 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Approximate Query Processing for Group-By Queries based on Conditional Generative Models
Jan 08, 2021
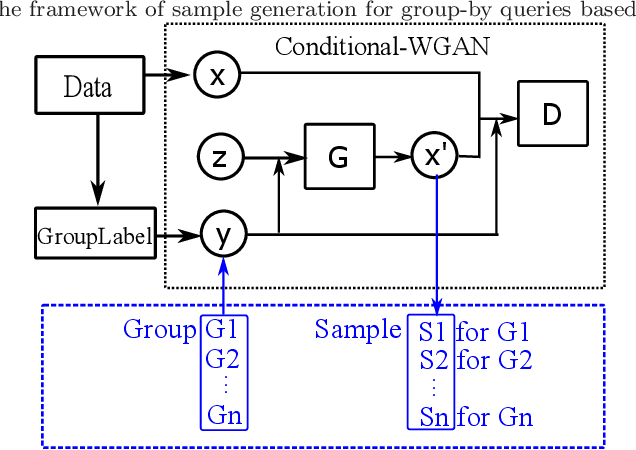

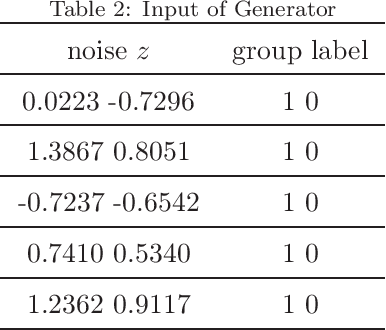
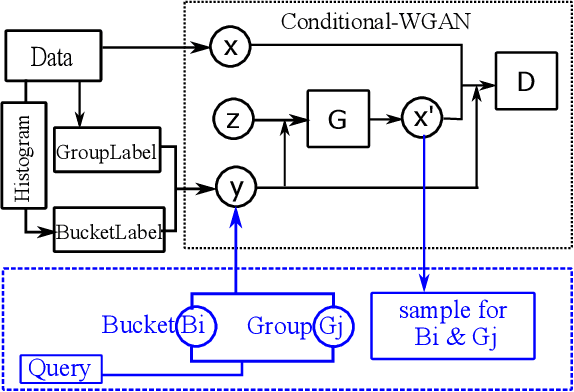
The Group-By query is an important kind of query, which is common and widely used in data warehouses, data analytics, and data visualization. Approximate query processing is an effective way to increase the querying efficiency on big data. The answer to a group-by query involves multiple values, which makes it difficult to provide sufficiently accurate estimations for all the groups. Stratified sampling improves the accuracy compared with the uniform sampling, but the samples chosen for some special queries cannot work for other queries. Online sampling chooses samples for the given query at query time, but it requires a long latency. Thus, it is a challenge to achieve both accuracy and efficiency at the same time. Facing such challenge, in this work, we propose a sample generation framework based on a conditional generative model. The sample generation framework can generate any number of samples for the given query without accessing the data. The proposed framework based on the lightweight model can be combined with stratified sampling and online aggregation to improve the estimation accuracy for group-by queries. The experimental results show that our proposed methods are both efficient and accurate.
Physics-oriented learning of nonlinear Schrödinger equation: optical fiber loss and dispersion profile identification
Apr 13, 2021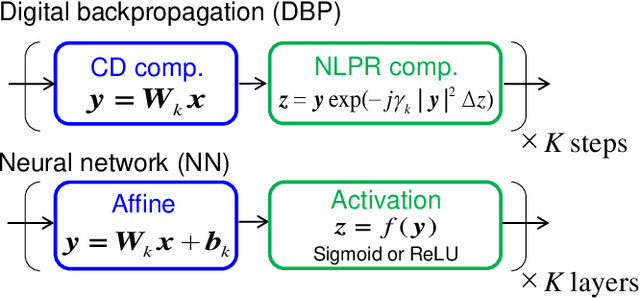
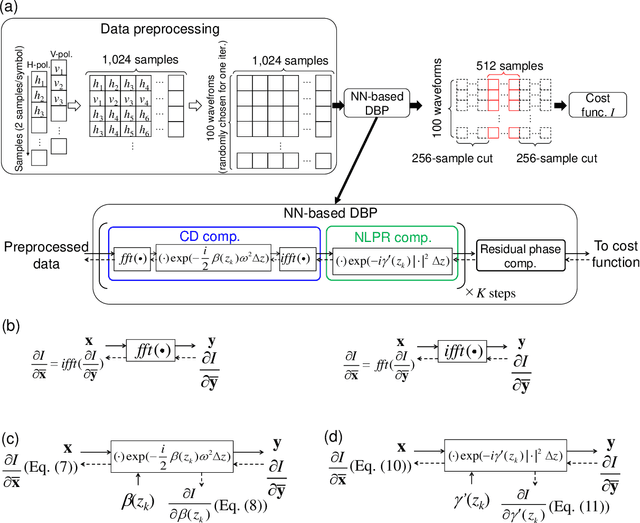
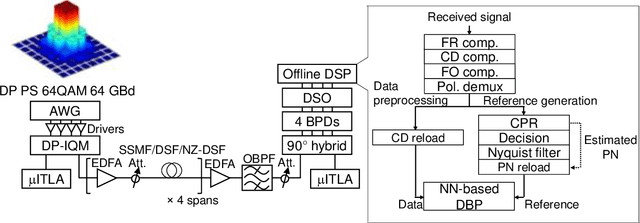
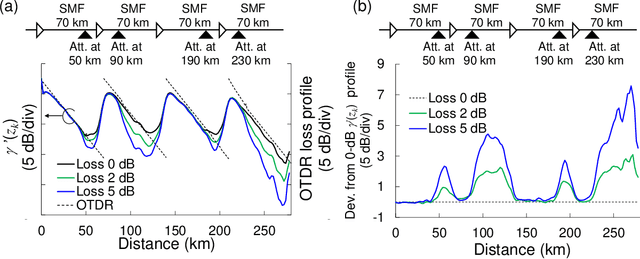
In optical fiber communication, system identification (SI) for the nonlinear Schr\"odinger equation (NLSE) has long been studied mainly for fiber nonlinearity compensation (NLC). One recent line of inquiry to combine a behavioral-model approach like digital backpropagation (DBP) and a data-driven approach like neural network (NN). These works are aimed for more NLC gain; however, by directing our attention to the learned parameters in such a SI process, system status information, i.e., optical fiber parameters, will possibly be extracted. Here, we show that the model-based optimization and interpretable nature of the learned parameters in NN-based DBP enable transmission line monitoring, fully extracting the actual in-line NLSE parameter distributions. Specifically, we demonstrate that longitudinal loss and dispersion profiles along a multi-span link can be obtained at once, directly from data-carrying signals without any dedicated analog devices such as optical time-domain reflectometry. We apply the method to a long-haul (~2,080 km) link and various link conditions are tested, including excess loss inserted, different fiber input power, and non-uniform level diagram. The measurement performance is also investigated in terms of measurement range, accuracy, and fiber launch power. These results provide a path toward simplified and automated network management as another application of DBP.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 09, 2021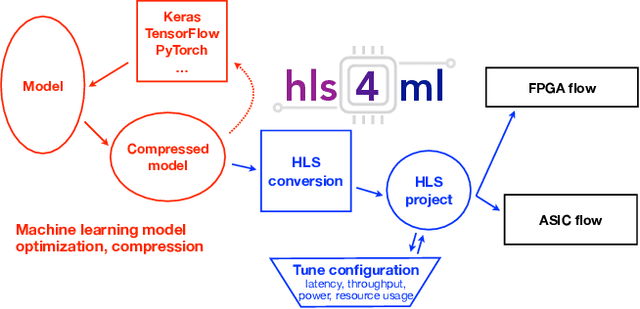
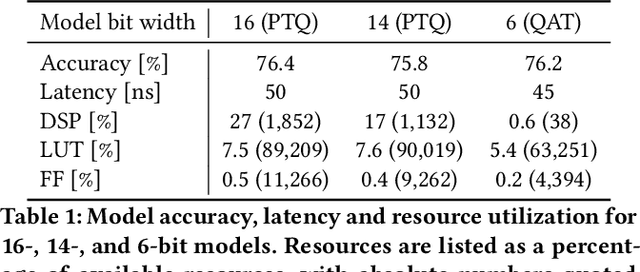
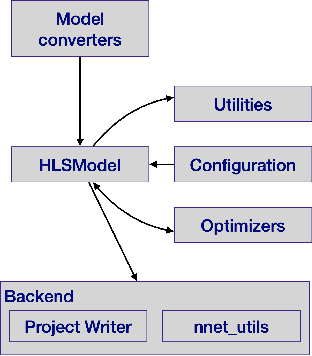
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
From Static to Dynamic Node Embeddings
Sep 21, 2020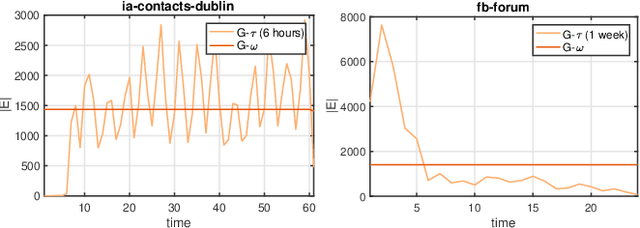
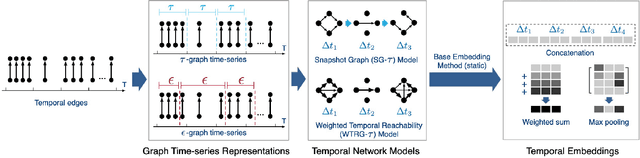
We introduce a general framework for leveraging graph stream data for temporal prediction-based applications. Our proposed framework includes novel methods for learning an appropriate graph time-series representation, modeling and weighting the temporal dependencies, and generalizing existing embedding methods for such data. While previous work on dynamic modeling and embedding has focused on representing a stream of timestamped edges using a time-series of graphs based on a specific time-scale (e.g., 1 month), we propose the notion of an $\epsilon$-graph time-series that uses a fixed number of edges for each graph, and show its superiority over the time-scale representation used in previous work. In addition, we propose a number of new temporal models based on the notion of temporal reachability graphs and weighted temporal summary graphs. These temporal models are then used to generalize existing base (static) embedding methods by enabling them to incorporate and appropriately model temporal dependencies in the data. From the 6 temporal network models investigated (for each of the 7 base embedding methods), we find that the top-3 temporal models are always those that leverage the new $\epsilon$-graph time-series representation. Furthermore, the dynamic embedding methods from the framework almost always achieve better predictive performance than existing state-of-the-art dynamic node embedding methods that are developed specifically for such temporal prediction tasks. Finally, the findings of this work are useful for designing better dynamic embedding methods.
Explaining Deep Neural Networks with a Polynomial Time Algorithm for Shapley Values Approximation
Apr 12, 2019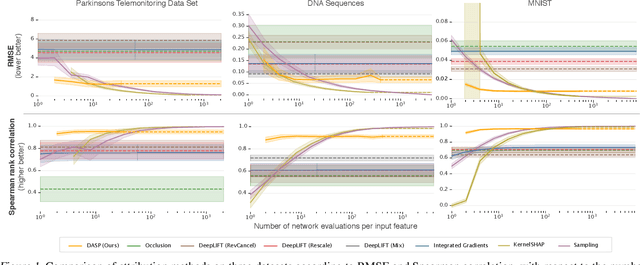
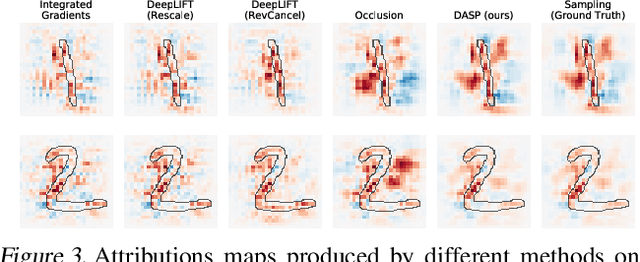
The problem of explaining the behavior of deep neural networks has gained a lot of attention over the last years. While several attribution methods have been proposed, most come without strong theoretical foundations. This raises the question of whether the resulting attributions are reliable. On the other hand, the literature on cooperative game theory suggests Shapley values as a unique way of assigning relevance scores such that certain desirable properties are satisfied. Previous works on attribution methods also showed that explanations based on Shapley values better agree with the human intuition. Unfortunately, the exact evaluation of Shapley values is prohibitively expensive, exponential in the number of input features. In this work, by leveraging recent results on uncertainty propagation, we propose a novel, polynomial-time approximation of Shapley values in deep neural networks. We show that our method produces significantly better approximations of Shapley values than existing state-of-the-art attribution methods.
Humanoid Control Under Interchangeable Fixed and Sliding Unilateral Contacts
Mar 04, 2021
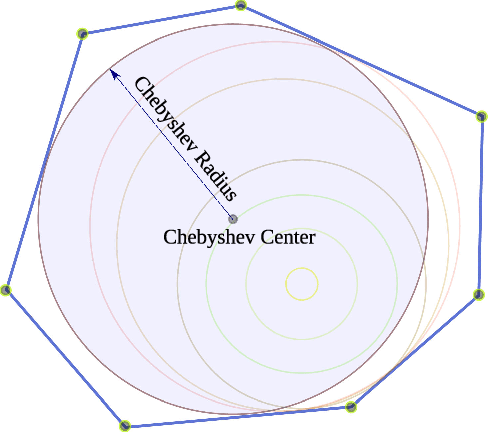
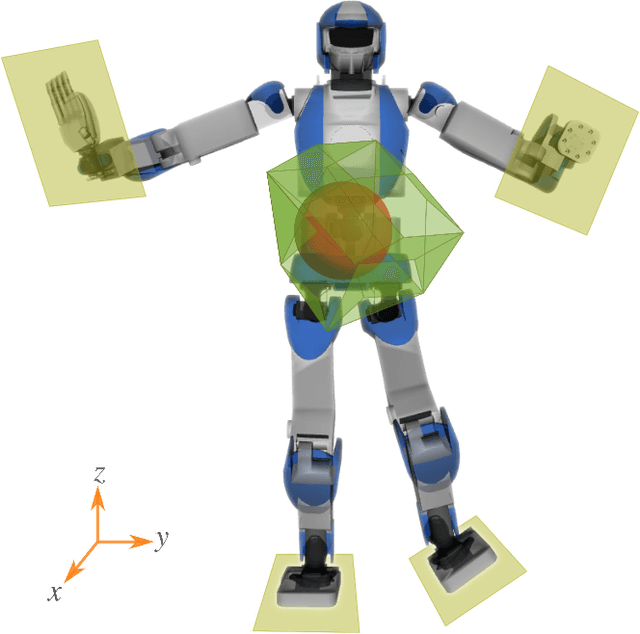
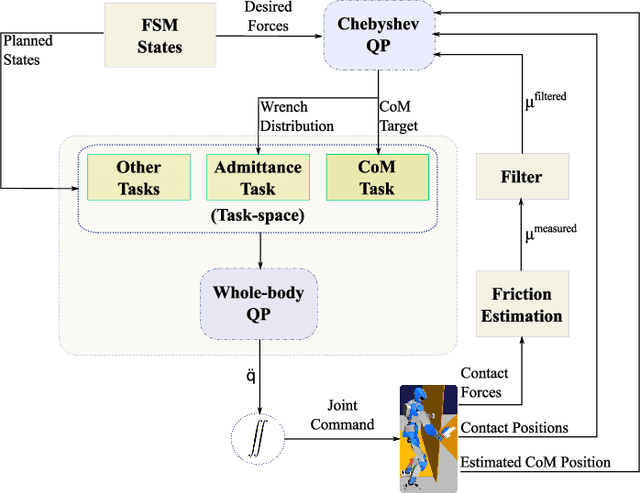
In this letter, we propose a whole-body control strategy for humanoid robots in multi-contact settings that enables switching between fixed and sliding contacts under active balance. We compute, in real-time, a safe center-of-mass position and wrench distribution of the contact points based on the Chebyshev center. Our solution is formulated as a quadratic programming problem without a priori computation of balance regions. We assess our approach with experiments highlighting switches between fixed and sliding contact modes in multi-contact configurations. A humanoid robot demonstrates such contact interchanges from fully-fixed to multi-sliding and also shuffling of the foot. The scenarios illustrate the performance of our control scheme in achieving the desired forces, CoM position attractor, and planned trajectories while actively maintaining balance.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 12, 2021
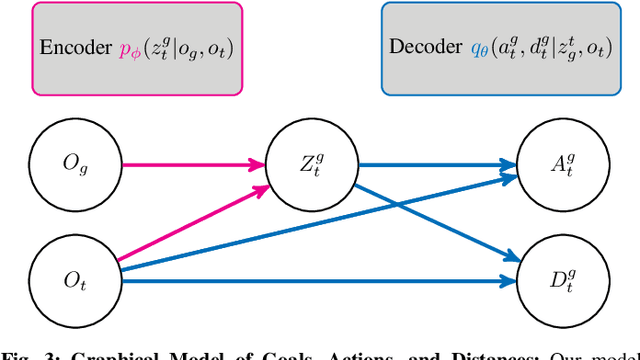
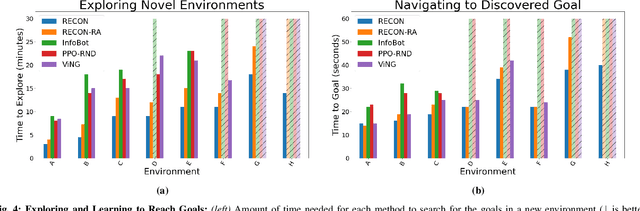
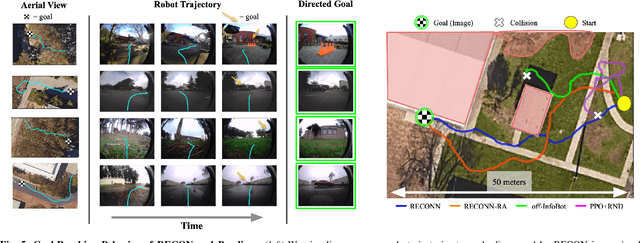
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies
Nov 01, 2020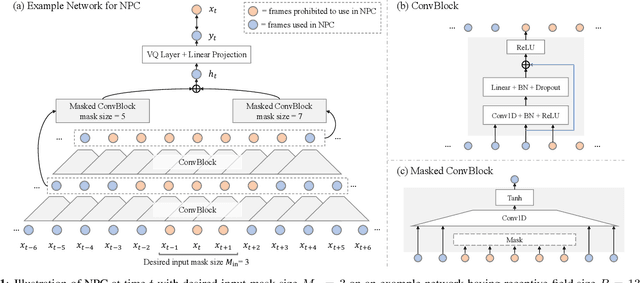
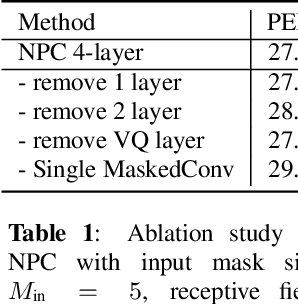
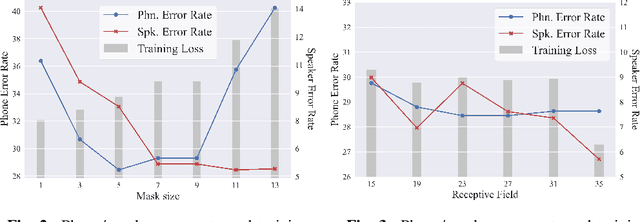
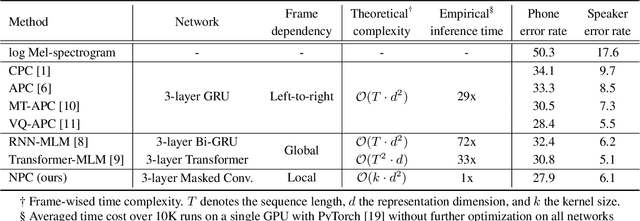
Self-supervised speech representations have been shown to be effective in a variety of speech applications. However, existing representation learning methods generally rely on the autoregressive model and/or observed global dependencies while generating the representation. In this work, we propose Non-Autoregressive Predictive Coding (NPC), a self-supervised method, to learn a speech representation in a non-autoregressive manner by relying only on local dependencies of speech. NPC has a conceptually simple objective and can be implemented easily with the introduced Masked Convolution Blocks. NPC offers a significant speedup for inference since it is parallelizable in time and has a fixed inference time for each time step regardless of the input sequence length. We discuss and verify the effectiveness of NPC by theoretically and empirically comparing it with other methods. We show that the NPC representation is comparable to other methods in speech experiments on phonetic and speaker classification while being more efficient.
Temporally-Continuous Probabilistic Prediction using Polynomial Trajectory Parameterization
Nov 01, 2020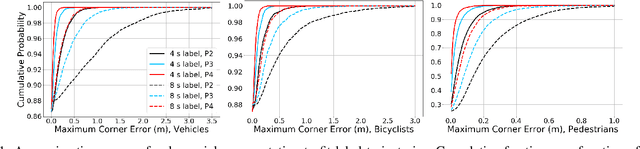
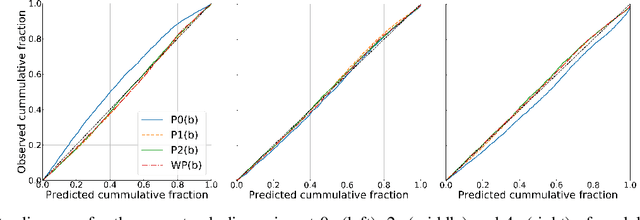
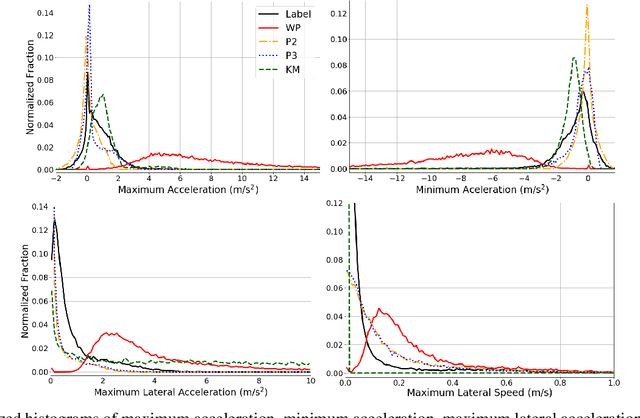
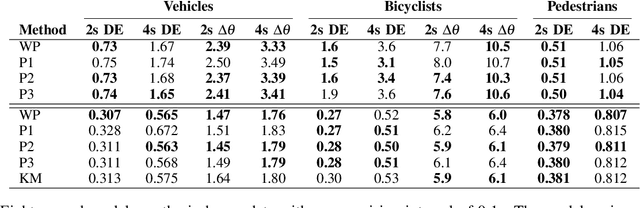
A commonly-used representation for motion prediction of actors is a sequence of waypoints (comprising positions and orientations) for each actor at discrete future time-points. While this approach is simple and flexible, it can exhibit unrealistic higher-order derivatives (such as acceleration) and approximation errors at intermediate time steps. To address this issue we propose a simple and general representation for temporally continuous probabilistic trajectory prediction that is based on polynomial trajectory parameterization. We evaluate the proposed representation on supervised trajectory prediction tasks using two large self-driving data sets. The results show realistic higher-order derivatives and better accuracy at interpolated time-points, as well as the benefits of the inferred noise distributions over the trajectories. Extensive experimental studies based on existing state-of-the-art models demonstrate the effectiveness of the proposed approach relative to other representations in predicting the future motions of vehicle, bicyclist, and pedestrian traffic actors.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016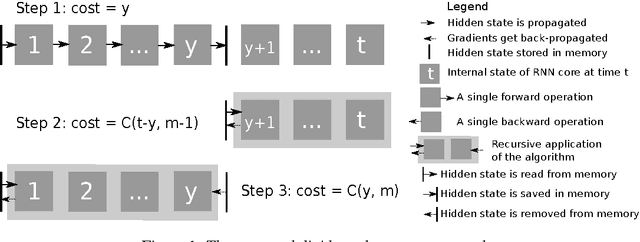
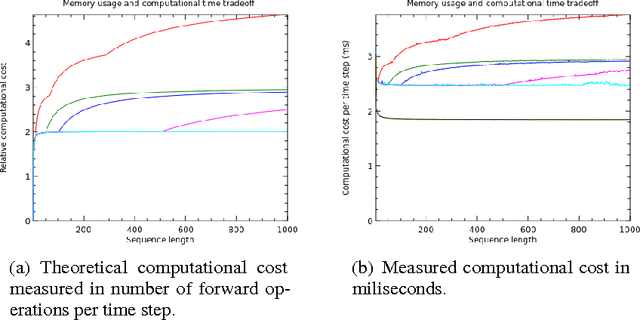
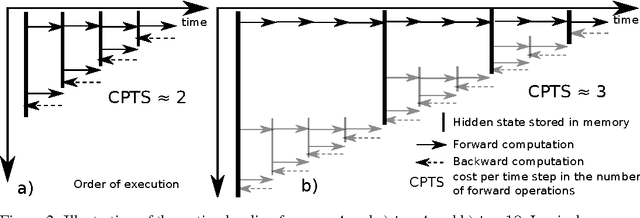
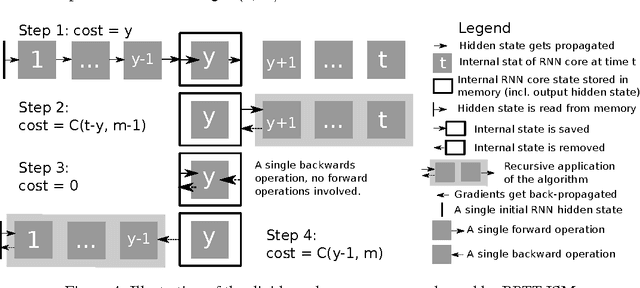
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.