 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Contextual Bandits with Deep Representation and Shallow Exploration
Dec 03, 2020
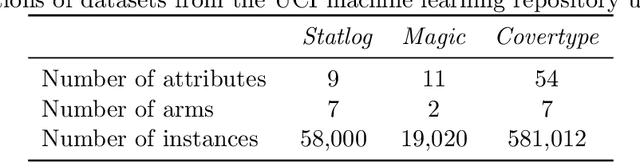
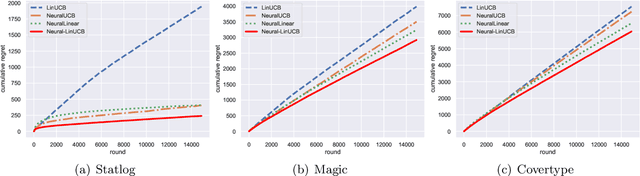
We study a general class of contextual bandits, where each context-action pair is associated with a raw feature vector, but the reward generating function is unknown. We propose a novel learning algorithm that transforms the raw feature vector using the last hidden layer of a deep ReLU neural network (deep representation learning), and uses an upper confidence bound (UCB) approach to explore in the last linear layer (shallow exploration). We prove that under standard assumptions, our proposed algorithm achieves $\tilde{O}(\sqrt{T})$ finite-time regret, where $T$ is the learning time horizon. Compared with existing neural contextual bandit algorithms, our approach is computationally much more efficient since it only needs to explore in the last layer of the deep neural network.
Simultaneous Multi-Pivot Neural Machine Translation
Apr 15, 2021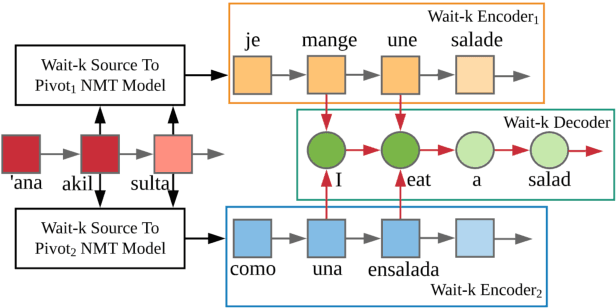
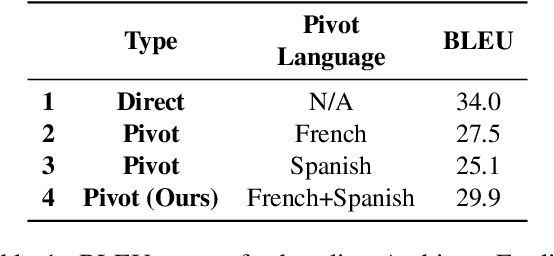
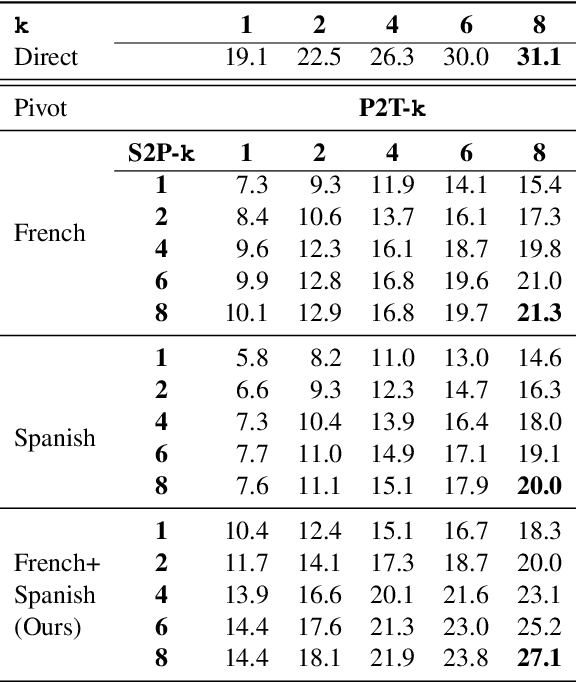
Parallel corpora are indispensable for training neural machine translation (NMT) models, and parallel corpora for most language pairs do not exist or are scarce. In such cases, pivot language NMT can be helpful where a pivot language is used such that there exist parallel corpora between the source and pivot and pivot and target languages. Naturally, the quality of pivot language translation is more inferior to what could be achieved with a direct parallel corpus of a reasonable size for that pair. In a real-time simultaneous translation setting, the quality of pivot language translation deteriorates even further given that the model has to output translations the moment a few source words become available. To solve this issue, we propose multi-pivot translation and apply it to a simultaneous translation setting involving pivot languages. Our approach involves simultaneously translating a source language into multiple pivots, which are then simultaneously translated together into the target language by leveraging multi-source NMT. Our experiments in a low-resource setting using the N-way parallel UN corpus for Arabic to English NMT via French and Spanish as pivots reveals that in a simultaneous pivot NMT setting, using two pivot languages can lead to an improvement of up to 5.8 BLEU.
Automated Tackle Injury Risk Assessment in Contact-Based Sports -- A Rugby Union Example
Apr 22, 2021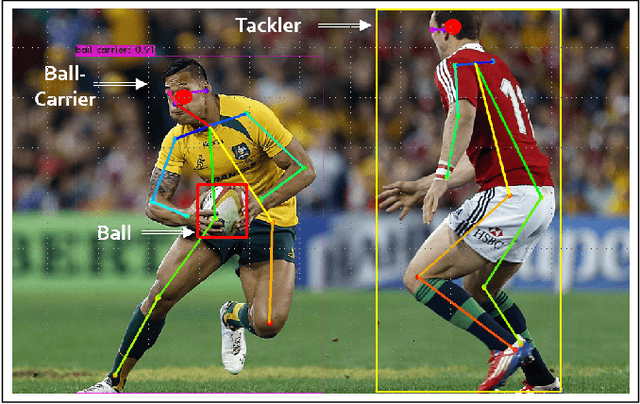
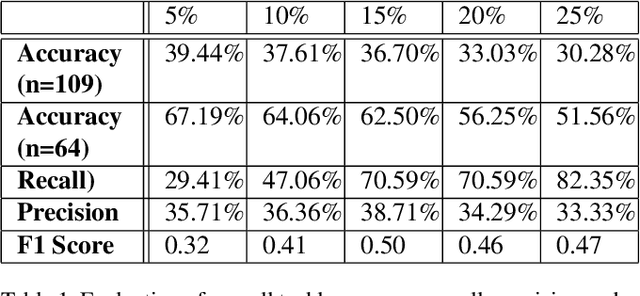
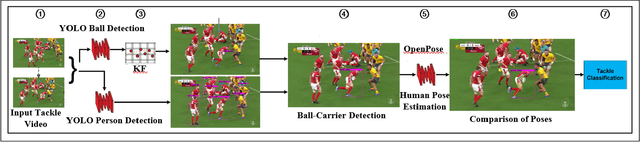
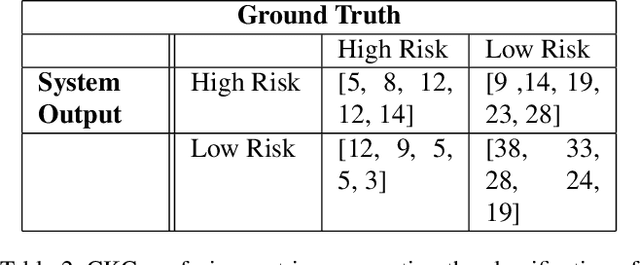
Video analysis in tackle-collision based sports is highly subjective and exposed to bias, which is inherent in human observation, especially under time constraints. This limitation of match analysis in tackle-collision based sports can be seen as an opportunity for computer vision applications. Objectively tracking, detecting and recognising an athlete's movements and actions during match play from a distance using video, along with our improved understanding of injury aetiology and skill execution will enhance our understanding how injury occurs, assist match day injury management, reduce referee subjectivity. In this paper, we present a system of objectively evaluating in-game tackle risk in rugby union matches. First, a ball detection model is trained using the You Only Look Once (YOLO) framework, these detections are then tracked by a Kalman Filter (KF). Following this, a separate YOLO model is used to detect persons/players within a tackle segment and then the ball-carrier and tackler are identified. Subsequently, we utilize OpenPose to determine the pose of ball-carrier and tackle, the relative pose of these is then used to evaluate the risk of the tackle. We tested the system on a diverse collection of rugby tackles and achieved an evaluation accuracy of 62.50%. These results will enable referees in tackle-contact based sports to make more subjective decisions, ultimately making these sports safer.
Quickest Detection over Sensor Networks with Unknown Post-Change Distribution
Dec 23, 2020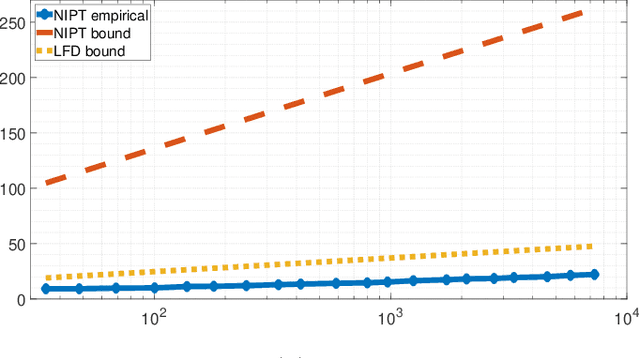
We propose a quickest change detection problem over sensor networks where both the subset of sensors undergoing a change and the local post-change distributions are unknown. Each sensor in the network observes a local discrete time random process over a finite alphabet. Initially, the observations are independent and identically distributed (i.i.d.) with known pre-change distributions independent from other sensors. At a fixed but unknown change point, a fixed but unknown subset of the sensors undergo a change and start observing samples from an unknown distribution. We assume the change can be quantified using concave (or convex) local statistics over the space of distributions. We propose an asymptotically optimal and computationally tractable stopping time for Lorden's criterion. Under this scenario, our proposed method uses a concave global cumulative sum (CUSUM) statistic at the fusion center and suppresses the most likely false alarms using information projection. Finally, we show some numerical results of the simulation of our algorithm for the problem described.
Disentangled Recurrent Wasserstein Autoencoder
Jan 19, 2021


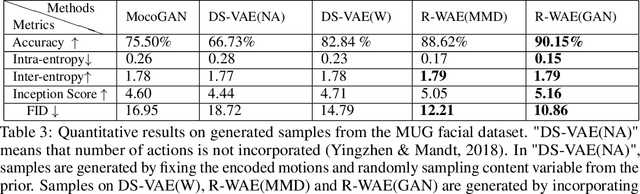
Learning disentangled representations leads to interpretable models and facilitates data generation with style transfer, which has been extensively studied on static data such as images in an unsupervised learning framework. However, only a few works have explored unsupervised disentangled sequential representation learning due to challenges of generating sequential data. In this paper, we propose recurrent Wasserstein Autoencoder (R-WAE), a new framework for generative modeling of sequential data. R-WAE disentangles the representation of an input sequence into static and dynamic factors (i.e., time-invariant and time-varying parts). Our theoretical analysis shows that, R-WAE minimizes an upper bound of a penalized form of the Wasserstein distance between model distribution and sequential data distribution, and simultaneously maximizes the mutual information between input data and different disentangled latent factors, respectively. This is superior to (recurrent) VAE which does not explicitly enforce mutual information maximization between input data and disentangled latent representations. When the number of actions in sequential data is available as weak supervision information, R-WAE is extended to learn a categorical latent representation of actions to improve its disentanglement. Experiments on a variety of datasets show that our models outperform other baselines with the same settings in terms of disentanglement and unconditional video generation both quantitatively and qualitatively.
Split Modeling for High-Dimensional Logistic Regression
Mar 12, 2021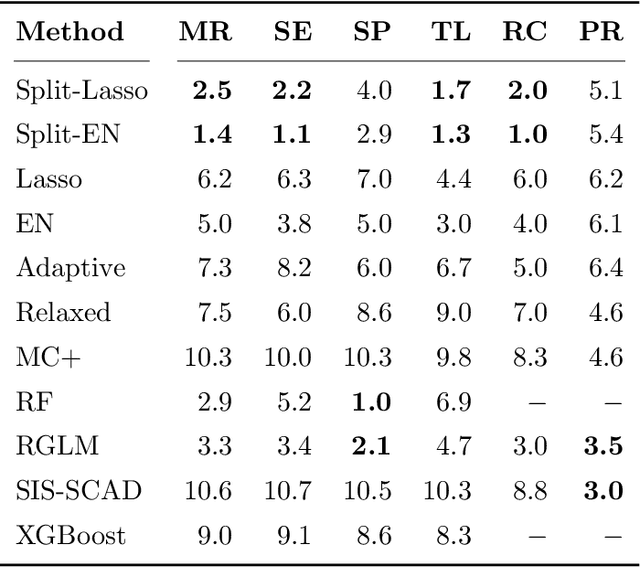
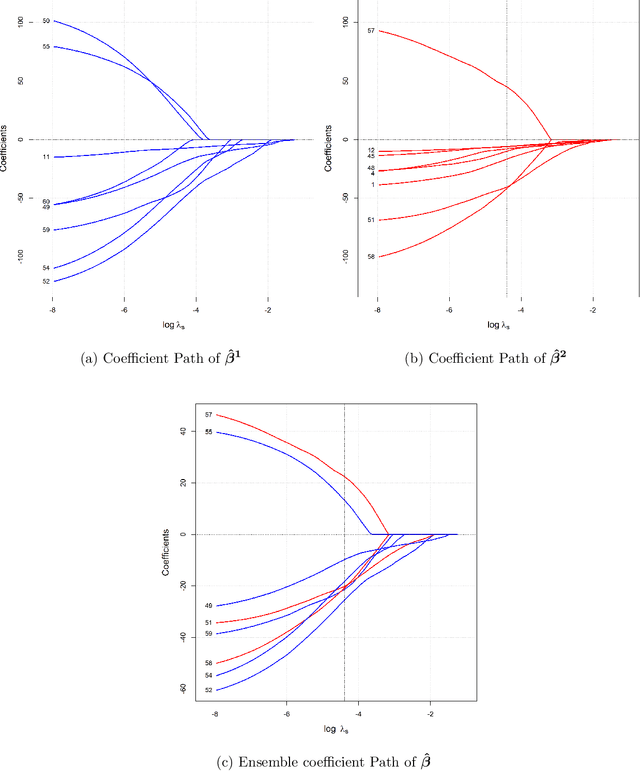
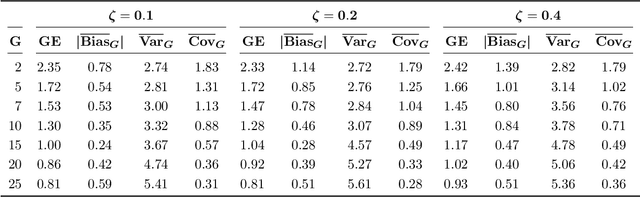
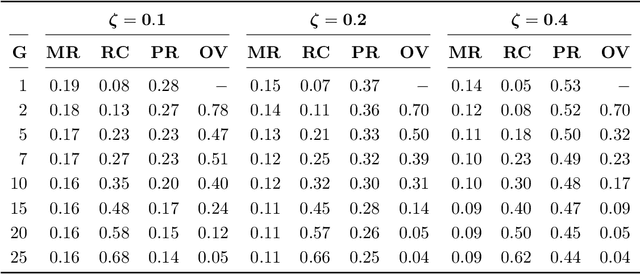
A novel method is proposed to learn an ensemble of logistic classification models in the context of high-dimensional binary classification. The models in the ensemble are built simultaneously by optimizing a multi-convex objective function. To enforce diversity between the models the objective function penalizes overlap between the models in the ensemble. We study the bias and variance of the individual models as well as their correlation and discuss how our method learns the ensemble by exploiting the accuracy-diversity trade-off for ensemble models. In contrast to other ensembling approaches, the resulting ensemble model is fully interpretable as a logistic regression model and at the same time yields excellent prediction accuracy as demonstrated in an extensive simulation study and gene expression data applications. An open-source compiled software library implementing the proposed method is briefly discussed.
Electromagnetic Models for Passive Detection and Localization of Multiple Bodies
Apr 15, 2021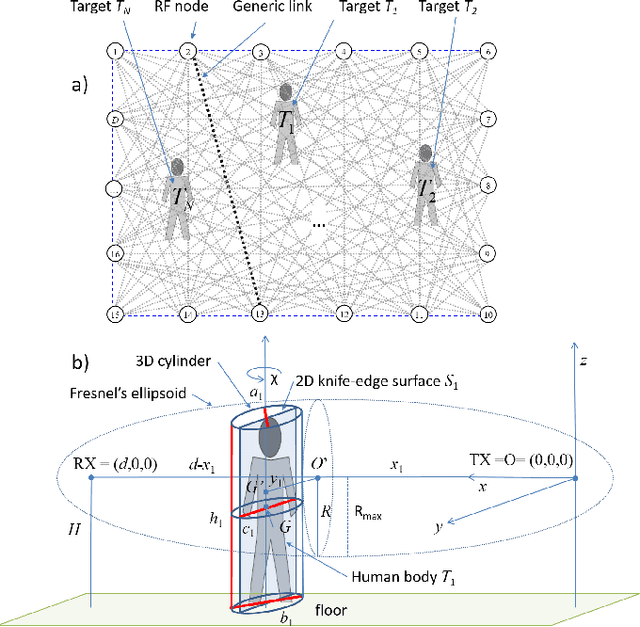
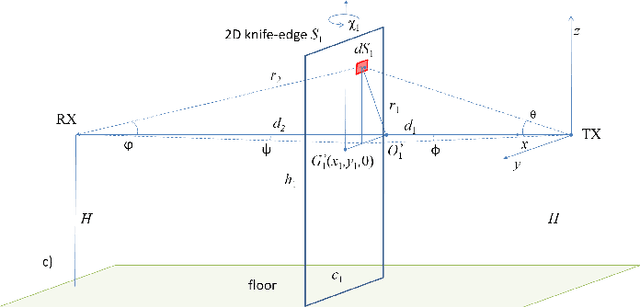
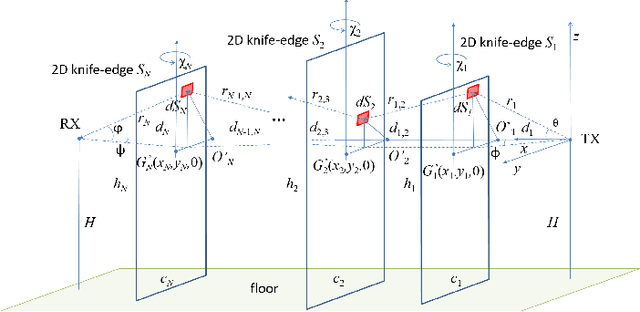
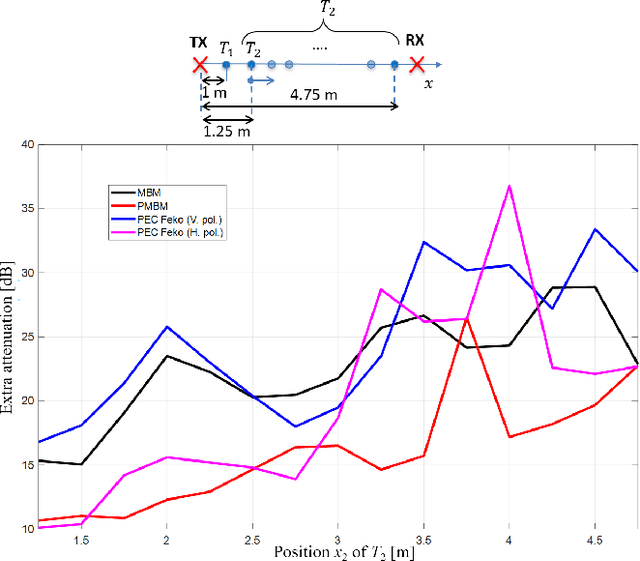
The paper proposes a multi-body electromagnetic (EM) model for the quantitative evaluation of the influence of multiple human bodies in the surroundings of a radio link. Modeling of human-induced fading is the key element for the development of real-time Device-Free (or passive) Localization (DFL) and body occupancy tracking systems based on the processing of the Received Signal Strength (RSS) data recorded by radio-frequency devices. The proposed physical-statistical model, is able to relate the RSS measurements to the position, size, orientation, and random movements of people located in the link area. This novel EM model is thus instrumental for crowd sensing, occupancy estimation and people counting applications for indoor and outdoor scenarios. The paper presents the complete framework for the generic N-body scenario where the proposed EM model is based on the knife-edge approach that is generalized here for multiple targets. The EM-equivalent size of each target is then optimized to reproduce the body-induced alterations of the free space radio propagation. The predicted results are then compared against the full EM simulations obtained with a commercially available simulator. Finally, experiments are carried out to confirm the validity the proposed model using IEEE 802.15.4-compliant industrial radio devices.
Channel Estimation via Successive Denoising in MIMO OFDM Systems: A Reinforcement Learning Approach
Jan 27, 2021
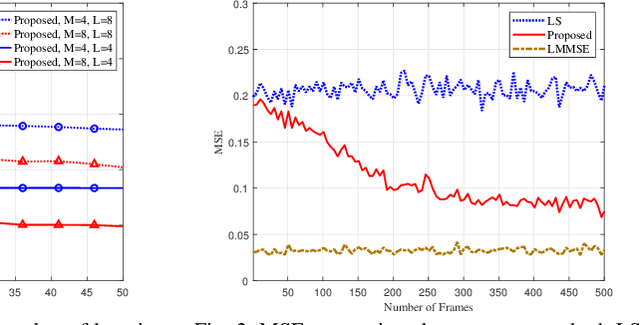
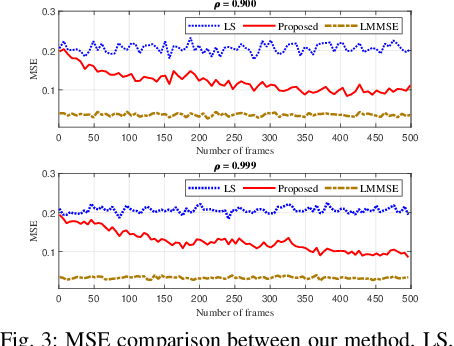
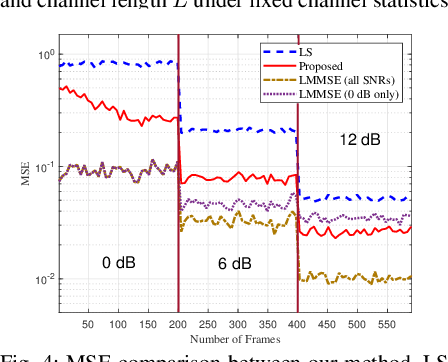
Reliable communication through multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) requires accurate channel estimation. Existing literature largely focuses on denoising methods for channel estimation that are dependent on either (i) channel analysis in the time-domain, and/or (ii) supervised learning techniques, requiring large pre-labeled datasets for training. To address these limitations, we present a frequency-domain denoising method based on the application of a reinforcement learning framework that does not need a priori channel knowledge and pre-labeled data. Our methodology includes a new successive channel denoising process based on channel curvature computation, for which we obtain a channel curvature magnitude threshold to identify unreliable channel estimates. Based on this process, we formulate the denoising mechanism as a Markov decision process, where we define the actions through a geometry-based channel estimation update, and the reward function based on a policy that reduces the MSE. We then resort to Q-learning to update the channel estimates over the time instances. Numerical results verify that our denoising algorithm can successfully mitigate noise in channel estimates. In particular, our algorithm provides a significant improvement over the practical least squares (LS) channel estimation method and provides performance that approaches that of the ideal linear minimum mean square error (LMMSE) with perfect knowledge of channel statistics.
Multi-term and Multi-task Affect Analysis in the Wild
Sep 29, 2020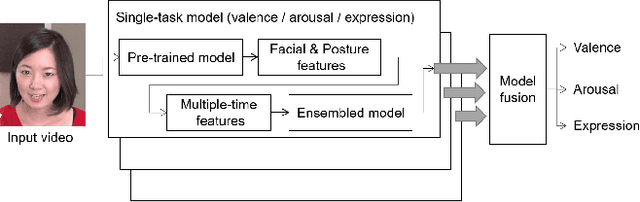
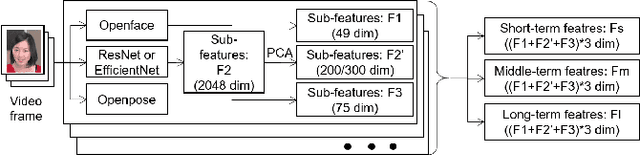
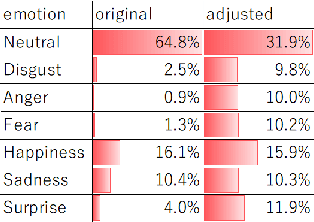
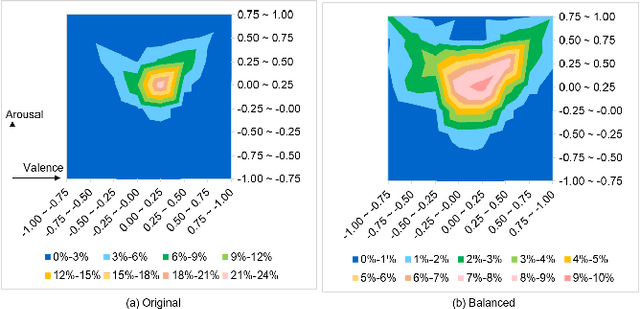
Human affect recognition is an important factor in human-computer interaction. However, the development of method for in-the-wild data is still nowhere near enough. in this paper, we introduce the affect recognition method that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2020 Contest. In our approach, since we considered that affective behaviors have different time window features, we generated features and averaged labels using short-term, medium-term, and long-term time windows from video images. Then, we generated affect recognition models in each time window, and esembled each models. In addition,we fuseed the VA and EXP models, taking into account that Valence, Arousal, and Expresion are closely related. The features were trained by gradient boosting, using the mean, standard deviation, max-range, and slope in each time winodows. We achieved the valence-arousal score: 0.495 and expression score: 0.464 on the validation set.
Business analytics meets artificial intelligence: Assessing the demand effects of discounts on Swiss train tickets
May 04, 2021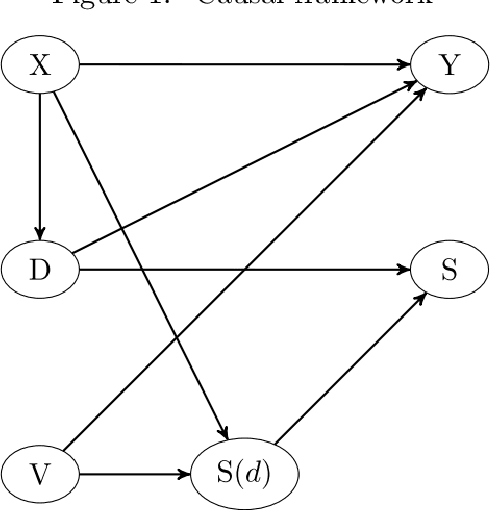
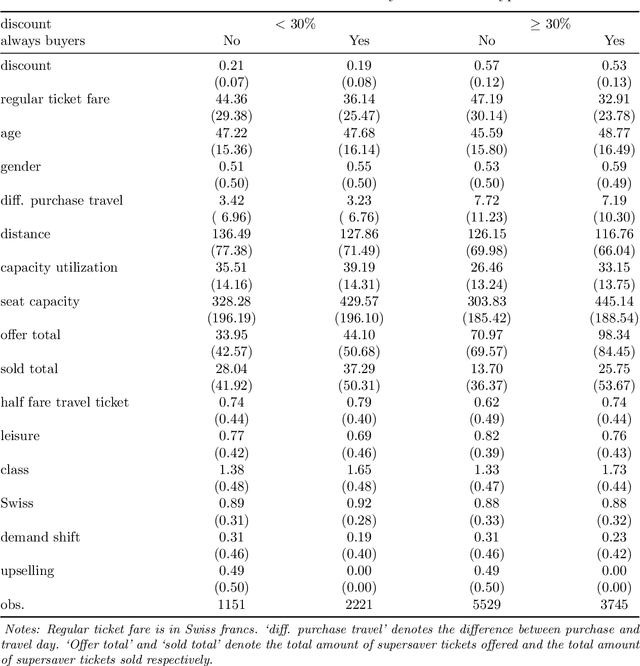

We assess the demand effects of discounts on train tickets issued by the Swiss Federal Railways, the so-called `supersaver tickets', based on machine learning, a subfield of artificial intelligence. Considering a survey-based sample of buyers of supersaver tickets, we investigate which customer- or trip-related characteristics (including the discount rate) predict buying behavior, namely: booking a trip otherwise not realized by train, buying a first- rather than second-class ticket, or rescheduling a trip (e.g.\ away from rush hours) when being offered a supersaver ticket. Predictive machine learning suggests that customer's age, demand-related information for a specific connection (like departure time and utilization), and the discount level permit forecasting buying behavior to a certain extent. Furthermore, we use causal machine learning to assess the impact of the discount rate on rescheduling a trip, which seems relevant in the light of capacity constraints at rush hours. Assuming that (i) the discount rate is quasi-random conditional on our rich set of characteristics and (ii) the buying decision increases weakly monotonically in the discount rate, we identify the discount rate's effect among `always buyers', who would have traveled even without a discount, based on our survey that asks about customer behavior in the absence of discounts. We find that on average, increasing the discount rate by one percentage point increases the share of rescheduled trips by 0.16 percentage points among always buyers. Investigating effect heterogeneity across observables suggests that the effects are higher for leisure travelers and during peak hours when controlling several other characteristics.