 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain Adaptive Monocular Depth Estimation With Semantic Information
Apr 12, 2021
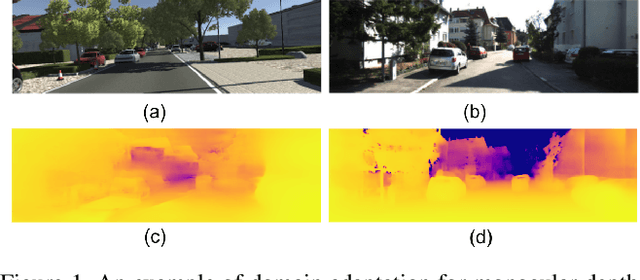
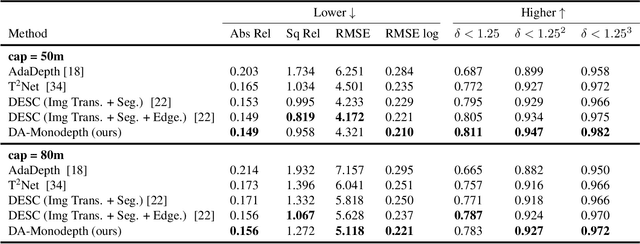
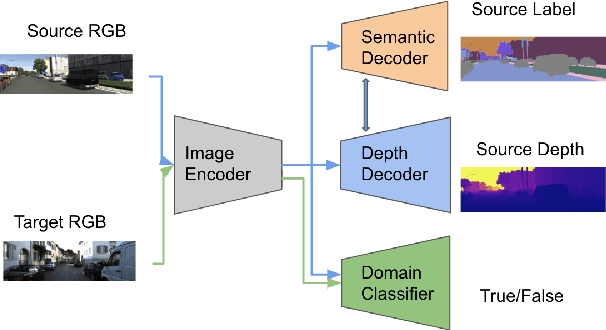
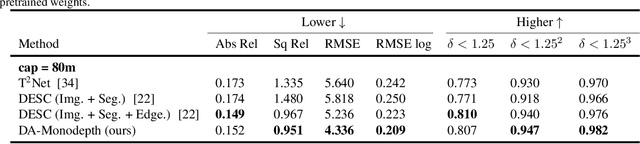
The advent of deep learning has brought an impressive advance to monocular depth estimation, e.g., supervised monocular depth estimation has been thoroughly investigated. However, the large amount of the RGB-to-depth dataset may not be always available since collecting accurate depth ground truth according to the RGB image is a time-consuming and expensive task. Although the network can be trained on an alternative dataset to overcome the dataset scale problem, the trained model is hard to generalize to the target domain due to the domain discrepancy. Adversarial domain alignment has demonstrated its efficacy to mitigate the domain shift on simple image classification tasks in previous works. However, traditional approaches hardly handle the conditional alignment as they solely consider the feature map of the network. In this paper, we propose an adversarial training model that leverages semantic information to narrow the domain gap. Based on the experiments conducted on the datasets for the monocular depth estimation task including KITTI and Cityscapes, the proposed compact model achieves state-of-the-art performance comparable to complex latest models and shows favorable results on boundaries and objects at far distances.
Dispersion-Minimizing Motion Primitives for Search-Based Motion Planning
Mar 26, 2021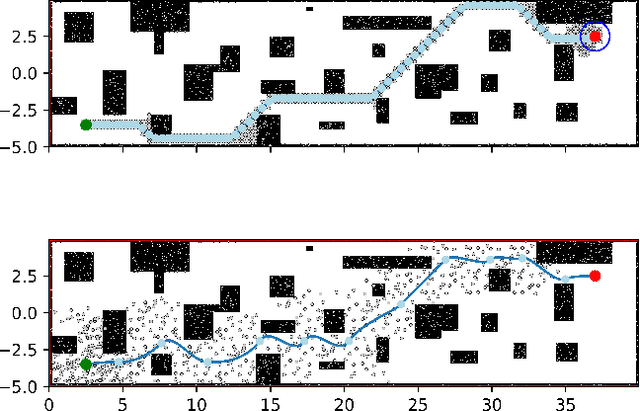
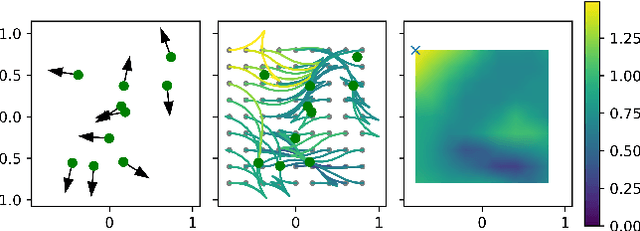

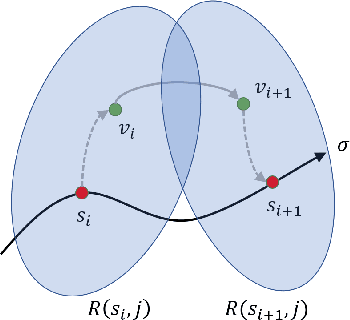
Search-based planning with motion primitives is a powerful motion planning technique that can provide dynamic feasibility, optimality, and real-time computation times on size, weight, and power-constrained platforms in unstructured environments. However, optimal design of the motion planning graph, while crucial to the performance of the planner, has not been a main focus of prior work. This paper proposes to address this by introducing a method of choosing vertices and edges in a motion primitive graph that is grounded in sampling theory and leads to theoretical guarantees on planner completeness. By minimizing dispersion of the graph vertices in the metric space induced by trajectory cost, we optimally cover the space of feasible trajectories with our motion primitive graph. In comparison with baseline motion primitives defined by uniform input space sampling, our motion primitive graphs have lower dispersion, find a plan with fewer iterations of the graph search, and have only one parameter to tune.
DA-DGCEx: Ensuring Validity of Deep Guided Counterfactual Explanations With Distribution-Aware Autoencoder Loss
Apr 20, 2021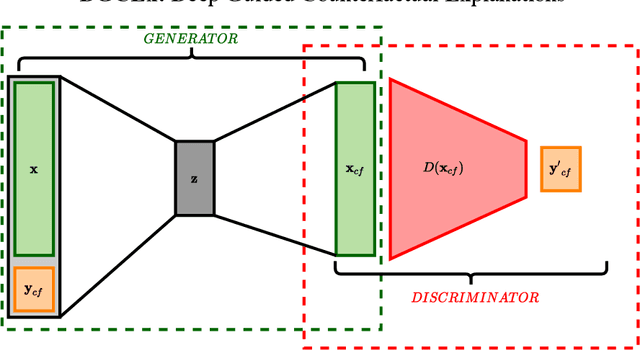
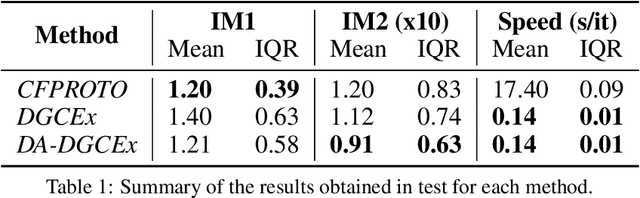
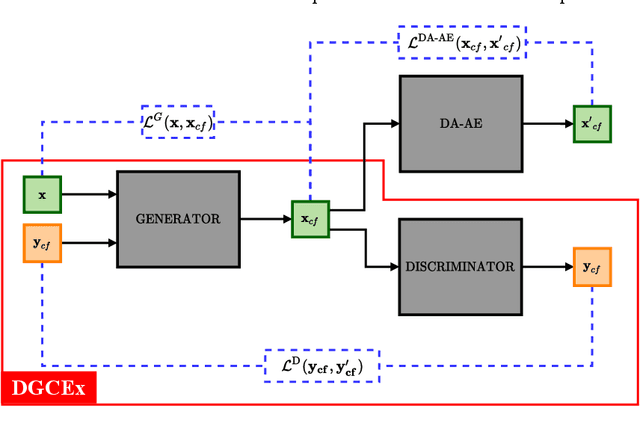
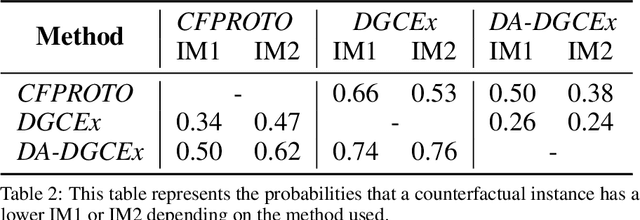
Deep Learning has become a very valuable tool in different fields, and no one doubts the learning capacity of these models. Nevertheless, since Deep Learning models are often seen as black boxes due to their lack of interpretability, there is a general mistrust in their decision-making process. To find a balance between effectiveness and interpretability, Explainable Artificial Intelligence (XAI) is gaining popularity in recent years, and some of the methods within this area are used to generate counterfactual explanations. The process of generating these explanations generally consists of solving an optimization problem for each input to be explained, which is unfeasible when real-time feedback is needed. To speed up this process, some methods have made use of autoencoders to generate instant counterfactual explanations. Recently, a method called Deep Guided Counterfactual Explanations (DGCEx) has been proposed, which trains an autoencoder attached to a classification model, in order to generate straightforward counterfactual explanations. However, this method does not ensure that the generated counterfactual instances are close to the data manifold, so unrealistic counterfactual instances may be generated. To overcome this issue, this paper presents Distribution Aware Deep Guided Counterfactual Explanations (DA-DGCEx), which adds a term to the DGCEx cost function that penalizes out of distribution counterfactual instances.
Efficient Transformer based Method for Remote Sensing Image Change Detection
Feb 27, 2021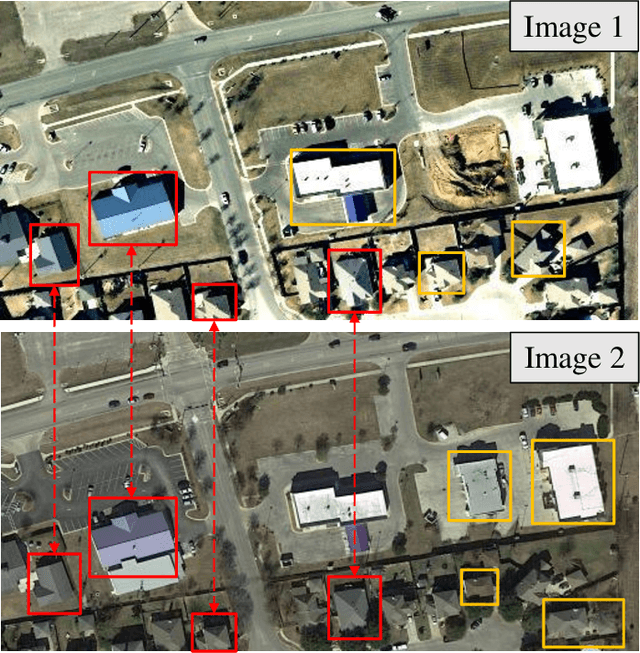
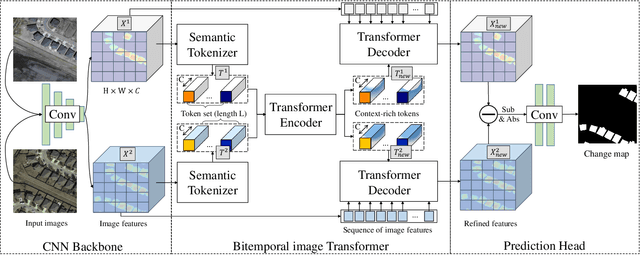
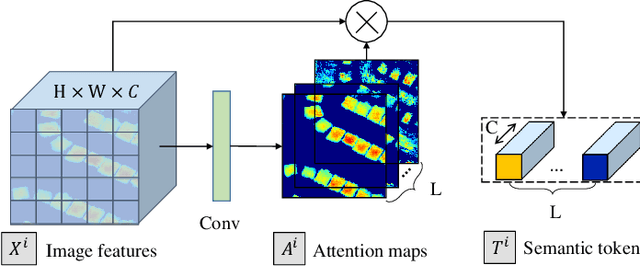
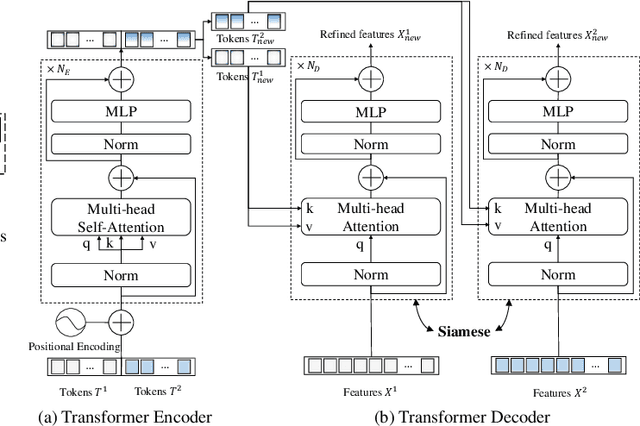
Modern change detection (CD) has achieved remarkable success by the powerful discriminative ability of deep convolutions. However, high-resolution remote sensing CD remains challenging due to the complexity of objects in the scene. The objects with the same semantic concept show distinct spectral behaviors at different times and different spatial locations. Modeling interactions between global semantic concepts is critical for change recognition. Most recent change detection pipelines using pure convolutions are still struggling to relate long-range concepts in space-time. Non-local self-attention approaches show promising performance via modeling dense relations among pixels, yet are computationally inefficient. In this paper, we propose a bitemporal image transformer (BiT) to efficiently and effectively model contexts within the spatial-temporal domain. Our intuition is that the high-level concepts of the change of interest can be represented by a few visual words, i.e., semantic tokens. To achieve this, we express the bitemporal image into a few tokens, and use a transformer encoder to model contexts in the compact token-based space-time. The learned context-rich tokens are then feedback to the pixel-space for refining the original features via a transformer decoder. We incorporate BiT in a deep feature differencing-based CD framework. Extensive experiments on three public CD datasets demonstrate the effectiveness and efficiency of the proposed method. Notably, our BiT-based model significantly outperforms the purely convolutional baseline using only 3 times lower computational costs and model parameters. Based on a naive backbone (ResNet18) without sophisticated structures (e.g., FPN, UNet), our model surpasses several state-of-the-art CD methods, including better than two recent attention-based methods in terms of efficiency and accuracy. Our code will be made public.
PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
May 09, 2021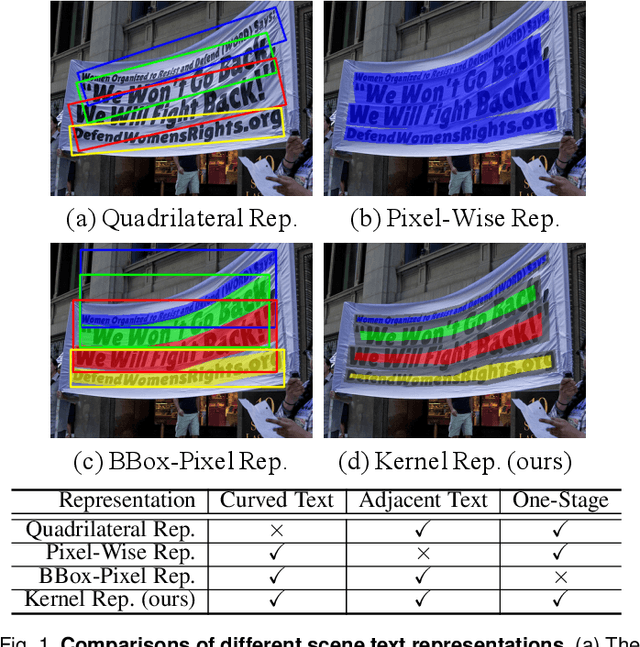
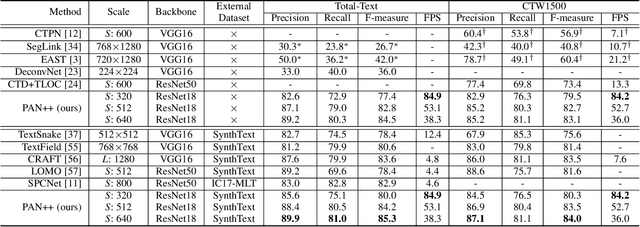
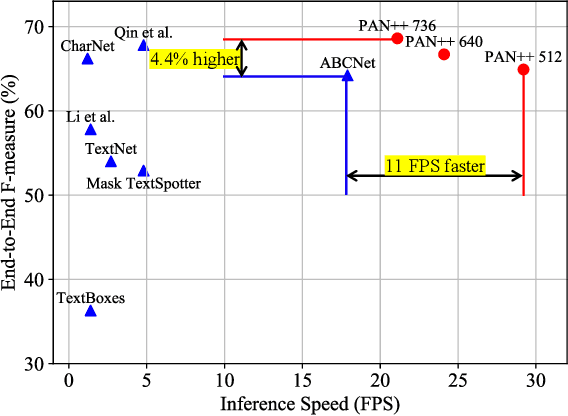
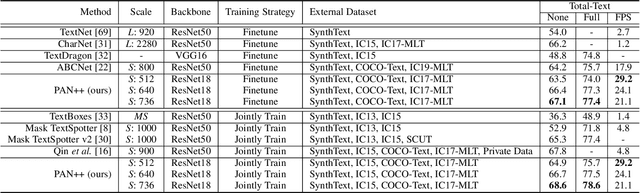
Scene text detection and recognition have been well explored in the past few years. Despite the progress, efficient and accurate end-to-end spotting of arbitrarily-shaped text remains challenging. In this work, we propose an end-to-end text spotting framework, termed PAN++, which can efficiently detect and recognize text of arbitrary shapes in natural scenes. PAN++ is based on the kernel representation that reformulates a text line as a text kernel (central region) surrounded by peripheral pixels. By systematically comparing with existing scene text representations, we show that our kernel representation can not only describe arbitrarily-shaped text but also well distinguish adjacent text. Moreover, as a pixel-based representation, the kernel representation can be predicted by a single fully convolutional network, which is very friendly to real-time applications. Taking the advantages of the kernel representation, we design a series of components as follows: 1) a computationally efficient feature enhancement network composed of stacked Feature Pyramid Enhancement Modules (FPEMs); 2) a lightweight detection head cooperating with Pixel Aggregation (PA); and 3) an efficient attention-based recognition head with Masked RoI. Benefiting from the kernel representation and the tailored components, our method achieves high inference speed while maintaining competitive accuracy. Extensive experiments show the superiority of our method. For example, the proposed PAN++ achieves an end-to-end text spotting F-measure of 64.9 at 29.2 FPS on the Total-Text dataset, which significantly outperforms the previous best method. Code will be available at: https://git.io/PAN.
Robot Program Parameter Inference via Differentiable Shadow Program Inversion
Mar 26, 2021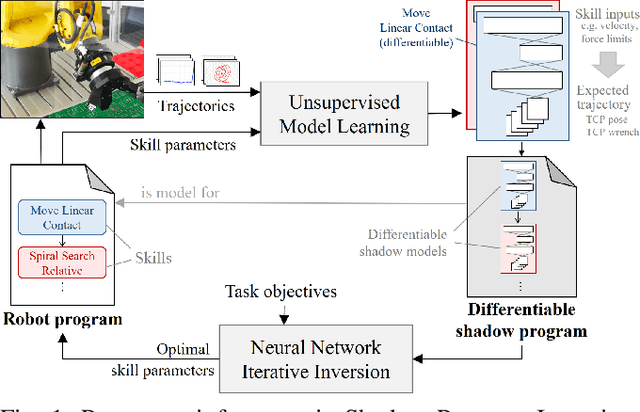
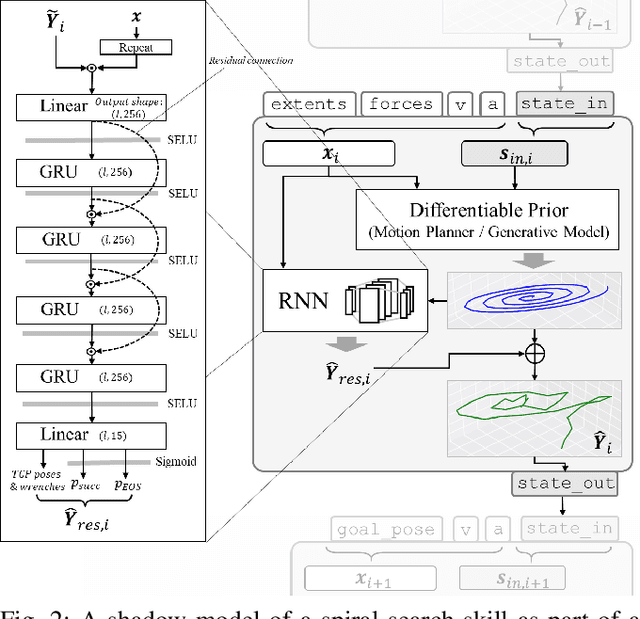
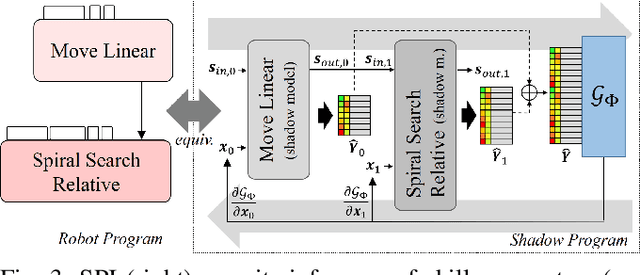
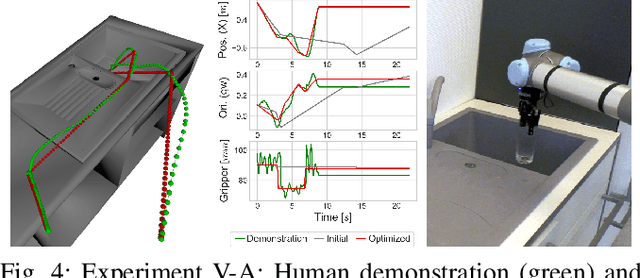
Challenging manipulation tasks can be solved effectively by combining individual robot skills, which must be parameterized for the concrete physical environment and task at hand. This is time-consuming and difficult for human programmers, particularly for force-controlled skills. To this end, we present Shadow Program Inversion (SPI), a novel approach to infer optimal skill parameters directly from data. SPI leverages unsupervised learning to train an auxiliary differentiable program representation ("shadow program") and realizes parameter inference via gradient-based model inversion. Our method enables the use of efficient first-order optimizers to infer optimal parameters for originally non-differentiable skills, including many skill variants currently used in production. SPI zero-shot generalizes across task objectives, meaning that shadow programs do not need to be retrained to infer parameters for different task variants. We evaluate our methods on three different robots and skill frameworks in industrial and household scenarios. Code and examples are available at https://innolab.artiminds.com/icra2021.
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 12, 2021
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
Apr 20, 2021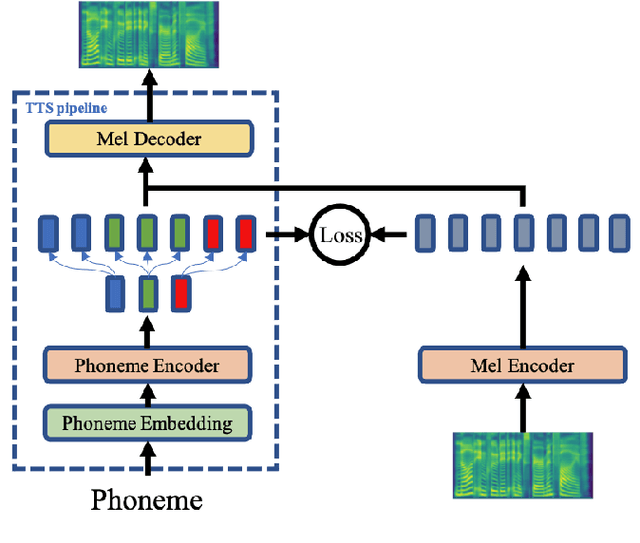
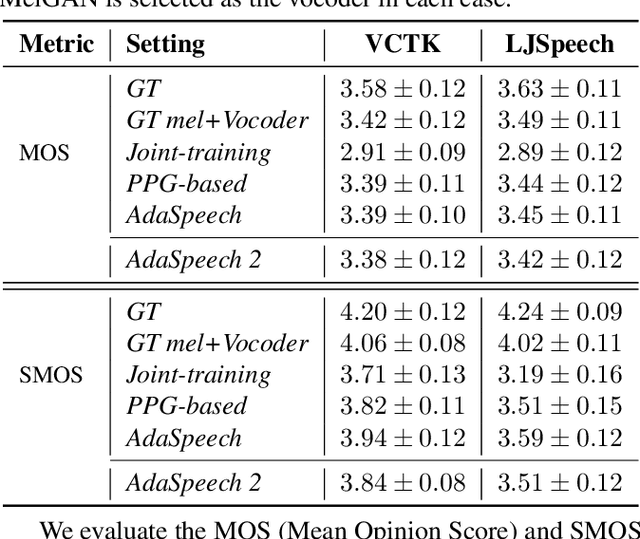
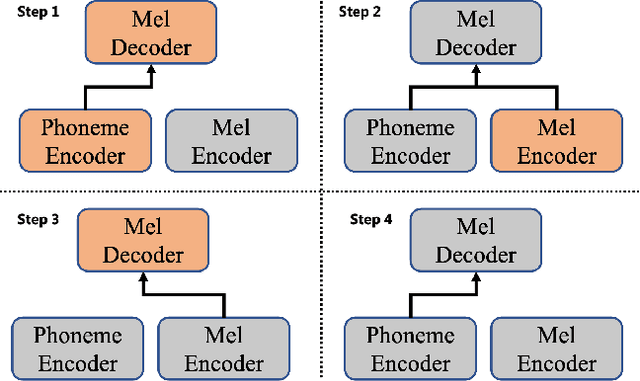

Text to speech (TTS) is widely used to synthesize personal voice for a target speaker, where a well-trained source TTS model is fine-tuned with few paired adaptation data (speech and its transcripts) on this target speaker. However, in many scenarios, only untranscribed speech data is available for adaptation, which brings challenges to the previous TTS adaptation pipelines (e.g., AdaSpeech). In this paper, we develop AdaSpeech 2, an adaptive TTS system that only leverages untranscribed speech data for adaptation. Specifically, we introduce a mel-spectrogram encoder to a well-trained TTS model to conduct speech reconstruction, and at the same time constrain the output sequence of the mel-spectrogram encoder to be close to that of the original phoneme encoder. In adaptation, we use untranscribed speech data for speech reconstruction and only fine-tune the TTS decoder. AdaSpeech 2 has two advantages: 1) Pluggable: our system can be easily applied to existing trained TTS models without re-training. 2) Effective: our system achieves on-par voice quality with the transcribed TTS adaptation (e.g., AdaSpeech) with the same amount of untranscribed data, and achieves better voice quality than previous untranscribed adaptation methods. Synthesized speech samples can be found at https://speechresearch.github.io/adaspeech2/.
Feasibility Study on Intra-Grid Location Estimation Using Power ENF Signals
May 03, 2021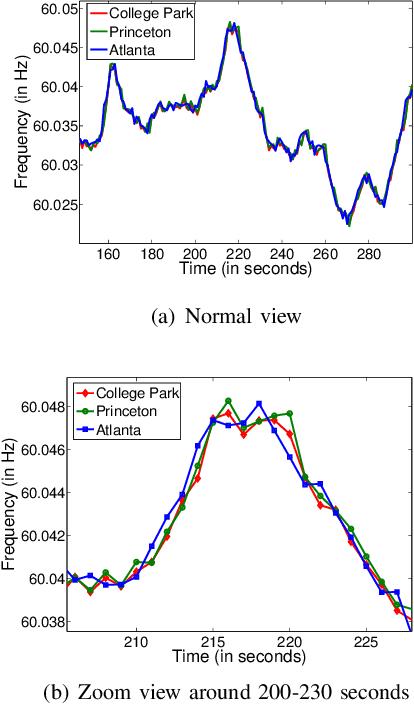
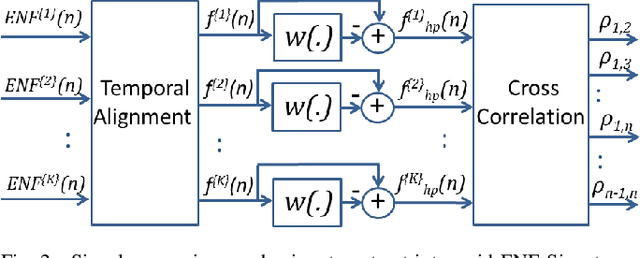
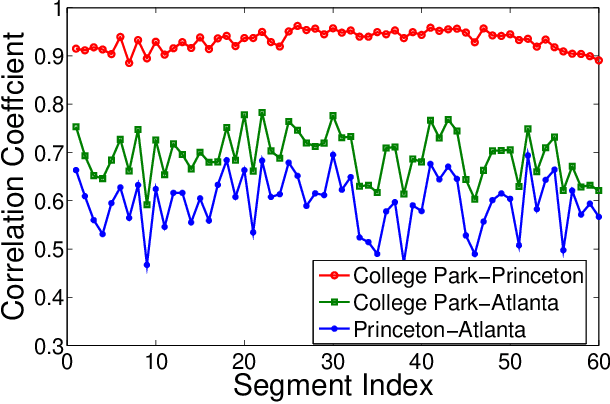
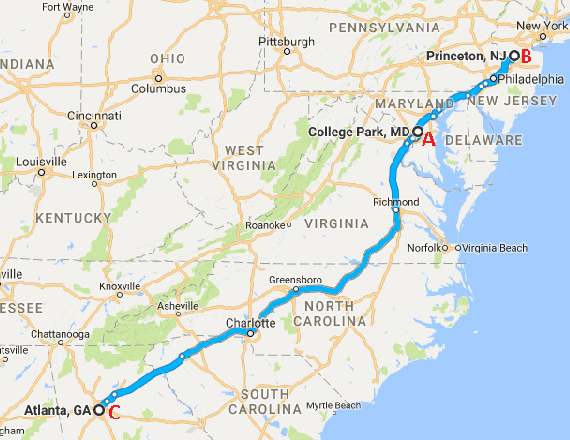
The Electric Network Frequency (ENF) is a signature of power distribution networks that can be captured by multimedia recordings made in areas where there is electrical activity. This has led to an emergence of several forensic applications based on the use of the ENF signature. Examples of such applications include estimating or verifying the time-of-recording of a media signal and inferring the power grid associated with the location in which the media signal was recorded. In this paper, we carry out a feasibility study to examine the possibility of using embedded ENF traces to pinpoint the location-of-recording of a signal within a power grid. In this study, we demonstrate that it is possible to pinpoint the location-of-recording to a certain geographical resolution using power signal recordings containing strong ENF traces. To this purpose, a high-passed version of an ENF signal is extracted and it is demonstrated that the correlation between two such signals, extracted from recordings made in different geographical locations within the same grid, decreases as the distance between the recording locations increases. We harness this property of correlation in the ENF signals to propose trilateration based localization methods, which pinpoint the unknown location of a recording while using some known recording locations as anchor locations. We also discuss the challenges that need to be overcome in order to extend this work to using ENF traces in noisier audio/video recordings for such fine localization purposes.
Model-aided Deep Reinforcement Learning for Sample-efficient UAV Trajectory Design in IoT Networks
May 03, 2021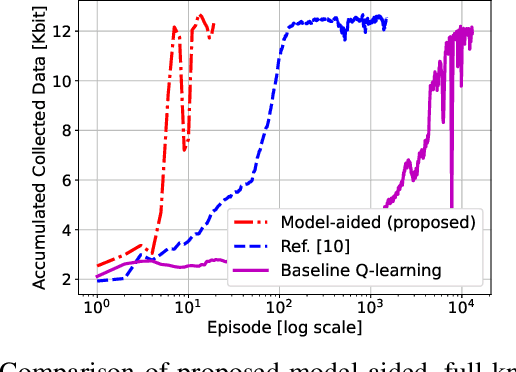
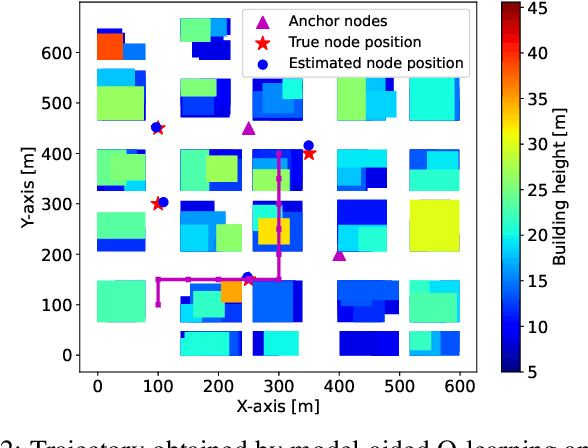
Deep Reinforcement Learning (DRL) is gaining attention as a potential approach to design trajectories for autonomous unmanned aerial vehicles (UAV) used as flying access points in the context of cellular or Internet of Things (IoT) connectivity. DRL solutions offer the advantage of on-the-go learning hence relying on very little prior contextual information. A corresponding drawback however lies in the need for many learning episodes which severely restricts the applicability of such approach in real-world time- and energy-constrained missions. Here, we propose a model-aided deep Q-learning approach that, in contrast to previous work, considerably reduces the need for extensive training data samples, while still achieving the overarching goal of DRL, i.e to guide a battery-limited UAV towards an efficient data harvesting trajectory, without prior knowledge of wireless channel characteristics and limited knowledge of wireless node locations. The key idea consists in using a small subset of nodes as anchors (i.e. with known location) and learning a model of the propagation environment while implicitly estimating the positions of regular nodes. Interaction with the model allows us to train a deep Q-network (DQN) to approximate the optimal UAV control policy. We show that in comparison with standard DRL approaches, the proposed model-aided approach requires at least one order of magnitude less training data samples to reach identical data collection performance, hence offering a first step towards making DRL a viable solution to the problem.