 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Acute Intracranial Hemorrhage Segmentation with Mixture Models
May 12, 2021
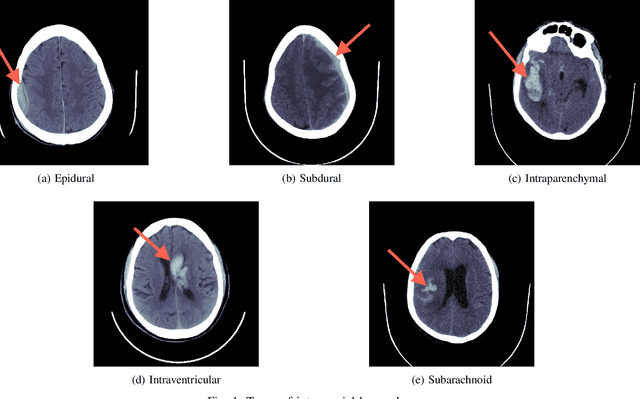
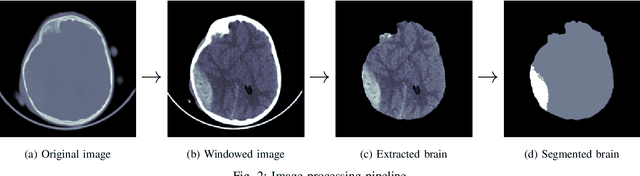
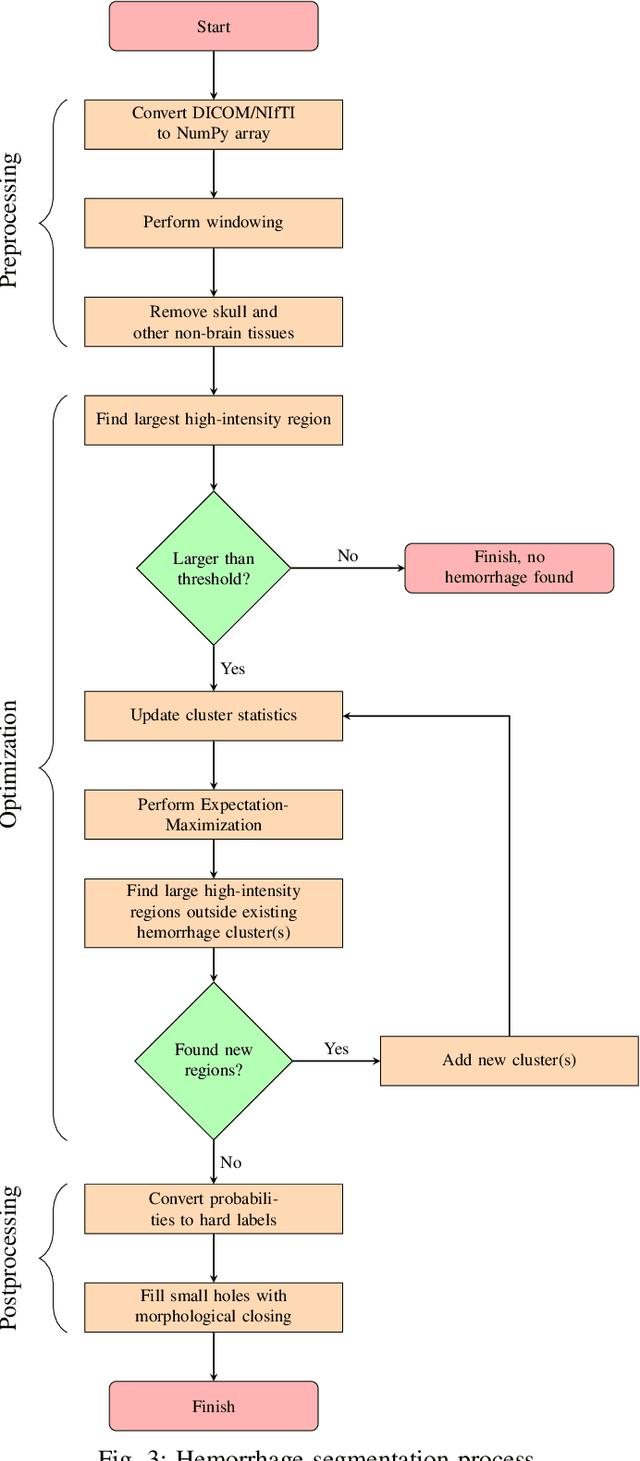
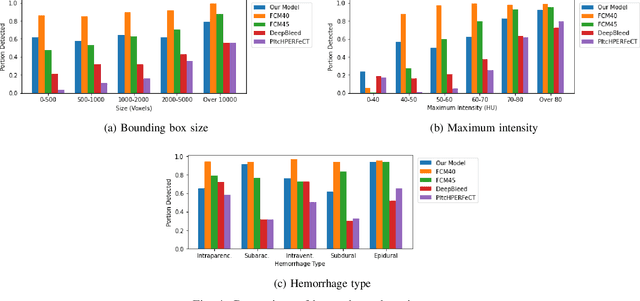
Intracranial hemorrhage occurs when blood vessels rupture or leak within the brain tissue or elsewhere inside the skull. It can be caused by physical trauma or by various medical conditions and in many cases leads to death. The treatment must be started as soon as possible, and therefore the hemorrhage should be diagnosed accurately and quickly. The diagnosis is usually performed by a radiologist who analyses a Computed Tomography (CT) scan containing a large number of cross-sectional images throughout the brain. Analysing each image manually can be very time-consuming, but automated techniques can help speed up the process. While much of the recent research has focused on solving this problem by using supervised machine learning algorithms, publicly-available training data remains scarce due to privacy concerns. This problem can be alleviated by unsupervised algorithms. In this paper, we propose a fully-unsupervised algorithm which is based on the mixture models. Our algorithm utilizes the fact that the properties of hemorrhage and healthy tissues follow different distributions, and therefore an appropriate formulation of these distributions allows us to separate them through an Expectation-Maximization process. In addition, our algorithm is able to adaptively determine the number of clusters such that all the hemorrhage regions can be found without including noisy voxels. We demonstrate the results of our algorithm on publicly-available datasets that contain all different hemorrhage types in various sizes and intensities, and our results are compared to earlier unsupervised and supervised algorithms. The results show that our algorithm can outperform the other algorithms with most hemorrhage types.
Adversarially learned iterative reconstruction for imaging inverse problems
Mar 30, 2021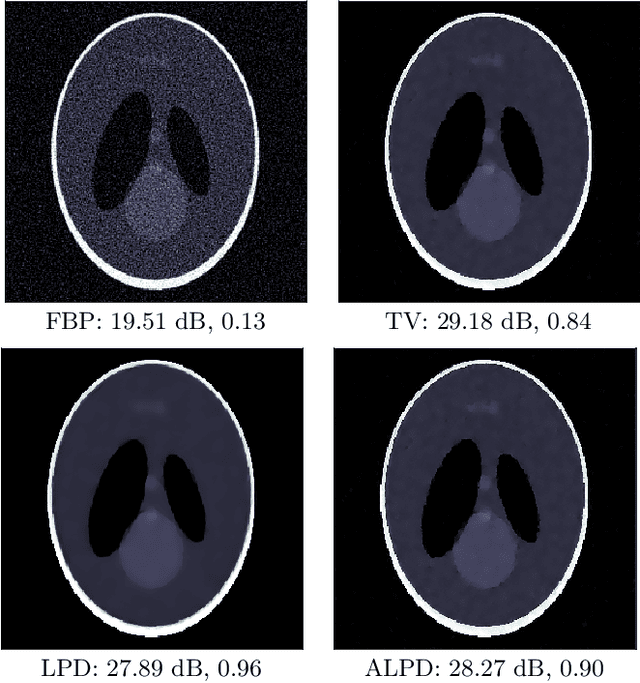
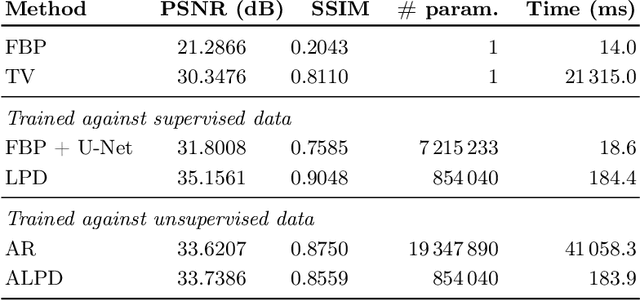
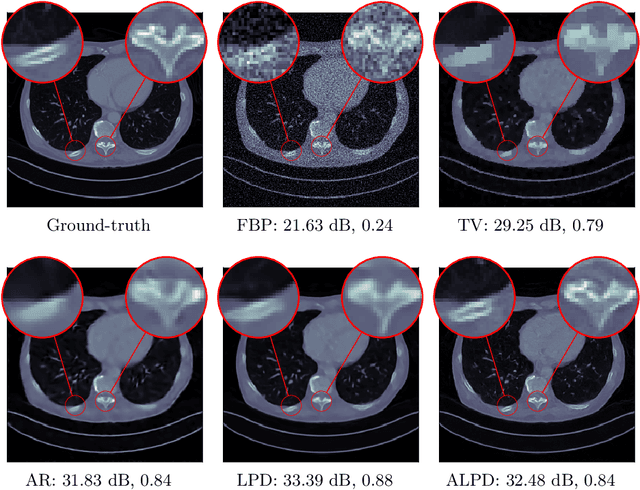
In numerous practical applications, especially in medical image reconstruction, it is often infeasible to obtain a large ensemble of ground-truth/measurement pairs for supervised learning. Therefore, it is imperative to develop unsupervised learning protocols that are competitive with supervised approaches in performance. Motivated by the maximum-likelihood principle, we propose an unsupervised learning framework for solving ill-posed inverse problems. Instead of seeking pixel-wise proximity between the reconstructed and the ground-truth images, the proposed approach learns an iterative reconstruction network whose output matches the ground-truth in distribution. Considering tomographic reconstruction as an application, we demonstrate that the proposed unsupervised approach not only performs on par with its supervised variant in terms of objective quality measures but also successfully circumvents the issue of over-smoothing that supervised approaches tend to suffer from. The improvement in reconstruction quality comes at the expense of higher training complexity, but, once trained, the reconstruction time remains the same as its supervised counterpart.
Learning to Route via Theory-Guided Residual Network
May 18, 2021
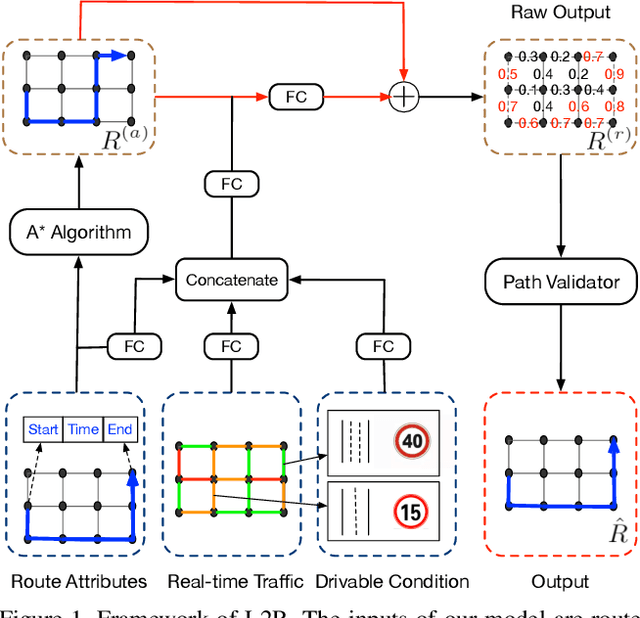
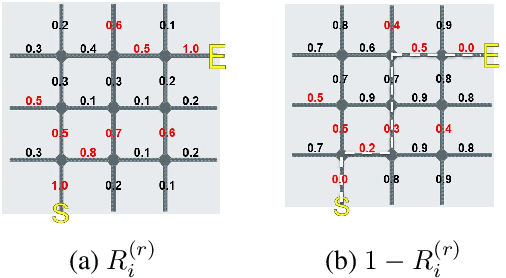
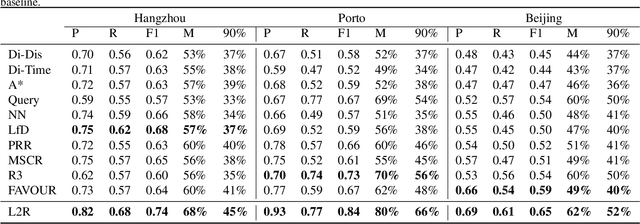
The heavy traffic and related issues have always been concerns for modern cities. With the help of deep learning and reinforcement learning, people have proposed various policies to solve these traffic-related problems, such as smart traffic signal control systems and taxi dispatching systems. People usually validate these policies in a city simulator, since directly applying them in the real city introduces real cost. However, these policies validated in the city simulator may fail in the real city if the simulator is significantly different from the real world. To tackle this problem, we need to build a real-like traffic simulation system. Therefore, in this paper, we propose to learn the human routing model, which is one of the most essential part in the traffic simulator. This problem has two major challenges. First, human routing decisions are determined by multiple factors, besides the common time and distance factor. Second, current historical routes data usually covers just a small portion of vehicles, due to privacy and device availability issues. To address these problems, we propose a theory-guided residual network model, where the theoretical part can emphasize the general principles for human routing decisions (e.g., fastest route), and the residual part can capture drivable condition preferences (e.g., local road or highway). Since the theoretical part is composed of traditional shortest path algorithms that do not need data to train, our residual network can learn human routing models from limited data. We have conducted extensive experiments on multiple real-world datasets to show the superior performance of our model, especially with small data. Besides, we have also illustrated why our model is better at recovering real routes through case studies.
Structured Inverted-File k-Means Clustering for High-Dimensional Sparse Data
Mar 30, 2021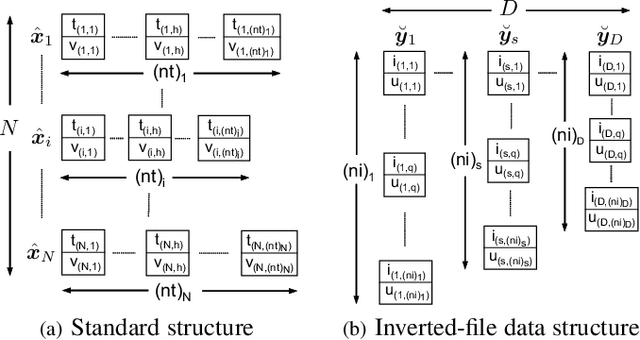
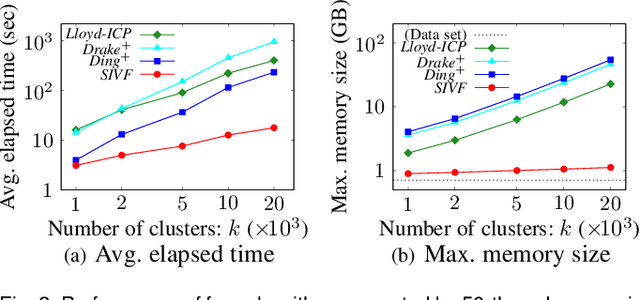
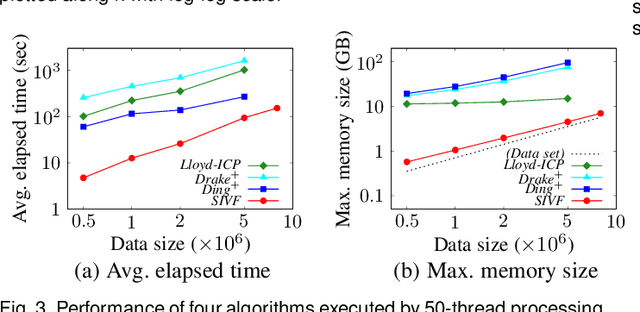
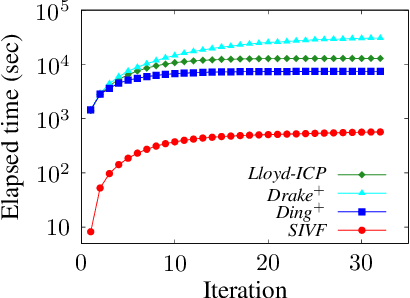
This paper presents an architecture-friendly k-means clustering algorithm called SIVF for a large-scale and high-dimensional sparse data set. Algorithm efficiency on time is often measured by the number of costly operations such as similarity calculations. In practice, however, it depends greatly on how the algorithm adapts to an architecture of the computer system which it is executed on. Our proposed SIVF employs invariant centroid-pair based filter (ICP) to decrease the number of similarity calculations between a data object and centroids of all the clusters. To maximize the ICP performance, SIVF exploits for a centroid set an inverted-file that is structured so as to reduce pipeline hazards. We demonstrate in our experiments on real large-scale document data sets that SIVF operates at higher speed and with lower memory consumption than existing algorithms. Our performance analysis reveals that SIVF achieves the higher speed by suppressing performance degradation factors of the number of cache misses and branch mispredictions rather than less similarity calculations.
Enabling Homomorphically Encrypted Inference for Large DNN Models
Mar 30, 2021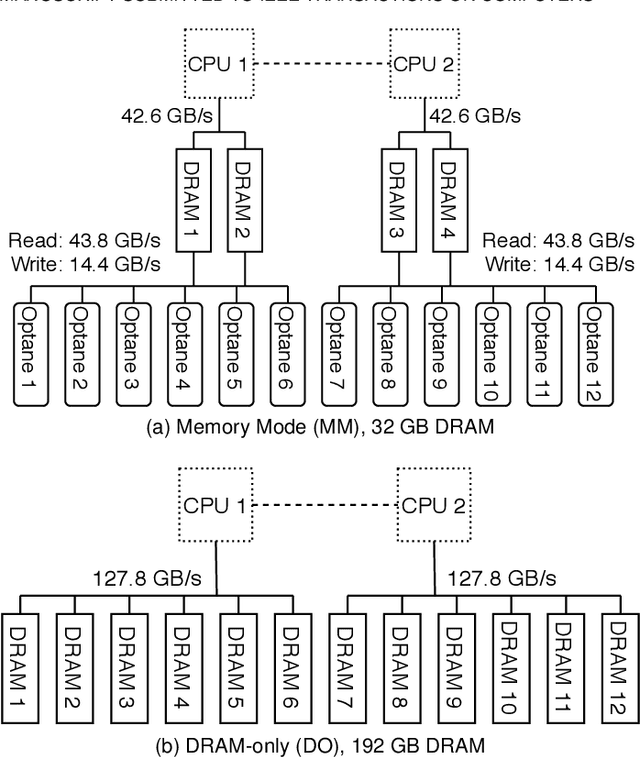
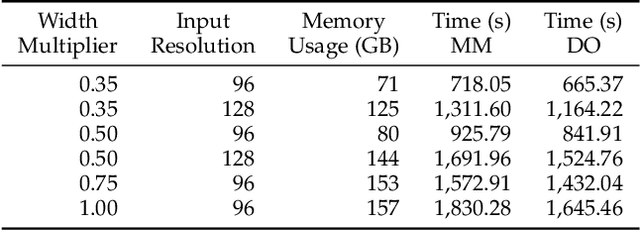
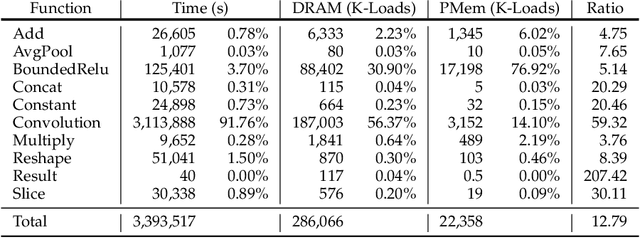
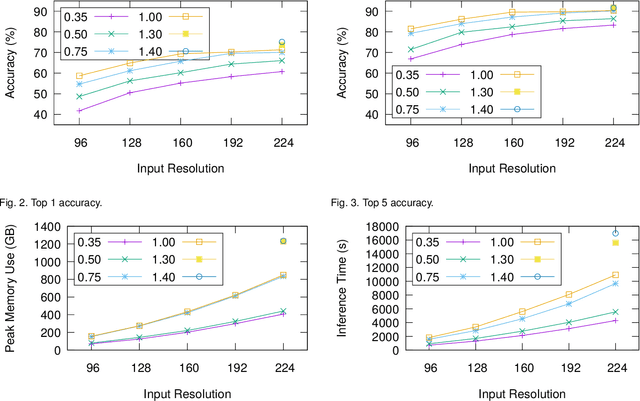
The proliferation of machine learning services in the last few years has raised data privacy concerns. Homomorphic encryption (HE) enables inference using encrypted data but it incurs 100x--10,000x memory and runtime overheads. Secure deep neural network (DNN) inference using HE is currently limited by computing and memory resources, with frameworks requiring hundreds of gigabytes of DRAM to evaluate small models. To overcome these limitations, in this paper we explore the feasibility of leveraging hybrid memory systems comprised of DRAM and persistent memory. In particular, we explore the recently-released Intel Optane PMem technology and the Intel HE-Transformer nGraph to run large neural networks such as MobileNetV2 (in its largest variant) and ResNet-50 for the first time in the literature. We present an in-depth analysis of the efficiency of the executions with different hardware and software configurations. Our results conclude that DNN inference using HE incurs on friendly access patterns for this memory configuration, yielding efficient executions.
DeepWORD: A GCN-based Approach for Owner-Member Relationship Detection in Autonomous Driving
Mar 30, 2021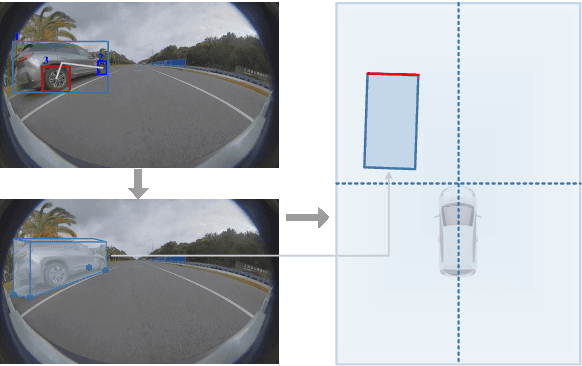
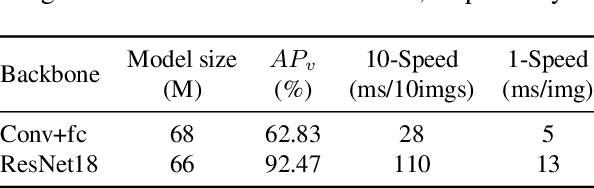

It's worth noting that the owner-member relationship between wheels and vehicles has an significant contribution to the 3D perception of vehicles, especially in the embedded environment. However, there are currently two main challenges about the above relationship prediction: i) The traditional heuristic methods based on IoU can hardly deal with the traffic jam scenarios for the occlusion. ii) It is difficult to establish an efficient applicable solution for the vehicle-mounted system. To address these issues, we propose an innovative relationship prediction method, namely DeepWORD, by designing a graph convolution network (GCN). Specifically, we utilize the feature maps with local correlation as the input of nodes to improve the information richness. Besides, we introduce the graph attention network (GAT) to dynamically amend the prior estimation deviation. Furthermore, we establish an annotated owner-member relationship dataset called WORD as a large-scale benchmark, which will be available soon. The experiments demonstrate that our solution achieves state-of-the-art accuracy and real-time in practice.
NetVec: A Scalable Hypergraph Embedding System
Mar 09, 2021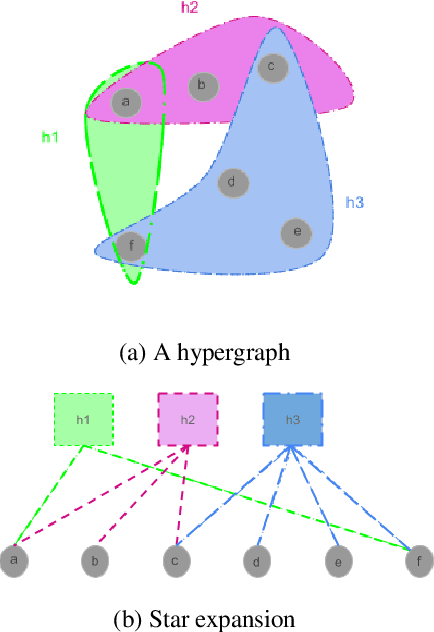
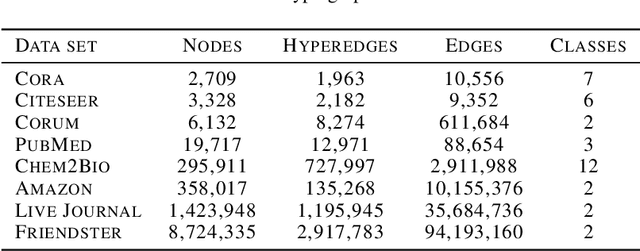
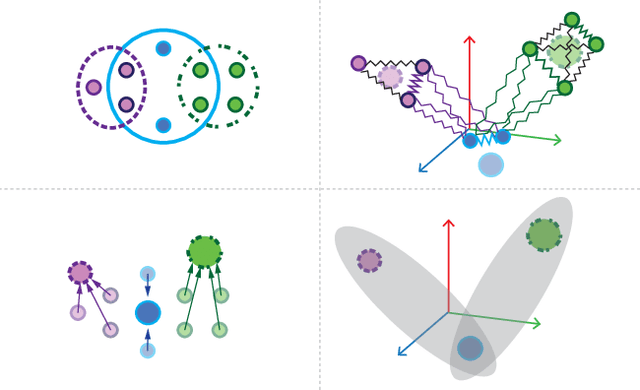

Many problems such as vertex classification andlink prediction in network data can be solvedusing graph embeddings, and a number of algo-rithms are known for constructing such embed-dings. However, it is difficult to use graphs tocapture non-binary relations such as communitiesof vertices. These kinds of complex relations areexpressed more naturally as hypergraphs. Whilehypergraphs are a generalization of graphs, state-of-the-art graph embedding techniques are notadequate for solving prediction and classificationtasks on large hypergraphs accurately in reason-able time. In this paper, we introduce NetVec,a novel multi-level framework for scalable un-supervised hypergraph embedding, that can becoupled with any graph embedding algorithm toproduce embeddings of hypergraphs with millionsof nodes and hyperedges in a few minutes.
LSTM Networks for Data-Aware Remaining Time Prediction of Business Process Instances
Nov 10, 2017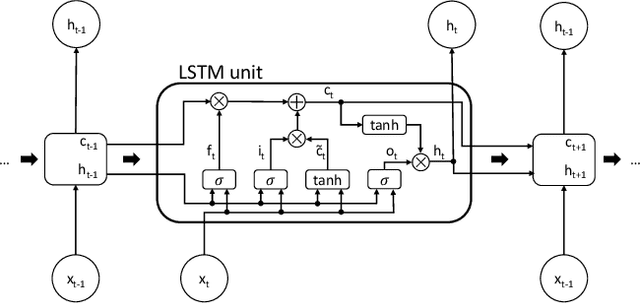
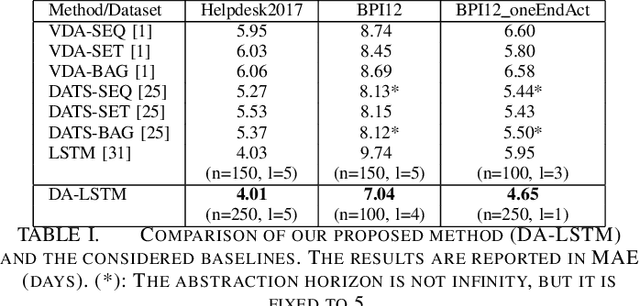
Predicting the completion time of business process instances would be a very helpful aid when managing processes under service level agreement constraints. The ability to know in advance the trend of running process instances would allow business managers to react in time, in order to prevent delays or undesirable situations. However, making such accurate forecasts is not easy: many factors may influence the required time to complete a process instance. In this paper, we propose an approach based on deep Recurrent Neural Networks (specifically LSTMs) that is able to exploit arbitrary information associated to single events, in order to produce an as-accurate-as-possible prediction of the completion time of running instances. Experiments on real-world datasets confirm the quality of our proposal.
Parameter and density estimation from real-world traffic data: A kinetic compartmental approach
Jan 27, 2021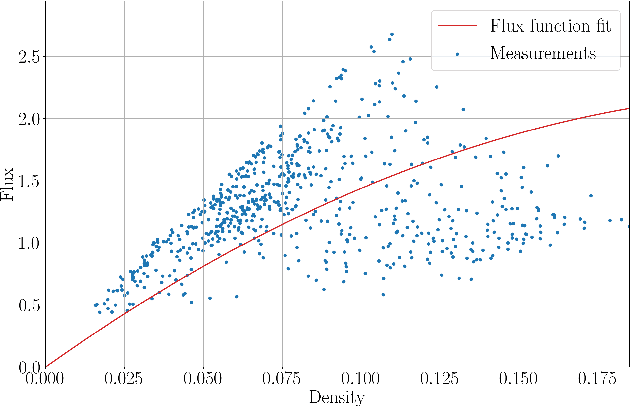
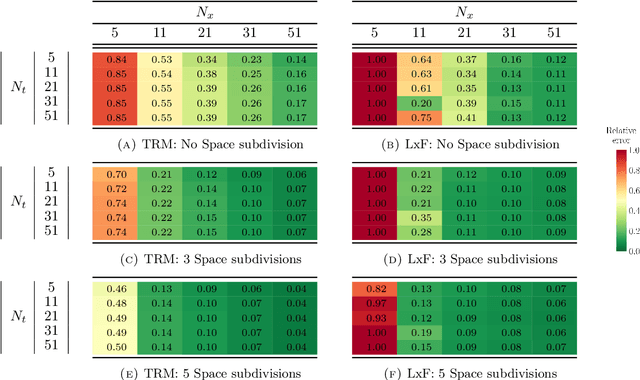
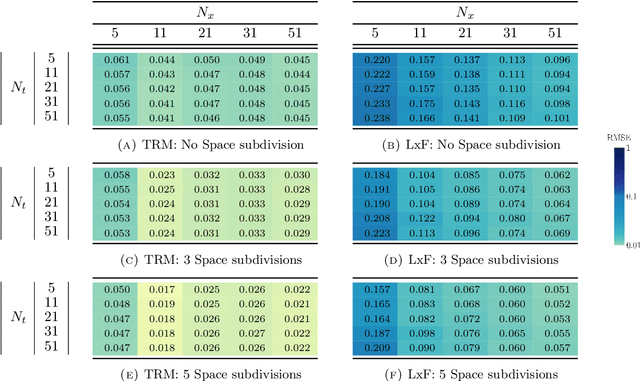
The main motivation of this work is to assess the validity of a LWR traffic flow model to model measurements obtained from trajectory data, and propose extensions of this model to improve it. A formulation for a discrete dynamical system is proposed aiming at reproducing the evolution in time of the density of vehicles along a road, as observed in the measurements. This system is formulated as a chemical reaction network where road cells are interpreted as compartments, the transfer of vehicles from one cell to the other is seen as a chemical reaction between adjacent compartment and the density of vehicles is seen as a concentration of reactant. Several degrees of flexibility on the parameters of this system, which basically consist of the reaction rates between the compartments, can be considered: a constant value or a function depending on time and/or space. Density measurements coming from trajectory data are then interpreted as observations of the states of this system at consecutive times. Optimal reaction rates for the system are then obtained by minimizing the discrepancy between the output of the system and the state measurements. This approach was tested both on simulated and real data, proved successful in recreating the complexity of traffic flows despite the assumptions on the flux-density relation.
RL-GRIT: Reinforcement Learning for Grammar Inference
May 17, 2021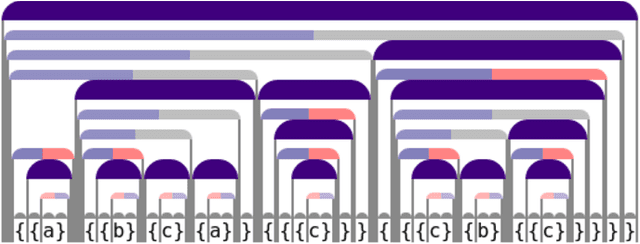
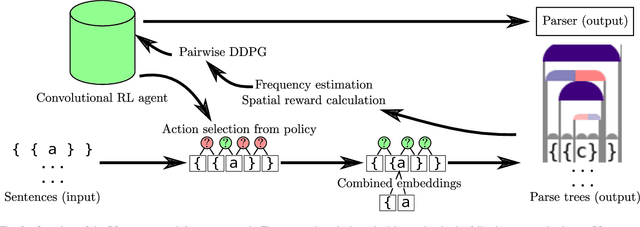
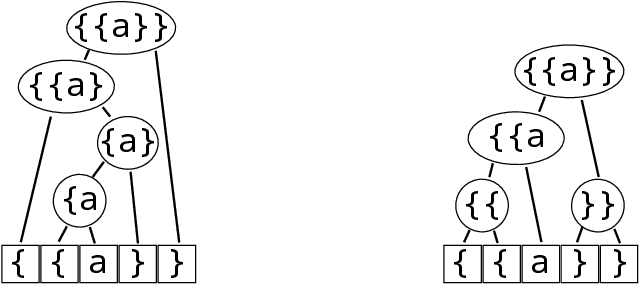
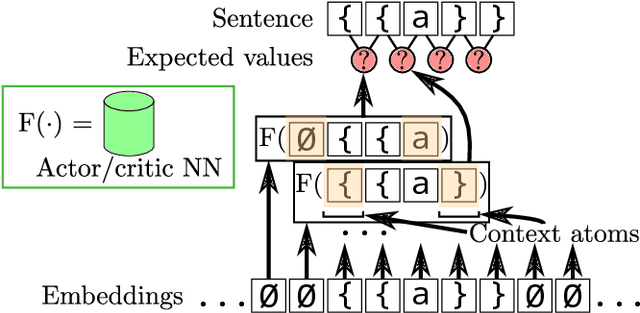
When working to understand usage of a data format, examples of the data format are often more representative than the format's specification. For example, two different applications might use very different JSON representations, or two PDF-writing applications might make use of very different areas of the PDF specification to realize the same rendered content. The complexity arising from these distinct origins can lead to large, difficult-to-understand attack surfaces, presenting a security concern when considering both exfiltration and data schizophrenia. Grammar inference can aid in describing the practical language generator behind examples of a data format. However, most grammar inference research focuses on natural language, not data formats, and fails to support crucial features such as type recursion. We propose a novel set of mechanisms for grammar inference, RL-GRIT, and apply them to understanding de facto data formats. After reviewing existing grammar inference solutions, it was determined that a new, more flexible scaffold could be found in Reinforcement Learning (RL). Within this work, we lay out the many algorithmic changes required to adapt RL from its traditional, sequential-time environment to the highly interdependent environment of parsing. The result is an algorithm which can demonstrably learn recursive control structures in simple data formats, and can extract meaningful structure from fragments of the PDF format. Whereas prior work in grammar inference focused on either regular languages or constituency parsing, we show that RL can be used to surpass the expressiveness of both classes, and offers a clear path to learning context-sensitive languages. The proposed algorithm can serve as a building block for understanding the ecosystems of de facto data formats.