 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks
Apr 08, 2021
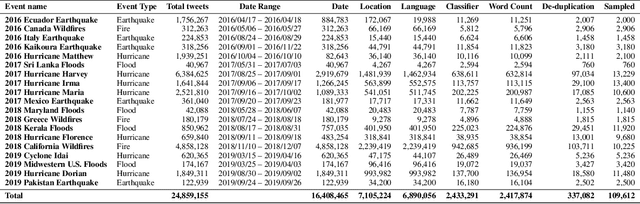
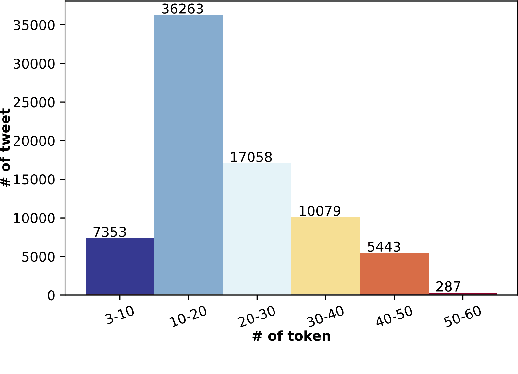
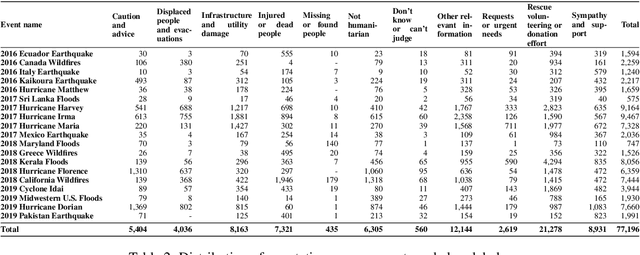
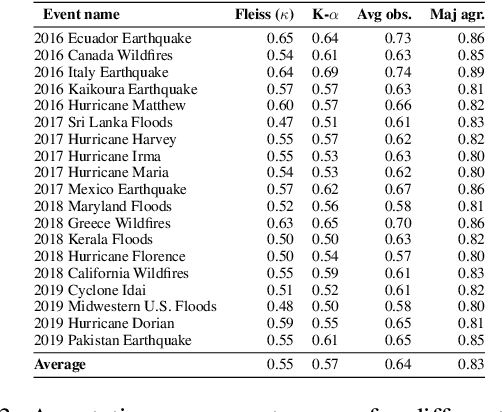
Social networks are widely used for information consumption and dissemination, especially during time-critical events such as natural disasters. Despite its significantly large volume, social media content is often too noisy for direct use in any application. Therefore, it is important to filter, categorize, and concisely summarize the available content to facilitate effective consumption and decision-making. To address such issues automatic classification systems have been developed using supervised modeling approaches, thanks to the earlier efforts on creating labeled datasets. However, existing datasets are limited in different aspects (e.g., size, contains duplicates) and less suitable to support more advanced and data-hungry deep learning models. In this paper, we present a new large-scale dataset with ~77K human-labeled tweets, sampled from a pool of ~24 million tweets across 19 disaster events that happened between 2016 and 2019. Moreover, we propose a data collection and sampling pipeline, which is important for social media data sampling for human annotation. We report multiclass classification results using classic and deep learning (fastText and transformer) based models to set the ground for future studies. The dataset and associated resources are publicly available. https://crisisnlp.qcri.org/humaid_dataset.html
Detecting residues of cosmic events using residual neural network
Jan 01, 2021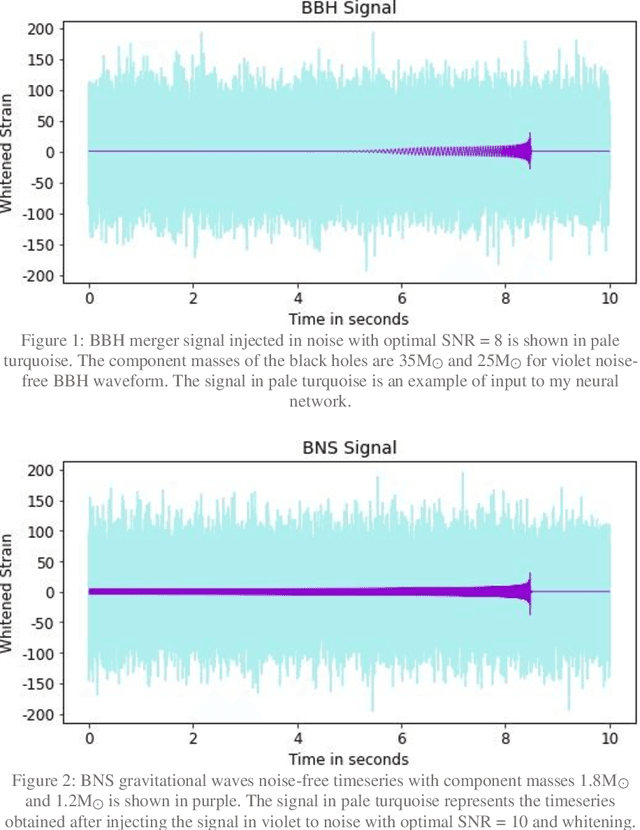
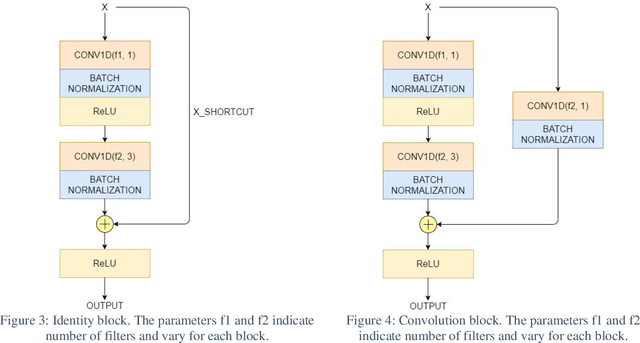

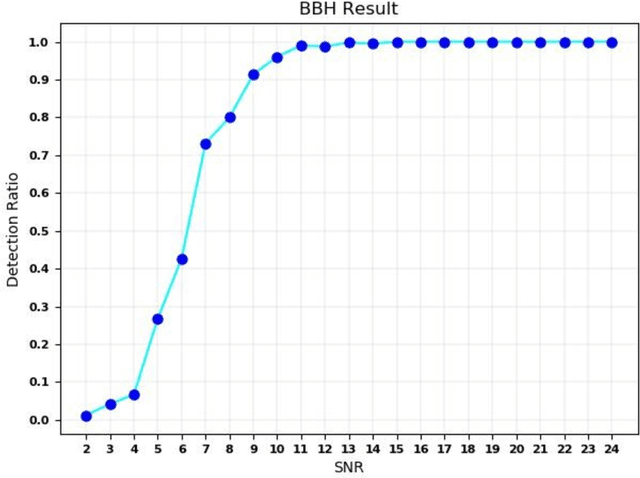
The detection of gravitational waves is considered to be one of the most magnificent discoveries of the century. Due to the high computational cost of matched filtering pipeline, there is a hunt for an alternative powerful system. I present, for the first time, the use of 1D residual neural network for detection of gravitational waves. Residual networks have transformed many fields like image classification, face recognition and object detection with their robust structure. With increase in sensitivity of LIGO detectors we expect many more sources of gravitational waves in the universe to be detected. However, deep learning networks are trained only once. When used for classification task, deep neural networks are trained to predict only a fixed number of classes. Therefore, when a new type of gravitational wave is to be detected, this turns out to be a drawback of deep learning. Shallow neural networks can be used to learn data with simple patterns but fail to give good results with increase in complexity of data. Remodelling the neural network with detection of each new type of GW is highly infeasible. In this letter, I also discuss ways to reduce the time required to adapt to such changes in detection of gravitational waves for deep learning methods. Primarily, I aim to create a custom residual neural network for 1-dimensional time series inputs, which can learn a ton of features from dataset without giving up on increasing the number of classes or increasing the complexity of data. I use the two class of binary coalescence signals (Binary Black Hole Merger and Binary Neutron Star Merger signals) detected by LIGO to check the performance of residual structure on gravitational waves detection.
Explaining Deep Neural Networks with a Polynomial Time Algorithm for Shapley Values Approximation
Apr 12, 2019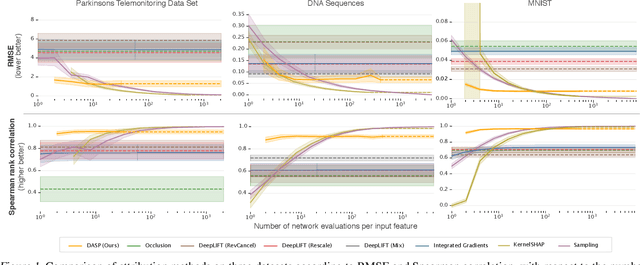
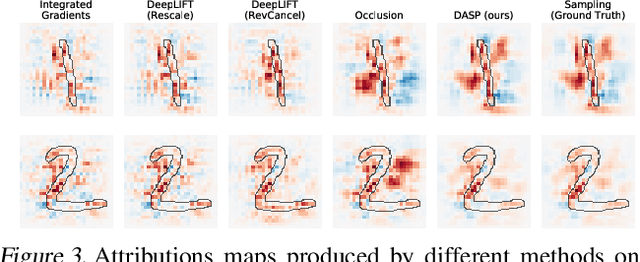
The problem of explaining the behavior of deep neural networks has gained a lot of attention over the last years. While several attribution methods have been proposed, most come without strong theoretical foundations. This raises the question of whether the resulting attributions are reliable. On the other hand, the literature on cooperative game theory suggests Shapley values as a unique way of assigning relevance scores such that certain desirable properties are satisfied. Previous works on attribution methods also showed that explanations based on Shapley values better agree with the human intuition. Unfortunately, the exact evaluation of Shapley values is prohibitively expensive, exponential in the number of input features. In this work, by leveraging recent results on uncertainty propagation, we propose a novel, polynomial-time approximation of Shapley values in deep neural networks. We show that our method produces significantly better approximations of Shapley values than existing state-of-the-art attribution methods.
H-Net: Unsupervised Attention-based Stereo Depth Estimation Leveraging Epipolar Geometry
Apr 22, 2021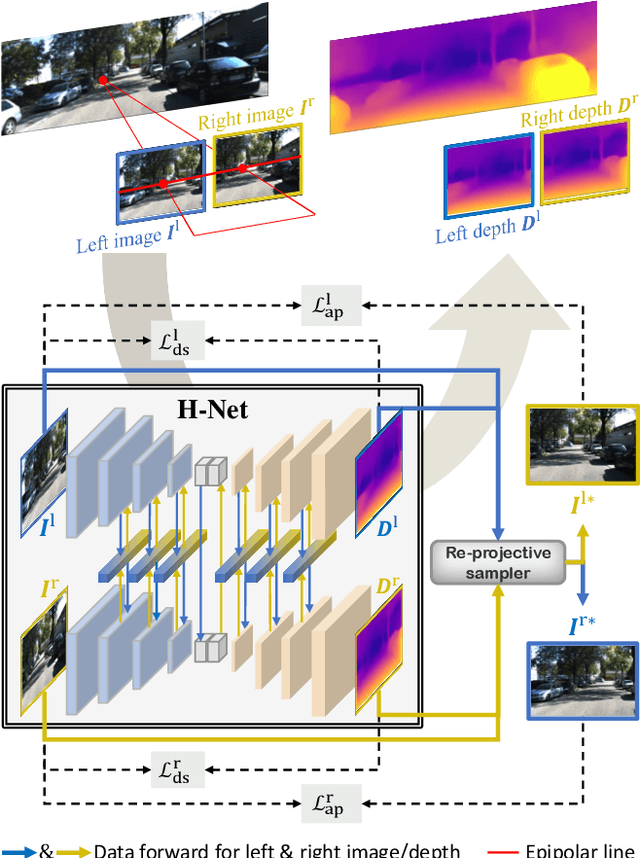
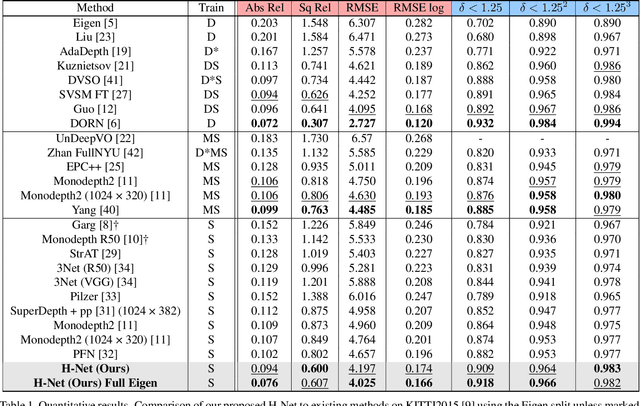
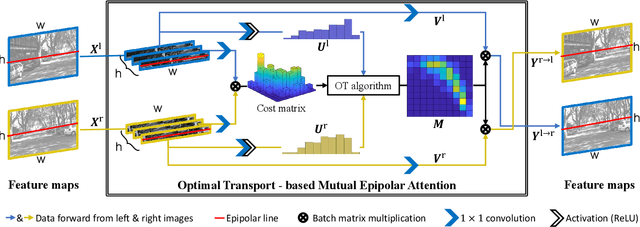
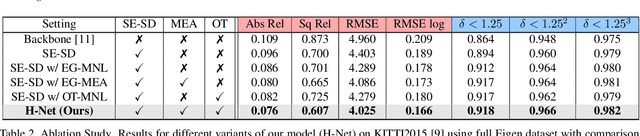
Depth estimation from a stereo image pair has become one of the most explored applications in computer vision, with most of the previous methods relying on fully supervised learning settings. However, due to the difficulty in acquiring accurate and scalable ground truth data, the training of fully supervised methods is challenging. As an alternative, self-supervised methods are becoming more popular to mitigate this challenge. In this paper, we introduce the H-Net, a deep-learning framework for unsupervised stereo depth estimation that leverages epipolar geometry to refine stereo matching. For the first time, a Siamese autoencoder architecture is used for depth estimation which allows mutual information between the rectified stereo images to be extracted. To enforce the epipolar constraint, the mutual epipolar attention mechanism has been designed which gives more emphasis to correspondences of features which lie on the same epipolar line while learning mutual information between the input stereo pair. Stereo correspondences are further enhanced by incorporating semantic information to the proposed attention mechanism. More specifically, the optimal transport algorithm is used to suppress attention and eliminate outliers in areas not visible in both cameras. Extensive experiments on KITTI2015 and Cityscapes show that our method outperforms the state-ofthe-art unsupervised stereo depth estimation methods while closing the gap with the fully supervised approaches.
Secure 3D medical Imaging
Oct 06, 2020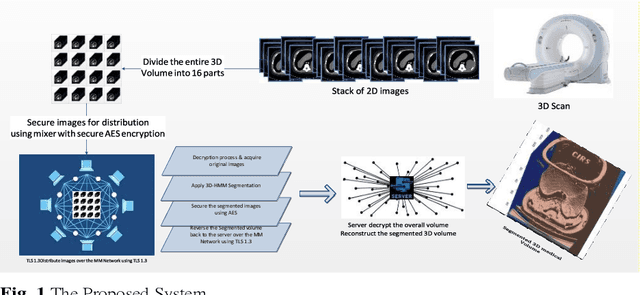
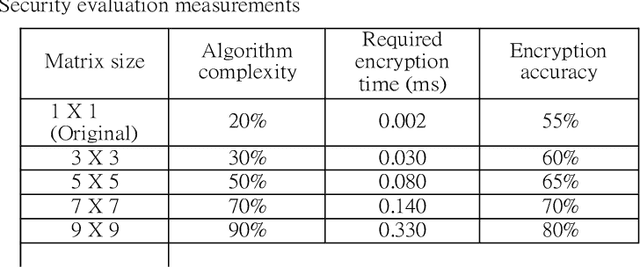

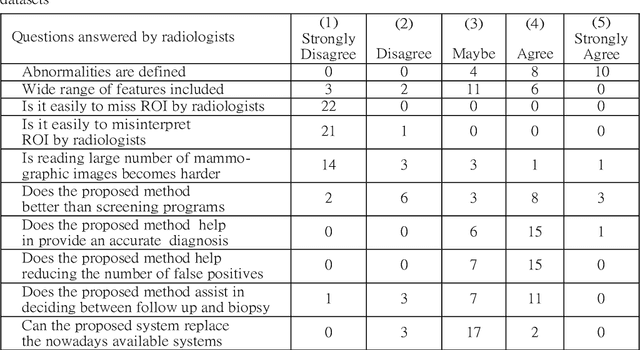
Image segmentation has proved its importance and plays an important role in various domains such as health systems and satellite-oriented military applications. In this context, accuracy, image quality, and execution time deem to be the major issues to always consider. Although many techniques have been applied, and their experimental results have shown appealing achievements for 2D images in real-time environments, however, there is a lack of works about 3D image segmentation despite its importance in improving segmentation accuracy. Specifically, HMM was used in this domain. However, it suffers from the time complexity, which was updated using different accelerators. As it is important to have efficient 3D image segmentation, we propose in this paper a novel system for partitioning the 3D segmentation process across several distributed machines. The concepts behind distributed multi-media network segmentation were employed to accelerate the segmentation computational time of training Hidden Markov Model (HMMs). Furthermore, a secure transmission has been considered in this distributed environment and various bidirectional multimedia security algorithms have been applied. The contribution of this work lies in providing an efficient and secure algorithm for 3D image segmentation. Through a number of extensive experiments, it was proved that our proposed system is of comparable efficiency to the state of art methods in terms of segmentation accuracy, security and execution time.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 03, 2021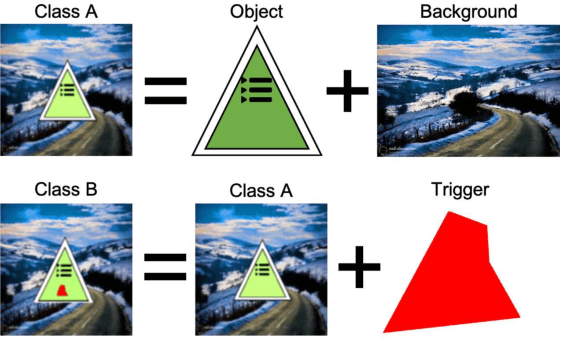

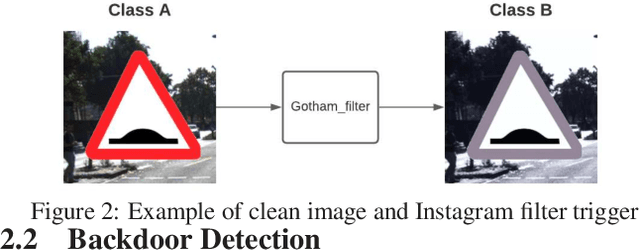
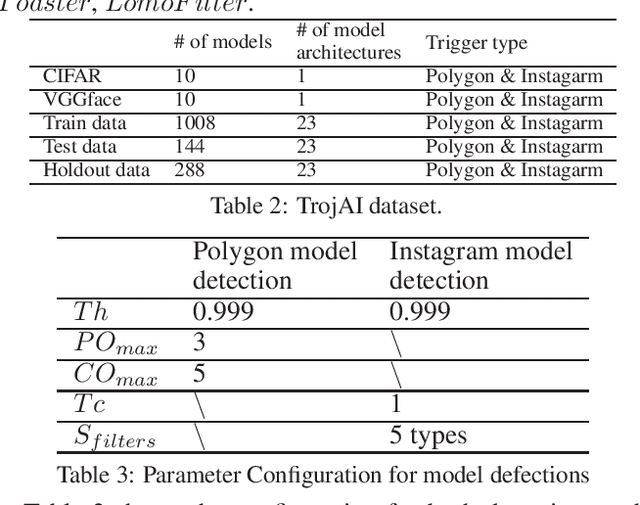
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.
Dory: Overcoming Barriers to Computing Persistent Homology
Mar 22, 2021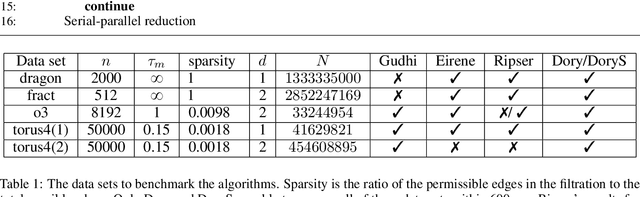
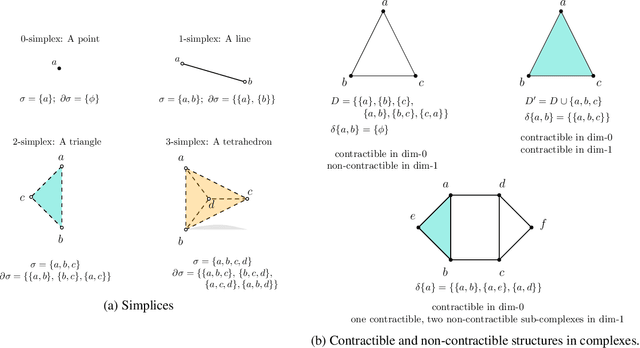
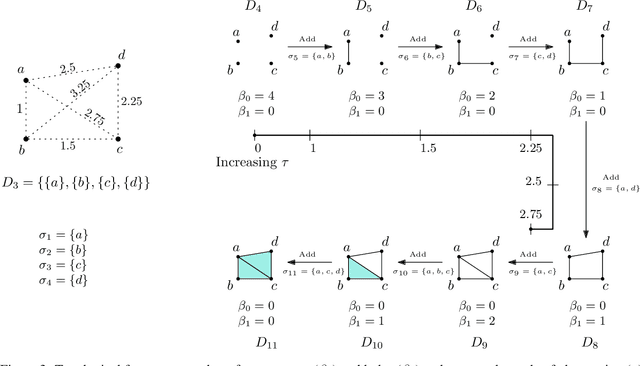
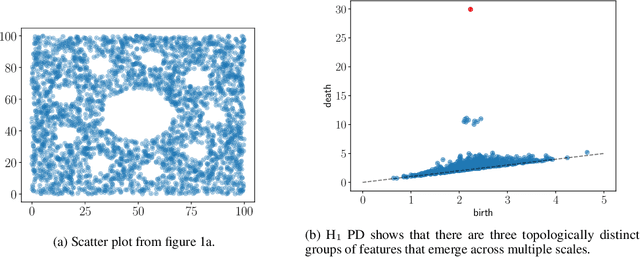
Persistent homology (PH) is an approach to topological data analysis (TDA) that computes multi-scale topologically invariant properties of high-dimensional data that are robust to noise. While PH has revealed useful patterns across various applications, computational requirements have limited applications to small data sets of a few thousand points. We present Dory, an efficient and scalable algorithm that can compute the persistent homology of large data sets. Dory uses significantly less memory than published algorithms and also provides significant reductions in the computation time compared to most algorithms. It scales to process data sets with millions of points. As an application, we compute the PH of the human genome at high resolution as revealed by a genome-wide Hi-C data set. Results show that the topology of the human genome changes significantly upon treatment with auxin, a molecule that degrades cohesin, corroborating the hypothesis that cohesin plays a crucial role in loop formation in DNA.
Split Modeling for High-Dimensional Logistic Regression
Mar 12, 2021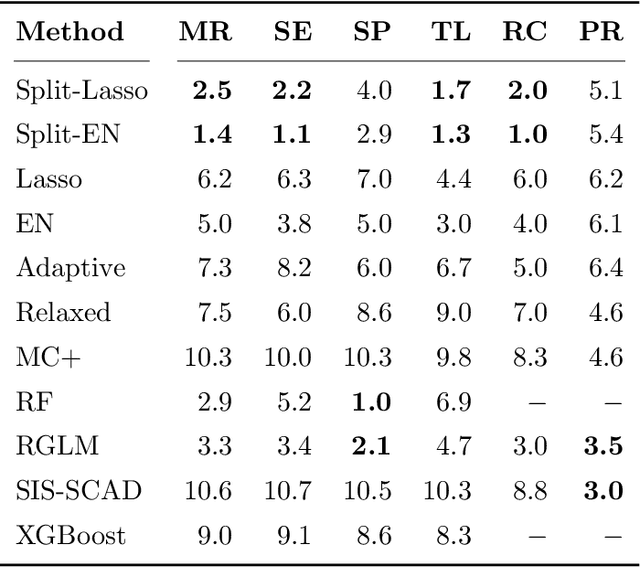
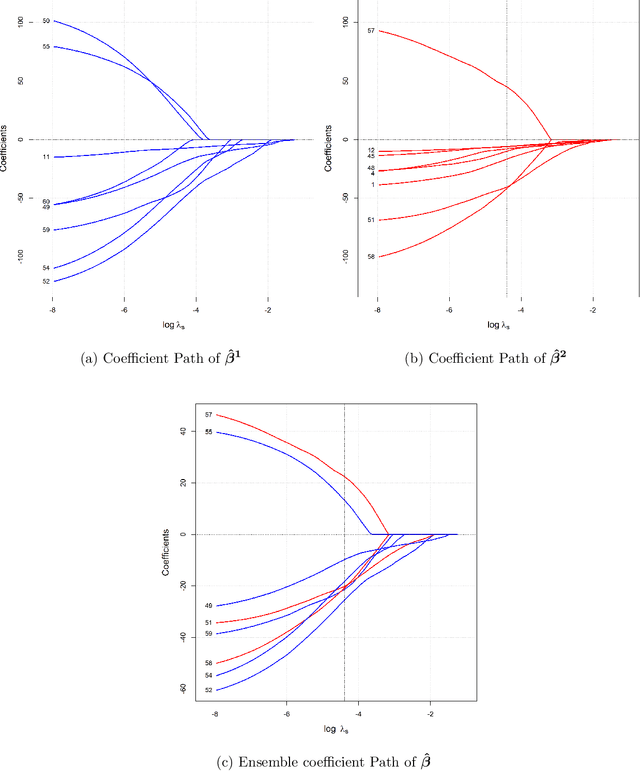
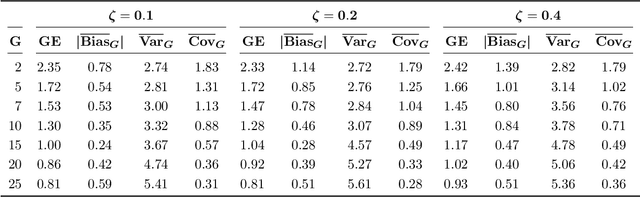
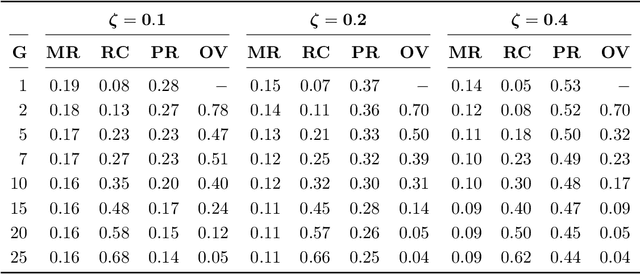
A novel method is proposed to learn an ensemble of logistic classification models in the context of high-dimensional binary classification. The models in the ensemble are built simultaneously by optimizing a multi-convex objective function. To enforce diversity between the models the objective function penalizes overlap between the models in the ensemble. We study the bias and variance of the individual models as well as their correlation and discuss how our method learns the ensemble by exploiting the accuracy-diversity trade-off for ensemble models. In contrast to other ensembling approaches, the resulting ensemble model is fully interpretable as a logistic regression model and at the same time yields excellent prediction accuracy as demonstrated in an extensive simulation study and gene expression data applications. An open-source compiled software library implementing the proposed method is briefly discussed.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021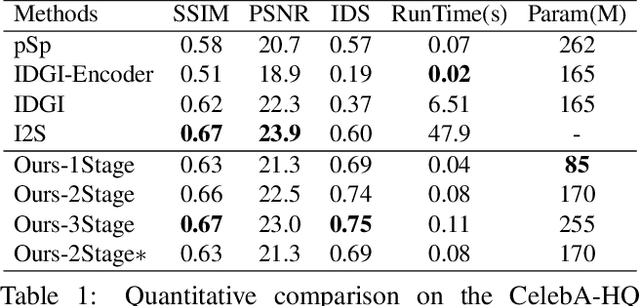
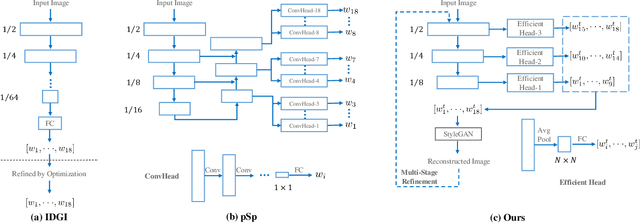
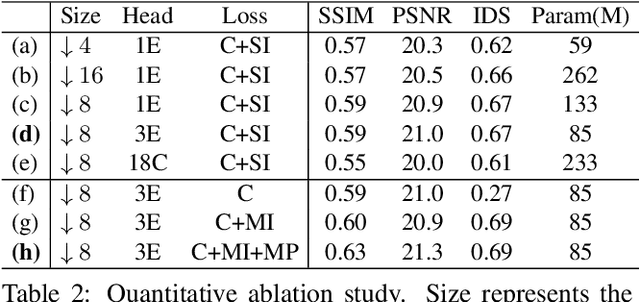

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.
Eigenvalue Decay Implies Polynomial-Time Learnability for Neural Networks
Aug 11, 2017We consider the problem of learning function classes computed by neural networks with various activations (e.g. ReLU or Sigmoid), a task believed to be computationally intractable in the worst-case. A major open problem is to understand the minimal assumptions under which these classes admit provably efficient algorithms. In this work we show that a natural distributional assumption corresponding to {\em eigenvalue decay} of the Gram matrix yields polynomial-time algorithms in the non-realizable setting for expressive classes of networks (e.g. feed-forward networks of ReLUs). We make no assumptions on the structure of the network or the labels. Given sufficiently-strong polynomial eigenvalue decay, we obtain {\em fully}-polynomial time algorithms in {\em all} the relevant parameters with respect to square-loss. Milder decay assumptions also lead to improved algorithms. This is the first purely distributional assumption that leads to polynomial-time algorithms for networks of ReLUs, even with one hidden layer. Further, unlike prior distributional assumptions (e.g., the marginal distribution is Gaussian), eigenvalue decay has been observed in practice on common data sets.