 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cisco at AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides using Contextualized Embeddings
Feb 09, 2021

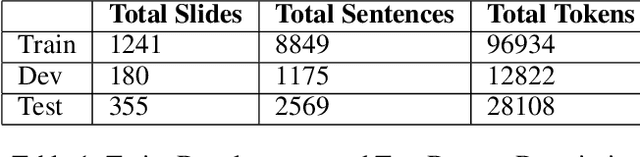
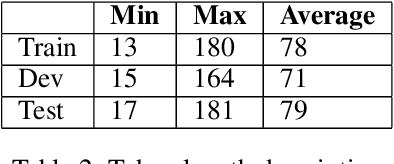
This paper describes our proposed system for the AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides. In this specific task, given the contents of a slide we are asked to predict the degree of emphasis to be laid on each word in the slide. We propose 2 approaches to this problem including a BiLSTM-ELMo approach and a transformers based approach based on RoBERTa and XLNet architectures. We achieve a score of 0.518 on the evaluation leaderboard which ranks us 3rd and 0.543 on the post-evaluation leaderboard which ranks us 1st at the time of writing the paper.
Fooling LiDAR Perception via Adversarial Trajectory Perturbation
Mar 29, 2021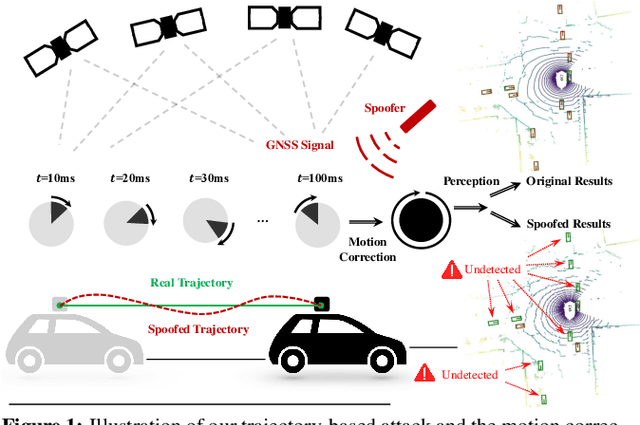
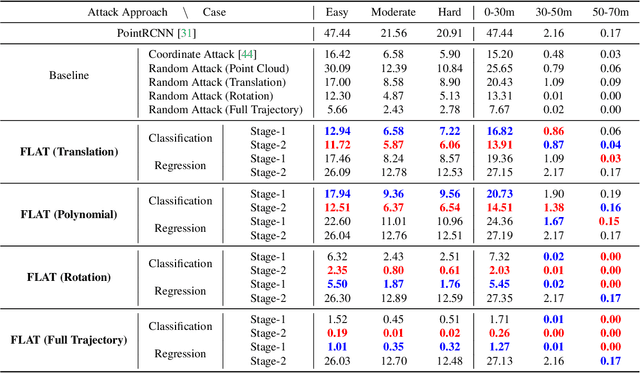
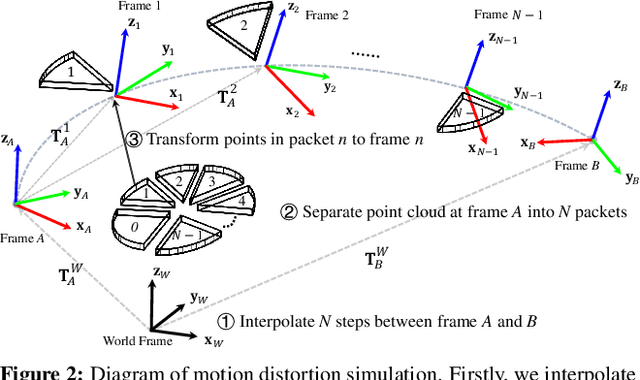
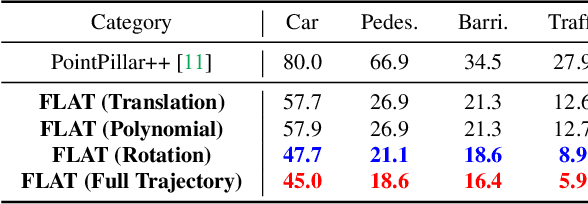
LiDAR point clouds collected from a moving vehicle are functions of its trajectories, because the sensor motion needs to be compensated to avoid distortions. When autonomous vehicles are sending LiDAR point clouds to deep networks for perception and planning, could the motion compensation consequently become a wide-open backdoor in those networks, due to both the adversarial vulnerability of deep learning and GPS-based vehicle trajectory estimation that is susceptible to wireless spoofing? We demonstrate such possibilities for the first time: instead of directly attacking point cloud coordinates which requires tampering with the raw LiDAR readings, only adversarial spoofing of a self-driving car's trajectory with small perturbations is enough to make safety-critical objects undetectable or detected with incorrect positions. Moreover, polynomial trajectory perturbation is developed to achieve a temporally-smooth and highly-imperceptible attack. Extensive experiments on 3D object detection have shown that such attacks not only lower the performance of the state-of-the-art detectors effectively, but also transfer to other detectors, raising a red flag for the community. The code is available on https://ai4ce.github.io/FLAT/.
Brain Tumors Classification for MR images based on Attention Guided Deep Learning Model
Apr 06, 2021
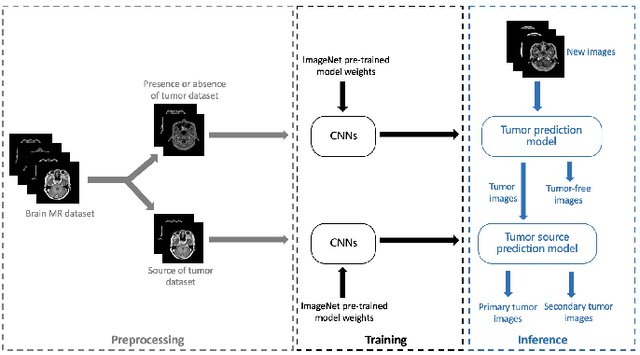
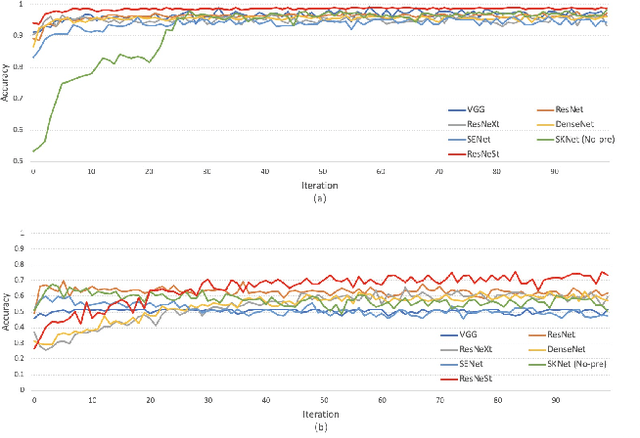
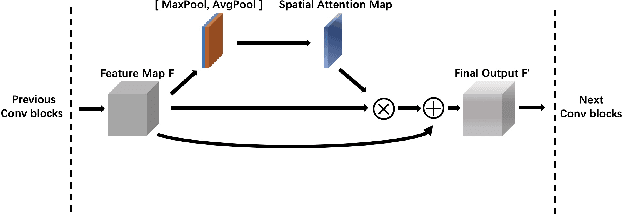
In the clinical diagnosis and treatment of brain tumors, manual image reading consumes a lot of energy and time. In recent years, the automatic tumor classification technology based on deep learning has entered people's field of vision. Brain tumors can be divided into primary and secondary intracranial tumors according to their source. However, to our best knowledge, most existing research on brain tumors are limited to primary intracranial tumor images and cannot classify the source of the tumor. In order to solve the task of tumor source type classification, we analyze the existing technology and propose an attention guided deep convolution neural network (CNN) model. Meanwhile, the method proposed in this paper also effectively improves the accuracy of classifying the presence or absence of tumor. For the brain MR dataset, our method can achieve the average accuracy of 99.18% under ten-fold cross-validation for identifying the presence or absence of tumor, and 83.38% for classifying the source of tumor. Experimental results show that our method is consistent with the method of medical experts. It can assist doctors in achieving efficient clinical diagnosis of brain tumors.
Multi-view data capture for dynamic object reconstruction using handheld augmented reality mobiles
Mar 20, 2021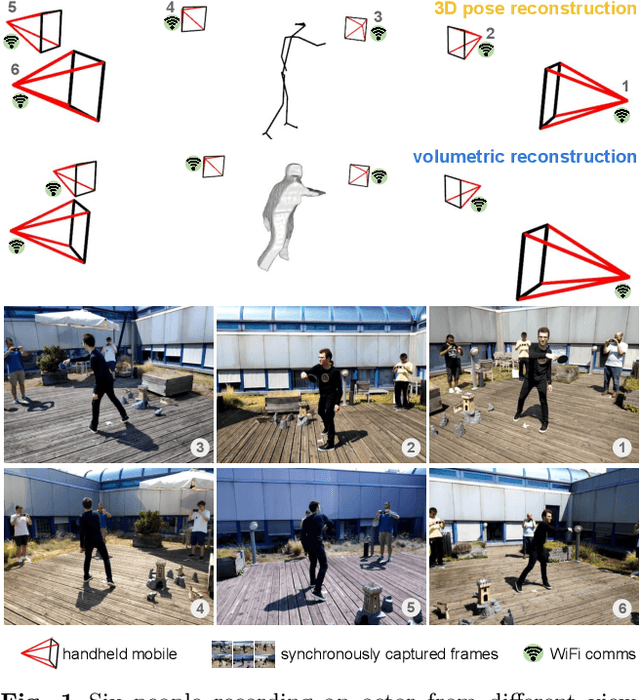

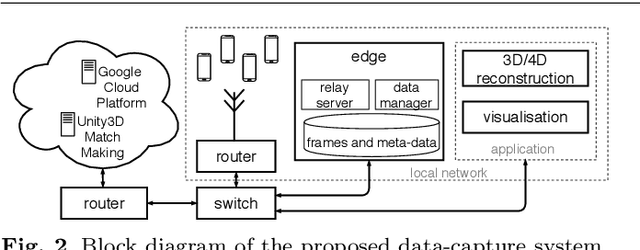

We propose a system to capture nearly-synchronous frame streams from multiple and moving handheld mobiles that is suitable for dynamic object 3D reconstruction. Each mobile executes Simultaneous Localisation and Mapping on-board to estimate its pose, and uses a wireless communication channel to send or receive synchronisation triggers. Our system can harvest frames and mobile poses in real time using a decentralised triggering strategy and a data-relay architecture that can be deployed either at the Edge or in the Cloud. We show the effectiveness of our system by employing it for 3D skeleton and volumetric reconstructions. Our triggering strategy achieves equal performance to that of an NTP-based synchronisation approach, but offers higher flexibility, as it can be adjusted online based on application needs. We created a challenging new dataset, namely 4DM, that involves six handheld augmented reality mobiles recording an actor performing sports actions outdoors. We validate our system on 4DM, analyse its strengths and limitations, and compare its modules with alternative ones.
UAV-Assisted Over-the-Air Computation
Jan 25, 2021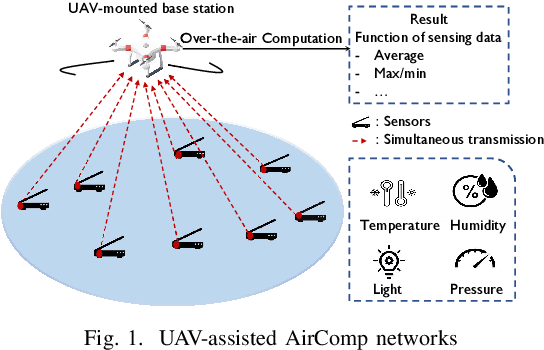
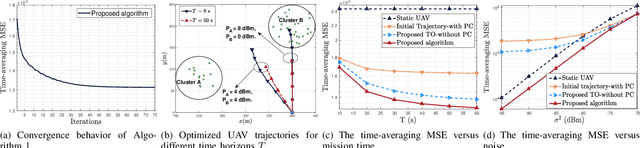
Over-the-air computation (AirComp) provides a promising way to support ultrafast aggregation of distributed data. However, its performance cannot be guaranteed in long-distance transmission due to the distortion induced by the channel fading and noise. To unleash the full potential of AirComp, this paper proposes to use a low-cost unmanned aerial vehicle (UAV) acting as a mobile base station to assist AirComp systems. Specifically, due to its controllable high-mobility and high-altitude, the UAV can move sufficiently close to the sensors to enable line-of-sight transmission and adaptively adjust all the links' distances, thereby enhancing the signal magnitude alignment and noise suppression. Our goal is to minimize the time-averaging mean-square error for AirComp by jointly optimizing the UAV trajectory, the scaling factor at the UAV, and the transmit power at the sensors, under constraints on the UAV's predetermined locations and flying speed, sensors' average and peak power limits. However, due to the highly coupled optimization variables and time-dependent constraints, the resulting problem is non-convex and challenging. We thus propose an efficient iterative algorithm by applying the block coordinate descent and successive convex optimization techniques. Simulation results verify the convergence of the proposed algorithm and demonstrate the performance gains and robustness of the proposed design compared with benchmarks.
Accelerating ODE-Based Neural Networks on Low-Cost FPGAs
Dec 31, 2020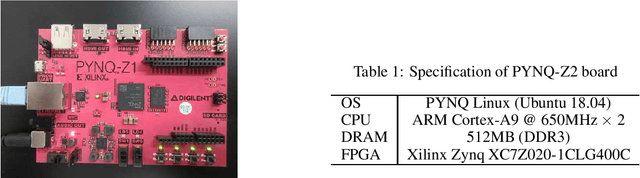
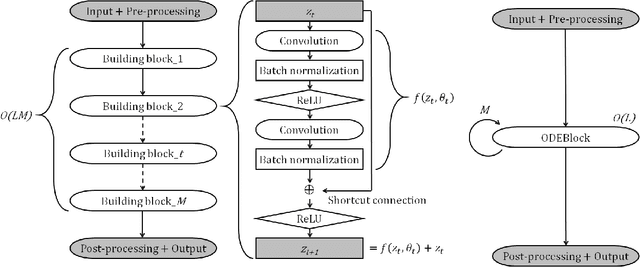
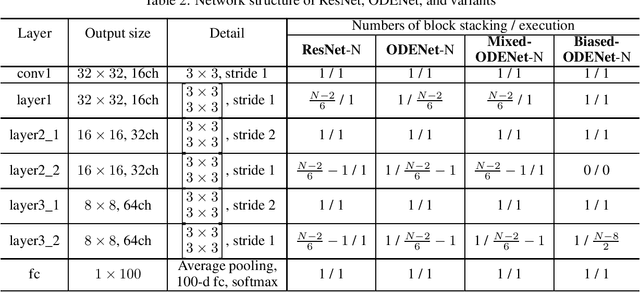
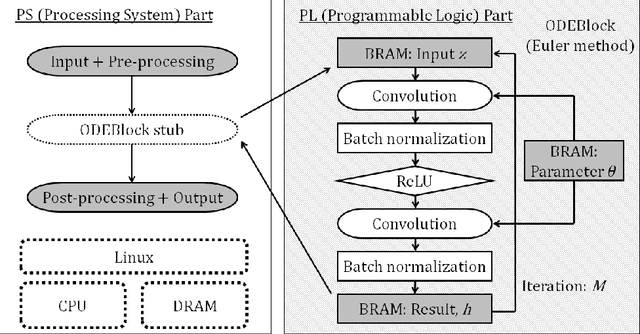
ODENet is a deep neural network architecture in which a stacking structure of ResNet is implemented with an ordinary differential equation (ODE) solver. It can reduce the number of parameters and strike a balance between accuracy and performance by selecting a proper solver. It is also possible to improve the accuracy while keeping the same number of parameters on resource-limited edge devices. In this paper, using Euler method as an ODE solver, a part of ODENet is implemented as a dedicated logic on a low-cost FPGA (Field-Programmable Gate Array) board, such as PYNQ-Z2 board. Two variants, one for high accuracy and the other for performance, are proposed and implemented on the FPGA board as well. They are evaluated in terms of parameter size, accuracy, execution time, and resource utilization on the FPGA. The results show that it is expected that an overall execution time of ODENet and its variants is improved by up to 1.77 times compared to a pure software execution if their convolution layers are executed by nine multiply-add units.
Deep imagination is a close to optimal policy for planning in large decision trees under limited resources
Apr 13, 2021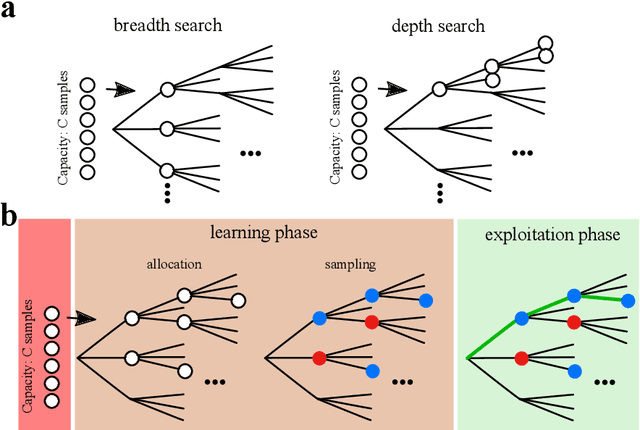
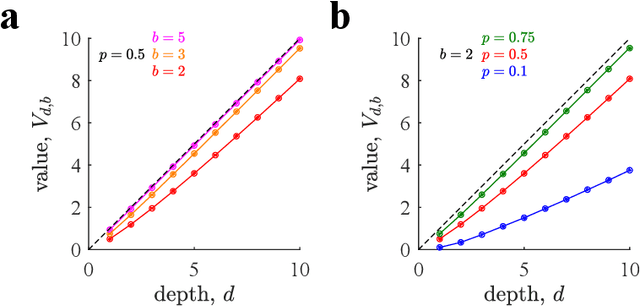
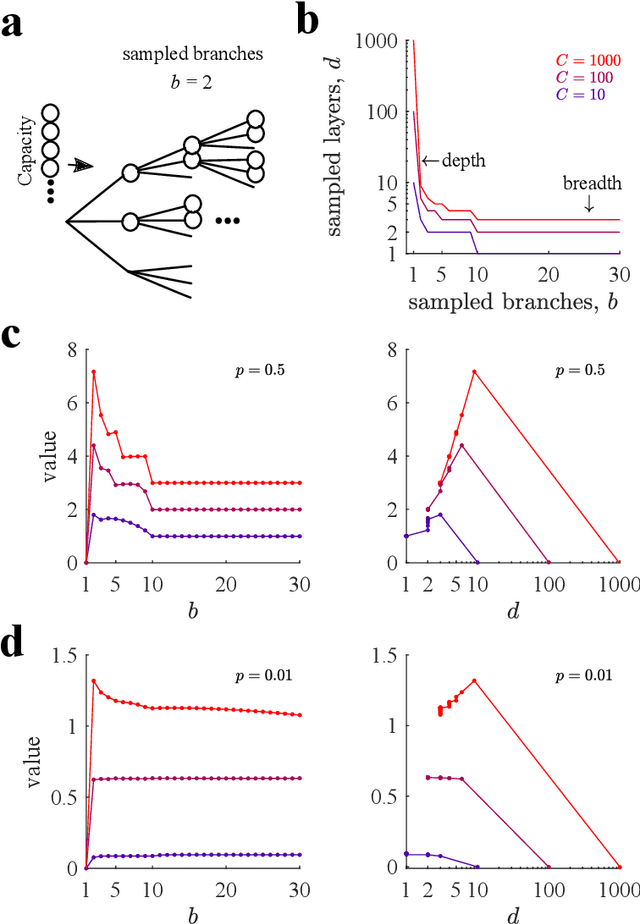
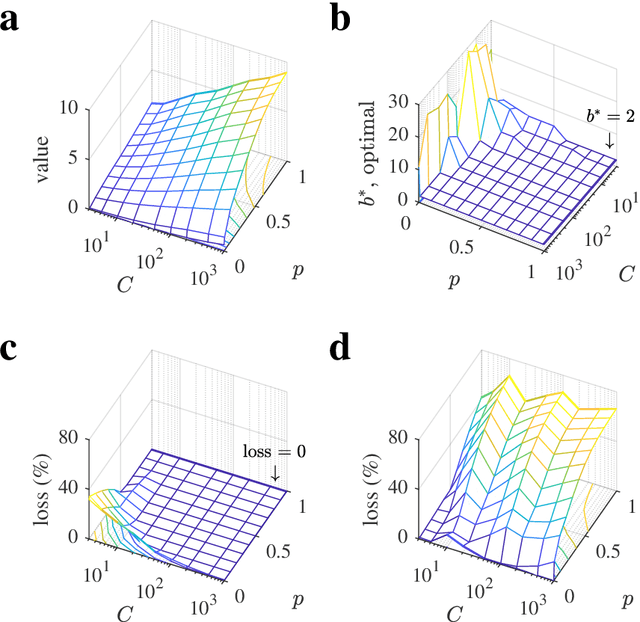
Many decisions involve choosing an uncertain course of actions in deep and wide decision trees, as when we plan to visit an exotic country for vacation. In these cases, exhaustive search for the best sequence of actions is not tractable due to the large number of possibilities and limited time or computational resources available to make the decision. Therefore, planning agents need to balance breadth (exploring many actions at each level of the tree) and depth (exploring many levels in the tree) to allocate optimally their finite search capacity. We provide efficient analytical solutions and numerical analysis to the problem of allocating finite sampling capacity in one shot to large decision trees. We find that in general the optimal policy is to allocate few samples per level so that deep levels can be reached, thus favoring depth over breadth search. In contrast, in poor environments and at low capacity, it is best to broadly sample branches at the cost of not sampling deeply, although this policy is marginally better than deep allocations. Our results provide a theoretical foundation for the optimality of deep imagination for planning and show that it is a generally valid heuristic that could have evolved from the finite constraints of cognitive systems.
Terrain assessment for precision agriculture using vehicle dynamic modelling
Apr 13, 2021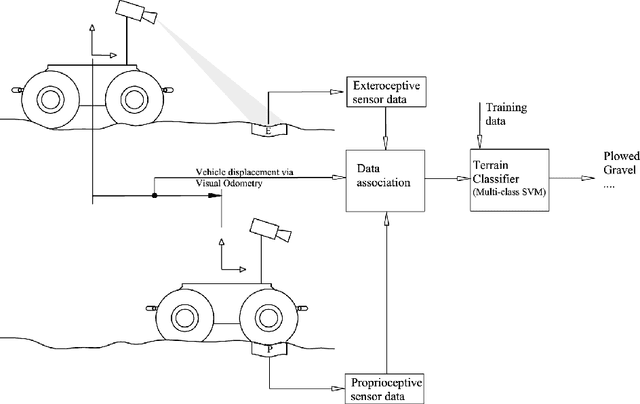


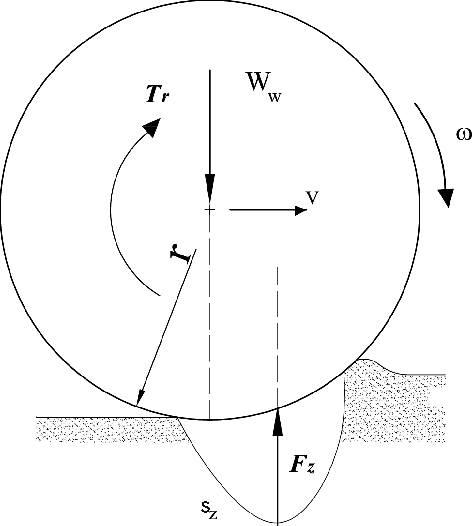
Advances in precision agriculture greatly rely on innovative control and sensing technologies that allow service units to increase their level of driving automation while ensuring at the same time high safety standards. This paper deals with automatic terrain estimation and classification that is performed simultaneously by an agricultural vehicle during normal operations. Vehicle mobility and safety, and the successful implementation of important agricultural tasks including seeding, ploughing, fertilising and controlled traffic depend or can be improved by a correct identification of the terrain that is traversed. The novelty of this research lies in that terrain estimation is performed by using not only traditional appearance-based features, that is colour and geometric properties, but also contact-based features, that is measuring physics-based dynamic effects that govern the vehicleeterrain interaction and that greatly affect its mobility. Experimental results obtained from an all-terrain vehicle operating on different surfaces are presented to validate the system in the field. It was shown that a terrain classifier trained with contact features was able to achieve a correct prediction rate of 85.1%, which is comparable or better than that obtained with approaches using traditional feature sets. To further improve the classification performance, all feature sets were merged in an augmented feature space, reaching, for these tests, 89.1% of correct predictions.
UAV Communications for Sustainable Federated Learning
Mar 20, 2021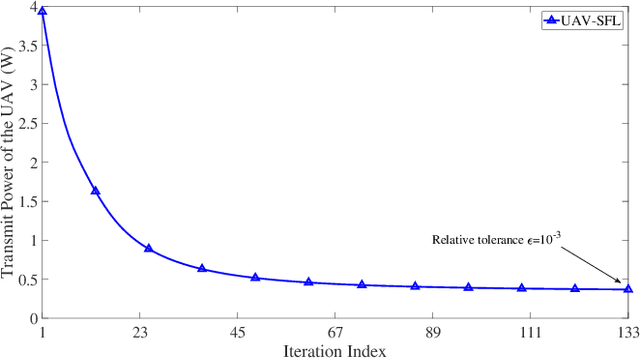
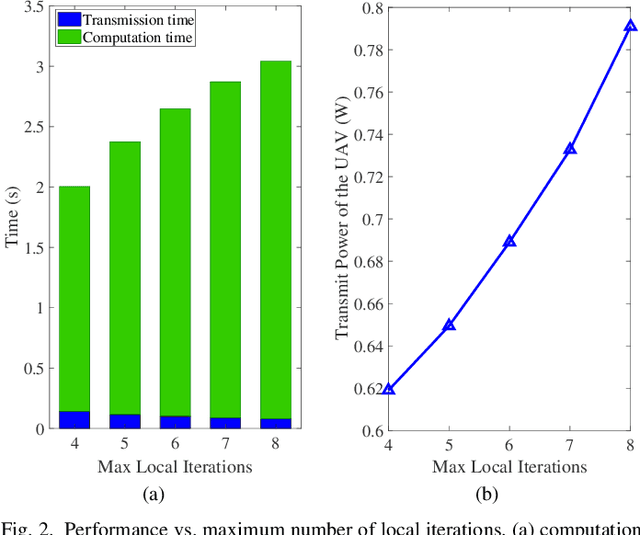
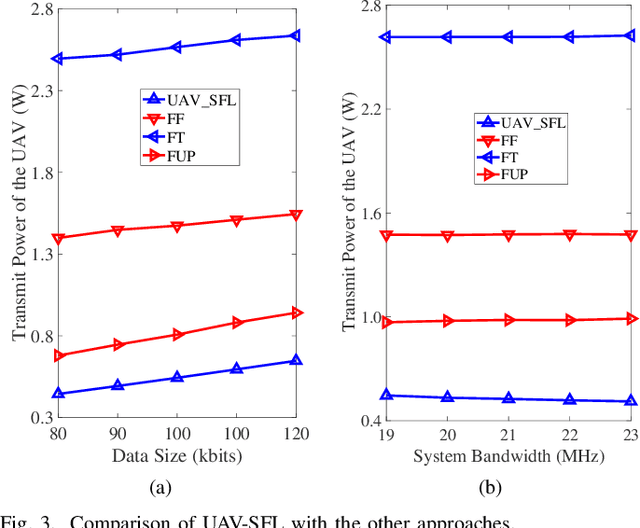
Federated learning (FL), invented by Google in 2016, has become a hot research trend. However, enabling FL in wireless networks has to overcome the limited battery challenge of mobile users. In this regard, we propose to apply unmanned aerial vehicle (UAV)-empowered wireless power transfer to enable sustainable FL-based wireless networks. The objective is to maximize the UAV transmit power efficiency, via a joint optimization of transmission time and bandwidth allocation, power control, and the UAV placement. Directly solving the formulated problem is challenging, due to the coupling of variables. Hence, we leverage the decomposition technique and a successive convex approximation approach to develop an efficient algorithm, namely UAV for sustainable FL (UAV-SFL). Finally, simulations illustrate the potential of our proposed UAV-SFL approach in providing a sustainable solution for FL-based wireless networks, and in reducing the UAV transmit power by 32.95%, 63.18%, and 78.81% compared with the benchmarks.
Stereo CenterNet based 3D Object Detection for Autonomous Driving
Mar 20, 2021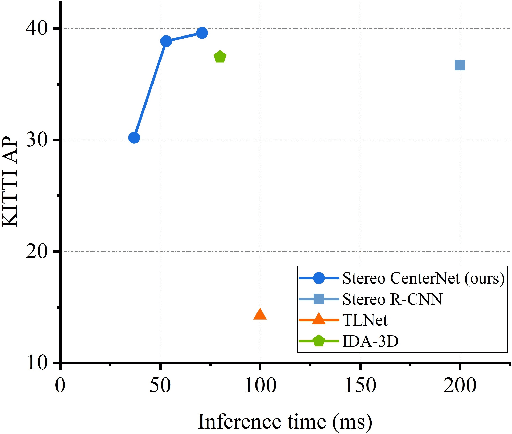
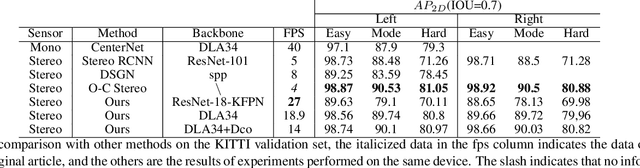
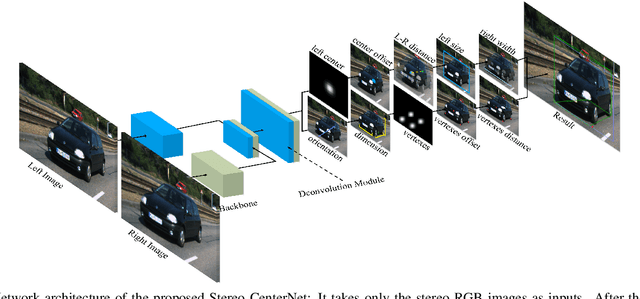
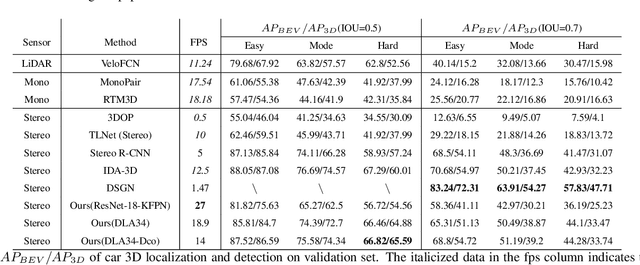
In recent years, 3D detection based on stereo cameras has made great progress, but most state-of-the-art methods use anchor-based 2D detection or depth estimation to solve this problem. However, the high computational cost makes these methods difficult to meet real-time performance. In this work, we propose a 3D object detection method using geometric information in stereo images, called Stereo CenterNet. Stereo CenterNet predicts the four semantic key points of the 3D bounding box of the object in space and uses 2D left right boxes, 3D dimension, orientation and key points to restore the bounding box of the object in the 3D space. Then, we use an improved photometric alignment module to further optimize the position of the 3D bounding box. Experiments conducted on the KITTI dataset show that our method achieves the best speed-accuracy trade-off compared with the state-of-the-art methods based on stereo geometry.