 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 09, 2021
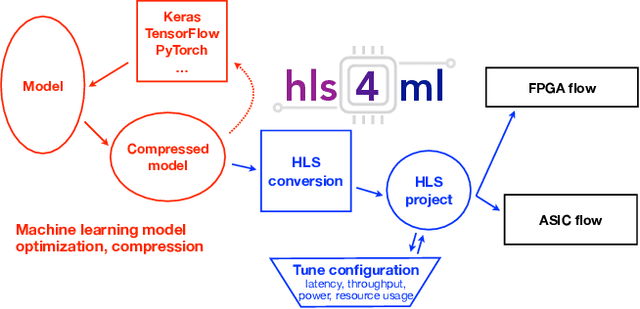
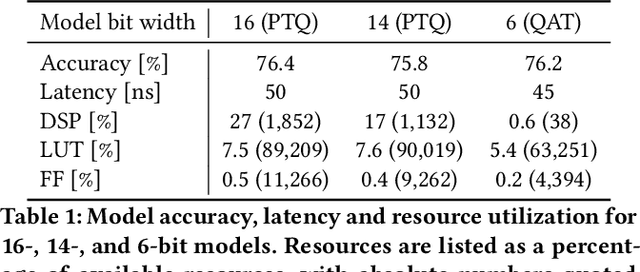
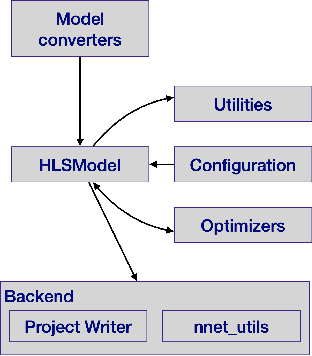
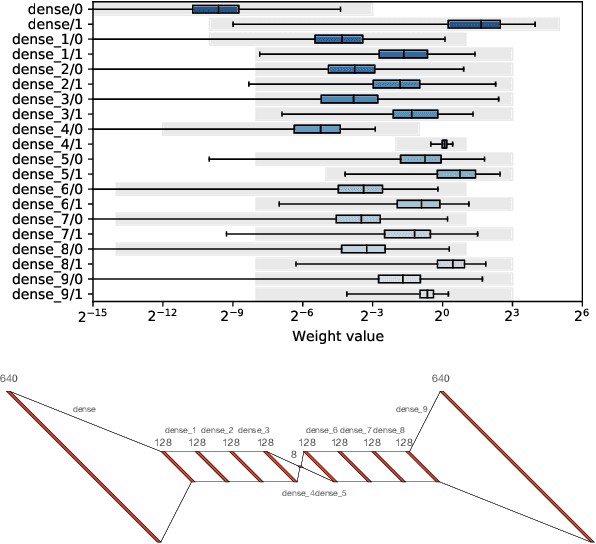
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
Evolving Neural Architecture Using One Shot Model
Dec 23, 2020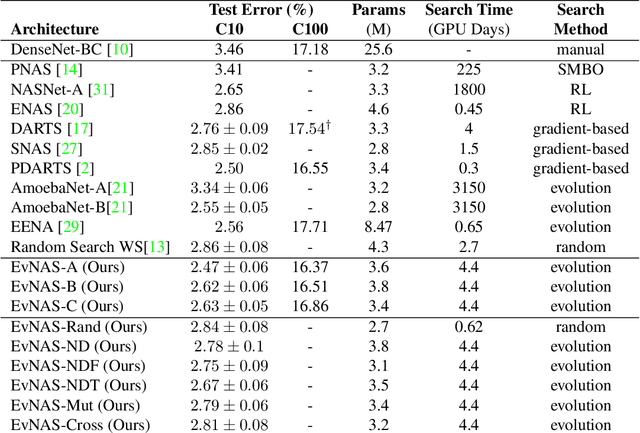
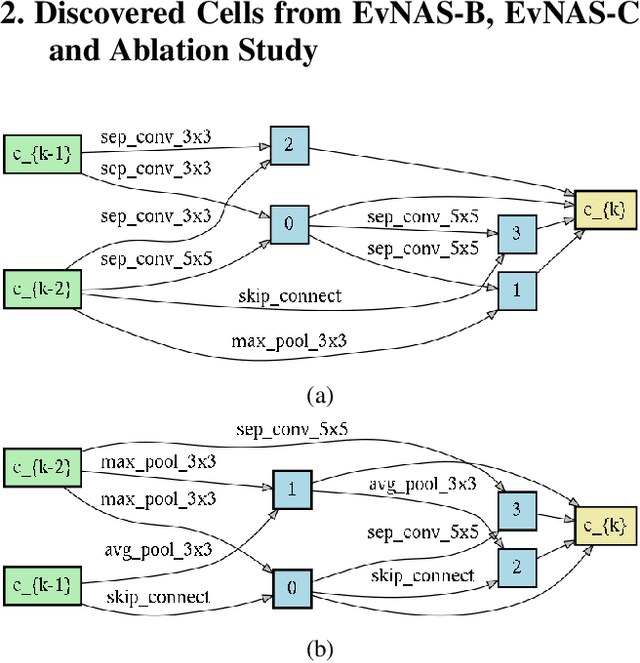
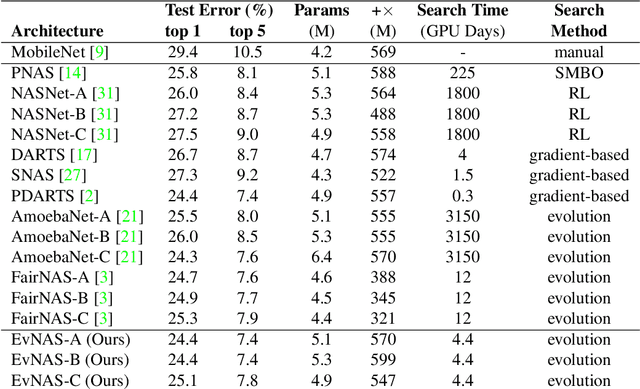
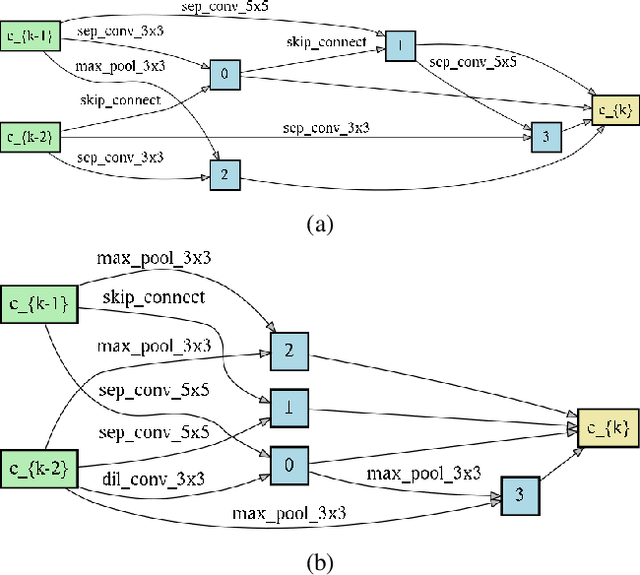
Neural Architecture Search (NAS) is emerging as a new research direction which has the potential to replace the hand-crafted neural architectures designed for specific tasks. Previous evolution based architecture search requires high computational resources resulting in high search time. In this work, we propose a novel way of applying a simple genetic algorithm to the NAS problem called EvNAS (Evolving Neural Architecture using One Shot Model) which reduces the search time significantly while still achieving better result than previous evolution based methods. The architectures are represented by using the architecture parameter of the one shot model which results in the weight sharing among the architectures for a given population of architectures and also weight inheritance from one generation to the next generation of architectures. We propose a decoding technique for the architecture parameter which is used to divert majority of the gradient information towards the given architecture and is also used for improving the performance prediction of the given architecture from the one shot model during the search process. Furthermore, we use the accuracy of the partially trained architecture on the validation data as a prediction of its fitness in order to reduce the search time. EvNAS searches for the architecture on the proxy dataset i.e. CIFAR-10 for 4.4 GPU day on a single GPU and achieves top-1 test error of 2.47% with 3.63M parameters which is then transferred to CIFAR-100 and ImageNet achieving top-1 error of 16.37% and top-5 error of 7.4% respectively. All of these results show the potential of evolutionary methods in solving the architecture search problem.
Humanoid Control Under Interchangeable Fixed and Sliding Unilateral Contacts
Mar 04, 2021
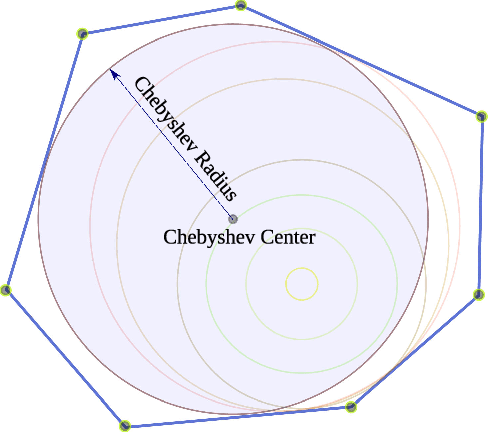
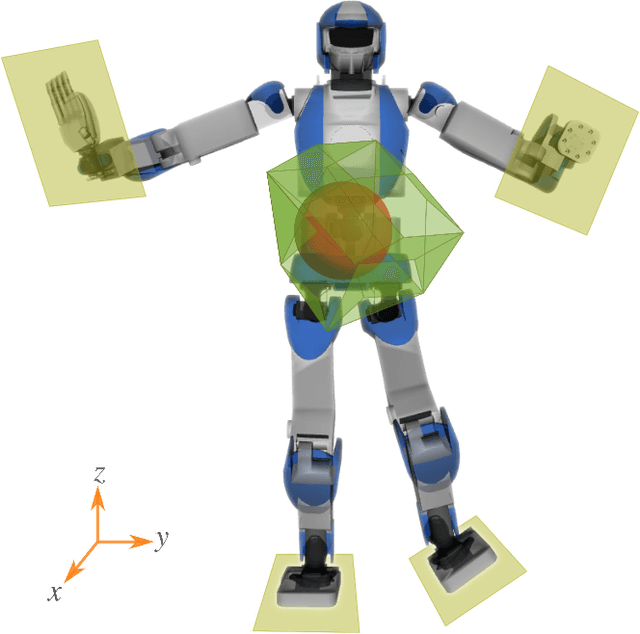
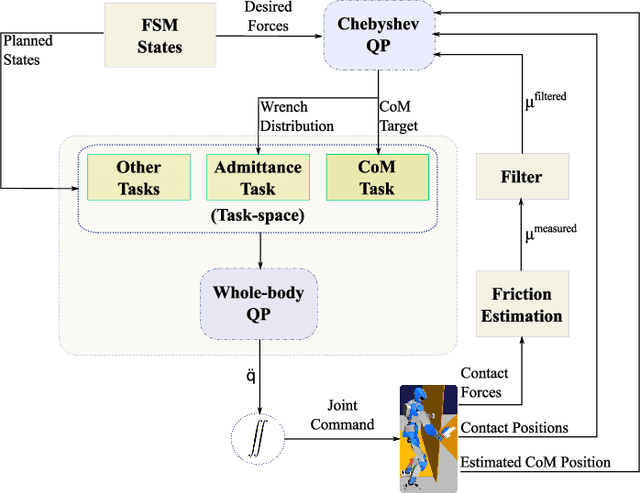
In this letter, we propose a whole-body control strategy for humanoid robots in multi-contact settings that enables switching between fixed and sliding contacts under active balance. We compute, in real-time, a safe center-of-mass position and wrench distribution of the contact points based on the Chebyshev center. Our solution is formulated as a quadratic programming problem without a priori computation of balance regions. We assess our approach with experiments highlighting switches between fixed and sliding contact modes in multi-contact configurations. A humanoid robot demonstrates such contact interchanges from fully-fixed to multi-sliding and also shuffling of the foot. The scenarios illustrate the performance of our control scheme in achieving the desired forces, CoM position attractor, and planned trajectories while actively maintaining balance.
CoordiNet: uncertainty-aware pose regressor for reliable vehicle localization
Mar 19, 2021
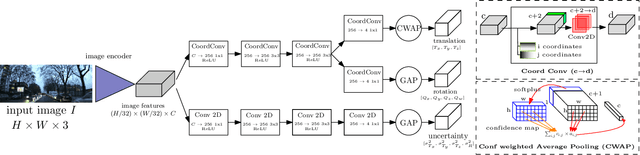

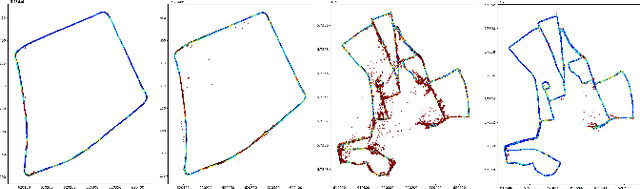
In this paper, we investigate visual-based camera localization with neural networks for robotics and autonomous vehicles applications. Our solution is a CNN-based algorithm which predicts camera pose (3D translation and 3D rotation) directly from a single image. It also provides an uncertainty estimate of the pose. Pose and uncertainty are learned together with a single loss function. Furthermore, we propose a new fully convolutional architecture, named CoordiNet, designed to embed some of the scene geometry. Our framework outperforms comparable methods on the largest available benchmark, the Oxford RobotCar dataset, with an average error of 8 meters where previous best was 19 meters. We have also investigated the performance of our method on large scenes for real time (18 fps) vehicle localization. In this setup, structure-based methods require a large database, and we show that our proposal is a reliable alternative, achieving 29cm median error in a 1.9km loop in a busy urban area.
Automated Performance Testing Based on Active Deep Learning
Apr 05, 2021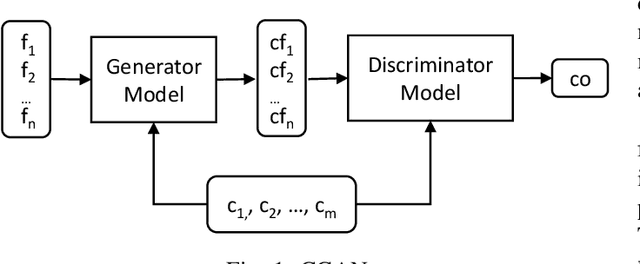
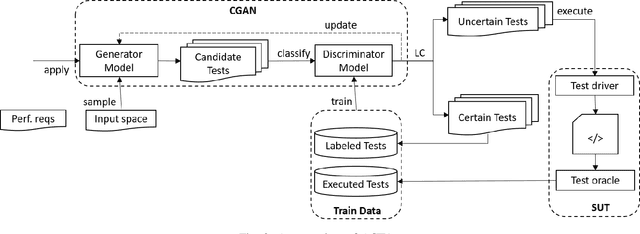
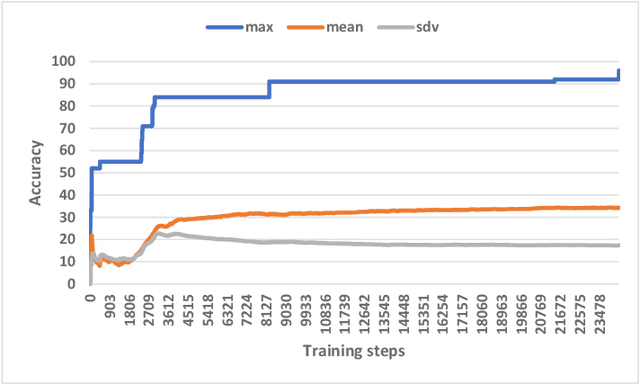
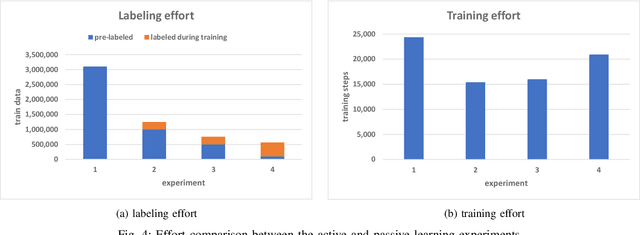
Generating tests that can reveal performance issues in large and complex software systems within a reasonable amount of time is a challenging task. On one hand, there are numerous combinations of input data values to explore. On the other hand, we have a limited test budget to execute tests. What makes this task even more difficult is the lack of access to source code and the internal details of these systems. In this paper, we present an automated test generation method called ACTA for black-box performance testing. ACTA is based on active learning, which means that it does not require a large set of historical test data to learn about the performance characteristics of the system under test. Instead, it dynamically chooses the tests to execute using uncertainty sampling. ACTA relies on a conditional variant of generative adversarial networks,and facilitates specifying performance requirements in terms of conditions and generating tests that address those conditions.We have evaluated ACTA on a benchmark web application, and the experimental results indicate that this method is comparable with random testing, and two other machine learning methods,i.e. PerfXRL and DN.
Artificial Neural Network Modeling for Airline Disruption Management
Apr 05, 2021

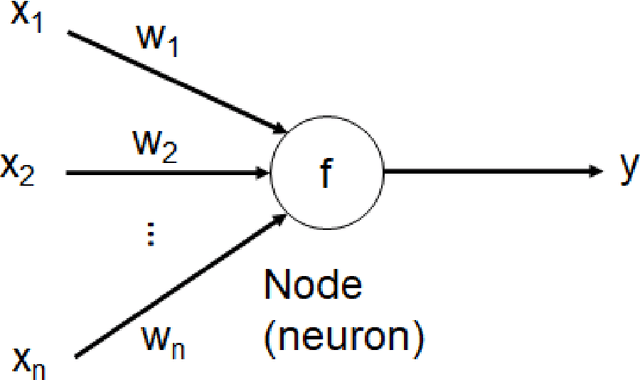
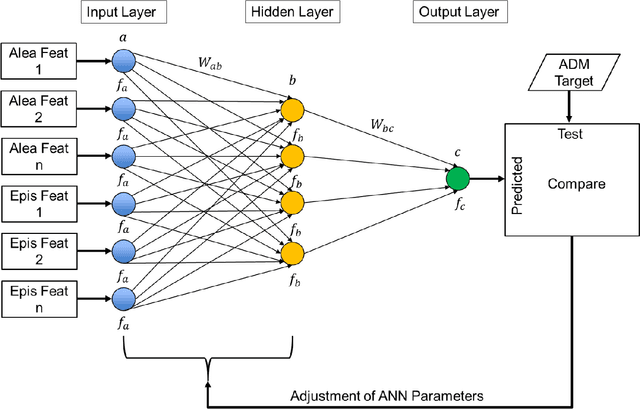
Since the 1970s, most airlines have incorporated computerized support for managing disruptions during flight schedule execution. However, existing platforms for airline disruption management (ADM) employ monolithic system design methods that rely on the creation of specific rules and requirements through explicit optimization routines, before a system that meets the specifications is designed. Thus, current platforms for ADM are unable to readily accommodate additional system complexities resulting from the introduction of new capabilities, such as the introduction of unmanned aerial systems (UAS), operations and infrastructure, to the system. To this end, we use historical data on airline scheduling and operations recovery to develop a system of artificial neural networks (ANNs), which describe a predictive transfer function model (PTFM) for promptly estimating the recovery impact of disruption resolutions at separate phases of flight schedule execution during ADM. Furthermore, we provide a modular approach for assessing and executing the PTFM by employing a parallel ensemble method to develop generative routines that amalgamate the system of ANNs. Our modular approach ensures that current industry standards for tardiness in flight schedule execution during ADM are satisfied, while accurately estimating appropriate time-based performance metrics for the separate phases of flight schedule execution.
Multi-Level Over-the-Air Aggregation of Mobile Edge Computing over D2D Wireless Networks
May 02, 2021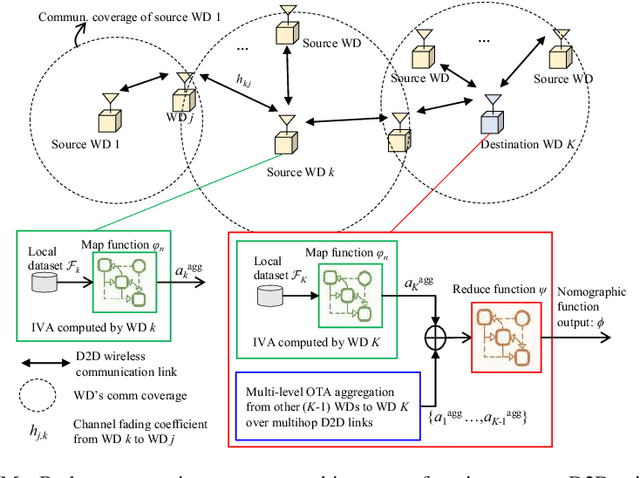
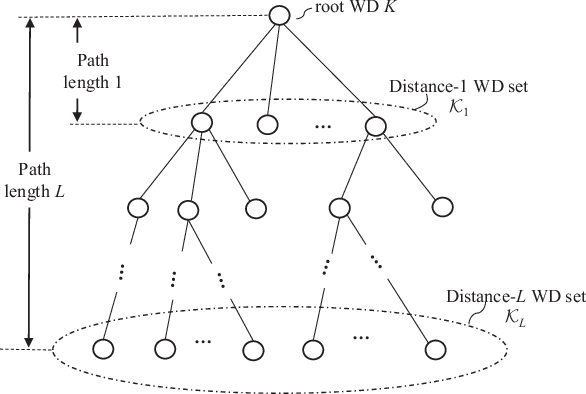
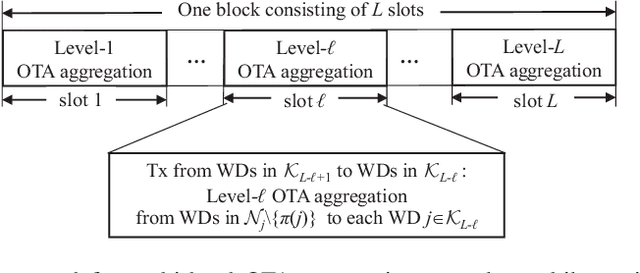
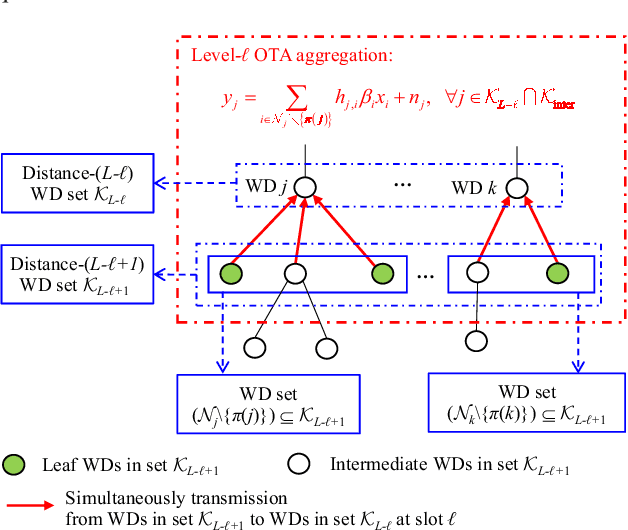
In this paper, we consider a wireless multihop device-to-device (D2D) based mobile edge computing (MEC) system, where the destination wireless device (WD) is scheduled to compute nomographic functions. Under the MapReduce framework and motivated by reducing communication resource overhead, we propose a new multi-level over-the-air (OTA) aggregation scheme for the destination WD to collect the individual partially aggregated intermediate values (IVAs) for reduction from multiple source WDs in the data shuffling phase. For OTA aggregation per level, the source WDs employ a channel inverse structure multiplied by their individual transmit coefficients in transmission over the same time frequency resource blocks, and the destination WD finally uses a receive filtering factor to construct the aggregated IVA. Under this setup, we develop a unified transceiver design framework that minimizes the mean squared error (MSE) of the aggregated IVA at the destination WD subject to the source WDs' individual power constraints, by jointly optimizing the source WDs' individual transmit coefficients and the destination WD's receive filtering factor. First, based on the primal decomposition method, we derive the closed-form solution under the special case of a common transmit coefficient. It shows that all the source WDs' common transmit is determined by the minimal transmit power budget among the source WDs. Next, for the general case, we transform the original problem into a quadratic fractional programming problem, and then develop a low-complexity algorithm to obtain the (near-) optimal solution by leveraging Dinkelbach's algorithm along with the Gaussian randomization method.
Improving Botnet Detection with Recurrent Neural Network and Transfer Learning
Apr 26, 2021
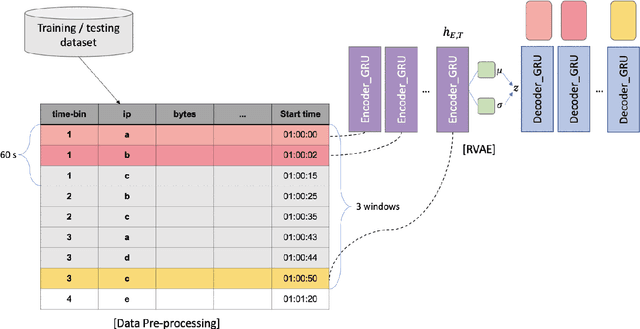
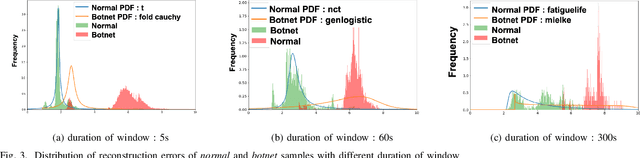
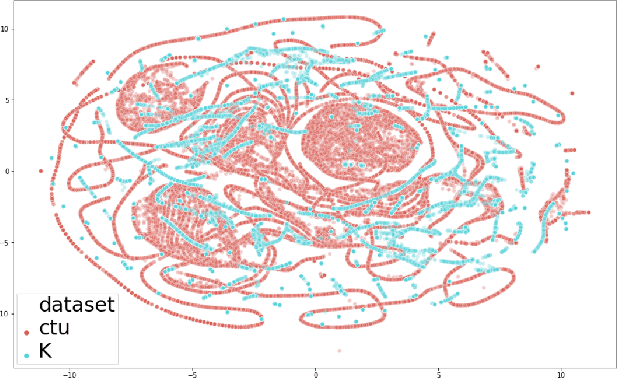
Botnet detection is a critical step in stopping the spread of botnets and preventing malicious activities. However, reliable detection is still a challenging task, due to a wide variety of botnets involving ever-increasing types of devices and attack vectors. Recent approaches employing machine learning (ML) showed improved performance than earlier ones, but these ML- based approaches still have significant limitations. For example, most ML approaches can not incorporate sequential pattern analysis techniques key to detect some classes of botnets. Another common shortcoming of ML-based approaches is the need to retrain neural networks in order to detect the evolving botnets; however, the training process is time-consuming and requires significant efforts to label the training data. For fast-evolving botnets, it might take too long to create sufficient training samples before the botnets have changed again. To address these challenges, we propose a novel botnet detection method, built upon Recurrent Variational Autoencoder (RVAE) that effectively captures sequential characteristics of botnet activities. In the experiment, this semi-supervised learning method achieves better detection accuracy than similar learning methods, especially on hard to detect classes. Additionally, we devise a transfer learning framework to learn from a well-curated source data set and transfer the knowledge to a target problem domain not seen before. Tests show that the true-positive rate (TPR) with transfer learning is higher than the RVAE semi-supervised learning method trained using the target data set (91.8% vs. 68.3%).
Advances in deep learning methods for pavement surface crack detection and identification with visible light visual images
Dec 29, 2020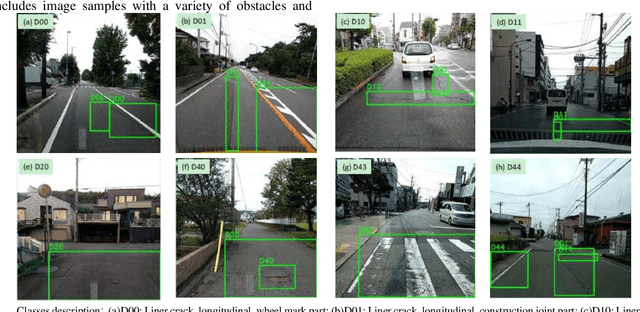
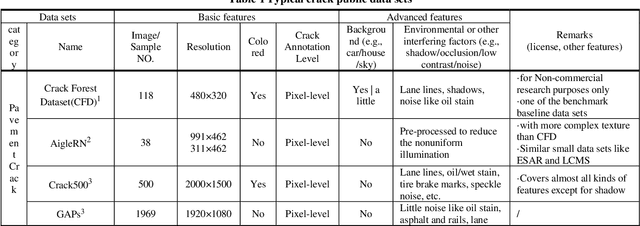


Compared to NDT and health monitoring method for cracks in engineering structures, surface crack detection or identification based on visible light images is non-contact, with the advantages of fast speed, low cost and high precision. Firstly, typical pavement (concrete also) crack public data sets were collected, and the characteristics of sample images as well as the random variable factors, including environmental, noise and interference etc., were summarized. Subsequently, the advantages and disadvantages of three main crack identification methods (i.e., hand-crafted feature engineering, machine learning, deep learning) were compared. Finally, from the aspects of model architecture, testing performance and predicting effectiveness, the development and progress of typical deep learning models, including self-built CNN, transfer learning(TL) and encoder-decoder(ED), which can be easily deployed on embedded platform, were reviewed. The benchmark test shows that: 1) It has been able to realize real-time pixel-level crack identification on embedded platform: the entire crack detection average time cost of an image sample is less than 100ms, either using the ED method (i.e., FPCNet) or the TL method based on InceptionV3. It can be reduced to less than 10ms with TL method based on MobileNet (a lightweight backbone base network). 2) In terms of accuracy, it can reach over 99.8% on CCIC which is easily identified by human eyes. On SDNET2018, some samples of which are difficult to be identified, FPCNet can reach 97.5%, while TL method is close to 96.1%. To the best of our knowledge, this paper for the first time comprehensively summarizes the pavement crack public data sets, and the performance and effectiveness of surface crack detection and identification deep learning methods for embedded platform, are reviewed and evaluated.
Real-time Segmentation and Facial Skin Tones Grading
Jan 09, 2020
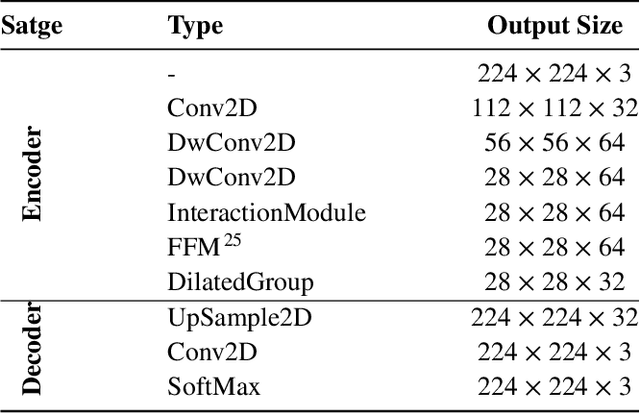
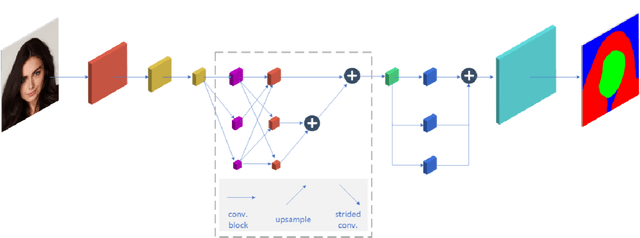
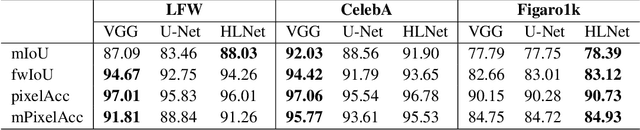
Modern approaches for semantic segmention usually pay too much attention to the accuracy of the model, and therefore it is strongly recommended to introduce cumbersome backbones, which brings heavy computation burden and memory footprint. To alleviate this problem, we propose an efficient segmentation method based on deep convolutional neural networks (DCNNs) for the task of hair and facial skin segmentation, which achieving remarkable trade-off between speed and performance on three benchmark datasets. As far as we know, the accuracy of skin tones classification is usually unsatisfactory due to the influence of external environmental factors such as illumination and background noise. Therefore, we use the segmentated face to obtain a specific face area, and further exploit the color moment algorithm to extract its color features. Specifically, for a 224 x 224 standard input, using our high-resolution spatial detail information and low-resolution contextual information fusion network (HLNet), we achieve 90.73% Pixel Accuracy on Figaro1k dataset at over 16 FPS in the case of CPU environment. Additional experiments on CamVid dataset further confirm the universality of the proposed model. We further use masked color moment for skin tones grade evaluation and approximate 80% classification accuracy demonstrate the feasibility of the proposed scheme.Code is available at https://github.com/JACKYLUO1991/Face-skin-hair-segmentaiton-and-skin-color-evaluation.