 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lethean Attack: An Online Data Poisoning Technique
Nov 24, 2020
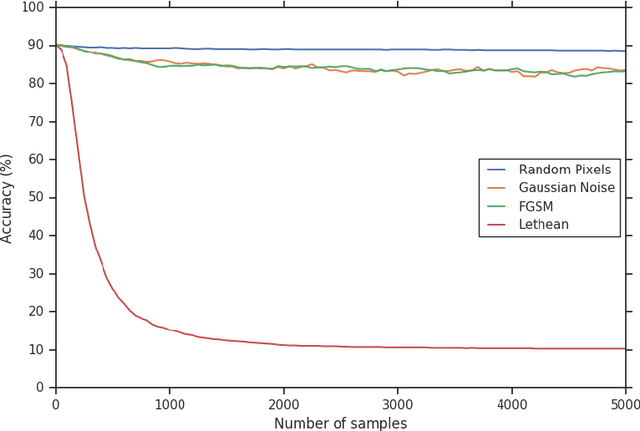
Data poisoning is an adversarial scenario where an attacker feeds a specially crafted sequence of samples to an online model in order to subvert learning. We introduce Lethean Attack, a novel data poisoning technique that induces catastrophic forgetting on an online model. We apply the attack in the context of Test-Time Training, a modern online learning framework aimed for generalization under distribution shifts. We present the theoretical rationale and empirically compare it against other sample sequences that naturally induce forgetting. Our results demonstrate that using lethean attacks, an adversary could revert a test-time training model back to coin-flip accuracy performance using a short sample sequence.
MultiCruise: Eco-Lane Selection Strategy with Eco-Cruise Control for Connected and Automated Vehicles
Apr 24, 2021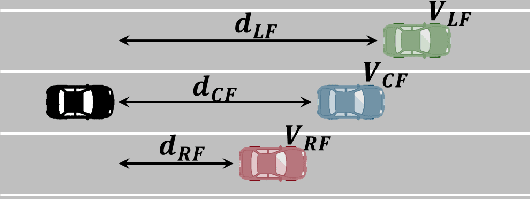
Connected and Automated Vehicles (CAVs) have real-time information from the surrounding environment by using local on-board sensors, V2X (Vehicle-to-Everything) communications, pre-loaded vehicle-specific lookup tables, and map database. CAVs are capable of improving energy efficiency by incorporating these information. In particular, Eco-Cruise and Eco-Lane Selection on highways and/or motorways have immense potential to save energy, because there are generally fewer traffic controllers and the vehicles keep moving in general. In this paper, we present a cooperative and energy-efficient lane-selection strategy named MultiCruise, where each CAV selects one among multiple candidate lanes that allows the most energy-efficient travel. MultiCruise incorporates an Eco-Cruise component to select the most energy-efficient lane. The Eco-Cruise component calculates the driving parameters and prospective energy consumption of the ego vehicle for each candidate lane, and the Eco-Lane Selection component uses these values. As a result, MultiCruise can account for multiple data sources, such as the road curvature and the surrounding vehicles' velocities and accelerations. The eco-autonomous driving strategy, MultiCruise, is tested, designed and verified by using a co-simulation test platform that includes autonomous driving software and realistic road networks to study the performance under realistic driving conditions. Our experimental evaluations show that our eco-autonomous MultiCruise saves up to 8.5% fuel consumption.
CrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Mar 14, 2021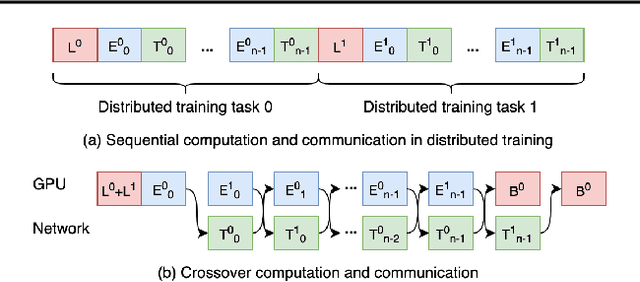
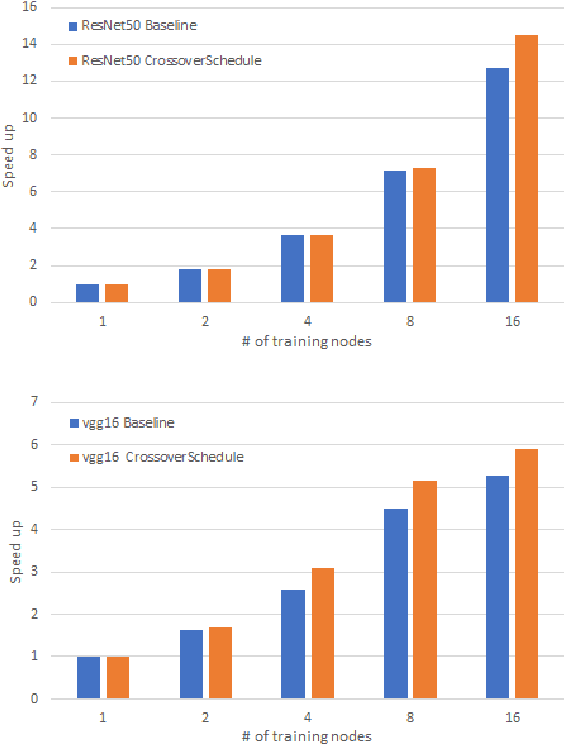
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.
Submodular Maximization via Taylor Series Approximation
Jan 19, 2021

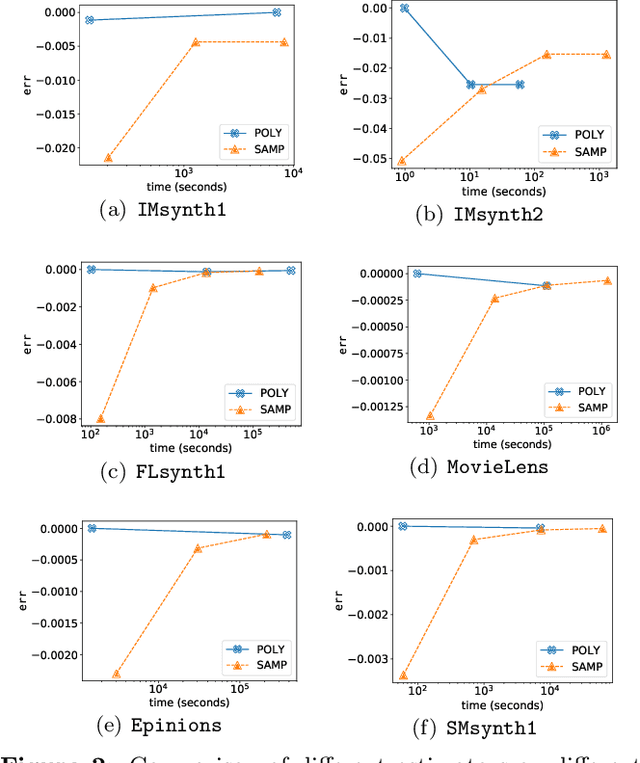
We study submodular maximization problems with matroid constraints, in particular, problems where the objective can be expressed via compositions of analytic and multilinear functions. We show that for functions of this form, the so-called continuous greedy algorithm attains a ratio arbitrarily close to $(1-1/e) \approx 0.63$ using a deterministic estimation via Taylor series approximation. This drastically reduces execution time over prior art that uses sampling.
Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities
Apr 30, 2021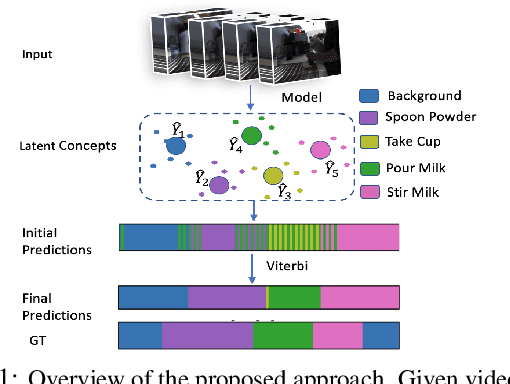
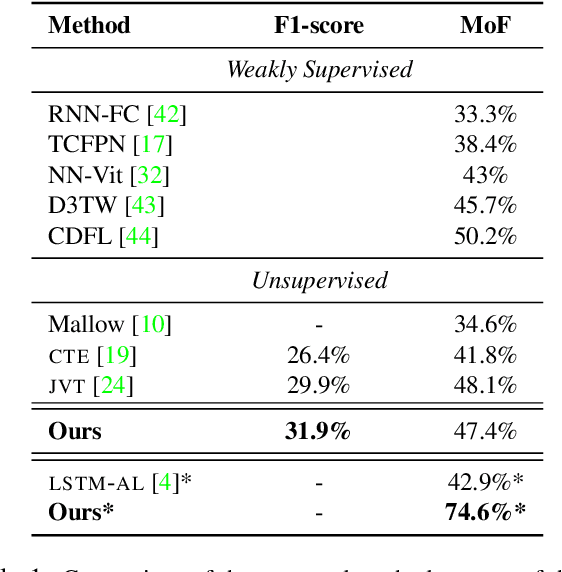
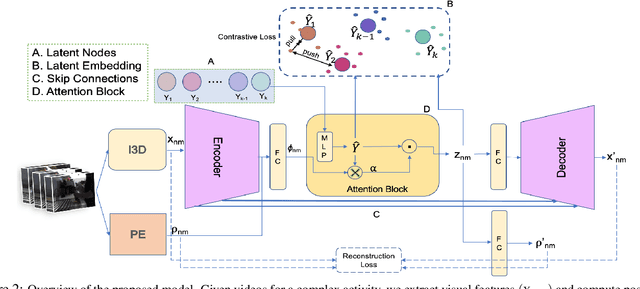

Action recognition and detection in the context of long untrimmed video sequences has seen an increased attention from the research community. However, annotation of complex activities is usually time consuming and challenging in practice. Therefore, recent works started to tackle the problem of unsupervised learning of sub-actions in complex activities. This paper proposes a novel approach for unsupervised sub-action learning in complex activities. The proposed method maps both visual and temporal representations to a latent space where the sub-actions are learnt discriminatively in an end-to-end fashion. To this end, we propose to learn sub-actions as latent concepts and a novel discriminative latent concept learning (DLCL) module aids in learning sub-actions. The proposed DLCL module lends on the idea of latent concepts to learn compact representations in the latent embedding space in an unsupervised way. The result is a set of latent vectors that can be interpreted as cluster centers in the embedding space. The latent space itself is formed by a joint visual and temporal embedding capturing the visual similarity and temporal ordering of the data. Our joint learning with discriminative latent concept module is novel which eliminates the need for explicit clustering. We validate our approach on three benchmark datasets and show that the proposed combination of visual-temporal embedding and discriminative latent concepts allow to learn robust action representations in an unsupervised setting.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 30, 2021
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
Distributed storage algorithms with optimal tradeoffs
Jan 13, 2021
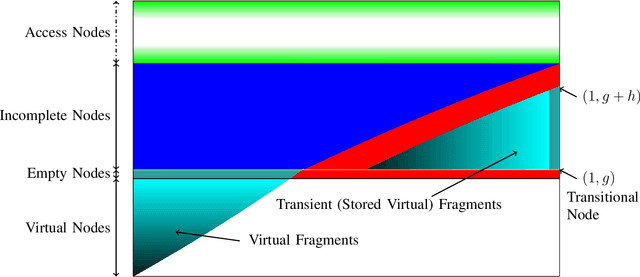
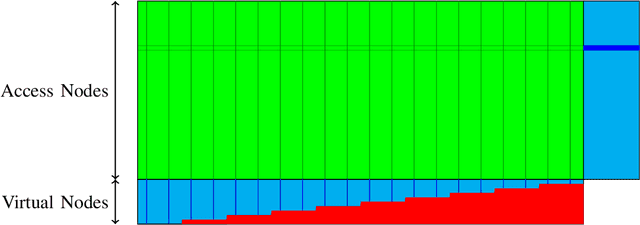
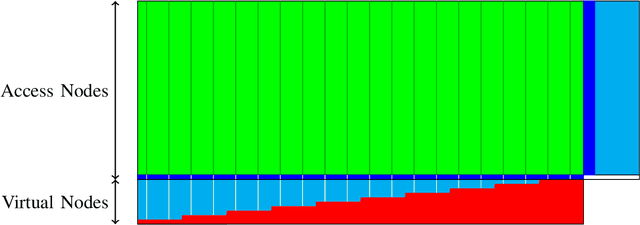
One of the primary objectives of a distributed storage system is to reliably store large amounts of source data for long durations using a large number $N$ of unreliable storage nodes, each with $c$ bits of storage capacity. Storage nodes fail randomly over time and are replaced with nodes of equal capacity initialized to zeroes, and thus bits are erased at some rate $e$. To maintain recoverability of the source data, a repairer continually reads data over a network from nodes at an average rate $r$, and generates and writes data to nodes based on the read data. The distributed storage source capacity is the maximum amount of source that can be reliably stored for long periods of time. Previous research shows that asymptotically the distributed storage source capacity is at most $\left(1-\frac{e}{2 \cdot r}\right) \cdot N \cdot c$ as $N$ and $r$ grow. In this work we introduce and analyze algorithms such that asymptotically the distributed storage source data capacity is at least the above equation. Thus, the above equation expresses a fundamental trade-off between network traffic and storage overhead to reliably store source data.
PMBM filter with partially grid-based birth model with applications in sensor management
Mar 19, 2021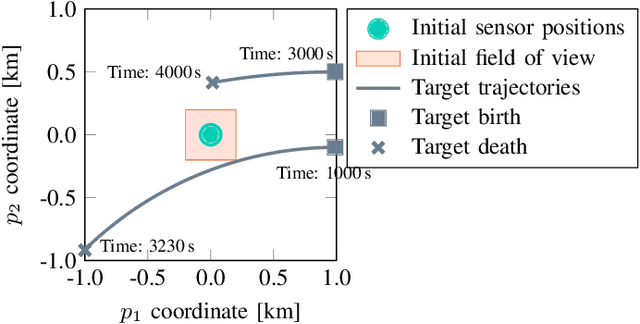
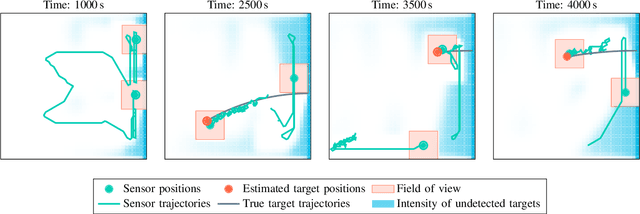
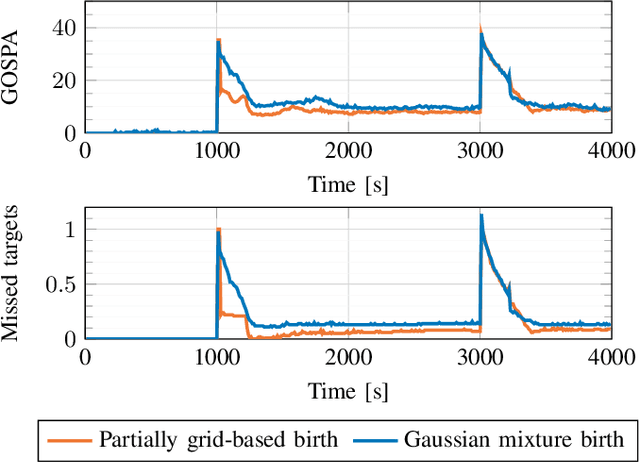
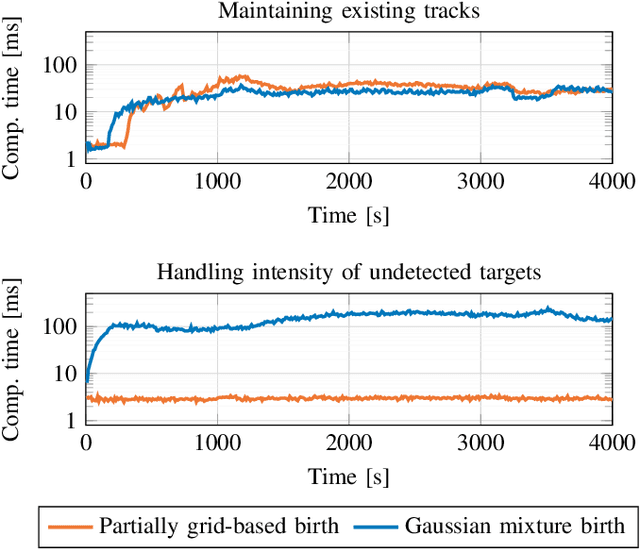
This paper introduces a Poisson multi-Bernoulli mixture (PMBM) filter in which the intensities of target birth and undetected targets are grid-based. A simplified version of the Rao-Blackwellized point mass filter is used to predict the intensity of undetected targets, and the density of targets detected for the first time are approximated as Gaussian. Whereas conventional PMBM filter implementations typically use Gaussian mixtures to model the intensity of undetected targets, the proposed representation allows the intensity to vary over the region of interest with sharp edges around the sensor's field of view, without using a large number of Gaussian mixture components. This reduces the computational complexity compared to the conventional approach. The proposed method is illustrated in a sensor management setting where trajectories of sensors with limited fields of view are controlled to search for and track the targets in a region of interest.
A CNN adapted to time series for the classification of Supernovae
Jan 02, 2019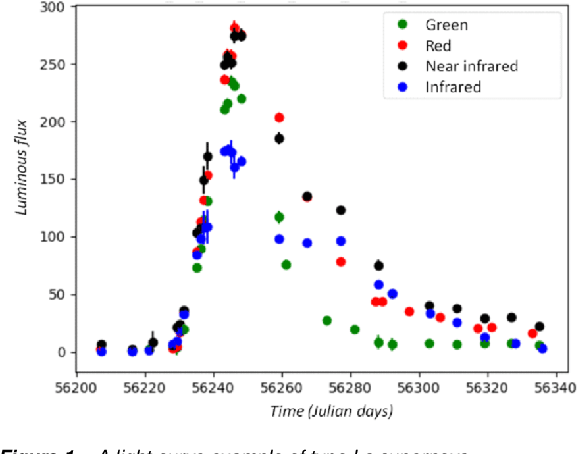
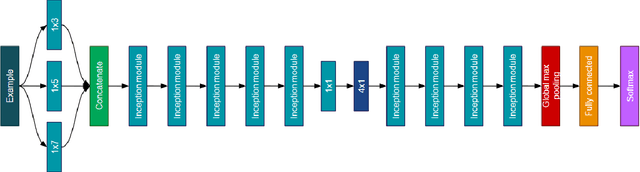
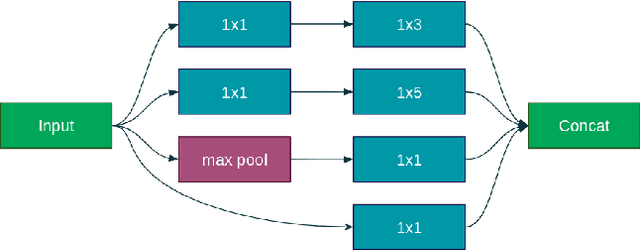
Cosmologists are facing the problem of the analysis of a huge quantity of data when observing the sky. The methods used in cosmology are, for the most of them, relying on astrophysical models, and thus, for the classification, they usually use a machine learning approach in two-steps, which consists in, first, extracting features, and second, using a classifier. In this paper, we are specifically studying the supernovae phenomenon and especially the binary classification "I.a supernovae versus not-I.a supernovae". We present two Convolutional Neural Networks (CNNs) defeating the current state-of-the-art. The first one is adapted to time series and thus to the treatment of supernovae light-curves. The second one is based on a Siamese CNN and is suited to the nature of data, i.e. their sparsity and their weak quantity (small learning database).
MC-LSTM: Mass-Conserving LSTM
Jan 13, 2021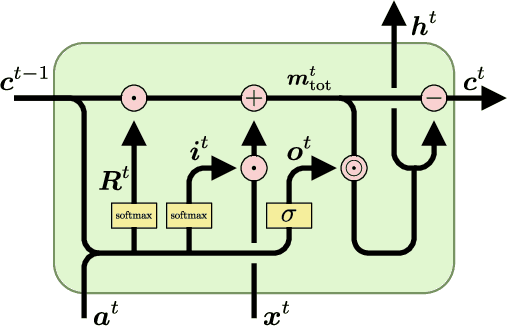
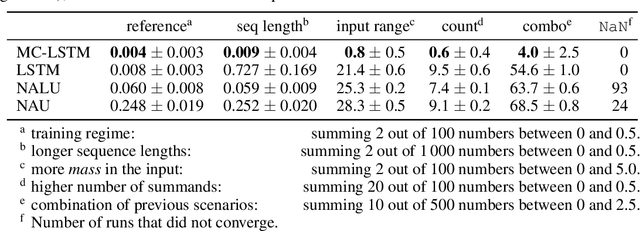
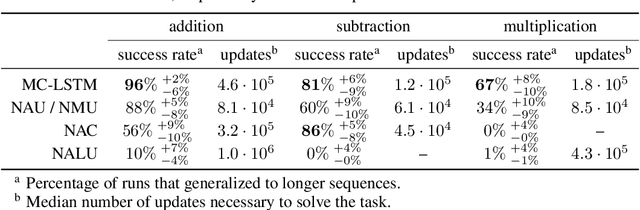
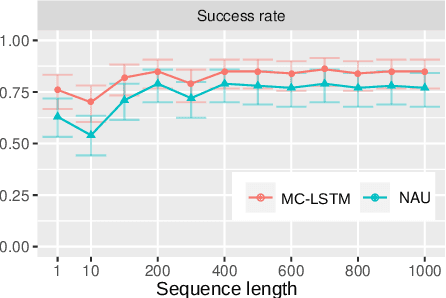
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.