 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RL-GRIT: Reinforcement Learning for Grammar Inference
May 17, 2021
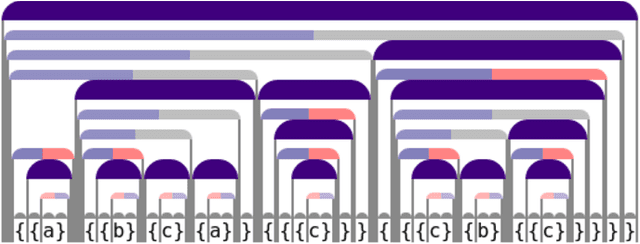
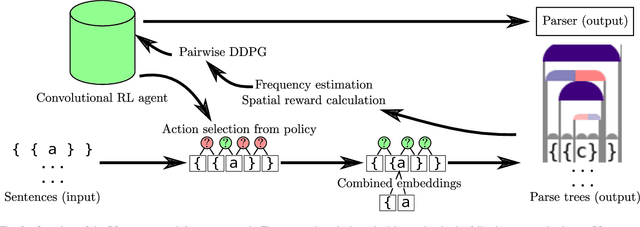
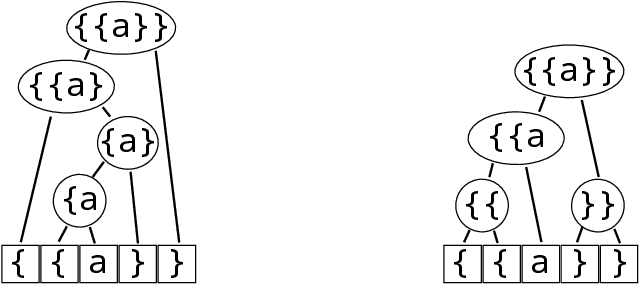
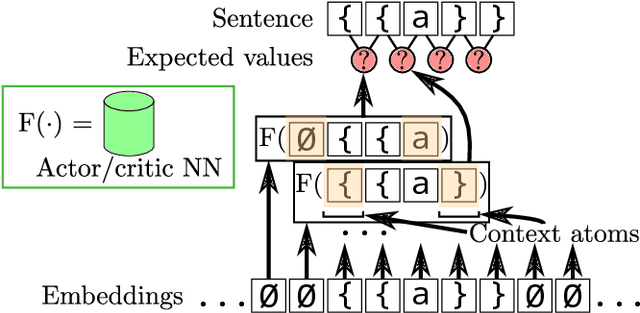
When working to understand usage of a data format, examples of the data format are often more representative than the format's specification. For example, two different applications might use very different JSON representations, or two PDF-writing applications might make use of very different areas of the PDF specification to realize the same rendered content. The complexity arising from these distinct origins can lead to large, difficult-to-understand attack surfaces, presenting a security concern when considering both exfiltration and data schizophrenia. Grammar inference can aid in describing the practical language generator behind examples of a data format. However, most grammar inference research focuses on natural language, not data formats, and fails to support crucial features such as type recursion. We propose a novel set of mechanisms for grammar inference, RL-GRIT, and apply them to understanding de facto data formats. After reviewing existing grammar inference solutions, it was determined that a new, more flexible scaffold could be found in Reinforcement Learning (RL). Within this work, we lay out the many algorithmic changes required to adapt RL from its traditional, sequential-time environment to the highly interdependent environment of parsing. The result is an algorithm which can demonstrably learn recursive control structures in simple data formats, and can extract meaningful structure from fragments of the PDF format. Whereas prior work in grammar inference focused on either regular languages or constituency parsing, we show that RL can be used to surpass the expressiveness of both classes, and offers a clear path to learning context-sensitive languages. The proposed algorithm can serve as a building block for understanding the ecosystems of de facto data formats.
Nanosecond machine learning event classification with boosted decision trees in FPGA for high energy physics
Apr 07, 2021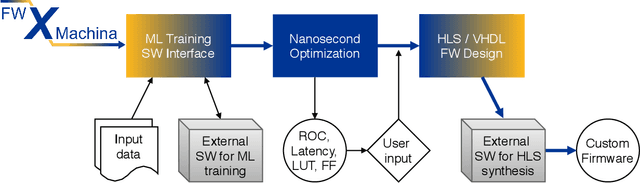
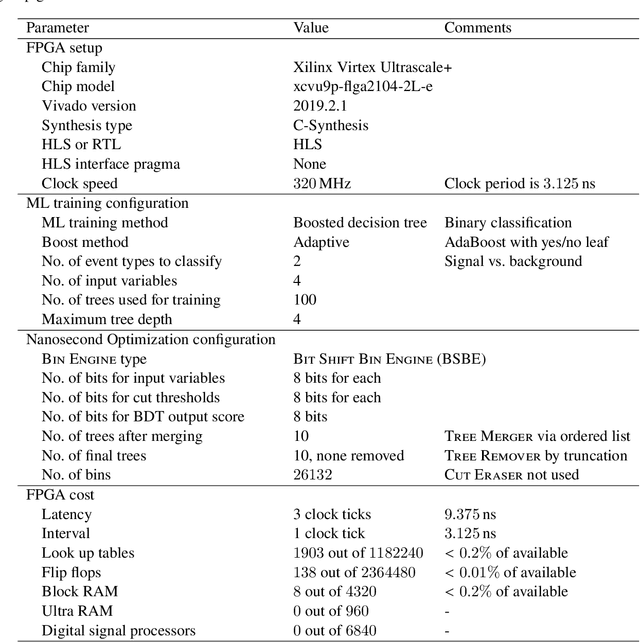
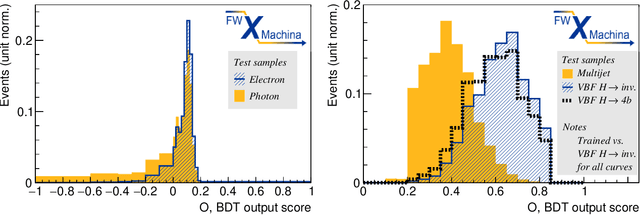
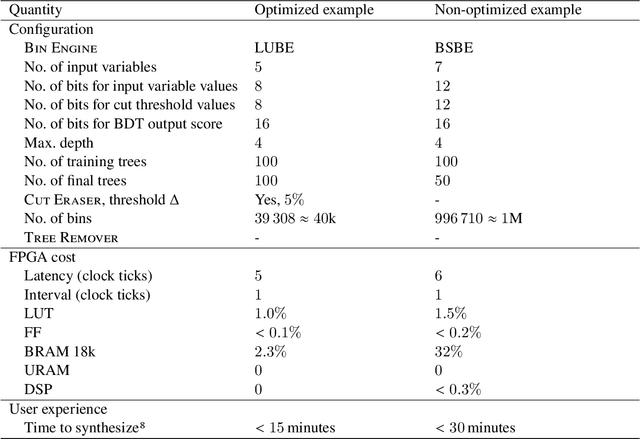
We present a novel implementation of classification using the machine learning / artificial intelligence method called boosted decision trees (BDT) on field programmable gate arrays (FPGA). The firmware implementation of binary classification requiring 100 training trees with a maximum depth of 4 using four input variables gives a latency value of about 10 ns, which corresponds to 3 clock ticks at 320 MHz in our setup. The low timing values are achieved by restructuring the BDT layout and reconfiguring its parameters. The FPGA resource utilization is also kept low at a range from 0.01% to 0.2% in our setup. A software package called fwXmachina achieves this implementation. Our intended audience is a user of custom electronics-based trigger systems in high energy physics experiments or anyone that needs decisions at the lowest latency values for real-time event classification. Two problems from high energy physics are considered, in the separation of electrons vs. photons and in the selection of vector boson fusion-produced Higgs bosons vs. the rejection of the multijet processes.
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021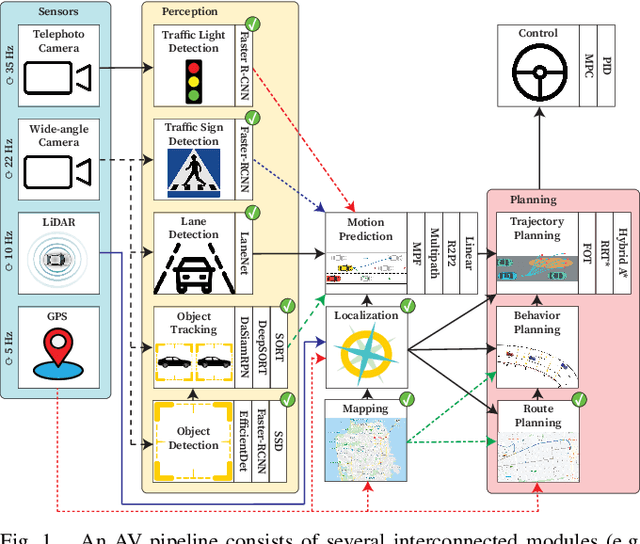

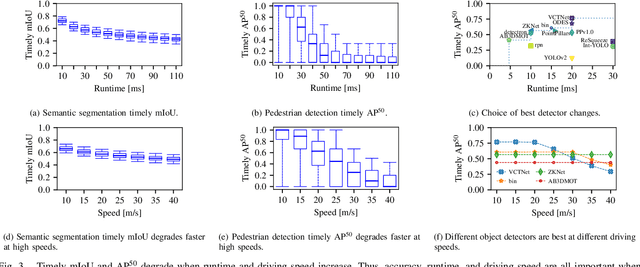
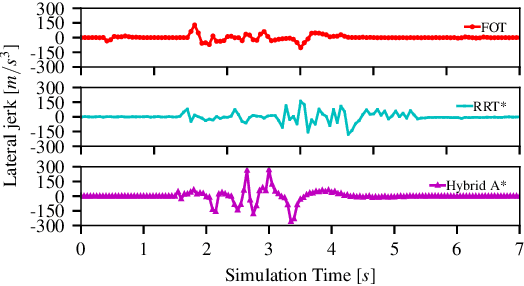
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.
PointLIE: Locally Invertible Embedding for Point Cloud Sampling and Recovery
Apr 30, 2021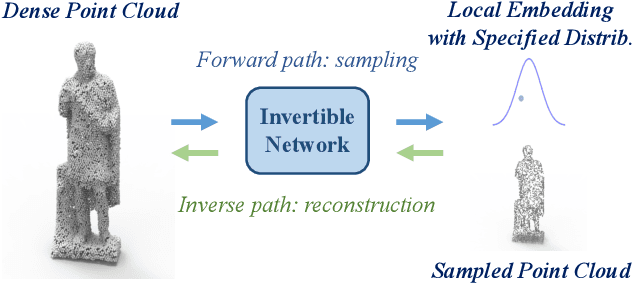
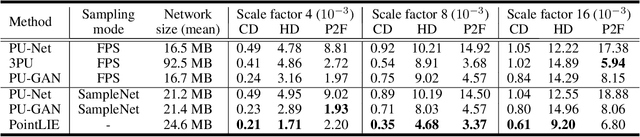
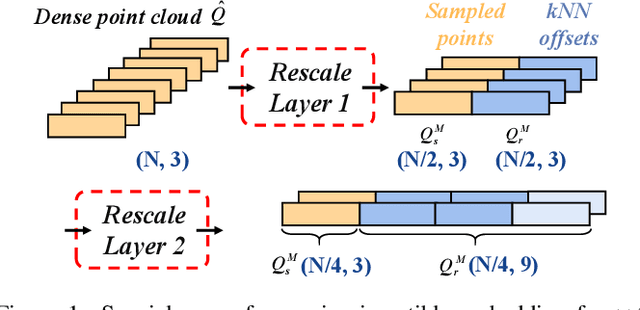
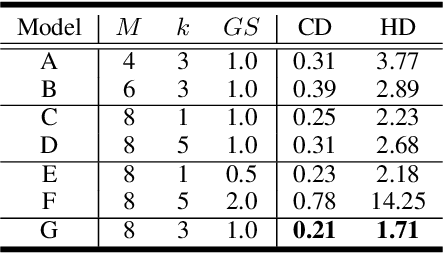
Point Cloud Sampling and Recovery (PCSR) is critical for massive real-time point cloud collection and processing since raw data usually requires large storage and computation. In this paper, we address a fundamental problem in PCSR: How to downsample the dense point cloud with arbitrary scales while preserving the local topology of discarding points in a case-agnostic manner (i.e. without additional storage for point relationship)? We propose a novel Locally Invertible Embedding for point cloud adaptive sampling and recovery (PointLIE). Instead of learning to predict the underlying geometry details in a seemingly plausible manner, PointLIE unifies point cloud sampling and upsampling to one single framework through bi-directional learning. Specifically, PointLIE recursively samples and adjusts neighboring points on each scale. Then it encodes the neighboring offsets of sampled points to a latent space and thus decouples the sampled points and the corresponding local geometric relationship. Once the latent space is determined and that the deep model is optimized, the recovery process could be conducted by passing the recover-pleasing sampled points and a randomly-drawn embedding to the same network through an invertible operation. Such a scheme could guarantee the fidelity of dense point recovery from sampled points. Extensive experiments demonstrate that the proposed PointLIE outperforms state-of-the-arts both quantitatively and qualitatively. Our code is released through https://github.com/zwb0/PointLIE.
* To appear in IJCAI 2021
Learning robust driving policies without online exploration
Mar 15, 2021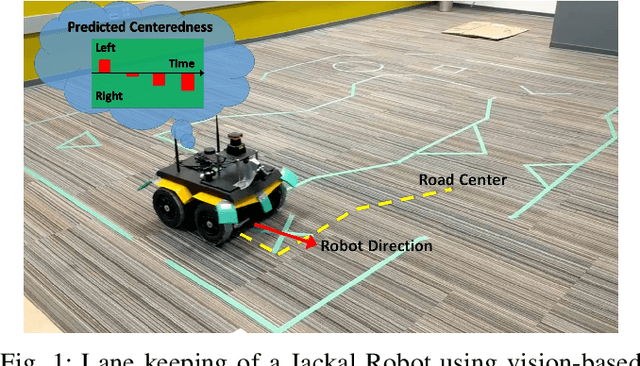
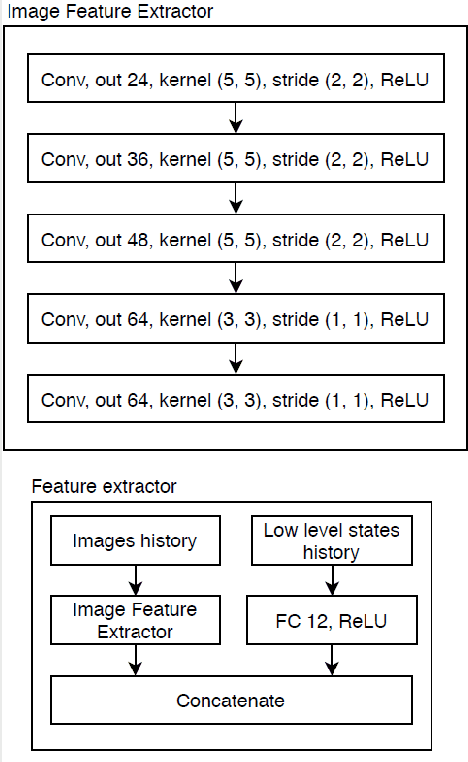
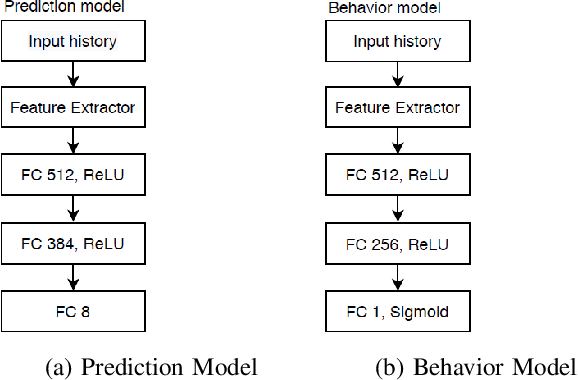
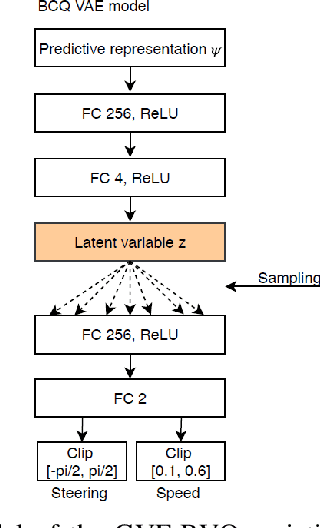
We propose a multi-time-scale predictive representation learning method to efficiently learn robust driving policies in an offline manner that generalize well to novel road geometries, and damaged and distracting lane conditions which are not covered in the offline training data. We show that our proposed representation learning method can be applied easily in an offline (batch) reinforcement learning setting demonstrating the ability to generalize well and efficiently under novel conditions compared to standard batch RL methods. Our proposed method utilizes training data collected entirely offline in the real-world which removes the need of intensive online explorations that impede applying deep reinforcement learning on real-world robot training. Various experiments were conducted in both simulator and real-world scenarios for the purpose of evaluation and analysis of our proposed claims.
Distributed Learning over Markovian Fading Channels for Stable Spectrum Access
Jan 27, 2021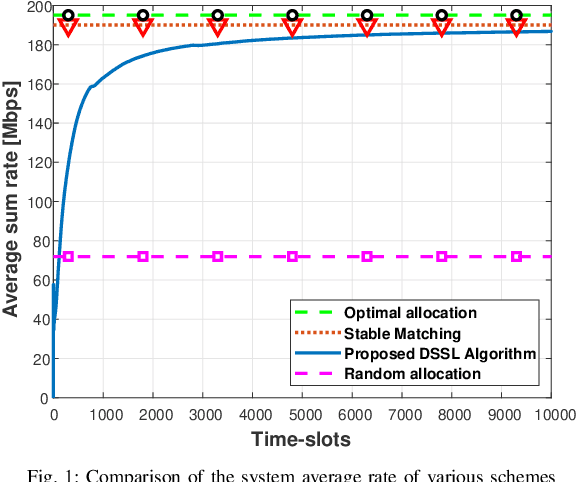
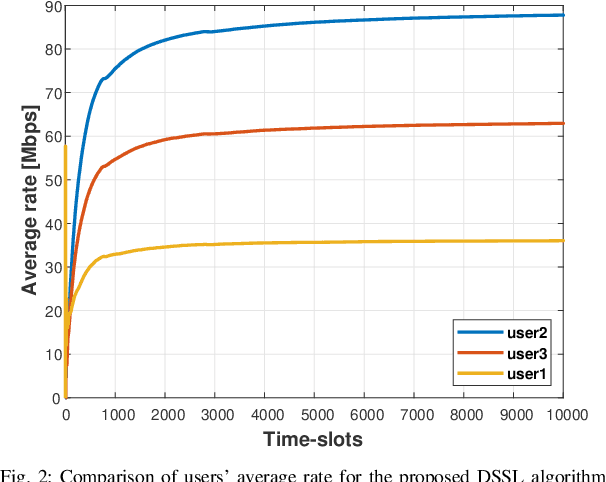
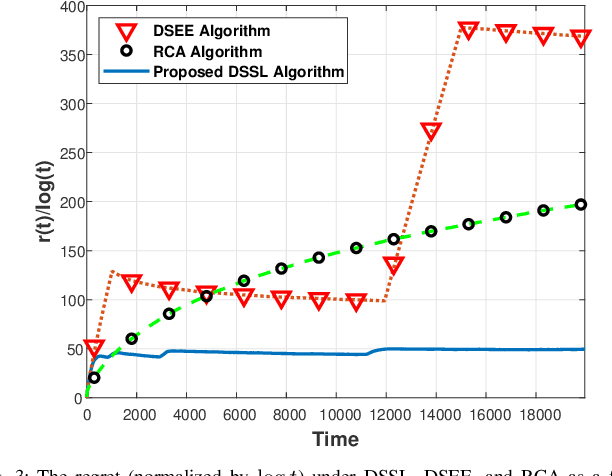
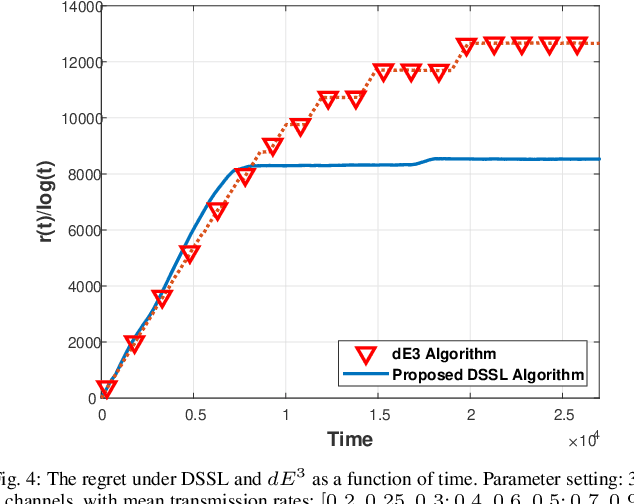
We consider the problem of multi-user spectrum access in wireless networks. The bandwidth is divided into K orthogonal channels, and M users aim to access the spectrum. Each user chooses a single channel for transmission at each time slot. The state of each channel is modeled by a restless unknown Markovian process. Previous studies have analyzed a special case of this setting, in which each channel yields the same expected rate for all users. By contrast, we consider a more general and practical model, where each channel yields a different expected rate for each user. This model adds a significant challenge of how to efficiently learn a channel allocation in a distributed manner to yield a global system-wide objective. We adopt the stable matching utility as the system objective, which is known to yield strong performance in multichannel wireless networks, and develop a novel Distributed Stable Strategy Learning (DSSL) algorithm to achieve the objective. We prove theoretically that DSSL converges to the stable matching allocation, and the regret, defined as the loss in total rate with respect to the stable matching solution, has a logarithmic order with time. Finally, simulation results demonstrate the strong performance of the DSSL algorithm.
Demonstrating Analog Inference on the BrainScaleS-2 Mobile System
Mar 29, 2021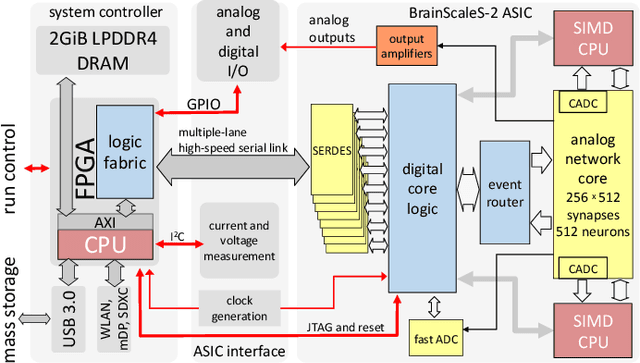

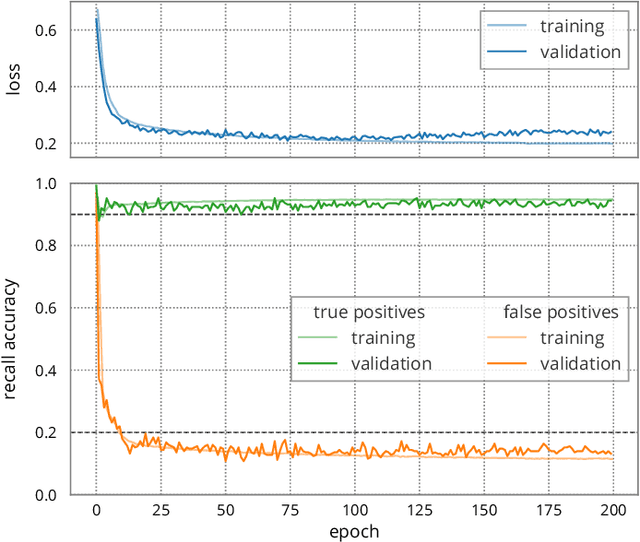
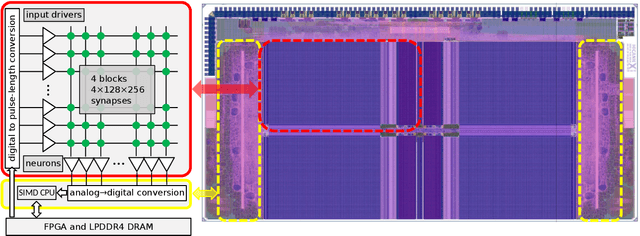
We present the BrainScaleS-2 mobile system as a compact analog inference engine based on the BrainScaleS-2 ASIC and demonstrate its capabilities at classifying a medical electrocardiogram dataset. The analog network core of the ASIC is utilized to perform the multiply-accumulate operations of a convolutional deep neural network. We measure a total energy consumption of 192uJ for the ASIC and achieve a classification time of 276us per electrocardiographic patient sample. Patients with atrial fibrillation are correctly identified with a detection rate of 93.7(7)% at 14.0(10)% false positives. The system is directly applicable to edge inference applications due to its small size, power envelope and flexible I/O capabilities. Possible future applications can furthermore combine conventional machine learning layers with online-learning in spiking neural networks on a single BrainScaleS-2 ASIC. The system has successfully participated and proven to operate reliably in the independently judged competition "Pilotinnovationswettbewerb 'Energieeffizientes KI-System'" of the German Federal Ministry of Education and Research (BMBF).
Jamming-Resilient Path Planning for Multiple UAVs via Deep Reinforcement Learning
Apr 15, 2021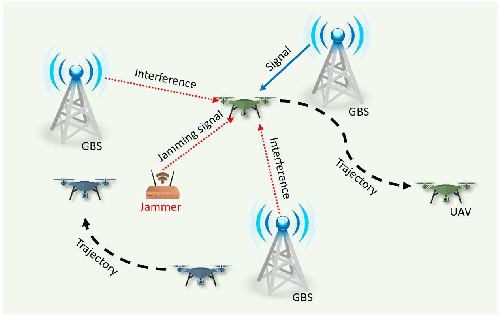
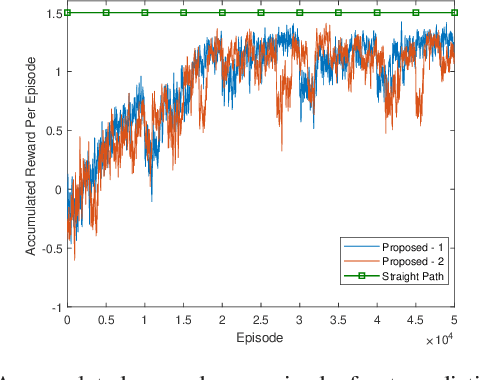
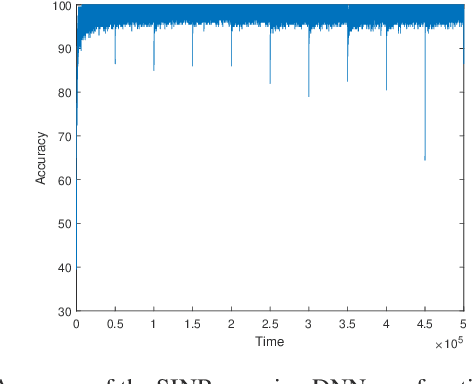
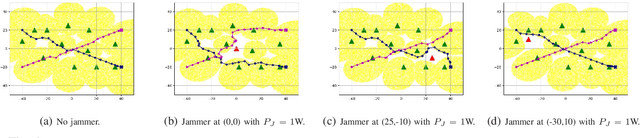
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks. In this paper, we aim to find collision-free paths for multiple cellular-connected UAVs, while satisfying requirements of connectivity with ground base stations (GBSs) in the presence of a dynamic jammer. We first formulate the problem as a sequential decision making problem in discrete domain, with connectivity, collision avoidance, and kinematic constraints. We, then, propose an offline temporal difference (TD) learning algorithm with online signal-to-interference-plus-noise ratio (SINR) mapping to solve the problem. More specifically, a value network is constructed and trained offline by TD method to encode the interactions among the UAVs and between the UAVs and the environment; and an online SINR mapping deep neural network (DNN) is designed and trained by supervised learning, to encode the influence and changes due to the jammer. Numerical results show that, without any information on the jammer, the proposed algorithm can achieve performance levels close to that of the ideal scenario with the perfect SINR-map. Real-time navigation for multi-UAVs can be efficiently performed with high success rates, and collisions are avoided.
Model-Driven Deep Learning Based Channel Estimation and Feedback for Millimeter-Wave Massive Hybrid MIMO Systems
May 06, 2021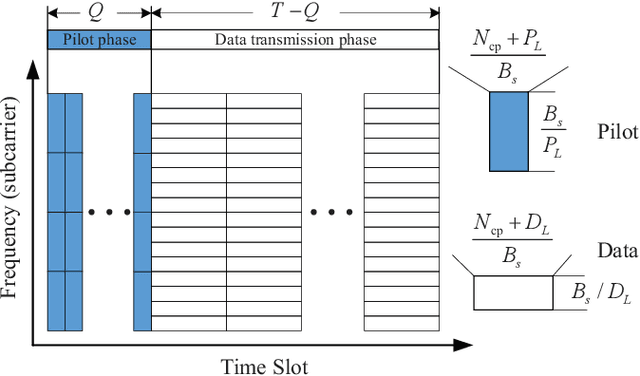
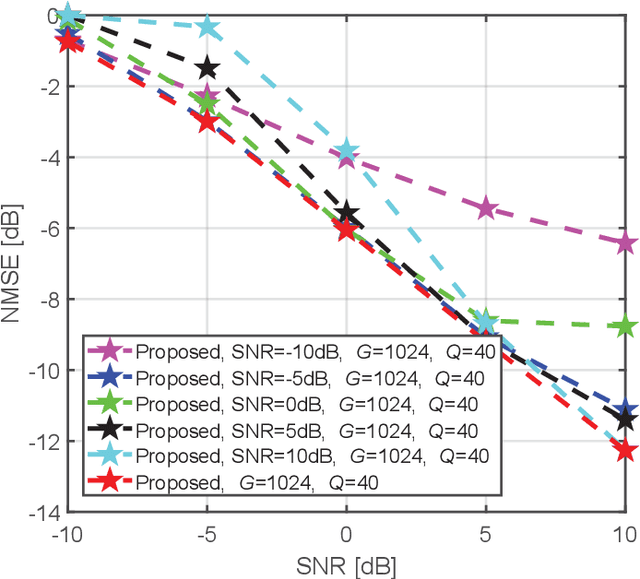
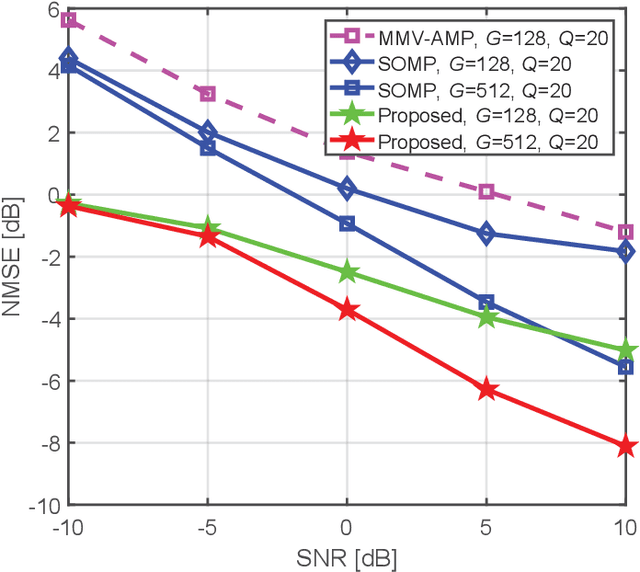
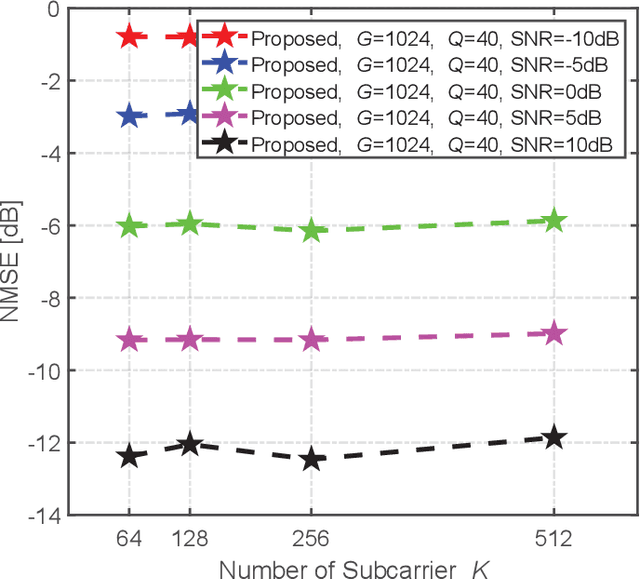
This paper proposes a model-driven deep learning (MDDL)-based channel estimation and feedback scheme for wideband millimeter-wave (mmWave) massive hybrid multiple-input multiple-output (MIMO) systems, where the angle-delay domain channels' sparsity is exploited for reducing the overhead. Firstly, we consider the uplink channel estimation for time-division duplexing systems. To reduce the uplink pilot overhead for estimating the high-dimensional channels from a limited number of radio frequency (RF) chains at the base station (BS), we propose to jointly train the phase shift network and the channel estimator as an auto-encoder. Particularly, by exploiting the channels' structured sparsity from an a priori model and learning the integrated trainable parameters from the data samples, the proposed multiple-measurement-vectors learned approximate message passing (MMV-LAMP) network with the devised redundant dictionary can jointly recover multiple subcarriers' channels with significantly enhanced performance. Moreover, we consider the downlink channel estimation and feedback for frequency-division duplexing systems. Similarly, the pilots at the BS and channel estimator at the users can be jointly trained as an encoder and a decoder, respectively. Besides, to further reduce the channel feedback overhead, only the received pilots on part of the subcarriers are fed back to the BS, which can exploit the MMV-LAMP network to reconstruct the spatial-frequency channel matrix. Numerical results show that the proposed MDDL-based channel estimation and feedback scheme outperforms the state-of-the-art approaches.
Deep Learning for Virus-Spreading Forecasting: a Brief Survey
Mar 03, 2021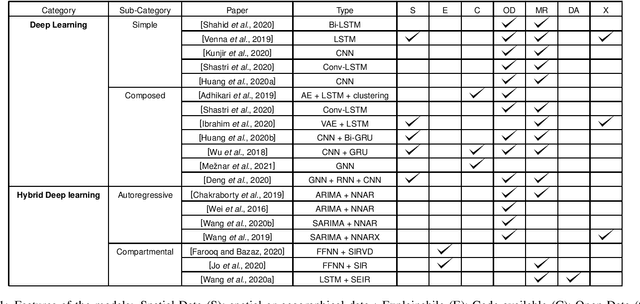
The advent of the coronavirus pandemic has sparked the interest in predictive models capable of forecasting virus-spreading, especially for boosting and supporting decision-making processes. In this paper, we will outline the main Deep Learning approaches aimed at predicting the spreading of a disease in space and time. The aim is to show the emerging trends in this area of research and provide a general perspective on the possible strategies to approach this problem. In doing so, we will mainly focus on two macro-categories: classical Deep Learning approaches and Hybrid models. Finally, we will discuss the main advantages and disadvantages of different models, and underline the most promising development directions to improve these approaches.