 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lambda Learner: Fast Incremental Learning on Data Streams
Oct 11, 2020
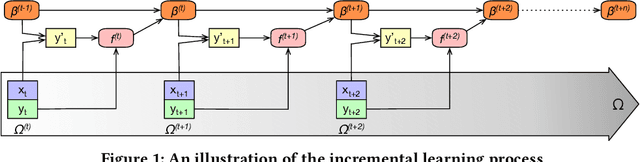
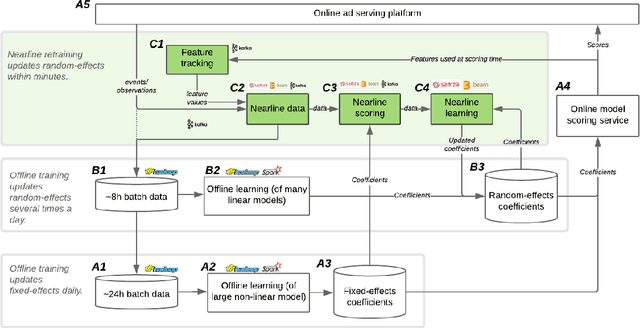
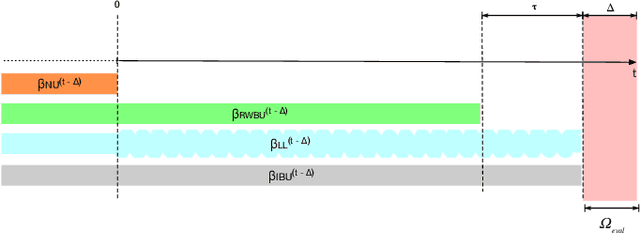
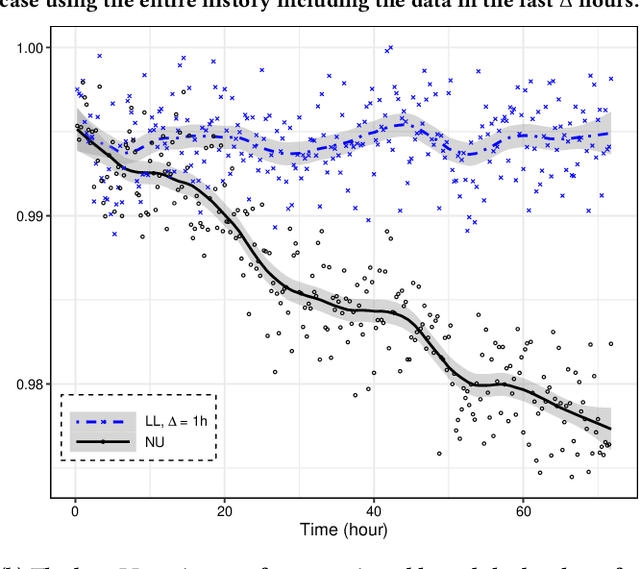
One of the most well-established applications of machine learning is in deciding what content to show website visitors. When observation data comes from high-velocity, user-generated data streams, machine learning methods perform a balancing act between model complexity, training time, and computational costs. Furthermore, when model freshness is critical, the training of models becomes time-constrained. Parallelized batch offline training, although horizontally scalable, is often not time-considerate or cost-effective. In this paper, we propose Lambda Learner, a new framework for training models by incremental updates in response to mini-batches from data streams. We show that the resulting model of our framework closely estimates a periodically updated model trained on offline data and outperforms it when model updates are time-sensitive. We provide theoretical proof that the incremental learning updates improve the loss-function over a stale batch model. We present a large-scale deployment on the sponsored content platform for a large social network, serving hundreds of millions of users across different channels (e.g., desktop, mobile). We address challenges and complexities from both algorithms and infrastructure perspectives, and illustrate the system details for computation, storage, and streaming production of training data.
COTR: Correspondence Transformer for Matching Across Images
Mar 25, 2021
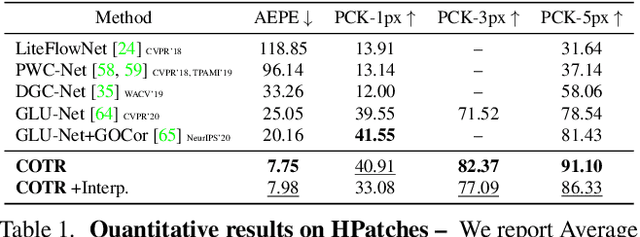
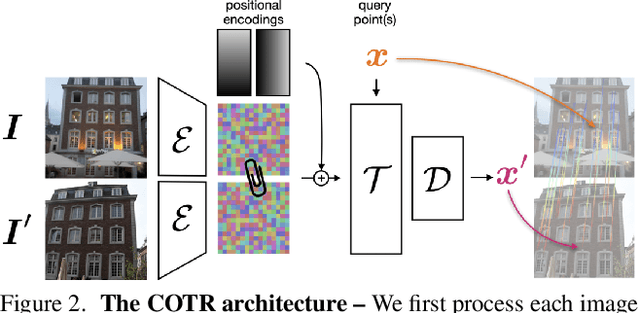
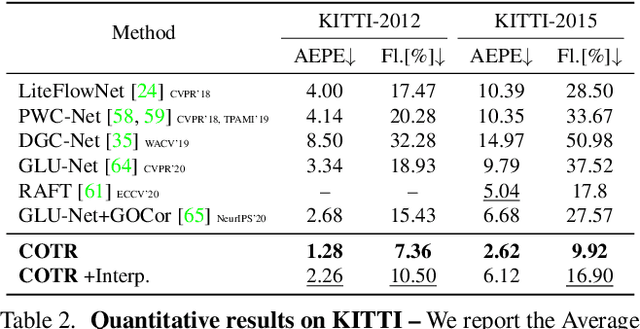
We propose a novel framework for finding correspondences in images based on a deep neural network that, given two images and a query point in one of them, finds its correspondence in the other. By doing so, one has the option to query only the points of interest and retrieve sparse correspondences, or to query all points in an image and obtain dense mappings. Importantly, in order to capture both local and global priors, and to let our model relate between image regions using the most relevant among said priors, we realize our network using a transformer. At inference time, we apply our correspondence network by recursively zooming in around the estimates, yielding a multiscale pipeline able to provide highly-accurate correspondences. Our method significantly outperforms the state of the art on both sparse and dense correspondence problems on multiple datasets and tasks, ranging from wide-baseline stereo to optical flow, without any retraining for a specific dataset. We commit to releasing data, code, and all the tools necessary to train from scratch and ensure reproducibility.
InversionNet3D: Efficient and Scalable Learning for 3D Full Waveform Inversion
Mar 25, 2021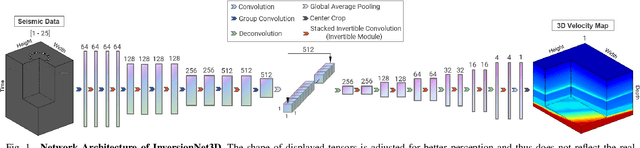
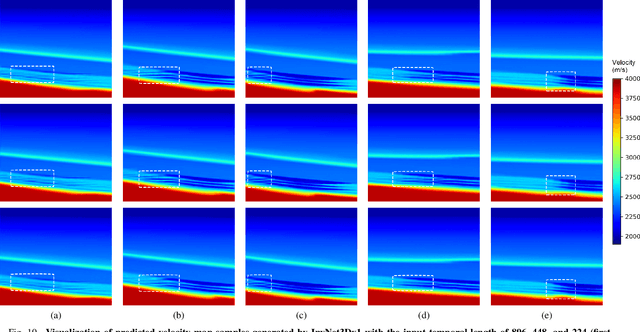
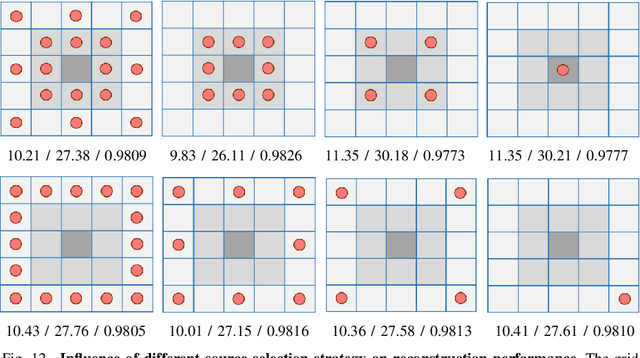
Recent progress in the use of deep learning for Full Waveform Inversion (FWI) has demonstrated the advantage of data-driven methods over traditional physics-based approaches in terms of reconstruction accuracy and computational efficiency. However, due to high computational complexity and large memory consumption, the reconstruction of 3D high-resolution velocity maps via deep networks is still a great challenge. In this paper, we present InversionNet3D, an efficient and scalable encoder-decoder network for 3D FWI. The proposed method employs group convolution in the encoder to establish an effective hierarchy for learning information from multiple sources while cutting down unnecessary parameters and operations at the same time. The introduction of invertible layers further reduces the memory consumption of intermediate features during training and thus enables the development of deeper networks with more layers and higher capacity as required by different application scenarios. Experiments on the 3D Kimberlina dataset demonstrate that InversionNet3D achieves state-of-the-art reconstruction performance with lower computational cost and lower memory footprint compared to the baseline.
StructFormer: Joint Unsupervised Induction of Dependency and Constituency Structure from Masked Language Modeling
Dec 01, 2020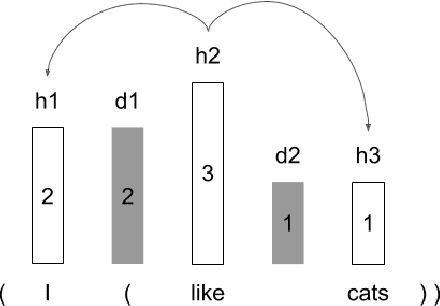

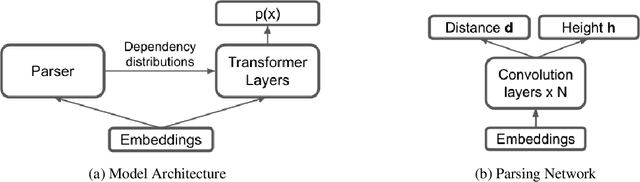
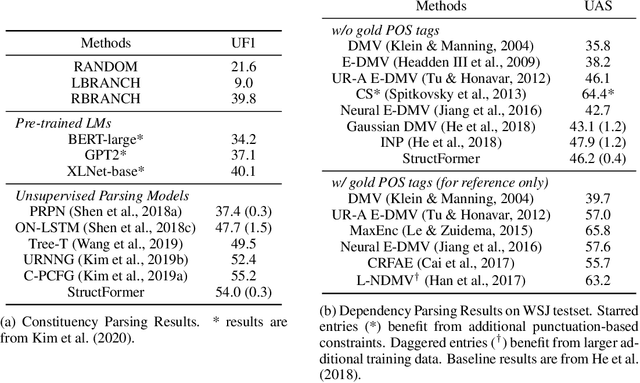
There are two major classes of natural language grammars -- the dependency grammar that models one-to-one correspondences between words and the constituency grammar that models the assembly of one or several corresponded words. While previous unsupervised parsing methods mostly focus on only inducing one class of grammars, we introduce a novel model, StructFormer, that can induce dependency and constituency structure at the same time. To achieve this, we propose a new parsing framework that can jointly generate a constituency tree and dependency graph. Then we integrate the induced dependency relations into the transformer, in a differentiable manner, through a novel dependency-constrained self-attention mechanism. Experimental results show that our model can achieve strong results on unsupervised constituency parsing, unsupervised dependency parsing, and masked language modeling at the same time.
Temporal Difference Learning as Gradient Splitting
Oct 27, 2020Temporal difference learning with linear function approximation is a popular method to obtain a low-dimensional approximation of the value function of a policy in a Markov Decision Process. We give a new interpretation of this method in terms of a splitting of the gradient of an appropriately chosen function. As a consequence of this interpretation, convergence proofs for gradient descent can be applied almost verbatim to temporal difference learning. Beyond giving a new, fuller explanation of why temporal difference works, our interpretation also yields improved convergence times. We consider the setting with $1/\sqrt{T}$ step-size, where previous comparable finite-time convergence time bounds for temporal difference learning had the multiplicative factor $1/(1-\gamma)$ in front of the bound, with $\gamma$ being the discount factor. We show that a minor variation on TD learning which estimates the mean of the value function separately has a convergence time where $1/(1-\gamma)$ only multiplies an asymptotically negligible term.
Oriented Bounding Boxes for Small and Freely Rotated Objects
Apr 24, 2021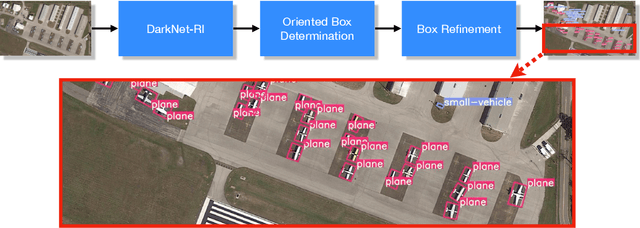
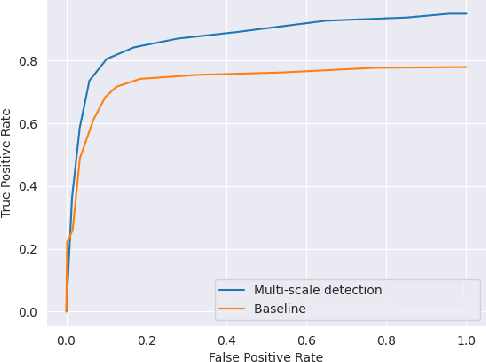
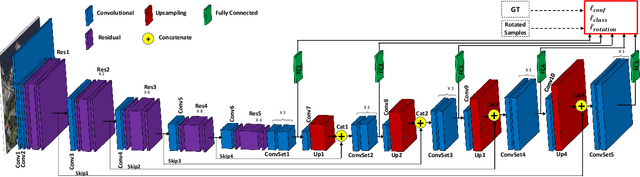
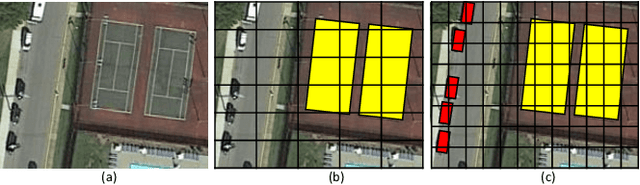
A novel object detection method is presented that handles freely rotated objects of arbitrary sizes, including tiny objects as small as $2\times 2$ pixels. Such tiny objects appear frequently in remotely sensed images, and present a challenge to recent object detection algorithms. More importantly, current object detection methods have been designed originally to accommodate axis-aligned bounding box detection, and therefore fail to accurately localize oriented boxes that best describe freely rotated objects. In contrast, the proposed CNN-based approach uses potential pixel information at multiple scale levels without the need for any external resources, such as anchor boxes.The method encodes the precise location and orientation of features of the target objects at grid cell locations. Unlike existing methods which regress the bounding box location and dimension,the proposed method learns all the required information by classification, which has the added benefit of enabling oriented bounding box detection without any extra computation. It thus infers the bounding boxes only at inference time by finding the minimum surrounding box for every set of the same predicted class labels. Moreover, a rotation-invariant feature representation is applied to each scale, which imposes a regularization constraint to enforce covering the 360 degree range of in-plane rotation of the training samples to share similar features. Evaluations on the xView and DOTA datasets show that the proposed method uniformly improves performance over existing state-of-the-art methods.
Crossing the Conversational Chasm: A Primer on Multilingual Task-Oriented Dialogue Systems
Apr 17, 2021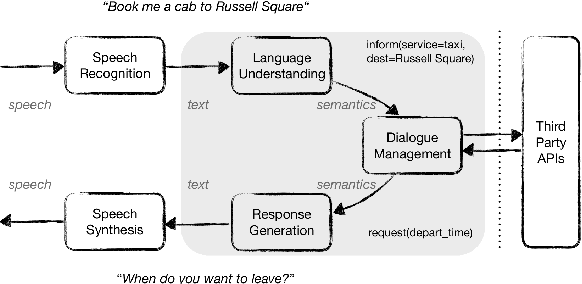
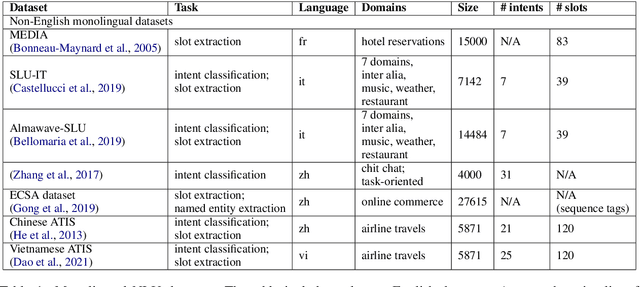
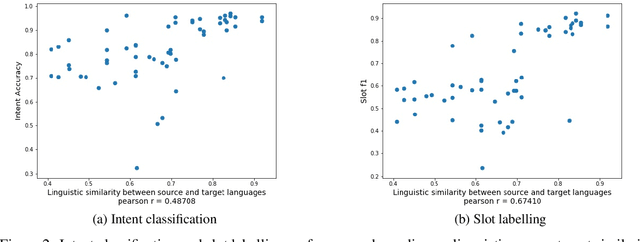
Despite the fact that natural language conversations with machines represent one of the central objectives of AI, and despite the massive increase of research and development efforts in conversational AI, task-oriented dialogue (ToD) -- i.e., conversations with an artificial agent with the aim of completing a concrete task -- is currently limited to a few narrow domains (e.g., food ordering, ticket booking) and a handful of major languages (e.g., English, Chinese). In this work, we provide an extensive overview of existing efforts in multilingual ToD and analyse the factors preventing the development of truly multilingual ToD systems. We identify two main challenges that combined hinder the faster progress in multilingual ToD: (1) current state-of-the-art ToD models based on large pretrained neural language models are data hungry; at the same time (2) data acquisition for ToD use cases is expensive and tedious. Most existing approaches to multilingual ToD thus rely on (zero- or few-shot) cross-lingual transfer from resource-rich languages (in ToD, this is basically only English), either by means of (i) machine translation or (ii) multilingual representation spaces. However, such approaches are currently not a viable solution for a large number of low-resource languages without parallel data and/or limited monolingual corpora. Finally, we discuss critical challenges and potential solutions by drawing parallels between ToD and other cross-lingual and multilingual NLP research.
Persistent Message Passing
Mar 01, 2021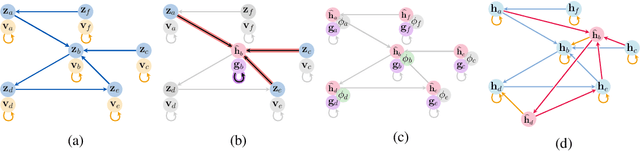
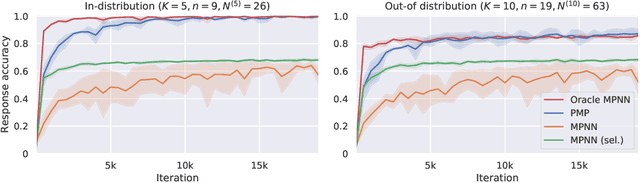
Graph neural networks (GNNs) are a powerful inductive bias for modelling algorithmic reasoning procedures and data structures. Their prowess was mainly demonstrated on tasks featuring Markovian dynamics, where querying any associated data structure depends only on its latest state. For many tasks of interest, however, it may be highly beneficial to support efficient data structure queries dependent on previous states. This requires tracking the data structure's evolution through time, placing significant pressure on the GNN's latent representations. We introduce Persistent Message Passing (PMP), a mechanism which endows GNNs with capability of querying past state by explicitly persisting it: rather than overwriting node representations, it creates new nodes whenever required. PMP generalises out-of-distribution to more than 2x larger test inputs on dynamic temporal range queries, significantly outperforming GNNs which overwrite states.
Estimación del Exponente de Hurst en Flujos de Tráfico Autosimilares
Mar 11, 2021In this paper it presents, develops and discusses the existence of a process with long scope memory structure, representing of the independence between the degree of randomness of the traffic generated by the sources and flow pattern exhibited by the network. The process existence is presented in term of a new algorithmic that is a variant of the maximum likelihood estimator (MLE) of Whittle, for the calculation of the Hurst exponent (H) of self-similar stationary second order time series of the flows of the individual sources and their aggregation. Also, it is discussed the additional problems introduced by the phenomenon of the locality of the Hurst exponent, that appears when the traffic flows consist of diverse elements with different Hurst exponents. The instance is exposed with the intention of being considered as a new and alternative approach for modeling and simulating traffic in existing computer networks.
Simulating Surface Wave Dynamics with Convolutional Networks
Dec 01, 2020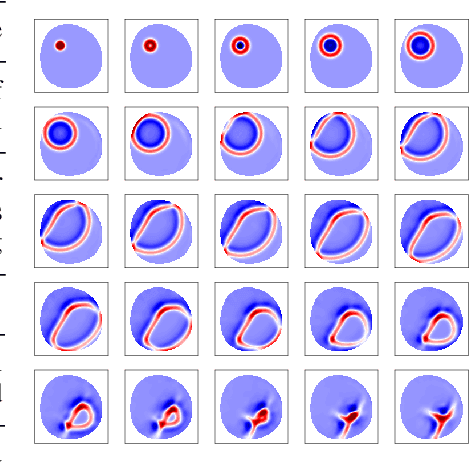
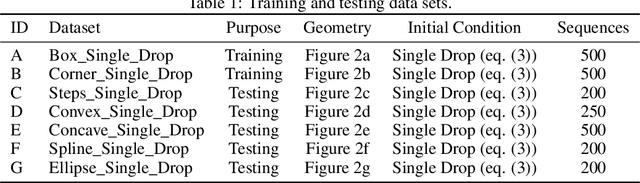
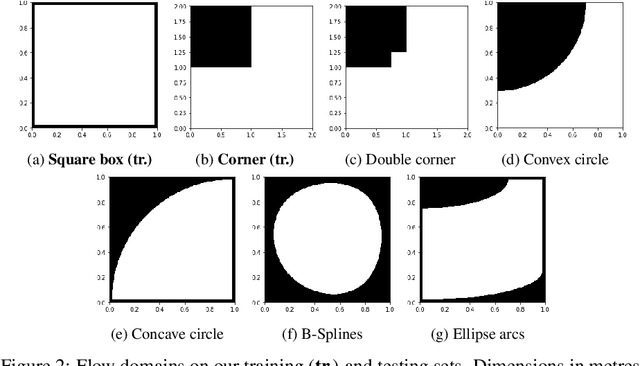
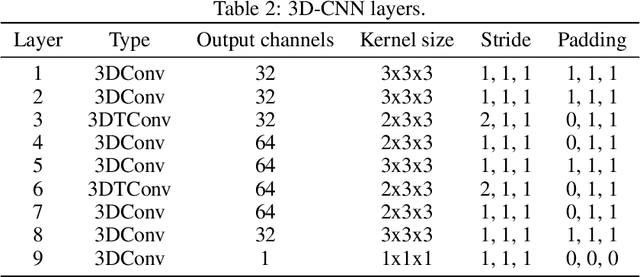
We investigate the performance of fully convolutional networks to simulate the motion and interaction of surface waves in open and closed complex geometries. We focus on a U-Net architecture and analyse how well it generalises to geometric configurations not seen during training. We demonstrate that a modified U-Net architecture is capable of accurately predicting the height distribution of waves on a liquid surface within curved and multi-faceted open and closed geometries, when only simple box and right-angled corner geometries were seen during training. We also consider a separate and independent 3D CNN for performing time-interpolation on the predictions produced by our U-Net. This allows generating simulations with a smaller time-step size than the one the U-Net has been trained for.