 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MBAPose: Mask and Bounding-Box Aware Pose Estimation of Surgical Instruments with Photorealistic Domain Randomization
Mar 15, 2021
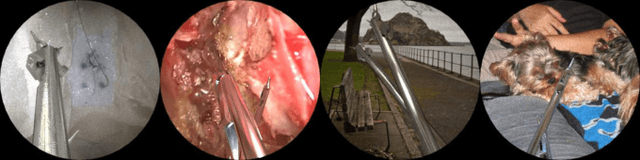
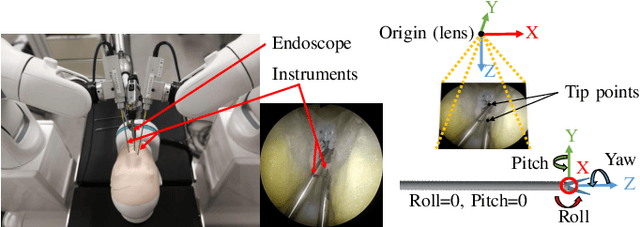
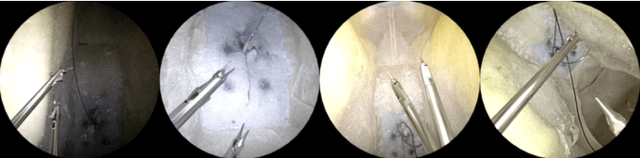
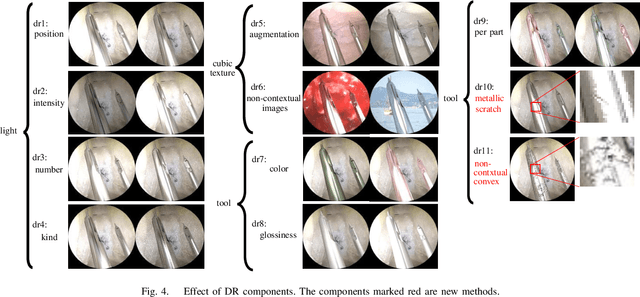
Surgical robots are controlled using a priori models based on robots' geometric parameters, which are calibrated before the surgical procedure. One of the challenges in using robots in real surgical settings is that parameters change over time, consequently deteriorating control accuracy. In this context, our group has been investigating online calibration strategies without added sensors. In one step toward that goal, we have developed an algorithm to estimate the pose of the instruments' shafts in endoscopic images. In this study, we build upon that earlier work and propose a new framework to more precisely estimate the pose of a rigid surgical instrument. Our strategy is based on a novel pose estimation model called MBAPose and the use of synthetic training data. Our experiments demonstrated an improvement of 21 % for translation error and 26 % for orientation error on synthetic test data with respect to our previous work. Results with real test data provide a baseline for further research.
Multi-scale Deep Learning Architecture for Nucleus Detection in Renal Cell Carcinoma Microscopy Image
Apr 28, 2021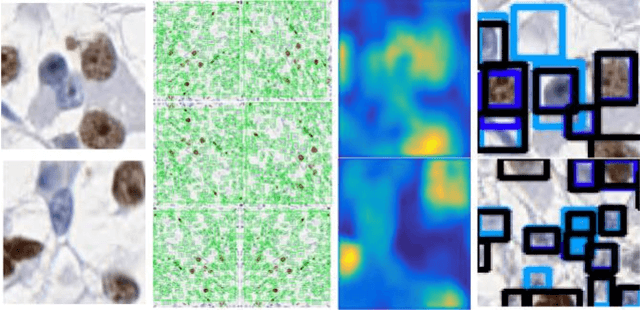
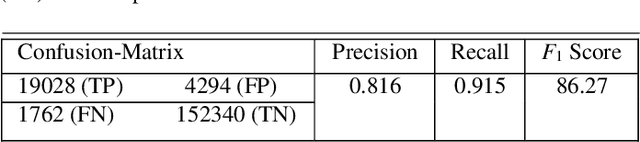
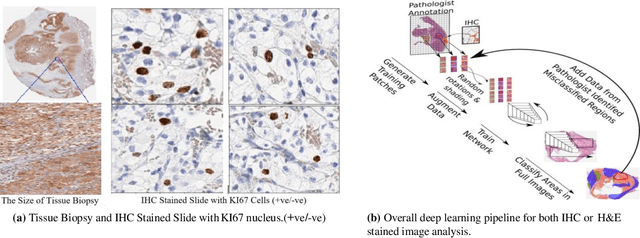
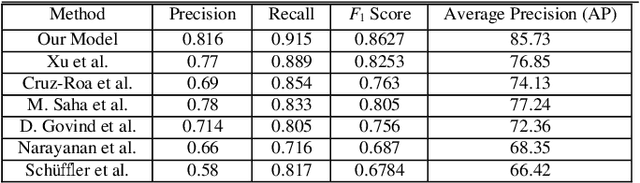
Clear cell renal cell carcinoma (ccRCC) is one of the most common forms of intratumoral heterogeneity in the study of renal cancer. ccRCC originates from the epithelial lining of proximal convoluted renal tubules. These cells undergo abnormal mutations in the presence of Ki67 protein and create a lump-like structure through cell proliferation. Manual counting of tumor cells in the tissue-affected sections is one of the strongest prognostic markers for renal cancer. However, this procedure is time-consuming and also prone to subjectivity. These assessments are based on the physical cell appearance and suffer wide intra-observer variations. Therefore, better cell nucleus detection and counting techniques can be an important biomarker for the assessment of tumor cell proliferation in routine pathological investigations. In this paper, we introduce a deep learning-based detection model for cell classification on IHC stained histology images. These images are classified into binary classes to find the presence of Ki67 protein in cancer-affected nucleus regions. Our model maps the multi-scale pyramid features and saliency information from local bounded regions and predicts the bounding box coordinates through regression. Our method validates the impact of Ki67 expression across a cohort of four hundred histology images treated with localized ccRCC and compares our results with the existing state-of-the-art nucleus detection methods. The precision and recall scores of the proposed method are computed and compared on the clinical data sets. The experimental results demonstrate that our model improves the F1 score up to 86.3% and an average area under the Precision-Recall curve as 85.73%.
Resolution Limits of 20 Questions Search Strategies for Moving Targets
Mar 15, 2021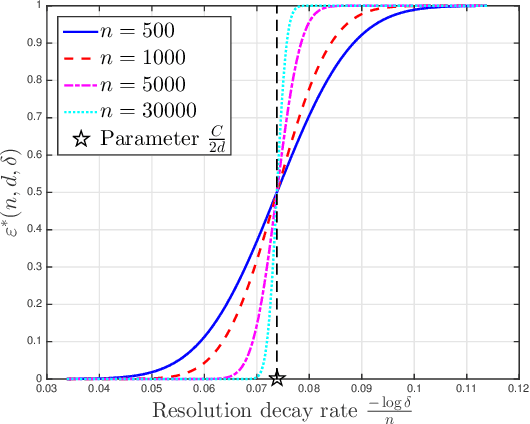
We establish fundamental limits of tracking a moving target over the unit cube under the framework of 20 questions with measurement-dependent noise. In this problem, there is an oracle who knows the instantaneous location of a target. Our task is to query the oracle as few times as possible to accurately estimate the trajectory of the moving target, whose initial location and velocity is \emph{unknown}. We study the case where the oracle's answer to each query is corrupted by random noise with query-dependent discrete distribution. In our formulation, the performance criterion is the resolution, which is defined as the maximal absolute value between the true location and estimated location at each discrete time during the searching process. We are interested in the minimal resolution of any non-adaptive searching procedure with a finite number of queries and derive approximations to this optimal resolution via the second-order asymptotic analysis.
Modulated Periodic Activations for Generalizable Local Functional Representations
Apr 08, 2021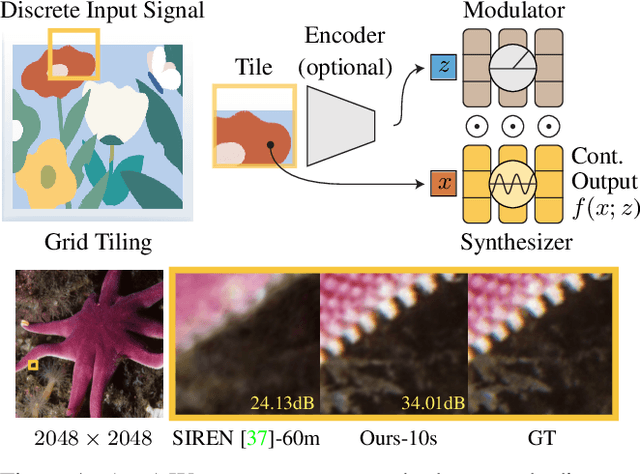
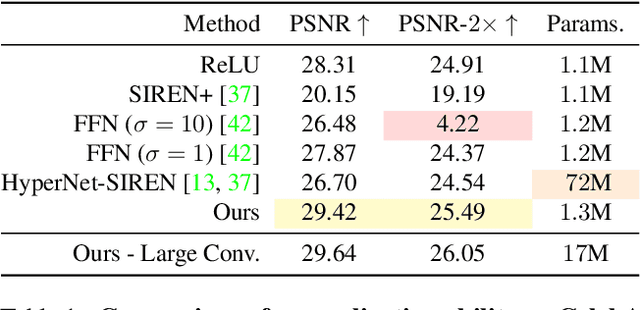
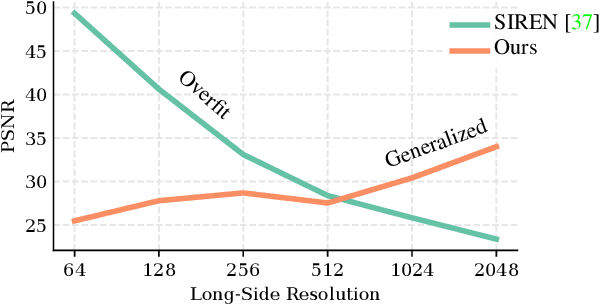
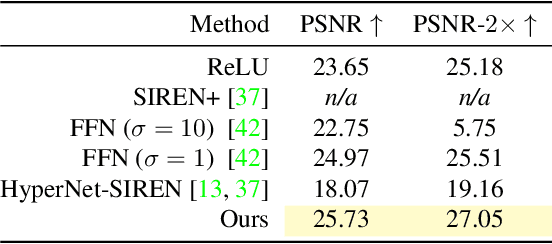
Multi-Layer Perceptrons (MLPs) make powerful functional representations for sampling and reconstruction problems involving low-dimensional signals like images,shapes and light fields. Recent works have significantly improved their ability to represent high-frequency content by using periodic activations or positional encodings. This often came at the expense of generalization: modern methods are typically optimized for a single signal. We present a new representation that generalizes to multiple instances and achieves state-of-the-art fidelity. We use a dual-MLP architecture to encode the signals. A synthesis network creates a functional mapping from a low-dimensional input (e.g. pixel-position) to the output domain (e.g. RGB color). A modulation network maps a latent code corresponding to the target signal to parameters that modulate the periodic activations of the synthesis network. We also propose a local-functional representation which enables generalization. The signal's domain is partitioned into a regular grid,with each tile represented by a latent code. At test time, the signal is encoded with high-fidelity by inferring (or directly optimizing) the latent code-book. Our approach produces generalizable functional representations of images, videos and shapes, and achieves higher reconstruction quality than prior works that are optimized for a single signal.
Deep Directed Information-Based Learning for Privacy-Preserving Smart Meter Data Release
Nov 20, 2020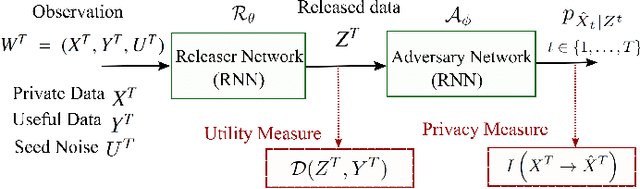
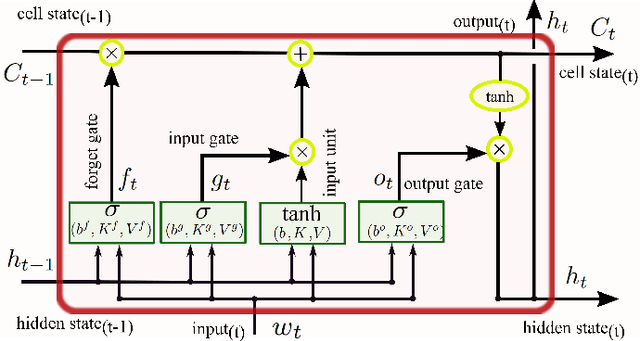
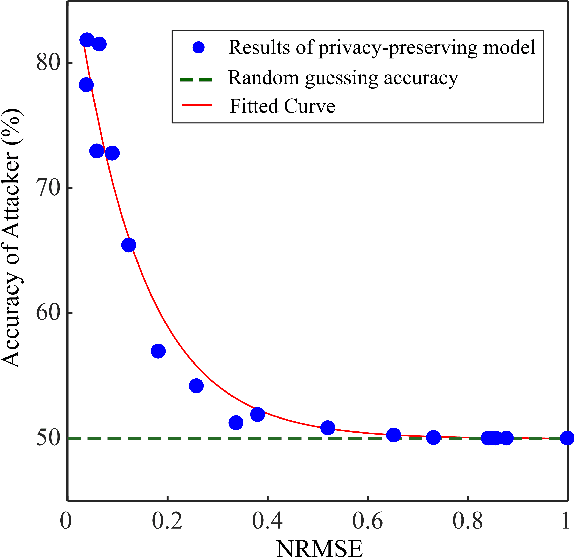
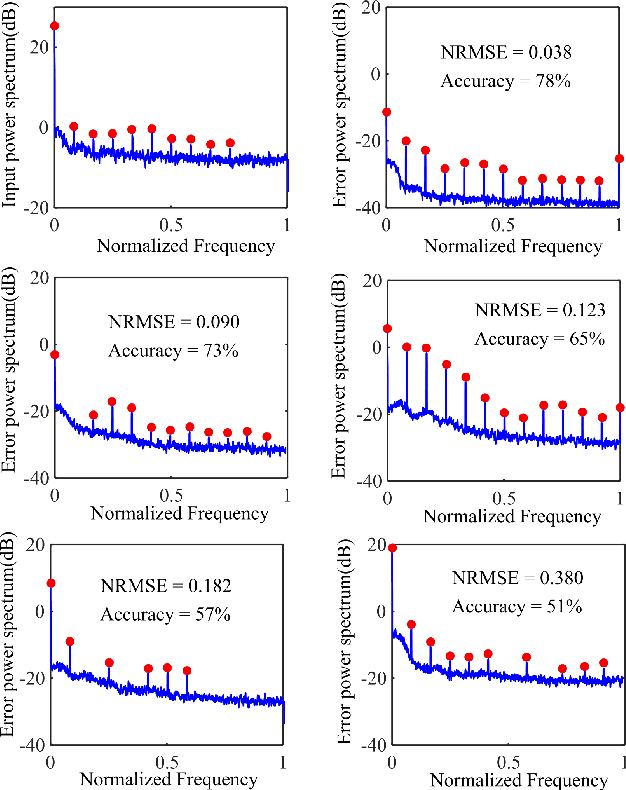
The explosion of data collection has raised serious privacy concerns in users due to the possibility that sharing data may also reveal sensitive information. The main goal of a privacy-preserving mechanism is to prevent a malicious third party from inferring sensitive information while keeping the shared data useful. In this paper, we study this problem in the context of time series data and smart meters (SMs) power consumption measurements in particular. Although Mutual Information (MI) between private and released variables has been used as a common information-theoretic privacy measure, it fails to capture the causal time dependencies present in the power consumption time series data. To overcome this limitation, we introduce the Directed Information (DI) as a more meaningful measure of privacy in the considered setting and propose a novel loss function. The optimization is then performed using an adversarial framework where two Recurrent Neural Networks (RNNs), referred to as the releaser and the adversary, are trained with opposite goals. Our empirical studies on real-world data sets from SMs measurements in the worst-case scenario where an attacker has access to all the training data set used by the releaser, validate the proposed method and show the existing trade-offs between privacy and utility.
COVID-19 and Big Data: Multi-faceted Analysis for Spatio-temporal Understanding of the Pandemic with Social Media Conversations
Apr 22, 2021COVID-19 has been devastating the world since the end of 2019 and has continued to play a significant role in major national and worldwide events, and consequently, the news. In its wake, it has left no life unaffected. Having earned the world's attention, social media platforms have served as a vehicle for the global conversation about COVID-19. In particular, many people have used these sites in order to express their feelings, experiences, and observations about the pandemic. We provide a multi-faceted analysis of critical properties exhibited by these conversations on social media regarding the novel coronavirus pandemic. We present a framework for analysis, mining, and tracking the critical content and characteristics of social media conversations around the pandemic. Focusing on Twitter and Reddit, we have gathered a large-scale dataset on COVID-19 social media conversations. Our analyses cover tracking potential reports on virus acquisition, symptoms, conversation topics, and language complexity measures through time and by region across the United States. We also present a BERT-based model for recognizing instances of hateful tweets in COVID-19 conversations, which achieves a lower error-rate than the state-of-the-art performance. Our results provide empirical validation for the effectiveness of our proposed framework and further demonstrate that social media data can be efficiently leveraged to provide public health experts with inexpensive but thorough insight over the course of an outbreak.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 21, 2021
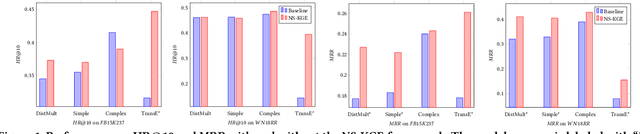
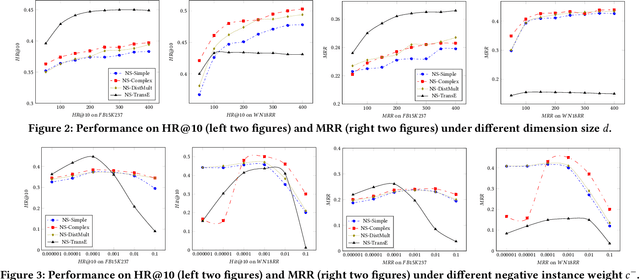
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
Segmentation of common and internal carotid arteries from 3D ultrasound images using adaptive triple U-Net
Feb 09, 2021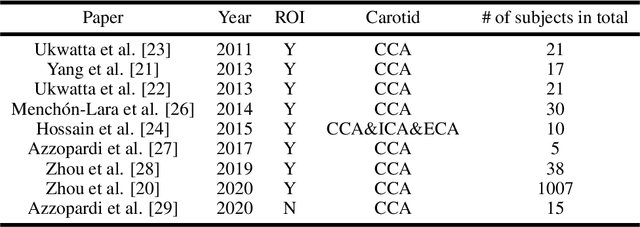
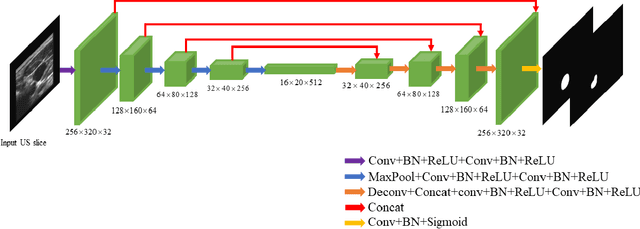
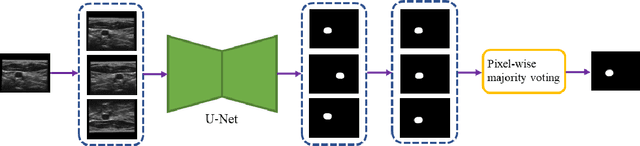
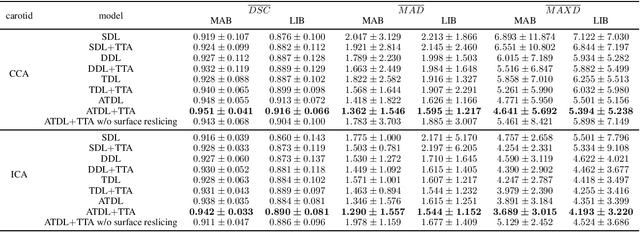
Objective: Vessel-wall-volume (VWV) and localized vessel-wall-thickness (VWT) measured from 3D ultrasound (US) carotid images are sensitive to anti-atherosclerotic effects of medical/dietary treatments. VWV and VWT measurements require the lumen-intima (LIB) and media-adventitia boundaries (MAB) at the common and internal carotid arteries (CCA and ICA). However, most existing segmentation techniques were capable of automating only CCA segmentation. An approach capable of segmenting the MAB and LIB from the CCA and ICA was required to accelerate VWV and VWT quantification. Methods: Segmentation for CCA and ICA were performed independently using the proposed two-channel U-Net, which was driven by a novel loss function known as the adaptive triple Dice loss (ADTL). A test-time augmentation (TTA) approach is used, in which segmentation was performed three times based on axial images and its flipped versions; the final segmentation was generated by pixel-wise majority voting. Results: Experiments involving 224 3DUS volumes produce a Dice-similarity-coefficient (DSC) of 95.1%$\pm$4.1% and 91.6%$\pm$6.6% for the MAB and LIB, in the CCA, respectively, and 94.2%$\pm$3.3% and 89.0%$\pm$8.1% for the MAB and LIB, in the ICA, respectively. TTA and ATDL independently contributed to a statistically significant improvement to all boundaries except the LIB in ICA. The total time required to segment the entire 3DUS volume (CCA+ICA) is 1.4s. Conclusion: The proposed two-channel U-Net with ADTL and TTA can segment the CCA and ICA accurately and efficiently from the 3DUS volume. Significance: Our approach has the potential to accelerate the transition of 3DUS measurements of carotid atherosclerosis to clinical research.
Robust Self-Ensembling Network for Hyperspectral Image Classification
Apr 08, 2021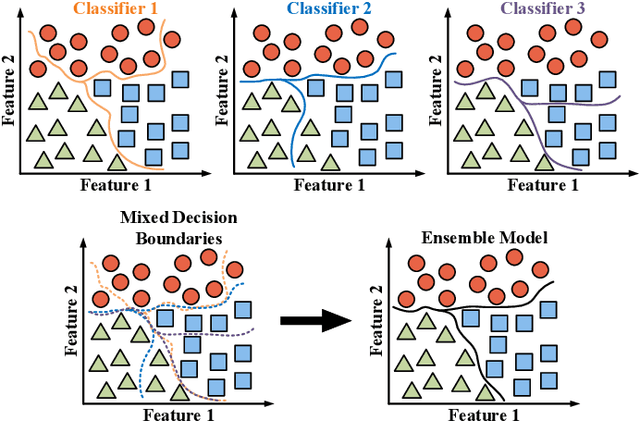
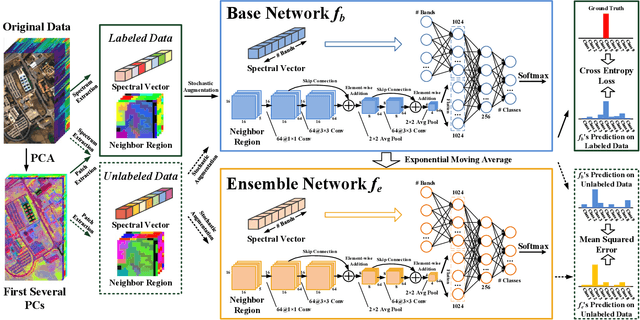
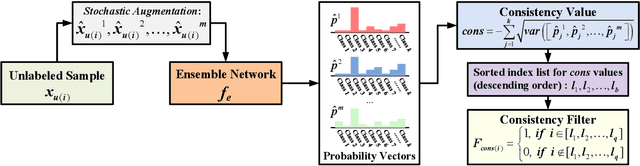
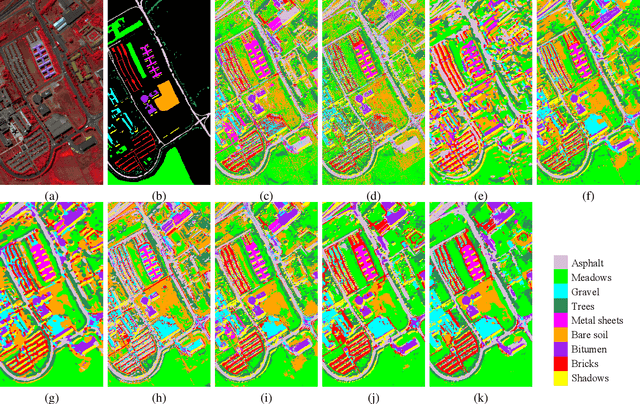
Recent research has shown the great potential of deep learning algorithms in the hyperspectral image (HSI) classification task. Nevertheless, training these models usually requires a large amount of labeled data. Since the collection of pixel-level annotations for HSI is laborious and time-consuming, developing algorithms that can yield good performance in the small sample size situation is of great significance. In this study, we propose a robust self-ensembling network (RSEN) to address this problem. The proposed RSEN consists of two subnetworks including a base network and an ensemble network. With the constraint of both the supervised loss from the labeled data and the unsupervised loss from the unlabeled data, the base network and the ensemble network can learn from each other, achieving the self-ensembling mechanism. To the best of our knowledge, the proposed method is the first attempt to introduce the self-ensembling technique into the HSI classification task, which provides a different view on how to utilize the unlabeled data in HSI to assist the network training. We further propose a novel consistency filter to increase the robustness of self-ensembling learning. Extensive experiments on three benchmark HSI datasets demonstrate that the proposed algorithm can yield competitive performance compared with the state-of-the-art methods.
Approximation Methods for Kernelized Bandits
Oct 26, 2020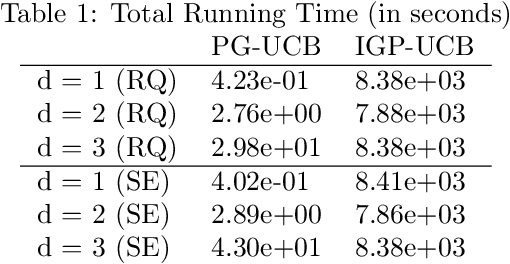
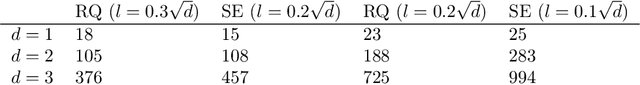
The RKHS bandit problem (also called kernelized multi-armed bandit problem) is an online optimization problem of non-linear functions with noisy feedbacks. Most of the existing methods for the problem have sub-linear regret guarantee at the cost of high computational complexity. For example, IGP-UCB requires at least quadratic time in the number of observed samples at each round. In this paper, using deep results provided by the approximation theory, we approximately reduce the problem to the well-studied linear bandit problem of an appropriate dimension. Then, we propose several algorithms and prove that they achieve comparable regret guarantee to the existing methods (GP-UCB, IGP-UCB) with less computational complexity. Specifically, our proposed methods require polylogarithmic time to select an arm at each round for kernels with "infinite smoothness" (e.g. the rational quadratic and squared exponential kernels). Furthermore, we empirically show our proposed method has comparable regret to the existing method and its running time is much shorter.