 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021

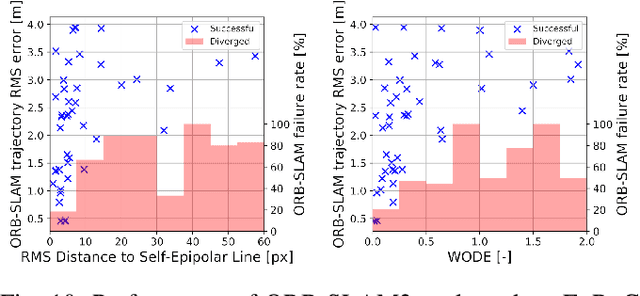

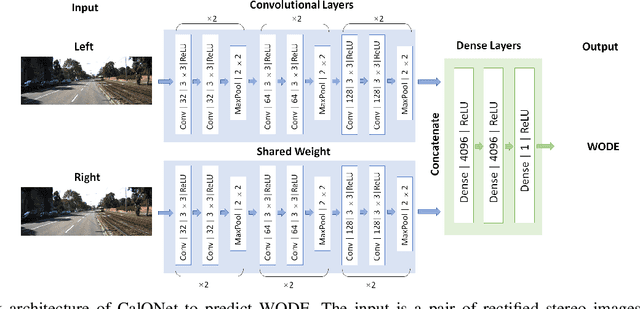
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.
FRDet: Balanced and Lightweight Object Detector based on Fire-Residual Modules for Embedded Processor of Autonomous Driving
Nov 16, 2020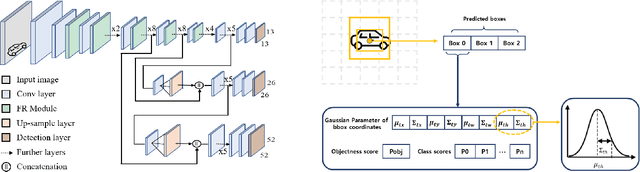
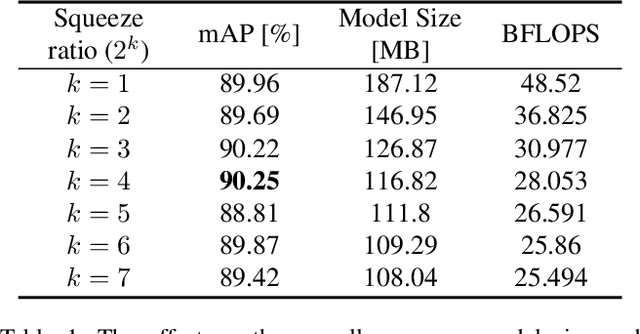
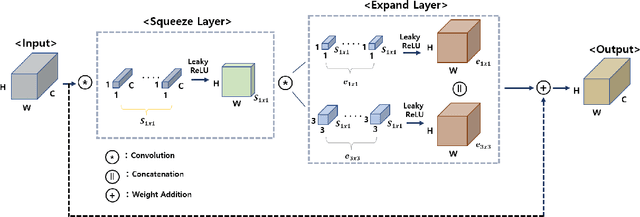

For deployment on an embedded processor for autonomous driving, the object detection network should satisfy all of the accuracy, real-time inference, and light model size requirements. Conventional deep CNN-based detectors aim for high accuracy, making their model size heavy for an embedded system with limited memory space. In contrast, lightweight object detectors are greatly compressed but at a significant sacrifice of accuracy. Therefore, we propose FRDet, a lightweight one-stage object detector that is balanced to satisfy all the constraints of accuracy, model size, and real-time processing on an embedded GPU processor for autonomous driving applications. Our network aims to maximize the compression of the model while achieving or surpassing YOLOv3 level of accuracy. This paper proposes the Fire-Residual (FR) module to design a lightweight network with low accuracy loss by adapting fire modules with residual skip connections. In addition, the Gaussian uncertainty modeling of the bounding box is applied to further enhance the localization accuracy. Experiments on the KITTI dataset showed that FRDet reduced the memory size by 50.8% but achieved higher accuracy by 1.12% mAP compared to YOLOv3. Moreover, the real-time detection speed reached 31.3 FPS on an embedded GPU board(NVIDIA Xavier). The proposed network achieved higher compression with comparable accuracy compared to other deep CNN object detectors while showing improved accuracy than the lightweight detector baselines. Therefore, the proposed FRDet is a well-balanced and efficient object detector for practical application in autonomous driving that can satisfies all the criteria of accuracy, real-time inference, and light model size.
Reinforcement Based Learning on Classification Task Could Yield Better Generalization and Adversarial Accuracy
Dec 08, 2020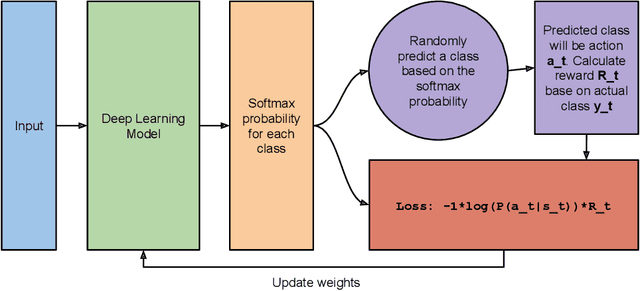
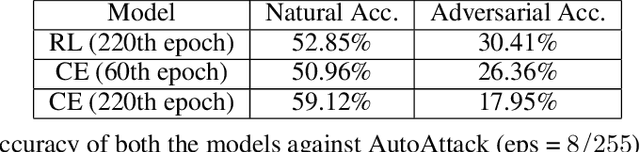
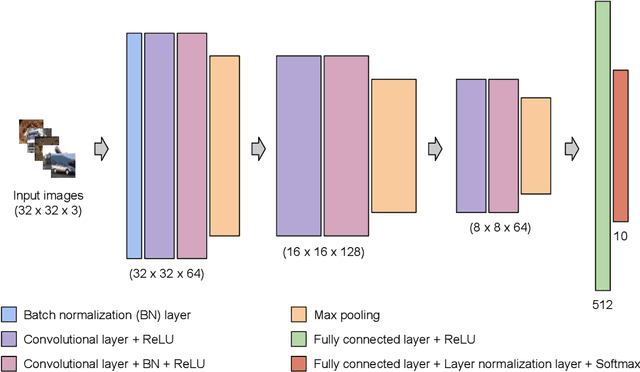
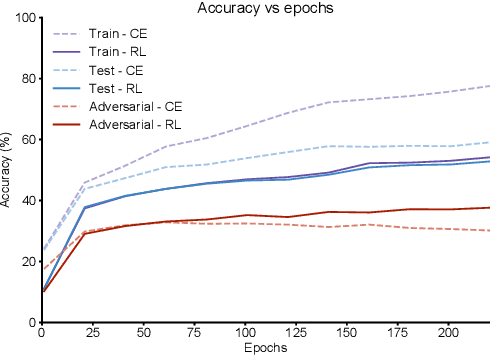
Deep Learning has become interestingly popular in computer vision, mostly attaining near or above human-level performance in various vision tasks. But recent work has also demonstrated that these deep neural networks are very vulnerable to adversarial examples (adversarial examples - inputs to a model which are naturally similar to original data but fools the model in classifying it into a wrong class). Humans are very robust against such perturbations; one possible reason could be that humans do not learn to classify based on an error between "target label" and "predicted label" but possibly due to reinforcements that they receive on their predictions. In this work, we proposed a novel method to train deep learning models on an image classification task. We used a reward-based optimization function, similar to the vanilla policy gradient method used in reinforcement learning, to train our model instead of conventional cross-entropy loss. An empirical evaluation on the cifar10 dataset showed that our method learns a more robust classifier than the same model architecture trained using cross-entropy loss function (on adversarial training). At the same time, our method shows a better generalization with the difference in test accuracy and train accuracy $< 2\%$ for most of the time compared to the cross-entropy one, whose difference most of the time remains $> 2\%$.
Classification of Urban Morphology with Deep Learning: Application on Urban Vitality
May 07, 2021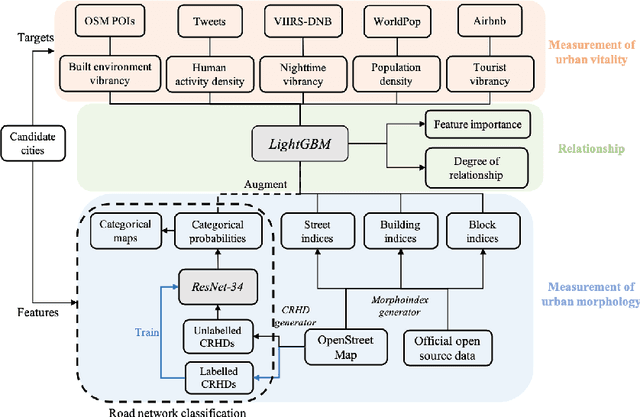
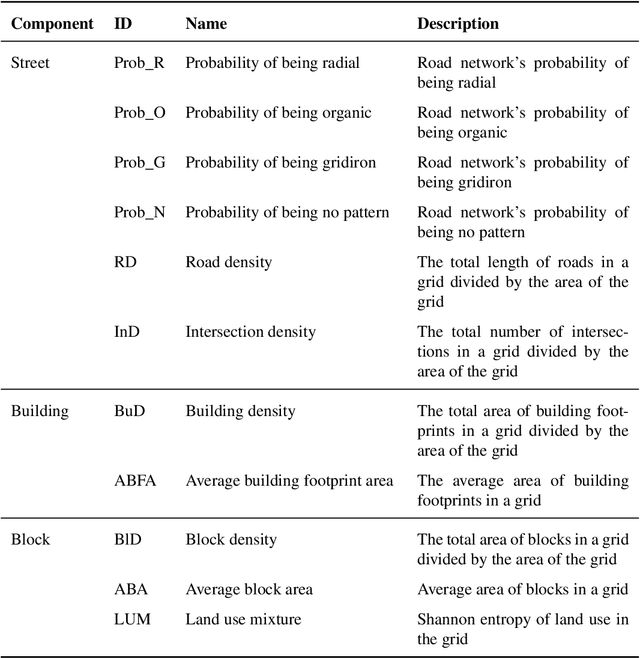
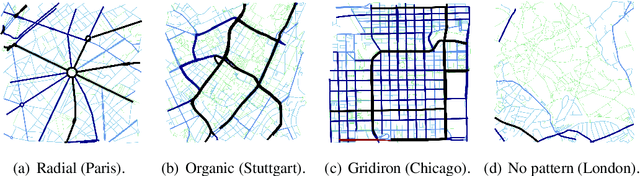
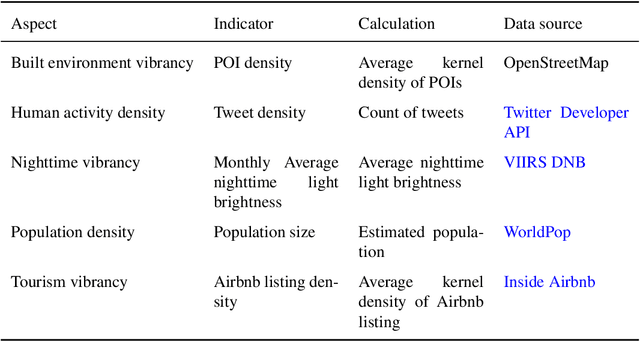
There is a prevailing trend to study urban morphology quantitatively thanks to the growing accessibility to various forms of spatial big data, increasing computing power, and use cases benefiting from such information. The methods developed up to now measure urban morphology with numerical indices describing density, proportion, and mixture, but they do not directly represent morphological features from human's visual and intuitive perspective. We take the first step to bridge the gap by proposing a deep learning-based technique to automatically classify road networks into four classes on a visual basis. The method is implemented by generating an image of the street network (Colored Road Hierarchy Diagram), which we introduce in this paper, and classifying it using a deep convolutional neural network (ResNet-34). The model achieves an overall classification accuracy of 0.875. Nine cities around the world are selected as the study areas and their road networks are acquired from OpenStreetMap. Latent subgroups among the cities are uncovered through a clustering on the percentage of each road network category. In the subsequent part of the paper, we focus on the usability of such classification: the effectiveness of our human perception augmentation is examined by a case study of urban vitality prediction. An advanced tree-based regression model is for the first time designated to establish the relationship between morphological indices and vitality indicators. A positive effect of human perception augmentation is detected in the comparative experiment of baseline model and augmented model. This work expands the toolkit of quantitative urban morphology study with new techniques, supporting further studies in the future.
Lottery Jackpots Exist in Pre-trained Models
Apr 18, 2021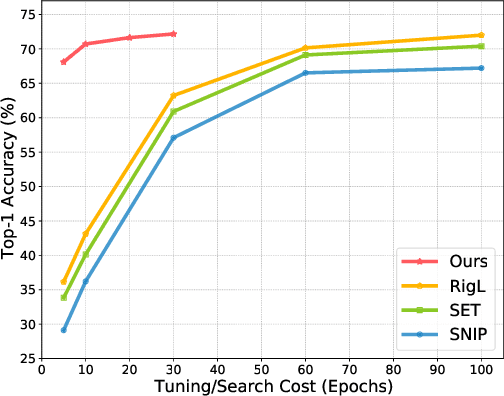
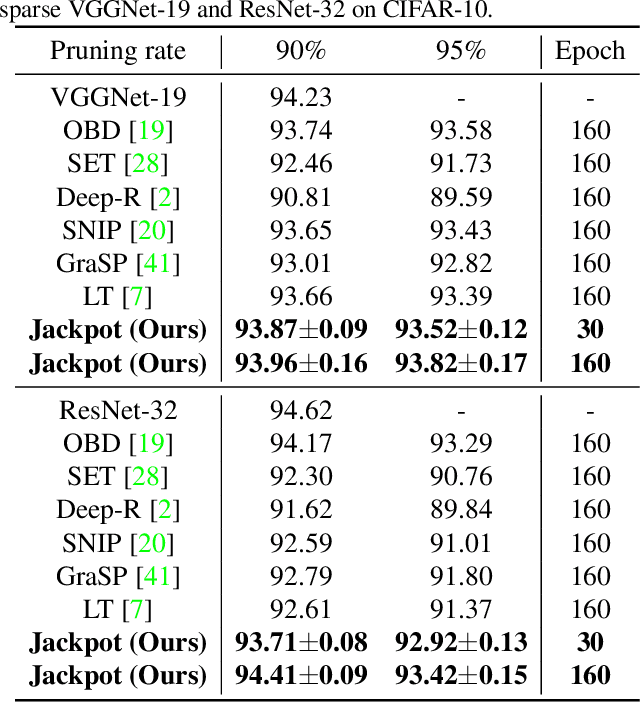
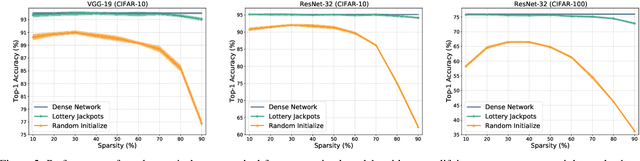
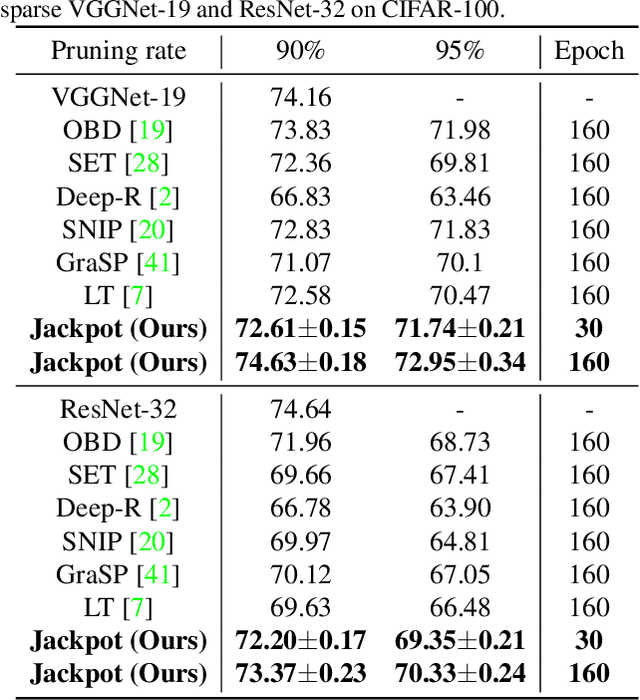
Network pruning is an effective approach to reduce network complexity without performance compromise. Existing studies achieve the sparsity of neural networks via time-consuming weight tuning or complex search on networks with expanded width, which greatly limits the applications of network pruning. In this paper, we show that high-performing and sparse sub-networks without the involvement of weight tuning, termed "lottery jackpots", exist in pre-trained models with unexpanded width. For example, we obtain a lottery jackpot that has only 10% parameters and still reaches the performance of the original dense VGGNet-19 without any modifications on the pre-trained weights. Furthermore, we observe that the sparse masks derived from many existing pruning criteria have a high overlap with the searched mask of our lottery jackpot, among which, the magnitude-based pruning results in the most similar mask with ours. Based on this insight, we initialize our sparse mask using the magnitude pruning, resulting in at least 3x cost reduction on the lottery jackpot search while achieves comparable or even better performance. Specifically, our magnitude-based lottery jackpot removes 90% weights in the ResNet-50, while easily obtains more than 70% top-1 accuracy using only 10 searching epochs on ImageNet.
FasterSeg: Searching for Faster Real-time Semantic Segmentation
Jan 16, 2020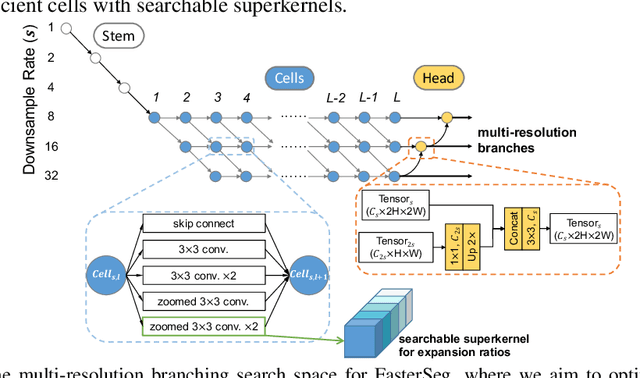
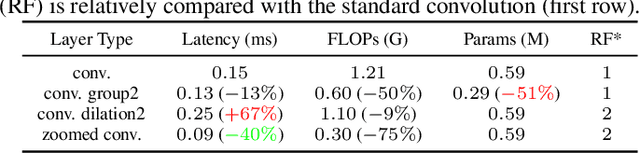
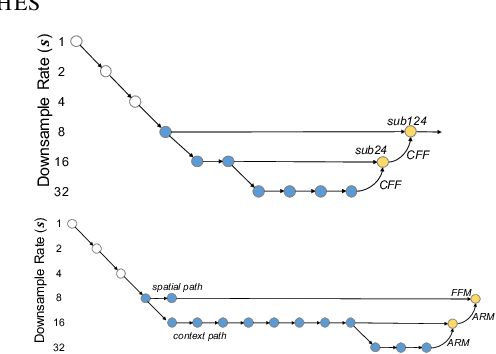
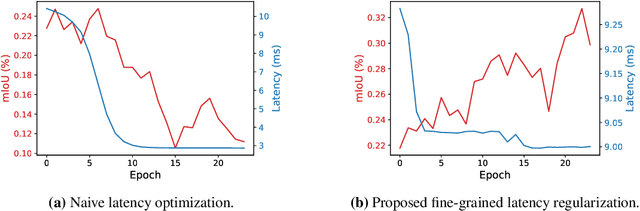
We present FasterSeg, an automatically designed semantic segmentation network with not only state-of-the-art performance but also faster speed than current methods. Utilizing neural architecture search (NAS), FasterSeg is discovered from a novel and broader search space integrating multi-resolution branches, that has been recently found to be vital in manually designed segmentation models. To better calibrate the balance between the goals of high accuracy and low latency, we propose a decoupled and fine-grained latency regularization, that effectively overcomes our observed phenomenons that the searched networks are prone to "collapsing" to low-latency yet poor-accuracy models. Moreover, we seamlessly extend FasterSeg to a new collaborative search (co-searching) framework, simultaneously searching for a teacher and a student network in the same single run. The teacher-student distillation further boosts the student model's accuracy. Experiments on popular segmentation benchmarks demonstrate the competency of FasterSeg. For example, FasterSeg can run over 30% faster than the closest manually designed competitor on Cityscapes, while maintaining comparable accuracy.
CrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Mar 14, 2021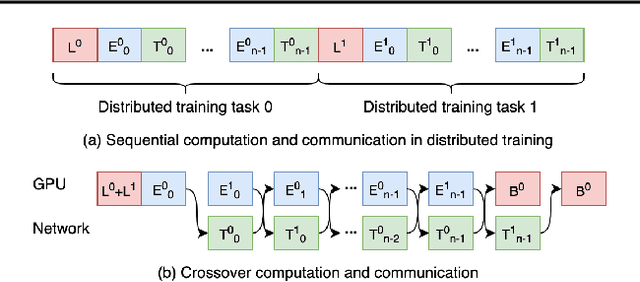
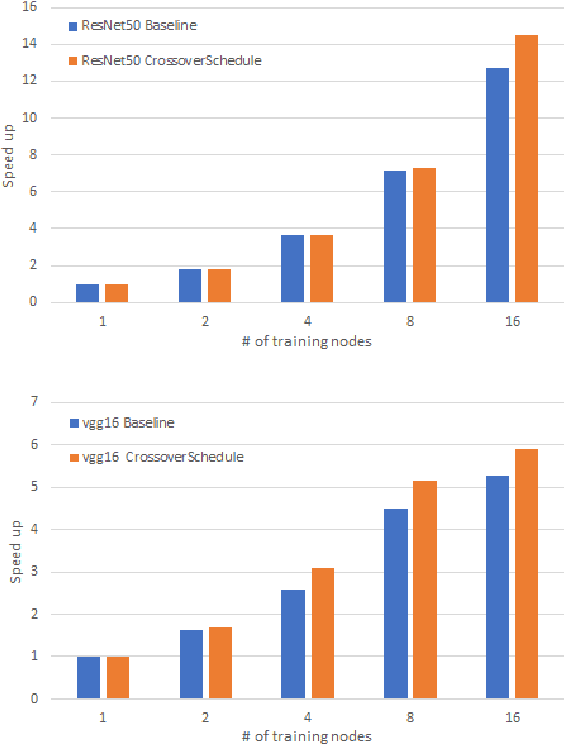
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.
Vulnerability of Appearance-based Gaze Estimation
Mar 24, 2021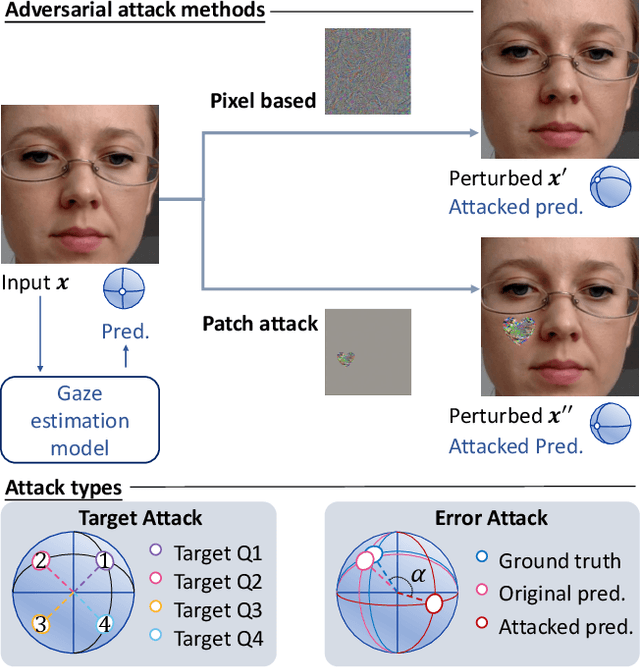
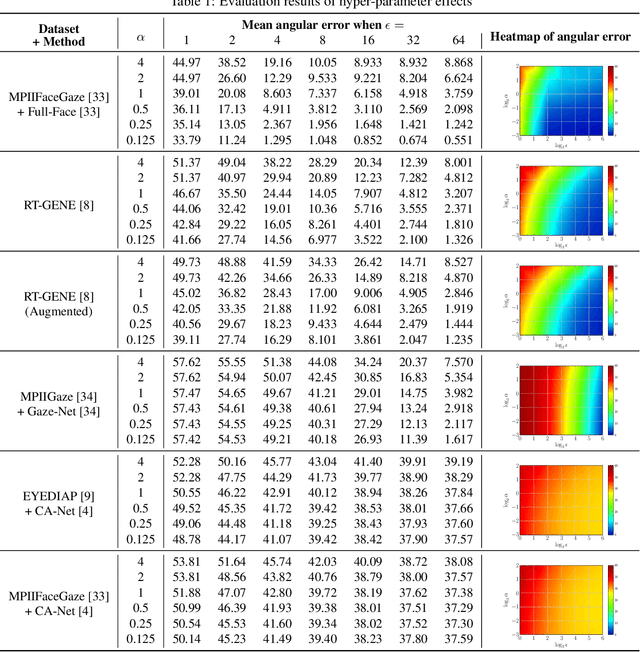
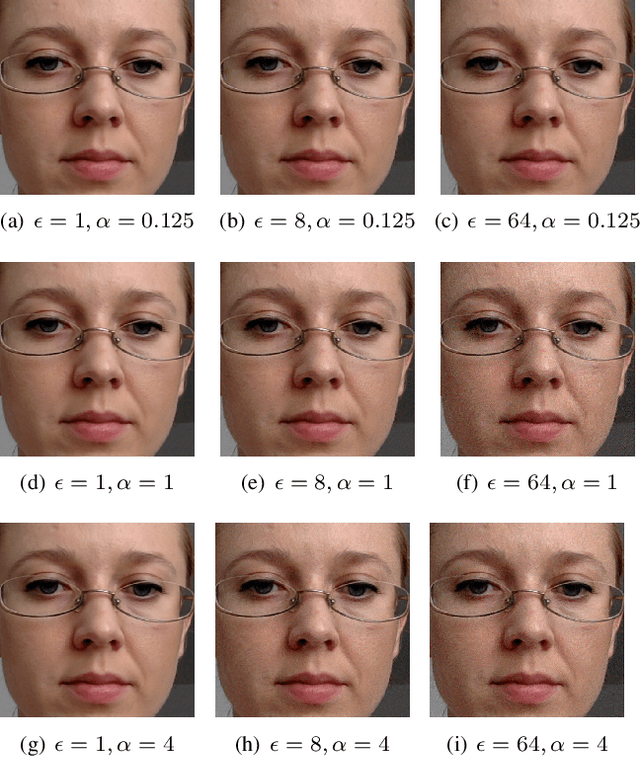
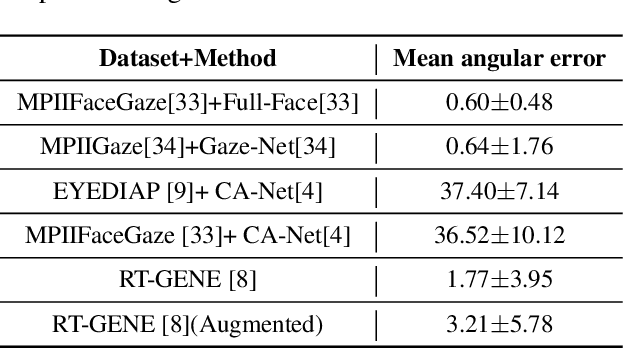
Appearance-based gaze estimation has achieved significant improvement by using deep learning. However, many deep learning-based methods suffer from the vulnerability property, i.e., perturbing the raw image using noise confuses the gaze estimation models. Although the perturbed image visually looks similar to the original image, the gaze estimation models output the wrong gaze direction. In this paper, we investigate the vulnerability of appearance-based gaze estimation. To our knowledge, this is the first time that the vulnerability of gaze estimation to be found. We systematically characterized the vulnerability property from multiple aspects, the pixel-based adversarial attack, the patch-based adversarial attack and the defense strategy. Our experimental results demonstrate that the CA-Net shows superior performance against attack among the four popular appearance-based gaze estimation networks, Full-Face, Gaze-Net, CA-Net and RT-GENE. This study draws the attention of researchers in the appearance-based gaze estimation community to defense from adversarial attacks.
Repetitive Activity Counting by Sight and Sound
Mar 24, 2021



This paper strives for repetitive activity counting in videos. Different from existing works, which all analyze the visual video content only, we incorporate for the first time the corresponding sound into the repetition counting process. This benefits accuracy in challenging vision conditions such as occlusion, dramatic camera view changes, low resolution, etc. We propose a model that starts with analyzing the sight and sound streams separately. Then an audiovisual temporal stride decision module and a reliability estimation module are introduced to exploit cross-modal temporal interaction. For learning and evaluation, an existing dataset is repurposed and reorganized to allow for repetition counting with sight and sound. We also introduce a variant of this dataset for repetition counting under challenging vision conditions. Experiments demonstrate the benefit of sound, as well as the other introduced modules, for repetition counting. Our sight-only model already outperforms the state-of-the-art by itself, when we add sound, results improve notably, especially under harsh vision conditions.
Efficient Online Hyperparameter Optimization for Kernel Ridge Regression with Applications to Traffic Time Series Prediction
Nov 01, 2018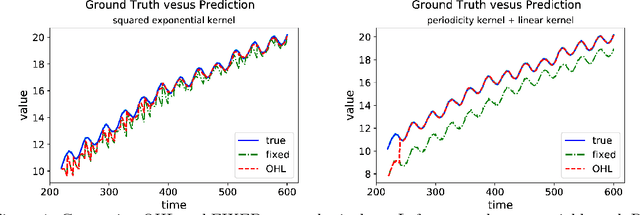
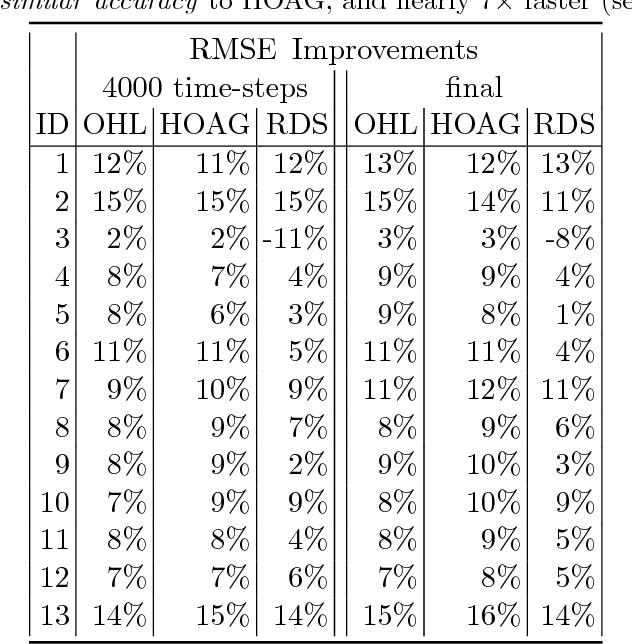
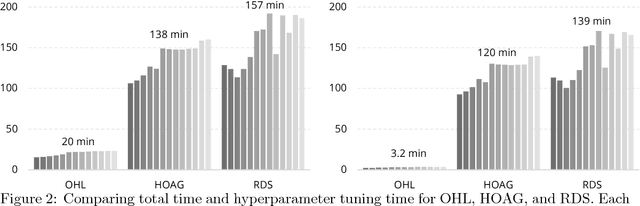
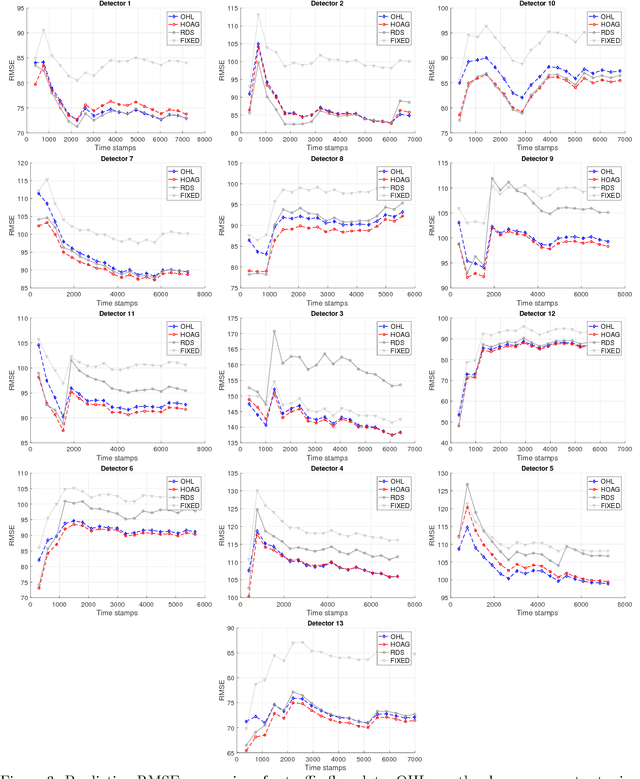
Computational efficiency is an important consideration for deploying machine learning models for time series prediction in an online setting. Machine learning algorithms adjust model parameters automatically based on the data, but often require users to set additional parameters, known as hyperparameters. Hyperparameters can significantly impact prediction accuracy. Traffic measurements, typically collected online by sensors, are serially correlated. Moreover, the data distribution may change gradually. A typical adaptation strategy is periodically re-tuning the model hyperparameters, at the cost of computational burden. In this work, we present an efficient and principled online hyperparameter optimization algorithm for Kernel Ridge regression applied to traffic prediction problems. In tests with real traffic measurement data, our approach requires as little as one-seventh of the computation time of other tuning methods, while achieving better or similar prediction accuracy.
* An extended version of "Efficient Online Hyperparameter Learning for Traffic Flow Prediction" published in The 21st IEEE International Conference on Intelligent Transportation Systems (ITSC 2018)