 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning Techniques for Software Quality Assurance: A Survey
Apr 29, 2021

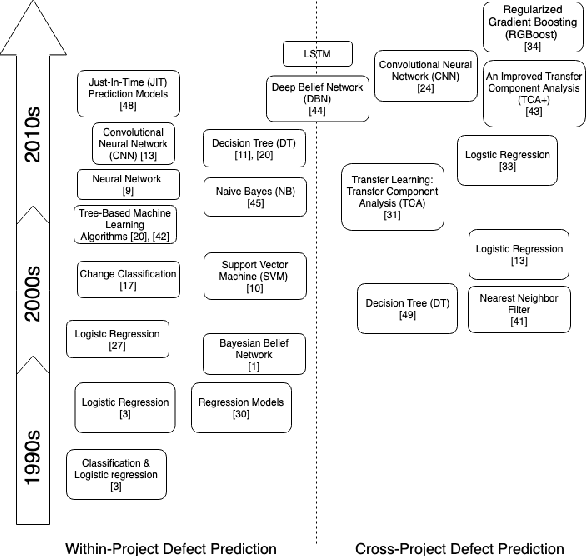
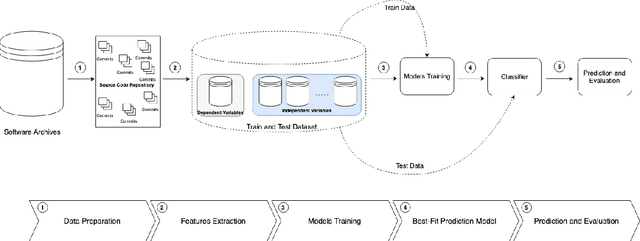
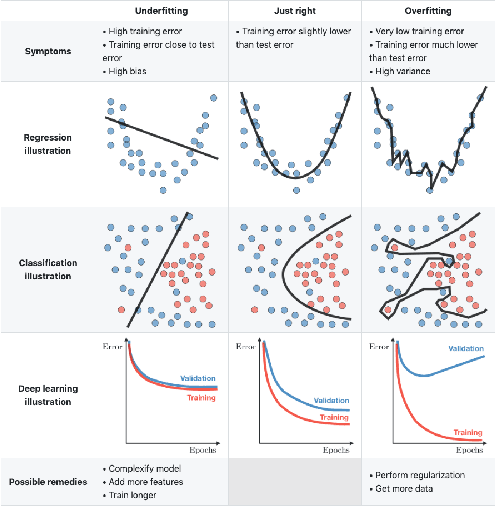
Over the last years, machine learning techniques have been applied to more and more application domains, including software engineering and, especially, software quality assurance. Important application domains have been, e.g., software defect prediction or test case selection and prioritization. The ability to predict which components in a large software system are most likely to contain the largest numbers of faults in the next release helps to better manage projects, including early estimation of possible release delays, and affordably guide corrective actions to improve the quality of the software. However, developing robust fault prediction models is a challenging task and many techniques have been proposed in the literature. Closely related to estimating defect-prone parts of a software system is the question of how to select and prioritize test cases, and indeed test case prioritization has been extensively researched as a means for reducing the time taken to discover regressions in software. In this survey, we discuss various approaches in both fault prediction and test case prioritization, also explaining how in recent studies deep learning algorithms for fault prediction help to bridge the gap between programs' semantics and fault prediction features. We also review recently proposed machine learning methods for test case prioritization (TCP), and their ability to reduce the cost of regression testing without negatively affecting fault detection capabilities.
Quantum spectral analysis: frequency in time, with applications to signal and image processing
Mar 16, 2018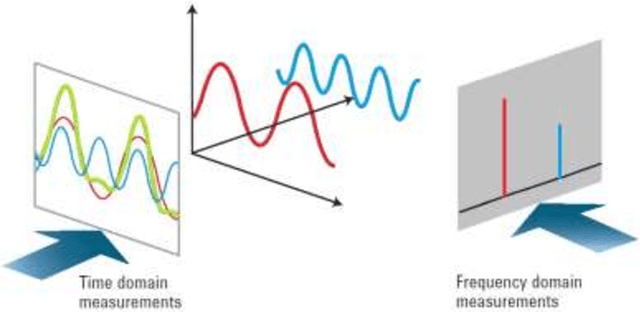

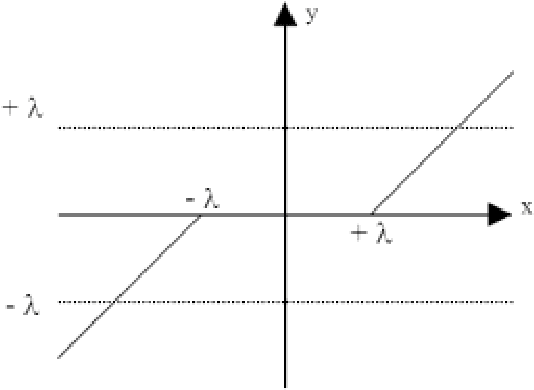
A quantum time-dependent spectrum analysis, or simply, quantum spectral analysis (QSA) is presented in this work, and it is based on Schrodinger equation, which is a partial differential equation that describes how the quantum state of a non-relativistic physical system changes with time. In classic world is named frequency in time (FIT), which is presented here in opposition and as a complement of traditional spectral analysis frequency-dependent based on Fourier theory. Besides, FIT is a metric, which assesses the impact of the flanks of a signal on its frequency spectrum, which is not taken into account by Fourier theory and even less in real time. Even more, and unlike all derived tools from Fourier Theory (i.e., continuous, discrete, fast, short-time, fractional and quantum Fourier Transform, as well as, Gabor) FIT has the following advantages: a) compact support with excellent energy output treatment, b) low computational cost, O(N) for signals and O(N2) for images, c) it does not have phase uncertainties (indeterminate phase for magnitude = 0) as Discrete and Fast Fourier Transform (DFT, FFT, respectively), d) among others. In fact, FIT constitutes one side of a triangle (which from now on is closed) and it consists of the original signal in time, spectral analysis based on Fourier Theory and FIT. Thus a toolbox is completed, which it is essential for all applications of Digital Signal Processing (DSP) and Digital Image Processing (DIP); and, even, in the latter, FIT allows edge detection (which is called flank detection in case of signals), denoising, despeckling, compression, and superresolution of still images. Such applications include signals intelligence and imagery intelligence. On the other hand, we will present other DIP tools, which are also derived from the Schrodinger equation.
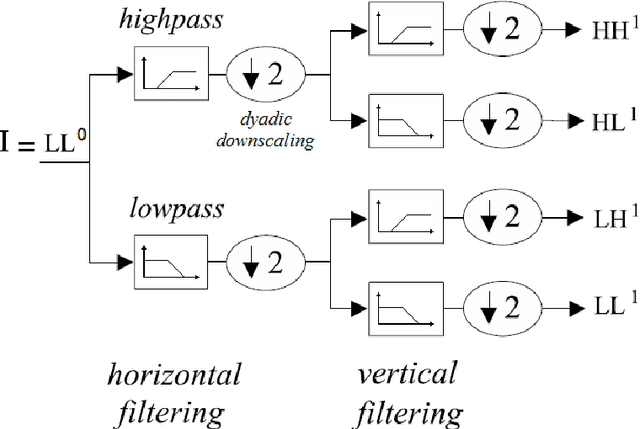
MVFNet: Multi-View Fusion Network for Efficient Video Recognition
Dec 13, 2020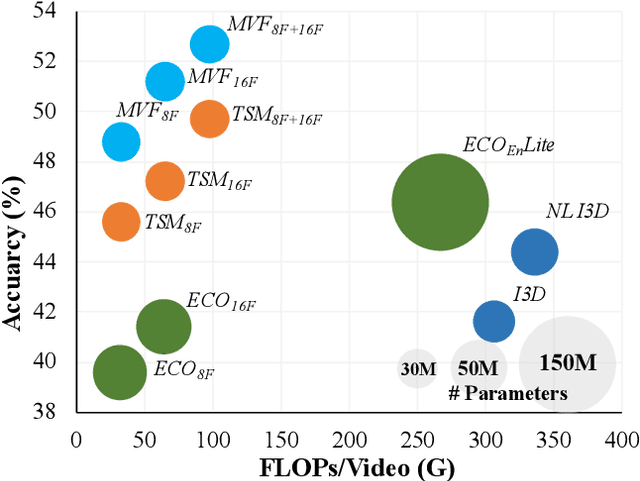
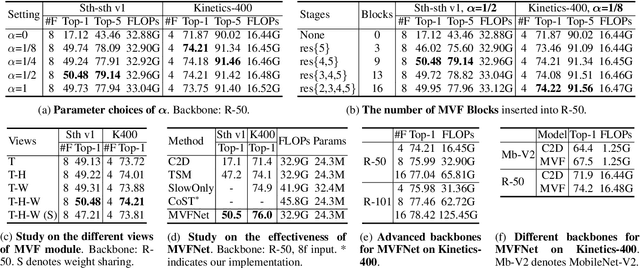
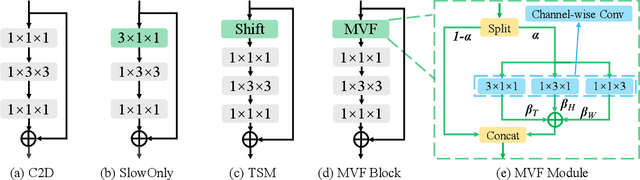
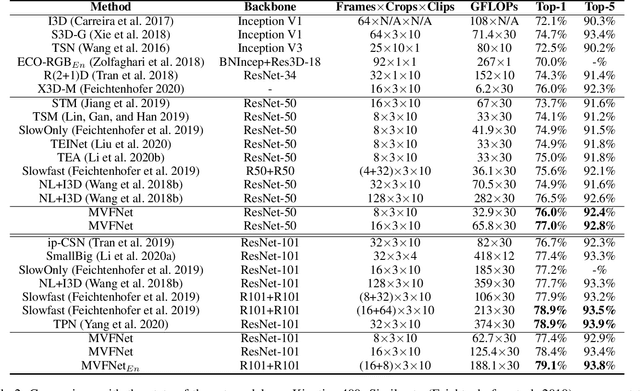
Conventionally, spatiotemporal modeling network and its complexity are the two most concentrated research topics in video action recognition. Existing state-of-the-art methods have achieved excellent accuracy regardless of the complexity meanwhile efficient spatiotemporal modeling solutions are slightly inferior in performance. In this paper, we attempt to acquire both efficiency and effectiveness simultaneously. First of all, besides traditionally treating H x W x T video frames as space-time signal (viewing from the Height-Width spatial plane), we propose to also model video from the other two Height-Time and Width-Time planes, to capture the dynamics of video thoroughly. Secondly, our model is designed based on 2D CNN backbones and model complexity is well kept in mind by design. Specifically, we introduce a novel multi-view fusion (MVF) module to exploit video dynamics using separable convolution for efficiency. It is a plug-and-play module and can be inserted into off-the-shelf 2D CNNs to form a simple yet effective model called MVFNet. Moreover, MVFNet can be thought of as a generalized video modeling framework and it can specialize to be existing methods such as C2D, SlowOnly, and TSM under different settings. Extensive experiments are conducted on popular benchmarks (i.e., Something-Something V1 & V2, Kinetics, UCF-101, and HMDB-51) to show its superiority. The proposed MVFNet can achieve state-of-the-art performance with 2D CNN's complexity.
CoSA: Scheduling by Constrained Optimization for Spatial Accelerators
May 05, 2021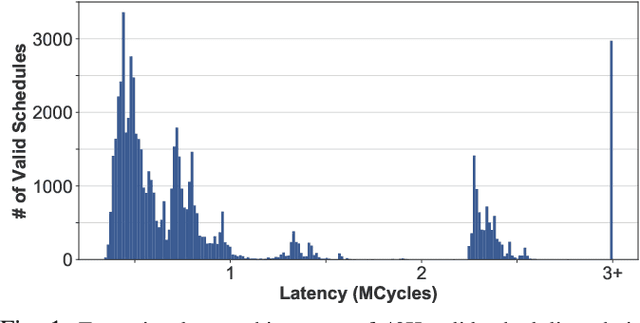
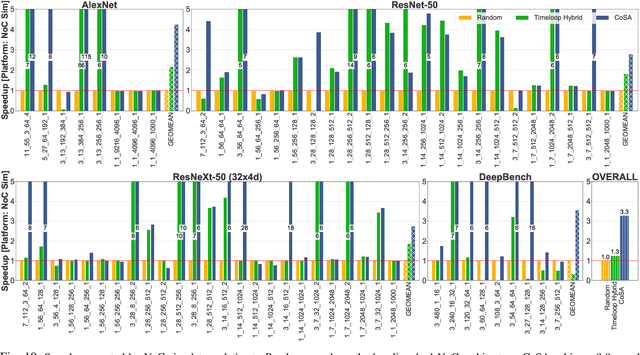
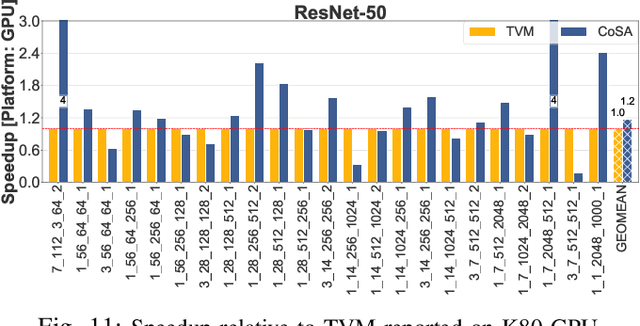
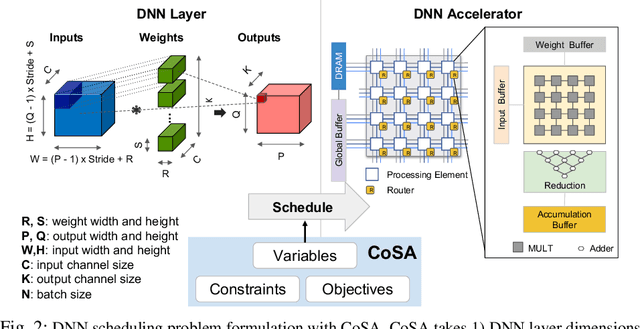
Recent advances in Deep Neural Networks (DNNs) have led to active development of specialized DNN accelerators, many of which feature a large number of processing elements laid out spatially, together with a multi-level memory hierarchy and flexible interconnect. While DNN accelerators can take advantage of data reuse and achieve high peak throughput, they also expose a large number of runtime parameters to the programmers who need to explicitly manage how computation is scheduled both spatially and temporally. In fact, different scheduling choices can lead to wide variations in performance and efficiency, motivating the need for a fast and efficient search strategy to navigate the vast scheduling space. To address this challenge, we present CoSA, a constrained-optimization-based approach for scheduling DNN accelerators. As opposed to existing approaches that either rely on designers' heuristics or iterative methods to navigate the search space, CoSA expresses scheduling decisions as a constrained-optimization problem that can be deterministically solved using mathematical optimization techniques. Specifically, CoSA leverages the regularities in DNN operators and hardware to formulate the DNN scheduling space into a mixed-integer programming (MIP) problem with algorithmic and architectural constraints, which can be solved to automatically generate a highly efficient schedule in one shot. We demonstrate that CoSA-generated schedules significantly outperform state-of-the-art approaches by a geometric mean of up to 2.5x across a wide range of DNN networks while improving the time-to-solution by 90x.
Learned complex masks for multi-instrument source separation
Mar 23, 2021
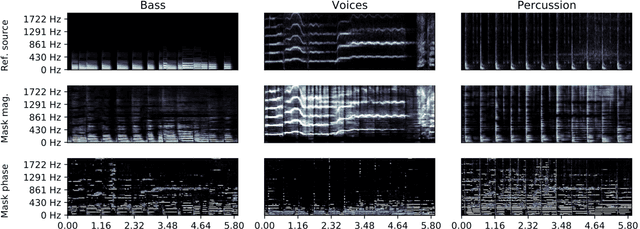
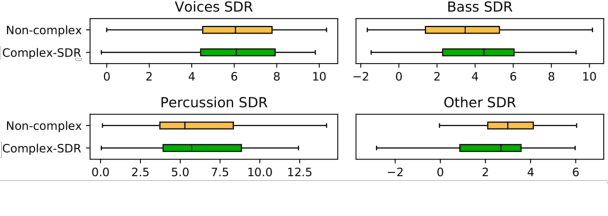
Music source separation in the time-frequency domain is commonly achieved by applying a soft or binary mask to the magnitude component of (complex) spectrograms. The phase component is usually not estimated, but instead copied from the mixture and applied to the magnitudes of the estimated isolated sources. While this method has several practical advantages, it imposes an upper bound on the performance of the system, where the estimated isolated sources inherently exhibit audible "phase artifacts". In this paper we address these shortcomings by directly estimating masks in the complex domain, extending recent work from the speech enhancement literature. The method is particularly well suited for multi-instrument musical source separation since residual phase artifacts are more pronounced for spectrally overlapping instrument sources, a common scenario in music. We show that complex masks result in better separation than masks that operate solely on the magnitude component.
TransCenter: Transformers with Dense Queries for Multiple-Object Tracking
Mar 28, 2021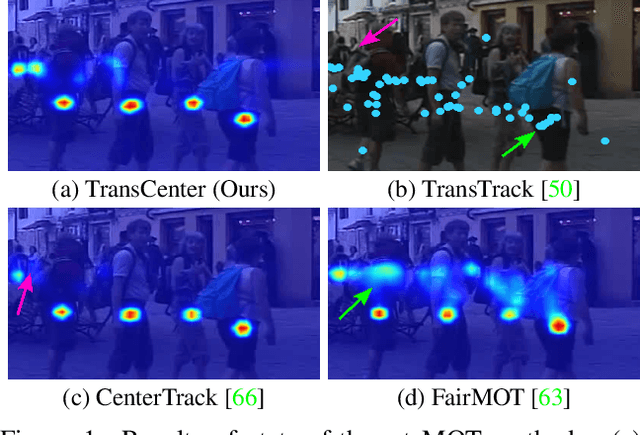
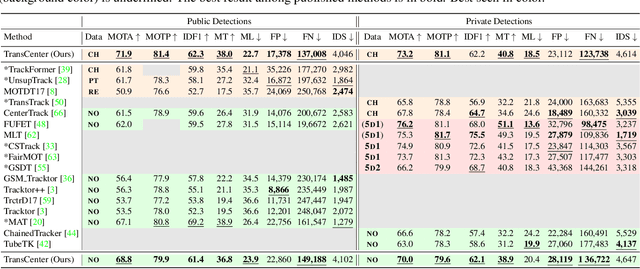
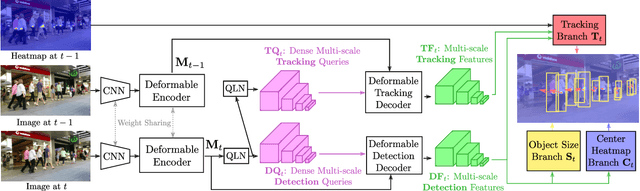
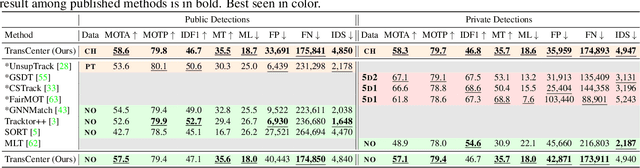
Transformer networks have proven extremely powerful for a wide variety of tasks since they were introduced. Computer vision is not an exception, as the use of transformers has become very popular in the vision community in recent years. Despite this wave, multiple-object tracking (MOT) exhibits for now some sort of incompatibility with transformers. We argue that the standard representation -- bounding boxes -- is not adapted to learning transformers for MOT. Inspired by recent research, we propose TransCenter, the first transformer-based architecture for tracking the centers of multiple targets. Methodologically, we propose the use of dense queries in a double-decoder network, to be able to robustly infer the heatmap of targets' centers and associate them through time. TransCenter outperforms the current state-of-the-art in multiple-object tracking, both in MOT17 and MOT20. Our ablation study demonstrates the advantage in the proposed architecture compared to more naive alternatives. The code will be made publicly available.
EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion
Apr 28, 2021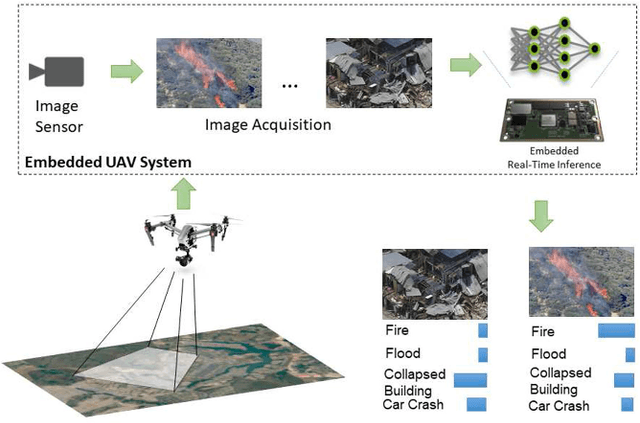



Deep learning-based algorithms can provide state-of-the-art accuracy for remote sensing technologies such as unmanned aerial vehicles (UAVs)/drones, potentially enhancing their remote sensing capabilities for many emergency response and disaster management applications. In particular, UAVs equipped with camera sensors can operating in remote and difficult to access disaster-stricken areas, analyze the image and alert in the presence of various calamities such as collapsed buildings, flood, or fire in order to faster mitigate their effects on the environment and on human population. However, the integration of deep learning introduces heavy computational requirements, preventing the deployment of such deep neural networks in many scenarios that impose low-latency constraints on inference, in order to make mission-critical decisions in real time. To this end, this article focuses on the efficient aerial image classification from on-board a UAV for emergency response/monitoring applications. Specifically, a dedicated Aerial Image Database for Emergency Response applications is introduced and a comparative analysis of existing approaches is performed. Through this analysis a lightweight convolutional neural network architecture is proposed, referred to as EmergencyNet, based on atrous convolutions to process multiresolution features and capable of running efficiently on low-power embedded platforms achieving upto 20x higher performance compared to existing models with minimal memory requirements with less than 1% accuracy drop compared to state-of-the-art models.
* C.Kyrkou and T. Theocharides, "EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion," in IEEE J Sel Top Appl Earth Obs Remote Sens. (JSTARS), vol. 13, pp. 1687-1699, 2020. arXiv admin note: substantial text overlap with arXiv:1906.08716
ProsoBeast Prosody Annotation Tool
Apr 06, 2021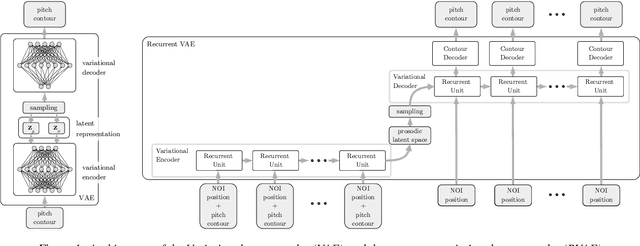
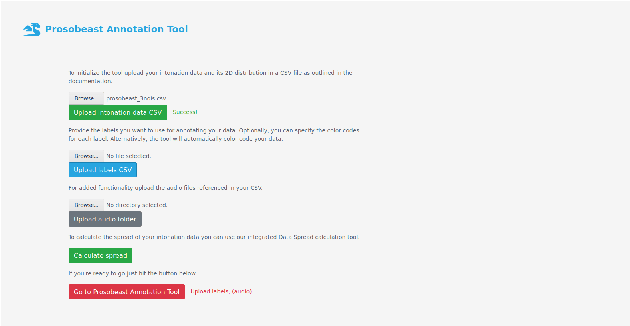
The labelling of speech corpora is a laborious and time-consuming process. The ProsoBeast Annotation Tool seeks to ease and accelerate this process by providing an interactive 2D representation of the prosodic landscape of the data, in which contours are distributed based on their similarity. This interactive map allows the user to inspect and label the utterances. The tool integrates several state-of-the-art methods for dimensionality reduction and feature embedding, including variational autoencoders. The user can use these to find a good representation for their data. In addition, as most of these methods are stochastic, each can be used to generate an unlimited number of different prosodic maps. The web app then allows the user to seamlessly switch between these alternative representations in the annotation process. Experiments with a sample prosodically rich dataset have shown that the tool manages to find good representations of varied data and is helpful both for annotation and label correction. The tool is released as free software for use by the community.
Parameterizing the Angular Distribution of Emission: A model for TOF-PET low counts reconstruction
May 05, 2021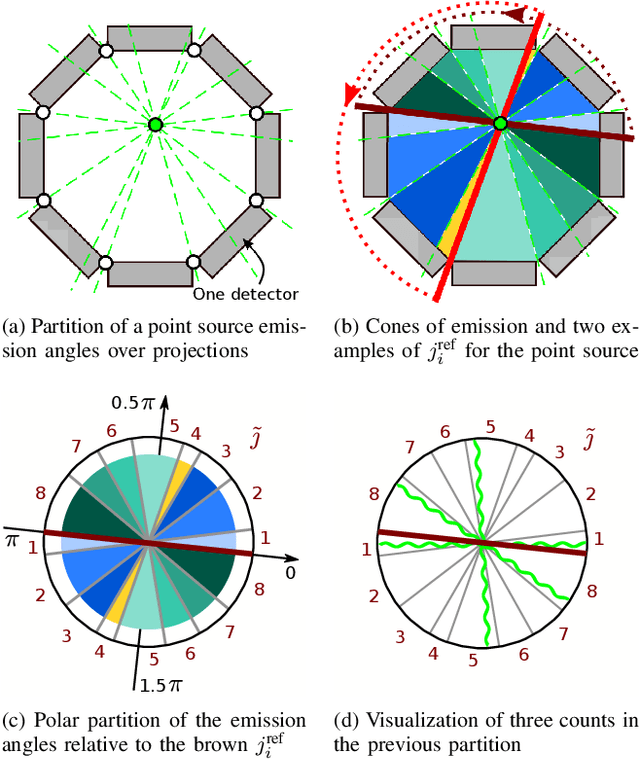
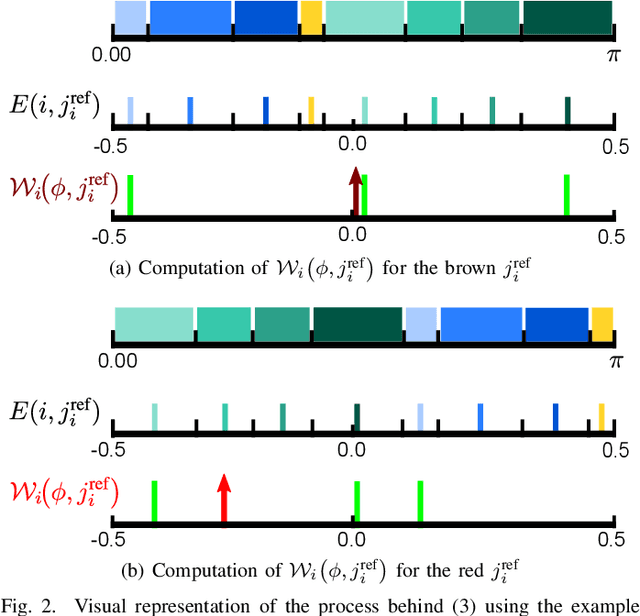

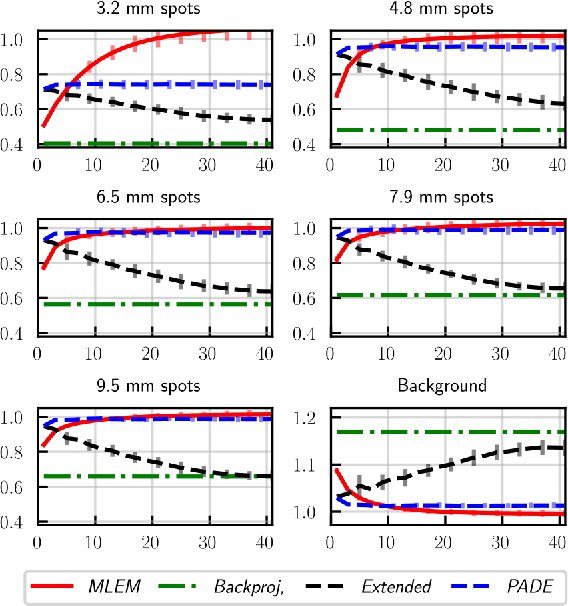
Low counts reconstruction remains a challenge for Positron Emission Tomography (PET) even with the recent progresses in time-of-flight (TOF) resolution. In that setting, the bias between the acquired histogram, composed of low values or zeros, and the expected histogram, obtained from the forward projector, is propagated to the image, resulting in a biased reconstruction. This could be exacerbated with finer resolution of the TOF information, which further sparsify the acquired histogram. We propose a new approach to circumvent this limitation of the classical reconstruction model. It consists of extending the parametrization of the reconstruction scheme to also explicitly include the projection domain. This parametrization has greater degrees of freedom than the log-likelihood model, which can not be harnessed in classical circumstances. We hypothesize that with ultra-fast TOF this new approach would not only be viable for low counts reconstruction but also more adequate than the classical reconstruction model. An implementation of this approach is compared to the log-likelihood model by using two-dimensional simulations of a hot spots phantom. The proposed model achieves similar contrast recovery coefficients as MLEM except for the smallest structures where the low counts nature of the simulations makes it difficult to draw conclusions. Also, this new model seems to converge toward a less noisy solution than the MLEM. These results suggest that this new approach has potential for low counts reconstruction with ultra-fast TOF.
Towards Optimized Distributed Multi-Robot Printing: An Algorithmic Approach
Feb 24, 2021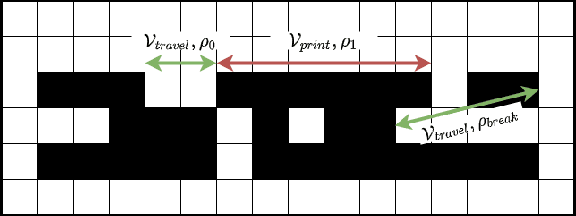
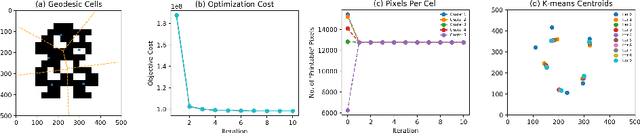
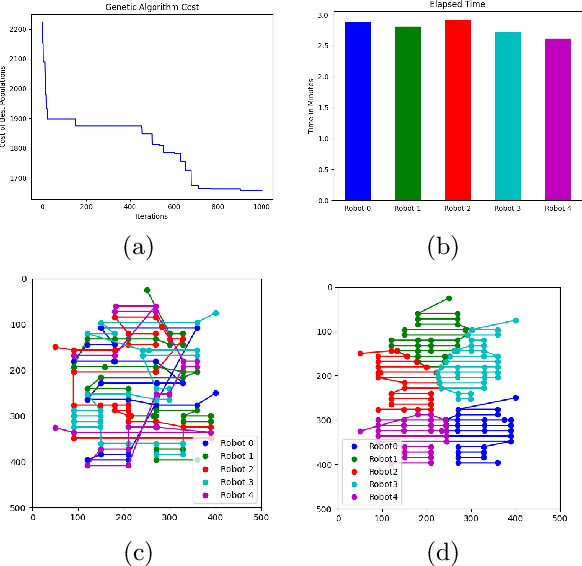
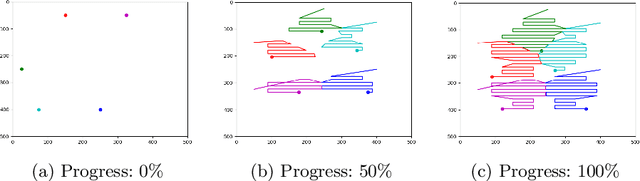
This paper presents a distributed multi-robot printing method which utilizes an optimization approach to decompose and allocate a printing task to a group of mobile robots. The motivation for this problem is to minimize the printing time of the robots by using an appropriate task decomposition algorithm. We present one such algorithm which decomposes an image into rasterized geodesic cells before allocating them to the robots for printing. In addition to this, we also present the design of a numerically controlled holonomic robot capable of spraying ink on smooth surfaces. Further, we use this robot to experimentally verify the results of this paper.