 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Non-Sampling Knowledge Graph Embedding
Apr 30, 2021

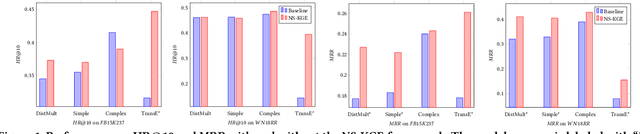
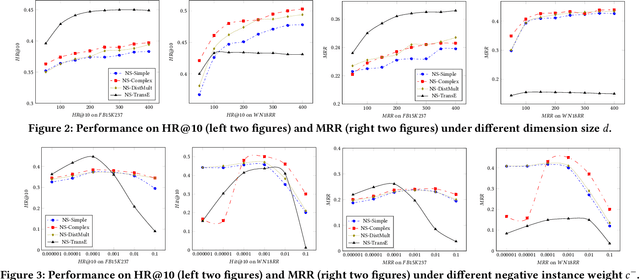
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
Few Shot Learning With No Labels
Dec 26, 2020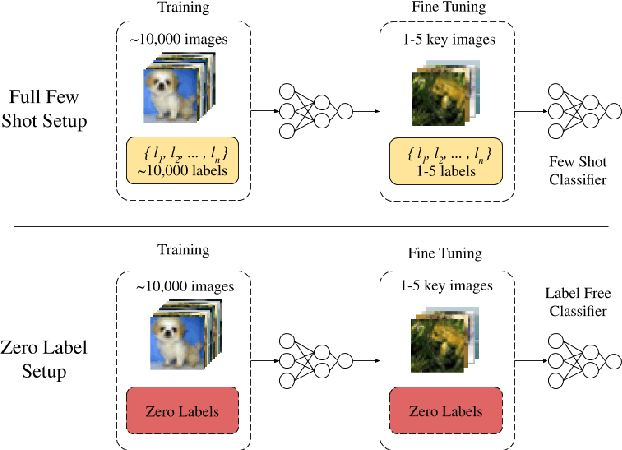

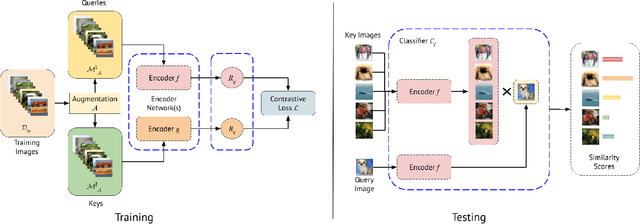
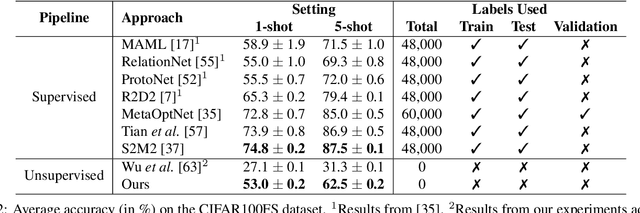
Few-shot learners aim to recognize new categories given only a small number of training samples. The core challenge is to avoid overfitting to the limited data while ensuring good generalization to novel classes. Existing literature makes use of vast amounts of annotated data by simply shifting the label requirement from novel classes to base classes. Since data annotation is time-consuming and costly, reducing the label requirement even further is an important goal. To that end, our paper presents a more challenging few-shot setting where no label access is allowed during training or testing. By leveraging self-supervision for learning image representations and image similarity for classification at test time, we achieve competitive baselines while using \textbf{zero} labels, which is at least fewer labels than state-of-the-art. We hope that this work is a step towards developing few-shot learning methods which do not depend on annotated data at all. Our code will be publicly released.
Focusing on What is Relevant: Time-Series Learning and Understanding using Attention
Jun 22, 2018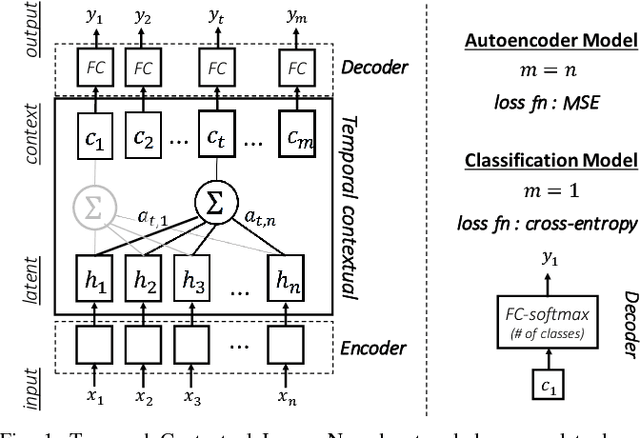
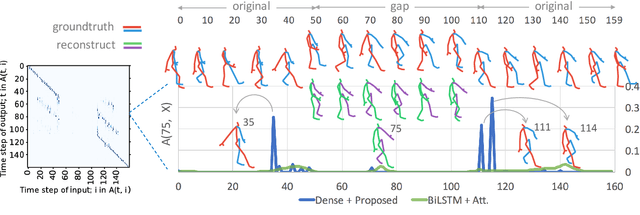

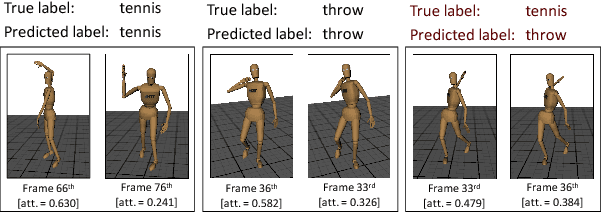
This paper is a contribution towards interpretability of the deep learning models in different applications of time-series. We propose a temporal attention layer that is capable of selecting the relevant information to perform various tasks, including data completion, key-frame detection and classification. The method uses the whole input sequence to calculate an attention value for each time step. This results in more focused attention values and more plausible visualisation than previous methods. We apply the proposed method to three different tasks. Experimental results show that the proposed network produces comparable results to a state of the art. In addition, the network provides better interpretability of the decision, that is, it generates more significant attention weight to related frames compared to similar techniques attempted in the past.
PMBM filter with partially grid-based birth model with applications in sensor management
Mar 19, 2021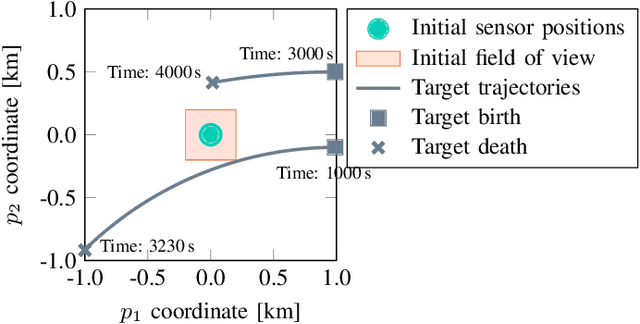
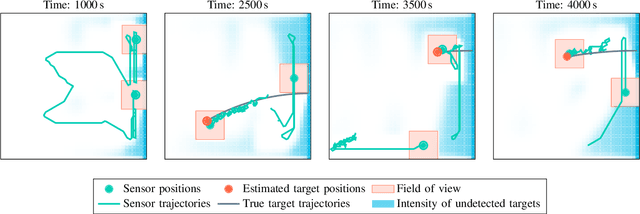
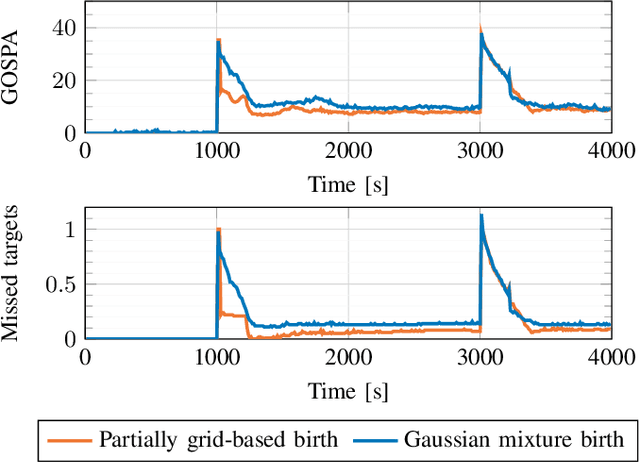
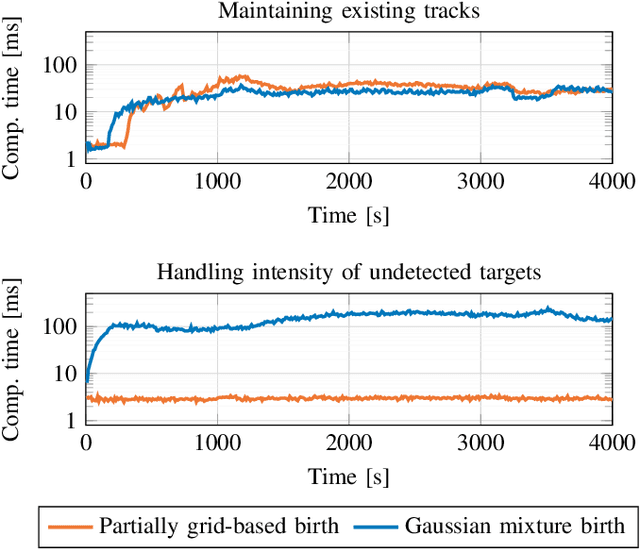
This paper introduces a Poisson multi-Bernoulli mixture (PMBM) filter in which the intensities of target birth and undetected targets are grid-based. A simplified version of the Rao-Blackwellized point mass filter is used to predict the intensity of undetected targets, and the density of targets detected for the first time are approximated as Gaussian. Whereas conventional PMBM filter implementations typically use Gaussian mixtures to model the intensity of undetected targets, the proposed representation allows the intensity to vary over the region of interest with sharp edges around the sensor's field of view, without using a large number of Gaussian mixture components. This reduces the computational complexity compared to the conventional approach. The proposed method is illustrated in a sensor management setting where trajectories of sensors with limited fields of view are controlled to search for and track the targets in a region of interest.
Analysis of high-dimensional Continuous Time Markov Chains using the Local Bouncy Particle Sampler
May 31, 2019


Sampling the parameters of high-dimensional Continuous Time Markov Chains (CTMC) is a challenging problem with important applications in many fields of applied statistics. In this work a recently proposed type of non-reversible rejection-free Markov Chain Monte Carlo (MCMC) sampler, the Bouncy Particle Sampler (BPS), is brought to bear to this problem. BPS has demonstrated its favorable computational efficiency compared with state-of-the-art MCMC algorithms, however to date applications to real-data scenario were scarce. An important aspect of the practical implementation of BPS is the simulation of event times. Default implementations use conservative thinning bounds. Such bounds can slow down the algorithm and limit the computational performance. Our paper develops an algorithm with an exact analytical solution to the random event times in the context of CTMCs. Our local version of BPS algorithm takes advantage of the sparse structure in the target factor graph and we also provide a framework for assessing the computational complexity of local BPS algorithms.
Data Processing for Short-Term Solar Irradiance Forecasting using Ground-Based Infrared Images
Jan 21, 2021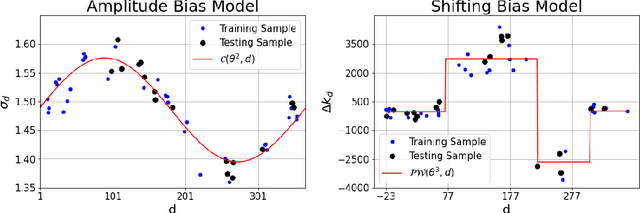
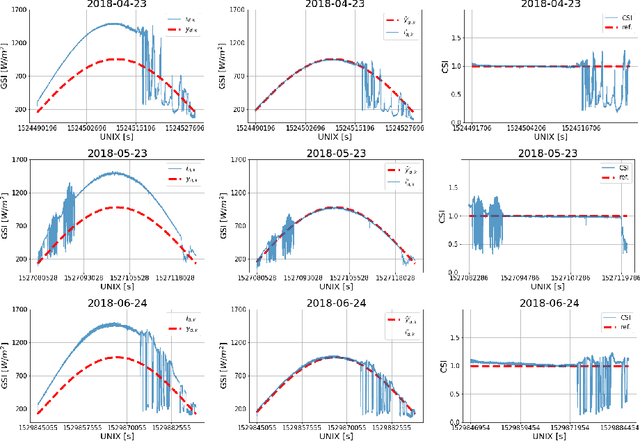
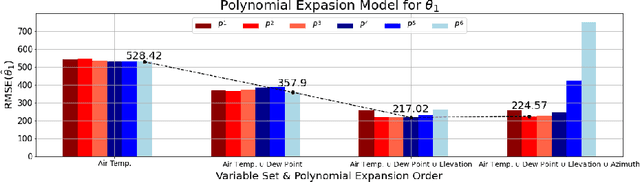
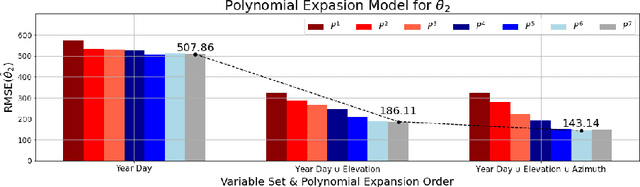
The generation of energy in a power grid which uses Photovoltaic (PV) systems depends on the projection of shadows from moving clouds in the Troposphere. This investigation proposes an efficient method of data processing for the statistical quantification of cloud features using long-wave infrared (IR) images and Global Solar Irradiance (GSI) measurements. The IR images are obtained using a data acquisition system (DAQ) mounted on a solar tracker. We explain how to remove cyclostationary biases in GSI measurements. Seasonal trends are removed from the GSI time series, using the theoretical GSI to obtain the Clear-Sky Index (CSI) time series. We introduce an atmospheric model to remove from IR images both the effect of atmosphere scatter irradiance and the effect of the Sun's direct irradiance. Scattering is produced by water spots and dust particles on the germanium lens of the enclosure. We explain how to remove the scattering effect produced by the germanium lens attached to the DAQ enclosure window of the IR camera. An atmospheric condition model classifies the sky-conditions in four different categories: clear-sky, cumulus, stratus and nimbus. When an IR image is classified in the category of clear-sky, it is used to model the scattering effect of the germanium lens.
On The Verification of Neural ODEs with Stochastic Guarantees
Dec 16, 2020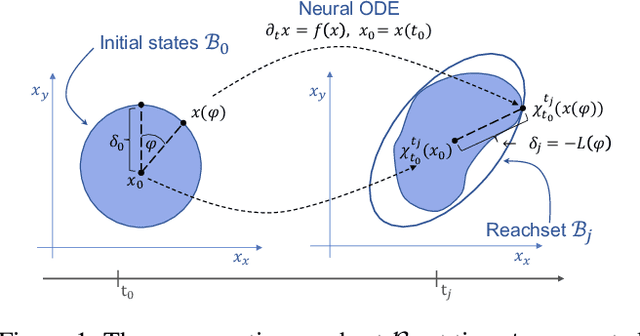
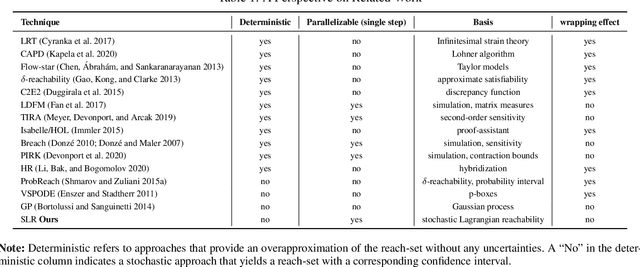
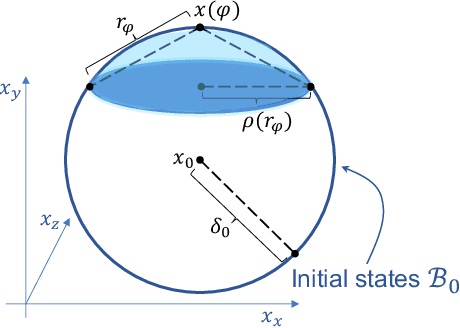
We show that Neural ODEs, an emerging class of time-continuous neural networks, can be verified by solving a set of global-optimization problems. For this purpose, we introduce Stochastic Lagrangian Reachability (SLR), an abstraction-based technique for constructing a tight Reachtube (an over-approximation of the set of reachable states over a given time-horizon), and provide stochastic guarantees in the form of confidence intervals for the Reachtube bounds. SLR inherently avoids the infamous wrapping effect (accumulation of over-approximation errors) by performing local optimization steps to expand safe regions instead of repeatedly forward-propagating them as is done by deterministic reachability methods. To enable fast local optimizations, we introduce a novel forward-mode adjoint sensitivity method to compute gradients without the need for backpropagation. Finally, we establish asymptotic and non-asymptotic convergence rates for SLR.
Evolving Real-Time Heuristics Search Algorithms with Building Blocks
May 21, 2018
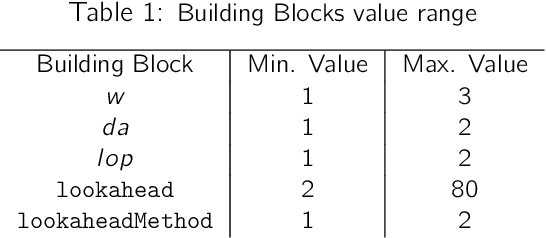
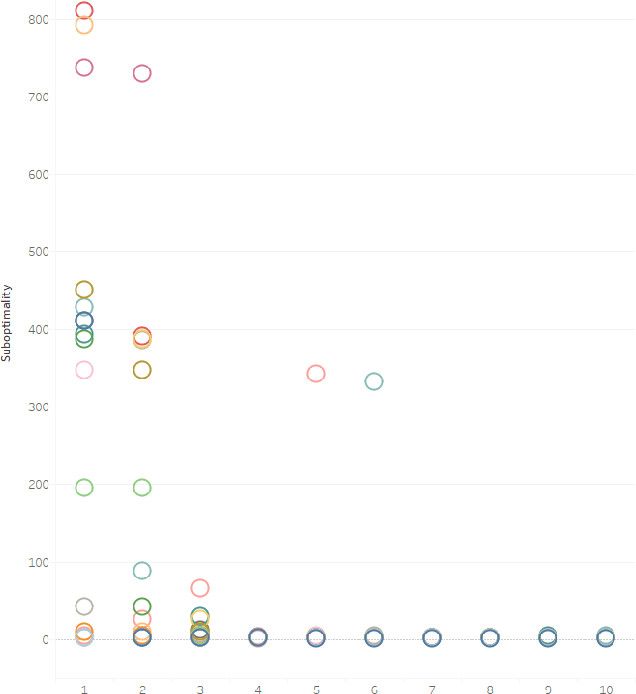
The research area of real-time heuristics search has produced quite many algorithms. In the landscape of real-time heuristics search research, it is not rare to find that an algorithm X that appears to perform better than algorithm Y on a group of problems, performed worse than Y for another group of problems. If these published algorithms are combined to generate a more powerful space of algorithms, then that novel space of algorithms may solve a distribution of problems more efficiently. Based on this intuition, a recent work Bulitko 2016 has defined the task of finding a combination of heuristics search algorithms as a survival task. In this evolutionary approach, a space of algorithms is defined over a set of building blocks published algorithms and a simulated evolution is used to recombine these building blocks to find out the best algorithm from that space of algorithms. In this paper, we extend the set of building blocks by adding one published algorithm, namely lookahead based A-star shaped local search space generation method from LSSLRTA-star, plus an unpublished novel strategy to generate local search space with Greedy Best First Search. Then we perform experiments in the new space of algorithms, which show that the best algorithms selected by the evolutionary process have the following property: the deeper is the lookahead depth of an algorithm, the lower is its suboptimality and scrubbing complexity.
R2N2: Residual Recurrent Neural Networks for Multivariate Time Series Forecasting
Sep 10, 2017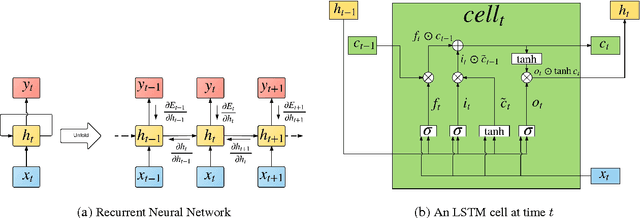
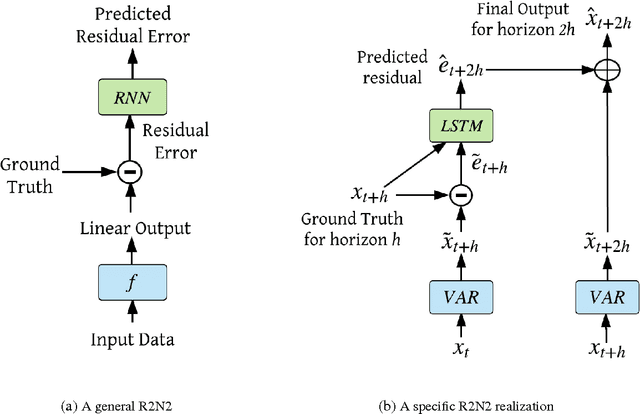
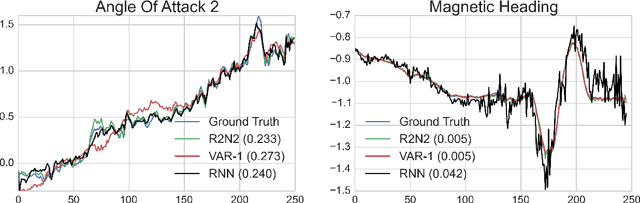
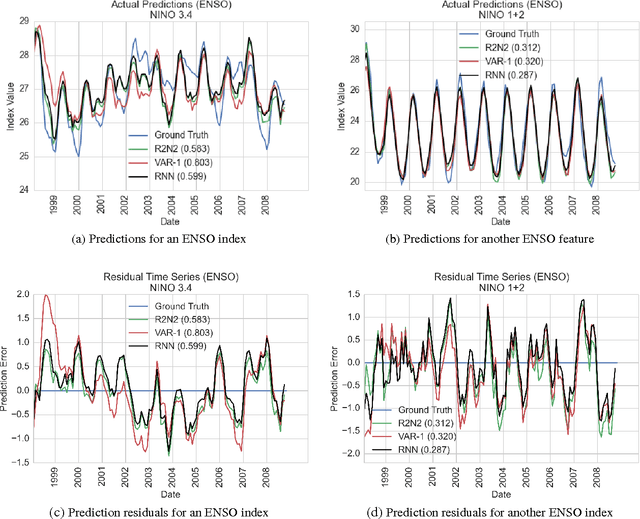
Multivariate time-series modeling and forecasting is an important problem with numerous applications. Traditional approaches such as VAR (vector auto-regressive) models and more recent approaches such as RNNs (recurrent neural networks) are indispensable tools in modeling time-series data. In many multivariate time series modeling problems, there is usually a significant linear dependency component, for which VARs are suitable, and a nonlinear component, for which RNNs are suitable. Modeling such times series with only VAR or only RNNs can lead to poor predictive performance or complex models with large training times. In this work, we propose a hybrid model called R2N2 (Residual RNN), which first models the time series with a simple linear model (like VAR) and then models its residual errors using RNNs. R2N2s can be trained using existing algorithms for VARs and RNNs. Through an extensive empirical evaluation on two real world datasets (aviation and climate domains), we show that R2N2 is competitive, usually better than VAR or RNN, used alone. We also show that R2N2 is faster to train as compared to an RNN, while requiring less number of hidden units.
Visually Guided Sound Source Separation and Localization using Self-Supervised Motion Representations
Apr 17, 2021
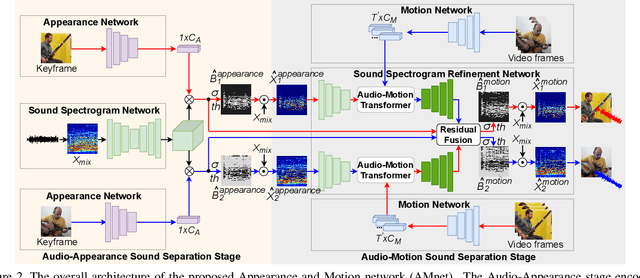
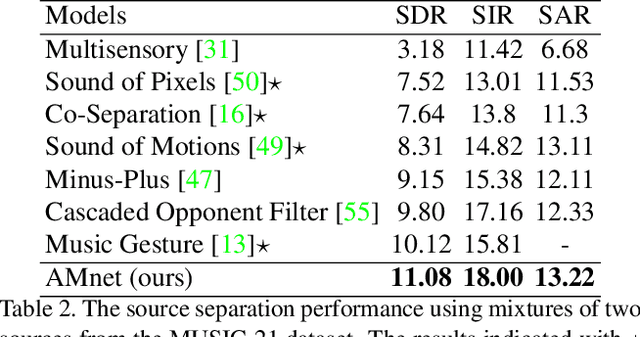
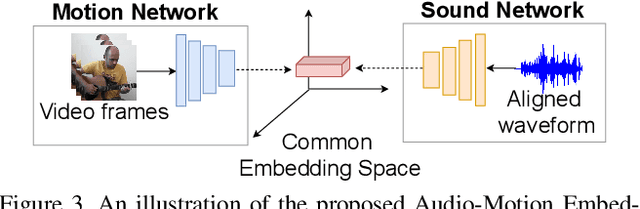
The objective of this paper is to perform audio-visual sound source separation, i.e.~to separate component audios from a mixture based on the videos of sound sources. Moreover, we aim to pinpoint the source location in the input video sequence. Recent works have shown impressive audio-visual separation results when using prior knowledge of the source type (e.g. human playing instrument) and pre-trained motion detectors (e.g. keypoints or optical flows). However, at the same time, the models are limited to a certain application domain. In this paper, we address these limitations and make the following contributions: i) we propose a two-stage architecture, called Appearance and Motion network (AMnet), where the stages specialise to appearance and motion cues, respectively. The entire system is trained in a self-supervised manner; ii) we introduce an Audio-Motion Embedding (AME) framework to explicitly represent the motions that related to sound; iii) we propose an audio-motion transformer architecture for audio and motion feature fusion; iv) we demonstrate state-of-the-art performance on two challenging datasets (MUSIC-21 and AVE) despite the fact that we do not use any pre-trained keypoint detectors or optical flow estimators. Project page: https://ly-zhu.github.io/self-supervised-motion-representations