 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Matching of Users and Creators in Two-Sided Markets with Departures
Jan 17, 2024
Many online platforms of today, including social media sites, are two-sided markets bridging content creators and users. Most of the existing literature on platform recommendation algorithms largely focuses on user preferences and decisions, and does not simultaneously address creator incentives. We propose a model of content recommendation that explicitly focuses on the dynamics of user-content matching, with the novel property that both users and creators may leave the platform permanently if they do not experience sufficient engagement. In our model, each player decides to participate at each time step based on utilities derived from the current match: users based on alignment of the recommended content with their preferences, and creators based on their audience size. We show that a user-centric greedy algorithm that does not consider creator departures can result in arbitrarily poor total engagement, relative to an algorithm that maximizes total engagement while accounting for two-sided departures. Moreover, in stark contrast to the case where only users or only creators leave the platform, we prove that with two-sided departures, approximating maximum total engagement within any constant factor is NP-hard. We present two practical algorithms, one with performance guarantees under mild assumptions on user preferences, and another that tends to outperform algorithms that ignore two-sided departures in practice.
Functional Linear Non-Gaussian Acyclic Model for Causal Discovery
Jan 17, 2024
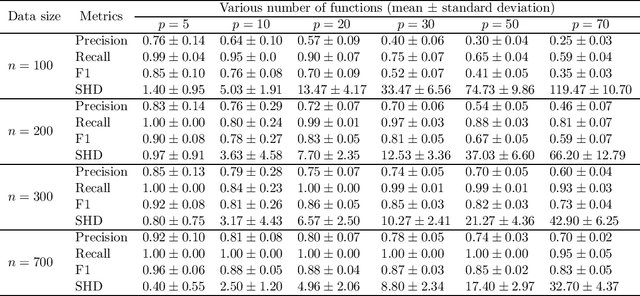
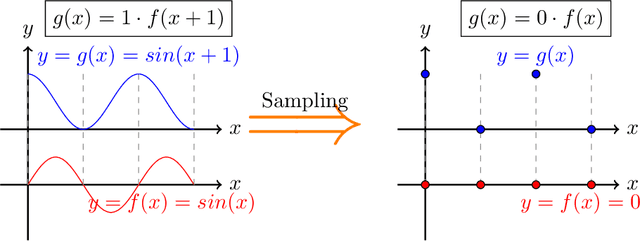
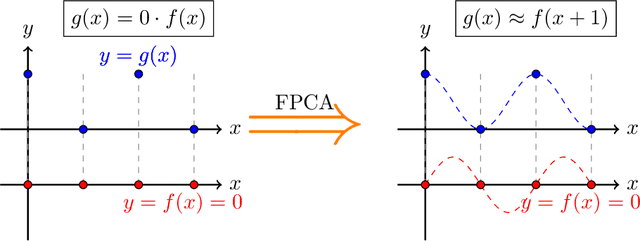
In causal discovery, non-Gaussianity has been used to characterize the complete configuration of a Linear Non-Gaussian Acyclic Model (LiNGAM), encompassing both the causal ordering of variables and their respective connection strengths. However, LiNGAM can only deal with the finite-dimensional case. To expand this concept, we extend the notion of variables to encompass vectors and even functions, leading to the Functional Linear Non-Gaussian Acyclic Model (Func-LiNGAM). Our motivation stems from the desire to identify causal relationships in brain-effective connectivity tasks involving, for example, fMRI and EEG datasets. We demonstrate why the original LiNGAM fails to handle these inherently infinite-dimensional datasets and explain the availability of functional data analysis from both empirical and theoretical perspectives. {We establish theoretical guarantees of the identifiability of the causal relationship among non-Gaussian random vectors and even random functions in infinite-dimensional Hilbert spaces.} To address the issue of sparsity in discrete time points within intrinsic infinite-dimensional functional data, we propose optimizing the coordinates of the vectors using functional principal component analysis. Experimental results on synthetic data verify the ability of the proposed framework to identify causal relationships among multivariate functions using the observed samples. For real data, we focus on analyzing the brain connectivity patterns derived from fMRI data.
To deform or not: treatment-aware longitudinal registration for breast DCE-MRI during neoadjuvant chemotherapy via unsupervised keypoints detection
Jan 17, 2024Clinicians compare breast DCE-MRI after neoadjuvant chemotherapy (NAC) with pre-treatment scans to evaluate the response to NAC. Clinical evidence supports that accurate longitudinal deformable registration without deforming treated tumor regions is key to quantifying tumor changes. We propose a conditional pyramid registration network based on unsupervised keypoint detection and selective volume-preserving to quantify changes over time. In this approach, we extract the structural and the abnormal keypoints from DCE-MRI, apply the structural keypoints for the registration algorithm to restrict large deformation, and employ volume-preserving loss based on abnormal keypoints to keep the volume of the tumor unchanged after registration. We use a clinical dataset with 1630 MRI scans from 314 patients treated with NAC. The results demonstrate that our method registers with better performance and better volume preservation of the tumors. Furthermore, a local-global-combining biomarker based on the proposed method achieves high accuracy in pathological complete response (pCR) prediction, indicating that predictive information exists outside tumor regions. The biomarkers could potentially be used to avoid unnecessary surgeries for certain patients. It may be valuable for clinicians and/or computer systems to conduct follow-up tumor segmentation and response prediction on images registered by our method. Our code is available on \url{https://github.com/fiy2W/Treatment-aware-Longitudinal-Registration}.
BENO: Boundary-embedded Neural Operators for Elliptic PDEs
Jan 17, 2024Elliptic partial differential equations (PDEs) are a major class of time-independent PDEs that play a key role in many scientific and engineering domains such as fluid dynamics, plasma physics, and solid mechanics. Recently, neural operators have emerged as a promising technique to solve elliptic PDEs more efficiently by directly mapping the input to solutions. However, existing networks typically cannot handle complex geometries and inhomogeneous boundary values present in the real world. Here we introduce Boundary-Embedded Neural Operators (BENO), a novel neural operator architecture that embeds the complex geometries and inhomogeneous boundary values into the solving of elliptic PDEs. Inspired by classical Green's function, BENO consists of two branches of Graph Neural Networks (GNNs) for interior source term and boundary values, respectively. Furthermore, a Transformer encoder maps the global boundary geometry into a latent vector which influences each message passing layer of the GNNs. We test our model extensively in elliptic PDEs with various boundary conditions. We show that all existing baseline methods fail to learn the solution operator. In contrast, our model, endowed with boundary-embedded architecture, outperforms state-of-the-art neural operators and strong baselines by an average of 60.96\%. Our source code can be found https://github.com/AI4Science-WestlakeU/beno.git.
Tight Fusion of Events and Inertial Measurements for Direct Velocity Estimation
Jan 17, 2024Traditional visual-inertial state estimation targets absolute camera poses and spatial landmark locations while first-order kinematics are typically resolved as an implicitly estimated sub-state. However, this poses a risk in velocity-based control scenarios, as the quality of the estimation of kinematics depends on the stability of absolute camera and landmark coordinates estimation. To address this issue, we propose a novel solution to tight visual-inertial fusion directly at the level of first-order kinematics by employing a dynamic vision sensor instead of a normal camera. More specifically, we leverage trifocal tensor geometry to establish an incidence relation that directly depends on events and camera velocity, and demonstrate how velocity estimates in highly dynamic situations can be obtained over short time intervals. Noise and outliers are dealt with using a nested two-layer RANSAC scheme. Additionally, smooth velocity signals are obtained from a tight fusion with pre-integrated inertial signals using a sliding window optimizer. Experiments on both simulated and real data demonstrate that the proposed tight event-inertial fusion leads to continuous and reliable velocity estimation in highly dynamic scenarios independently of absolute coordinates. Furthermore, in extreme cases, it achieves more stable and more accurate estimation of kinematics than traditional, point-position-based visual-inertial odometry.
Exploration of Activation Fault Reliability in Quantized Systolic Array-Based DNN Accelerators
Jan 17, 2024The stringent requirements for the Deep Neural Networks (DNNs) accelerator's reliability stand along with the need for reducing the computational burden on the hardware platforms, i.e. reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators. Moreover, the growing demand for specialized DNN accelerators with tailored requirements, particularly for safety-critical applications, necessitates a comprehensive design space exploration to enable the development of efficient and robust accelerators that meet those requirements. Therefore, the trade-off between hardware performance, i.e. area and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis. This paper presents a comprehensive methodology for exploring and enabling a holistic assessment of the trilateral impact of quantization on model accuracy, activation fault reliability, and hardware efficiency. A fully automated framework is introduced that is capable of applying various quantization-aware techniques, fault injection, and hardware implementation, thus enabling the measurement of hardware parameters. Moreover, this paper proposes a novel lightweight protection technique integrated within the framework to ensure the dependable deployment of the final systolic-array-based FPGA implementation. The experiments on established benchmarks demonstrate the analysis flow and the profound implications of quantization on reliability, hardware performance, and network accuracy, particularly concerning the transient faults in the network's activations.
Herding LLaMaS: Using LLMs as an OS Module
Jan 17, 2024Computer systems are becoming increasingly heterogeneous with the emergence of new memory technologies and compute devices. GPUs alongside CPUs have become commonplace and CXL is poised to be a mainstay of cloud systems. The operating system is responsible for managing these hardware resources, requiring modification every time a new device is released. Years of research and development are sunk into tuning the OS for high performance with each new heterogeneous device. With the recent explosion in memory technologies and domain-specific accelerators, it would be beneficial to have an OS that could provide high performance for new devices without significant effort. We propose LLaMaS which can adapt to new devices easily. LLaMaS uses Large Language Models (LLMs) to extract the useful features of new devices from their textual description and uses these features to make operating system decisions at runtime. Adding support to LLaMaS for a new device is as simple as describing the system and new device properties in plaintext. LLaMaS reduces the burden on system administrators to enable easy integration of new devices into production systems. Preliminary evaluation using ChatGPT shows that LLMs are capable of extracting device features from text and make correct OS decisions based on those features.
Reservoir computing with logistic map
Jan 17, 2024Recent studies on reservoir computing essentially involve a high dimensional dynamical system as the reservoir, which transforms and stores the input as a higher dimensional state, for temporal and nontemporal data processing. We demonstrate here a method to predict temporal and nontemporal tasks by constructing virtual nodes as constituting a reservoir in reservoir computing using a nonlinear map, namely logistic map, and a simple finite trigonometric series. We predict three nonlinear systems, namely Lorenz, R\"ossler, and Hindmarsh-Rose, for temporal tasks and a seventh order polynomial for nontemporal tasks with great accuracy. Also, the prediction is made in the presence of noise and found to closely agree with the target. Remarkably, the logistic map performs well and predicts close to the actual or target values. The low values of the root mean square error confirm the accuracy of this method in terms of efficiency. Our approach removes the necessity of continuous dynamical systems for constructing the reservoir in reservoir computing. Moreover, the accurate prediction for the three different nonlinear systems suggests that this method can be considered a general one and can be applied to predict many systems. Finally, we show that the method also accurately anticipates the time series for the future (self prediction).
LatestEval: Addressing Data Contamination in Language Model Evaluation through Dynamic and Time-Sensitive Test Construction
Dec 26, 2023Data contamination in evaluation is getting increasingly prevalent with the emergence of language models pre-trained on super large, automatically crawled corpora. This problem leads to significant challenges in the accurate assessment of model capabilities and generalisations. In this paper, we propose LatestEval, an automatic method that leverages the most recent texts to create uncontaminated reading comprehension evaluations. LatestEval avoids data contamination by only using texts published within a recent time window, ensuring no overlap with the training corpora of pre-trained language models. We develop the LatestEval automated pipeline to 1) gather the latest texts; 2) identify key information, and 3) construct questions targeting the information while removing the existing answers from the context. This encourages models to infer the answers themselves based on the remaining context, rather than just copy-paste. Our experiments demonstrate that language models exhibit negligible memorisation behaviours on LatestEval as opposed to previous benchmarks, suggesting a significantly reduced risk of data contamination and leading to a more robust evaluation. Data and code are publicly available at: https://github.com/liyucheng09/LatestEval.
Input Convex Lipschitz RNN: A Fast and Robust Approach for Engineering Tasks
Jan 15, 2024Computational efficiency and adversarial robustness are critical factors in real-world engineering applications. Yet, conventional neural networks often fall short in addressing both simultaneously, or even separately. Drawing insights from natural physical systems and existing literature, it is known that an input convex architecture enhances computational efficiency, while a Lipschitz-constrained architecture bolsters adversarial robustness. By leveraging the strengths of convexity and Lipschitz continuity, we develop a novel network architecture, termed Input Convex Lipschitz Recurrent Neural Network. This model outperforms existing recurrent units across a spectrum of engineering tasks in terms of computational efficiency and adversarial robustness. These tasks encompass a benchmark MNIST image classification, real-world solar irradiance prediction for Solar PV system planning at LHT Holdings in Singapore, and real-time Model Predictive Control optimization for a chemical reactor.