 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Training Neural Networks is ER-complete
Feb 19, 2021
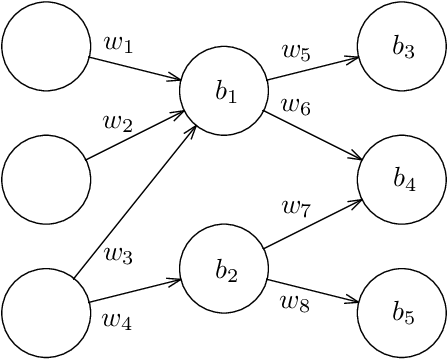
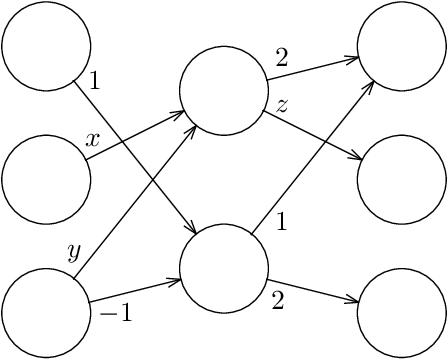
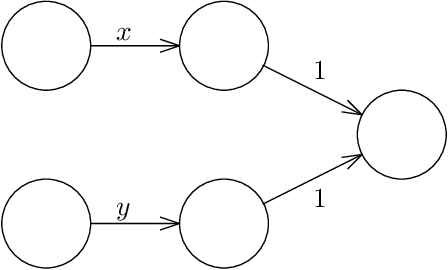
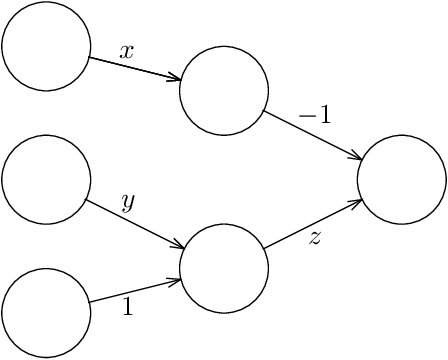
Given a neural network, training data, and a threshold, it was known that it is NP-hard to find weights for the neural network such that the total error is below the threshold. We determine the algorithmic complexity of this fundamental problem precisely, by showing that it is ER-complete. This means that the problem is equivalent, up to polynomial-time reductions, to deciding whether a system of polynomial equations and inequalities with integer coefficients and real unknowns has a solution. If, as widely expected, ER is strictly larger than NP, our work implies that the problem of training neural networks is not even in NP.
MultiCruise: Eco-Lane Selection Strategy with Eco-Cruise Control for Connected and Automated Vehicles
Apr 24, 2021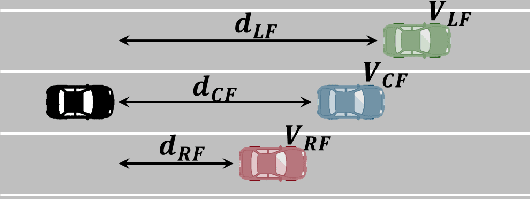
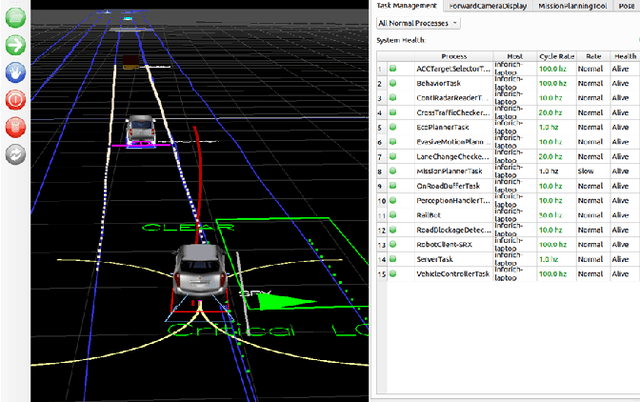
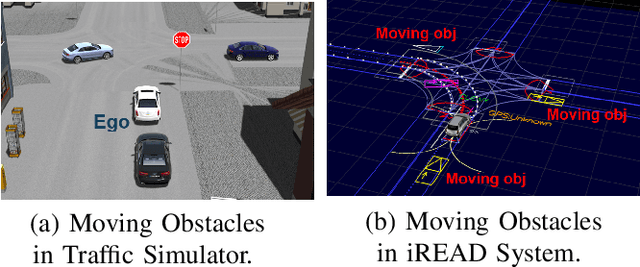
Connected and Automated Vehicles (CAVs) have real-time information from the surrounding environment by using local on-board sensors, V2X (Vehicle-to-Everything) communications, pre-loaded vehicle-specific lookup tables, and map database. CAVs are capable of improving energy efficiency by incorporating these information. In particular, Eco-Cruise and Eco-Lane Selection on highways and/or motorways have immense potential to save energy, because there are generally fewer traffic controllers and the vehicles keep moving in general. In this paper, we present a cooperative and energy-efficient lane-selection strategy named MultiCruise, where each CAV selects one among multiple candidate lanes that allows the most energy-efficient travel. MultiCruise incorporates an Eco-Cruise component to select the most energy-efficient lane. The Eco-Cruise component calculates the driving parameters and prospective energy consumption of the ego vehicle for each candidate lane, and the Eco-Lane Selection component uses these values. As a result, MultiCruise can account for multiple data sources, such as the road curvature and the surrounding vehicles' velocities and accelerations. The eco-autonomous driving strategy, MultiCruise, is tested, designed and verified by using a co-simulation test platform that includes autonomous driving software and realistic road networks to study the performance under realistic driving conditions. Our experimental evaluations show that our eco-autonomous MultiCruise saves up to 8.5% fuel consumption.
Towards Improving Spatiotemporal Action Recognition in Videos
Dec 15, 2020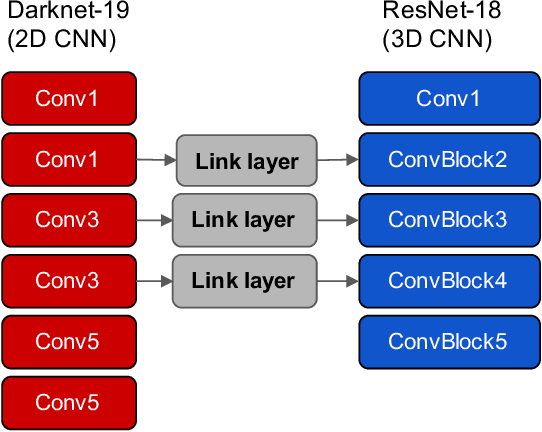
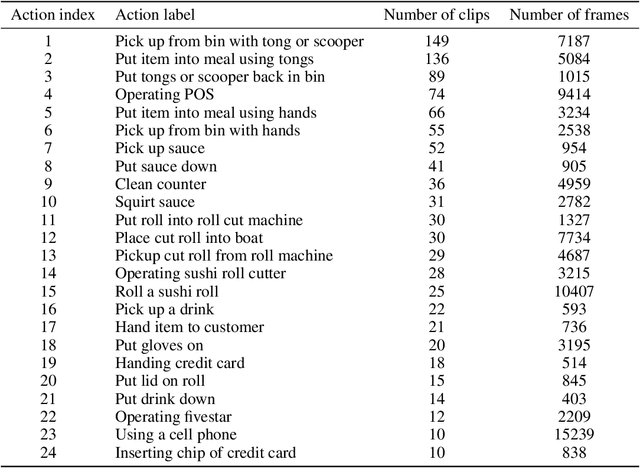
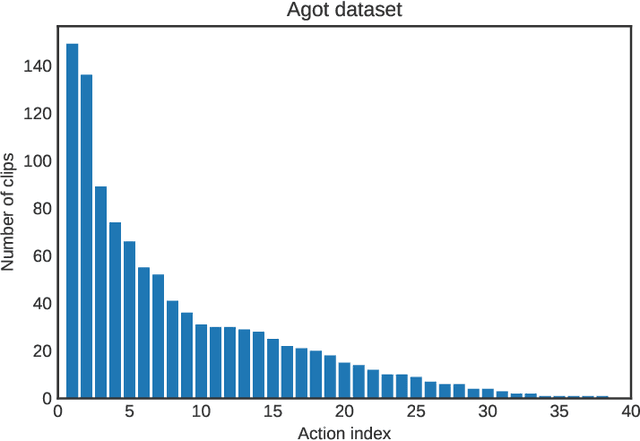
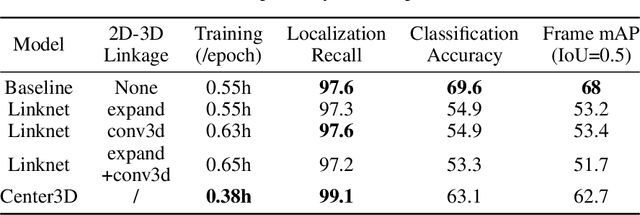
Spatiotemporal action recognition deals with locating and classifying actions in videos. Motivated by the latest state-of-the-art real-time object detector You Only Watch Once (YOWO), we aim to modify its structure to increase action detection precision and reduce computational time. Specifically, we propose four novel approaches in attempts to improve YOWO and address the imbalanced class issue in videos by modifying the loss function. We consider two moderate-sized datasets to apply our modification of YOWO - the popular Joint-annotated Human Motion Data Base (J-HMDB-21) and a private dataset of restaurant video footage provided by a Carnegie Mellon University-based startup, Agot.AI. The latter involves fast-moving actions with small objects as well as unbalanced data classes, making the task of action localization more challenging. We implement our proposed methods in the GitHub repository https://github.com/stoneMo/YOWOv2.
BAXTER: Bi-modal Aerial-Terrestrial Hybrid Vehicle for Long-endurance Versatile Mobility: Preprint Version
Feb 05, 2021
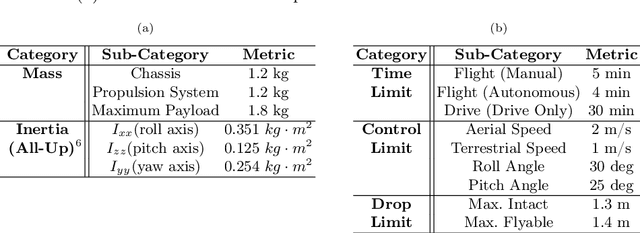


Unmanned aerial vehicles are rapidly evolving within the field of robotics. However, their performance is often limited by payload capacity, operational time, and robustness to impact and collision. These limitations of aerial vehicles become more acute for missions in challenging environments such as subterranean structures which may require extended autonomous operation in confined spaces. While software solutions for aerial robots are developing rapidly, improvements to hardware are critical to applying advanced planners and algorithms in large and dangerous environments where the short range and high susceptibility to collisions of most modern aerial robots make applications in realistic subterranean missions infeasible. To provide such hardware capabilities, one needs to design and implement a hardware solution that takes into the account the Size, Weight, and Power (SWaP) constraints. This work focuses on providing a robust and versatile hybrid platform that improves payload capacity, operation time, endurance, and versatility. The Bi-modal Aerial and Terrestrial hybrid vehicle (BAXTER) is a solution that provides two modes of operation, aerial and terrestrial. BAXTER employs two novel hardware mechanisms: the M-Suspension and the Decoupled Transmission which together provide resilience during landing and crashes and efficient terrestrial operation. Extensive flight tests were conducted to characterize the vehicle's capabilities, including robustness and endurance. Additionally, we propose Agile Mode Transfer (AMT), a transition from aerial to terrestrial operation that seeks to minimize impulses during impact to the ground which is a quick and simple transition process that exploits BAXTER's resilience to impact.
Dual Online Stein Variational Inference for Control and Dynamics
Mar 23, 2021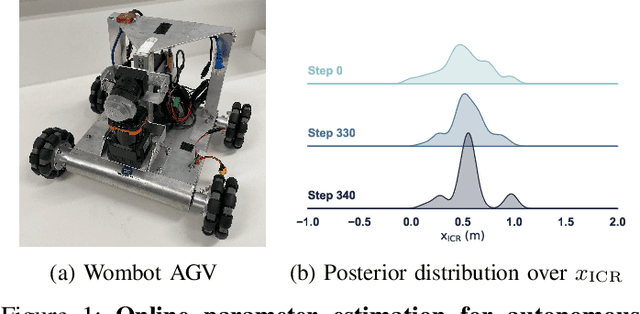
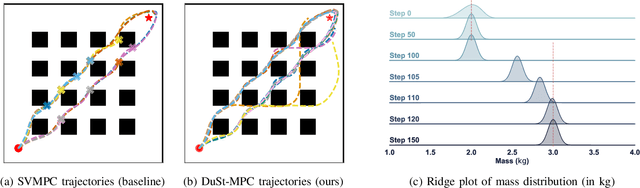
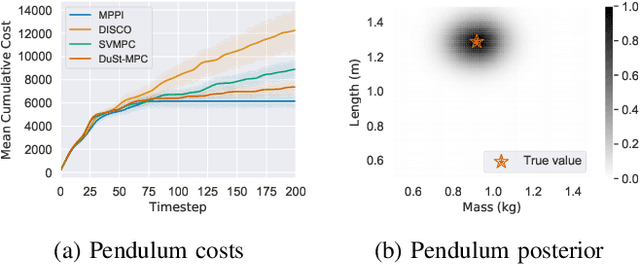
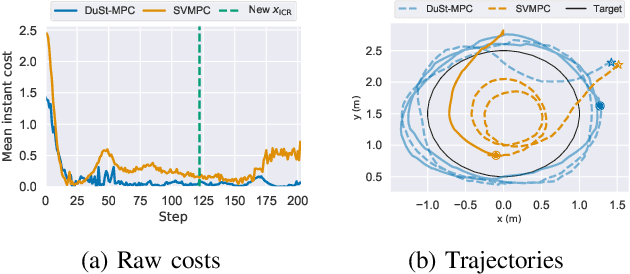
Model predictive control (MPC) schemes have a proven track record for delivering aggressive and robust performance in many challenging control tasks, coping with nonlinear system dynamics, constraints, and observational noise. Despite their success, these methods often rely on simple control distributions, which can limit their performance in highly uncertain and complex environments. MPC frameworks must be able to accommodate changing distributions over system parameters, based on the most recent measurements. In this paper, we devise an implicit variational inference algorithm able to estimate distributions over model parameters and control inputs on-the-fly. The method incorporates Stein Variational gradient descent to approximate the target distributions as a collection of particles, and performs updates based on a Bayesian formulation. This enables the approximation of complex multi-modal posterior distributions, typically occurring in challenging and realistic robot navigation tasks. We demonstrate our approach on both simulated and real-world experiments requiring real-time execution in the face of dynamically changing environments.
A Plenum-Based Calibration Device for Tactile Sensor Arrays
Mar 23, 2021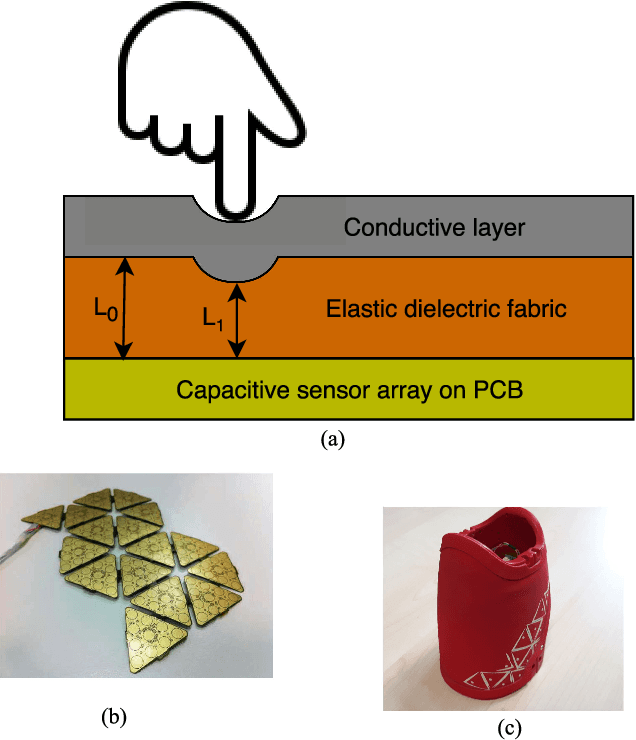
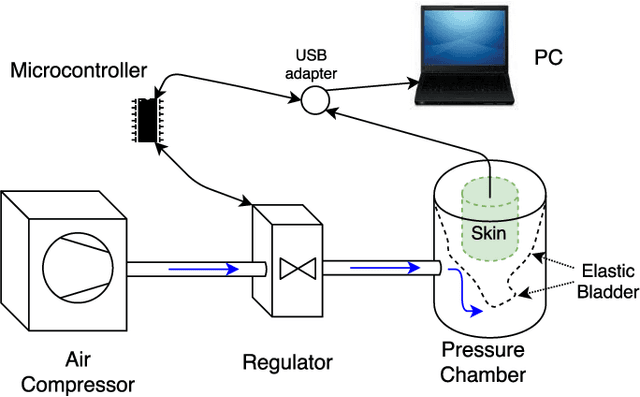
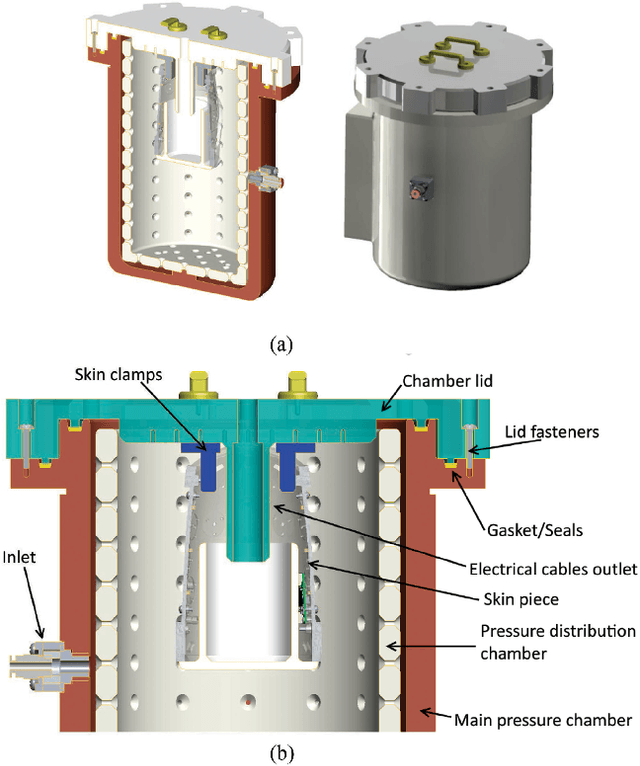
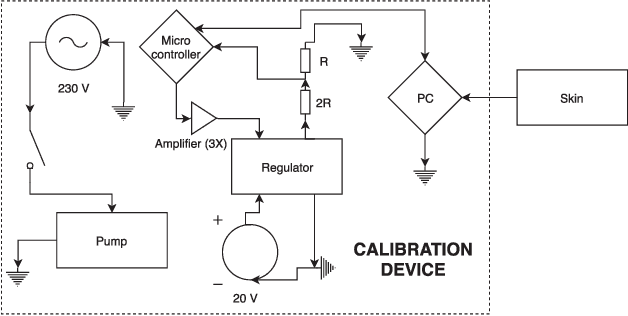
In modern robotic applications, tactile sensor arrays (i.e., artificial skins) are an emergent solution to determine the locations of contacts between a robot and an external agent. Localizing the point of contact is useful but determining the force applied on the skin provides many additional possibilities. This additional feature usually requires time-consuming calibration procedures to relate the sensor readings to the applied forces. This letter presents a novel device that enables the calibration of tactile sensor arrays in a fast and simple way. The key idea is to design a plenum chamber where the skin is inserted, and then the calibration of the tactile sensors is achieved by relating the air pressure and the sensor readings. This general concept is tested experimentally to calibrate the skin of the iCub robot. The validation of the calibration device is achieved by placing the masses of known weight on the artificial skin and comparing the applied force against the one estimated by the sensors.
* 8 pages, 18 figures
Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities
Apr 30, 2021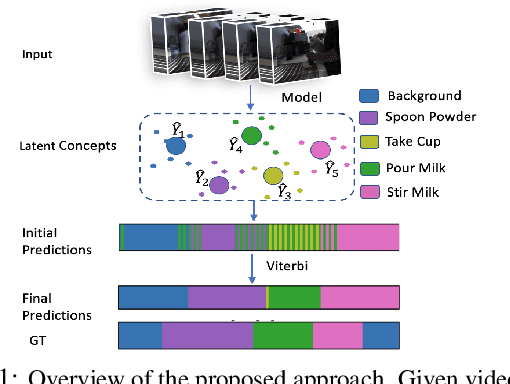
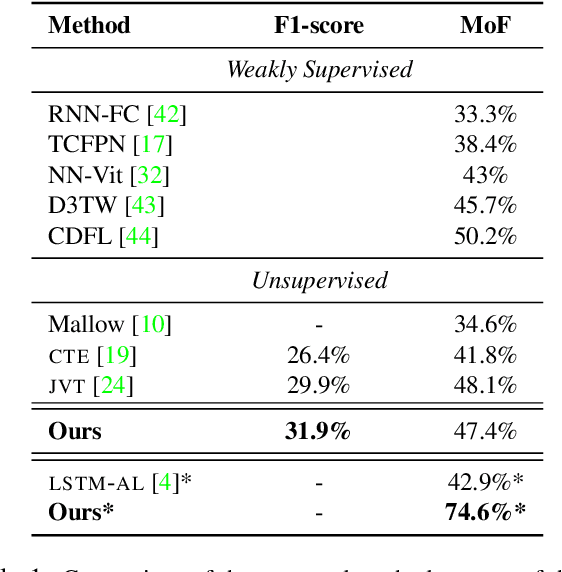
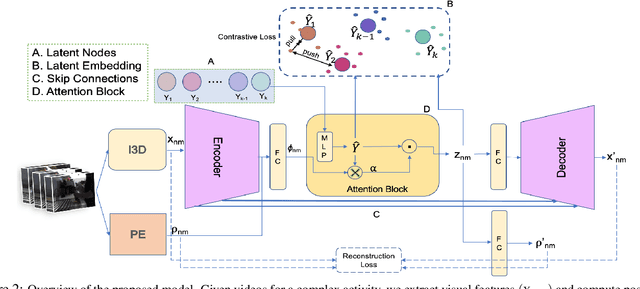

Action recognition and detection in the context of long untrimmed video sequences has seen an increased attention from the research community. However, annotation of complex activities is usually time consuming and challenging in practice. Therefore, recent works started to tackle the problem of unsupervised learning of sub-actions in complex activities. This paper proposes a novel approach for unsupervised sub-action learning in complex activities. The proposed method maps both visual and temporal representations to a latent space where the sub-actions are learnt discriminatively in an end-to-end fashion. To this end, we propose to learn sub-actions as latent concepts and a novel discriminative latent concept learning (DLCL) module aids in learning sub-actions. The proposed DLCL module lends on the idea of latent concepts to learn compact representations in the latent embedding space in an unsupervised way. The result is a set of latent vectors that can be interpreted as cluster centers in the embedding space. The latent space itself is formed by a joint visual and temporal embedding capturing the visual similarity and temporal ordering of the data. Our joint learning with discriminative latent concept module is novel which eliminates the need for explicit clustering. We validate our approach on three benchmark datasets and show that the proposed combination of visual-temporal embedding and discriminative latent concepts allow to learn robust action representations in an unsupervised setting.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 30, 2021
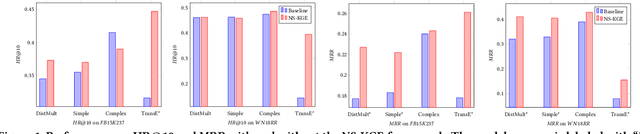
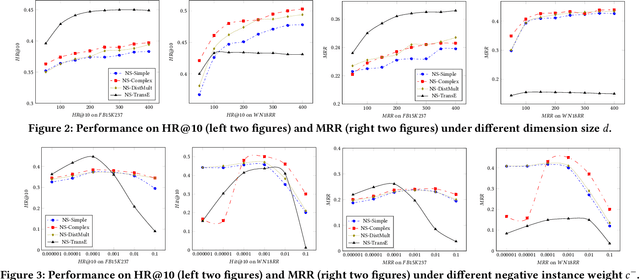
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016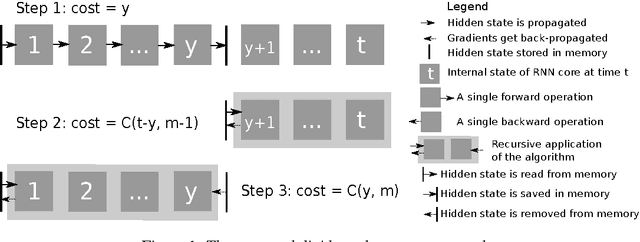
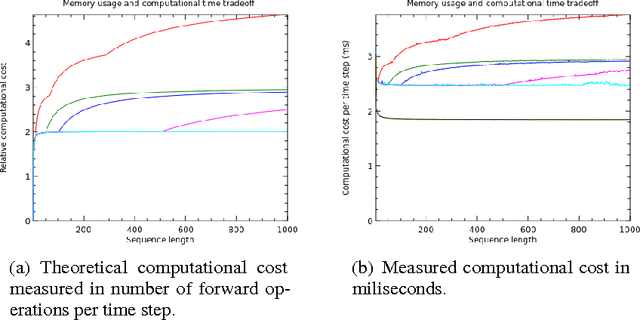
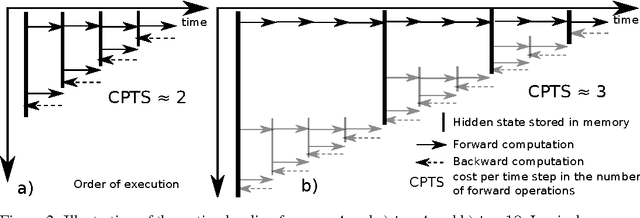
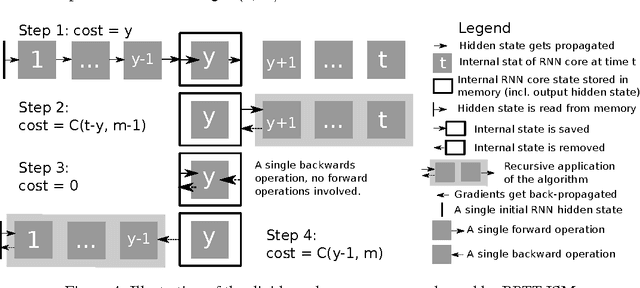
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.
Visually Guided Sound Source Separation and Localization using Self-Supervised Motion Representations
Apr 17, 2021
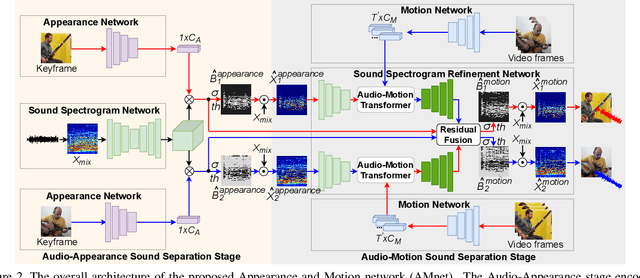
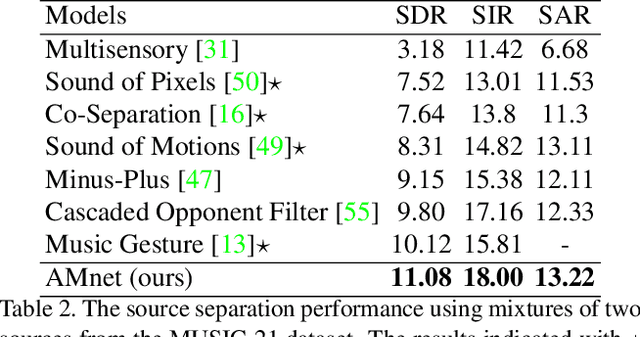
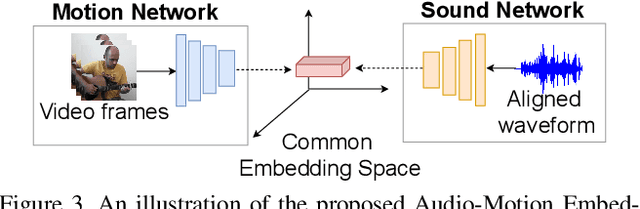
The objective of this paper is to perform audio-visual sound source separation, i.e.~to separate component audios from a mixture based on the videos of sound sources. Moreover, we aim to pinpoint the source location in the input video sequence. Recent works have shown impressive audio-visual separation results when using prior knowledge of the source type (e.g. human playing instrument) and pre-trained motion detectors (e.g. keypoints or optical flows). However, at the same time, the models are limited to a certain application domain. In this paper, we address these limitations and make the following contributions: i) we propose a two-stage architecture, called Appearance and Motion network (AMnet), where the stages specialise to appearance and motion cues, respectively. The entire system is trained in a self-supervised manner; ii) we introduce an Audio-Motion Embedding (AME) framework to explicitly represent the motions that related to sound; iii) we propose an audio-motion transformer architecture for audio and motion feature fusion; iv) we demonstrate state-of-the-art performance on two challenging datasets (MUSIC-21 and AVE) despite the fact that we do not use any pre-trained keypoint detectors or optical flow estimators. Project page: https://ly-zhu.github.io/self-supervised-motion-representations