 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Driver Drowsiness Detection for Android Application Using Deep Neural Networks Techniques
Nov 05, 2018


Road crashes and related forms of accidents are a common cause of injury and death among the human population. According to 2015 data from the World Health Organization, road traffic injuries resulted in approximately 1.25 million deaths worldwide, i.e. approximately every 25 seconds an individual will experience a fatal crash. While the cost of traffic accidents in Europe is estimated at around 160 billion Euros, driver drowsiness accounts for approximately 100,000 accidents per year in the United States alone as reported by The American National Highway Traffic Safety Administration (NHTSA). In this paper, a novel approach towards real-time drowsiness detection is proposed. This approach is based on a deep learning method that can be implemented on Android applications with high accuracy. The main contribution of this work is the compression of heavy baseline model to a lightweight model. Moreover, minimal network structure is designed based on facial landmark key point detection to recognize whether the driver is drowsy. The proposed model is able to achieve an accuracy of more than 80%. Keywords: Driver Monitoring System; Drowsiness Detection; Deep Learning; Real-time Deep Neural Network; Android.
Microscope 2.0: An Augmented Reality Microscope with Real-time Artificial Intelligence Integration
Dec 04, 2018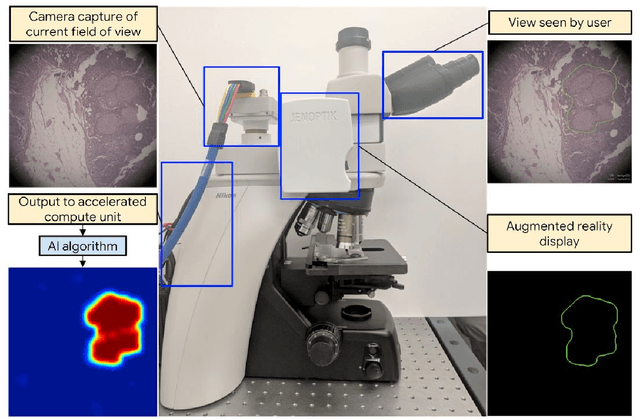
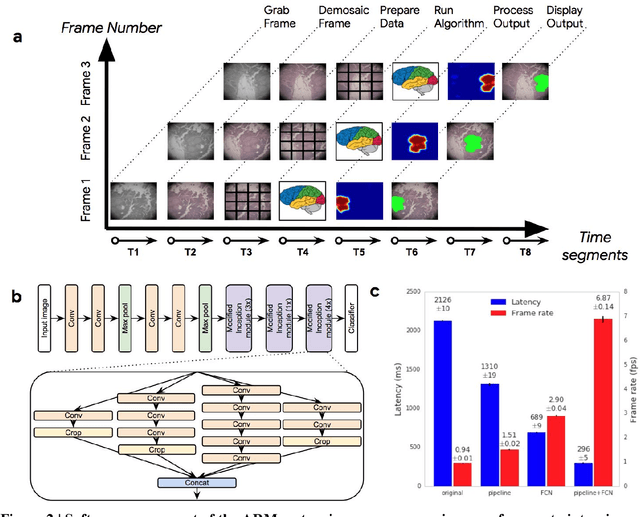
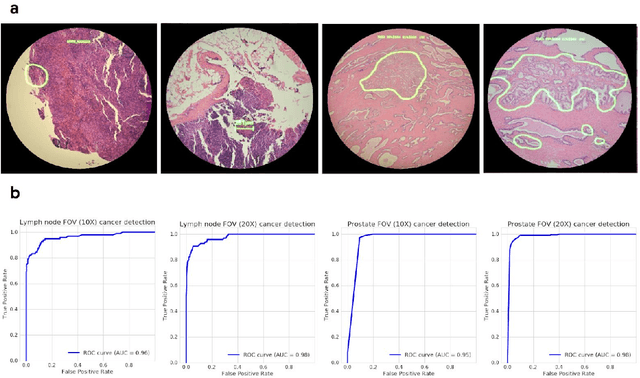
The brightfield microscope is instrumental in the visual examination of both biological and physical samples at sub-millimeter scales. One key clinical application has been in cancer histopathology, where the microscopic assessment of the tissue samples is used for the diagnosis and staging of cancer and thus guides clinical therapy. However, the interpretation of these samples is inherently subjective, resulting in significant diagnostic variability. Moreover, in many regions of the world, access to pathologists is severely limited due to lack of trained personnel. In this regard, Artificial Intelligence (AI) based tools promise to improve the access and quality of healthcare. However, despite significant advances in AI research, integration of these tools into real-world cancer diagnosis workflows remains challenging because of the costs of image digitization and difficulties in deploying AI solutions. Here we propose a cost-effective solution to the integration of AI: the Augmented Reality Microscope (ARM). The ARM overlays AI-based information onto the current view of the sample through the optical pathway in real-time, enabling seamless integration of AI into the regular microscopy workflow. We demonstrate the utility of ARM in the detection of lymph node metastases in breast cancer and the identification of prostate cancer with a latency that supports real-time workflows. We anticipate that ARM will remove barriers towards the use of AI in microscopic analysis and thus improve the accuracy and efficiency of cancer diagnosis. This approach is applicable to other microscopy tasks and AI algorithms in the life sciences and beyond.
Dual Online Stein Variational Inference for Control and Dynamics
Mar 23, 2021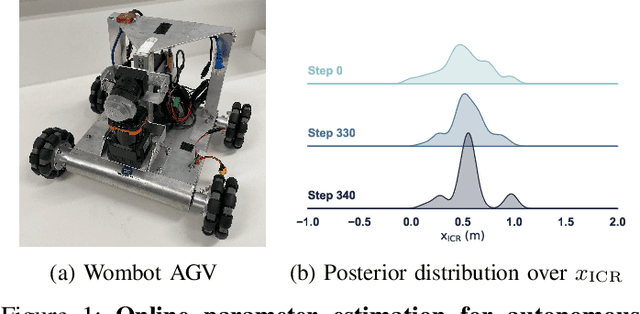
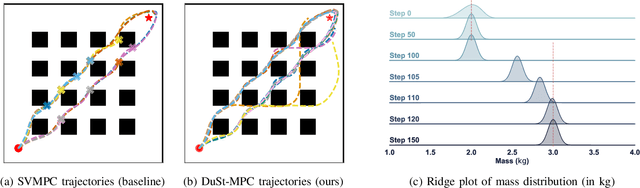
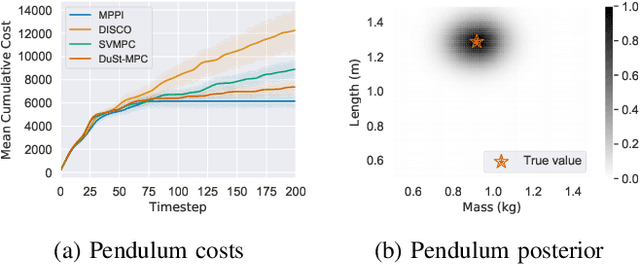
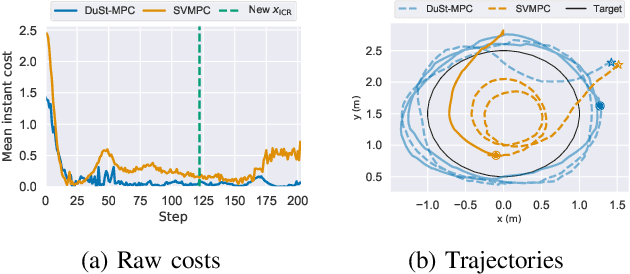
Model predictive control (MPC) schemes have a proven track record for delivering aggressive and robust performance in many challenging control tasks, coping with nonlinear system dynamics, constraints, and observational noise. Despite their success, these methods often rely on simple control distributions, which can limit their performance in highly uncertain and complex environments. MPC frameworks must be able to accommodate changing distributions over system parameters, based on the most recent measurements. In this paper, we devise an implicit variational inference algorithm able to estimate distributions over model parameters and control inputs on-the-fly. The method incorporates Stein Variational gradient descent to approximate the target distributions as a collection of particles, and performs updates based on a Bayesian formulation. This enables the approximation of complex multi-modal posterior distributions, typically occurring in challenging and realistic robot navigation tasks. We demonstrate our approach on both simulated and real-world experiments requiring real-time execution in the face of dynamically changing environments.
iX-BSP: Incremental Belief Space Planning
Feb 18, 2021

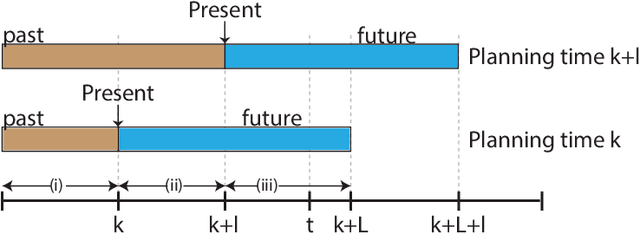

Deciding what's next? is a fundamental problem in robotics and Artificial Intelligence. Under belief space planning (BSP), in a partially observable setting, it involves calculating the expected accumulated belief-dependent reward, where the expectation is with respect to all future measurements. Since solving this general un-approximated problem quickly becomes intractable, state of the art approaches turn to approximations while still calculating planning sessions from scratch. In this work we propose a novel paradigm, Incremental BSP (iX-BSP), based on the key insight that calculations across planning sessions are similar in nature and can be appropriately re-used. We calculate the expectation incrementally by utilizing Multiple Importance Sampling techniques for selective re-sampling and re-use of measurement from previous planning sessions. The formulation of our approach considers general distributions and accounts for data association aspects. We demonstrate how iX-BSP could benefit existing approximations of the general problem, introducing iML-BSP, which re-uses calculations across planning sessions under the common Maximum Likelihood assumption. We evaluate both methods and demonstrate a substantial reduction in computation time while statistically preserving accuracy. The evaluation includes both simulation and real-world experiments considering autonomous vision-based navigation and SLAM. As a further contribution, we introduce to iX-BSP the non-integral wildfire approximation, allowing one to trade accuracy for computational performance by averting from updating re-used beliefs when they are "close enough". We evaluate iX-BSP under wildfire demonstrating a substantial reduction in computation time while controlling the accuracy sacrifice. We also provide analytical and empirical bounds of the effect wildfire holds over the objective value.
A Plenum-Based Calibration Device for Tactile Sensor Arrays
Mar 23, 2021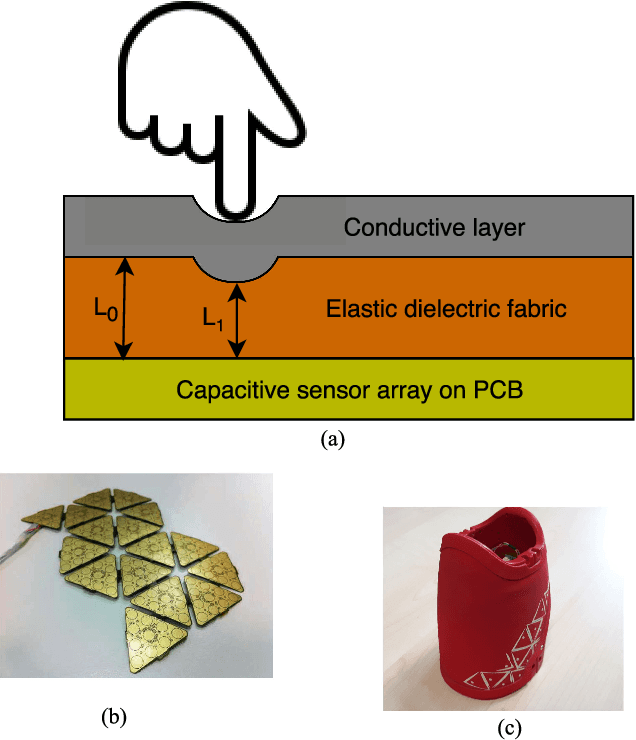
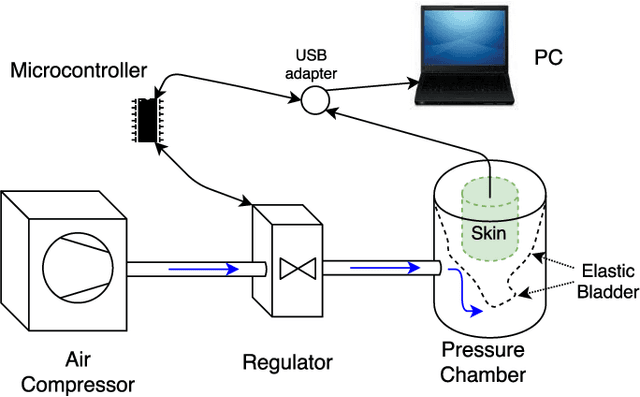
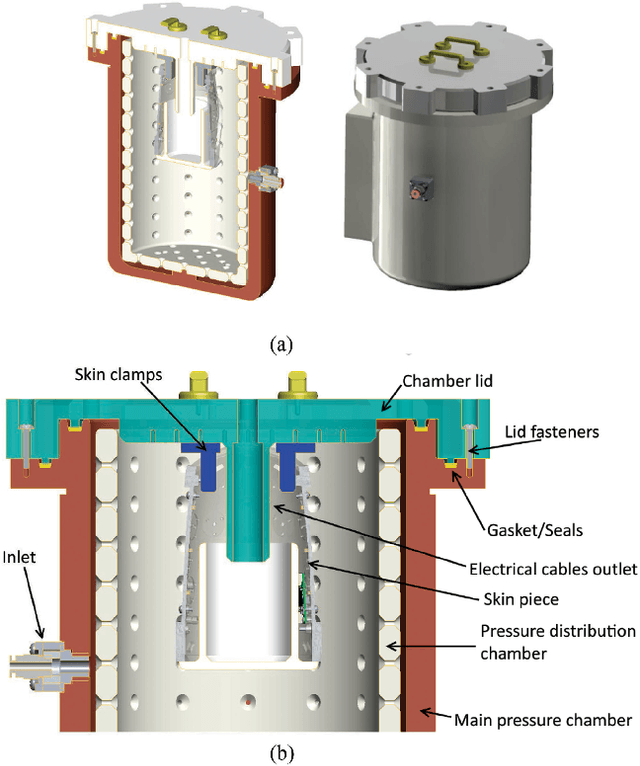
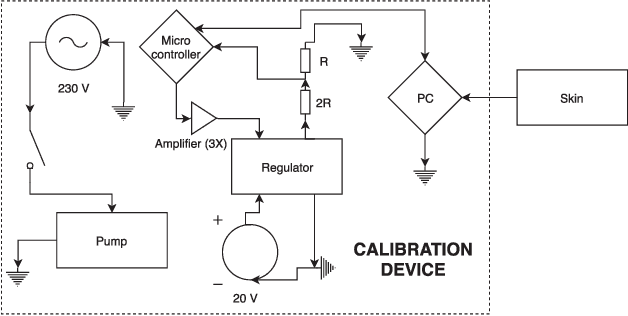
In modern robotic applications, tactile sensor arrays (i.e., artificial skins) are an emergent solution to determine the locations of contacts between a robot and an external agent. Localizing the point of contact is useful but determining the force applied on the skin provides many additional possibilities. This additional feature usually requires time-consuming calibration procedures to relate the sensor readings to the applied forces. This letter presents a novel device that enables the calibration of tactile sensor arrays in a fast and simple way. The key idea is to design a plenum chamber where the skin is inserted, and then the calibration of the tactile sensors is achieved by relating the air pressure and the sensor readings. This general concept is tested experimentally to calibrate the skin of the iCub robot. The validation of the calibration device is achieved by placing the masses of known weight on the artificial skin and comparing the applied force against the one estimated by the sensors.
* 8 pages, 18 figures
Estimation and inference of signals via the stochastic geometry of spectrogram level sets
May 06, 2021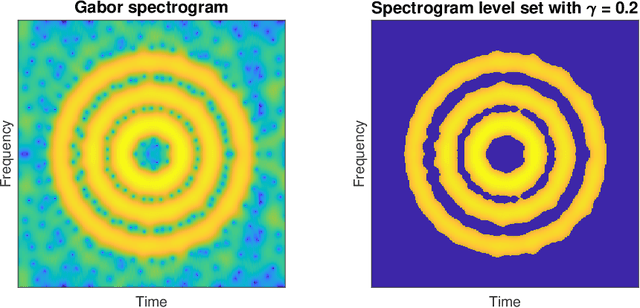
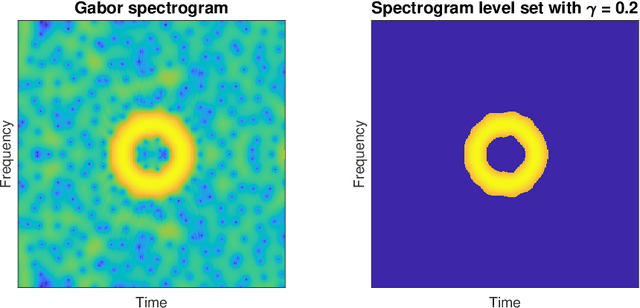
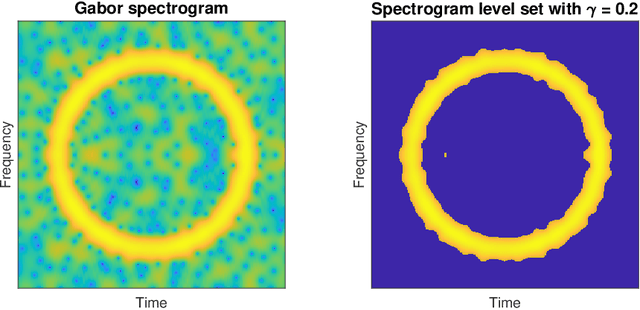
Spectrograms are fundamental tools in the detection, estimation and analysis of signals in the time-frequency analysis paradigm. Signal analysis via spectrograms have traditionally explored their peaks, i.e. their maxima, complemented by a recent interest in their zeros or minima. In particular, recent investigations have demonstrated connections between Gabor spectrograms of Gaussian white noise and Gaussian analytic functions (abbrv. GAFs) in different geometries. However, the zero sets (or the maxima or minima) of GAFs have a complicated stochastic structure, which makes a direct theoretical analysis of usual spectrogram based techniques via GAFs a difficult proposition. These techniques, in turn, largely rely on statistical observables from the analysis of spatial data, whose distributional properties for spectrogram extrema are mostly understood empirically. In this work, we investigate spectrogram analysis via an examination of the stochastic, geometric and analytical properties of their level sets. This includes a comparative analysis of relevant spectrogram structures, with vs without the presence of signals coupled with Gaussian white noise. We obtain theorems demonstrating the efficacy of a spectrogram level sets based approach to the detection and estimation of signals, framed in a concrete inferential set-up. Exploiting these ideas as theoretical underpinnings, we propose a level sets based algorithm for signal analysis that is intrinsic to given spectrogram data. We substantiate the effectiveness of the algorithm by extensive empirical studies, and provide additional theoretical analysis to elucidate some of its key features. Our results also have theoretical implications for spectrogram zero based approaches to signal analysis.
Action in Mind: A Neural Network Approach to Action Recognition and Segmentation
Apr 30, 2021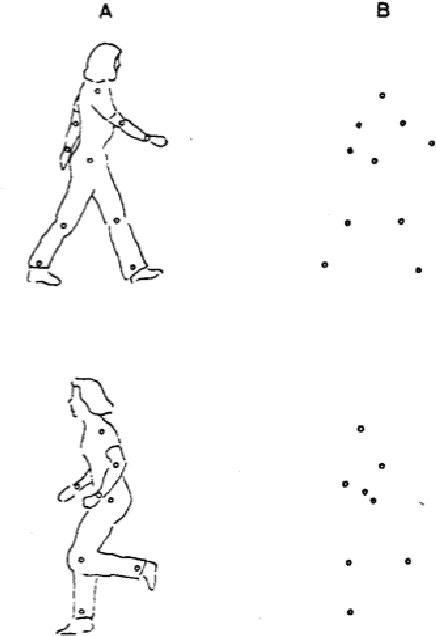
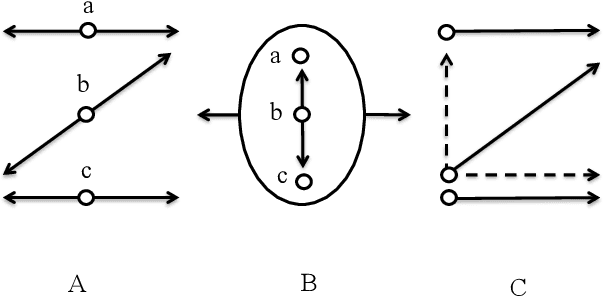
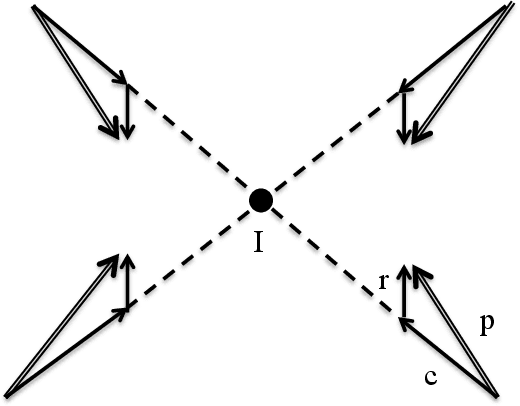
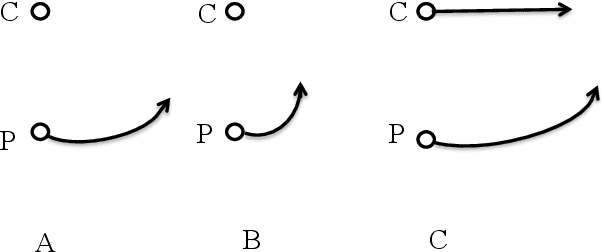
Recognizing and categorizing human actions is an important task with applications in various fields such as human-robot interaction, video analysis, surveillance, video retrieval, health care system and entertainment industry. This thesis presents a novel computational approach for human action recognition through different implementations of multi-layer architectures based on artificial neural networks. Each system level development is designed to solve different aspects of the action recognition problem including online real-time processing, action segmentation and the involvement of objects. The analysis of the experimental results are illustrated and described in six articles. The proposed action recognition architecture of this thesis is composed of several processing layers including a preprocessing layer, an ordered vector representation layer and three layers of neural networks. It utilizes self-organizing neural networks such as Kohonen feature maps and growing grids as the main neural network layers. Thus the architecture presents a biological plausible approach with certain features such as topographic organization of the neurons, lateral interactions, semi-supervised learning and the ability to represent high dimensional input space in lower dimensional maps. For each level of development the system is trained with the input data consisting of consecutive 3D body postures and tested with generalized input data that the system has never met before. The experimental results of different system level developments show that the system performs well with quite high accuracy for recognizing human actions.
Instance and Panoptic Segmentation Using Conditional Convolutions
Feb 05, 2021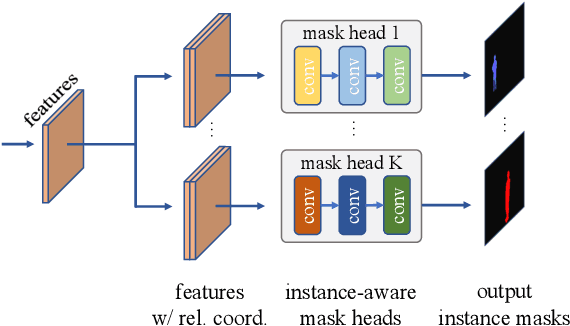


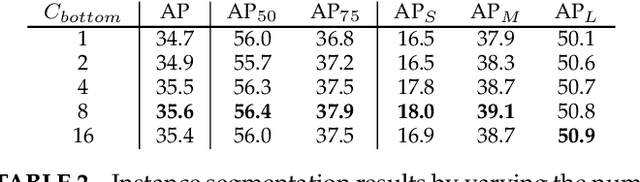
We propose a simple yet effective framework for instance and panoptic segmentation, termed CondInst (conditional convolutions for instance and panoptic segmentation). In the literature, top-performing instance segmentation methods typically follow the paradigm of Mask R-CNN and rely on ROI operations (typically ROIAlign) to attend to each instance. In contrast, we propose to attend to the instances with dynamic conditional convolutions. Instead of using instance-wise ROIs as inputs to the instance mask head of fixed weights, we design dynamic instance-aware mask heads, conditioned on the instances to be predicted. CondInst enjoys three advantages: 1.) Instance and panoptic segmentation are unified into a fully convolutional network, eliminating the need for ROI cropping and feature alignment. 2.) The elimination of the ROI cropping also significantly improves the output instance mask resolution. 3.) Due to the much improved capacity of dynamically-generated conditional convolutions, the mask head can be very compact (e.g., 3 conv. layers, each having only 8 channels), leading to significantly faster inference time per instance and making the overall inference time almost constant, irrelevant to the number of instances. We demonstrate a simpler method that can achieve improved accuracy and inference speed on both instance and panoptic segmentation tasks. On the COCO dataset, we outperform a few state-of-the-art methods. We hope that CondInst can be a strong baseline for instance and panoptic segmentation. Code is available at: https://git.io/AdelaiDet
StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
Jul 24, 2018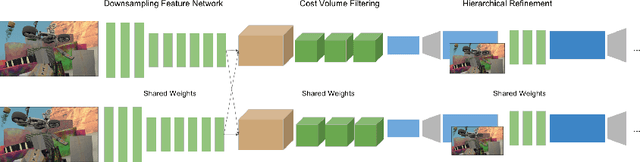
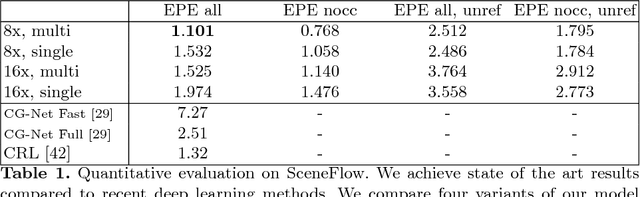
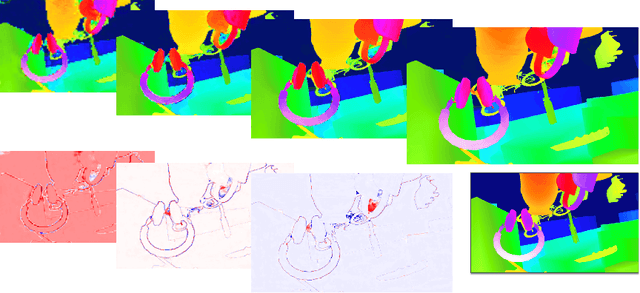
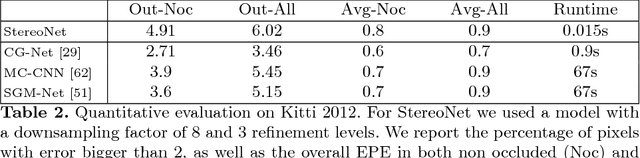
This paper presents StereoNet, the first end-to-end deep architecture for real-time stereo matching that runs at 60 fps on an NVidia Titan X, producing high-quality, edge-preserved, quantization-free disparity maps. A key insight of this paper is that the network achieves a sub-pixel matching precision than is a magnitude higher than those of traditional stereo matching approaches. This allows us to achieve real-time performance by using a very low resolution cost volume that encodes all the information needed to achieve high disparity precision. Spatial precision is achieved by employing a learned edge-aware upsampling function. Our model uses a Siamese network to extract features from the left and right image. A first estimate of the disparity is computed in a very low resolution cost volume, then hierarchically the model re-introduces high-frequency details through a learned upsampling function that uses compact pixel-to-pixel refinement networks. Leveraging color input as a guide, this function is capable of producing high-quality edge-aware output. We achieve compelling results on multiple benchmarks, showing how the proposed method offers extreme flexibility at an acceptable computational budget.
Unsupervised Contextual Paraphrase Generation using Lexical Control and Reinforcement Learning
Mar 23, 2021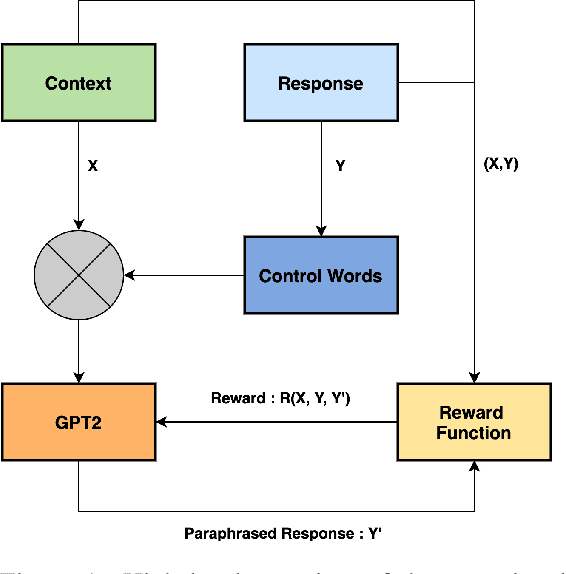


Customer support via chat requires agents to resolve customer queries with minimum wait time and maximum customer satisfaction. Given that the agents as well as the customers can have varying levels of literacy, the overall quality of responses provided by the agents tend to be poor if they are not predefined. But using only static responses can lead to customer detraction as the customers tend to feel that they are no longer interacting with a human. Hence, it is vital to have variations of the static responses to reduce monotonicity of the responses. However, maintaining a list of such variations can be expensive. Given the conversation context and the agent response, we propose an unsupervised frame-work to generate contextual paraphrases using autoregressive models. We also propose an automated metric based on Semantic Similarity, Textual Entailment, Expression Diversity and Fluency to evaluate the quality of contextual paraphrases and demonstrate performance improvement with Reinforcement Learning (RL) fine-tuning using the automated metric as the reward function.