 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lighting the Darkness in the Deep Learning Era
Apr 21, 2021

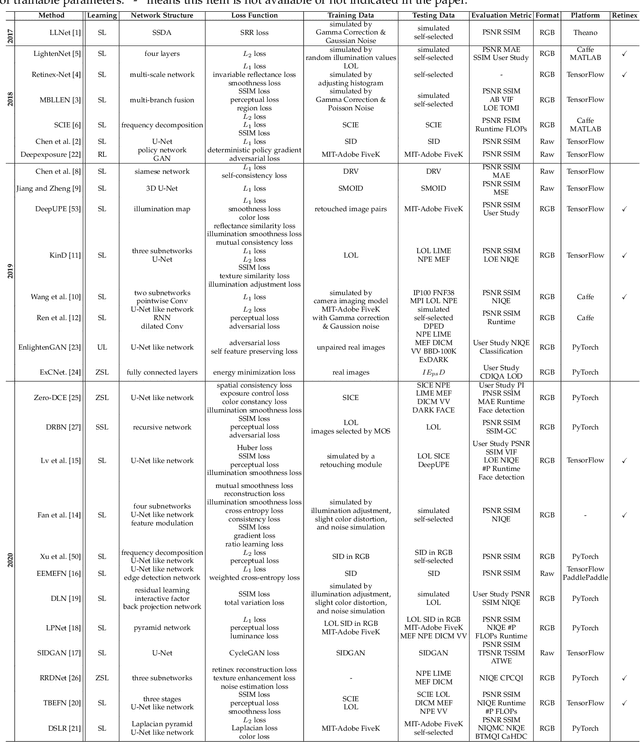

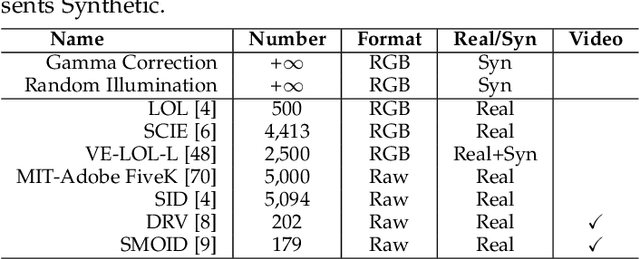
Low-light image enhancement (LLIE) aims at improving the perception or interpretability of an image captured in an environment with poor illumination. Recent advances in this area are dominated by deep learning-based solutions, where many learning strategies, network structures, loss functions, training data, etc. have been employed. In this paper, we provide a comprehensive survey to cover various aspects ranging from algorithm taxonomy to unsolved open issues. To examine the generalization of existing methods, we propose a large-scale low-light image and video dataset, in which the images and videos are taken by different mobile phones' cameras under diverse illumination conditions. Besides, for the first time, we provide a unified online platform that covers many popular LLIE methods, of which the results can be produced through a user-friendly web interface. In addition to qualitative and quantitative evaluation of existing methods on publicly available and our proposed datasets, we also validate their performance in face detection in the dark. This survey together with the proposed dataset and online platform could serve as a reference source for future study and promote the development of this research field. The proposed platform and the collected methods, datasets, and evaluation metrics are publicly available and will be regularly updated at https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open. We will release our low-light image and video dataset.
Network Classifiers Based on Social Learning
Oct 23, 2020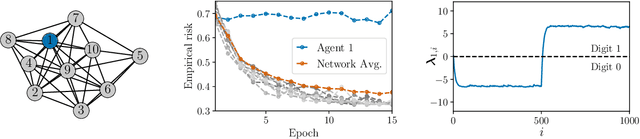
This work proposes a new way of combining independently trained classifiers over space and time. Combination over space means that the outputs of spatially distributed classifiers are aggregated. Combination over time means that the classifiers respond to streaming data during testing and continue to improve their performance even during this phase. By doing so, the proposed architecture is able to improve prediction performance over time with unlabeled data. Inspired by social learning algorithms, which require prior knowledge of the observations distribution, we propose a Social Machine Learning (SML) paradigm that is able to exploit the imperfect models generated during the learning phase. We show that this strategy results in consistent learning with high probability, and it yields a robust structure against poorly trained classifiers. Simulations with an ensemble of feedforward neural networks are provided to illustrate the theoretical results.
Distantly Supervised Transformers For E-Commerce Product QA
Apr 07, 2021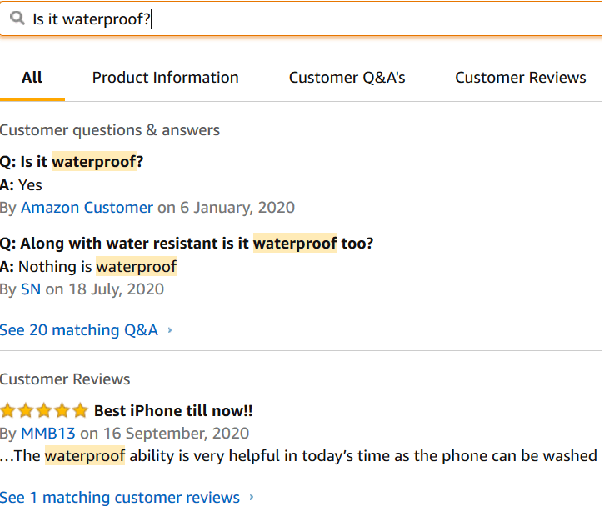
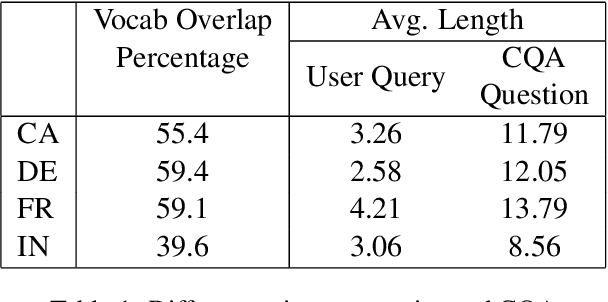
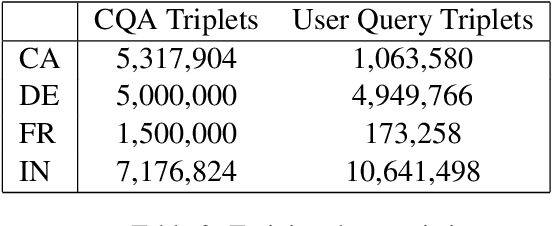
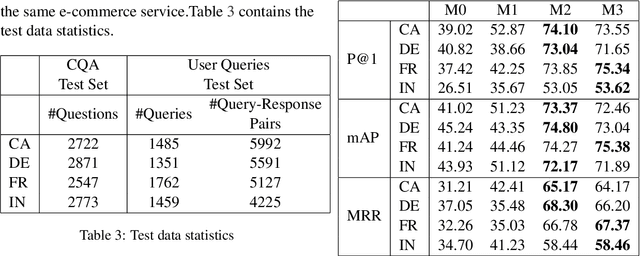
We propose a practical instant question answering (QA) system on product pages of ecommerce services, where for each user query, relevant community question answer (CQA) pairs are retrieved. User queries and CQA pairs differ significantly in language characteristics making relevance learning difficult. Our proposed transformer-based model learns a robust relevance function by jointly learning unified syntactic and semantic representations without the need for human labeled data. This is achieved by distantly supervising our model by distilling from predictions of a syntactic matching system on user queries and simultaneously training with CQA pairs. Training with CQA pairs helps our model learning semantic QA relevance and distant supervision enables learning of syntactic features as well as the nuances of user querying language. Additionally, our model encodes queries and candidate responses independently allowing offline candidate embedding generation thereby minimizing the need for real-time transformer model execution. Consequently, our framework is able to scale to large e-commerce QA traffic. Extensive evaluation on user queries shows that our framework significantly outperforms both syntactic and semantic baselines in offline as well as large scale online A/B setups of a popular e-commerce service.
TSception: Capturing Temporal Dynamics and Spatial Asymmetry from EEG for Emotion Recognition
Apr 07, 2021
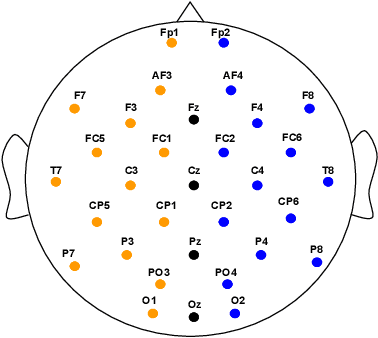
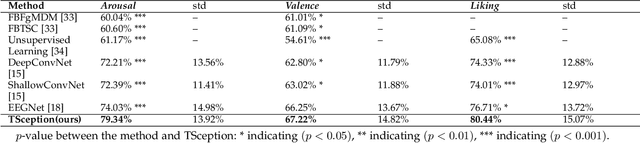
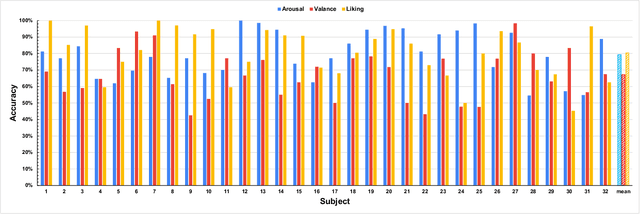
In this paper, we propose TSception, a multi-scale convolutional neural network, to learn temporal dynamics and spatial asymmetry from affective electroencephalogram (EEG). TSception consists of dynamic temporal, asymmetric spatial, and high-level fusion Layers, which learn discriminative representations in the time and channel dimensions simultaneously. The dynamic temporal layer consists of multi-scale 1D convolutional kernels whose lengths are related to the sampling rate of the EEG signal, which learns its dynamic temporal and frequency representations. The asymmetric spatial layer takes advantage of the asymmetric neural activations underlying emotional responses, learning the discriminative global and hemisphere representations. The learned spatial representations will be fused by a high-level fusion layer. With robust nested cross-validation settings, the proposed method is evaluated on two publicly available datasets DEAP and AMIGOS. And the performance is compared with prior reported methods such as FBFgMDM, FBTSC, Unsupervised learning, DeepConvNet, ShallowConvNet, and EEGNet. The results indicate that the proposed method significantly (p<0.05) outperforms others in terms of classification accuracy. The proposed methods can be utilized in emotion regulation therapy for emotion recognition in the future. The source code can be found at: https://github.com/deepBrains/TSception-New
From Static to Dynamic Node Embeddings
Sep 21, 2020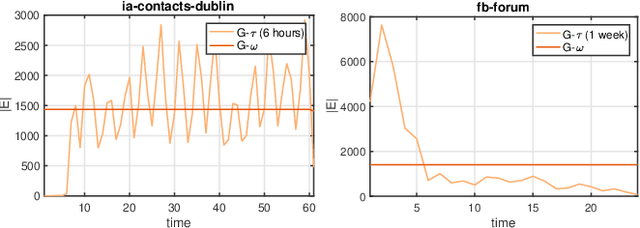
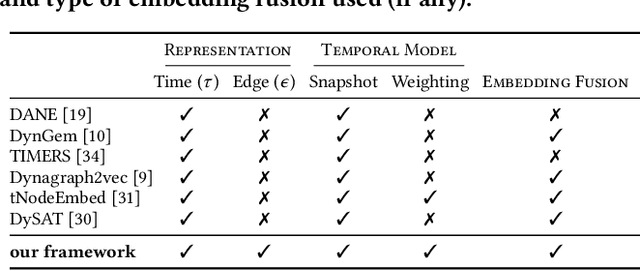
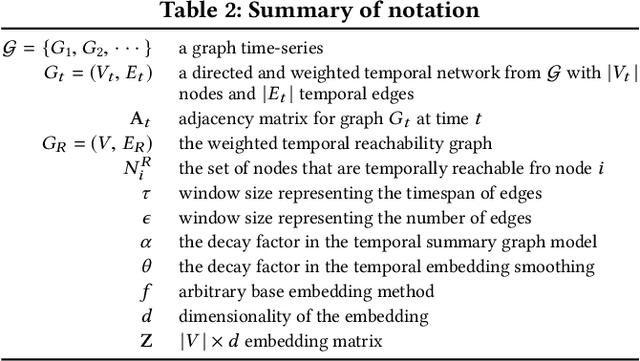
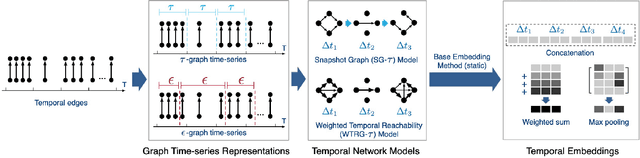
We introduce a general framework for leveraging graph stream data for temporal prediction-based applications. Our proposed framework includes novel methods for learning an appropriate graph time-series representation, modeling and weighting the temporal dependencies, and generalizing existing embedding methods for such data. While previous work on dynamic modeling and embedding has focused on representing a stream of timestamped edges using a time-series of graphs based on a specific time-scale (e.g., 1 month), we propose the notion of an $\epsilon$-graph time-series that uses a fixed number of edges for each graph, and show its superiority over the time-scale representation used in previous work. In addition, we propose a number of new temporal models based on the notion of temporal reachability graphs and weighted temporal summary graphs. These temporal models are then used to generalize existing base (static) embedding methods by enabling them to incorporate and appropriately model temporal dependencies in the data. From the 6 temporal network models investigated (for each of the 7 base embedding methods), we find that the top-3 temporal models are always those that leverage the new $\epsilon$-graph time-series representation. Furthermore, the dynamic embedding methods from the framework almost always achieve better predictive performance than existing state-of-the-art dynamic node embedding methods that are developed specifically for such temporal prediction tasks. Finally, the findings of this work are useful for designing better dynamic embedding methods.
Self-Supervised Motion Retargeting with Safety Guarantee
Mar 11, 2021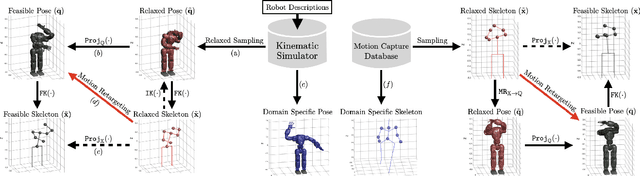
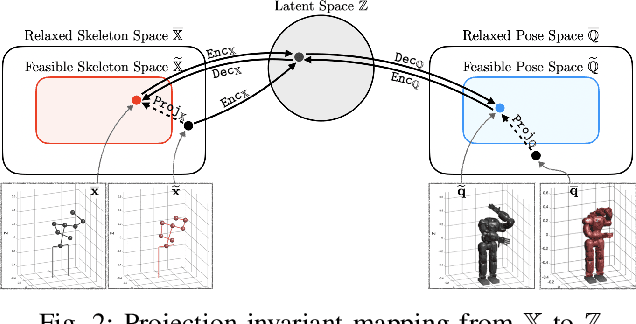
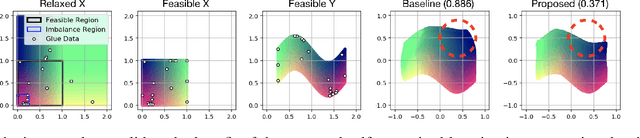
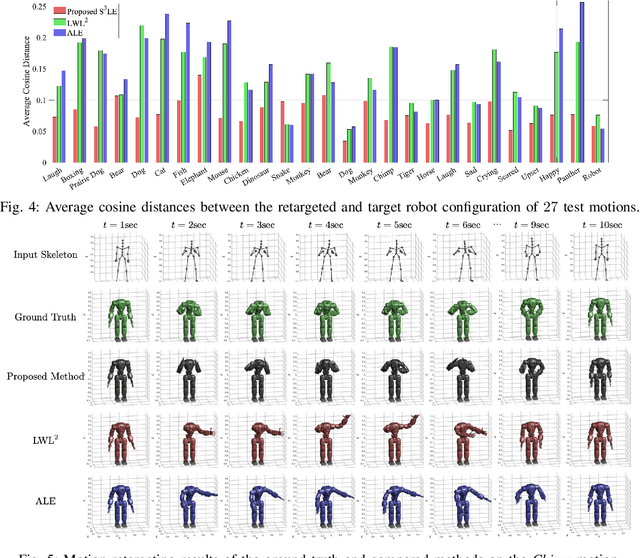
In this paper, we present self-supervised shared latent embedding (S3LE), a data-driven motion retargeting method that enables the generation of natural motions in humanoid robots from motion capture data or RGB videos. While it requires paired data consisting of human poses and their corresponding robot configurations, it significantly alleviates the necessity of time-consuming data-collection via novel paired data generating processes. Our self-supervised learning procedure consists of two steps: automatically generating paired data to bootstrap the motion retargeting, and learning a projection-invariant mapping to handle the different expressivity of humans and humanoid robots. Furthermore, our method guarantees that the generated robot pose is collision-free and satisfies position limits by utilizing nonparametric regression in the shared latent space. We demonstrate that our method can generate expressive robotic motions from both the CMU motion capture database and YouTube videos.
Strongly Adaptive OCO with Memory
Feb 02, 2021
Recent progress in online control has popularized online learning with memory, a variant of the standard online learning problem with loss functions dependent on the prediction history. In this paper, we propose the first strongly adaptive algorithm for this problem: on any interval $\mathcal{I}\subset[1:T]$, the proposed algorithm achieves $\tilde O\left(\sqrt{|\mathcal{I}|}\right)$ policy regret against the best fixed comparator for that interval. Combined with online control techniques, our algorithm results in a strongly adaptive regret bound for the control of linear time-varying systems.
Real-Time Energy Disaggregation of a Distribution Feeder's Demand Using Online Learning
May 04, 2018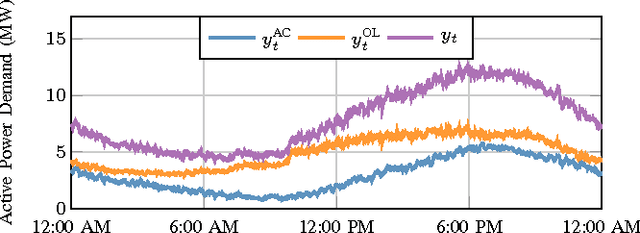
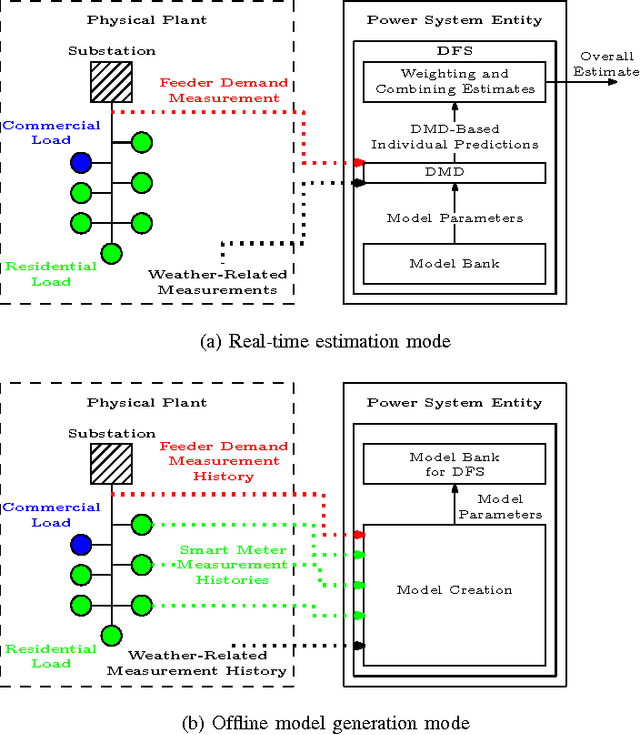
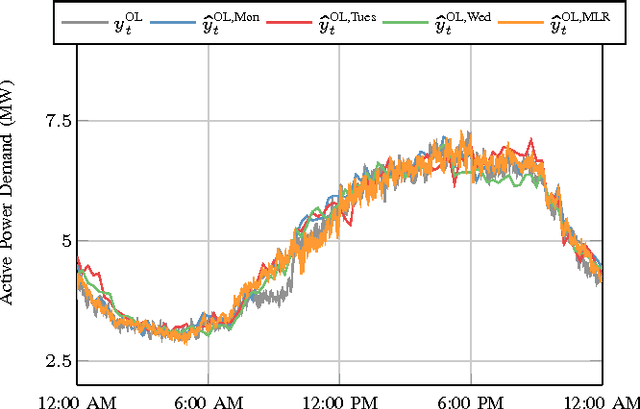
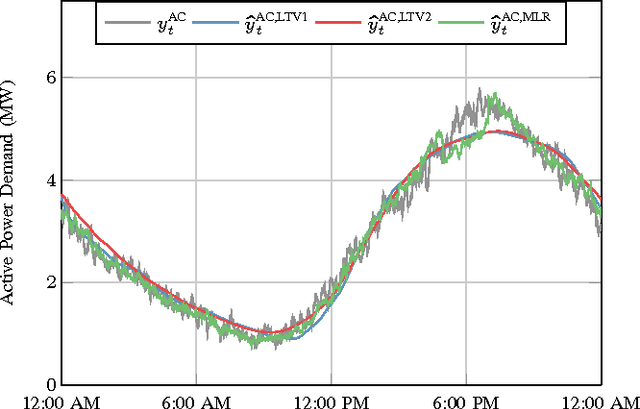
Though distribution system operators have been adding more sensors to their networks, they still often lack an accurate real-time picture of the behavior of distributed energy resources such as demand responsive electric loads and residential solar generation. Such information could improve system reliability, economic efficiency, and environmental impact. Rather than installing additional, costly sensing and communication infrastructure to obtain additional real-time information, it may be possible to use existing sensing capabilities and leverage knowledge about the system to reduce the need for new infrastructure. In this paper, we disaggregate a distribution feeder's demand measurements into: 1) the demand of a population of air conditioners, and 2) the demand of the remaining loads connected to the feeder. We use an online learning algorithm, Dynamic Fixed Share (DFS), that uses the real-time distribution feeder measurements as well as models generated from historical building- and device-level data. We develop two implementations of the algorithm and conduct case studies using real demand data from households and commercial buildings to investigate the effectiveness of the algorithm. The case studies demonstrate that DFS can effectively perform online disaggregation and the choice and construction of models included in the algorithm affects its accuracy, which is comparable to that of a set of Kalman filters.
Building Deep Learning Models to Predict Mortality in ICU Patients
Dec 11, 2020
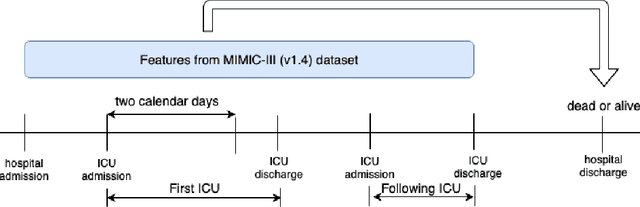
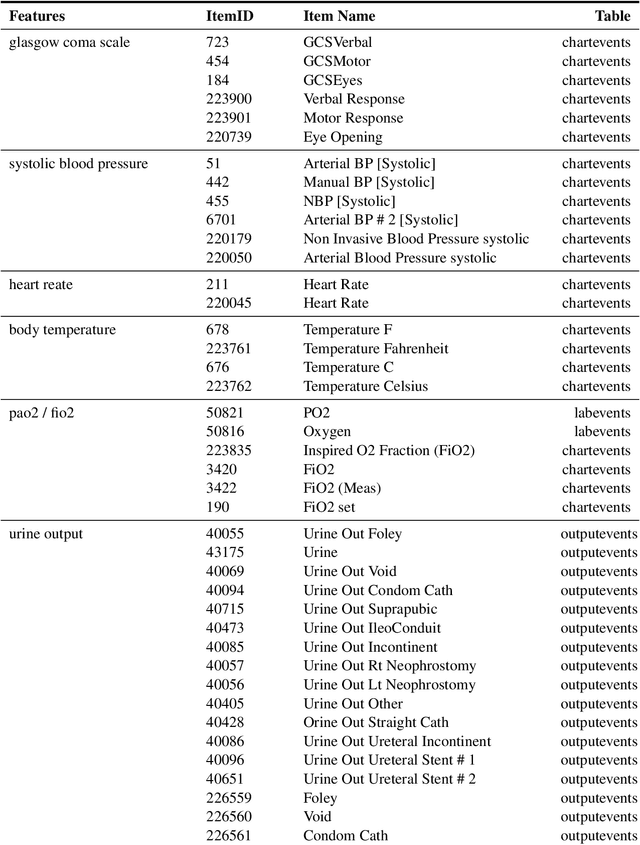
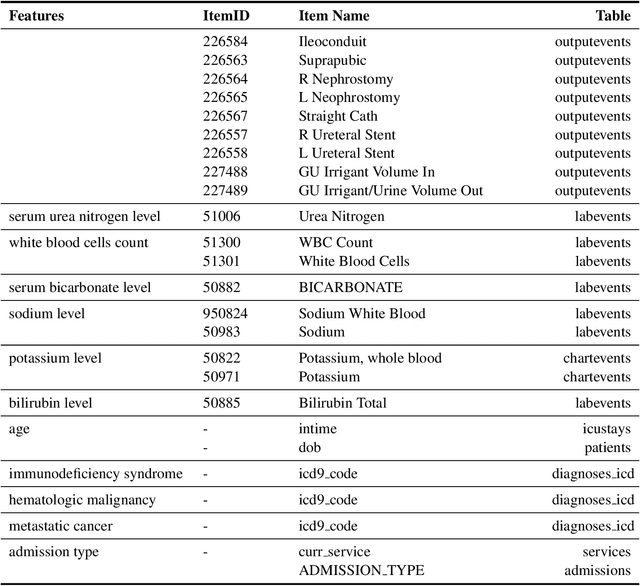
Mortality prediction in intensive care units is considered one of the critical steps for efficiently treating patients in serious condition. As a result, various prediction models have been developed to address this problem based on modern electronic healthcare records. However, it becomes increasingly challenging to model such tasks as time series variables because some laboratory test results such as heart rate and blood pressure are sampled with inconsistent time frequencies. In this paper, we propose several deep learning models using the same features as the SAPS II score. To derive insight into the proposed model performance. Several experiments have been conducted based on the well known clinical dataset Medical Information Mart for Intensive Care III. The prediction results demonstrate the proposed model's capability in terms of precision, recall, F1 score, and area under the receiver operating characteristic curve.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
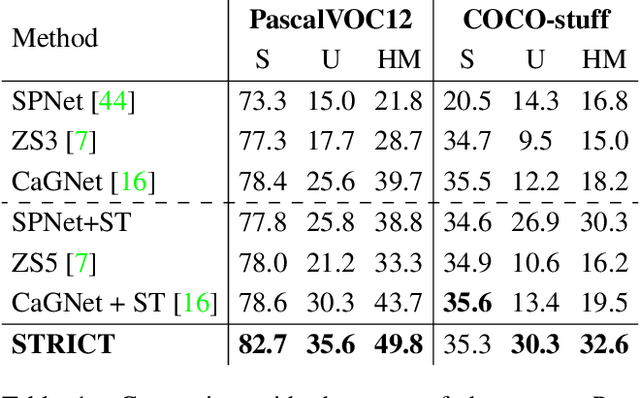
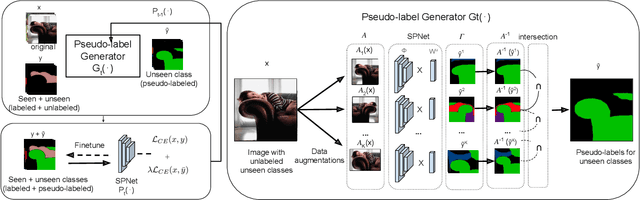
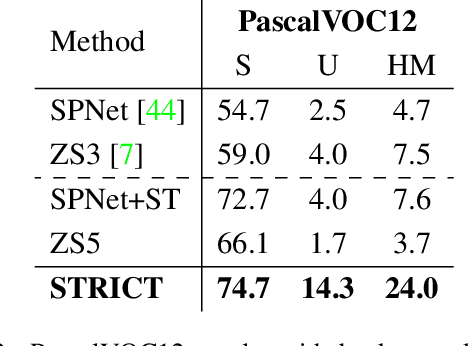
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.