 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advances in deep learning methods for pavement surface crack detection and identification with visible light visual images
Dec 29, 2020
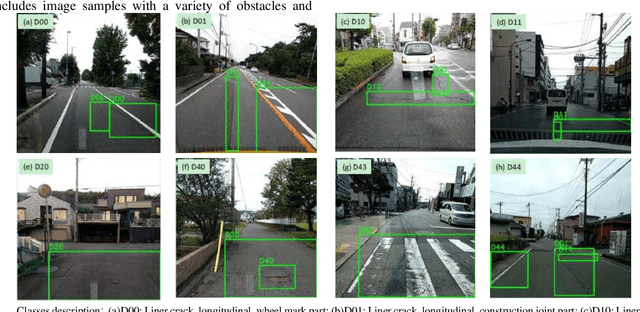
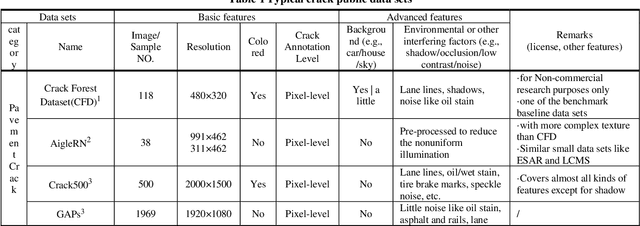


Compared to NDT and health monitoring method for cracks in engineering structures, surface crack detection or identification based on visible light images is non-contact, with the advantages of fast speed, low cost and high precision. Firstly, typical pavement (concrete also) crack public data sets were collected, and the characteristics of sample images as well as the random variable factors, including environmental, noise and interference etc., were summarized. Subsequently, the advantages and disadvantages of three main crack identification methods (i.e., hand-crafted feature engineering, machine learning, deep learning) were compared. Finally, from the aspects of model architecture, testing performance and predicting effectiveness, the development and progress of typical deep learning models, including self-built CNN, transfer learning(TL) and encoder-decoder(ED), which can be easily deployed on embedded platform, were reviewed. The benchmark test shows that: 1) It has been able to realize real-time pixel-level crack identification on embedded platform: the entire crack detection average time cost of an image sample is less than 100ms, either using the ED method (i.e., FPCNet) or the TL method based on InceptionV3. It can be reduced to less than 10ms with TL method based on MobileNet (a lightweight backbone base network). 2) In terms of accuracy, it can reach over 99.8% on CCIC which is easily identified by human eyes. On SDNET2018, some samples of which are difficult to be identified, FPCNet can reach 97.5%, while TL method is close to 96.1%. To the best of our knowledge, this paper for the first time comprehensively summarizes the pavement crack public data sets, and the performance and effectiveness of surface crack detection and identification deep learning methods for embedded platform, are reviewed and evaluated.
Performance Prediction for Convolutional Neural Networks in Edge Devices
Oct 21, 2020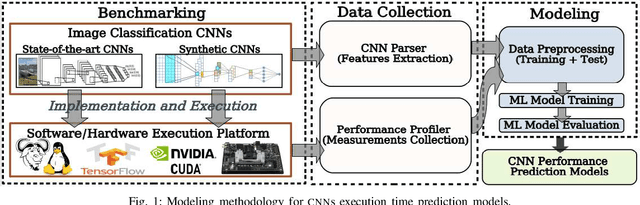
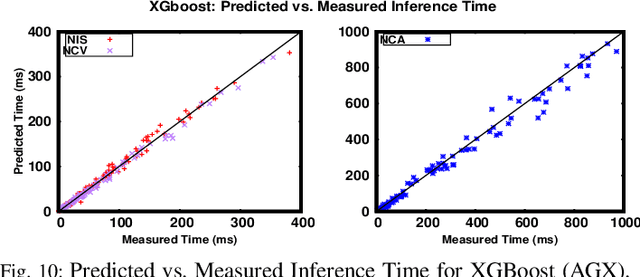
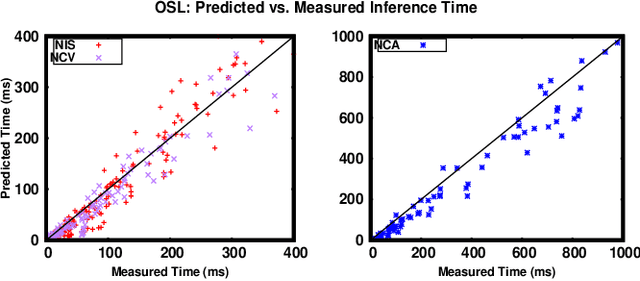
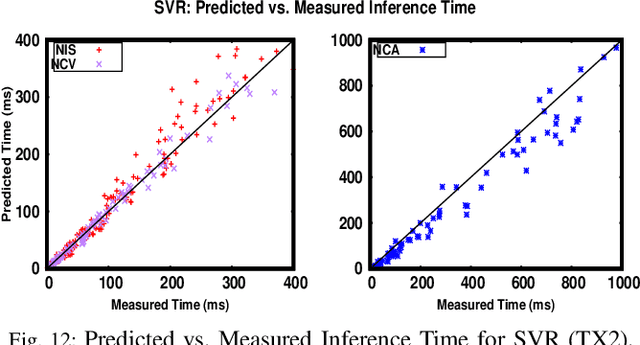
Running Convolutional Neural Network (CNN) based applications on edge devices near the source of data can meet the latency and privacy challenges. However due to their reduced computing resources and their energy constraints, these edge devices can hardly satisfy CNN needs in processing and data storage. For these platforms, choosing the CNN with the best trade-off between accuracy and execution time while respecting Hardware constraints is crucial. In this paper, we present and compare five (5) of the widely used Machine Learning based methods for execution time prediction of CNNs on two (2) edge GPU platforms. For these 5 methods, we also explore the time needed for their training and tuning their corresponding hyperparameters. Finally, we compare times to run the prediction models on different platforms. The utilization of these methods will highly facilitate design space exploration by providing quickly the best CNN on a target edge GPU. Experimental results show that eXtreme Gradient Boosting (XGBoost) provides a less than 14.73% average prediction error even for unexplored and unseen CNN models' architectures. Random Forest (RF) depicts comparable accuracy but needs more effort and time to be trained. The other 3 approaches (OLS, MLP and SVR) are less accurate for CNN performances estimation.
DLRRMS: Deep Learning based Respiratory Rate Monitoring System using Mobile Robots and Edges
Nov 17, 2020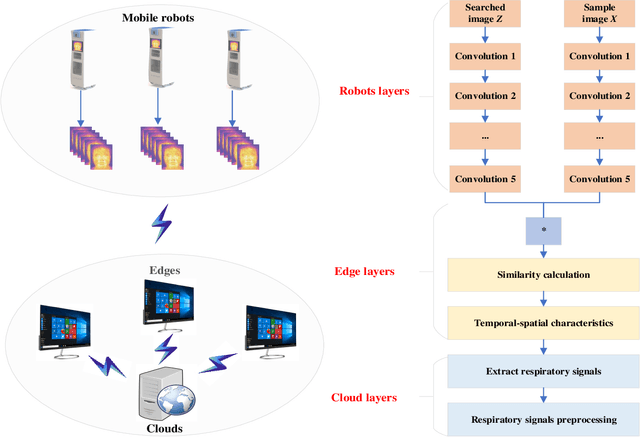
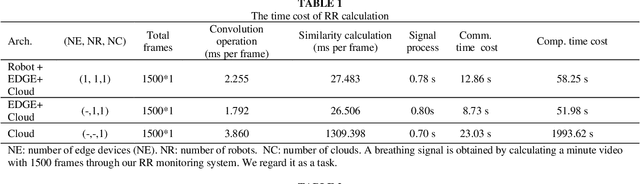
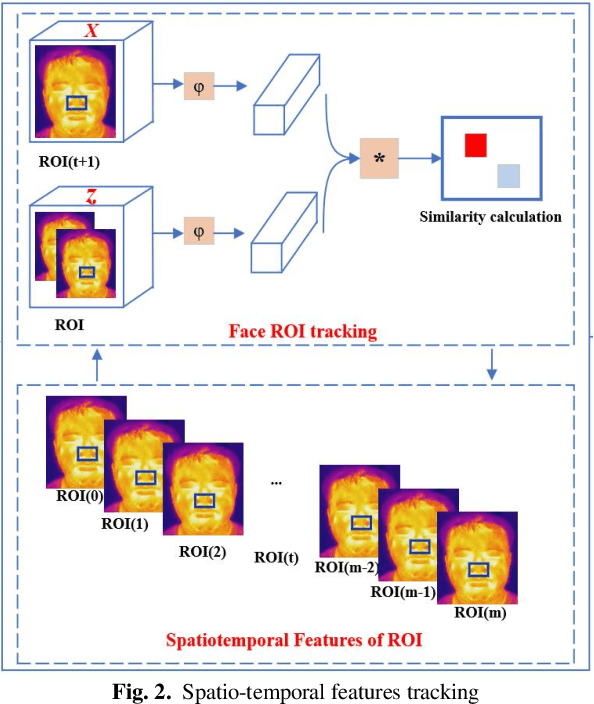
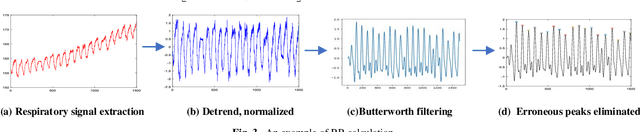
Deep learning technology has been widely used in edges. However, the limited storage and computing resources of mobile devices cannot meet the real-time requirements of deep neural network computing. In this paper, we propose a safer respiratory rate monitoring system using a three-tier architecture: robot layers, edge layers, and cloud layers. We decompose the task into a three-tier architecture of a lightweight network according to the computing resources of different devices, including mobile robots, edges, and clouds. We deploy feature extraction tasks, Spatio-temporal feature tracking tasks, and signal extraction and preprocessing tasks to robot layers, edge layers, and cloud layers, respectively. We have deployed this non-contact respiratory monitoring system in the Second Affiliated Hospital of the Anhui Medical University of China. Experimental results show that the proposed approach in this paper significantly outperforms other approaches. It is supported by the computation time cost of robot+edge+cloud architecture, which are 2.26 ms per frame, 27.48 ms per frame, 0.78 seconds for processing one-minute length respiratory signals, respectively. Furthermore, the computation time costs of using the proposed system to calculate the respiratory rate are less than that of edge+cloud architecture and cloud architecture.
Panoptic-PolarNet: Proposal-free LiDAR Point Cloud Panoptic Segmentation
Mar 27, 2021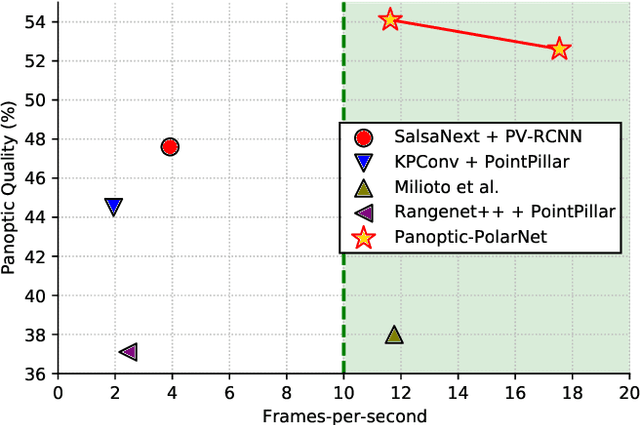
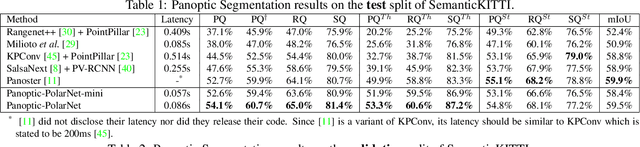
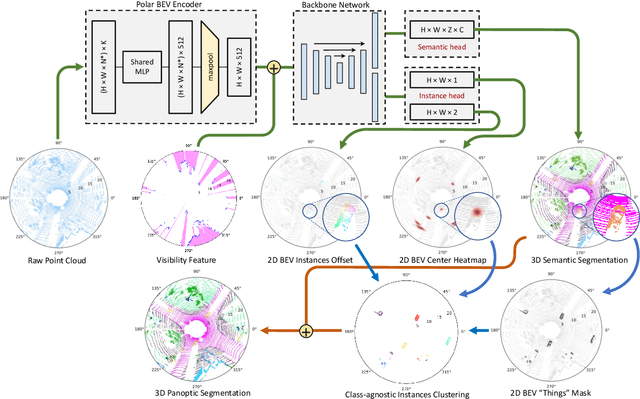
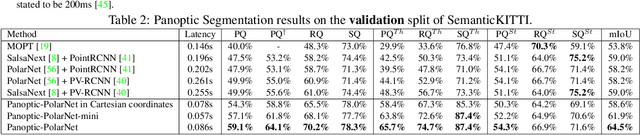
Panoptic segmentation presents a new challenge in exploiting the merits of both detection and segmentation, with the aim of unifying instance segmentation and semantic segmentation in a single framework. However, an efficient solution for panoptic segmentation in the emerging domain of LiDAR point cloud is still an open research problem and is very much under-explored. In this paper, we present a fast and robust LiDAR point cloud panoptic segmentation framework, referred to as Panoptic-PolarNet. We learn both semantic segmentation and class-agnostic instance clustering in a single inference network using a polar Bird's Eye View (BEV) representation, enabling us to circumvent the issue of occlusion among instances in urban street scenes. To improve our network's learnability, we also propose an adapted instance augmentation technique and a novel adversarial point cloud pruning method. Our experiments show that Panoptic-PolarNet outperforms the baseline methods on SemanticKITTI and nuScenes datasets with an almost real-time inference speed. Panoptic-PolarNet achieved 54.1% PQ in the public SemanticKITTI panoptic segmentation leaderboard and leading performance for the validation set of nuScenes.
Orientation to Pose: Continuum Robots Shape Sensing Based on Piecewise Polynomial Curvature Model
Mar 09, 2021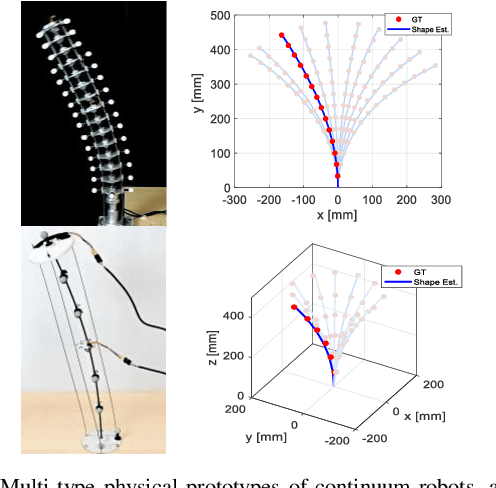
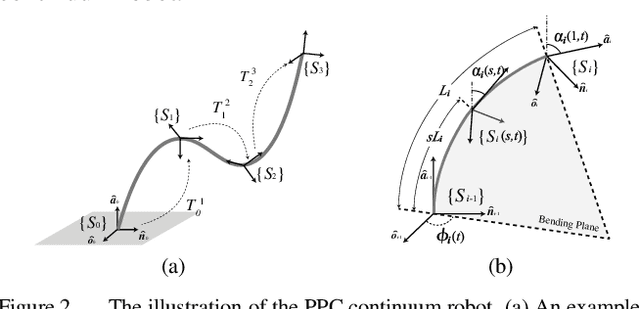
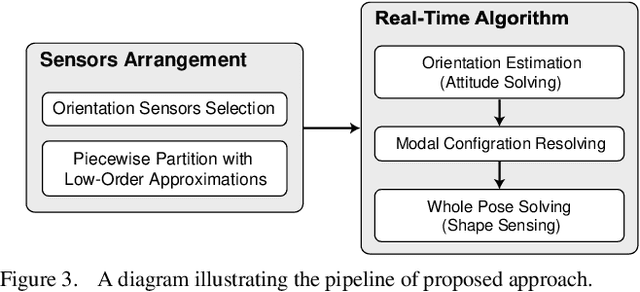
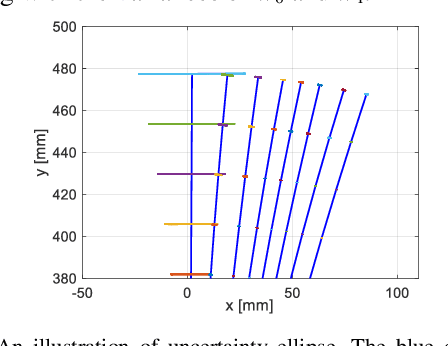
Continuum robots are typically slender and flexible with infinite freedoms in theory, which poses a challenge for their control and application. The shape sensing of continuum robots is vital to realise accuracy control. This letter proposed a novel general real-time shape sensing framework of continuum robots based on the piecewise polynomial curvature (PPC) kinematics model. We illustrate the coupling between orientation and position at any given location of the continuum robots. Further, the coupling relation could be bridged by the PPC kinematics. Therefore, we propose to estimate the shape of continuum robots through orientation estimation, using the off-the-shelf orientation sensors, e.g., IMUs, mounted on certain locations. The approach gives a valuable framework to the shape sensing of continuum robots, universality, accuracy and convenience. The accuracy of the general approach is verified in the experiments of multi-type physical prototypes.
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 18, 2021
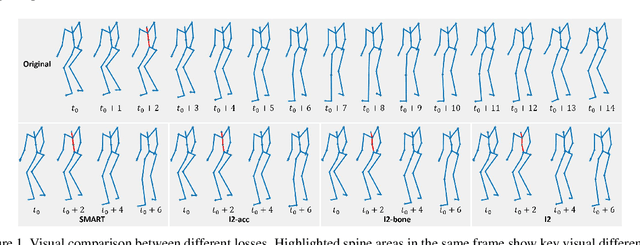
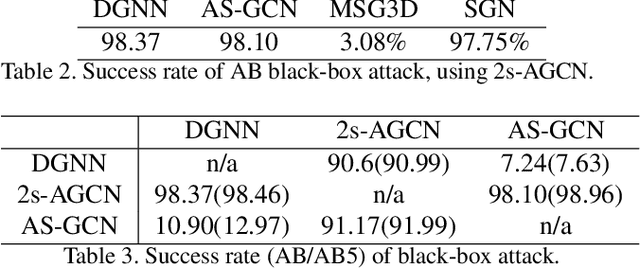

Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
Accelerated NMR Spectroscopy: Merge Optimization with Deep Learning
Dec 29, 2020
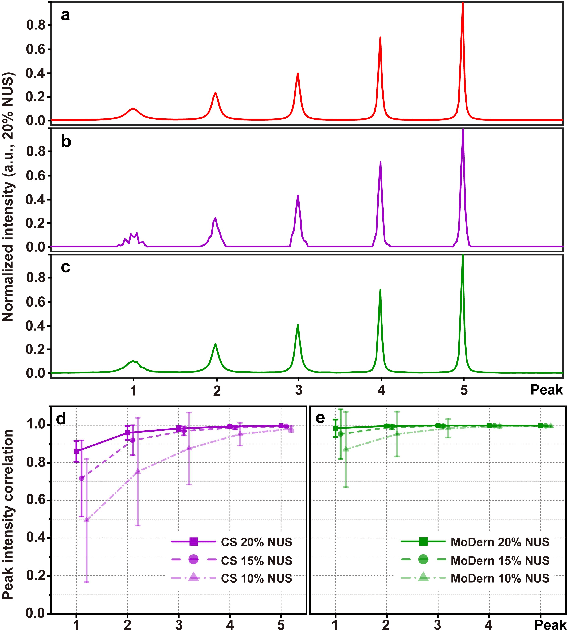
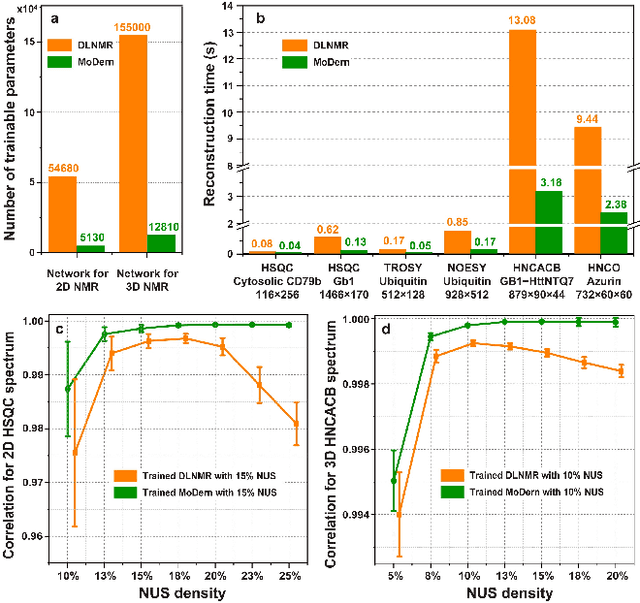
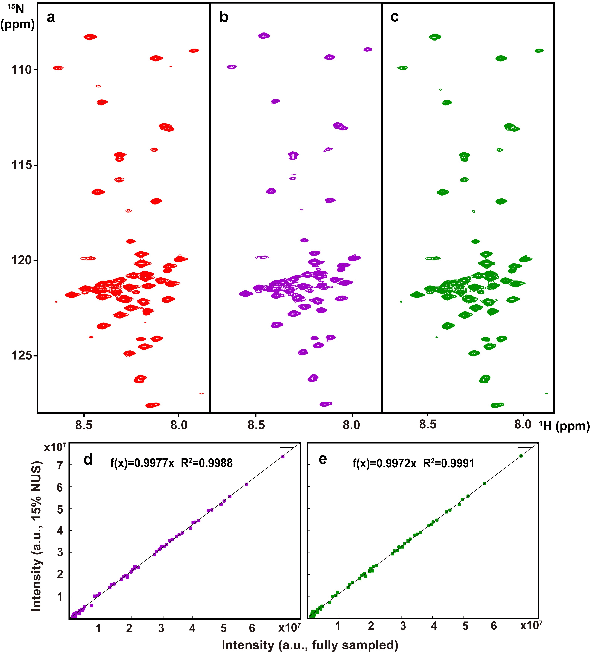
Multi-dimensional NMR spectroscopy is an invaluable biophysical tool in studies of structure, interactions, and dynamics of large molecules like proteins and nuclear acids. Non-uniform sampling is a powerful approach for shortening measurement time and increasing spectra resolution. Several methods have been established for spectra reconstruction from the undersampled data, typical approaches include model-based optimization and data-driven deep learning. The former is well theoretically grounded and provides high-quality spectra, while the latter has a huge advantage in reconstruction time potential and push further limits of spectra quality and analysis. Combining the merits of the two, we propose a model-inspired deep learning, for reliable, high-quality, and ultra-fast spectra reconstruction, exemplified by multi-dimensional spectra of several representative proteins. We demonstrate that the proposed network needs very few parameters, and shows very high robustness in respect to dissimilarity of the training and target data in the spectra size, type, and sampling level. This work can be considered as a proof-of-concept of merging optimization with deep learning in NMR spectroscopy.
Combining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021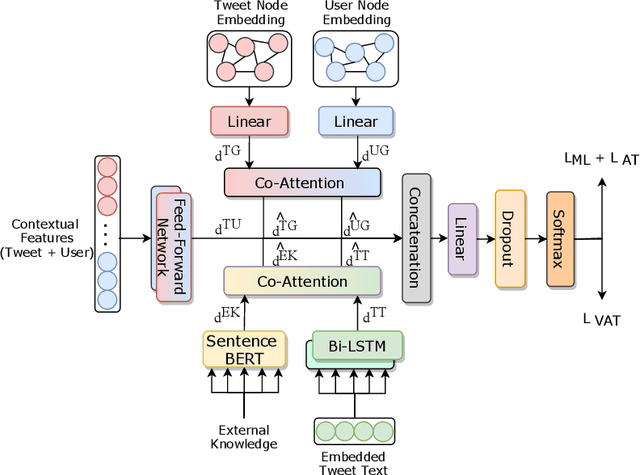
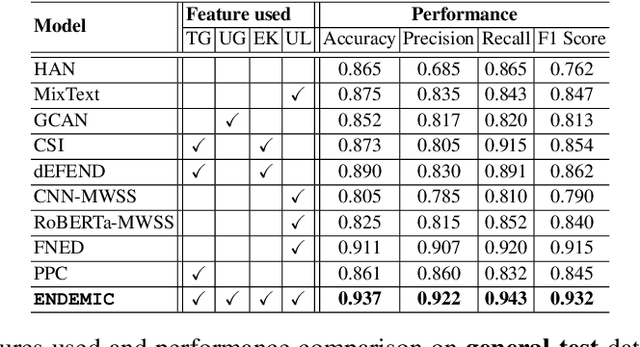
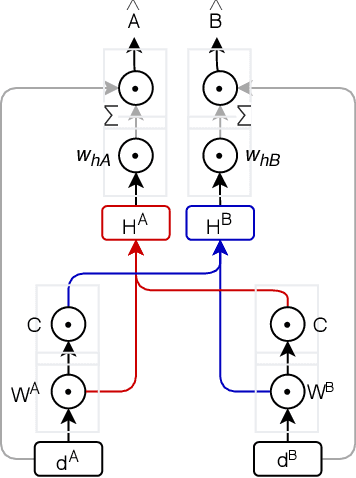
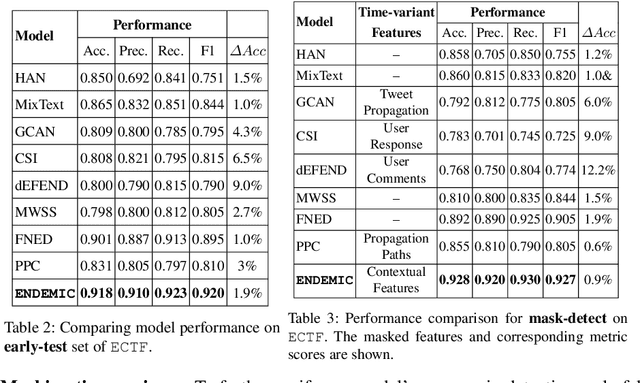
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.
Enforcing constraints for time series prediction in supervised, unsupervised and reinforcement learning
May 17, 2019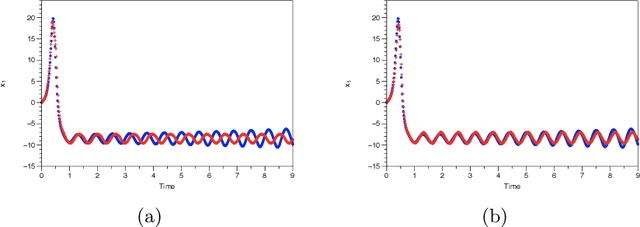
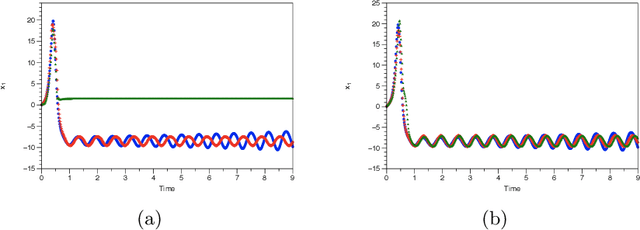
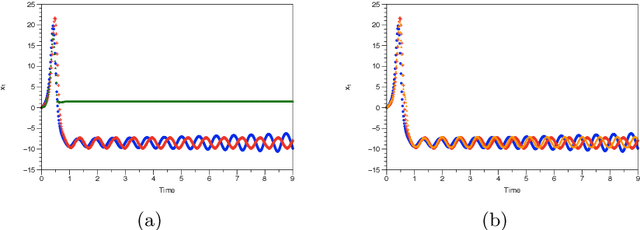
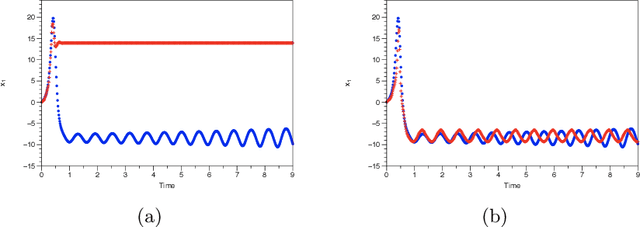
We assume that we are given a time series of data from a dynamical system and our task is to learn the flow map of the dynamical system. We present a collection of results on how to enforce constraints coming from the dynamical system in order to accelerate the training of deep neural networks to represent the flow map of the system as well as increase their predictive ability. In particular, we provide ways to enforce constraints during training for all three major modes of learning, namely supervised, unsupervised and reinforcement learning. In general, the dynamic constraints need to include terms which are analogous to memory terms in model reduction formalisms. Such memory terms act as a restoring force which corrects the errors committed by the learned flow map during prediction. For supervised learning, the constraints are added to the objective function. For the case of unsupervised learning, in particular generative adversarial networks, the constraints are introduced by augmenting the input of the discriminator. Finally, for the case of reinforcement learning and in particular actor-critic methods, the constraints are added to the reward function. In addition, for the reinforcement learning case, we present a novel approach based on homotopy of the action-value function in order to stabilize and accelerate training. We use numerical results for the Lorenz system to illustrate the various constructions.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016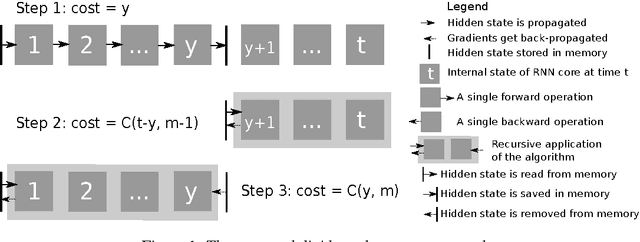
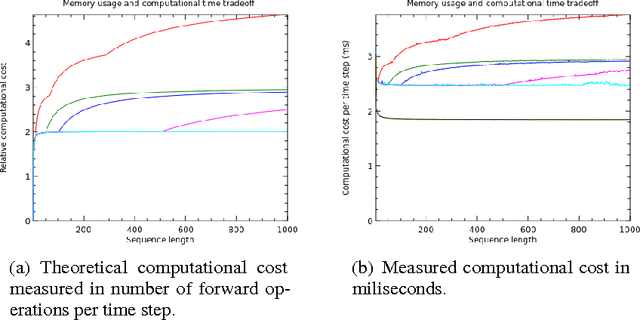
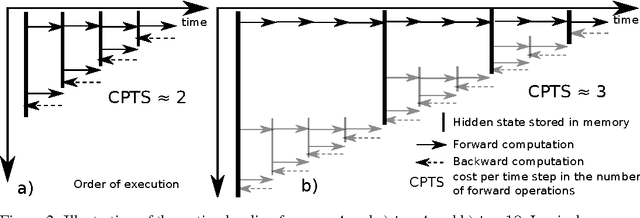
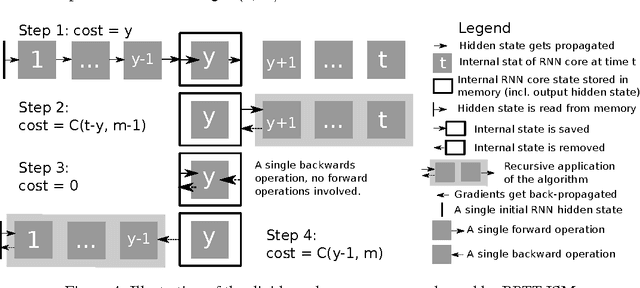
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.