 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recent Advances in Adversarial Training for Adversarial Robustness
Feb 23, 2021
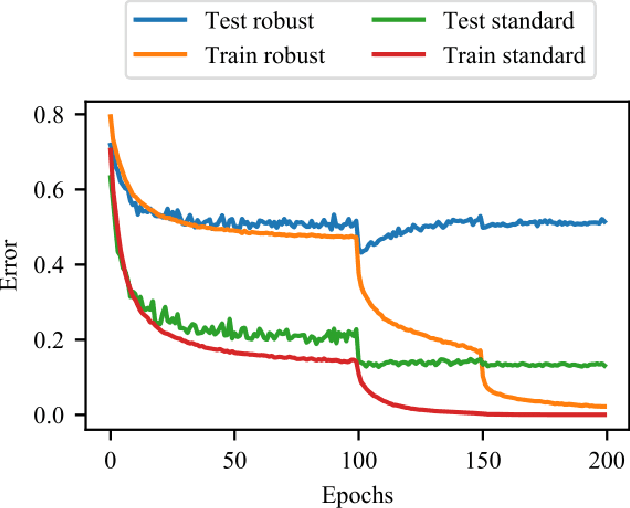
Adversarial training is one of the most effective approaches defending against adversarial examples for deep learning models. Unlike other defense strategies, adversarial training aims to promote the robustness of models intrinsically. During the last few years, adversarial training has been studied and discussed from various aspects. A variety of improvements and developments of adversarial training are proposed, which were, however, neglected in existing surveys. For the first time in this survey, we systematically review the recent progress on adversarial training for adversarial robustness with a novel taxonomy. Then we discuss the generalization problems in adversarial training from three perspectives. Finally, we highlight the challenges which are not fully tackled and present potential future directions.
Exploring Edge TPU for Network Intrusion Detection in IoT
Mar 30, 2021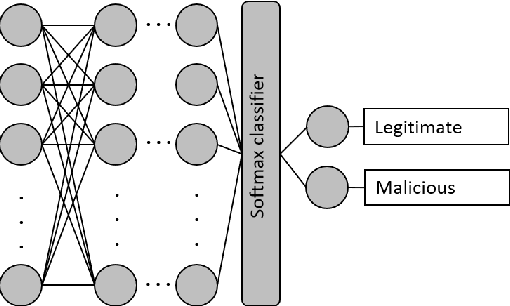
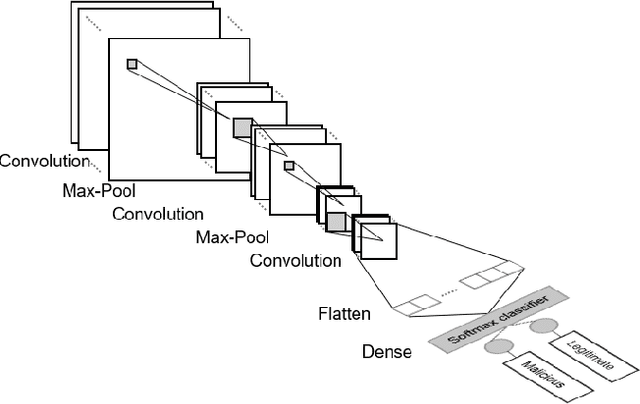

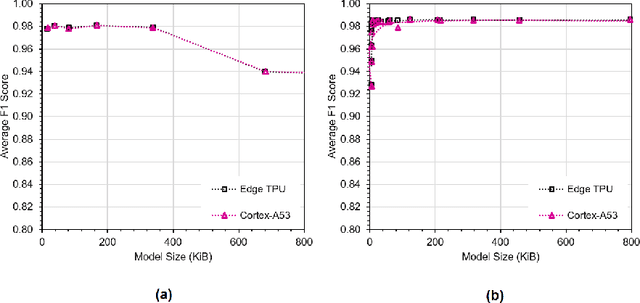
This paper explores Google's Edge TPU for implementing a practical network intrusion detection system (NIDS) at the edge of IoT, based on a deep learning approach. While there are a significant number of related works that explore machine learning based NIDS for the IoT edge, they generally do not consider the issue of the required computational and energy resources. The focus of this paper is the exploration of deep learning-based NIDS at the edge of IoT, and in particular the computational and energy efficiency. In particular, the paper studies Google's Edge TPU as a hardware platform, and considers the following three key metrics: computation (inference) time, energy efficiency and the traffic classification performance. Various scaled model sizes of two major deep neural network architectures are used to investigate these three metrics. The performance of the Edge TPU-based implementation is compared with that of an energy efficient embedded CPU (ARM Cortex A53). Our experimental evaluation shows some unexpected results, such as the fact that the CPU significantly outperforms the Edge TPU for small model sizes.
Leveraging Self-Supervision for Cross-Domain Crowd Counting
Mar 30, 2021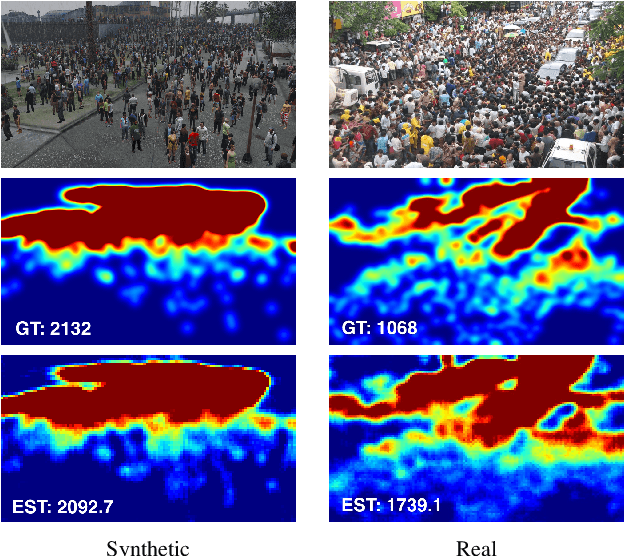
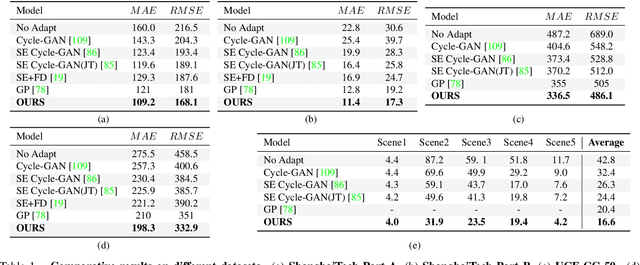
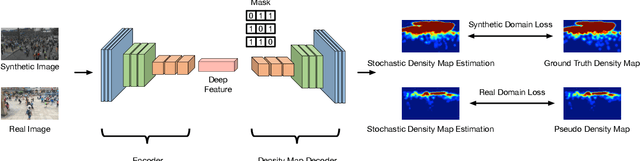
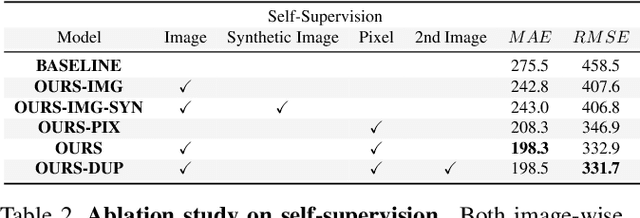
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. While effective, these data-driven approaches rely on large amount of data annotation to achieve good performance, which stops these models from being deployed in emergencies during which data annotation is either too costly or cannot be obtained fast enough. One popular solution is to use synthetic data for training. Unfortunately, due to domain shift, the resulting models generalize poorly on real imagery. We remedy this shortcoming by training with both synthetic images, along with their associated labels, and unlabeled real images. To this end, we force our network to learn perspective-aware features by training it to recognize upside-down real images from regular ones and incorporate into it the ability to predict its own uncertainty so that it can generate useful pseudo labels for fine-tuning purposes. This yields an algorithm that consistently outperforms state-of-the-art cross-domain crowd counting ones without any extra computation at inference time.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 03, 2021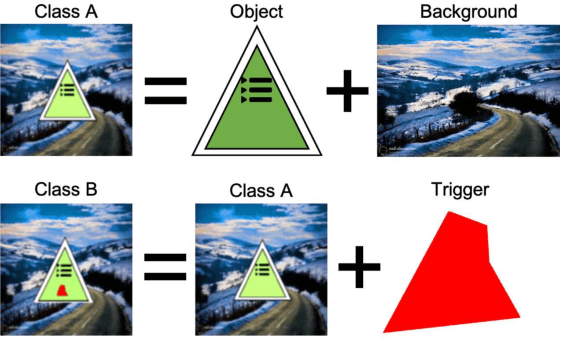

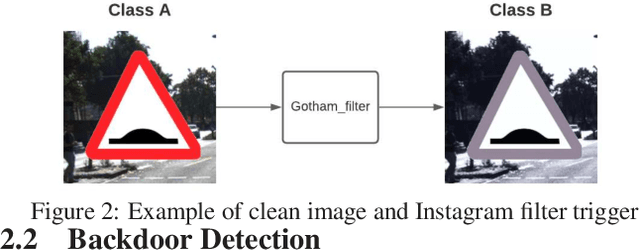
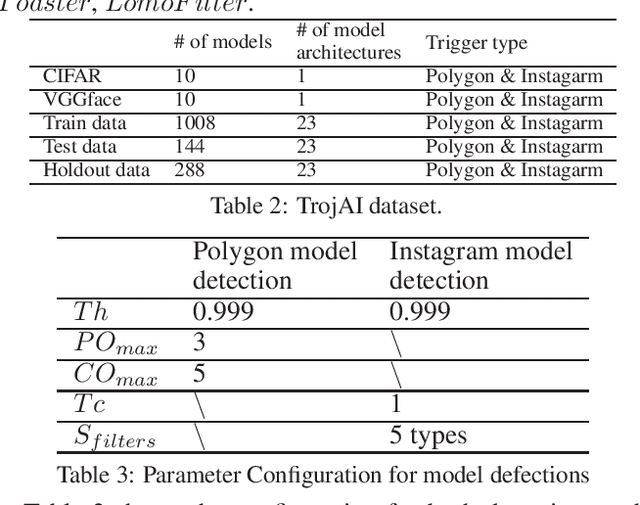
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.
Emotion Dynamics in Movie Dialogues
Mar 06, 2021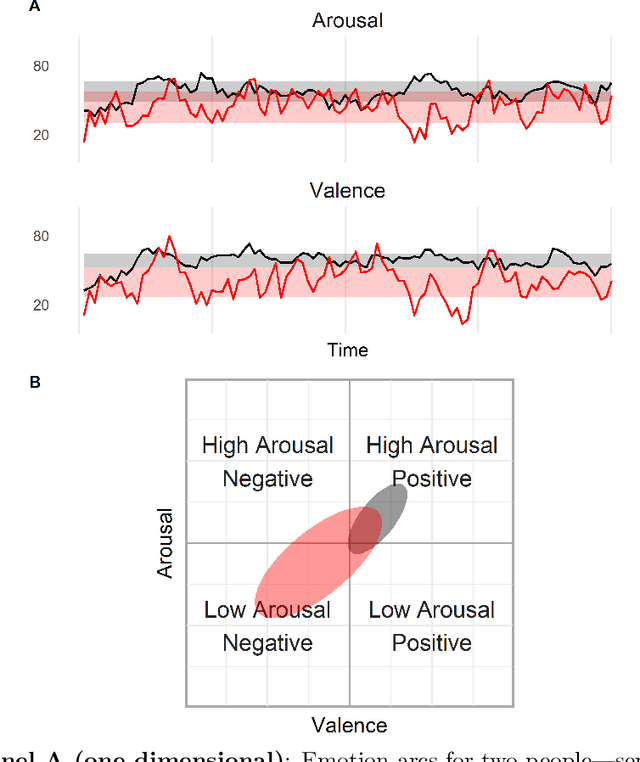
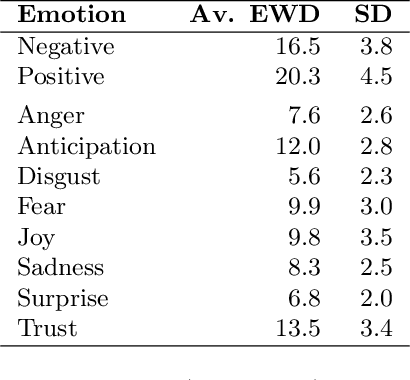
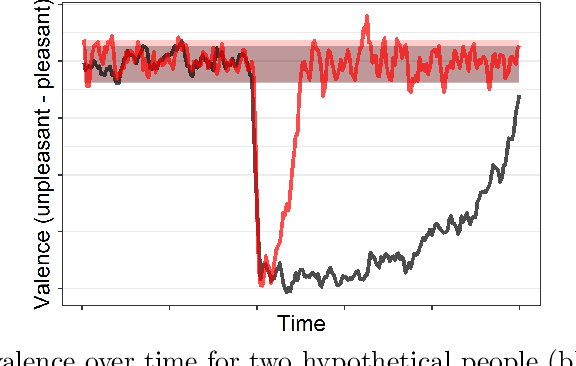
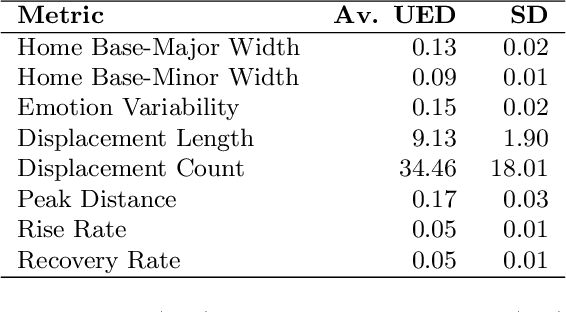
Emotion dynamics is a framework for measuring how an individual's emotions change over time. It is a powerful tool for understanding how we behave and interact with the world. In this paper, we introduce a framework to track emotion dynamics through one's utterances. Specifically we introduce a number of utterance emotion dynamics (UED) metrics inspired by work in Psychology. We use this approach to trace emotional arcs of movie characters. We analyze thousands of such character arcs to test hypotheses that inform our broader understanding of stories. Notably, we show that there is a tendency for characters to use increasingly more negative words and become increasingly emotionally discordant with each other until about 90 percent of the narrative length. UED also has applications in behavior studies, social sciences, and public health.
Learning from History for Byzantine Robust Optimization
Dec 18, 2020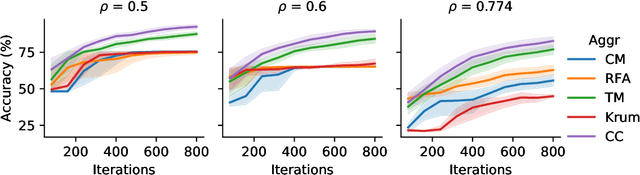
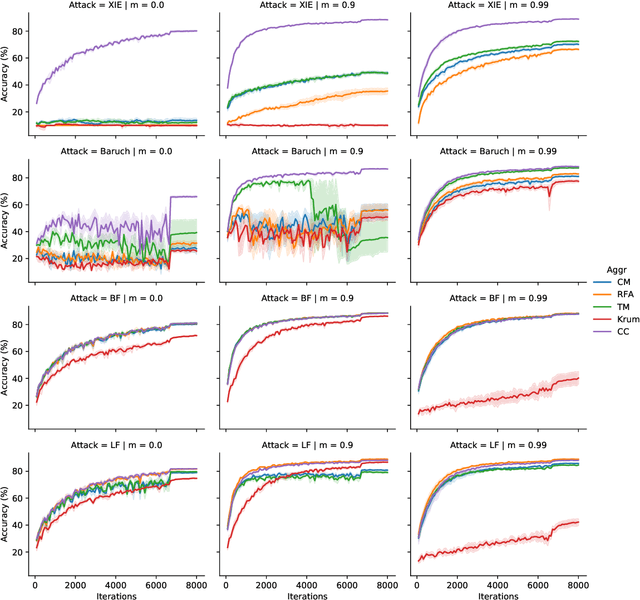
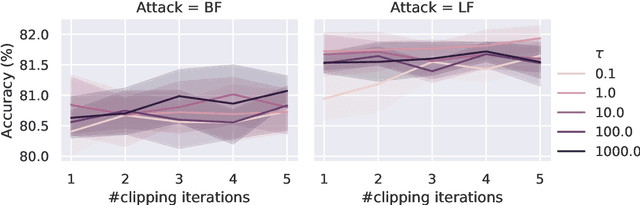
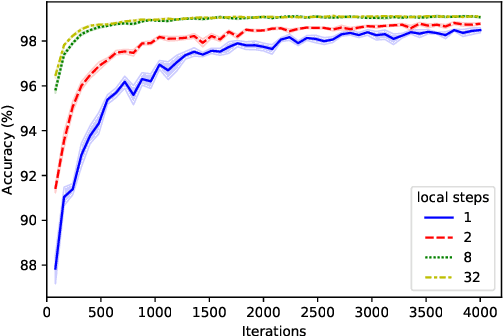
Byzantine robustness has received significant attention recently given its importance for distributed and federated learning. In spite of this, we identify severe flaws in existing algorithms even when the data across the participants is assumed to be identical. First, we show that most existing robust aggregation rules may not converge even in the absence of any Byzantine attackers, because they are overly sensitive to the distribution of the noise in the stochastic gradients. Secondly, we show that even if the aggregation rules may succeed in limiting the influence of the attackers in a single round, the attackers can couple their attacks across time eventually leading to divergence. To address these issues, we present two surprisingly simple strategies: a new iterative clipping procedure, and incorporating worker momentum to overcome time-coupled attacks. This is the first provably robust method for the standard stochastic non-convex optimization setting.
Loss Bounds and Time Complexity for Speed Priors
Apr 12, 2016This paper establishes for the first time the predictive performance of speed priors and their computational complexity. A speed prior is essentially a probability distribution that puts low probability on strings that are not efficiently computable. We propose a variant to the original speed prior (Schmidhuber, 2002), and show that our prior can predict sequences drawn from probability measures that are estimable in polynomial time. Our speed prior is computable in doubly-exponential time, but not in polynomial time. On a polynomial time computable sequence our speed prior is computable in exponential time. We show better upper complexity bounds for Schmidhuber's speed prior under the same conditions, and that it predicts deterministic sequences that are computable in polynomial time; however, we also show that it is not computable in polynomial time, and the question of its predictive properties for stochastic sequences remains open.
Universal and Flexible Optical Aberration Correction Using Deep-Prior Based Deconvolution
Apr 07, 2021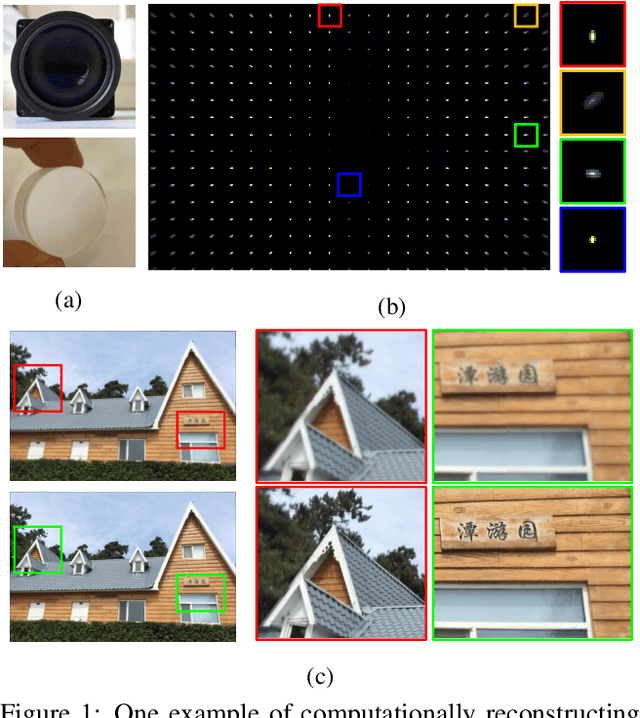

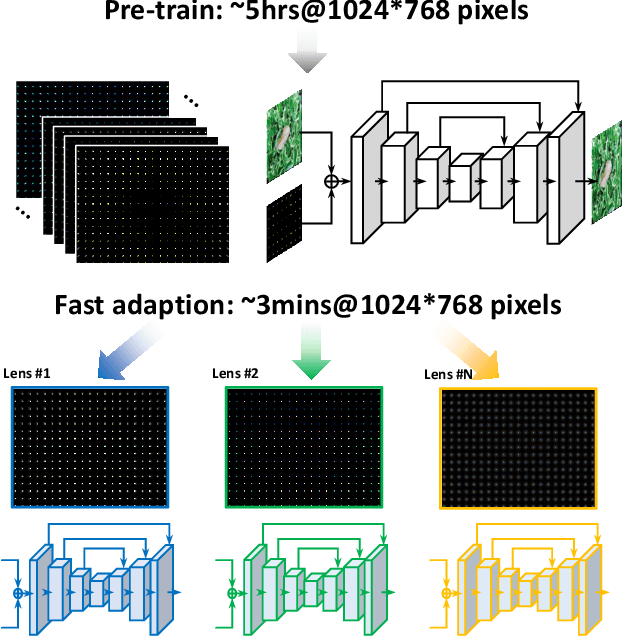
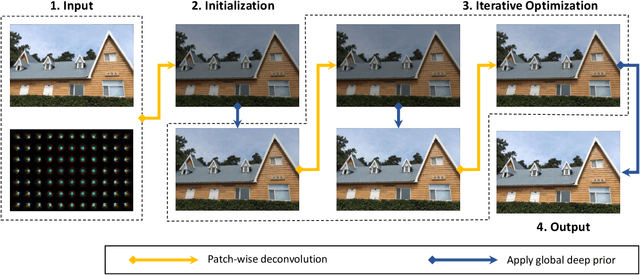
High quality imaging usually requires bulky and expensive lenses to compensate geometric and chromatic aberrations. This poses high constraints on the optical hash or low cost applications. Although one can utilize algorithmic reconstruction to remove the artifacts of low-end lenses, the degeneration from optical aberrations is spatially varying and the computation has to trade off efficiency for performance. For example, we need to conduct patch-wise optimization or train a large set of local deep neural networks to achieve high reconstruction performance across the whole image. In this paper, we propose a PSF aware plug-and-play deep network, which takes the aberrant image and PSF map as input and produces the latent high quality version via incorporating lens-specific deep priors, thus leading to a universal and flexible optical aberration correction method. Specifically, we pre-train a base model from a set of diverse lenses and then adapt it to a given lens by quickly refining the parameters, which largely alleviates the time and memory consumption of model learning. The approach is of high efficiency in both training and testing stages. Extensive results verify the promising applications of our proposed approach for compact low-end cameras.
Lighting the Darkness in the Deep Learning Era
Apr 21, 2021
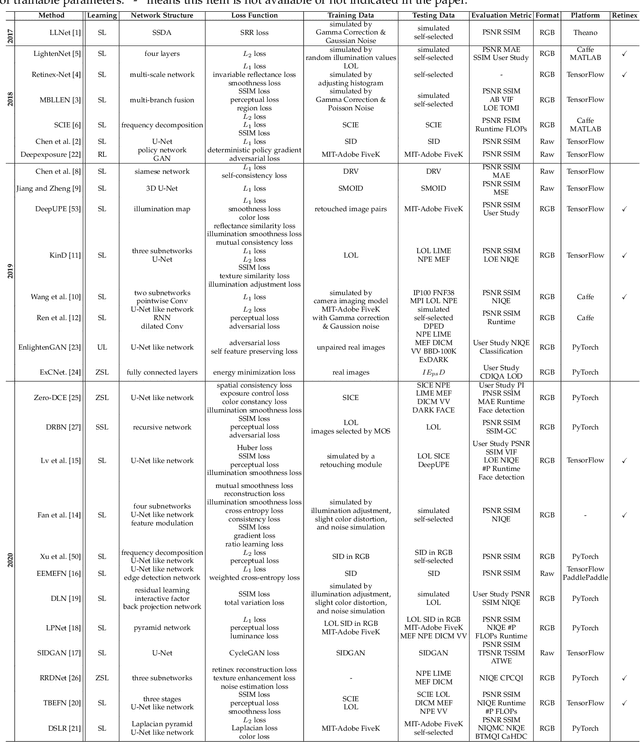

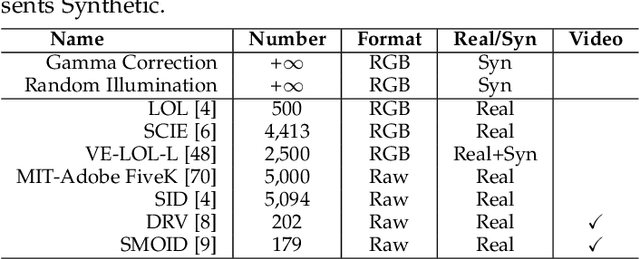
Low-light image enhancement (LLIE) aims at improving the perception or interpretability of an image captured in an environment with poor illumination. Recent advances in this area are dominated by deep learning-based solutions, where many learning strategies, network structures, loss functions, training data, etc. have been employed. In this paper, we provide a comprehensive survey to cover various aspects ranging from algorithm taxonomy to unsolved open issues. To examine the generalization of existing methods, we propose a large-scale low-light image and video dataset, in which the images and videos are taken by different mobile phones' cameras under diverse illumination conditions. Besides, for the first time, we provide a unified online platform that covers many popular LLIE methods, of which the results can be produced through a user-friendly web interface. In addition to qualitative and quantitative evaluation of existing methods on publicly available and our proposed datasets, we also validate their performance in face detection in the dark. This survey together with the proposed dataset and online platform could serve as a reference source for future study and promote the development of this research field. The proposed platform and the collected methods, datasets, and evaluation metrics are publicly available and will be regularly updated at https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open. We will release our low-light image and video dataset.
Quantified Sleep: Machine learning techniques for observational n-of-1 studies
May 14, 2021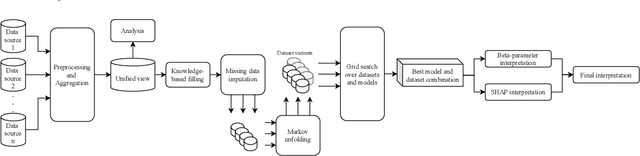
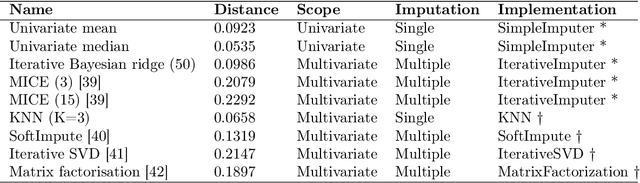
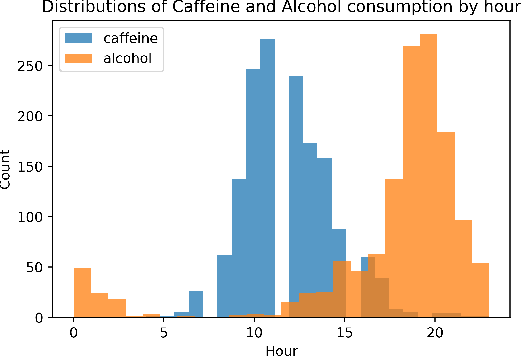
This paper applies statistical learning techniques to an observational Quantified-Self (QS) study to build a descriptive model of sleep quality. A total of 472 days of my sleep data was collected with an Oura ring and combined with lifestyle, environmental, and psychological data. Such n-of-1 QS projects pose a number of challenges: heterogeneous data sources; missing values; high dimensionality; dynamic feedback loops; human biases. This paper directly addresses these challenges with an end-to-end QS pipeline that produces robust descriptive models. Sleep quality is one of the most difficult modelling targets in QS research, due to high noise and a large number of weakly-contributing factors. Sleep quality was selected so that approaches from this paper would generalise to most other n-of-1 QS projects. Techniques are presented for combining and engineering features for the different classes of data types, sample frequencies, and schema - including event logs, weather, and geo-spatial data. Statistical analyses for outliers, normality, (auto)correlation, stationarity, and missing data are detailed, along with a proposed method for hierarchical clustering to identify correlated groups of features. The missing data was overcome using a combination of knowledge-based and statistical techniques, including several multivariate imputation algorithms. "Markov unfolding" is presented for collapsing the time series into a collection of independent observations, whilst incorporating historical information. The final model was interpreted in two ways: by inspecting the internal $\beta$-parameters, and using the SHAP framework. These two interpretation techniques were combined to produce a list of the 16 most-predictive features, demonstrating that an observational study can greatly narrow down the number of features that need to be considered when designing interventional QS studies.