 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-shot learning through contextual data augmentation
Mar 31, 2021

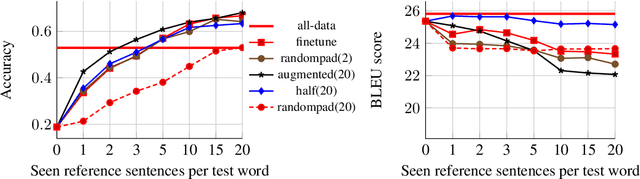
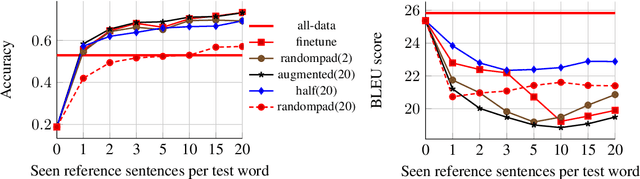
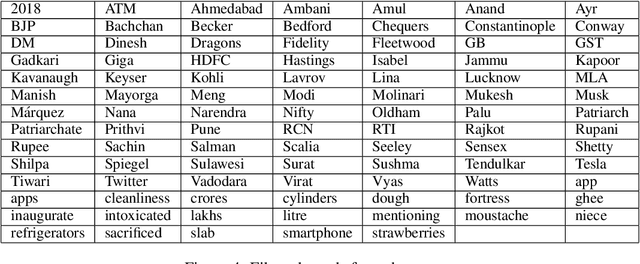
Machine translation (MT) models used in industries with constantly changing topics, such as translation or news agencies, need to adapt to new data to maintain their performance over time. Our aim is to teach a pre-trained MT model to translate previously unseen words accurately, based on very few examples. We propose (i) an experimental setup allowing us to simulate novel vocabulary appearing in human-submitted translations, and (ii) corresponding evaluation metrics to compare our approaches. We extend a data augmentation approach using a pre-trained language model to create training examples with similar contexts for novel words. We compare different fine-tuning and data augmentation approaches and show that adaptation on the scale of one to five examples is possible. Combining data augmentation with randomly selected training sentences leads to the highest BLEU score and accuracy improvements. Impressively, with only 1 to 5 examples, our model reports better accuracy scores than a reference system trained with on average 313 parallel examples.
Testing for a Random Walk Structure in the Frequency Evolution of a Tone in Noise
Mar 05, 2021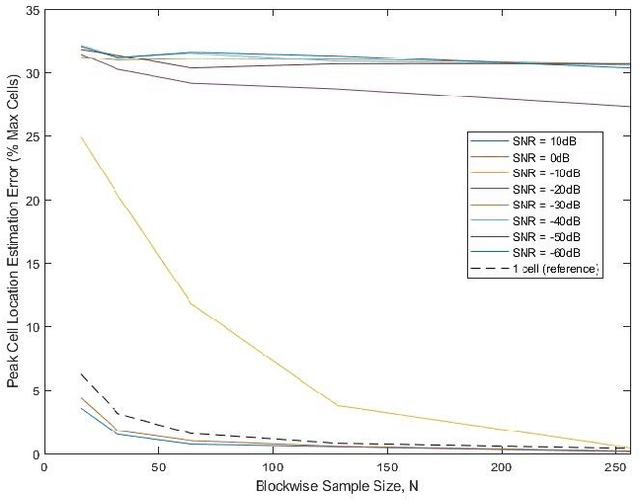
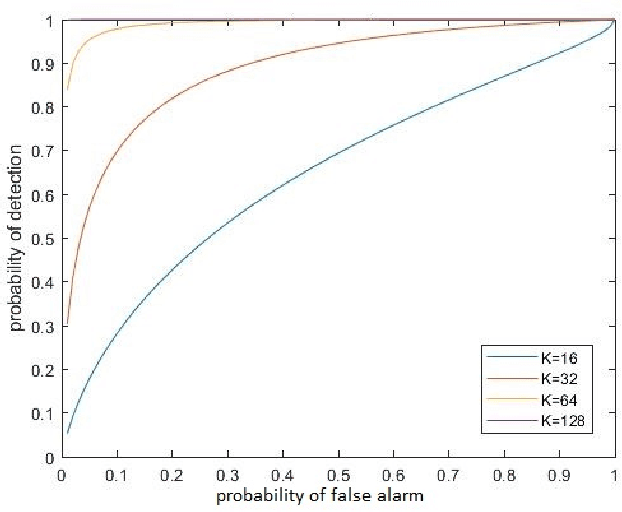
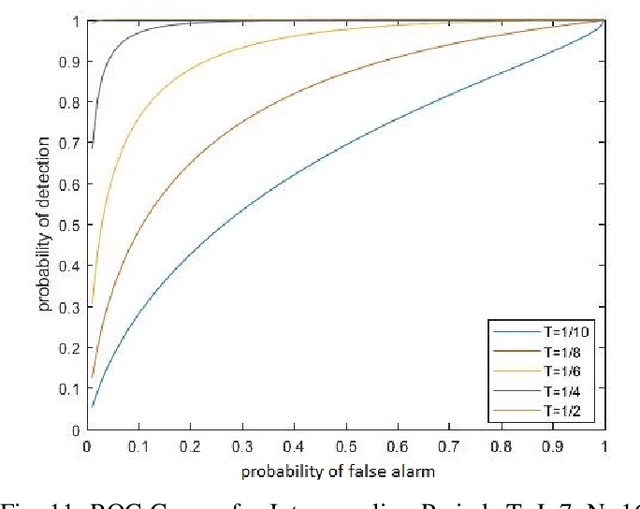
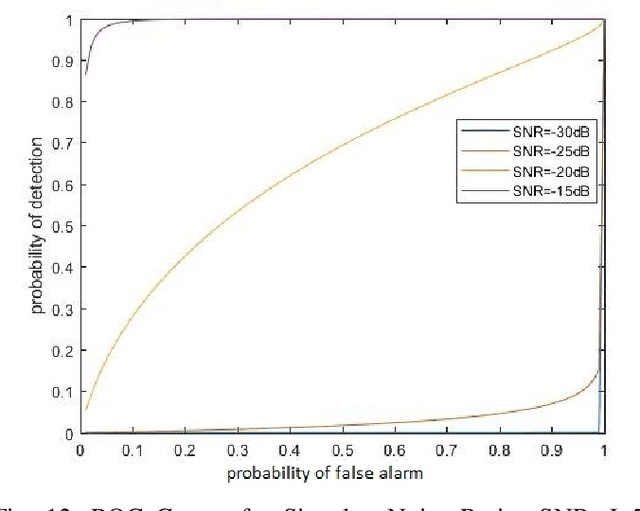
Inference and hypothesis testing is constructed on the basis that a specific model holds for the data. To determine the veracity of conclusions drawn from such data analyses, one must be able to identify the presence of the assumed structure within the data. A model verification test is developed for the presence of a random walk-like structure for variations in the frequency of complex-valued sinusoidal signals measured in additive Gaussian noise. This test evaluates the joint inference of the random walk hypothesis tests found in economics literature that seek random walk behaviours in time series data, with an additional test to account for how the random walk behaves in frequency space.
Adversarial Driving: Attacking End-to-End Autonomous Driving Systems
Mar 21, 2021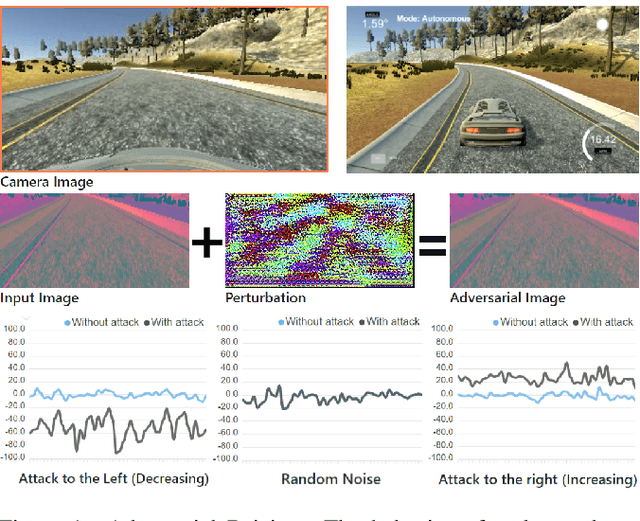
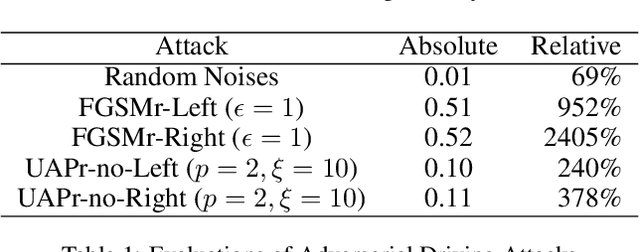
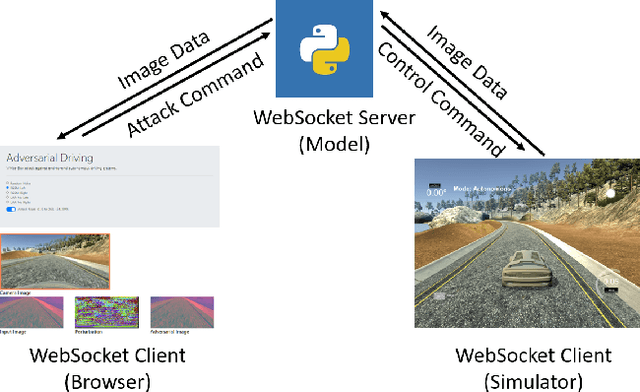
As the research in deep neural networks advances, deep convolutional networks become feasible for automated driving tasks. There is an emerging trend of employing end-to-end models in the automation of driving tasks. However, previous research unveils that deep neural networks are vulnerable to adversarial attacks in classification tasks. While for regression tasks such as autonomous driving, the effect of these attacks remains rarely explored. In this research, we devise two white-box targeted attacks against end-to-end autonomous driving systems. The driving model takes an image as input and outputs the steering angle. Our attacks can manipulate the behaviour of the autonomous driving system only by perturbing the input image. Both attacks can be initiated in real-time on CPUs without employing GPUs. This demo aims to raise concerns over applications of end-to-end models in safety-critical systems.
Advancing Trajectory Optimization with Approximate Inference: Exploration, Covariance Control and Adaptive Risk
Mar 10, 2021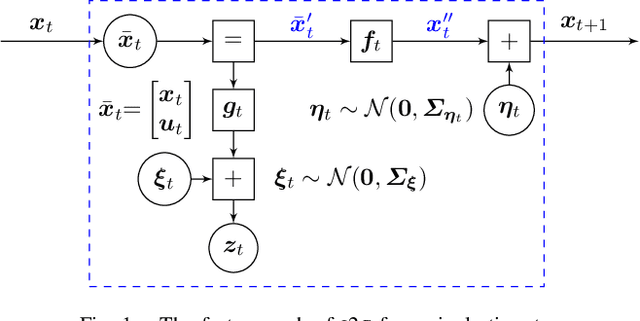
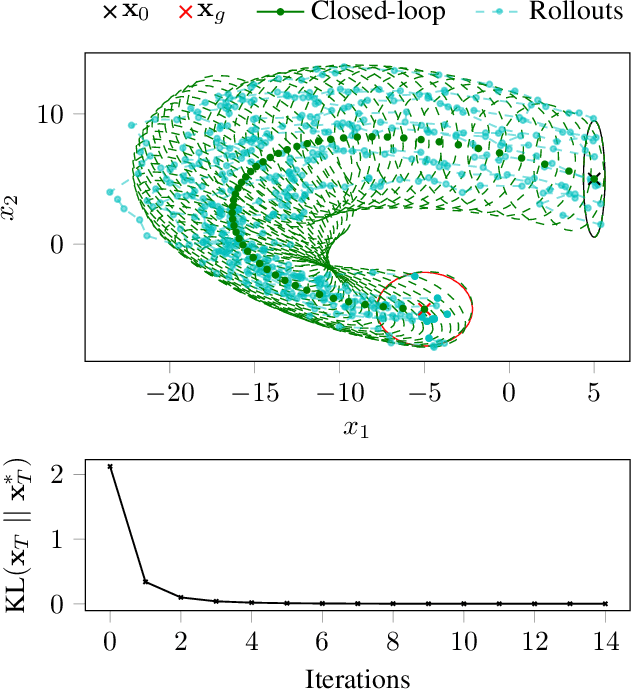
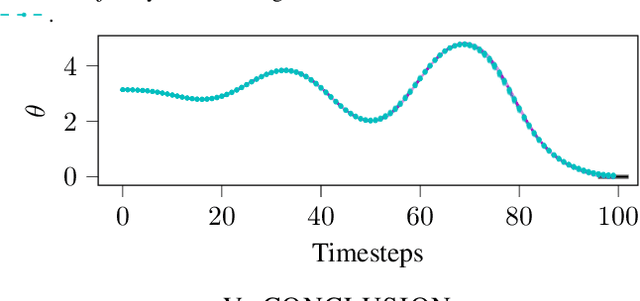

Discrete-time stochastic optimal control remains a challenging problem for general, nonlinear systems under significant uncertainty, with practical solvers typically relying on the certainty equivalence assumption, replanning and/or extensive regularization. Control as inference is an approach that frames stochastic control as an equivalent inference problem, and has demonstrated desirable qualities over existing methods, namely in exploration and regularization. We look specifically at the input inference for control (i2c) algorithm, and derive three key characteristics that enable advanced trajectory optimization: An `expert' linear Gaussian controller that combines the benefits of open-loop optima and closed-loop variance reduction when optimizing for nonlinear systems, inherent adaptive risk sensitivity from the inference formulation, and covariance control functionality with only a minor algorithmic adjustment.
Bootstrapping User and Item Representations for One-Class Collaborative Filtering
May 13, 2021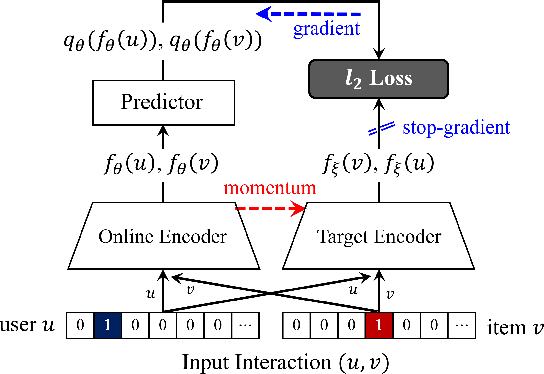
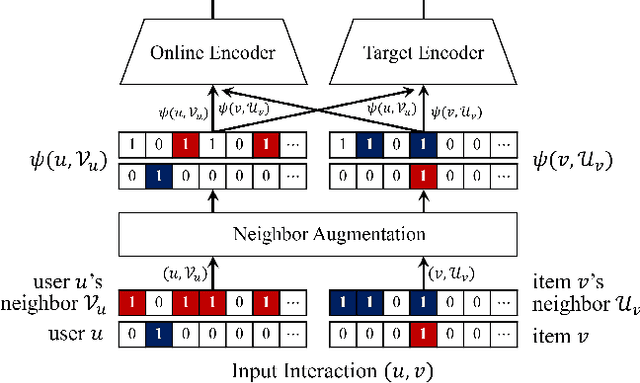
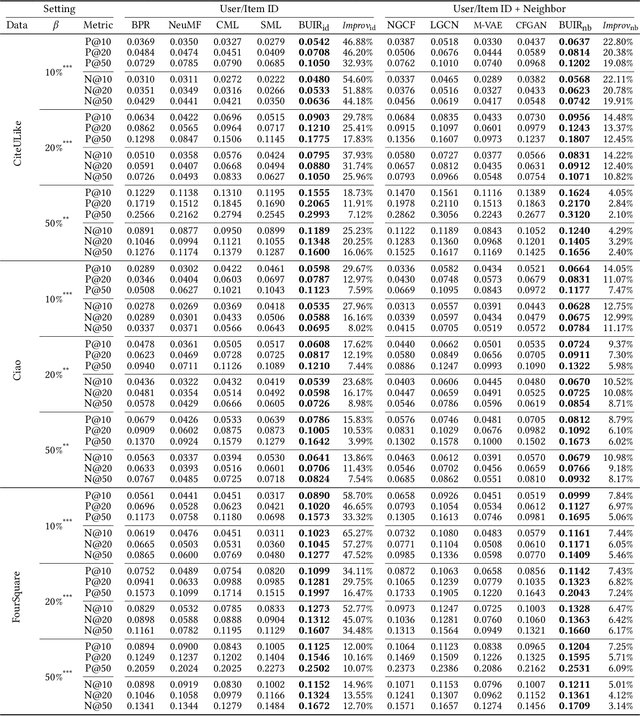
The goal of one-class collaborative filtering (OCCF) is to identify the user-item pairs that are positively-related but have not been interacted yet, where only a small portion of positive user-item interactions (e.g., users' implicit feedback) are observed. For discriminative modeling between positive and negative interactions, most previous work relied on negative sampling to some extent, which refers to considering unobserved user-item pairs as negative, as actual negative ones are unknown. However, the negative sampling scheme has critical limitations because it may choose "positive but unobserved" pairs as negative. This paper proposes a novel OCCF framework, named as BUIR, which does not require negative sampling. To make the representations of positively-related users and items similar to each other while avoiding a collapsed solution, BUIR adopts two distinct encoder networks that learn from each other; the first encoder is trained to predict the output of the second encoder as its target, while the second encoder provides the consistent targets by slowly approximating the first encoder. In addition, BUIR effectively alleviates the data sparsity issue of OCCF, by applying stochastic data augmentation to encoder inputs. Based on the neighborhood information of users and items, BUIR randomly generates the augmented views of each positive interaction each time it encodes, then further trains the model by this self-supervision. Our extensive experiments demonstrate that BUIR consistently and significantly outperforms all baseline methods by a large margin especially for much sparse datasets in which any assumptions about negative interactions are less valid.
Alignment & joint recovery of multi-slice dynamic MRI using deep generative manifold model
Jan 20, 2021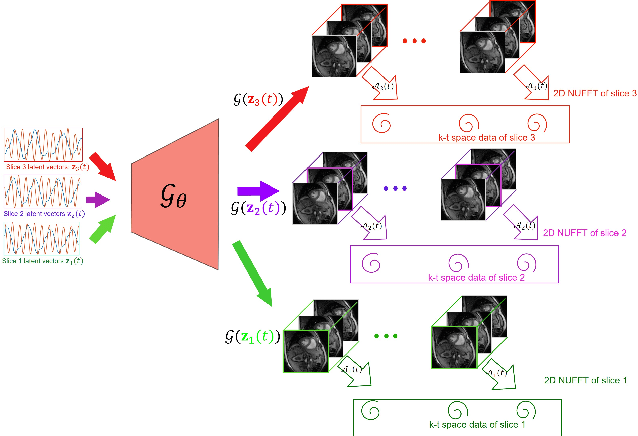
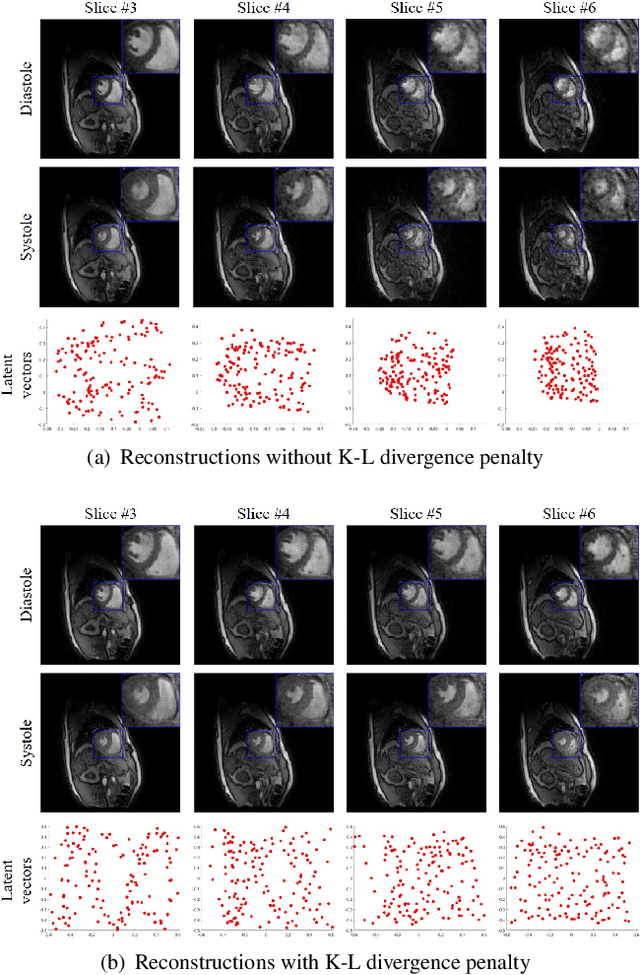
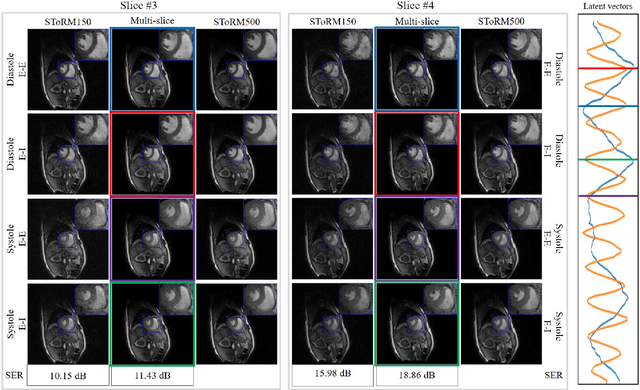
We introduce a novel unsupervised deep generative manifold model for the recovery of multi-slice free-breathing and ungated cardiac MRI from highly undersampled measurements. The proposed scheme represents the multi-slice volume at each time point as the output of a deep convolutional neural network (CNN) generator, which is driven by latent vectors that capture the cardiac and respiratory phase at the specific time point. The main difference between the proposed method and the traditional CNN approaches is that the proposed scheme learns the network parameters from only the highly undersampled data rather than the extensive fully-sampled training data. We also learn the latent codes from the undersampled data using the stochastic gradient descent. Regularizations on the network and the latent codes are introduced to encourage the learning of smooth image manifold and the latent codes for each slice have the same distribution. The main benefits of the proposed scheme are (a) the ability to align multi-slice data and capitalize on the redundancy between the slices; (b) the ability to estimate the gating information directly from the k-t space data; and (c) the unsupervised learning strategy that eliminates the need for extensive training data.
Adversarial Imitation Learning with Trajectorial Augmentation and Correction
Mar 26, 2021
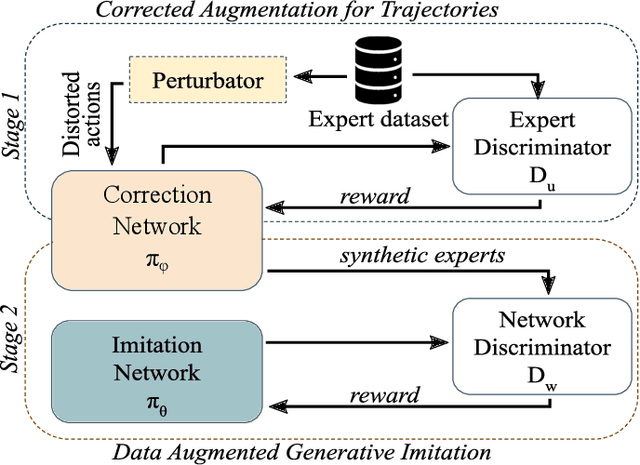
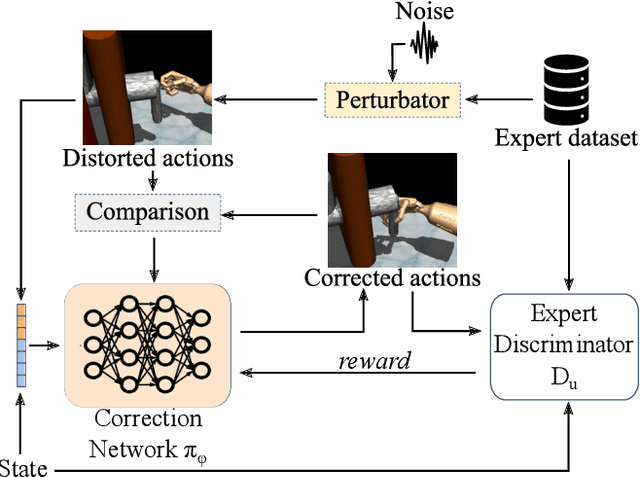
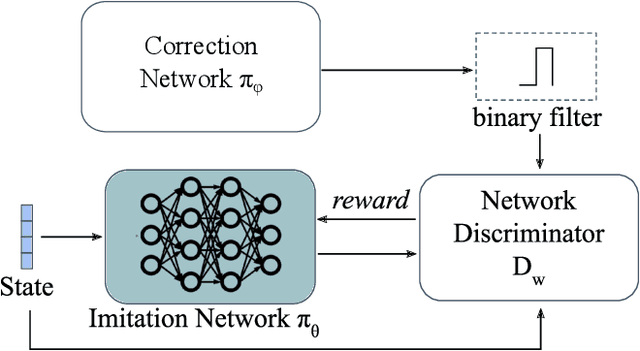
Deep Imitation Learning requires a large number of expert demonstrations, which are not always easy to obtain, especially for complex tasks. A way to overcome this shortage of labels is through data augmentation. However, this cannot be easily applied to control tasks due to the sequential nature of the problem. In this work, we introduce a novel augmentation method which preserves the success of the augmented trajectories. To achieve this, we introduce a semi-supervised correction network that aims to correct distorted expert actions. To adequately test the abilities of the correction network, we develop an adversarial data augmented imitation architecture to train an imitation agent using synthetic experts. Additionally, we introduce a metric to measure diversity in trajectory datasets. Experiments show that our data augmentation strategy can improve accuracy and convergence time of adversarial imitation while preserving the diversity between the generated and real trajectories.
Improving the filtering of Branch-And-Bound MDD solver (extended)
Apr 24, 2021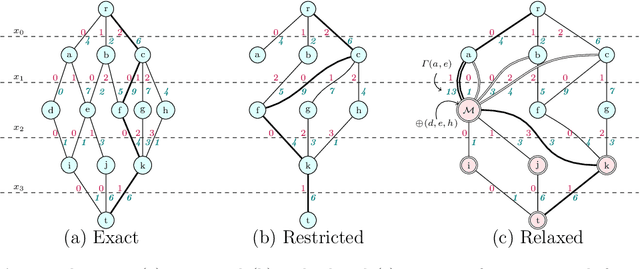
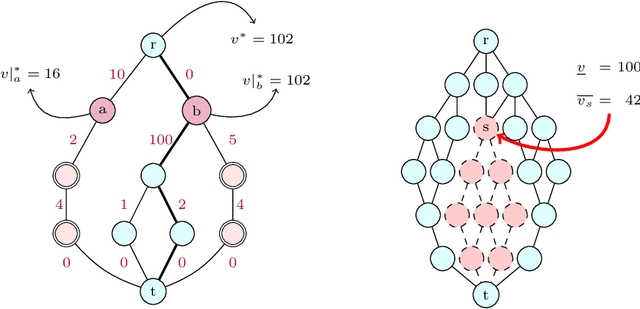
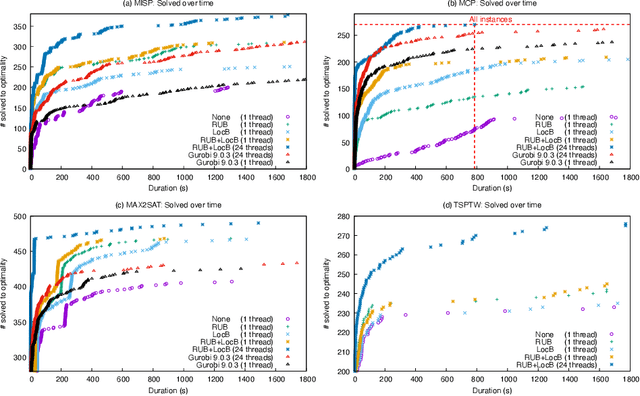
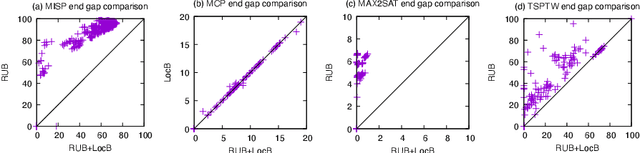
This paper presents and evaluates two pruning techniques to reinforce the efficiency of constraint optimization solvers based on multi-valued decision-diagrams (MDD). It adopts the branch-and-bound framework proposed by Bergman et al. in 2016 to solve dynamic programs to optimality. In particular, our paper presents and evaluates the effectiveness of the local-bound (LocB) and rough upper-bound pruning (RUB). LocB is a new and effective rule that leverages the approximate MDD structure to avoid the exploration of non-interesting nodes. RUB is a rule to reduce the search space during the development of bounded-width-MDDs. The experimental study we conducted on the Maximum Independent Set Problem (MISP), Maximum Cut Problem (MCP), Maximum 2 Satisfiability (MAX2SAT) and the Traveling Salesman Problem with Time Windows (TSPTW) shows evidence indicating that rough-upper-bound and local-bound pruning have a high impact on optimization solvers based on branch-and-bound with MDDs. In particular, it shows that RUB delivers excellent results but requires some effort when defining the model. Also, it shows that LocB provides a significant improvement automatically; without necessitating any user-supplied information. Finally, it also shows that rough-upper-bound and local-bound pruning are not mutually exclusive, and their combined benefit supersedes the individual benefit of using each technique.
Scalable Deep Convolutional Neural Networks for Sparse, Locally Dense Liquid Argon Time Projection Chamber Data
Mar 15, 2019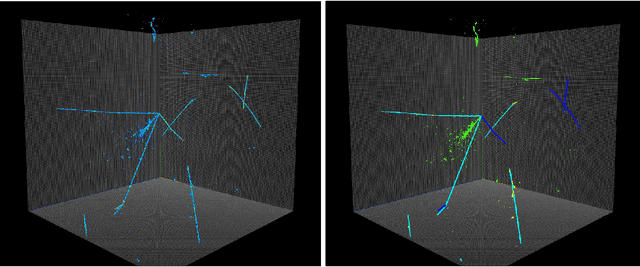
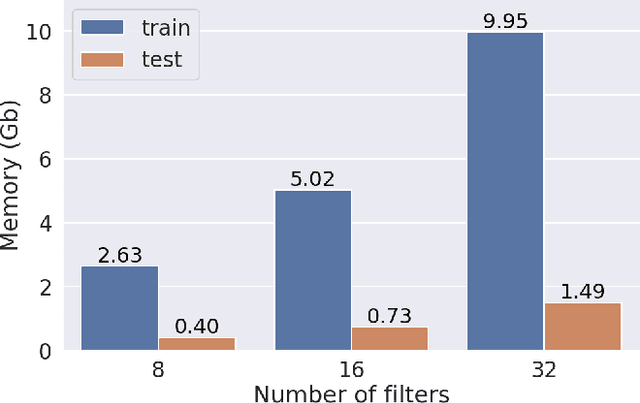
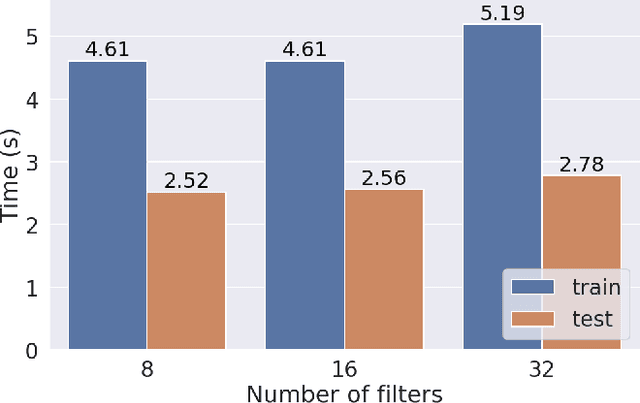
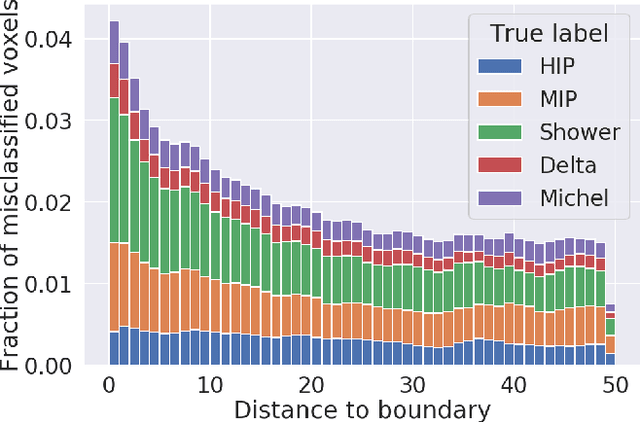
Deep convolutional neural networks (CNNs) show strong promise for analyzing scientific data in many domains including particle imaging detectors such as a liquid argon time projection chamber (LArTPC). Yet the high sparsity of LArTPC data challenges traditional CNNs which were designed for dense data such as photographs. A naive application of CNNs on LArTPC data results in inefficient computations and a poor scalability to large LArTPC detectors such as the Short Baseline Neutrino Program and Deep Underground Neutrino Experiment. Recently Submanifold Sparse Convolutional Networks (SSCNs) have been proposed to address this challenge. We report their performance on a 3D semantic segmentation task on simulated LArTPC samples. In comparison with standard CNNs, we observe that the computation memory and wall-time cost for inference are reduced by factor of 364 and 33 respectively without loss of accuracy. The same factors for 2D samples are found to be 93 and 3.1 respectively. Using SSCN, we present the first machine learning-based approach to the reconstruction of Michel electrons using public 3D LArTPC samples. We find a Michel electron identification efficiency of 93.9\% with 98.8\% of true positive rate. Reconstructed Michel electron clusters yield 96.1\% in average pixel clustering efficiency and 97.3\% in purity. The results are compelling to show strong promise of scalable data reconstruction technique using deep neural networks for large scale LArTPC detectors.
CharacterGAN: Few-Shot Keypoint Character Animation and Reposing
Feb 05, 2021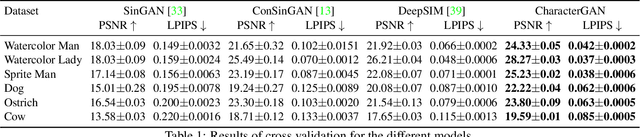
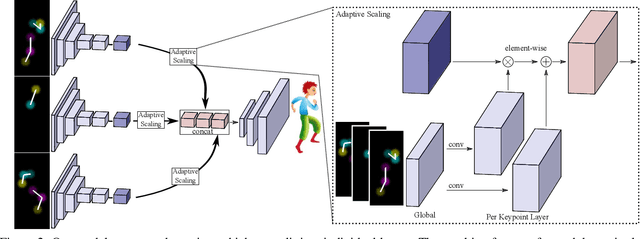
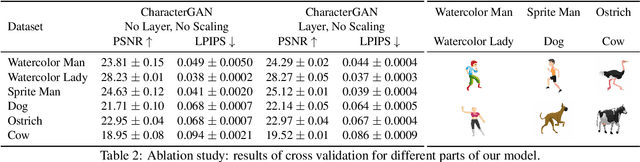

We introduce CharacterGAN, a generative model that can be trained on only a few samples (8 - 15) of a given character. Our model generates novel poses based on keypoint locations, which can be modified in real time while providing interactive feedback, allowing for intuitive reposing and animation. Since we only have very limited training samples, one of the key challenges lies in how to address (dis)occlusions, e.g. when a hand moves behind or in front of a body. To address this, we introduce a novel layering approach which explicitly splits the input keypoints into different layers which are processed independently. These layers represent different parts of the character and provide a strong implicit bias that helps to obtain realistic results even with strong (dis)occlusions. To combine the features of individual layers we use an adaptive scaling approach conditioned on all keypoints. Finally, we introduce a mask connectivity constraint to reduce distortion artifacts that occur with extreme out-of-distribution poses at test time. We show that our approach outperforms recent baselines and creates realistic animations for diverse characters. We also show that our model can handle discrete state changes, for example a profile facing left or right, that the different layers do indeed learn features specific for the respective keypoints in those layers, and that our model scales to larger datasets when more data is available.