 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Hammer and the Nut: Is Bilevel Optimization Really Needed to Poison Linear Classifiers?
Mar 23, 2021
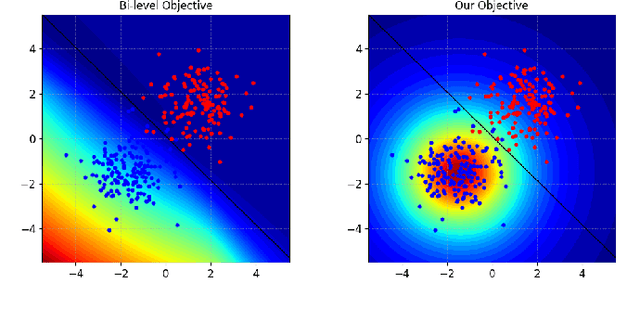



One of the most concerning threats for modern AI systems is data poisoning, where the attacker injects maliciously crafted training data to corrupt the system's behavior at test time. Availability poisoning is a particularly worrisome subset of poisoning attacks where the attacker aims to cause a Denial-of-Service (DoS) attack. However, the state-of-the-art algorithms are computationally expensive because they try to solve a complex bi-level optimization problem (the "hammer"). We observed that in particular conditions, namely, where the target model is linear (the "nut"), the usage of computationally costly procedures can be avoided. We propose a counter-intuitive but efficient heuristic that allows contaminating the training set such that the target system's performance is highly compromised. We further suggest a re-parameterization trick to decrease the number of variables to be optimized. Finally, we demonstrate that, under the considered settings, our framework achieves comparable, or even better, performances in terms of the attacker's objective while being significantly more computationally efficient.
Empowering Mobile Edge Computing by Exploiting Reconfigurable Intelligent Surface
Feb 04, 2021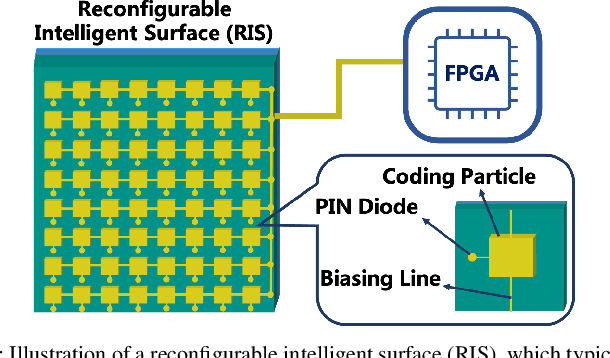
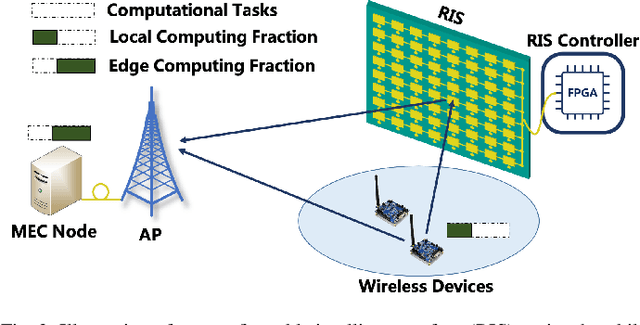
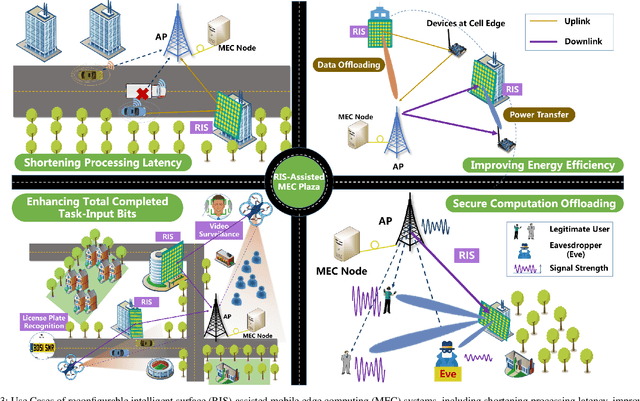
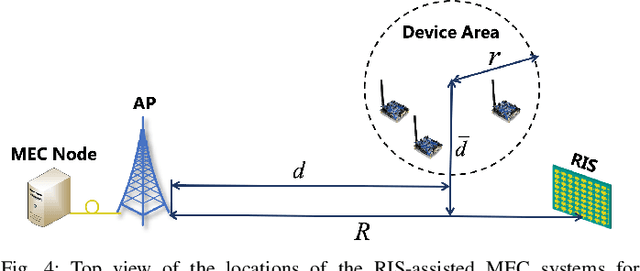
Along with the proliferation of sensors and of smart devices, an explosive volume of data will be generated. However, restricted by their limited physical sizes and low manufacturing costs, these wireless devices are typically equipped with limited computational capabilities and battery lives and thus incapable of processing data time-efficiently. To overcome this issue, the paradigm of mobile edge computing (MEC) is proposed, where wireless devices may offload all or a fraction of their computation tasks to their nearby computing nodes deployed at the network edge. At the time of writing, the benefits of MEC systems have not been fully exploited, predominately because the computation offloading link is still far from the perfect. In this article, we propose to empower the MEC systems by exploiting the emerging technique of reconfigurable intelligent surfaces, which is capable of reconfiguring the wireless propagation environments and hence of enhancing the offloading links. The beneficial role of RISs can be exploited by jointly optimizing both the RISs as well as communications and computing resource allocations of MEC systems, which imposes new research challenges on the systemic design and thus necessitates a specific investigation. Against this background, this article provides an overview of RIS-assisted MEC systems and highlights their four use cases as well as their design challenges and solutions. Then their advantageous performance is validated with the aid of a specific case study. Finally, a guide on future research opportunities is elucidated.
Accelerating ODE-Based Neural Networks on Low-Cost FPGAs
Jan 03, 2021
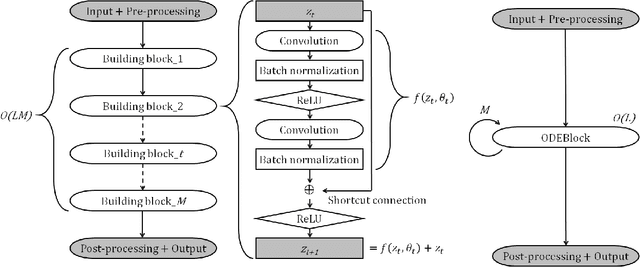
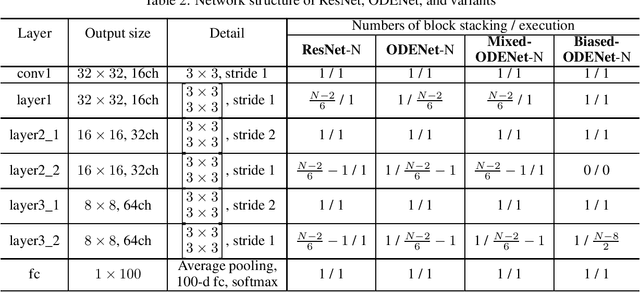
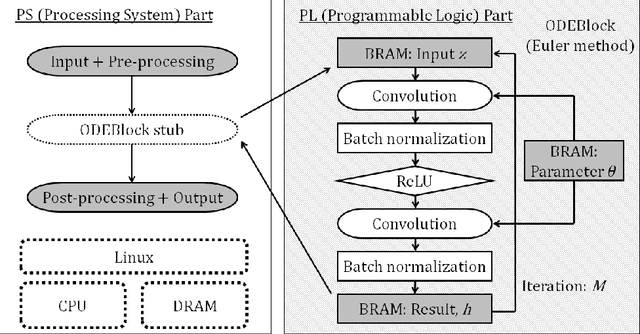
ODENet is a deep neural network architecture in which a stacking structure of ResNet is implemented with an ordinary differential equation (ODE) solver. It can reduce the number of parameters and strike a balance between accuracy and performance by selecting a proper solver. It is also possible to improve the accuracy while keeping the same number of parameters on resource-limited edge devices. In this paper, using Euler method as an ODE solver, a part of ODENet is implemented as a dedicated logic on a low-cost FPGA (Field-Programmable Gate Array) board, such as PYNQ-Z2 board. Two variants, one for high accuracy and the other for performance, are proposed and implemented on the FPGA board as well. They are evaluated in terms of parameter size, accuracy, execution time, and resource utilization on the FPGA. The results show that an overall execution time of ODENet and its variants is improved by up to 2.50 times compared to a pure software execution when a part of convolution layers is executed by the programmable logic.
Reversible Watermarking in Deep Convolutional Neural Networks for Integrity Authentication
Apr 09, 2021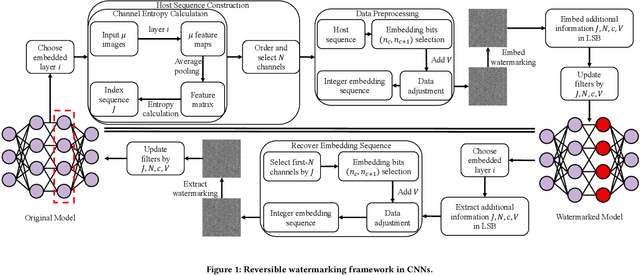
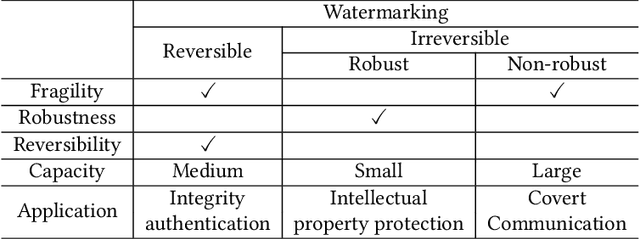
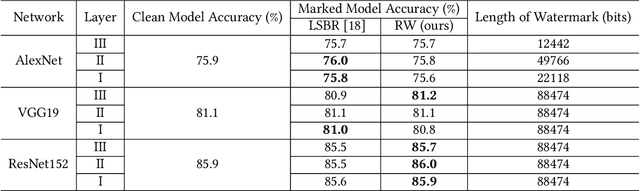
Deep convolutional neural networks have made outstanding contributions in many fields such as computer vision in the past few years and many researchers published well-trained network for downloading. But recent studies have shown serious concerns about integrity due to model-reuse attacks and backdoor attacks. In order to protect these open-source networks, many algorithms have been proposed such as watermarking. However, these existing algorithms modify the contents of the network permanently and are not suitable for integrity authentication. In this paper, we propose a reversible watermarking algorithm for integrity authentication. Specifically, we present the reversible watermarking problem of deep convolutional neural networks and utilize the pruning theory of model compression technology to construct a host sequence used for embedding watermarking information by histogram shift. As shown in the experiments, the influence of embedding reversible watermarking on the classification performance is less than 0.5% and the parameters of the model can be fully recovered after extracting the watermarking. At the same time, the integrity of the model can be verified by applying the reversible watermarking: if the model is modified illegally, the authentication information generated by original model will be absolutely different from the extracted watermarking information.
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021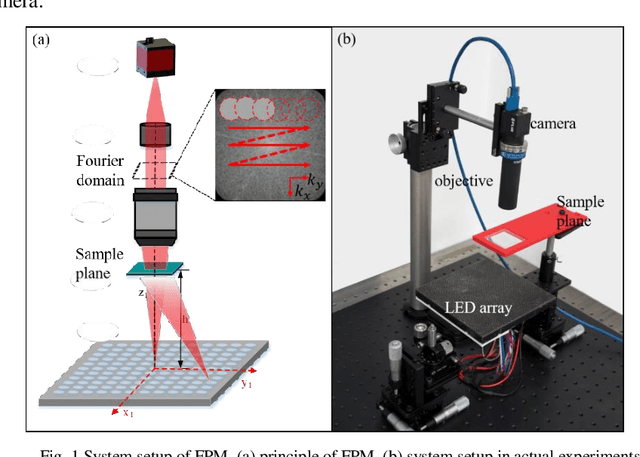
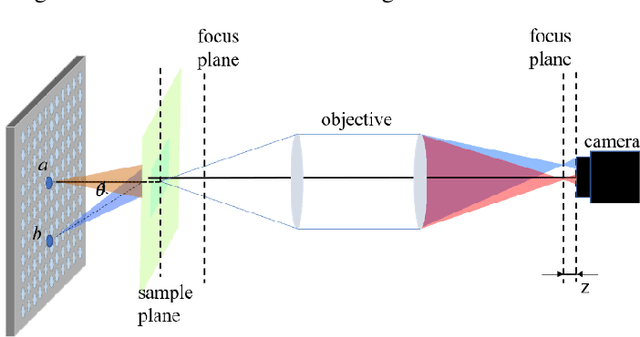
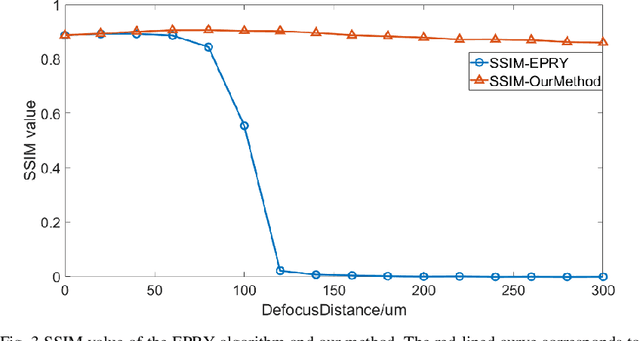

Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
RFI Mitigation for One-bit UWB Radar Systems
Feb 17, 2021
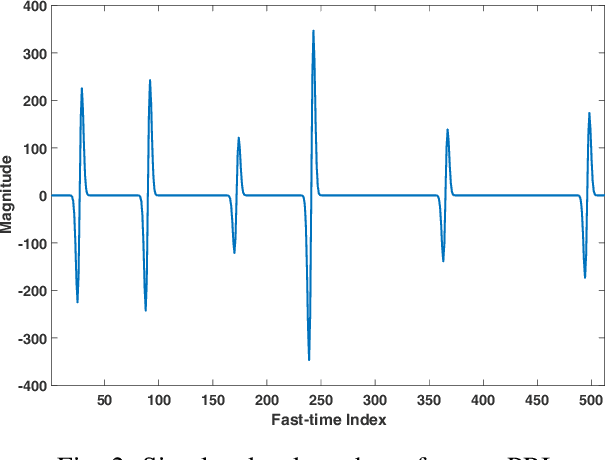
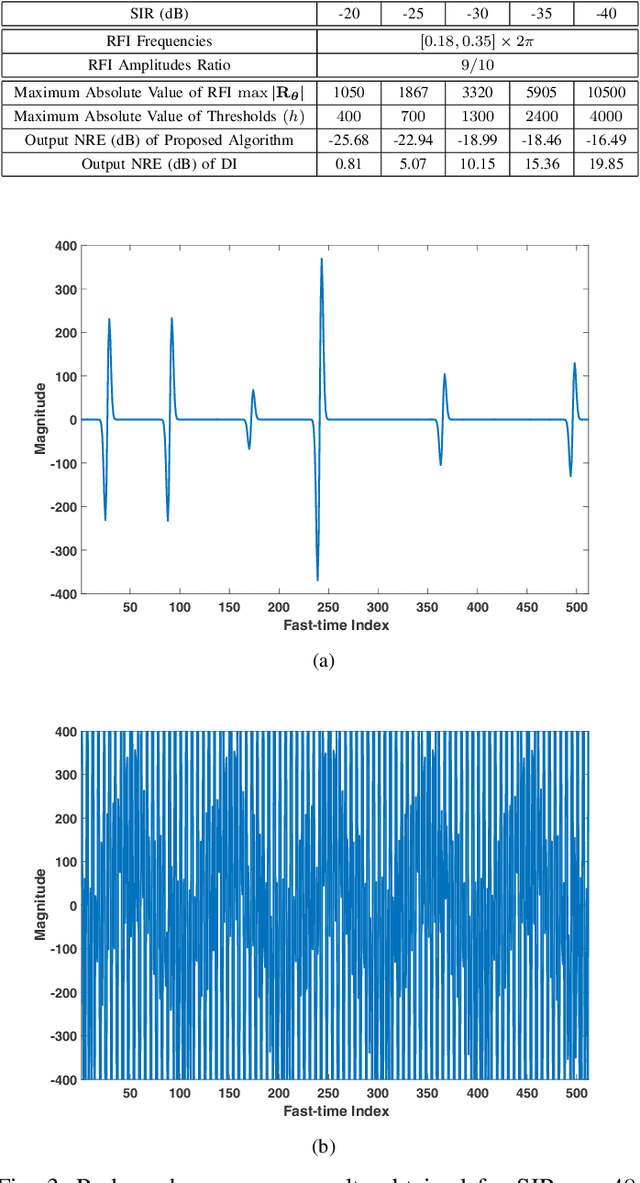
Radio frequency interference (RFI) mitigation is critical to the proper operation of ultra-wideband (UWB) radar systems since RFI can severely degrade the radar imaging capability and target detection performance. In this paper, we address the RFI mitigation problem for one-bit UWB radar systems. A one-bit UWB system obtains its signed measurements via a low-cost and high rate sampling scheme, referred to as the Continuous Time Binary Value (CTBV) technology. This sampling strategy compares the signal to a known threshold varying with slow-time and therefore can be used to achieve a rather high sampling rate and quantization resolution with rather simple and affordable hardware. This paper establishes a proper data model for the RFI sources and proposes a novel RFI mitigation method for the one-bit UWB radar system that uses the CTBV sampling technique. Specifically, we first model the RFI sources as a sum of sinusoids with frequencies fixed during the coherent processing interval (CPI) and we exploit the sparsity of the RFI spectrum. We extend a majorization-minimization based 1bRELAX algorithm, referred to as 1bMMRELAX, to estimate the RFI source parameters from the signed measurements obtained by using the CTBV sampling strategy. We also devise a new fast frequency initialization method based on the Alternating Direction Method of Multipliers (ADMM) methodology for the extended 1bMMRELAX algorithm to significantly improve its computational efficiency. Moreover, an ADMM-based sparse method is introduced to recover the desired radar echoes using the estimated RFI parameters. Both simulated and experimental results are presented to demonstrate that our proposed algorithm outperforms the existing digital integration method, especially for severe RFI cases.
Stochastic Reweighted Gradient Descent
Mar 23, 2021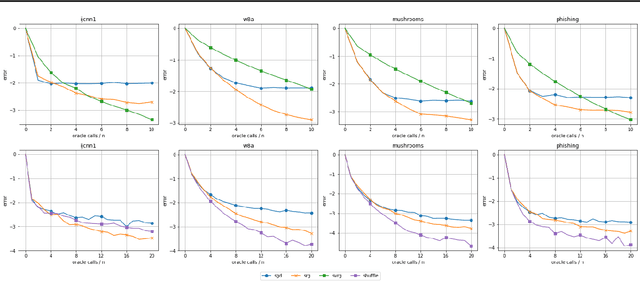
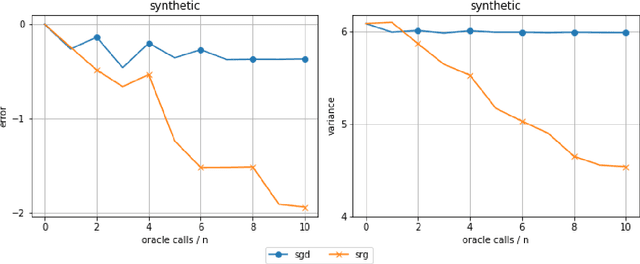
Despite the strong theoretical guarantees that variance-reduced finite-sum optimization algorithms enjoy, their applicability remains limited to cases where the memory overhead they introduce (SAG/SAGA), or the periodic full gradient computation they require (SVRG/SARAH) are manageable. A promising approach to achieving variance reduction while avoiding these drawbacks is the use of importance sampling instead of control variates. While many such methods have been proposed in the literature, directly proving that they improve the convergence of the resulting optimization algorithm has remained elusive. In this work, we propose an importance-sampling-based algorithm we call SRG (stochastic reweighted gradient). We analyze the convergence of SRG in the strongly-convex case and show that, while it does not recover the linear rate of control variates methods, it provably outperforms SGD. We pay particular attention to the time and memory overhead of our proposed method, and design a specialized red-black tree allowing its efficient implementation. Finally, we present empirical results to support our findings.
Adaptive Robust Model Predictive Control with Matched and Unmatched Uncertainty
Apr 16, 2021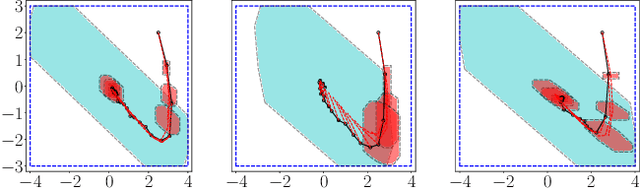
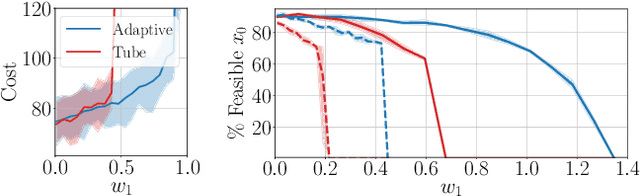
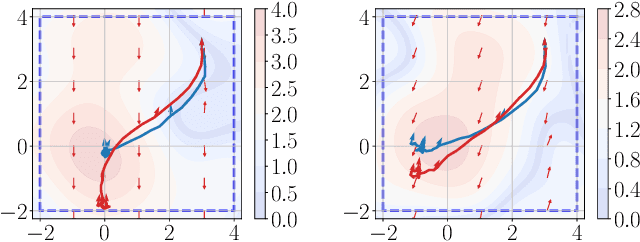
We propose a learning-based robust predictive control algorithm that can handle large uncertainty in the dynamics for a class of discrete-time systems that are nominally linear with an additive nonlinear dynamics component. Such systems commonly model the nonlinear effects of an unknown environment on a nominal system. Motivated by an inability of existing learning-based predictive control algorithms to achieve safety guarantees in the presence of uncertainties of large magnitude in this setting, we achieve significant performance improvements by optimizing over a novel class of nonlinear feedback policies inspired by certainty equivalent "estimate-and-cancel" control laws pioneered in classical adaptive control. In contrast with previous work in robust adaptive MPC, this allows us to take advantage of the structure in the a priori unknown dynamics that are learned online through function approximation. Our approach also extends typical nonlinear adaptive control methods to systems with state and input constraints even when an additive uncertain function cannot directly be canceled from the dynamics. Moreover, our approach allows us to apply contemporary statistical estimation techniques to certify the safety of the system through persistent constraint satisfaction with high probability. We show that our method allows us to consider larger unknown terms in the dynamics than existing methods through simulated examples.
DIFFnet: Diffusion parameter mapping network generalized for input diffusion gradient schemes and bvalues
Feb 04, 2021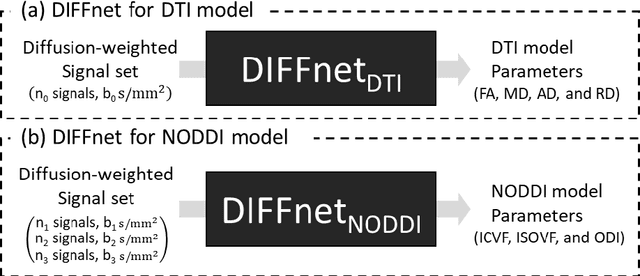
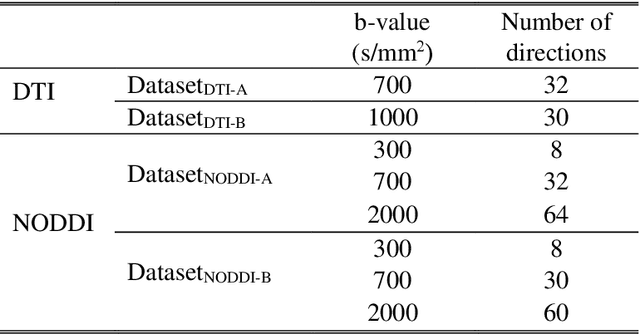
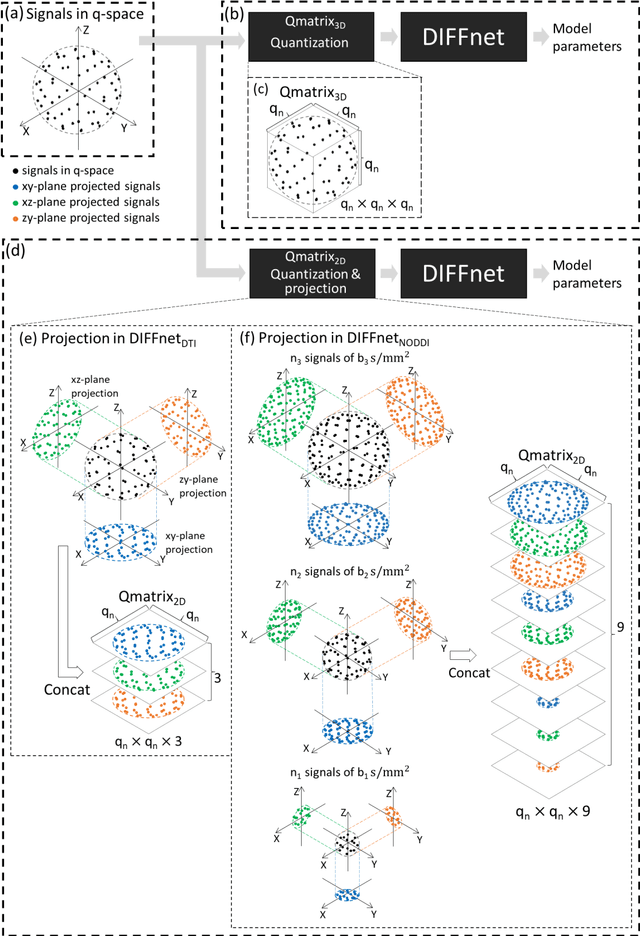
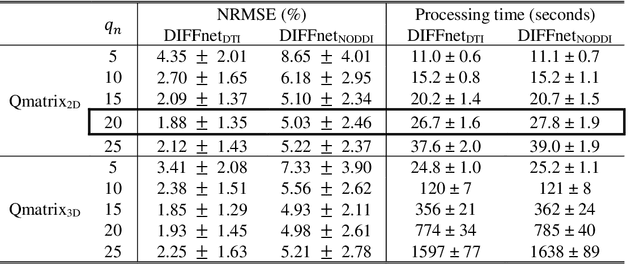
In MRI, deep neural networks have been proposed to reconstruct diffusion model parameters. However, the inputs of the networks were designed for a specific diffusion gradient scheme (i.e., diffusion gradient directions and numbers) and a specific b-value that are the same as the training data. In this study, a new deep neural network, referred to as DIFFnet, is developed to function as a generalized reconstruction tool of the diffusion-weighted signals for various gradient schemes and b-values. For generalization, diffusion signals are normalized in a q-space and then projected and quantized, producing a matrix (Qmatrix) as an input for the network. To demonstrate the validity of this approach, DIFFnet is evaluated for diffusion tensor imaging (DIFFnetDTI) and for neurite orientation dispersion and density imaging (DIFFnetNODDI). In each model, two datasets with different gradient schemes and b-values are tested. The results demonstrate accurate reconstruction of the diffusion parameters at substantially reduced processing time (approximately 8.7 times and 2240 times faster processing time than conventional methods in DTI and NODDI, respectively; less than 4% mean normalized root-mean-square errors (NRMSE) in DTI and less than 8% in NODDI). The generalization capability of the networks was further validated using reduced numbers of diffusion signals from the datasets. Different from previously proposed deep neural networks, DIFFnet does not require any specific gradient scheme and b-value for its input. As a result, it can be adopted as an online reconstruction tool for various complex diffusion imaging.
proScript: Partially Ordered Scripts Generation via Pre-trained Language Models
Apr 16, 2021
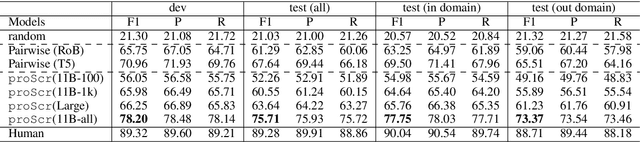
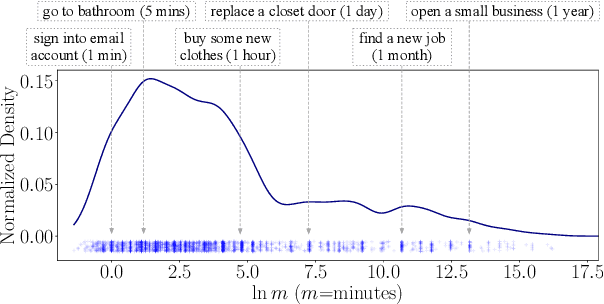
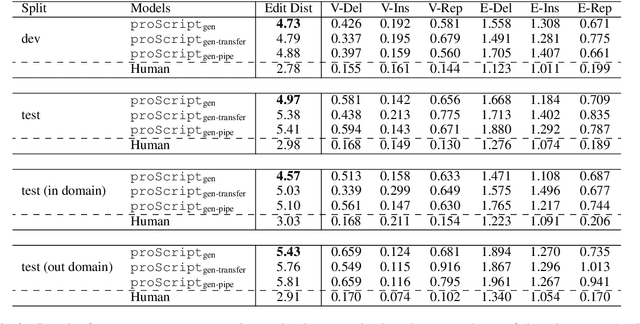
Scripts - standardized event sequences describing typical everyday activities - have been shown to help understand narratives by providing expectations, resolving ambiguity, and filling in unstated information. However, to date they have proved hard to author or extract from text. In this work, we demonstrate for the first time that pre-trained neural language models (LMs) can be be finetuned to generate high-quality scripts, at varying levels of granularity, for a wide range of everyday scenarios (e.g., bake a cake). To do this, we collected a large (6.4k), crowdsourced partially ordered scripts (named proScript), which is substantially larger than prior datasets, and developed models that generate scripts with combining language generation and structure prediction. We define two complementary tasks: (i) edge prediction: given a scenario and unordered events, organize the events into a valid (possibly partial-order) script, and (ii) script generation: given only a scenario, generate events and organize them into a (possibly partial-order) script. Our experiments show that our models perform well (e.g., F1=75.7 in task (i)), illustrating a new approach to overcoming previous barriers to script collection. We also show that there is still significant room for improvement toward human level performance. Together, our tasks, dataset, and models offer a new research direction for learning script knowledge.