 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Multiple Relations for Fashion Trend Forecasting Based on Social Media
May 11, 2021
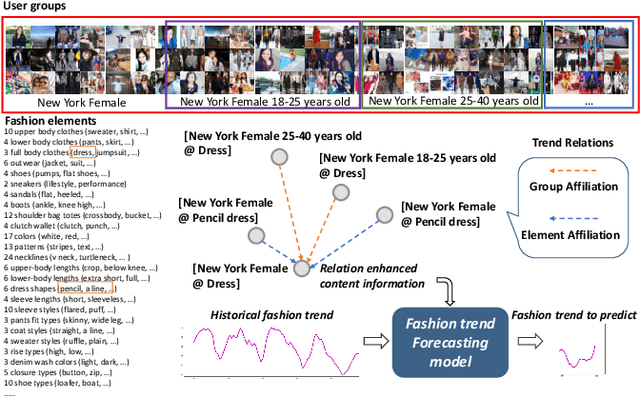
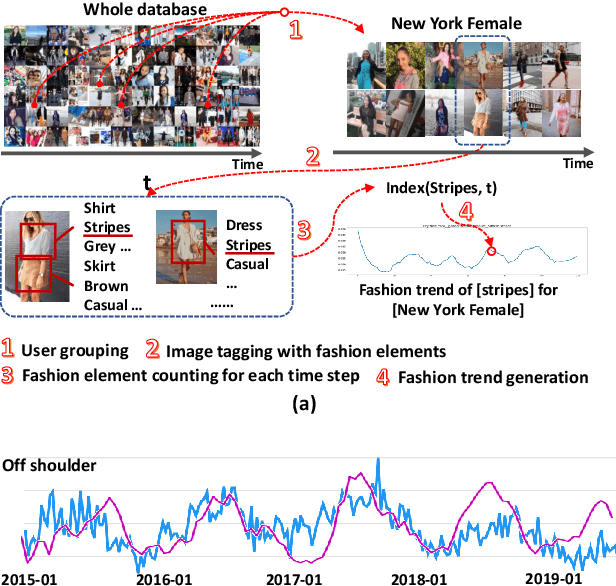
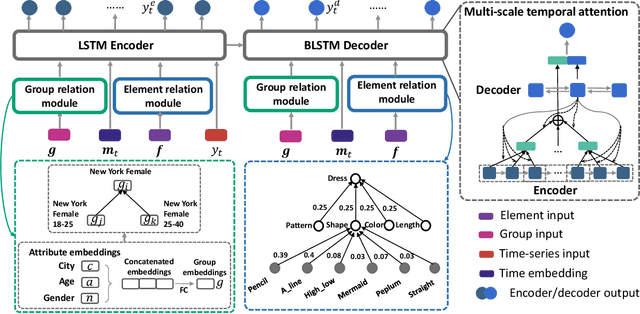
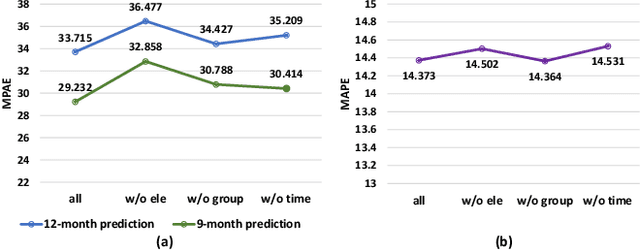
Fashion trend forecasting is of great research significance in providing useful suggestions for both fashion companies and fashion lovers. Although various studies have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real complex fashion trends. Moreover, the mainstream solutions for this task are still statistical-based and solely focus on time-series data modeling, which limit the forecast accuracy. Towards insightful fashion trend forecasting, previous work [1] proposed to analyze more fine-grained fashion elements which can informatively reveal fashion trends. Specifically, it focused on detailed fashion element trend forecasting for specific user groups based on social media data. In addition, it proposed a neural network-based method, namely KERN, to address the problem of fashion trend modeling and forecasting. In this work, to extend the previous work, we propose an improved model named Relation Enhanced Attention Recurrent (REAR) network. Compared to KERN, the REAR model leverages not only the relations among fashion elements but also those among user groups, thus capturing more types of correlations among various fashion trends. To further improve the performance of long-range trend forecasting, the REAR method devises a sliding temporal attention mechanism, which is able to capture temporal patterns on future horizons better. Extensive experiments and more analysis have been conducted on the FIT and GeoStyle datasets to evaluate the performance of REAR. Experimental and analytical results demonstrate the effectiveness of the proposed REAR model in fashion trend forecasting, which also show the improvement of REAR compared to the KERN.
* 12 pages, 8 figures
Continual Learning on the Edge with TensorFlow Lite
May 05, 2021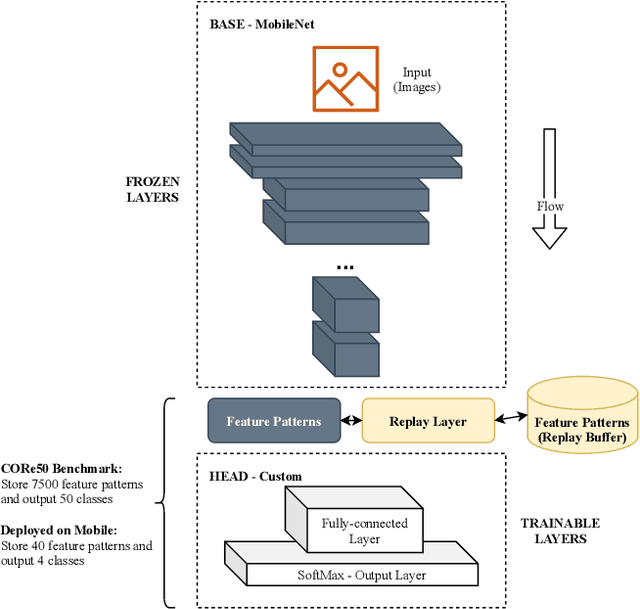
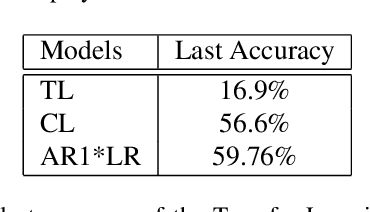
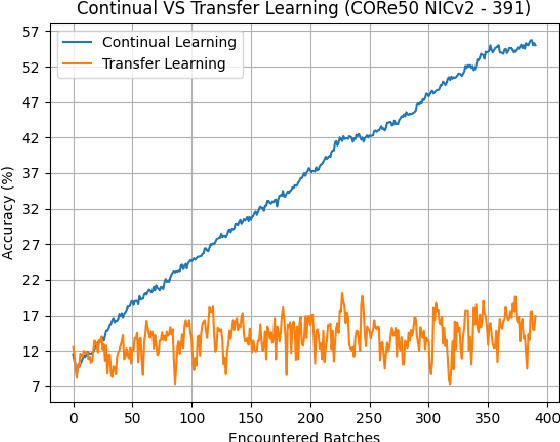
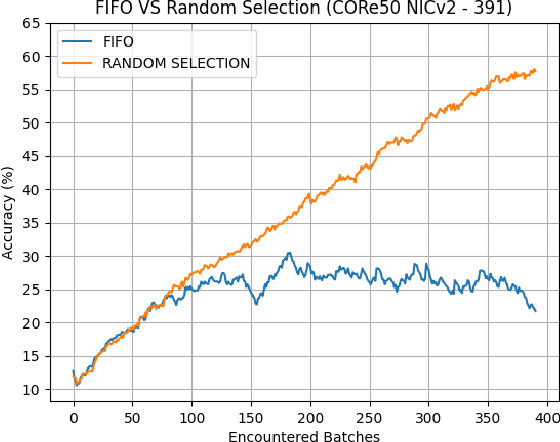
Deploying sophisticated deep learning models on embedded devices with the purpose of solving real-world problems is a struggle using today's technology. Privacy and data limitations, network connection issues, and the need for fast model adaptation are some of the challenges that constitute today's approaches unfit for many applications on the edge and make real-time on-device training a necessity. Google is currently working on tackling these challenges by embedding an experimental transfer learning API to their TensorFlow Lite, machine learning library. In this paper, we show that although transfer learning is a good first step for on-device model training, it suffers from catastrophic forgetting when faced with more realistic scenarios. We present this issue by testing a simple transfer learning model on the CORe50 benchmark as well as by demonstrating its limitations directly on an Android application we developed. In addition, we expand the TensorFlow Lite library to include continual learning capabilities, by integrating a simple replay approach into the head of the current transfer learning model. We test our continual learning model on the CORe50 benchmark to show that it tackles catastrophic forgetting, and we demonstrate its ability to continually learn, even under non-ideal conditions, using the application we developed. Finally, we open-source the code of our Android application to enable developers to integrate continual learning to their own smartphone applications, as well as to facilitate further development of continual learning functionality into the TensorFlow Lite environment.
Machine Learning Techniques for Software Quality Assurance: A Survey
Apr 29, 2021
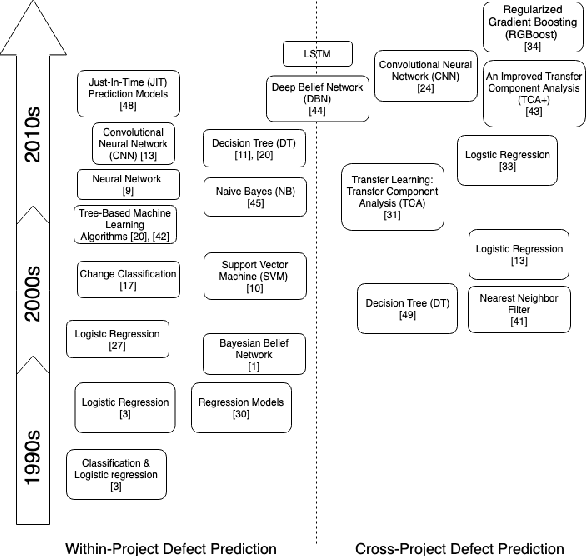
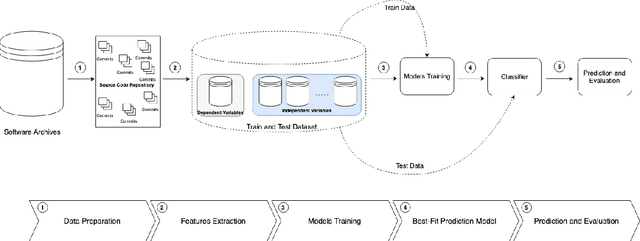
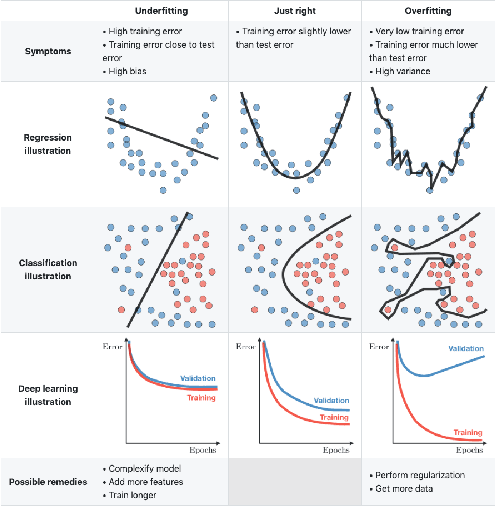
Over the last years, machine learning techniques have been applied to more and more application domains, including software engineering and, especially, software quality assurance. Important application domains have been, e.g., software defect prediction or test case selection and prioritization. The ability to predict which components in a large software system are most likely to contain the largest numbers of faults in the next release helps to better manage projects, including early estimation of possible release delays, and affordably guide corrective actions to improve the quality of the software. However, developing robust fault prediction models is a challenging task and many techniques have been proposed in the literature. Closely related to estimating defect-prone parts of a software system is the question of how to select and prioritize test cases, and indeed test case prioritization has been extensively researched as a means for reducing the time taken to discover regressions in software. In this survey, we discuss various approaches in both fault prediction and test case prioritization, also explaining how in recent studies deep learning algorithms for fault prediction help to bridge the gap between programs' semantics and fault prediction features. We also review recently proposed machine learning methods for test case prioritization (TCP), and their ability to reduce the cost of regression testing without negatively affecting fault detection capabilities.
Random Fourier Features based SLAM
Nov 01, 2020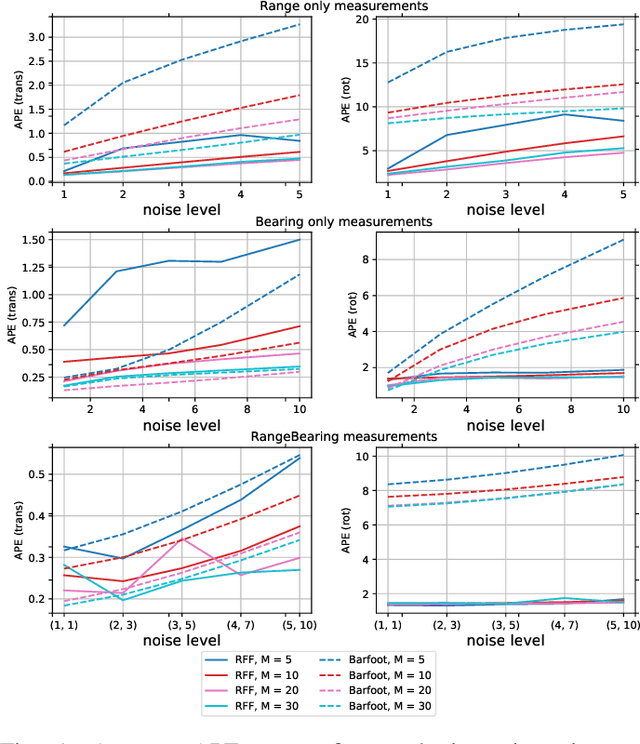
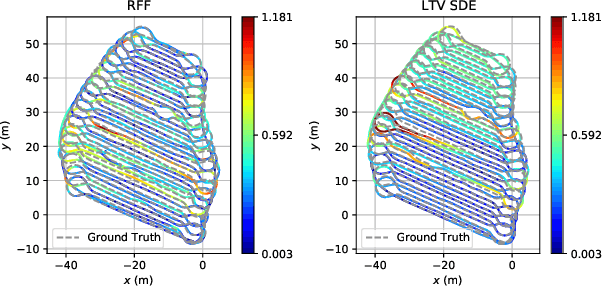
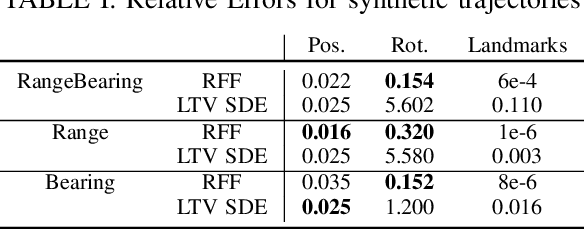
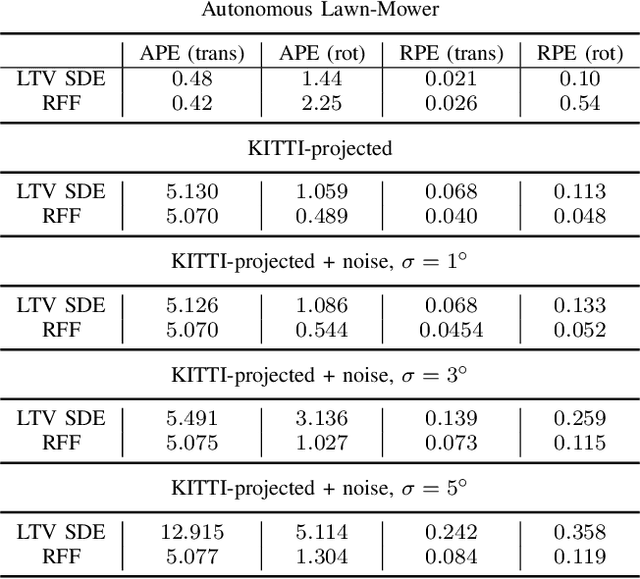
This work is dedicated to simultaneous continuous-time trajectory estimation and mapping based on Gaussian Processes (GP). State-of-the-art GP-based models for Simultaneous Localization and Mapping (SLAM) are computationally efficient but can only be used with a restricted class of kernel functions. This paper provides the algorithm based on GP with Random Fourier Features(RFF)approximation for SLAM without any constraints. The advantages of RFF for continuous-time SLAM are that we can consider a broader class of kernels and, at the same time, significantly reduce computational complexity by operating in the Fourier space of features. The additional speedup can be obtained by limiting the number of features. Our experimental results on synthetic and real-world benchmarks demonstrate the cases in which our approach provides better results compared to the current state-of-the-art.
Learned complex masks for multi-instrument source separation
Mar 23, 2021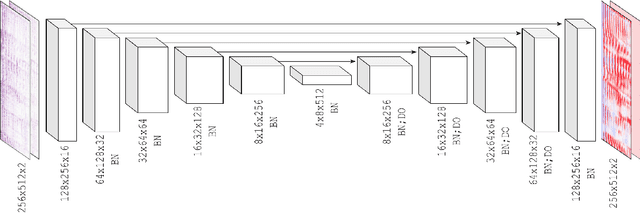
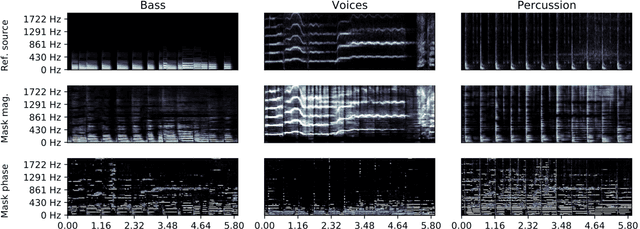
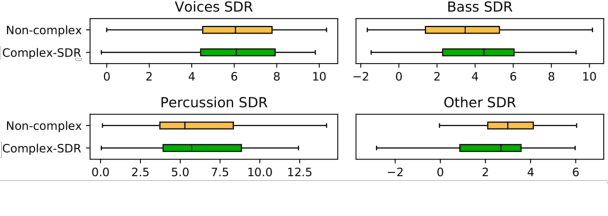
Music source separation in the time-frequency domain is commonly achieved by applying a soft or binary mask to the magnitude component of (complex) spectrograms. The phase component is usually not estimated, but instead copied from the mixture and applied to the magnitudes of the estimated isolated sources. While this method has several practical advantages, it imposes an upper bound on the performance of the system, where the estimated isolated sources inherently exhibit audible "phase artifacts". In this paper we address these shortcomings by directly estimating masks in the complex domain, extending recent work from the speech enhancement literature. The method is particularly well suited for multi-instrument musical source separation since residual phase artifacts are more pronounced for spectrally overlapping instrument sources, a common scenario in music. We show that complex masks result in better separation than masks that operate solely on the magnitude component.
CoSA: Scheduling by Constrained Optimization for Spatial Accelerators
May 05, 2021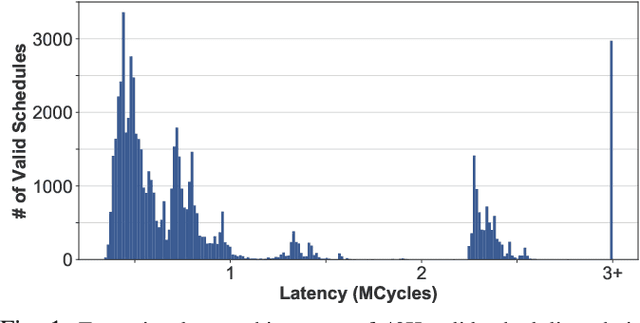
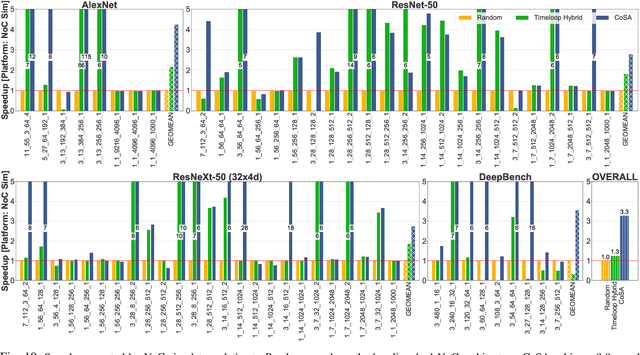
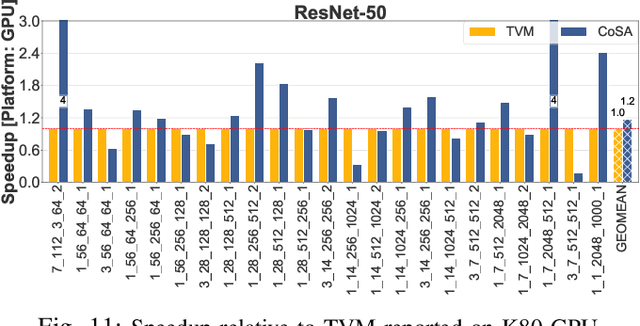
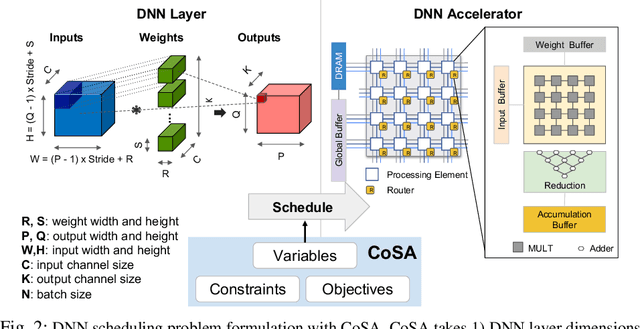
Recent advances in Deep Neural Networks (DNNs) have led to active development of specialized DNN accelerators, many of which feature a large number of processing elements laid out spatially, together with a multi-level memory hierarchy and flexible interconnect. While DNN accelerators can take advantage of data reuse and achieve high peak throughput, they also expose a large number of runtime parameters to the programmers who need to explicitly manage how computation is scheduled both spatially and temporally. In fact, different scheduling choices can lead to wide variations in performance and efficiency, motivating the need for a fast and efficient search strategy to navigate the vast scheduling space. To address this challenge, we present CoSA, a constrained-optimization-based approach for scheduling DNN accelerators. As opposed to existing approaches that either rely on designers' heuristics or iterative methods to navigate the search space, CoSA expresses scheduling decisions as a constrained-optimization problem that can be deterministically solved using mathematical optimization techniques. Specifically, CoSA leverages the regularities in DNN operators and hardware to formulate the DNN scheduling space into a mixed-integer programming (MIP) problem with algorithmic and architectural constraints, which can be solved to automatically generate a highly efficient schedule in one shot. We demonstrate that CoSA-generated schedules significantly outperform state-of-the-art approaches by a geometric mean of up to 2.5x across a wide range of DNN networks while improving the time-to-solution by 90x.
TransCenter: Transformers with Dense Queries for Multiple-Object Tracking
Mar 28, 2021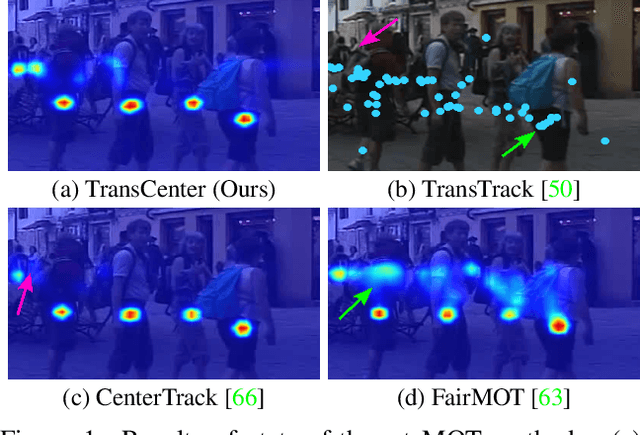
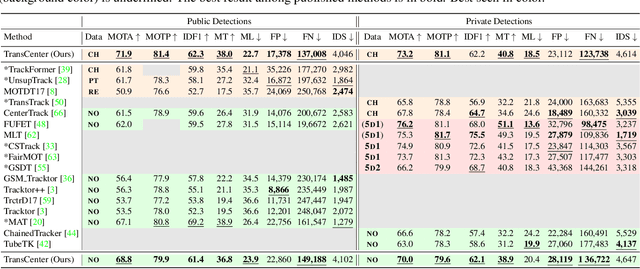
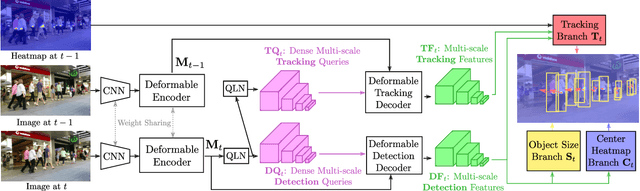
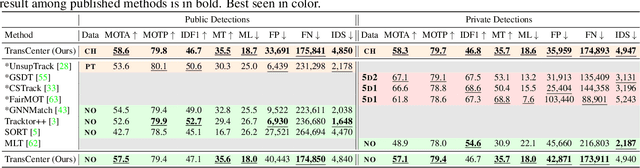
Transformer networks have proven extremely powerful for a wide variety of tasks since they were introduced. Computer vision is not an exception, as the use of transformers has become very popular in the vision community in recent years. Despite this wave, multiple-object tracking (MOT) exhibits for now some sort of incompatibility with transformers. We argue that the standard representation -- bounding boxes -- is not adapted to learning transformers for MOT. Inspired by recent research, we propose TransCenter, the first transformer-based architecture for tracking the centers of multiple targets. Methodologically, we propose the use of dense queries in a double-decoder network, to be able to robustly infer the heatmap of targets' centers and associate them through time. TransCenter outperforms the current state-of-the-art in multiple-object tracking, both in MOT17 and MOT20. Our ablation study demonstrates the advantage in the proposed architecture compared to more naive alternatives. The code will be made publicly available.
Symmetric Boolean Factor Analysis with Applications to InstaHide
Feb 02, 2021In this work we examine the security of InstaHide, a recently proposed scheme for distributed learning (Huang et al.). A number of recent works have given reconstruction attacks for InstaHide in various regimes by leveraging an intriguing connection to the following matrix factorization problem: given the Gram matrix of a collection of m random k-sparse Boolean vectors in {0,1}^r, recover the vectors (up to the trivial symmetries). Equivalently, this can be thought of as a sparse, symmetric variant of the well-studied problem of Boolean factor analysis, or as an average-case version of the classic problem of recovering a k-uniform hypergraph from its line graph. As previous algorithms either required m to be exponentially large in k or only applied to k = 2, they left open the question of whether InstaHide possesses some form of "fine-grained security" against reconstruction attacks for moderately large k. In this work, we answer this in the negative by giving a simple O(m^{\omega + 1}) time algorithm for the above matrix factorization problem. Our algorithm, based on tensor decomposition, only requires m to be at least quasi-linear in r. We complement this result with a quasipolynomial-time algorithm for a worst-case setting of the problem where the collection of k-sparse vectors is chosen arbitrarily.
Analysis of high-dimensional Continuous Time Markov Chains using the Local Bouncy Particle Sampler
Jun 03, 2019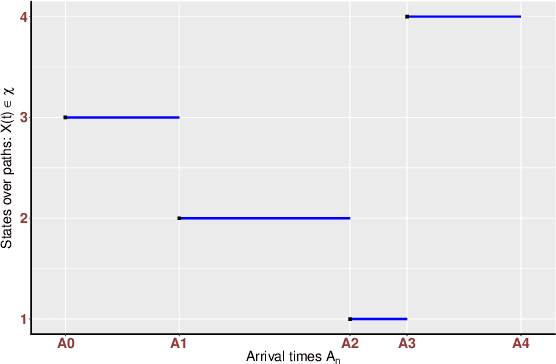

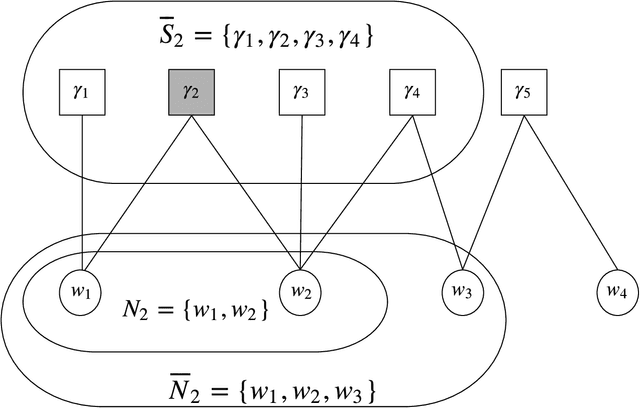

Sampling the parameters of high-dimensional Continuous Time Markov Chains (CTMC) is a challenging problem with important applications in many fields of applied statistics. In this work a recently proposed type of non-reversible rejection-free Markov Chain Monte Carlo (MCMC) sampler, the Bouncy Particle Sampler (BPS), is brought to bear to this problem. BPS has demonstrated its favorable computational efficiency compared with state-of-the-art MCMC algorithms, however to date applications to real-data scenario were scarce. An important aspect of the practical implementation of BPS is the simulation of event times. Default implementations use conservative thinning bounds. Such bounds can slow down the algorithm and limit the computational performance. Our paper develops an algorithm with an exact analytical solution to the random event times in the context of CTMCs. Our local version of BPS algorithm takes advantage of the sparse structure in the target factor graph and we also provide a framework for assessing the computational complexity of local BPS algorithms.
Agnostic Proper Learning of Halfspaces under Gaussian Marginals
Feb 10, 2021
We study the problem of agnostically learning halfspaces under the Gaussian distribution. Our main result is the {\em first proper} learning algorithm for this problem whose sample complexity and computational complexity qualitatively match those of the best known improper agnostic learner. Building on this result, we also obtain the first proper polynomial-time approximation scheme (PTAS) for agnostically learning homogeneous halfspaces. Our techniques naturally extend to agnostically learning linear models with respect to other non-linear activations, yielding in particular the first proper agnostic algorithm for ReLU regression.