 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models
Jan 25, 2021
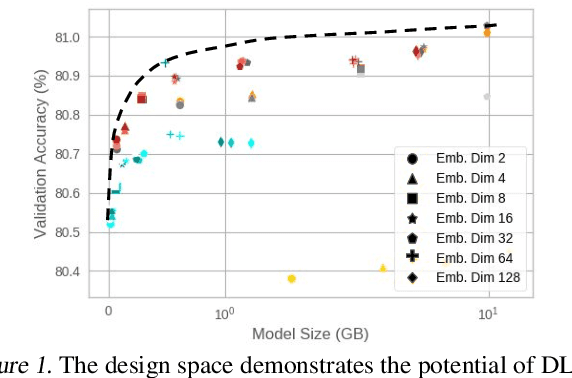
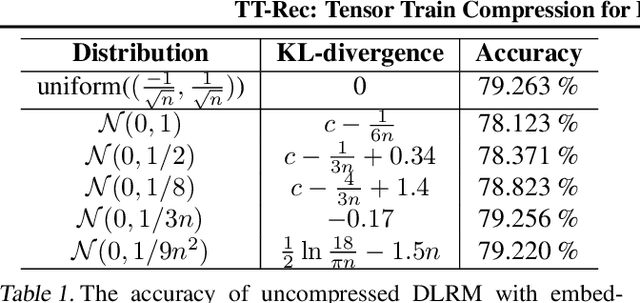
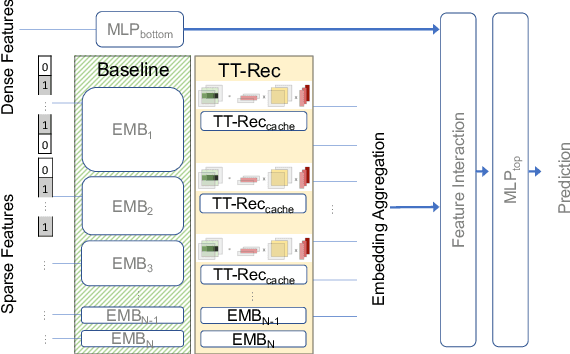
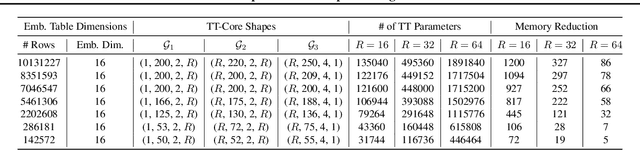
The memory capacity of embedding tables in deep learning recommendation models (DLRMs) is increasing dramatically from tens of GBs to TBs across the industry. Given the fast growth in DLRMs, novel solutions are urgently needed, in order to enable fast and efficient DLRM innovations. At the same time, this must be done without having to exponentially increase infrastructure capacity demands. In this paper, we demonstrate the promising potential of Tensor Train decomposition for DLRMs (TT-Rec), an important yet under-investigated context. We design and implement optimized kernels (TT-EmbeddingBag) to evaluate the proposed TT-Rec design. TT-EmbeddingBag is 3 times faster than the SOTA TT implementation. The performance of TT-Rec is further optimized with the batched matrix multiplication and caching strategies for embedding vector lookup operations. In addition, we present mathematically and empirically the effect of weight initialization distribution on DLRM accuracy and propose to initialize the tensor cores of TT-Rec following the sampled Gaussian distribution. We evaluate TT-Rec across three important design space dimensions -- memory capacity, accuracy, and timing performance -- by training MLPerf-DLRM with Criteo's Kaggle and Terabyte data sets. TT-Rec achieves 117 times and 112 times model size compression, for Kaggle and Terabyte, respectively. This impressive model size reduction can come with no accuracy nor training time overhead as compared to the uncompressed baseline.
Automating Visual Blockage Classification of Culverts with Deep Learning
Apr 21, 2021
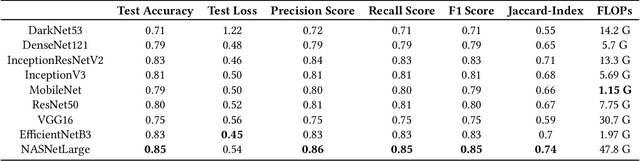
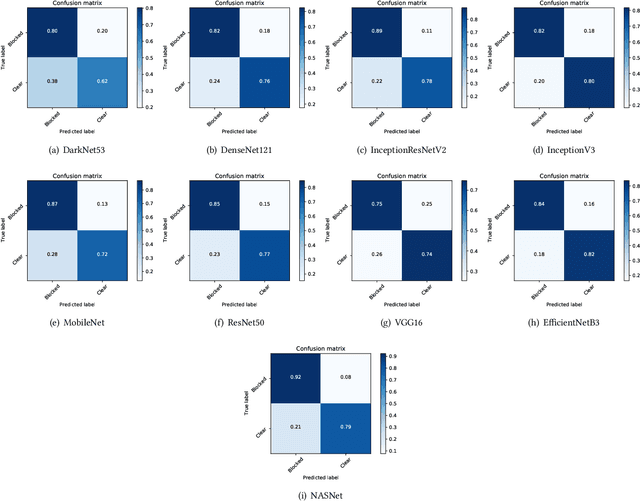
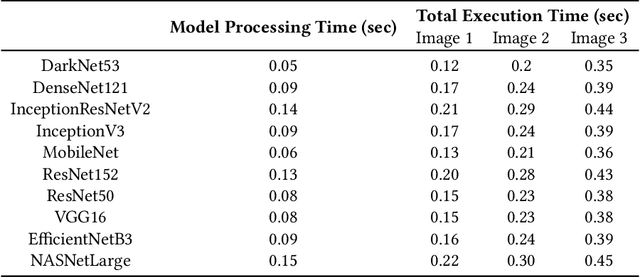
Blockage of culverts by transported debris materials is reported as main contributor in originating urban flash floods. Conventional modelling approaches had no success in addressing the problem largely because of unavailability of peak floods hydraulic data and highly non-linear behaviour of debris at culvert. This article explores a new dimension to investigate the issue by proposing the use of Intelligent Video Analytic (IVA) algorithms for extracting blockage related information. Potential of using existing Convolutional Neural Network (CNN) algorithms (i.e., DarkNet53, DenseNet121, InceptionResNetV2, InceptionV3, MobileNet, ResNet50, VGG16, EfficientNetB3, NASNet) is investigated over a custom collected blockage dataset (i.e., Images of Culvert Openings and Blockage (ICOB)) to predict the blockage in a given image. Models were evaluated based on their performance on test dataset (i.e., accuracy, loss, precision, recall, F1-score, Jaccard-Index), Floating Point Operations Per Second (FLOPs) and response times to process a single test instance. From the results, NASNet was reported most efficient in classifying the blockage with the accuracy of 85\%; however, EfficientNetB3 was recommended for the hardware implementation because of its improved response time with accuracy comparable to NASNet (i.e., 83\%). False Negative (FN) instances, False Positive (FP) instances and CNN layers activation suggested that background noise and oversimplified labelling criteria were two contributing factors in degraded performance of existing CNN algorithms.
Self-Supervised Motion Retargeting with Safety Guarantee
Mar 11, 2021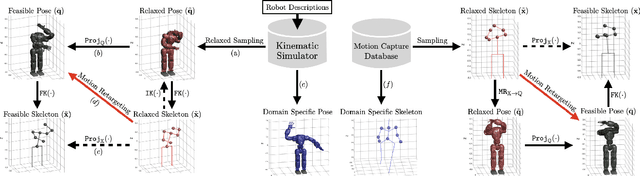
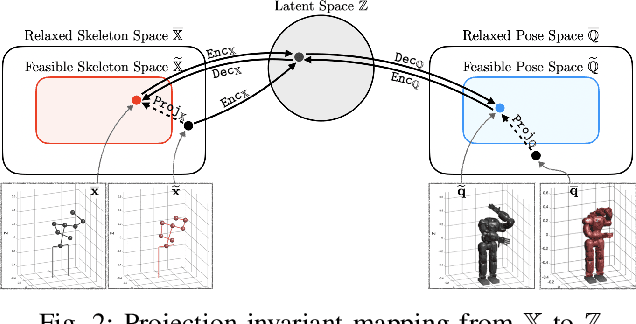
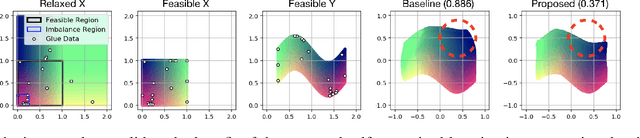
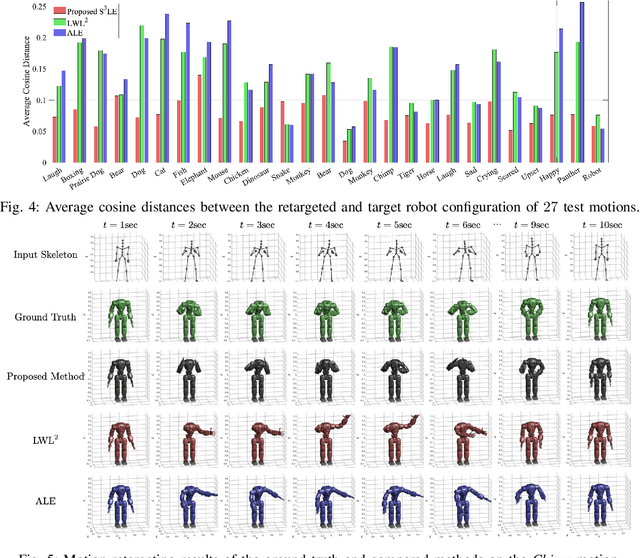
In this paper, we present self-supervised shared latent embedding (S3LE), a data-driven motion retargeting method that enables the generation of natural motions in humanoid robots from motion capture data or RGB videos. While it requires paired data consisting of human poses and their corresponding robot configurations, it significantly alleviates the necessity of time-consuming data-collection via novel paired data generating processes. Our self-supervised learning procedure consists of two steps: automatically generating paired data to bootstrap the motion retargeting, and learning a projection-invariant mapping to handle the different expressivity of humans and humanoid robots. Furthermore, our method guarantees that the generated robot pose is collision-free and satisfies position limits by utilizing nonparametric regression in the shared latent space. We demonstrate that our method can generate expressive robotic motions from both the CMU motion capture database and YouTube videos.
Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Feb 26, 2018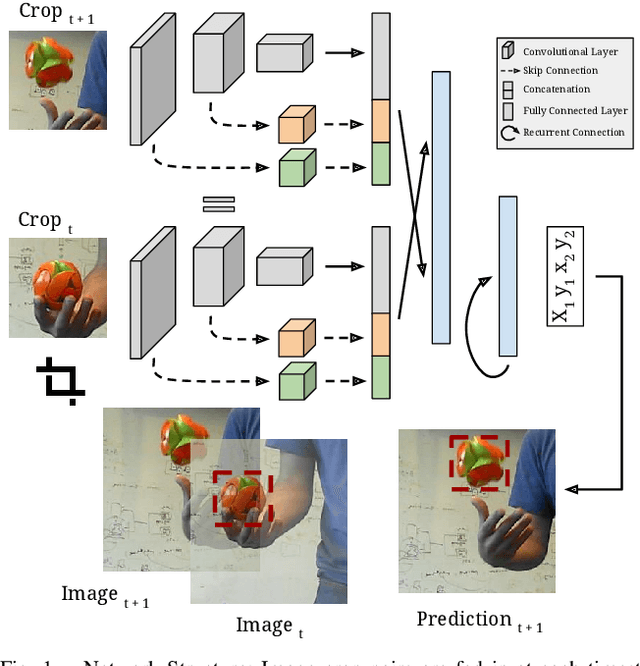
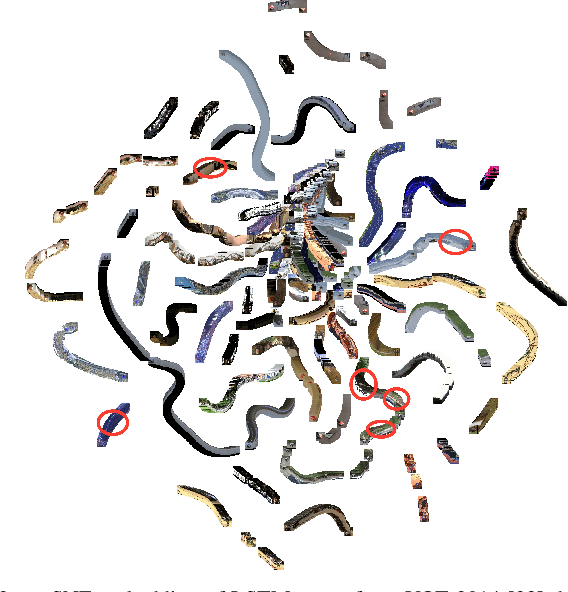
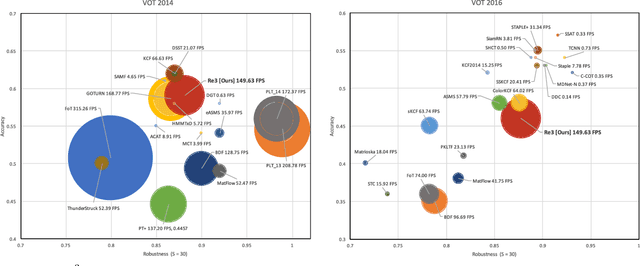
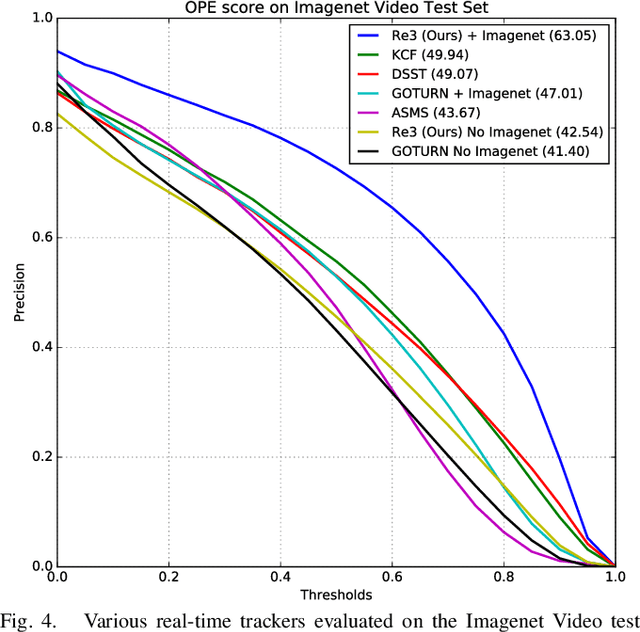
Robust object tracking requires knowledge and understanding of the object being tracked: its appearance, its motion, and how it changes over time. A tracker must be able to modify its underlying model and adapt to new observations. We present Re3, a real-time deep object tracker capable of incorporating temporal information into its model. Rather than focusing on a limited set of objects or training a model at test-time to track a specific instance, we pretrain our generic tracker on a large variety of objects and efficiently update on the fly; Re3 simultaneously tracks and updates the appearance model with a single forward pass. This lightweight model is capable of tracking objects at 150 FPS, while attaining competitive results on challenging benchmarks. We also show that our method handles temporary occlusion better than other comparable trackers using experiments that directly measure performance on sequences with occlusion.
* Presented at ICRA 2018
Model Learning with Personalized Interpretability Estimation (ML-PIE)
Apr 14, 2021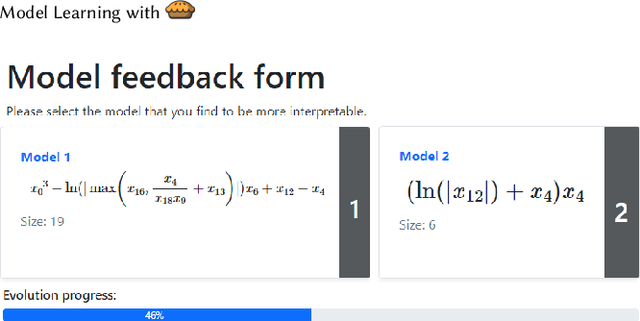
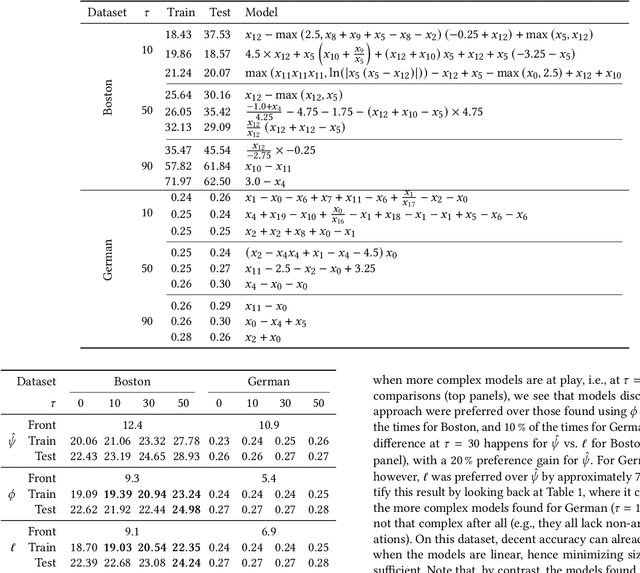
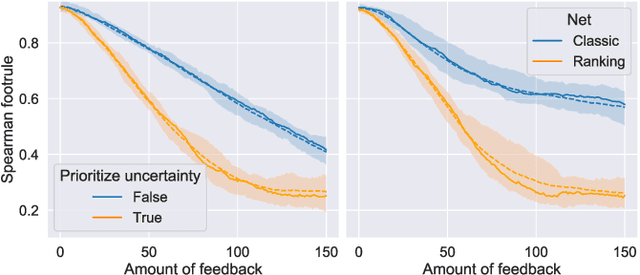
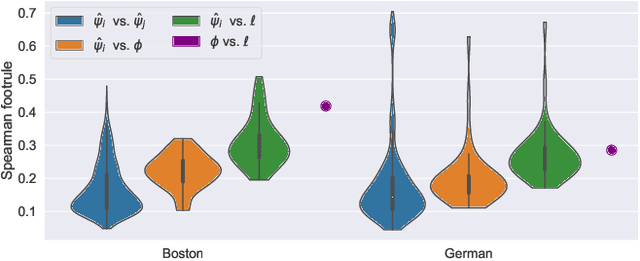
High-stakes applications require AI-generated models to be interpretable. Current algorithms for the synthesis of potentially interpretable models rely on objectives or regularization terms that represent interpretability only coarsely (e.g., model size) and are not designed for a specific user. Yet, interpretability is intrinsically subjective. In this paper, we propose an approach for the synthesis of models that are tailored to the user by enabling the user to steer the model synthesis process according to her or his preferences. We use a bi-objective evolutionary algorithm to synthesize models with trade-offs between accuracy and a user-specific notion of interpretability. The latter is estimated by a neural network that is trained concurrently to the evolution using the feedback of the user, which is collected using uncertainty-based active learning. To maximize usability, the user is only asked to tell, given two models at the time, which one is less complex. With experiments on two real-world datasets involving 61 participants, we find that our approach is capable of learning estimations of interpretability that can be very different for different users. Moreover, the users tend to prefer models found using the proposed approach over models found using non-personalized interpretability indices.
On the Applicability of Synthetic Data for Face Recognition
Apr 06, 2021
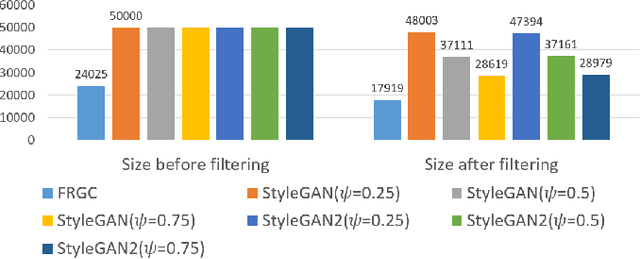
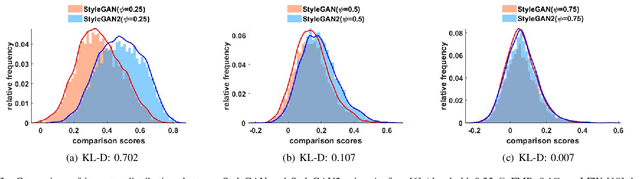
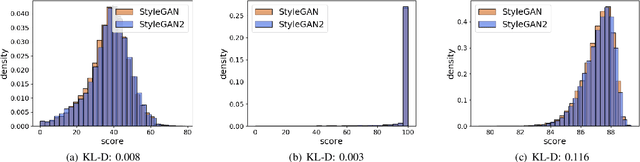
Face verification has come into increasing focus in various applications including the European Entry/Exit System, which integrates face recognition mechanisms. At the same time, the rapid advancement of biometric authentication requires extensive performance tests in order to inhibit the discriminatory treatment of travellers due to their demographic background. However, the use of face images collected as part of border controls is restricted by the European General Data Protection Law to be processed for no other reason than its original purpose. Therefore, this paper investigates the suitability of synthetic face images generated with StyleGAN and StyleGAN2 to compensate for the urgent lack of publicly available large-scale test data. Specifically, two deep learning-based (SER-FIQ, FaceQnet v1) and one standard-based (ISO/IEC TR 29794-5) face image quality assessment algorithm is utilized to compare the applicability of synthetic face images compared to real face images extracted from the FRGC dataset. Finally, based on the analysis of impostor score distributions and utility score distributions, our experiments reveal negligible differences between StyleGAN vs. StyleGAN2, and further also minor discrepancies compared to real face images.
Secure 3D medical Imaging
Oct 06, 2020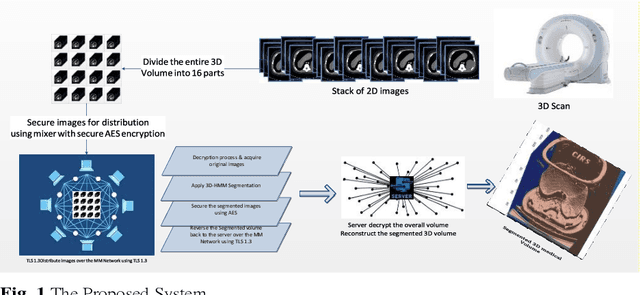
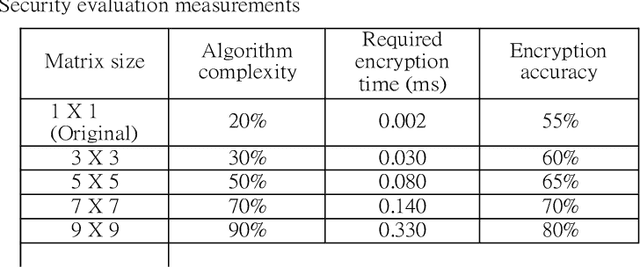

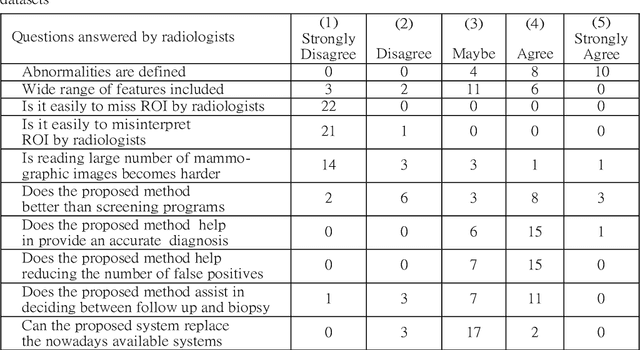
Image segmentation has proved its importance and plays an important role in various domains such as health systems and satellite-oriented military applications. In this context, accuracy, image quality, and execution time deem to be the major issues to always consider. Although many techniques have been applied, and their experimental results have shown appealing achievements for 2D images in real-time environments, however, there is a lack of works about 3D image segmentation despite its importance in improving segmentation accuracy. Specifically, HMM was used in this domain. However, it suffers from the time complexity, which was updated using different accelerators. As it is important to have efficient 3D image segmentation, we propose in this paper a novel system for partitioning the 3D segmentation process across several distributed machines. The concepts behind distributed multi-media network segmentation were employed to accelerate the segmentation computational time of training Hidden Markov Model (HMMs). Furthermore, a secure transmission has been considered in this distributed environment and various bidirectional multimedia security algorithms have been applied. The contribution of this work lies in providing an efficient and secure algorithm for 3D image segmentation. Through a number of extensive experiments, it was proved that our proposed system is of comparable efficiency to the state of art methods in terms of segmentation accuracy, security and execution time.
Guided Upsampling Network for Real-Time Semantic Segmentation
Jul 19, 2018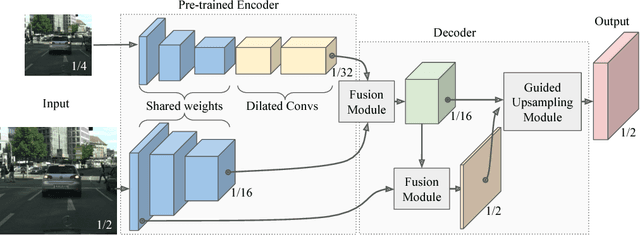
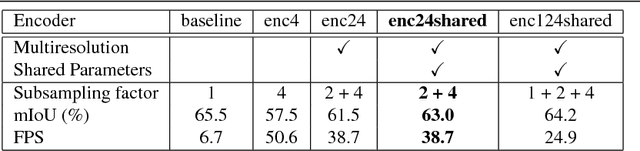
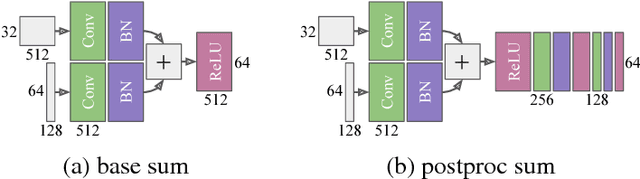
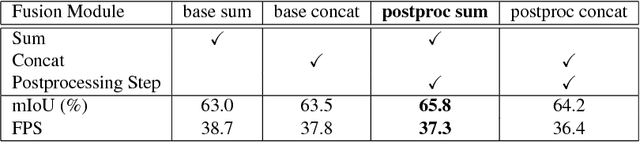
Semantic segmentation architectures are mainly built upon an encoder-decoder structure. These models perform subsequent downsampling operations in the encoder. Since operations on high-resolution activation maps are computationally expensive, usually the decoder produces output segmentation maps by upsampling with parameters-free operators like bilinear or nearest-neighbor. We propose a Neural Network named Guided Upsampling Network which consists of a multiresolution architecture that jointly exploits high-resolution and large context information. Then we introduce a new module named Guided Upsampling Module (GUM) that enriches upsampling operators by introducing a learnable transformation for semantic maps. It can be plugged into any existing encoder-decoder architecture with little modifications and low additional computation cost. We show with quantitative and qualitative experiments how our network benefits from the use of GUM module. A comprehensive set of experiments on the publicly available Cityscapes dataset demonstrates that Guided Upsampling Network can efficiently process high-resolution images in real-time while attaining state-of-the art performances.
Spectral Machine Learning for Pancreatic Mass Imaging Classification
May 03, 2021
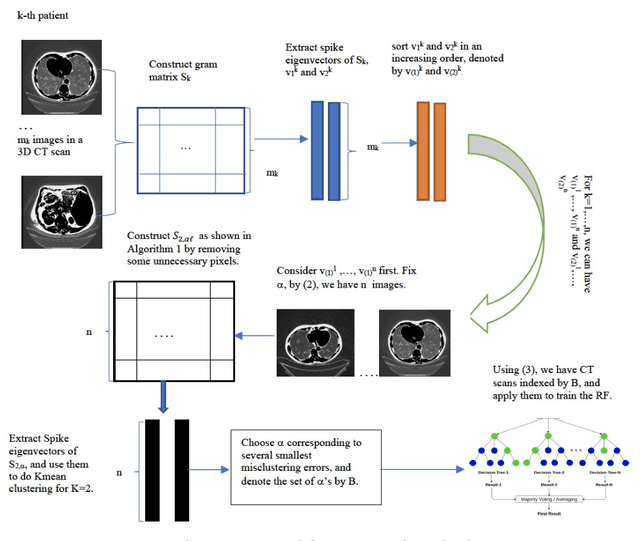
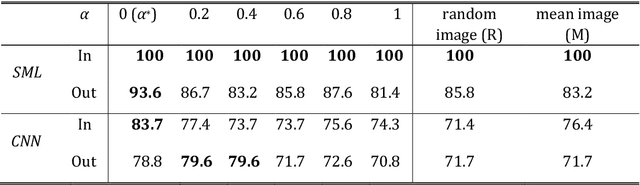
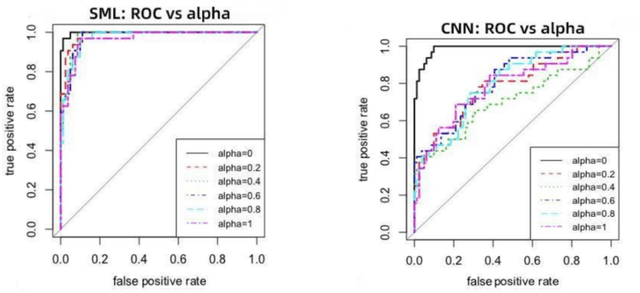
We present a novel spectral machine learning (SML) method in screening for pancreatic mass using CT imaging. Our algorithm is trained with approximately 30,000 images from 250 patients (50 patients with normal pancreas and 200 patients with abnormal pancreas findings) based on public data sources. A test accuracy of 94.6 percents was achieved in the out-of-sample diagnosis classification based on a total of approximately 15,000 images from 113 patients, whereby 26 out of 32 patients with normal pancreas and all 81 patients with abnormal pancreas findings were correctly diagnosed. SML is able to automatically choose fundamental images (on average 5 or 9 images for each patient) in the diagnosis classification and achieve the above mentioned accuracy. The computational time is 75 seconds for diagnosing 113 patients in a laptop with standard CPU running environment. Factors that influenced high performance of a well-designed integration of spectral learning and machine learning included: 1) use of eigenvectors corresponding to several of the largest eigenvalues of sample covariance matrix (spike eigenvectors) to choose input attributes in classification training, taking into account only the fundamental information of the raw images with less noise; 2) removal of irrelevant pixels based on mean-level spectral test to lower the challenges of memory capacity and enhance computational efficiency while maintaining superior classification accuracy; 3) adoption of state-of-the-art machine learning classification, gradient boosting and random forest. Our methodology showcases practical utility and improved accuracy of image diagnosis in pancreatic mass screening in the era of AI.
ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
Apr 06, 2021
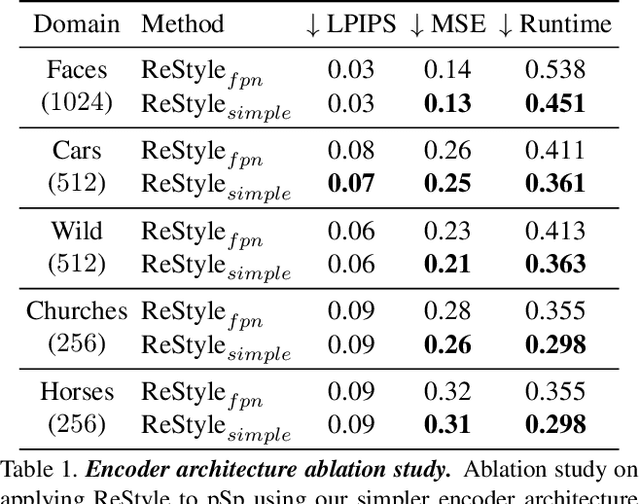
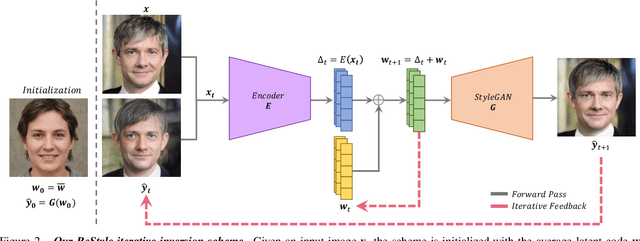
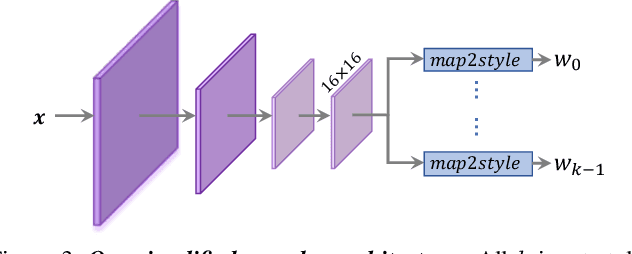
Recently, the power of unconditional image synthesis has significantly advanced through the use of Generative Adversarial Networks (GANs). The task of inverting an image into its corresponding latent code of the trained GAN is of utmost importance as it allows for the manipulation of real images, leveraging the rich semantics learned by the network. Recognizing the limitations of current inversion approaches, in this work we present a novel inversion scheme that extends current encoder-based inversion methods by introducing an iterative refinement mechanism. Instead of directly predicting the latent code of a given real image using a single pass, the encoder is tasked with predicting a residual with respect to the current estimate of the inverted latent code in a self-correcting manner. Our residual-based encoder, named ReStyle, attains improved accuracy compared to current state-of-the-art encoder-based methods with a negligible increase in inference time. We analyze the behavior of ReStyle to gain valuable insights into its iterative nature. We then evaluate the performance of our residual encoder and analyze its robustness compared to optimization-based inversion and state-of-the-art encoders.