 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Multi-Objective Optimization for Deep Learning
Mar 24, 2021
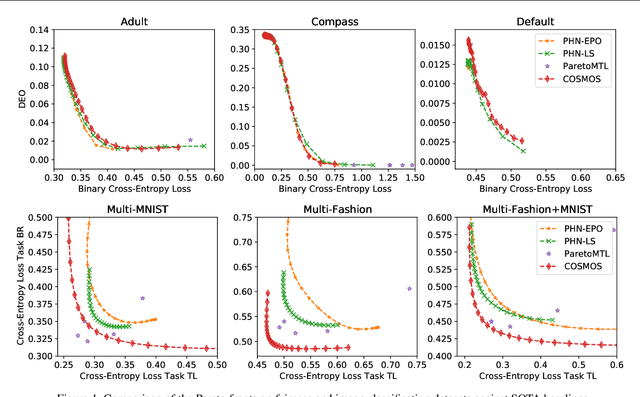
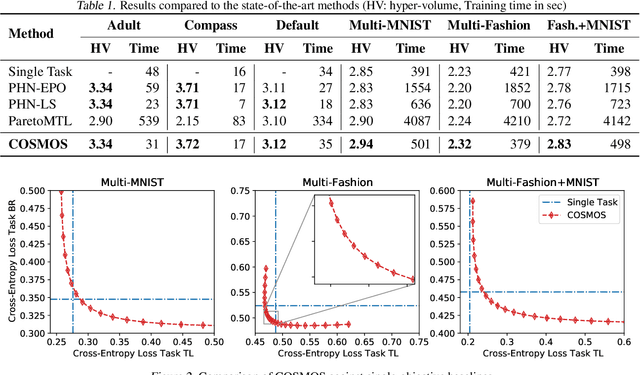
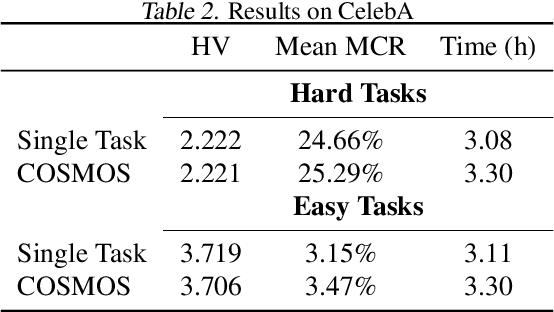
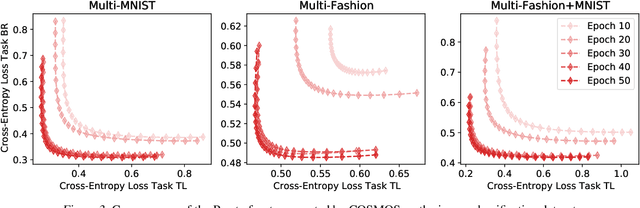
Multi-objective optimization (MOO) is a prevalent challenge for Deep Learning, however, there exists no scalable MOO solution for truly deep neural networks. Prior work either demand optimizing a new network for every point on the Pareto front, or induce a large overhead to the number of trainable parameters by using hyper-networks conditioned on modifiable preferences. In this paper, we propose to condition the network directly on these preferences by augmenting them to the feature space. Furthermore, we ensure a well-spread Pareto front by penalizing the solutions to maintain a small angle to the preference vector. In a series of experiments, we demonstrate that our Pareto fronts achieve state-of-the-art quality despite being computed significantly faster. Furthermore, we showcase the scalability as our method approximates the full Pareto front on the CelebA dataset with an EfficientNet network at a tiny training time overhead of 7% compared to a simple single-objective optimization. We make our code publicly available at https://github.com/ruchtem/cosmos.
Analysis of high-dimensional Continuous Time Markov Chains using the Local Bouncy Particle Sampler
Jun 03, 2019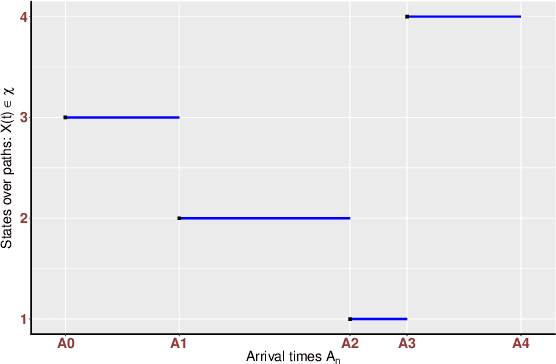

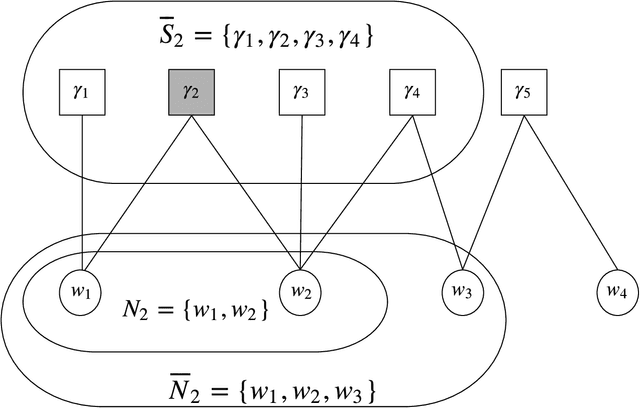

Sampling the parameters of high-dimensional Continuous Time Markov Chains (CTMC) is a challenging problem with important applications in many fields of applied statistics. In this work a recently proposed type of non-reversible rejection-free Markov Chain Monte Carlo (MCMC) sampler, the Bouncy Particle Sampler (BPS), is brought to bear to this problem. BPS has demonstrated its favorable computational efficiency compared with state-of-the-art MCMC algorithms, however to date applications to real-data scenario were scarce. An important aspect of the practical implementation of BPS is the simulation of event times. Default implementations use conservative thinning bounds. Such bounds can slow down the algorithm and limit the computational performance. Our paper develops an algorithm with an exact analytical solution to the random event times in the context of CTMCs. Our local version of BPS algorithm takes advantage of the sparse structure in the target factor graph and we also provide a framework for assessing the computational complexity of local BPS algorithms.
One-time learning and reverse salience signal with a salience affected neural network (SANN)
Aug 12, 2019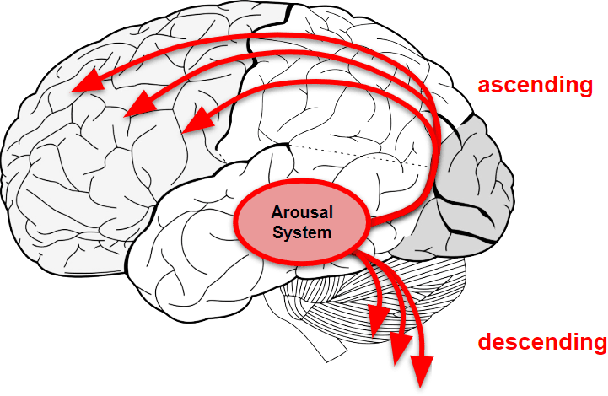
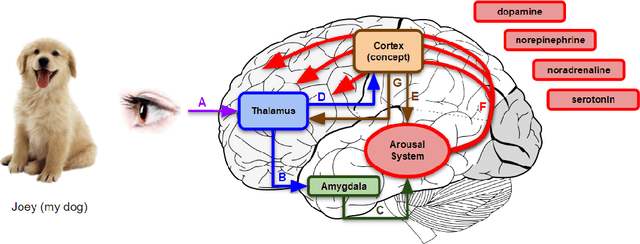
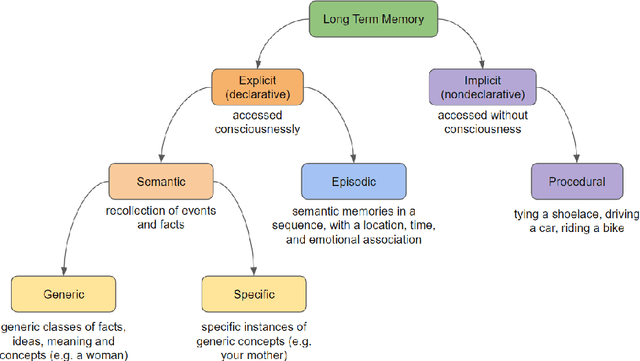
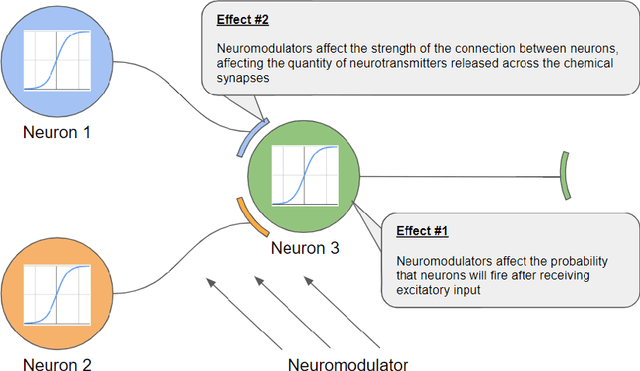
Standard artificial neural networks model key cognitive aspects of brain function, such as learning and classification, but they do not model the affective (emotional) aspects; however primary and secondary emotions play a key role in interactions with the physical, ecological, and social environment. These emotions are associated with memories when neuromodulators such as dopamine and noradrenaline affect entire patterns of synaptically activated neurons. Standard artificial neural networks (ANNs) do not model this non-local effect of neuromodulators, which are a significant feature in the brain (the associated `ascending systems' have been hard-wired into the brain by evolutionary processes). In this paper we present a salience-affected neural network (SANN) model which, at the same time as local network processing of task-specific information, includes non-local salience (significance) effects responding to an input salience signal. We show that during training, a SANN allows for single-exposure learning of an image and associated salience signal. During pattern recognition, input combinations similar to the salience-affected inputs in the training data sets will produce reverse salience signals corresponding to those experienced when the memories were laid down. In addition, training with salience affects the weights of connections between nodes, and improves the overall accuracy of a classification of images similar to the salience-tagged input after just a single iteration of training.
Vulnerability of Appearance-based Gaze Estimation
Mar 24, 2021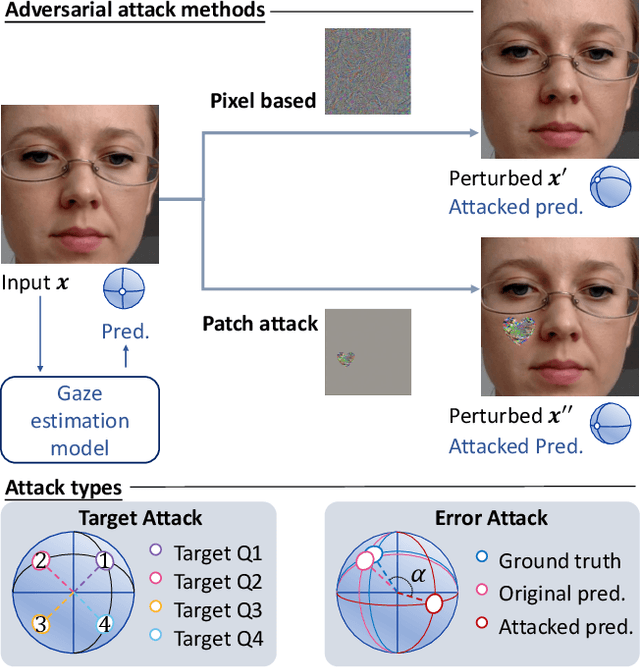
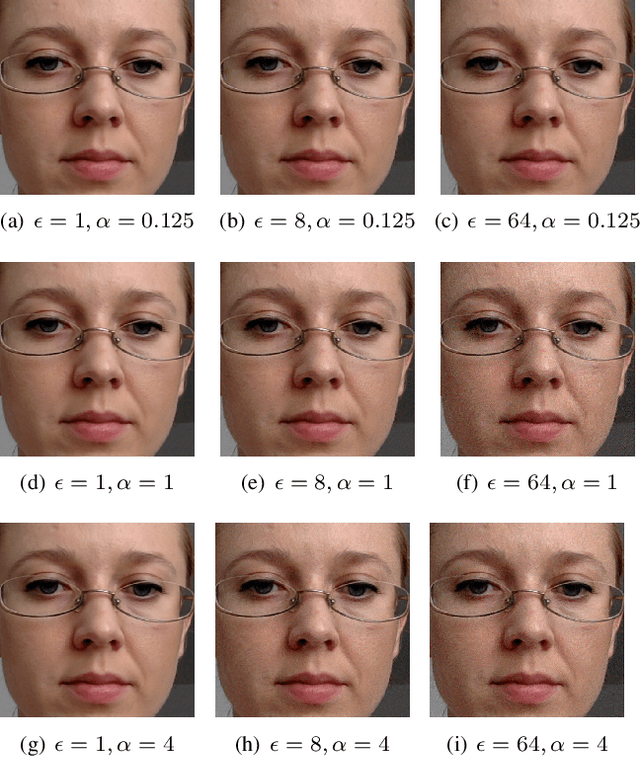
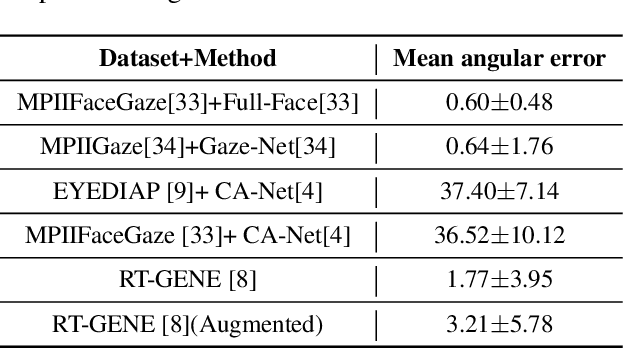
Appearance-based gaze estimation has achieved significant improvement by using deep learning. However, many deep learning-based methods suffer from the vulnerability property, i.e., perturbing the raw image using noise confuses the gaze estimation models. Although the perturbed image visually looks similar to the original image, the gaze estimation models output the wrong gaze direction. In this paper, we investigate the vulnerability of appearance-based gaze estimation. To our knowledge, this is the first time that the vulnerability of gaze estimation to be found. We systematically characterized the vulnerability property from multiple aspects, the pixel-based adversarial attack, the patch-based adversarial attack and the defense strategy. Our experimental results demonstrate that the CA-Net shows superior performance against attack among the four popular appearance-based gaze estimation networks, Full-Face, Gaze-Net, CA-Net and RT-GENE. This study draws the attention of researchers in the appearance-based gaze estimation community to defense from adversarial attacks.
Do as we do: Multiple Person Video-To-Video Transfer
Apr 10, 2021



Our goal is to transfer the motion of real people from a source video to a target video with realistic results. While recent advances significantly improved image-to-image translations, only few works account for body motions and temporal consistency. However, those focus only on video re-targeting for a single actor/ for single actors. In this work, we propose a marker-less approach for multiple-person video-to-video transfer using pose as an intermediate representation. Given a source video with multiple persons dancing or working out, our method transfers the body motion of all actors to a new set of actors in a different video. Differently from recent "do as I do" methods, we focus specifically on transferring multiple person at the same time and tackle the related identity switch problem. Our method is able to convincingly transfer body motion to the target video, while preserving specific features of the target video, such as feet touching the floor and relative position of the actors. The evaluation is performed with visual quality and appearance metrics using publicly available videos with the permission of their owners.
Can Machine Learning Help in Solving Cargo Capacity Management Booking Control Problems?
Jan 29, 2021
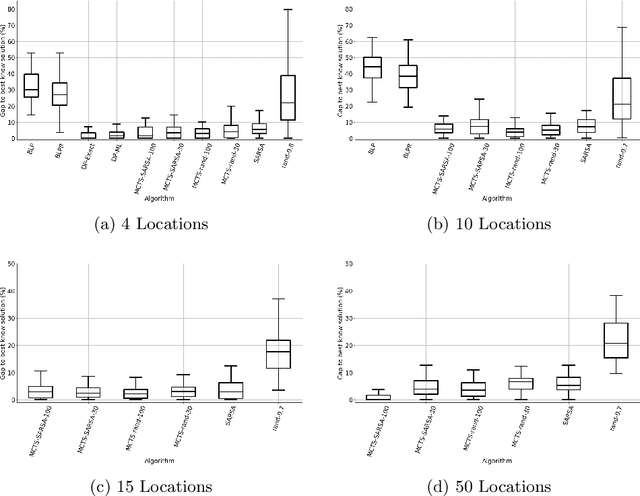
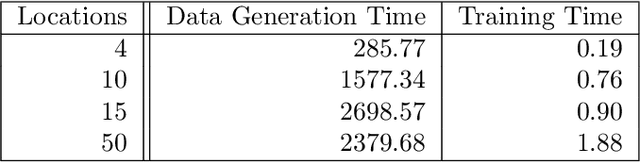
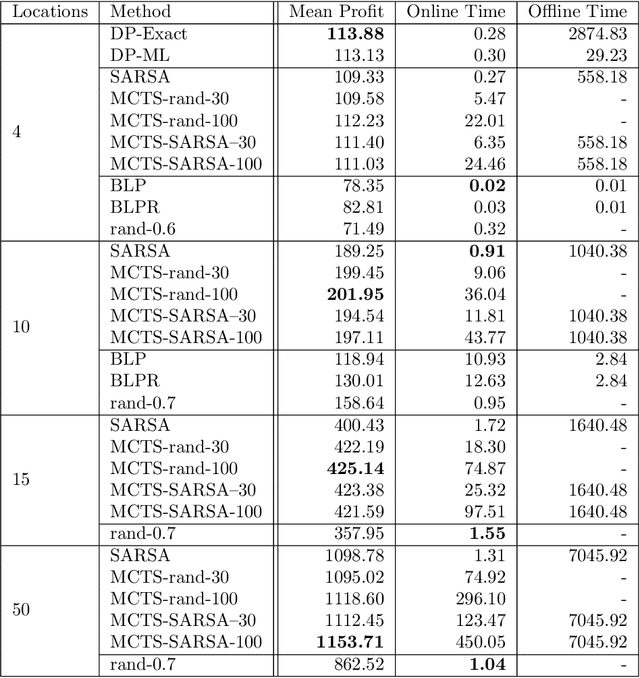
Revenue management is important for carriers (e.g., airlines and railroads). In this paper, we focus on cargo capacity management which has received less attention in the literature than its passenger counterpart. More precisely, we focus on the problem of controlling booking accept/reject decisions: Given a limited capacity, accept a booking request or reject it to reserve capacity for future bookings with potentially higher revenue. We formulate the problem as a finite-horizon stochastic dynamic program. The cost of fulfilling the accepted bookings, incurred at the end of the horizon, depends on the packing and routing of the cargo. This is a computationally challenging aspect as the latter are solutions to an operational decision-making problem, in our application a vehicle routing problem (VRP). Seeking a balance between online and offline computation, we propose to train a predictor of the solution costs to the VRPs using supervised learning. In turn, we use the predictions online in approximate dynamic programming and reinforcement learning algorithms to solve the booking control problem. We compare the results to an existing approach in the literature and show that we are able to obtain control policies that provide increased profit at a reduced evaluation time. This is achieved thanks to accurate approximation of the operational costs and negligible computing time in comparison to solving the VRPs.
MultiCruise: Eco-Lane Selection Strategy with Eco-Cruise Control for Connected and Automated Vehicles
Apr 24, 2021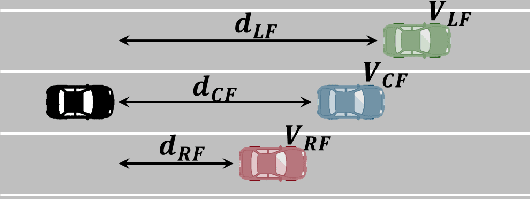
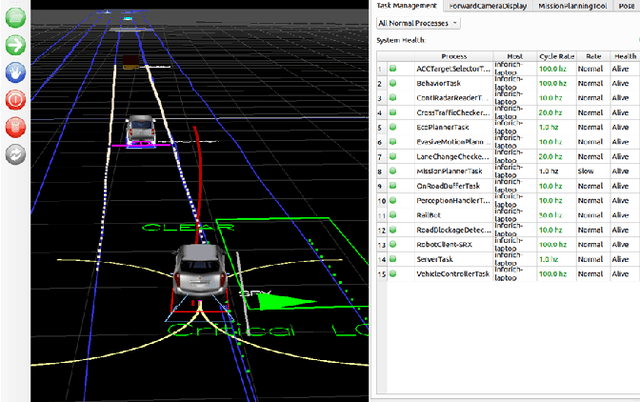
Connected and Automated Vehicles (CAVs) have real-time information from the surrounding environment by using local on-board sensors, V2X (Vehicle-to-Everything) communications, pre-loaded vehicle-specific lookup tables, and map database. CAVs are capable of improving energy efficiency by incorporating these information. In particular, Eco-Cruise and Eco-Lane Selection on highways and/or motorways have immense potential to save energy, because there are generally fewer traffic controllers and the vehicles keep moving in general. In this paper, we present a cooperative and energy-efficient lane-selection strategy named MultiCruise, where each CAV selects one among multiple candidate lanes that allows the most energy-efficient travel. MultiCruise incorporates an Eco-Cruise component to select the most energy-efficient lane. The Eco-Cruise component calculates the driving parameters and prospective energy consumption of the ego vehicle for each candidate lane, and the Eco-Lane Selection component uses these values. As a result, MultiCruise can account for multiple data sources, such as the road curvature and the surrounding vehicles' velocities and accelerations. The eco-autonomous driving strategy, MultiCruise, is tested, designed and verified by using a co-simulation test platform that includes autonomous driving software and realistic road networks to study the performance under realistic driving conditions. Our experimental evaluations show that our eco-autonomous MultiCruise saves up to 8.5% fuel consumption.
Repetitive Activity Counting by Sight and Sound
Mar 24, 2021



This paper strives for repetitive activity counting in videos. Different from existing works, which all analyze the visual video content only, we incorporate for the first time the corresponding sound into the repetition counting process. This benefits accuracy in challenging vision conditions such as occlusion, dramatic camera view changes, low resolution, etc. We propose a model that starts with analyzing the sight and sound streams separately. Then an audiovisual temporal stride decision module and a reliability estimation module are introduced to exploit cross-modal temporal interaction. For learning and evaluation, an existing dataset is repurposed and reorganized to allow for repetition counting with sight and sound. We also introduce a variant of this dataset for repetition counting under challenging vision conditions. Experiments demonstrate the benefit of sound, as well as the other introduced modules, for repetition counting. Our sight-only model already outperforms the state-of-the-art by itself, when we add sound, results improve notably, especially under harsh vision conditions.
Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities
Apr 30, 2021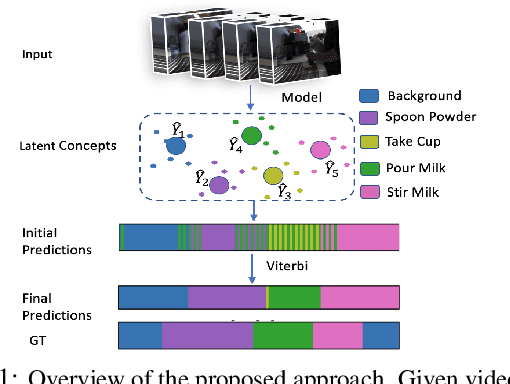
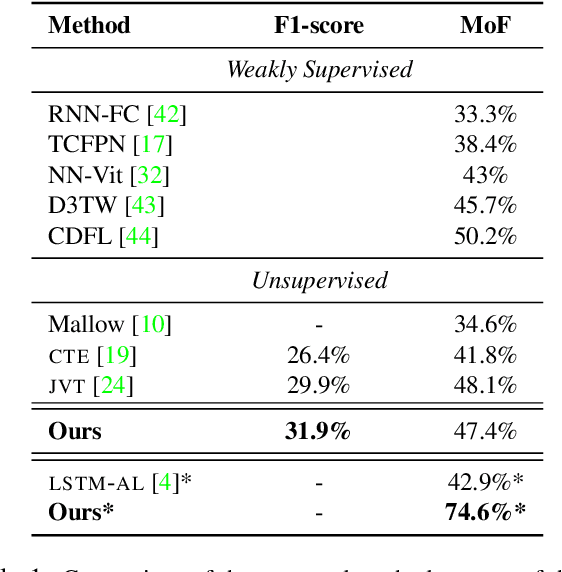
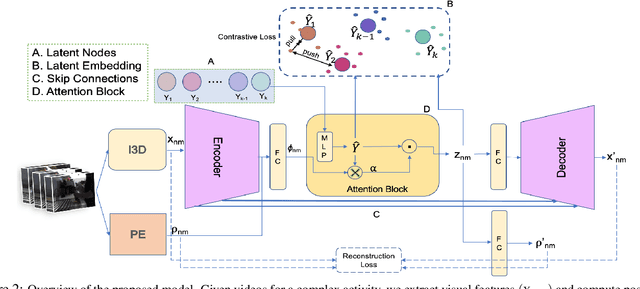

Action recognition and detection in the context of long untrimmed video sequences has seen an increased attention from the research community. However, annotation of complex activities is usually time consuming and challenging in practice. Therefore, recent works started to tackle the problem of unsupervised learning of sub-actions in complex activities. This paper proposes a novel approach for unsupervised sub-action learning in complex activities. The proposed method maps both visual and temporal representations to a latent space where the sub-actions are learnt discriminatively in an end-to-end fashion. To this end, we propose to learn sub-actions as latent concepts and a novel discriminative latent concept learning (DLCL) module aids in learning sub-actions. The proposed DLCL module lends on the idea of latent concepts to learn compact representations in the latent embedding space in an unsupervised way. The result is a set of latent vectors that can be interpreted as cluster centers in the embedding space. The latent space itself is formed by a joint visual and temporal embedding capturing the visual similarity and temporal ordering of the data. Our joint learning with discriminative latent concept module is novel which eliminates the need for explicit clustering. We validate our approach on three benchmark datasets and show that the proposed combination of visual-temporal embedding and discriminative latent concepts allow to learn robust action representations in an unsupervised setting.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 30, 2021
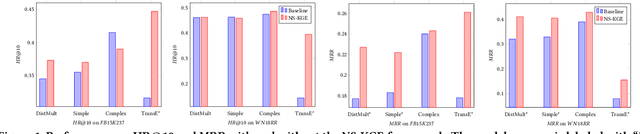
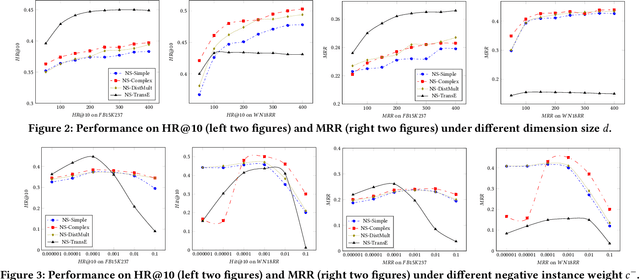
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.