recognition tasks, the illumination variations can cause distinct changes in object appearance and thus confuse the deep neural network based recognition models. Especially for some rare illumination conditions, collecting sufficient training samples could be time-consuming and expensive. To solve this problem, in this paper we propose a novel neural network architecture called Separating-Illumination Network (Sill-Net). Sill-Net learns to separate illumination features from images, and then during training we augment training samples with these separated illumination features in the feature space. Experimental results demonstrate that our approach outperforms current state-of-the-art methods in several object classification benchmarks.
Adversarial Semi-supervised Learning for Corporate Credit Ratings
Apr 12, 2021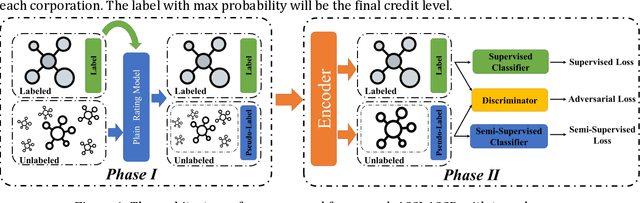
Corporate credit rating is an analysis of credit risks within a corporation, which plays a vital role during the management of financial risk. Traditionally, the rating assessment process based on the historical profile of corporation is usually expensive and complicated, which often takes months. Therefore, most of the corporations, which are lacking in money and time, can't get their own credit level. However, we believe that although these corporations haven't their credit rating levels (unlabeled data), this big data contains useful knowledge to improve credit system. In this work, its major challenge lies in how to effectively learn the knowledge from unlabeled data and help improve the performance of the credit rating system. Specifically, we consider the problem of adversarial semi-supervised learning (ASSL) for corporate credit rating which has been rarely researched before. A novel framework adversarial semi-supervised learning for corporate credit rating (ASSL4CCR) which includes two phases is proposed to address these problems. In the first phase, we train a normal rating system via a normal machine-learning algorithm to give unlabeled data pseudo rating level. Then in the second phase, adversarial semi-supervised learning is applied uniting labeled data and pseudo-labeled data. To demonstrate the effectiveness of the proposed ASSL4CCR, we conduct extensive experiments on the Chinese public-listed corporate rating dataset, which proves that ASSL4CCR outperforms the state-of-the-art methods consistently.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 12, 2021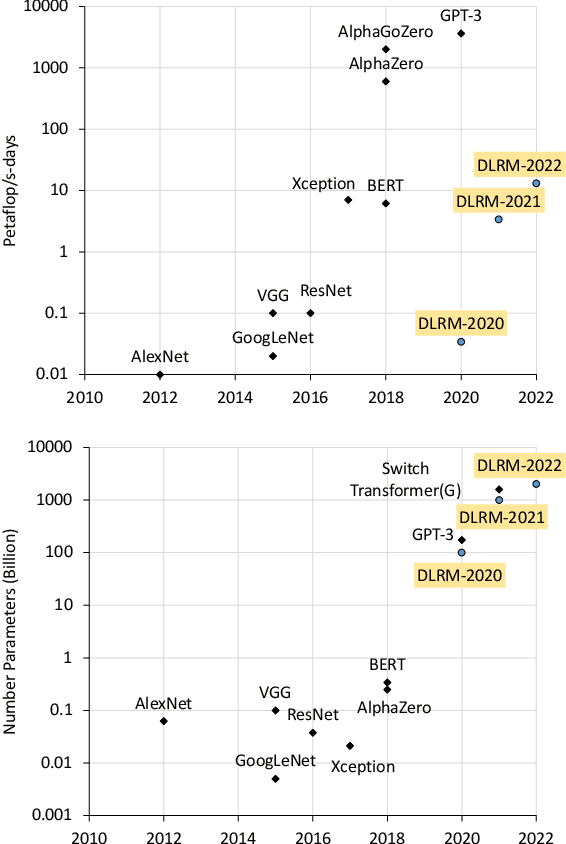

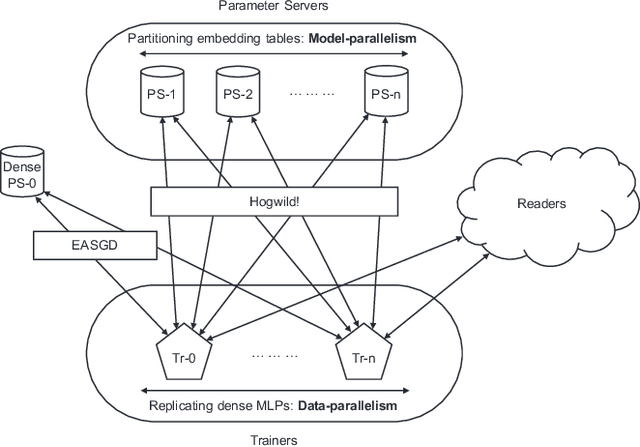
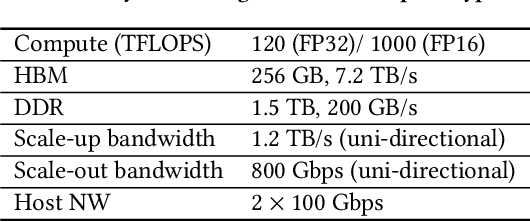
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of \zion platform, namely \zionex. We demonstrate the capability to train very large DLRMs with up to \emph{12 Trillion parameters} and show that we can attain $40\times$ speedup in terms of time to solution over previous systems. We achieve this by (i) designing the \zionex platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.