 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph-based Motion Planning for Automated Vehicles using Multi-model Branching and Admissible Heuristics
Feb 15, 2021
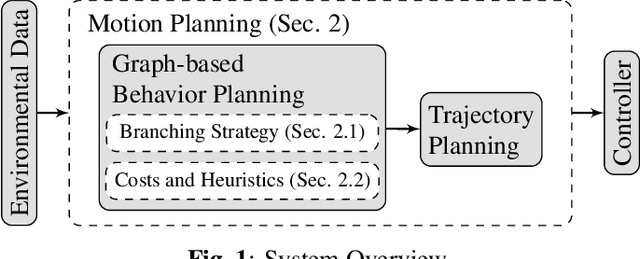
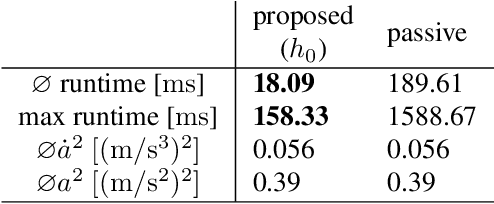
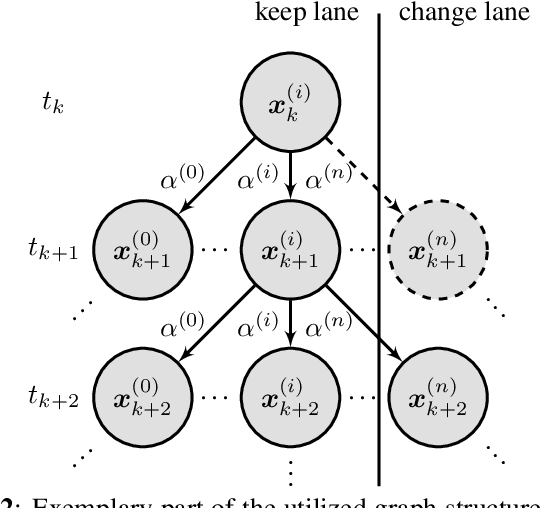
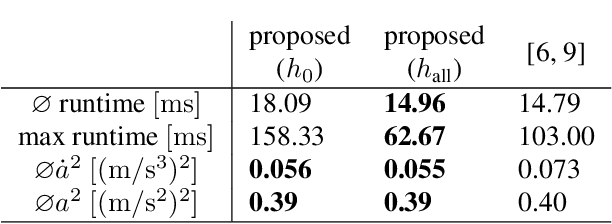
Automated driving in urban scenarios requires efficient planning algorithms able to handle complex situations in real-time. A popular approach is to use graph-based planning methods in order to obtain a rough trajectory which is subsequently optimized. A key aspect is the generation of trajectories implementing comfortable and safe behavior already during graph-search while keeping computation times low. To capture this aspect, on the one hand, a branching strategy is presented in this work that leads to better performance in terms of quality of resulting trajectories and runtime. On the other hand, admissible heuristics are shown which guide the graph-search efficiently, where the solution remains optimal.
UAV-Assisted Over-the-Air Computation
Jan 25, 2021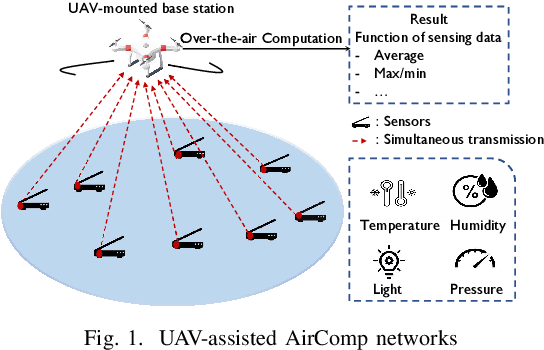
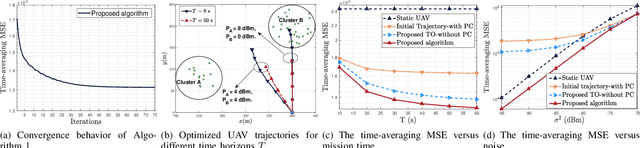
Over-the-air computation (AirComp) provides a promising way to support ultrafast aggregation of distributed data. However, its performance cannot be guaranteed in long-distance transmission due to the distortion induced by the channel fading and noise. To unleash the full potential of AirComp, this paper proposes to use a low-cost unmanned aerial vehicle (UAV) acting as a mobile base station to assist AirComp systems. Specifically, due to its controllable high-mobility and high-altitude, the UAV can move sufficiently close to the sensors to enable line-of-sight transmission and adaptively adjust all the links' distances, thereby enhancing the signal magnitude alignment and noise suppression. Our goal is to minimize the time-averaging mean-square error for AirComp by jointly optimizing the UAV trajectory, the scaling factor at the UAV, and the transmit power at the sensors, under constraints on the UAV's predetermined locations and flying speed, sensors' average and peak power limits. However, due to the highly coupled optimization variables and time-dependent constraints, the resulting problem is non-convex and challenging. We thus propose an efficient iterative algorithm by applying the block coordinate descent and successive convex optimization techniques. Simulation results verify the convergence of the proposed algorithm and demonstrate the performance gains and robustness of the proposed design compared with benchmarks.
Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies
Nov 01, 2020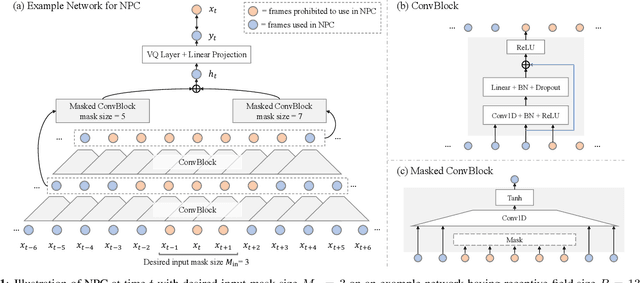
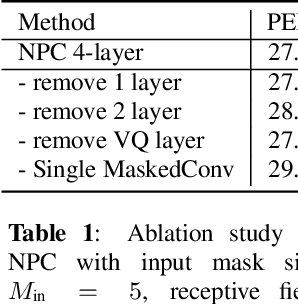
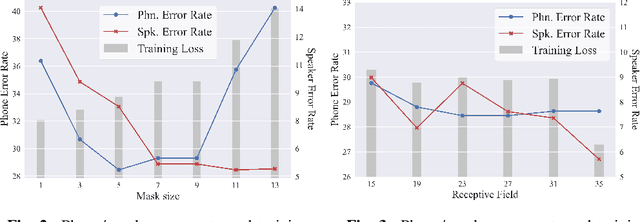
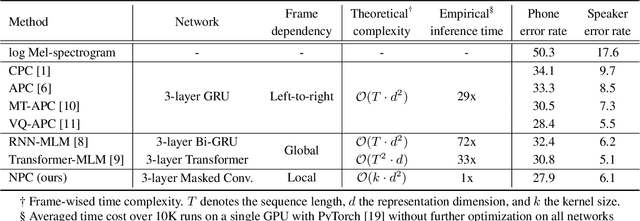
Self-supervised speech representations have been shown to be effective in a variety of speech applications. However, existing representation learning methods generally rely on the autoregressive model and/or observed global dependencies while generating the representation. In this work, we propose Non-Autoregressive Predictive Coding (NPC), a self-supervised method, to learn a speech representation in a non-autoregressive manner by relying only on local dependencies of speech. NPC has a conceptually simple objective and can be implemented easily with the introduced Masked Convolution Blocks. NPC offers a significant speedup for inference since it is parallelizable in time and has a fixed inference time for each time step regardless of the input sequence length. We discuss and verify the effectiveness of NPC by theoretically and empirically comparing it with other methods. We show that the NPC representation is comparable to other methods in speech experiments on phonetic and speaker classification while being more efficient.
MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo
Mar 29, 2021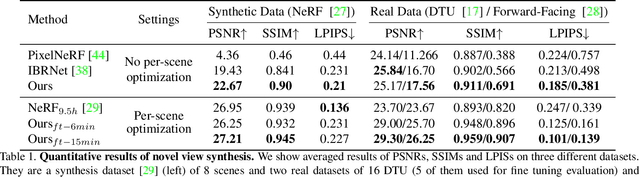
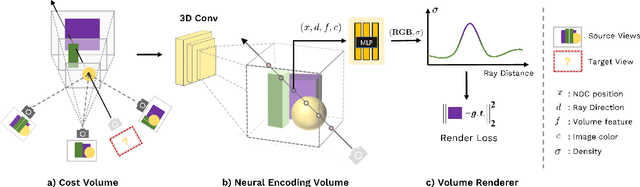
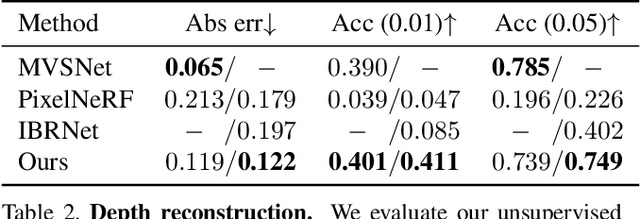

We present MVSNeRF, a novel neural rendering approach that can efficiently reconstruct neural radiance fields for view synthesis. Unlike prior works on neural radiance fields that consider per-scene optimization on densely captured images, we propose a generic deep neural network that can reconstruct radiance fields from only three nearby input views via fast network inference. Our approach leverages plane-swept cost volumes (widely used in multi-view stereo) for geometry-aware scene reasoning, and combines this with physically based volume rendering for neural radiance field reconstruction. We train our network on real objects in the DTU dataset, and test it on three different datasets to evaluate its effectiveness and generalizability. Our approach can generalize across scenes (even indoor scenes, completely different from our training scenes of objects) and generate realistic view synthesis results using only three input images, significantly outperforming concurrent works on generalizable radiance field reconstruction. Moreover, if dense images are captured, our estimated radiance field representation can be easily fine-tuned; this leads to fast per-scene reconstruction with higher rendering quality and substantially less optimization time than NeRF.
Analyzing Collective Motion Using Graph Fourier Analysis
Mar 15, 2021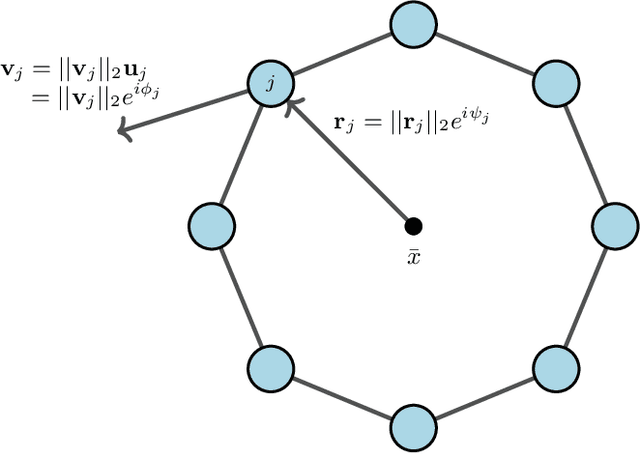
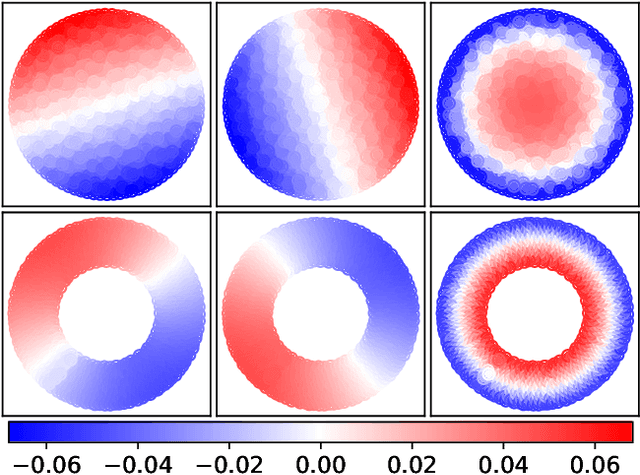
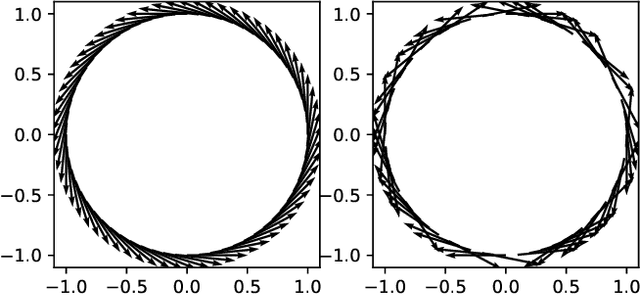
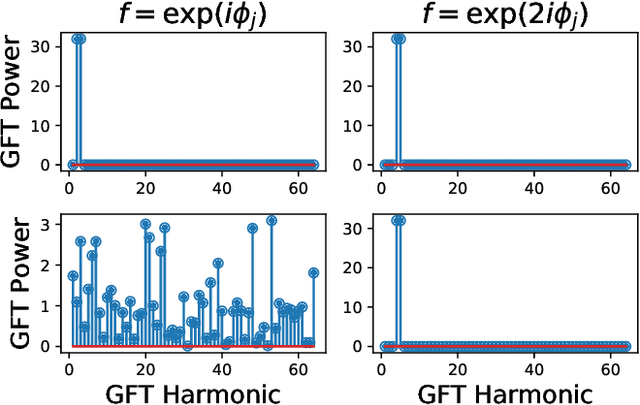
Collective motion in animal groups, such as swarms of insects, flocks of birds, and schools of fish, are some of the most visually striking examples of emergent behavior. Empirical analysis of these behaviors in experiment or computational simulation primarily involves the use of "swarm-averaged" metrics or order parameters such as velocity alignment and angular momentum. Recently, tools from computational topology have been applied to the analysis of swarms to further understand and automate the detection of fundamentally different swarm structures evolving in space and time. Here, we show how the field of graph signal processing can be used to fuse these two approaches by collectively analyzing swarm properties using graph Fourier harmonics that respect the topological structure of the swarm. This graph Fourier analysis reveals hidden structure in a number of common swarming states and forms the basis of a flexible analysis framework for collective motion.
Temporally-Continuous Probabilistic Prediction using Polynomial Trajectory Parameterization
Nov 01, 2020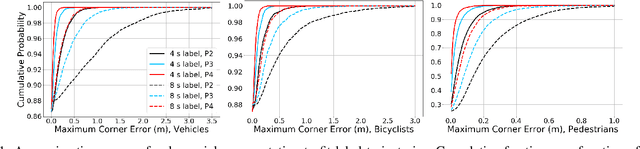
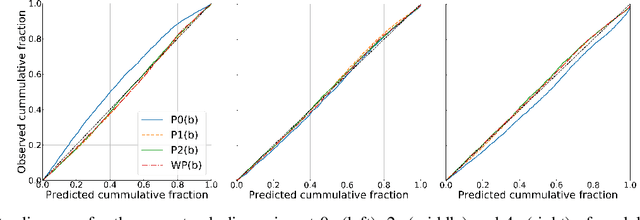
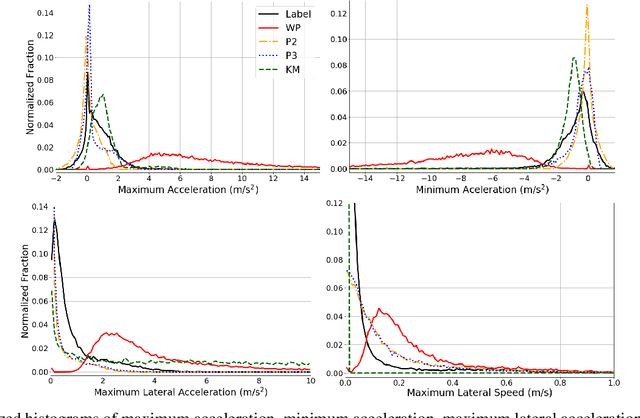
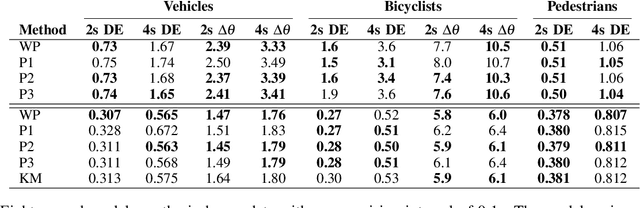
A commonly-used representation for motion prediction of actors is a sequence of waypoints (comprising positions and orientations) for each actor at discrete future time-points. While this approach is simple and flexible, it can exhibit unrealistic higher-order derivatives (such as acceleration) and approximation errors at intermediate time steps. To address this issue we propose a simple and general representation for temporally continuous probabilistic trajectory prediction that is based on polynomial trajectory parameterization. We evaluate the proposed representation on supervised trajectory prediction tasks using two large self-driving data sets. The results show realistic higher-order derivatives and better accuracy at interpolated time-points, as well as the benefits of the inferred noise distributions over the trajectories. Extensive experimental studies based on existing state-of-the-art models demonstrate the effectiveness of the proposed approach relative to other representations in predicting the future motions of vehicle, bicyclist, and pedestrian traffic actors.
ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
Apr 06, 2021
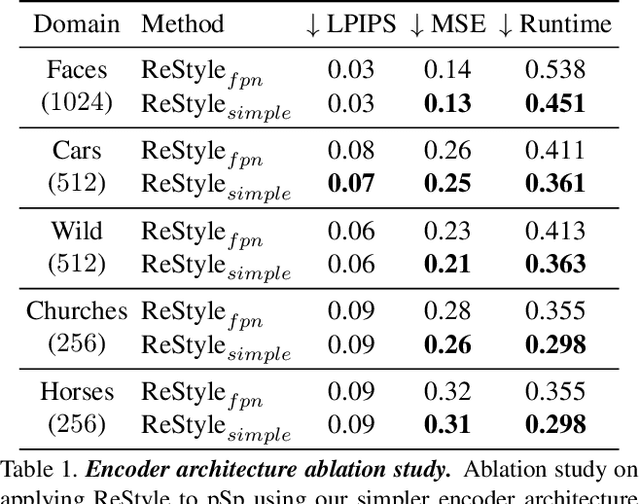
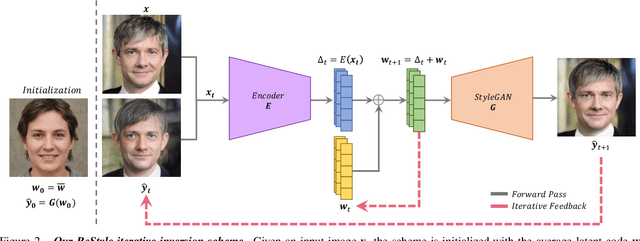
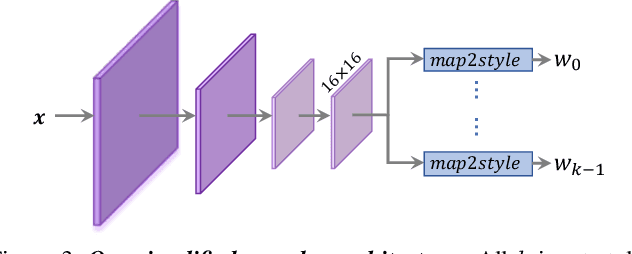
Recently, the power of unconditional image synthesis has significantly advanced through the use of Generative Adversarial Networks (GANs). The task of inverting an image into its corresponding latent code of the trained GAN is of utmost importance as it allows for the manipulation of real images, leveraging the rich semantics learned by the network. Recognizing the limitations of current inversion approaches, in this work we present a novel inversion scheme that extends current encoder-based inversion methods by introducing an iterative refinement mechanism. Instead of directly predicting the latent code of a given real image using a single pass, the encoder is tasked with predicting a residual with respect to the current estimate of the inverted latent code in a self-correcting manner. Our residual-based encoder, named ReStyle, attains improved accuracy compared to current state-of-the-art encoder-based methods with a negligible increase in inference time. We analyze the behavior of ReStyle to gain valuable insights into its iterative nature. We then evaluate the performance of our residual encoder and analyze its robustness compared to optimization-based inversion and state-of-the-art encoders.
Slow manifolds in recurrent networks encode working memory efficiently and robustly
Jan 08, 2021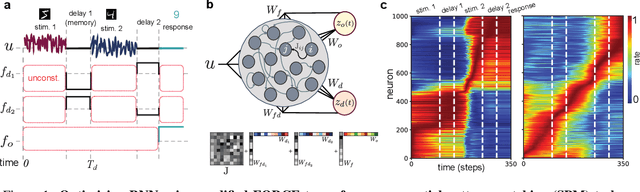
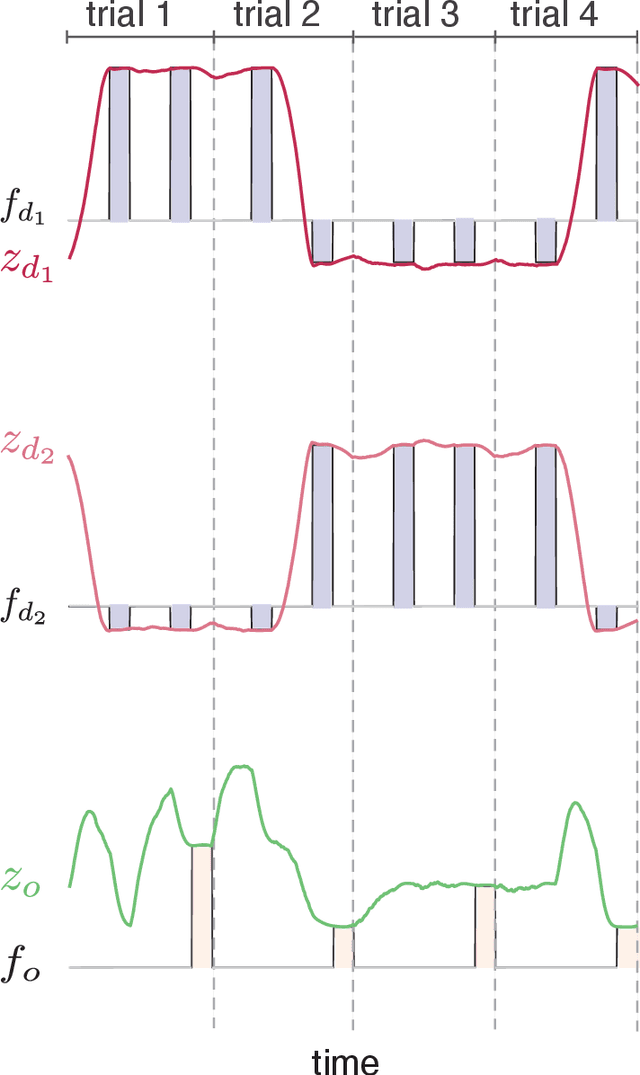
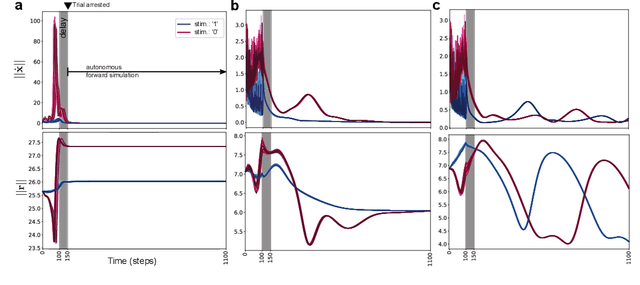
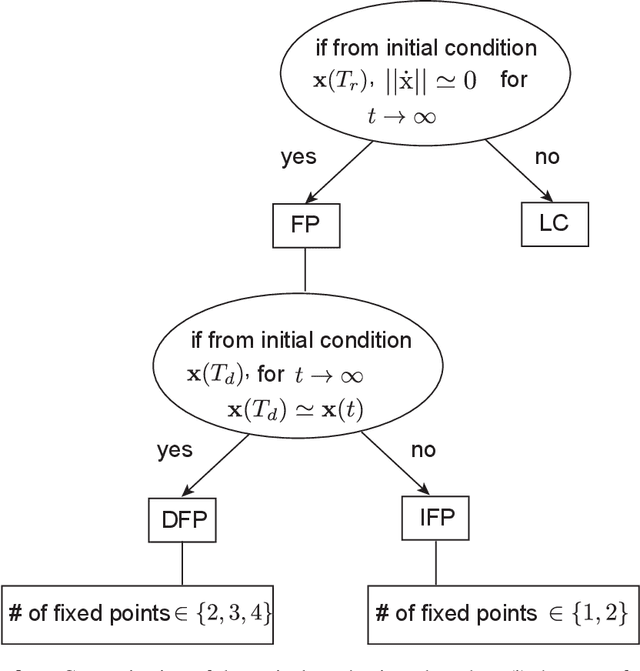
Working memory is a cognitive function involving the storage and manipulation of latent information over brief intervals of time, thus making it crucial for context-dependent computation. Here, we use a top-down modeling approach to examine network-level mechanisms of working memory, an enigmatic issue and central topic of study in neuroscience and machine intelligence. We train thousands of recurrent neural networks on a working memory task and then perform dynamical systems analysis on the ensuing optimized networks, wherein we find that four distinct dynamical mechanisms can emerge. In particular, we show the prevalence of a mechanism in which memories are encoded along slow stable manifolds in the network state space, leading to a phasic neuronal activation profile during memory periods. In contrast to mechanisms in which memories are directly encoded at stable attractors, these networks naturally forget stimuli over time. Despite this seeming functional disadvantage, they are more efficient in terms of how they leverage their attractor landscape and paradoxically, are considerably more robust to noise. Our results provide new dynamical hypotheses regarding how working memory function is encoded in both natural and artificial neural networks.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 14, 2021
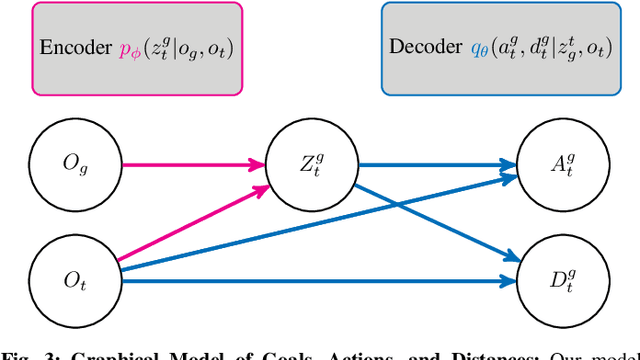
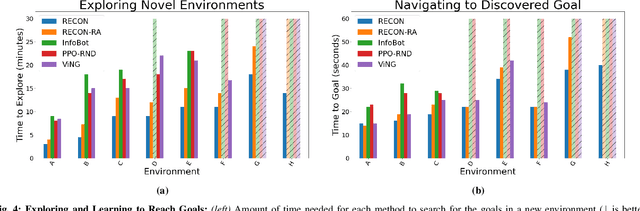
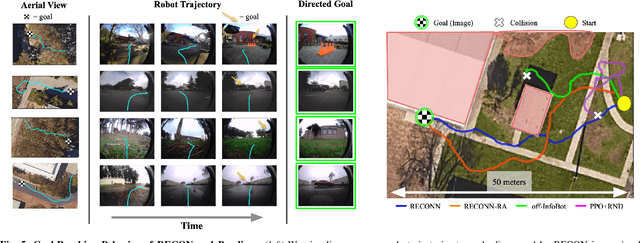
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Dynamic Network Embedding Survey
Mar 29, 2021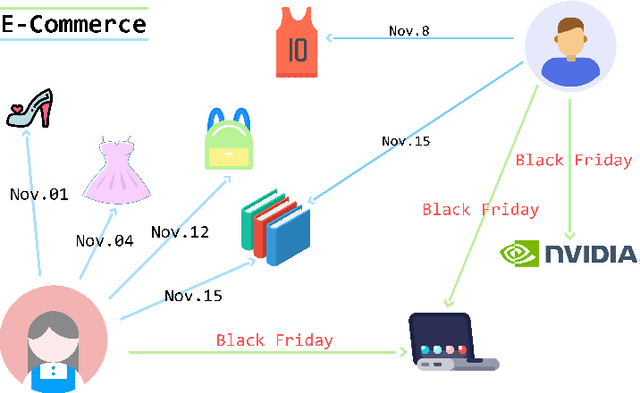
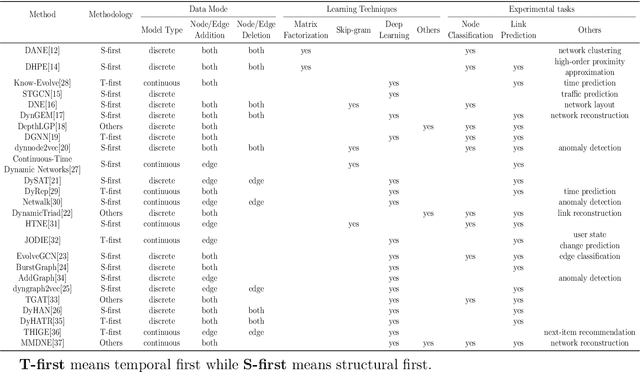
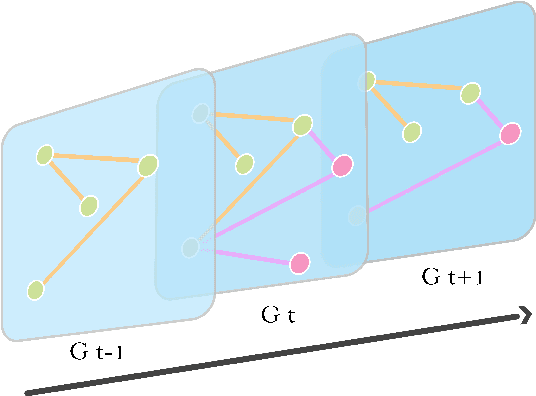
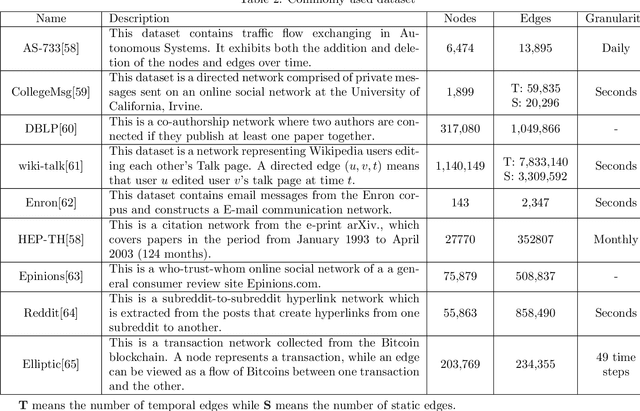
Since many real world networks are evolving over time, such as social networks and user-item networks, there are increasing research efforts on dynamic network embedding in recent years. They learn node representations from a sequence of evolving graphs but not only the latest network, for preserving both structural and temporal information from the dynamic networks. Due to the lack of comprehensive investigation of them, we give a survey of dynamic network embedding in this paper. Our survey inspects the data model, representation learning technique, evaluation and application of current related works and derives common patterns from them. Specifically, we present two basic data models, namely, discrete model and continuous model for dynamic networks. Correspondingly, we summarize two major categories of dynamic network embedding techniques, namely, structural-first and temporal-first that are adopted by most related works. Then we build a taxonomy that refines the category hierarchy by typical learning models. The popular experimental data sets and applications are also summarized. Lastly, we have a discussion of several distinct research topics in dynamic network embedding.