 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recent Advances in Domain Adaptation for the Classification of Remote Sensing Data
Apr 15, 2021
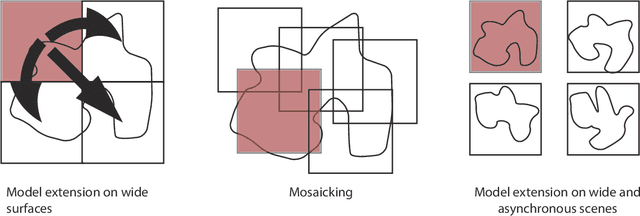
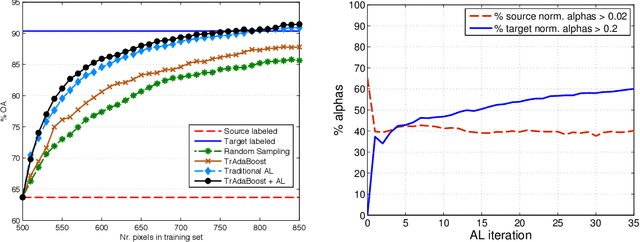
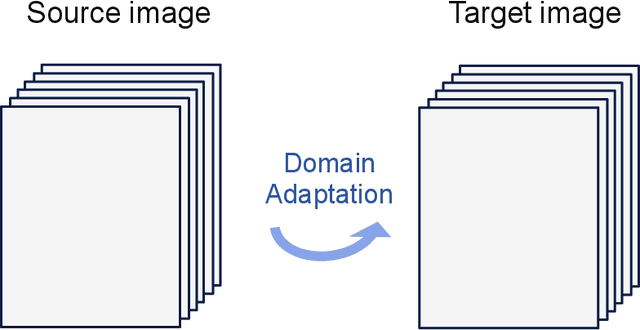
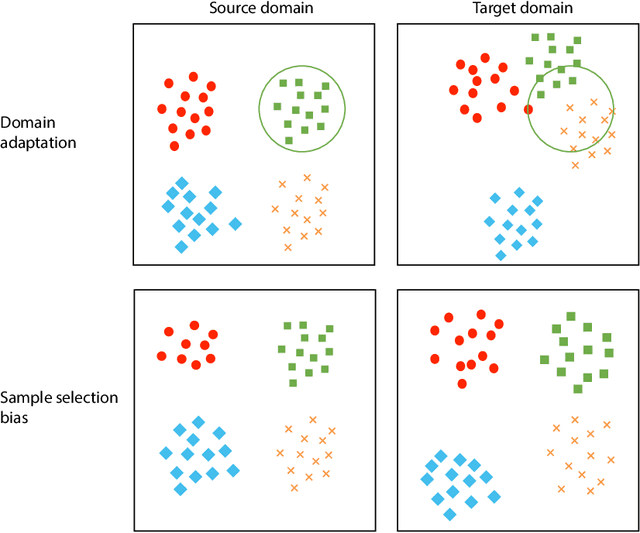
The success of supervised classification of remotely sensed images acquired over large geographical areas or at short time intervals strongly depends on the representativity of the samples used to train the classification algorithm and to define the model. When training samples are collected from an image (or a spatial region) different from the one used for mapping, spectral shifts between the two distributions are likely to make the model fail. Such shifts are generally due to differences in acquisition and atmospheric conditions or to changes in the nature of the object observed. In order to design classification methods that are robust to data-set shifts, recent remote sensing literature has considered solutions based on domain adaptation (DA) approaches. Inspired by machine learning literature, several DA methods have been proposed to solve specific problems in remote sensing data classification. This paper provides a critical review of the recent advances in DA for remote sensing and presents an overview of methods divided into four categories: i) invariant feature selection; ii) representation matching; iii) adaptation of classifiers and iv) selective sampling. We provide an overview of recent methodologies, as well as examples of application of the considered techniques to real remote sensing images characterized by very high spatial and spectral resolution. Finally, we propose guidelines to the selection of the method to use in real application scenarios.
Sub-seasonal forecasting with a large ensemble of deep-learning weather prediction models
Feb 09, 2021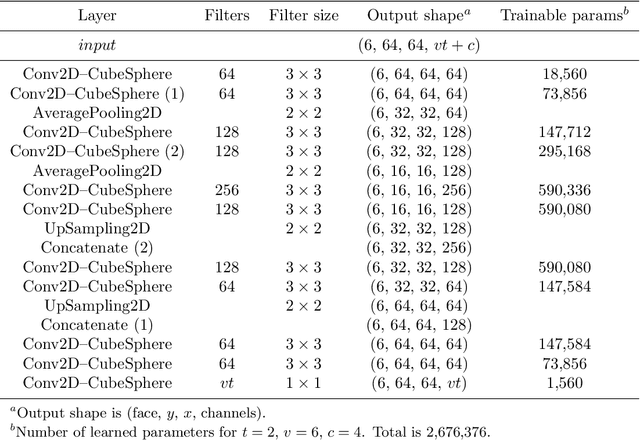
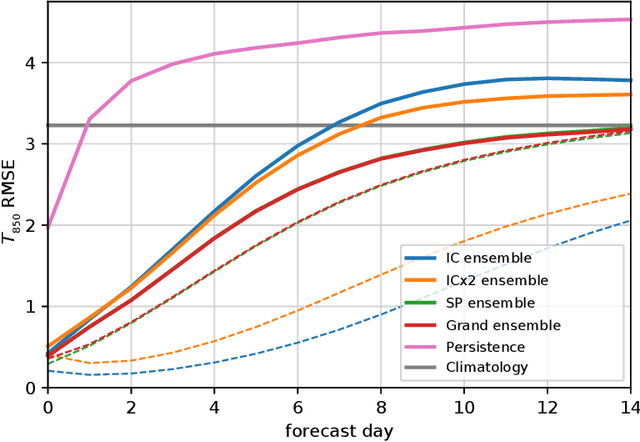
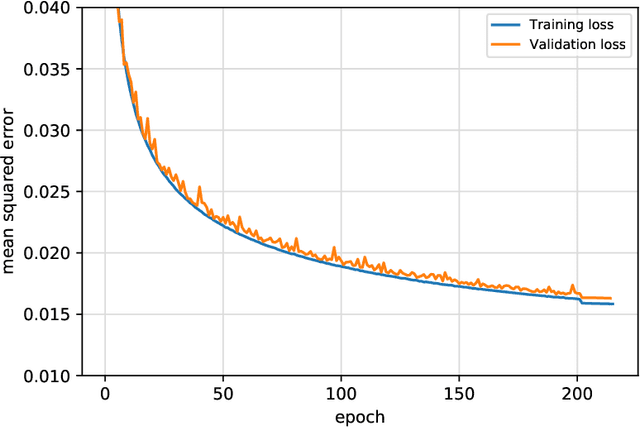
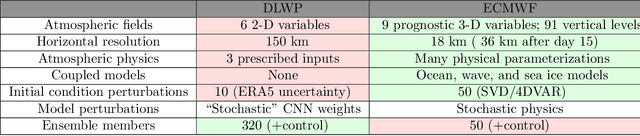
We present an ensemble prediction system using a Deep Learning Weather Prediction (DLWP) model that recursively predicts key atmospheric variables with six-hour time resolution. This model uses convolutional neural networks (CNNs) on a cubed sphere grid to produce global forecasts. The approach is computationally efficient, requiring just three minutes on a single GPU to produce a 320-member set of six-week forecasts at 1.4{\deg} resolution. Ensemble spread is primarily produced by randomizing the CNN training process to create a set of 32 DLWP models with slightly different learned weights. Although our DLWP model does not forecast precipitation, it does forecast total column water vapor, and it gives a reasonable 4.5-day deterministic forecast of Hurricane Irma. In addition to simulating mid-latitude weather systems, it spontaneously generates tropical cyclones in a one-year free-running simulation. Averaged globally and over a two-year test set, the ensemble mean RMSE retains skill relative to climatology beyond two-weeks, with anomaly correlation coefficients remaining above 0.6 through six days. Our primary application is to subseasonal-to-seasonal (S2S) forecasting at lead times from two to six weeks. Current forecast systems have low skill in predicting one- or 2-week-average weather patterns at S2S time scales. The continuous ranked probability score (CRPS) and the ranked probability skill score (RPSS) show that the DLWP ensemble is only modestly inferior in performance to the European Centre for Medium Range Weather Forecasts (ECMWF) S2S ensemble over land at lead times of 4 and 5-6 weeks. At shorter lead times, the ECMWF ensemble performs better than DLWP.
Multi-scale Deep Learning Architecture for Nucleus Detection in Renal Cell Carcinoma Microscopy Image
Apr 28, 2021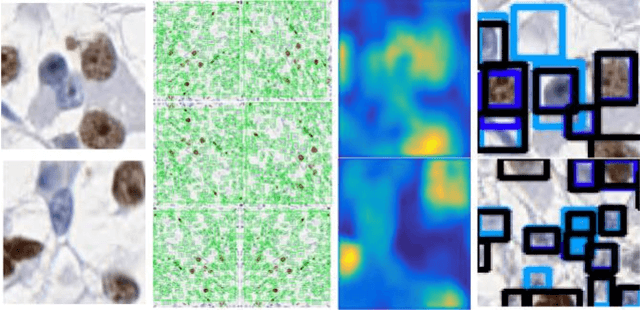
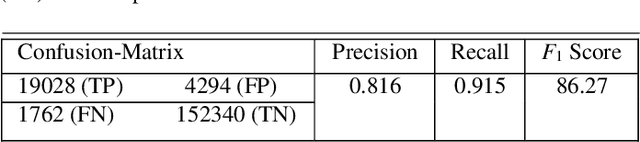
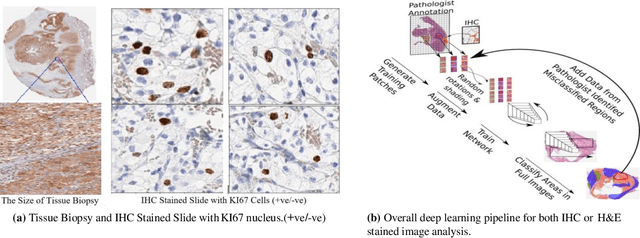
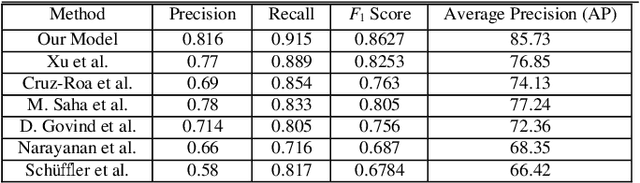
Clear cell renal cell carcinoma (ccRCC) is one of the most common forms of intratumoral heterogeneity in the study of renal cancer. ccRCC originates from the epithelial lining of proximal convoluted renal tubules. These cells undergo abnormal mutations in the presence of Ki67 protein and create a lump-like structure through cell proliferation. Manual counting of tumor cells in the tissue-affected sections is one of the strongest prognostic markers for renal cancer. However, this procedure is time-consuming and also prone to subjectivity. These assessments are based on the physical cell appearance and suffer wide intra-observer variations. Therefore, better cell nucleus detection and counting techniques can be an important biomarker for the assessment of tumor cell proliferation in routine pathological investigations. In this paper, we introduce a deep learning-based detection model for cell classification on IHC stained histology images. These images are classified into binary classes to find the presence of Ki67 protein in cancer-affected nucleus regions. Our model maps the multi-scale pyramid features and saliency information from local bounded regions and predicts the bounding box coordinates through regression. Our method validates the impact of Ki67 expression across a cohort of four hundred histology images treated with localized ccRCC and compares our results with the existing state-of-the-art nucleus detection methods. The precision and recall scores of the proposed method are computed and compared on the clinical data sets. The experimental results demonstrate that our model improves the F1 score up to 86.3% and an average area under the Precision-Recall curve as 85.73%.
Flying Robots for Safe and Efficient Parcel Delivery Within the COVID-19 Pandemic
Jan 19, 2021
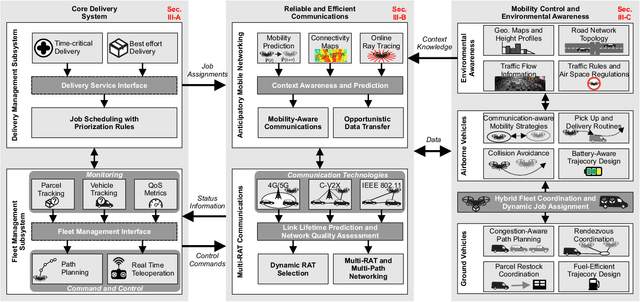
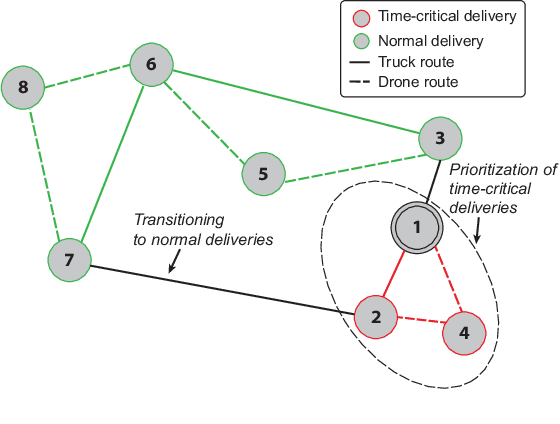
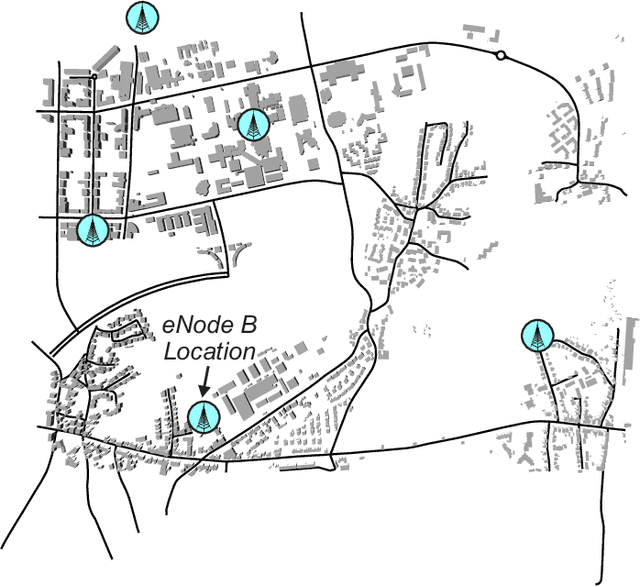
The integration of small-scale Unmanned Aerial Vehicles (UAVs) into Intelligent Transportation Systems (ITSs) will empower novel smart-city applications and services. After the unforeseen outbreak of the COVID-19 pandemic, the public demand for delivery services has multiplied. Mobile robotic systems inherently offer the potential for minimizing the amount of direct human-to-human interactions with the parcel delivery process. The proposed system-of-systems consists of various complex aspects such as assigning and distributing delivery jobs, establishing and maintaining reliable communication links between the vehicles, as well as path planning and mobility control. In this paper, we apply a system-level perspective for identifying key challenges and promising solution approaches for modeling, analysis, and optimization of UAV-aided parcel delivery. We present a system-of-systems model for UAV-assisted parcel delivery to cope with higher capacity requirements induced by the COVID-19. To demonstrate the benefits of hybrid vehicular delivery, we present a case study focusing on the prioritization of time-critical deliveries such as medical goods. The results further confirm that the capacity of traditional delivery fleets can be upgraded with drone usage. Furthermore, we observe that the delay incurred by prioritizing time-critical deliveries can be compensated with drone deployment. Finally, centralized and decentralized communication approaches for data transmission inside hybrid delivery fleets are compared.
Learning from Noisy Labels via Dynamic Loss Thresholding
Apr 01, 2021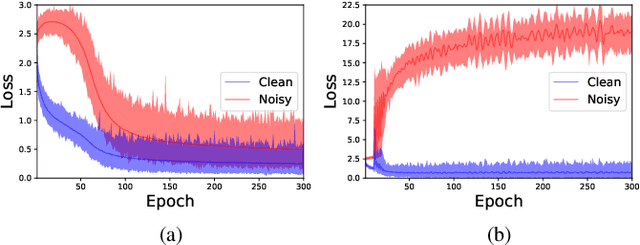
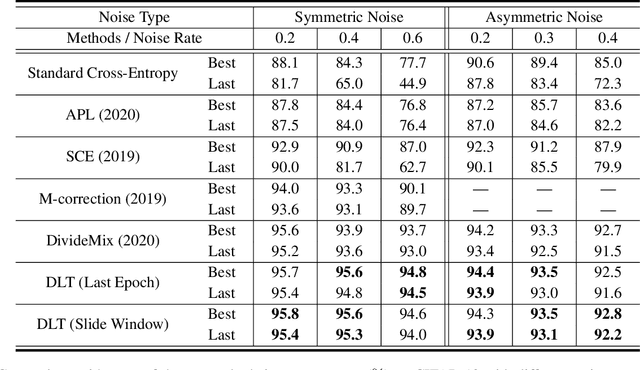
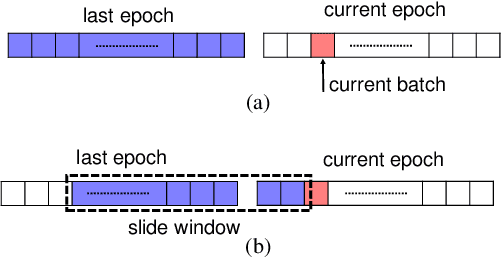
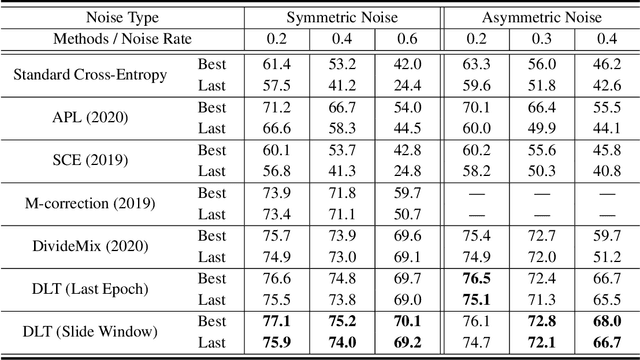
Numerous researches have proved that deep neural networks (DNNs) can fit everything in the end even given data with noisy labels, and result in poor generalization performance. However, recent studies suggest that DNNs tend to gradually memorize the data, moving from correct data to mislabeled data. Inspired by this finding, we propose a novel method named Dynamic Loss Thresholding (DLT). During the training process, DLT records the loss value of each sample and calculates dynamic loss thresholds. Specifically, DLT compares the loss value of each sample with the current loss threshold. Samples with smaller losses can be considered as clean samples with higher probability and vice versa. Then, DLT discards the potentially corrupted labels and further leverages supervised learning techniques. Experiments on CIFAR-10/100 and Clothing1M demonstrate substantial improvements over recent state-of-the-art methods. In addition, we investigate two real-world problems for the first time. Firstly, we propose a novel approach to estimate the noise rates of datasets based on the loss difference between the early and late training stages of DNNs. Secondly, we explore the effect of hard samples (which are difficult to be distinguished) on the process of learning from noisy labels.
A Predictive Autoscaler for Elastic Batch Jobs
Oct 10, 2020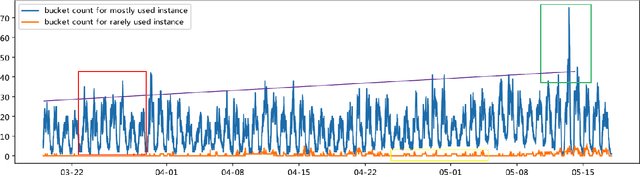

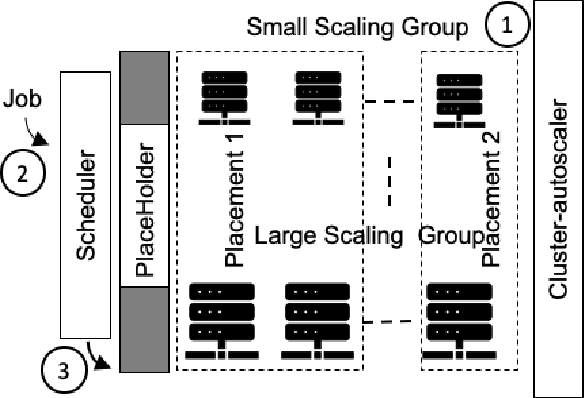

Large batch jobs such as Deep Learning, HPC and Spark require far more computational resources and higher cost than conventional online service. Like the processing of other time series data, these jobs possess a variety of characteristics such as trend, burst, and seasonality. Cloud providers offer short-term instances to achieve scalability, stability, and cost-efficiency. Given the time lag caused by joining into the cluster and initialization, crowded workloads may lead to a violation in the scheduling system. Based on the assumption that there are infinite resources and ideal placements available for users to require in the cloud environment, we propose a predictive autoscaler to provide an elastic interface for the customers and overprovision instances based on the trained regression model. We contribute to a method to embed heterogeneous resource requirements in continuous space into discrete resource buckets and an autoscaler to do predictive expand plans on the time series of resource bucket counts. Our experimental evaluation of the production resources usage data validates the solution and the results show that the predictive autoscaler relieves the burden of making scaling plans, avoids long launching time at lower cost and outperforms other prediction methods with fine-tuned settings.
Spatiotemporal tomography based on scattered multiangular signals and its application for resolving evolving clouds using moving platforms
Dec 06, 2020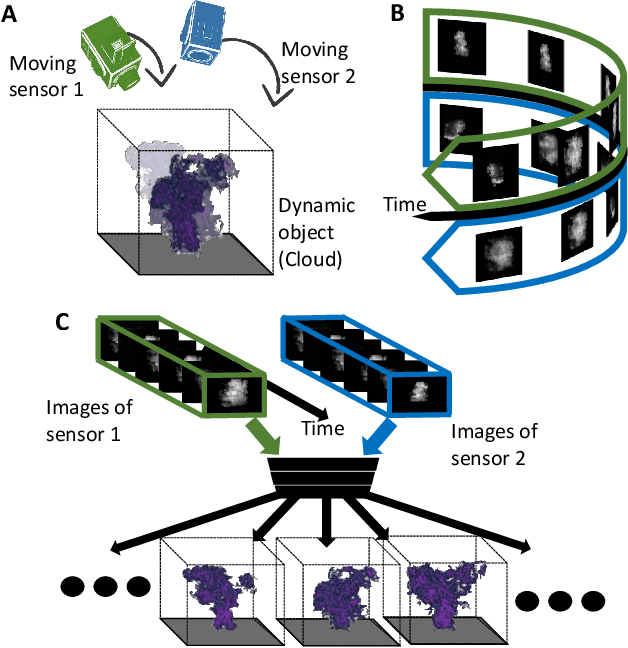
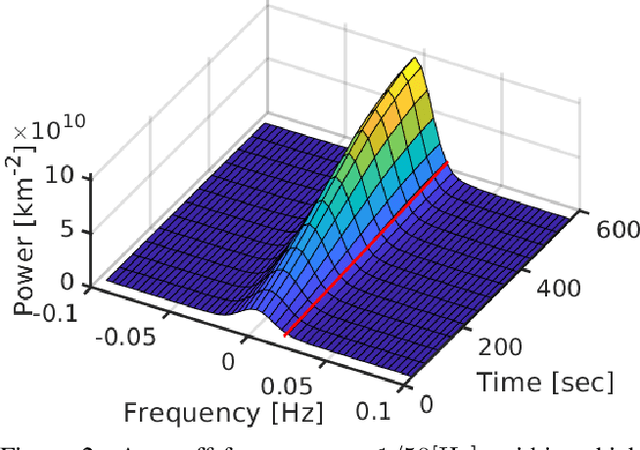
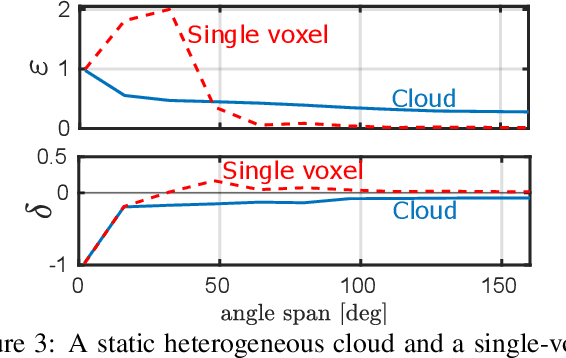
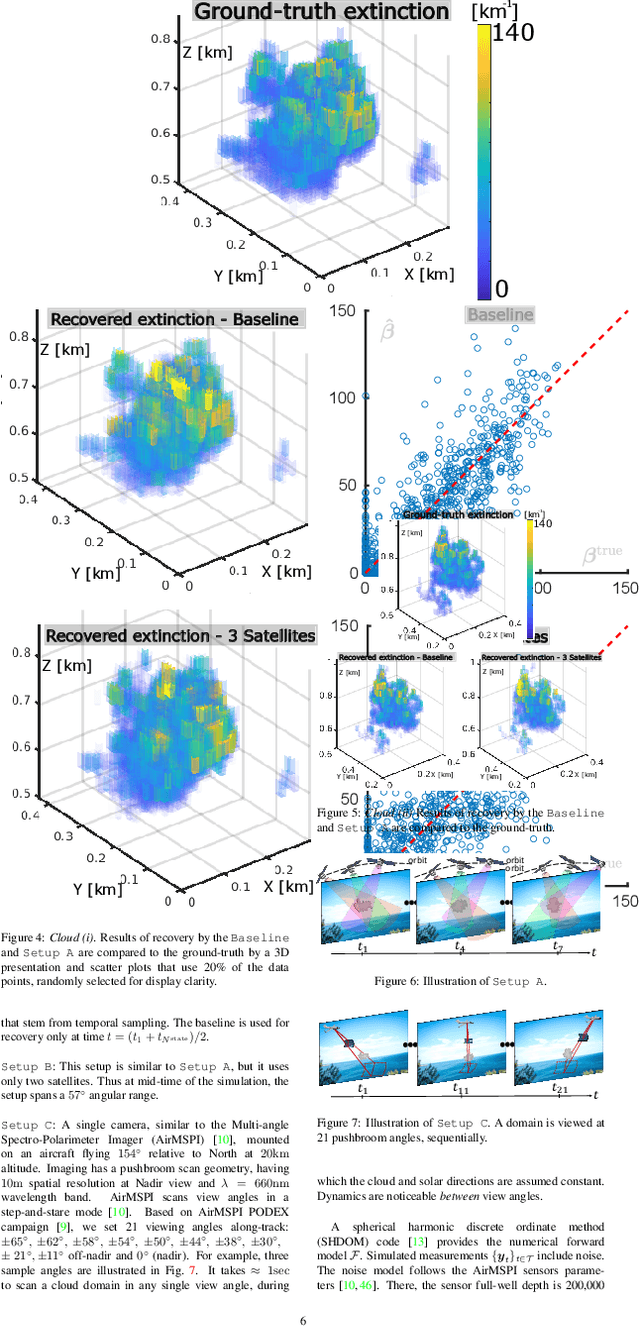
We derive computed tomography (CT) of a time-varying volumetric translucent object, using a small number of moving cameras. We particularly focus on passive scattering tomography, which is a non-linear problem. We demonstrate the approach on dynamic clouds, as clouds have a major effect on Earth's climate. State of the art scattering CT assumes a static object. Existing 4D CT methods rely on a linear image formation model and often on significant priors. In this paper, the angular and temporal sampling rates needed for a proper recovery are discussed. If these rates are used, the paper leads to a representation of the time-varying object, which simplifies 4D CT tomography. The task is achieved using gradient-based optimization. We demonstrate this in physics-based simulations and in an experiment that had yielded real-world data.
Modulated Periodic Activations for Generalizable Local Functional Representations
Apr 08, 2021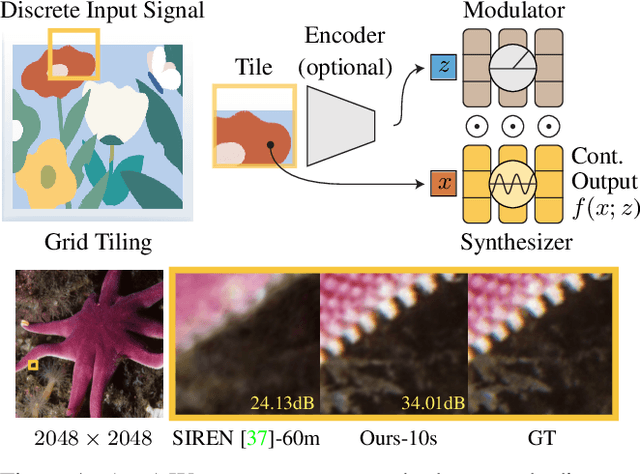
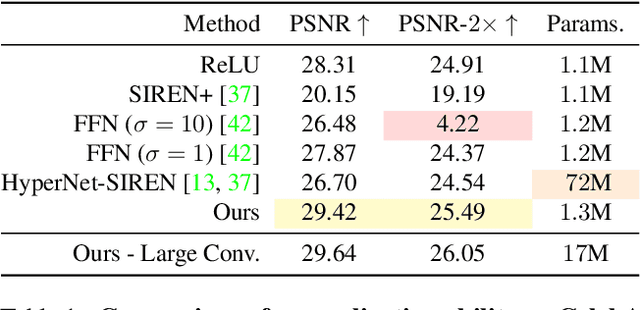
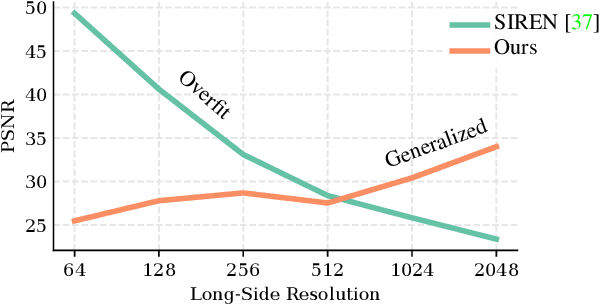
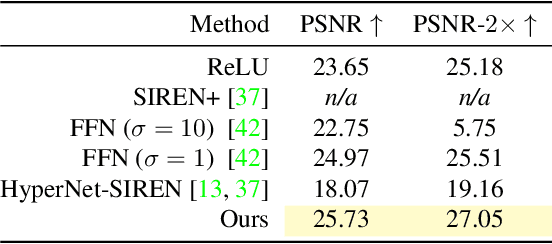
Multi-Layer Perceptrons (MLPs) make powerful functional representations for sampling and reconstruction problems involving low-dimensional signals like images,shapes and light fields. Recent works have significantly improved their ability to represent high-frequency content by using periodic activations or positional encodings. This often came at the expense of generalization: modern methods are typically optimized for a single signal. We present a new representation that generalizes to multiple instances and achieves state-of-the-art fidelity. We use a dual-MLP architecture to encode the signals. A synthesis network creates a functional mapping from a low-dimensional input (e.g. pixel-position) to the output domain (e.g. RGB color). A modulation network maps a latent code corresponding to the target signal to parameters that modulate the periodic activations of the synthesis network. We also propose a local-functional representation which enables generalization. The signal's domain is partitioned into a regular grid,with each tile represented by a latent code. At test time, the signal is encoded with high-fidelity by inferring (or directly optimizing) the latent code-book. Our approach produces generalizable functional representations of images, videos and shapes, and achieves higher reconstruction quality than prior works that are optimized for a single signal.
MBAPose: Mask and Bounding-Box Aware Pose Estimation of Surgical Instruments with Photorealistic Domain Randomization
Mar 15, 2021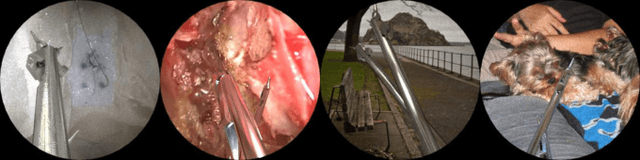
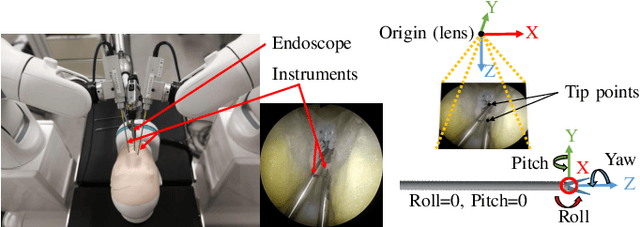
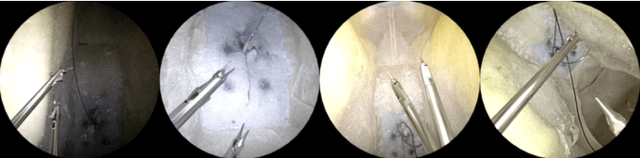
Surgical robots are controlled using a priori models based on robots' geometric parameters, which are calibrated before the surgical procedure. One of the challenges in using robots in real surgical settings is that parameters change over time, consequently deteriorating control accuracy. In this context, our group has been investigating online calibration strategies without added sensors. In one step toward that goal, we have developed an algorithm to estimate the pose of the instruments' shafts in endoscopic images. In this study, we build upon that earlier work and propose a new framework to more precisely estimate the pose of a rigid surgical instrument. Our strategy is based on a novel pose estimation model called MBAPose and the use of synthetic training data. Our experiments demonstrated an improvement of 21 % for translation error and 26 % for orientation error on synthetic test data with respect to our previous work. Results with real test data provide a baseline for further research.
COVID-19 and Big Data: Multi-faceted Analysis for Spatio-temporal Understanding of the Pandemic with Social Media Conversations
Apr 22, 2021COVID-19 has been devastating the world since the end of 2019 and has continued to play a significant role in major national and worldwide events, and consequently, the news. In its wake, it has left no life unaffected. Having earned the world's attention, social media platforms have served as a vehicle for the global conversation about COVID-19. In particular, many people have used these sites in order to express their feelings, experiences, and observations about the pandemic. We provide a multi-faceted analysis of critical properties exhibited by these conversations on social media regarding the novel coronavirus pandemic. We present a framework for analysis, mining, and tracking the critical content and characteristics of social media conversations around the pandemic. Focusing on Twitter and Reddit, we have gathered a large-scale dataset on COVID-19 social media conversations. Our analyses cover tracking potential reports on virus acquisition, symptoms, conversation topics, and language complexity measures through time and by region across the United States. We also present a BERT-based model for recognizing instances of hateful tweets in COVID-19 conversations, which achieves a lower error-rate than the state-of-the-art performance. Our results provide empirical validation for the effectiveness of our proposed framework and further demonstrate that social media data can be efficiently leveraged to provide public health experts with inexpensive but thorough insight over the course of an outbreak.