 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Multiple Relations for Fashion TrendForecasting Based on Social Media
May 07, 2021
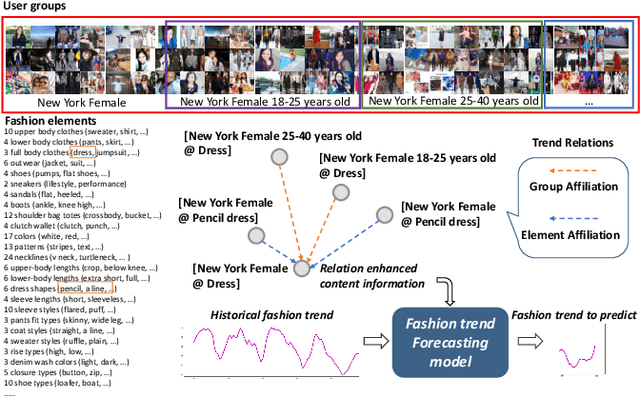
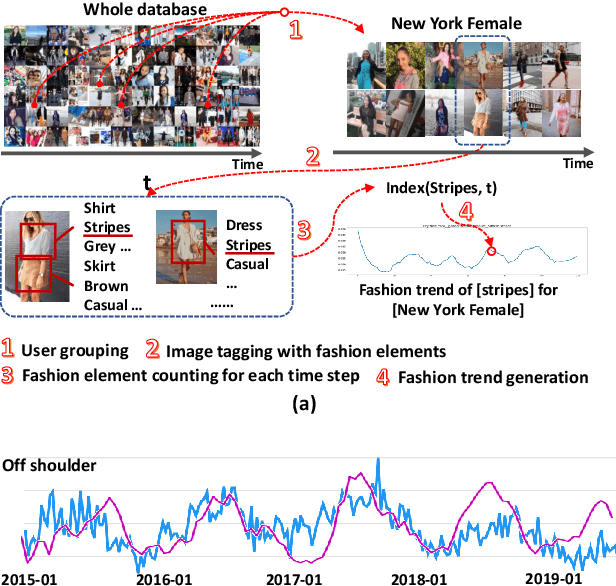
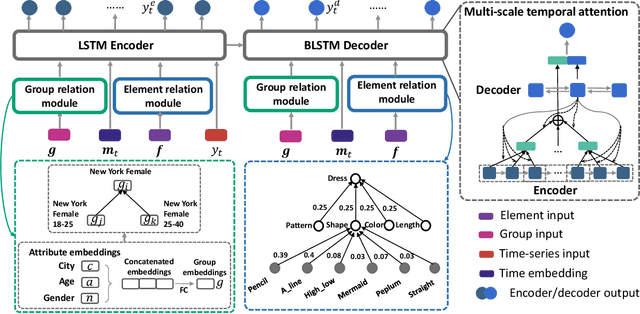
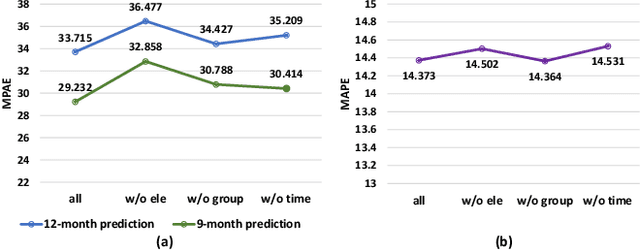
Fashion trend forecasting is of great research significance in providing useful suggestions for both fashion companies and fashion lovers. Although various studies have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real complex fashion trends. Moreover, the mainstream solutions for this task are still statistical-based and solely focus on time-series data modeling, which limit the forecast accuracy. Towards insightful fashion trend forecasting, previous work [1] proposed to analyze more fine-grained fashion elements which can informatively reveal fashion trends. Specifically, it focused on detailed fashion element trend forecasting for specific user groups based on social media data. In addition, it proposed a neural network-based method, namely KERN, to address the problem of fashion trend modeling and forecasting. In this work, to extend the previous work, we propose an improved model named Relation Enhanced Attention Recurrent (REAR) network. Compared to KERN, the REAR model leverages not only the relations among fashion elements but also those among user groups, thus capturing more types of correlations among various fashion trends. To further improve the performance of long-range trend forecasting, the REAR method devises a sliding temporal attention mechanism, which is able to capture temporal patterns on future horizons better. Extensive experiments and more analysis have been conducted on the FIT and GeoStyle datasets to evaluate the performance of REAR. Experimental and analytical results demonstrate the effectiveness of the proposed REAR model in fashion trend forecasting, which also show the improvement of REAR compared to the KERN.
TagMe: GPS-Assisted Automatic Object Annotation in Videos
Mar 24, 2021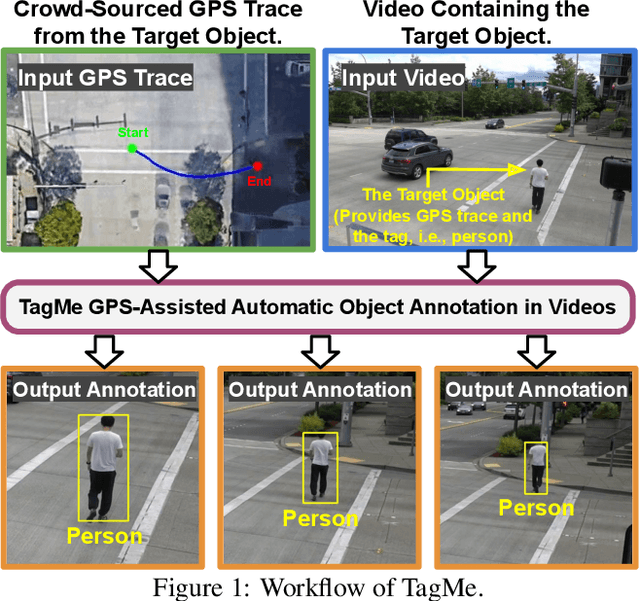
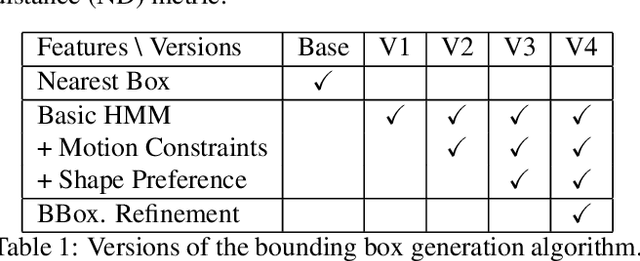

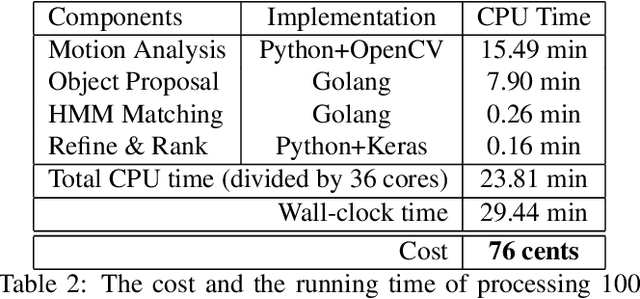
Training high-accuracy object detection models requires large and diverse annotated datasets. However, creating these data-sets is time-consuming and expensive since it relies on human annotators. We design, implement, and evaluate TagMe, a new approach for automatic object annotation in videos that uses GPS data. When the GPS trace of an object is available, TagMe matches the object's motion from GPS trace and the pixels' motions in the video to find the pixels belonging to the object in the video and creates the bounding box annotations of the object. TagMe works using passive data collection and can continuously generate new object annotations from outdoor video streams without any human annotators. We evaluate TagMe on a dataset of 100 video clips. We show TagMe can produce high-quality object annotations in a fully-automatic and low-cost way. Compared with the traditional human-in-the-loop solution, TagMe can produce the same amount of annotations at a much lower cost, e.g., up to 110x.
Efficient Multi-Objective Optimization for Deep Learning
Mar 24, 2021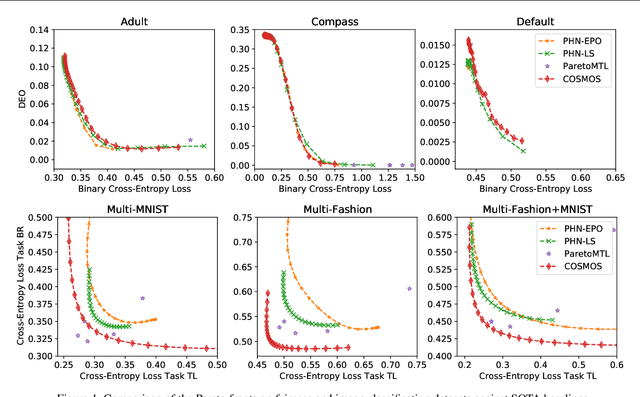
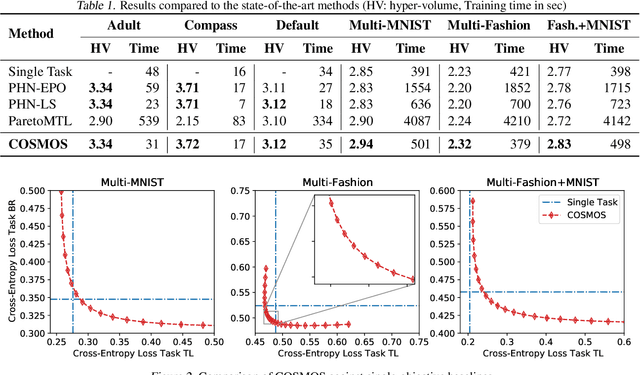
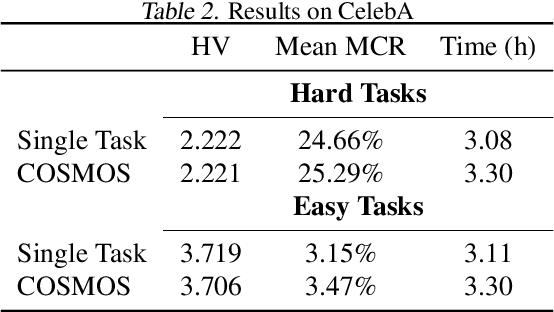
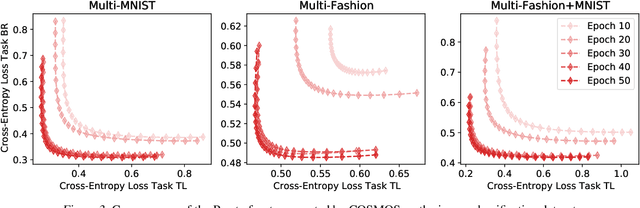
Multi-objective optimization (MOO) is a prevalent challenge for Deep Learning, however, there exists no scalable MOO solution for truly deep neural networks. Prior work either demand optimizing a new network for every point on the Pareto front, or induce a large overhead to the number of trainable parameters by using hyper-networks conditioned on modifiable preferences. In this paper, we propose to condition the network directly on these preferences by augmenting them to the feature space. Furthermore, we ensure a well-spread Pareto front by penalizing the solutions to maintain a small angle to the preference vector. In a series of experiments, we demonstrate that our Pareto fronts achieve state-of-the-art quality despite being computed significantly faster. Furthermore, we showcase the scalability as our method approximates the full Pareto front on the CelebA dataset with an EfficientNet network at a tiny training time overhead of 7% compared to a simple single-objective optimization. We make our code publicly available at https://github.com/ruchtem/cosmos.
Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Feb 26, 2018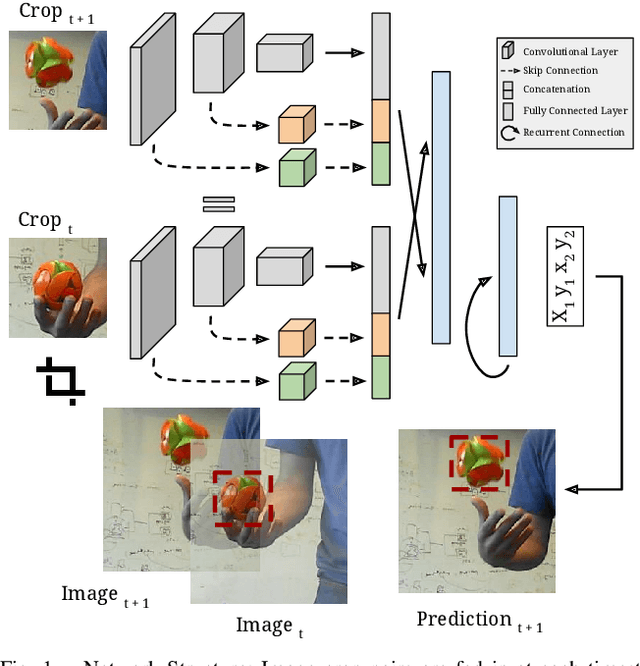
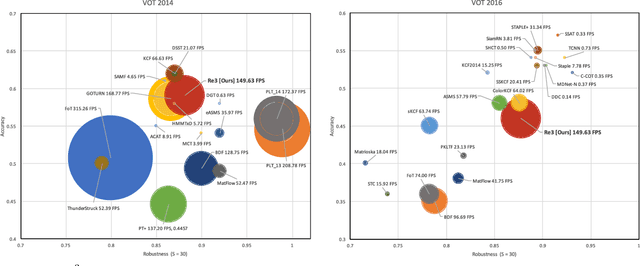
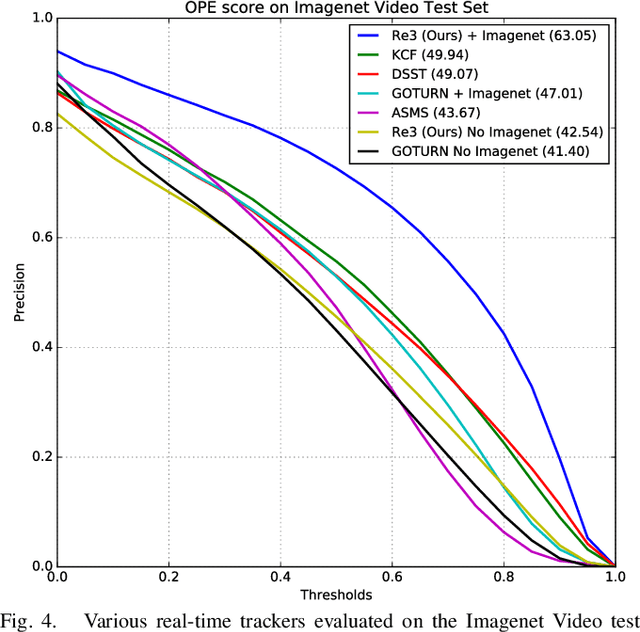
Robust object tracking requires knowledge and understanding of the object being tracked: its appearance, its motion, and how it changes over time. A tracker must be able to modify its underlying model and adapt to new observations. We present Re3, a real-time deep object tracker capable of incorporating temporal information into its model. Rather than focusing on a limited set of objects or training a model at test-time to track a specific instance, we pretrain our generic tracker on a large variety of objects and efficiently update on the fly; Re3 simultaneously tracks and updates the appearance model with a single forward pass. This lightweight model is capable of tracking objects at 150 FPS, while attaining competitive results on challenging benchmarks. We also show that our method handles temporary occlusion better than other comparable trackers using experiments that directly measure performance on sequences with occlusion.
* Presented at ICRA 2018
Control with adaptive Q-learning
Nov 03, 2020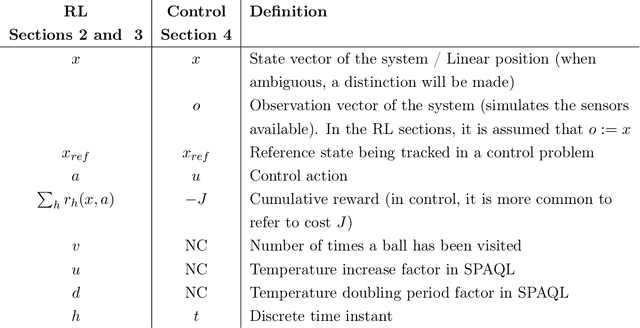
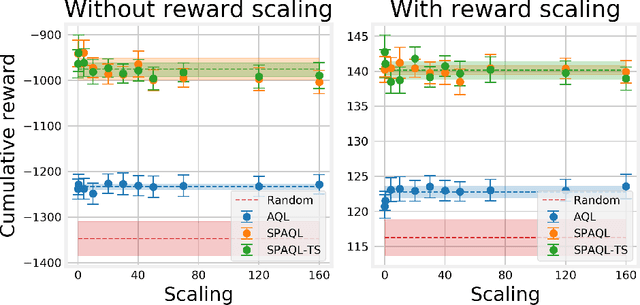

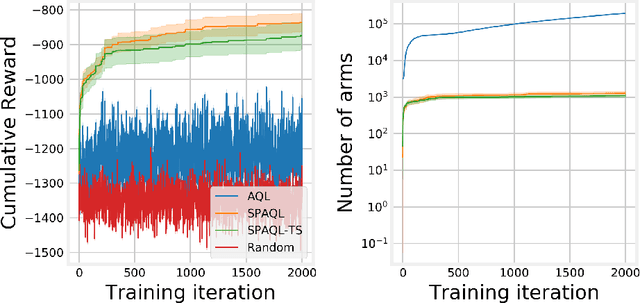
This paper evaluates adaptive Q-learning (AQL) and single-partition adaptive Q-learning (SPAQL), two algorithms for efficient model-free episodic reinforcement learning (RL), in two classical control problems (Pendulum and Cartpole). AQL adaptively partitions the state-action space of a Markov decision process (MDP), while learning the control policy, i. e., the mapping from states to actions. The main difference between AQL and SPAQL is that the latter learns time-invariant policies, where the mapping from states to actions does not depend explicitly on the time step. This paper also proposes the SPAQL with terminal state (SPAQL-TS), an improved version of SPAQL tailored for the design of regulators for control problems. The time-invariant policies are shown to result in a better performance than the time-variant ones in both problems studied. These algorithms are particularly fitted to RL problems where the action space is finite, as is the case with the Cartpole problem. SPAQL-TS solves the OpenAI Gym Cartpole problem, while also displaying a higher sample efficiency than trust region policy optimization (TRPO), a standard RL algorithm for solving control tasks. Moreover, the policies learned by SPAQL are interpretable, while TRPO policies are typically encoded as neural networks, and therefore hard to interpret. Yielding interpretable policies while being sample-efficient are the major advantages of SPAQL.
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021
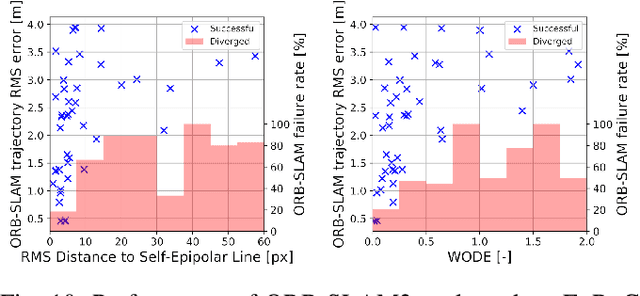

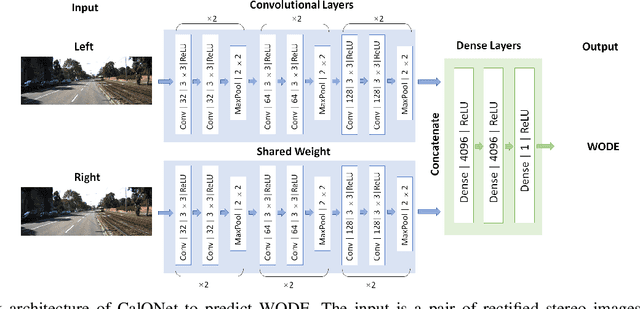
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.
AOBTM: Adaptive Online Biterm Topic Modeling for Version Sensitive Short-texts Analysis
Sep 13, 2020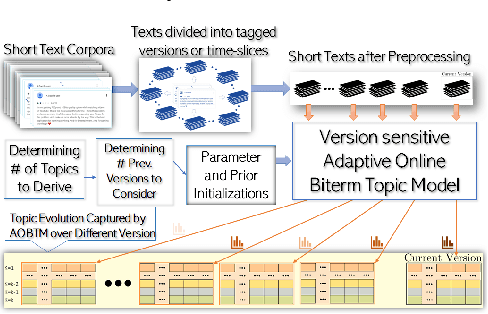
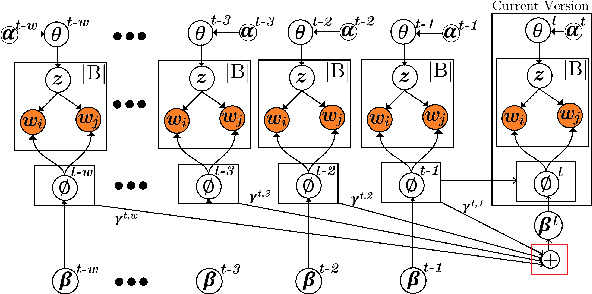
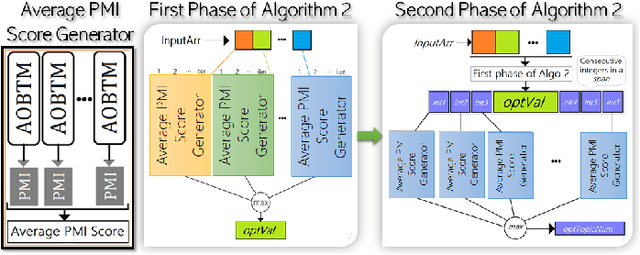
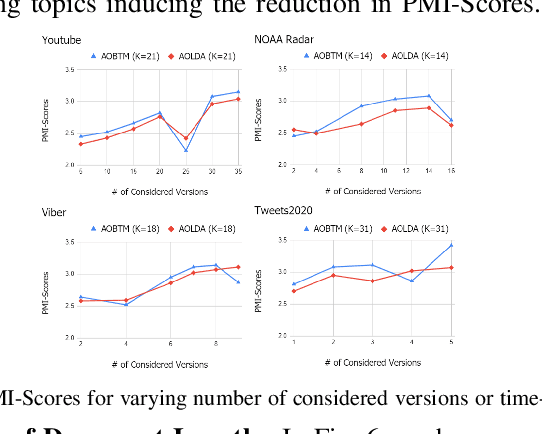
Analysis of mobile app reviews has shown its important role in requirement engineering, software maintenance and evolution of mobile apps. Mobile app developers check their users' reviews frequently to clarify the issues experienced by users or capture the new issues that are introduced due to a recent app update. App reviews have a dynamic nature and their discussed topics change over time. The changes in the topics among collected reviews for different versions of an app can reveal important issues about the app update. A main technique in this analysis is using topic modeling algorithms. However, app reviews are short texts and it is challenging to unveil their latent topics over time. Conventional topic models suffer from the sparsity of word co-occurrence patterns while inferring topics for short texts. Furthermore, these algorithms cannot capture topics over numerous consecutive time-slices. Online topic modeling algorithms speed up the inference of topic models for the texts collected in the latest time-slice by saving a fraction of data from the previous time-slice. But these algorithms do not analyze the statistical-data of all the previous time-slices, which can confer contributions to the topic distribution of the current time-slice. We propose Adaptive Online Biterm Topic Model (AOBTM) to model topics in short texts adaptively. AOBTM alleviates the sparsity problem in short-texts and considers the statistical-data for an optimal number of previous time-slices. We also propose parallel algorithms to automatically determine the optimal number of topics and the best number of previous versions that should be considered in topic inference phase. Automatic evaluation on collections of app reviews and real-world short text datasets confirm that AOBTM can find more coherent topics and outperforms the state-of-the-art baselines.
Toward Accurate Platform-Aware Performance Modeling for Deep Neural Networks
Dec 01, 2020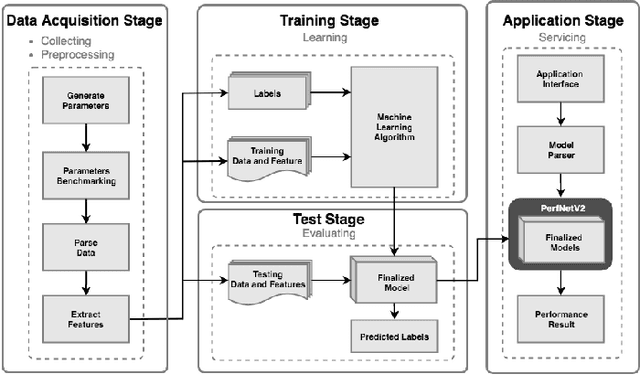
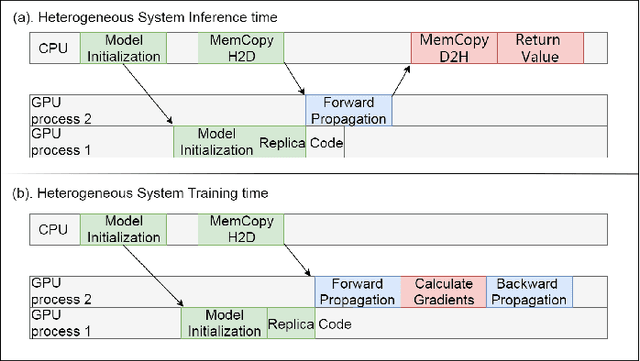
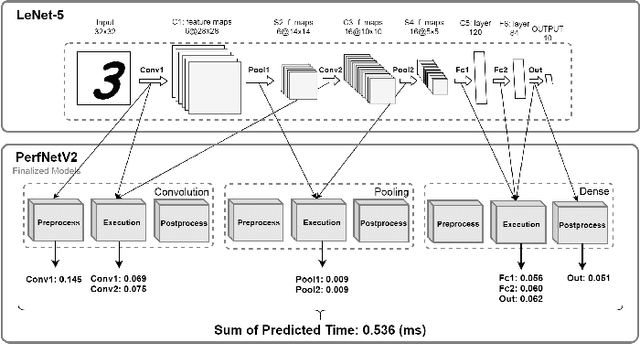
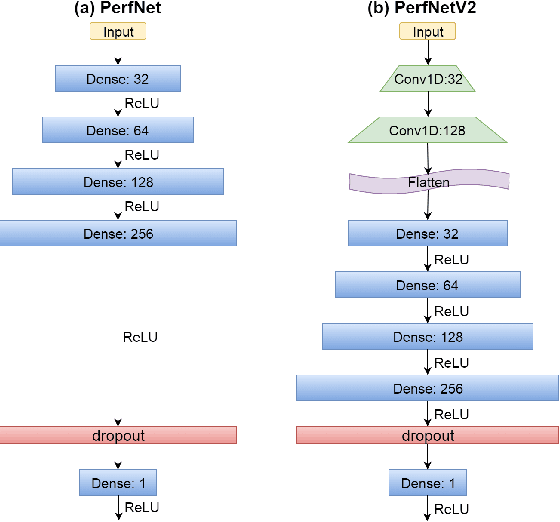
In this paper, we provide a fine-grain machine learning-based method, PerfNetV2, which improves the accuracy of our previous work for modeling the neural network performance on a variety of GPU accelerators. Given an application, the proposed method can be used to predict the inference time and training time of the convolutional neural networks used in the application, which enables the system developer to optimize the performance by choosing the neural networks and/or incorporating the hardware accelerators to deliver satisfactory results in time. Furthermore, the proposed method is capable of predicting the performance of an unseen or non-existing device, e.g. a new GPU which has a higher operating frequency with less processor cores, but more memory capacity. This allows a system developer to quickly search the hardware design space and/or fine-tune the system configuration. Compared to the previous works, PerfNetV2 delivers more accurate results by modeling detailed host-accelerator interactions in executing the full neural networks and improving the architecture of the machine learning model used in the predictor. Our case studies show that PerfNetV2 yields a mean absolute percentage error within 13.1% on LeNet, AlexNet, and VGG16 on NVIDIA GTX-1080Ti, while the error rate on a previous work published in ICBD 2018 could be as large as 200%.
Data Processing for Short-Term Solar Irradiance Forecasting using Ground-Based Infrared Images
Jan 21, 2021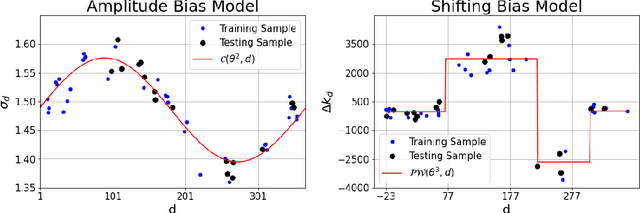
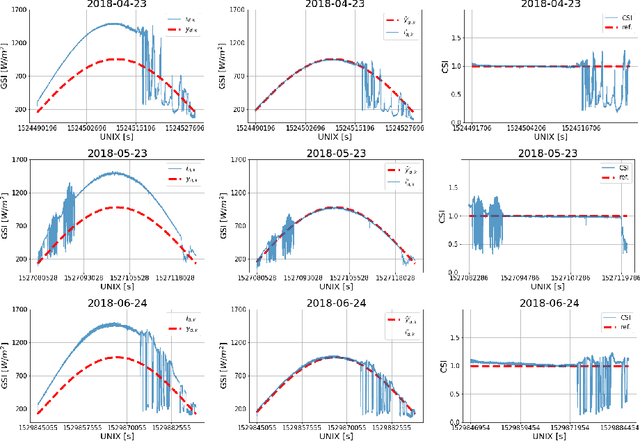
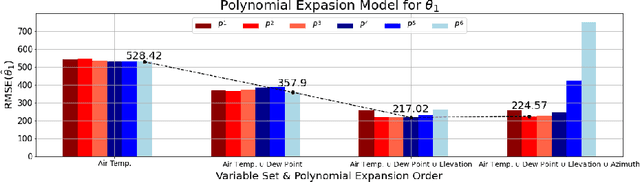
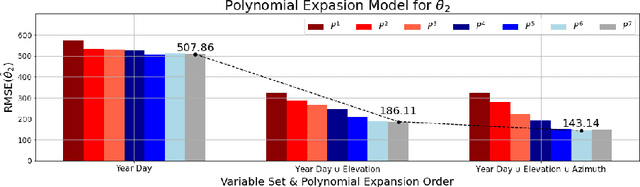
The generation of energy in a power grid which uses Photovoltaic (PV) systems depends on the projection of shadows from moving clouds in the Troposphere. This investigation proposes an efficient method of data processing for the statistical quantification of cloud features using long-wave infrared (IR) images and Global Solar Irradiance (GSI) measurements. The IR images are obtained using a data acquisition system (DAQ) mounted on a solar tracker. We explain how to remove cyclostationary biases in GSI measurements. Seasonal trends are removed from the GSI time series, using the theoretical GSI to obtain the Clear-Sky Index (CSI) time series. We introduce an atmospheric model to remove from IR images both the effect of atmosphere scatter irradiance and the effect of the Sun's direct irradiance. Scattering is produced by water spots and dust particles on the germanium lens of the enclosure. We explain how to remove the scattering effect produced by the germanium lens attached to the DAQ enclosure window of the IR camera. An atmospheric condition model classifies the sky-conditions in four different categories: clear-sky, cumulus, stratus and nimbus. When an IR image is classified in the category of clear-sky, it is used to model the scattering effect of the germanium lens.
Classification of Urban Morphology with Deep Learning: Application on Urban Vitality
May 07, 2021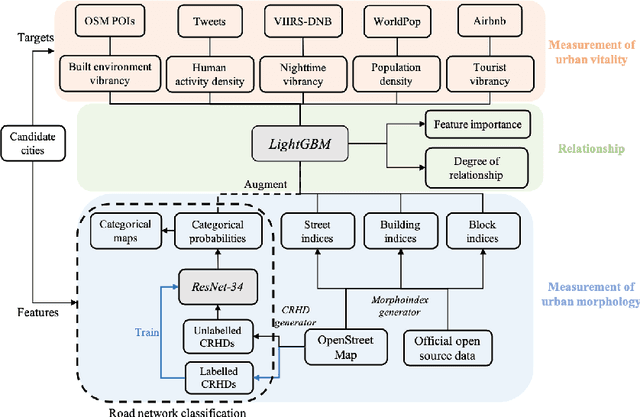
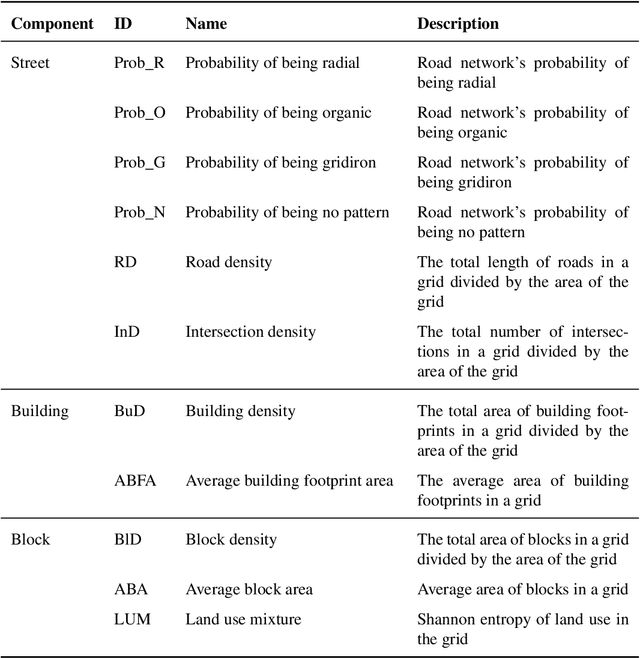
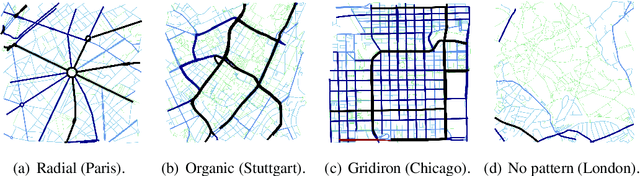
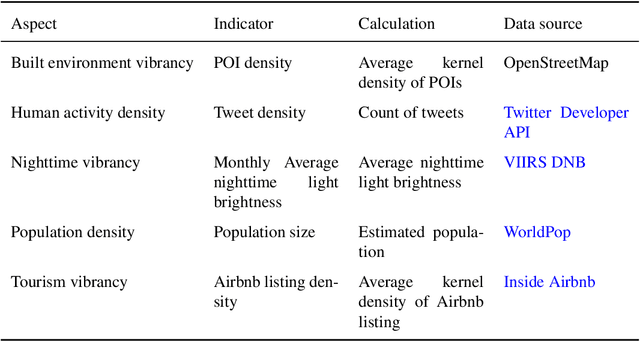
There is a prevailing trend to study urban morphology quantitatively thanks to the growing accessibility to various forms of spatial big data, increasing computing power, and use cases benefiting from such information. The methods developed up to now measure urban morphology with numerical indices describing density, proportion, and mixture, but they do not directly represent morphological features from human's visual and intuitive perspective. We take the first step to bridge the gap by proposing a deep learning-based technique to automatically classify road networks into four classes on a visual basis. The method is implemented by generating an image of the street network (Colored Road Hierarchy Diagram), which we introduce in this paper, and classifying it using a deep convolutional neural network (ResNet-34). The model achieves an overall classification accuracy of 0.875. Nine cities around the world are selected as the study areas and their road networks are acquired from OpenStreetMap. Latent subgroups among the cities are uncovered through a clustering on the percentage of each road network category. In the subsequent part of the paper, we focus on the usability of such classification: the effectiveness of our human perception augmentation is examined by a case study of urban vitality prediction. An advanced tree-based regression model is for the first time designated to establish the relationship between morphological indices and vitality indicators. A positive effect of human perception augmentation is detected in the comparative experiment of baseline model and augmented model. This work expands the toolkit of quantitative urban morphology study with new techniques, supporting further studies in the future.