 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning based Multi-modal Computing with Feature Disentanglement for MRI Image Synthesis
May 06, 2021
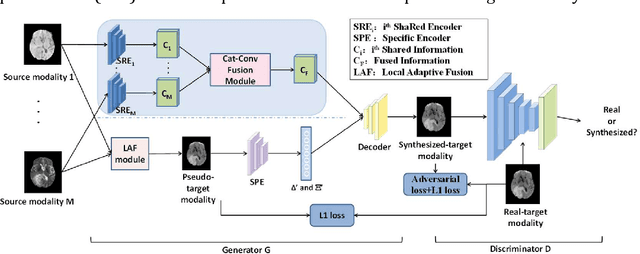
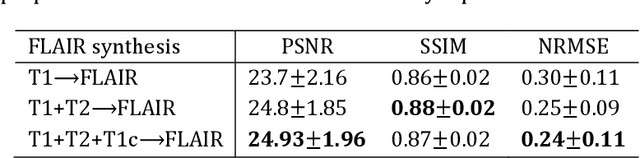
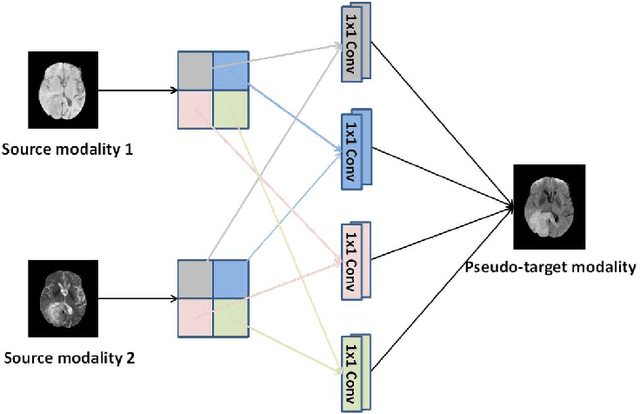
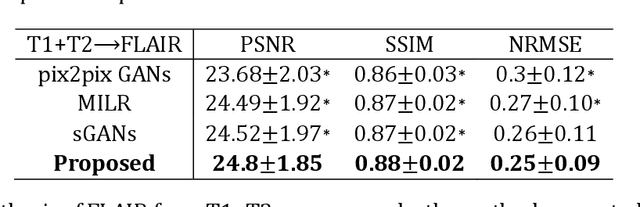
Purpose: Different Magnetic resonance imaging (MRI) modalities of the same anatomical structure are required to present different pathological information from the physical level for diagnostic needs. However, it is often difficult to obtain full-sequence MRI images of patients owing to limitations such as time consumption and high cost. The purpose of this work is to develop an algorithm for target MRI sequences prediction with high accuracy, and provide more information for clinical diagnosis. Methods: We propose a deep learning based multi-modal computing model for MRI synthesis with feature disentanglement strategy. To take full advantage of the complementary information provided by different modalities, multi-modal MRI sequences are utilized as input. Notably, the proposed approach decomposes each input modality into modality-invariant space with shared information and modality-specific space with specific information, so that features are extracted separately to effectively process the input data. Subsequently, both of them are fused through the adaptive instance normalization (AdaIN) layer in the decoder. In addition, to address the lack of specific information of the target modality in the test phase, a local adaptive fusion (LAF) module is adopted to generate a modality-like pseudo-target with specific information similar to the ground truth. Results: To evaluate the synthesis performance, we verify our method on the BRATS2015 dataset of 164 subjects. The experimental results demonstrate our approach significantly outperforms the benchmark method and other state-of-the-art medical image synthesis methods in both quantitative and qualitative measures. Compared with the pix2pixGANs method, the PSNR improves from 23.68 to 24.8. Conclusion: The proposed method could be effective in prediction of target MRI sequences, and useful for clinical diagnosis and treatment.
Open Range Pitch Tracking for Carrier Frequency Difference Estimation from HF Transmitted Speech
Mar 03, 2021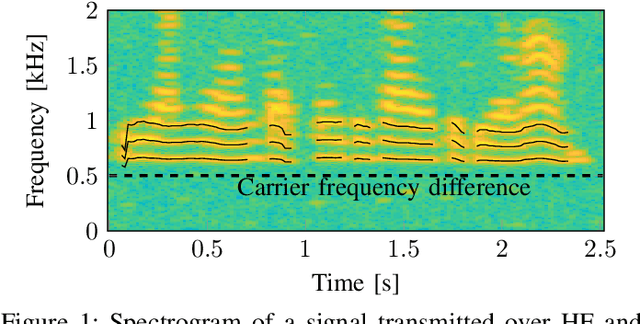
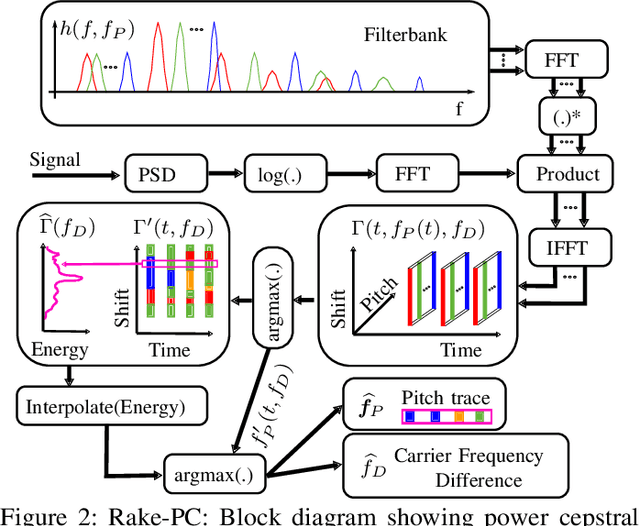
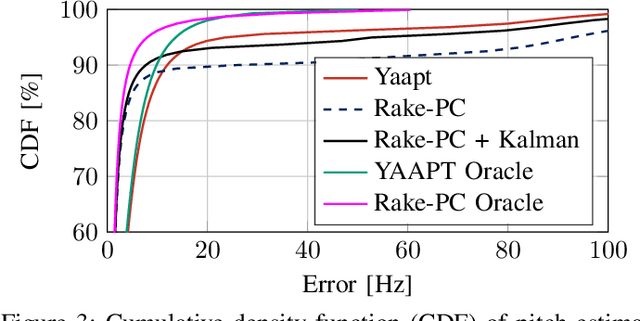
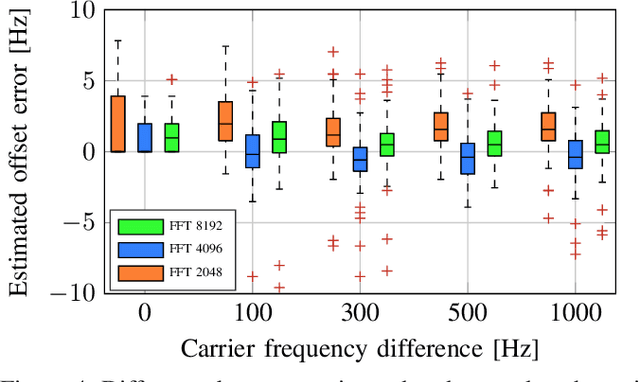
In this paper we investigate the task of detecting carrier frequency differences from demodulated single sideband signals by examining the pitch contours of the received baseband speech signal in the short-time spectral domain. From the detected pitch frequency trajectory and its harmonics a carrier frequency difference, which is caused by demodulating the radio signal with the wrong carrier frequency, can be deduced. A computationally efficient realization in the power cepstral domain is presented. The core component, i.e., the pitch tracking algorithm, is shown to perform comparably to a state of the art algorithm. The full carrier frequency difference estimation system is tested on recordings of real transmissions over HF links. A comparison with an existing approach shows improved estimation accuracy, both on short and longer speech utterances
Bayesian filtering for nonlinear stochastic systems using holonomic gradient method with integral transform
Mar 03, 2021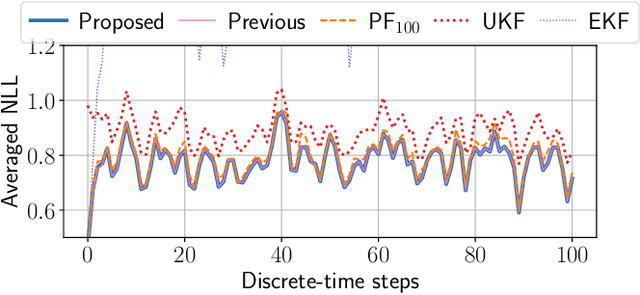
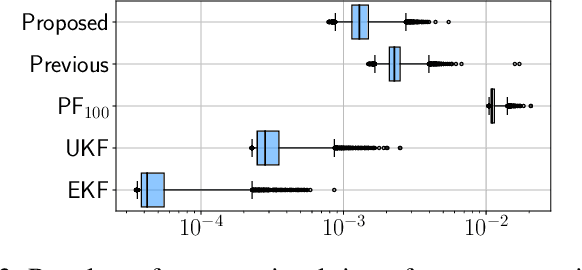
This paper proposes a symbolic-numeric Bayesian filtering method for a class of discrete-time nonlinear stochastic systems to achieve high accuracy with a relatively small online computational cost. The proposed method is based on the holonomic gradient method (HGM), which is a symbolic-numeric method to evaluate integrals efficiently depending on several parameters. By approximating the posterior probability density function (PDF) of the state as a Gaussian PDF, the update process of its mean and variance can be formulated as evaluations of several integrals that exactly take into account the nonlinearity of the system dynamics. An integral transform is used to evaluate these integrals more efficiently using the HGM than our previous method. Further, a numerical example is provided to demonstrate the efficiency of the proposed method compared to other existing methods.
Large-scale kernelized GRANGER causality to infer topology of directed graphs with applications to brain networks
Nov 16, 2020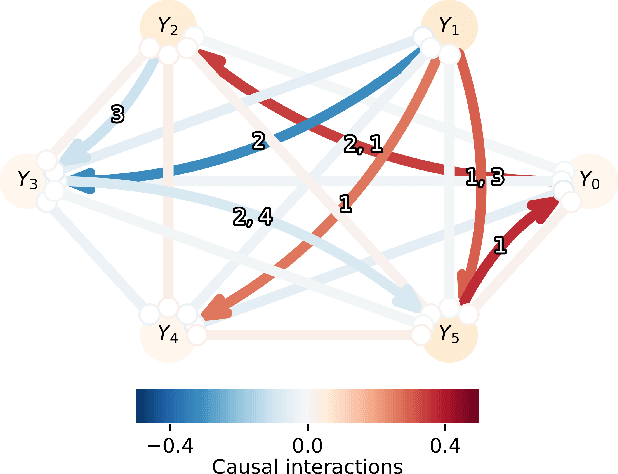
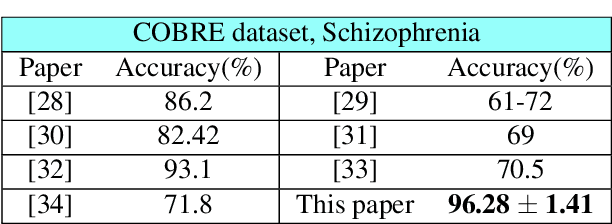
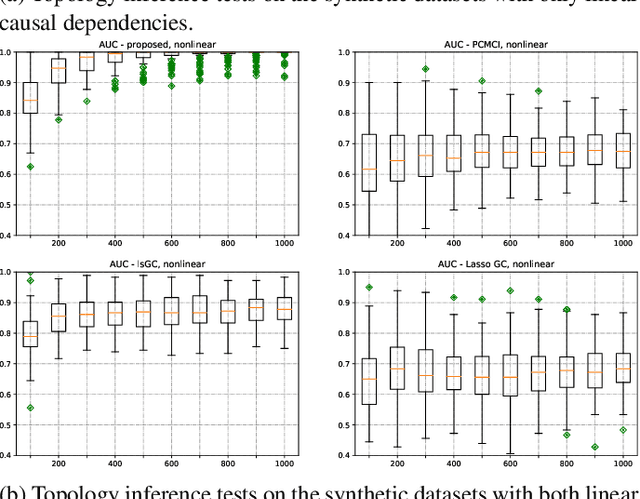
Graph topology inference of network processes with co-evolving and interacting time-series is crucial for network studies. Vector autoregressive models (VAR) are popular approaches for topology inference of directed graphs; however, in large networks with short time-series, topology estimation becomes ill-posed. The present paper proposes a novel nonlinearity-preserving topology inference method for directed networks with co-evolving nodal processes that solves the ill-posedness problem. The proposed method, large-scale kernelized Granger causality (lsKGC), uses kernel functions to transform data into a low-dimensional feature space and solves the autoregressive problem in the feature space, then finds the pre-images in the input space to infer the topology. Extensive simulations on synthetic datasets with nonlinear and linear dependencies and known ground-truth demonstrate significant improvement in the Area Under the receiver operating characteristic Curve ( AUC ) of the receiver operating characteristic for network recovery compared to existing methods. Furthermore, tests on real datasets from a functional magnetic resonance imaging (fMRI) study demonstrate 96.3 percent accuracy in diagnosis tasks of schizophrenia patients, which is the highest in the literature with only brain time-series information.
Reliably fast adversarial training via latent adversarial perturbation
Apr 04, 2021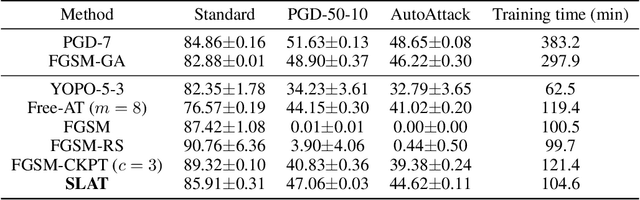
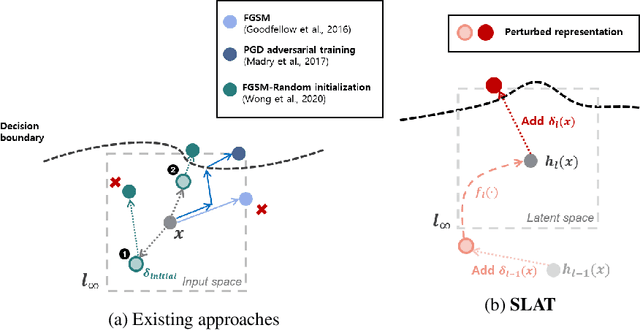
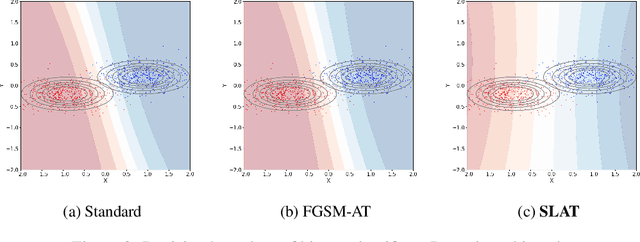

While multi-step adversarial training is widely popular as an effective defense method against strong adversarial attacks, its computational cost is notoriously expensive, compared to standard training. Several single-step adversarial training methods have been proposed to mitigate the above-mentioned overhead cost; however, their performance is not sufficiently reliable depending on the optimization setting. To overcome such limitations, we deviate from the existing input-space-based adversarial training regime and propose a single-step latent adversarial training method (SLAT), which leverages the gradients of latent representation as the latent adversarial perturbation. We demonstrate that the L1 norm of feature gradients is implicitly regularized through the adopted latent perturbation, thereby recovering local linearity and ensuring reliable performance, compared to the existing single-step adversarial training methods. Because latent perturbation is based on the gradients of the latent representations which can be obtained for free in the process of input gradients computation, the proposed method costs roughly the same time as the fast gradient sign method. Experiment results demonstrate that the proposed method, despite its structural simplicity, outperforms state-of-the-art accelerated adversarial training methods.
A Human-Centered Dynamic Scheduling Architecture for Collaborative Application
Mar 03, 2021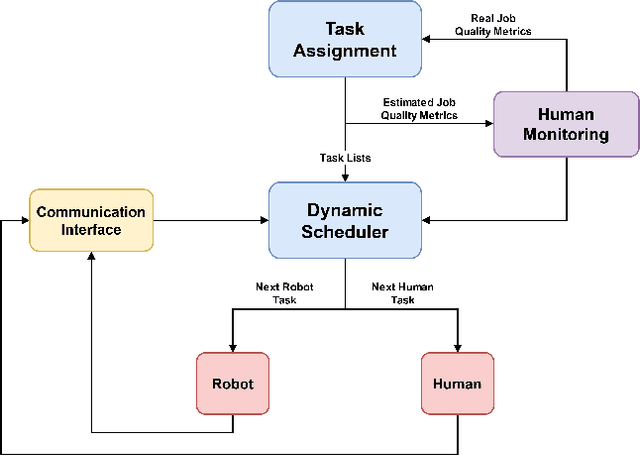
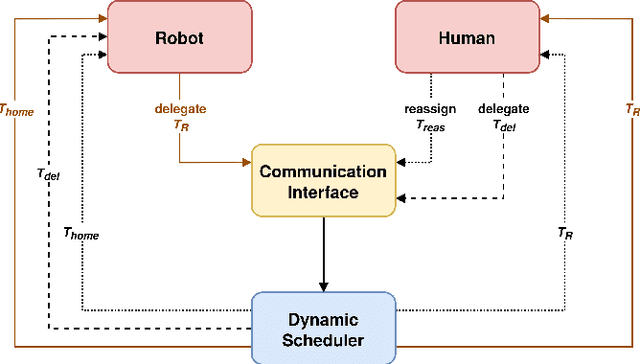

In collaborative robotic applications, human and robot have to work together during a whole shift for executing a sequence of jobs. The performance of the human robot team can be enhanced by scheduling the right tasks to the human and the robot. The scheduling should consider the task execution constraints, the variability in the task execution by the human, and the job quality of the human. Therefore, it is necessary to dynamically schedule the assigned tasks. In this paper, we propose a two-layered architecture for task allocation and scheduling in a collaborative cell. Job quality is explicitly considered during the allocation of the tasks and over a sequence of jobs. The tasks are dynamically scheduled based on the real time monitoring of the human's activities. The effectiveness of the proposed architecture is experimentally validated.
Evaluating the Effect of Longitudinal Dose and INR Data on Maintenance Warfarin Dose Predictions
May 06, 2021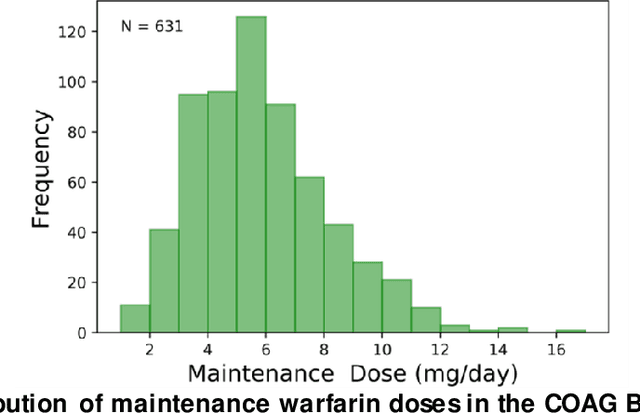
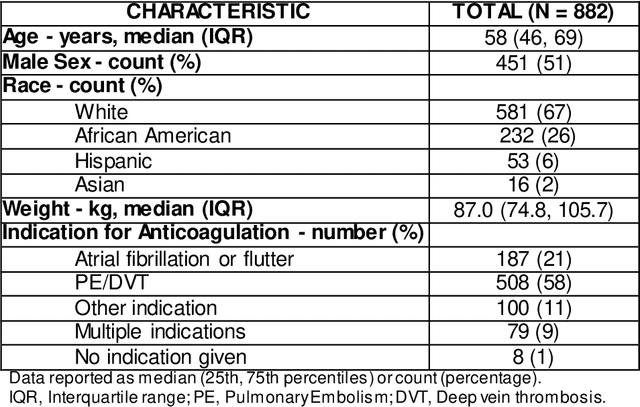
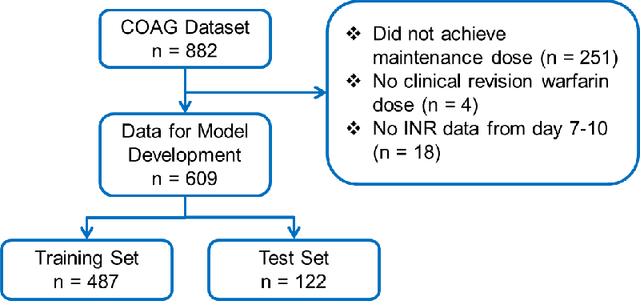
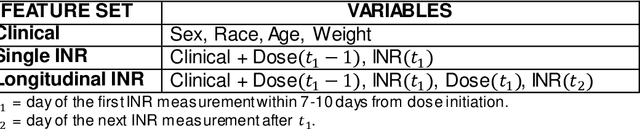
Warfarin, a commonly prescribed drug to prevent blood clots, has a highly variable individual response. Determining a maintenance warfarin dose that achieves a therapeutic blood clotting time, as measured by the international normalized ratio (INR), is crucial in preventing complications. Machine learning algorithms are increasingly being used for warfarin dosing; usually, an initial dose is predicted with clinical and genotype factors, and this dose is revised after a few days based on previous doses and current INR. Since a sequence of prior doses and INR better capture the variability in individual warfarin response, we hypothesized that longitudinal dose response data will improve maintenance dose predictions. To test this hypothesis, we analyzed a dataset from the COAG warfarin dosing study, which includes clinical data, warfarin doses and INR measurements over the study period, and maintenance dose when therapeutic INR was achieved. Various machine learning regression models to predict maintenance warfarin dose were trained with clinical factors and dosing history and INR data as features. Overall, dose revision algorithms with a single dose and INR achieved comparable performance as the baseline dose revision algorithm. In contrast, dose revision algorithms with longitudinal dose and INR data provided maintenance dose predictions that were statistically significantly much closer to the true maintenance dose. Focusing on the best performing model, gradient boosting (GB), the proportion of ideal estimated dose, i.e., defined as within $\pm$20% of the true dose, increased from the baseline (54.92%) to the GB model with the single (63.11%) and longitudinal (75.41%) INR. More accurate maintenance dose predictions with longitudinal dose response data can potentially achieve therapeutic INR faster, reduce drug-related complications and improve patient outcomes with warfarin therapy.
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Mar 27, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
Combining GANs and AutoEncoders for Efficient Anomaly Detection
Nov 16, 2020
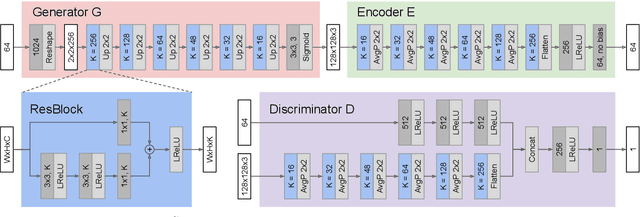
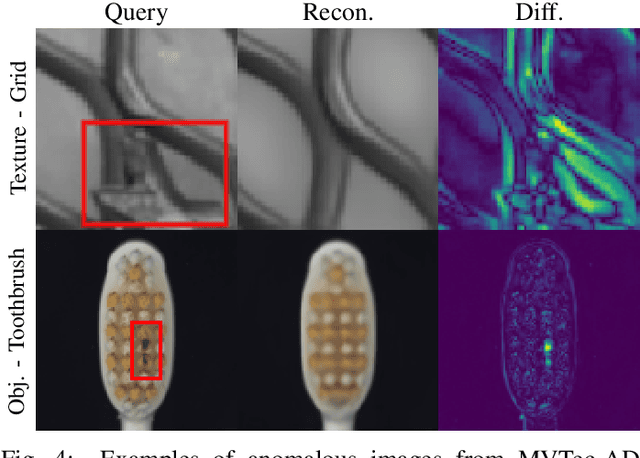
Deep learned models are now largely adopted in different fields, and they generally provide superior performances with respect to classical signal-based approaches. Notwithstanding this, their actual reliability when working in an unprotected environment is far enough to be proven. In this work, we consider a novel deep neural network architecture, named Neural Ordinary Differential Equations (N-ODE), that is getting particular attention due to an attractive property --- a test-time tunable trade-off between accuracy and efficiency. This paper analyzes the robustness of N-ODE image classifiers when faced against a strong adversarial attack and how its effectiveness changes when varying such a tunable trade-off. We show that adversarial robustness is increased when the networks operate in different tolerance regimes during test time and training time. On this basis, we propose a novel adversarial detection strategy for N-ODE nets based on the randomization of the adaptive ODE solver tolerance. Our evaluation performed on standard image classification benchmarks shows that our detection technique provides high rejection of adversarial examples while maintaining most of the original samples under white-box attacks and zero-knowledge adversaries.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
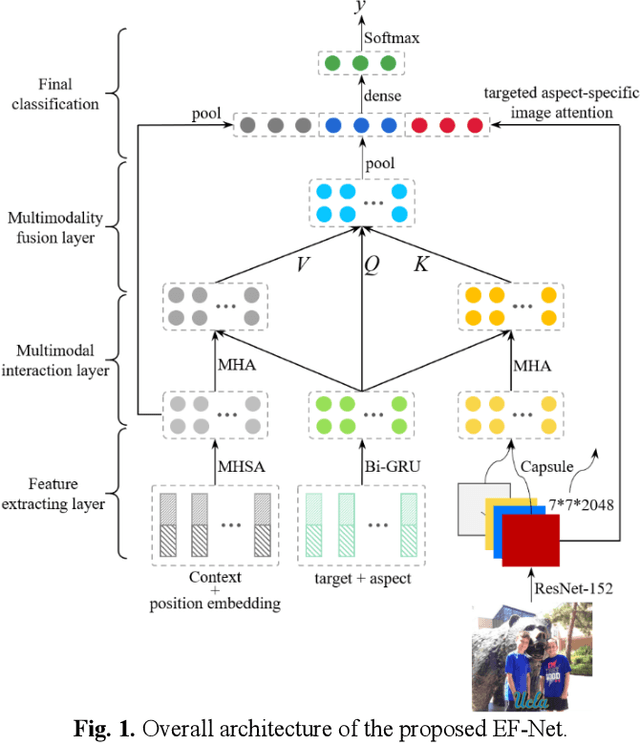
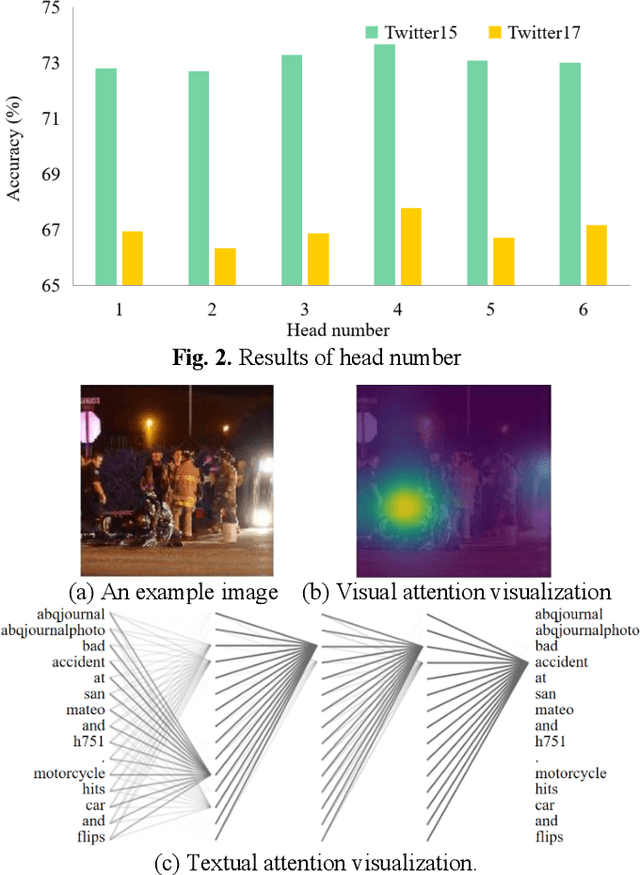
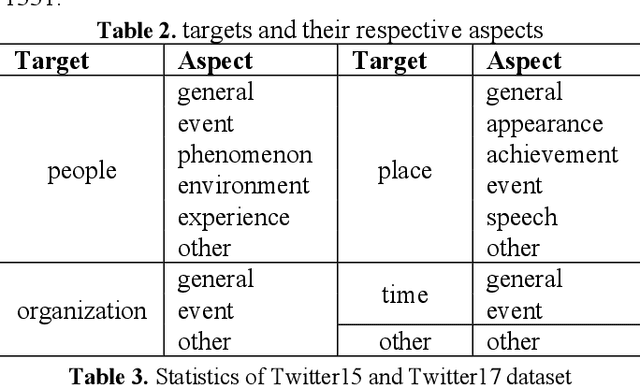
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.